
面向篇章的框架关系预测的表示学习
2023-05-08 03:01吕国英任国华
计算机应用与软件 2023年4期
王 燕 吕国英 李 茹,2,3 任国华
1(山西大学计算机与信息技术学院 山西 太原 030006) 2(山西大学计算智能与中文信息处理教育部重点实验室 山西 太原 030006) 3(山西省大数据挖掘与智能技术协同创新中心 山西 太原 030006)
0 引 言
汉语框架网(Chinese FrameNet,CFN)[1]是山西大学从2006年开始,基于框架语义学理论[2],以汉语真实语料为依据,参照英文FrameNet(FN)[3]的构建方法逐步构建的。CFN[4]是一种重要的可以用于汉语语义分析的知识库,该知识库由词元库、框架库和例句库三部分组成。词元是指能够激发语义场景的词语,包括动词、形容词和名词等,是框架的承担词。框架是由词元和每个框架特有的框架元素构成的用来描述一个事件或一个语义场景[5]的一组概念,其形成的框架网络体系使各个框架之间建立起语义关联[6]。
框架关系用来描述两个框架之间的语义关系,FrameNet中的框架关系类型[7]共分为八类十三种,分别是继承关系、透视关系、总分关系、先后关系、起始关系、致使关系、使用关系和参照关系八类[8],其中五类具有相反关系,分别是继承关系(分为Inherits From,Is Inherited By)、透视关系(分为Perspective on,Is Perspectivized in)、总分关系(分为Subframe of,Has Subframe(s))、先后关系(分为Precedes,Is Preceded by)和使用关系(分为Uses,Is Used by),CFN继承使用了FN中的八类十三种框架关系类型,本文使用十三种英文状态的框架关系类型进行框架关系预测。
基于汉语框架语义的推理是实现语义理解的有效手段,框架关系为篇章语义分析提供了一种语义资源,通过标注篇章中多个句子框架(词元所属框架)之间的关系,能够从语义场景角度为篇章句子之间建立语义联系,通过这种语义联系,为篇章语义理解研究提供了一种框架语义信息,便于计算机理解篇章语义。框架关系可应用于机器阅读理解中的推理、问答等任务,通过两个框架之间的框架关系,得到这两个框架元素之间的映射关系,利用这种映射关系可以得到篇章中语义信息单元之间的联系,为推理、问答等任务提供语块级的相关信息,帮助解题。如图1所示[9],S1中的目标词“进行”激起框架“有意行为”,S0中的目标词“帮助”激起框架“协助”,这两个框架之间具有“使用”框架关系,具有“使用”关系的框架之间存在特定的框架元素映射,通过这种映射关系可以得到S0中的框架元素类型“dom(领域)”对应S1中的“dom”,即“在矿业、能源制造业、电信、农业等领域”为问题S0的答案映射。
CFN中的框架关系主要是从FN中翻译过来的,FN中的框架关系不可能达到完备,所以CFN中也会存在框架间关系缺失的问题。通过对篇章构建框架关系图(构建方法如第二部分所示)发现图中存在孤立框架,一篇文章表达的是一个语义整体,框架间关系缺失阻碍了篇章句子之间建立联系,所以做面向篇章的框架关系预测方法研究是至关重要的。
1 相关工作
作框架关系预测可以分解为两个子任务:框架表示和关系预测。
张力文等[11]将每个句子中的词向量求和再平均作为句子的向量表示,进而再将框架下所有例句的向量表示求和再平均,得到框架表示,进行汉语框架排歧。Hermann等在框架识别任务中使用WSABIE算法[12]将框架和词元及其上下文单词投影到相同的潜在空间中,利用WARP损耗和基于梯度的更新来学习两个投影矩阵(一个用于框架,另一个用于谓词),使得谓词的向量表示与正确框架的向量表示之间的距离最小化,使用该方法得到了框架表示,本文将把框架表示提取出来,并在框架关系预测方面进行研究。
Mikolov等[13]使用Word2vec算法的神经网络体系结构通过预测给定上下文单词的目标词(CBOW模型)或通过预测给定目标单词的上下文单词(skip-gram模型)来学习词向量。Botschen等[10]将例句库中所有句子作为Word2Vec训练语料,将每个句子的目标词替换为它所激起的框架,获得了框架表示。有不同的任务被专门设计来评估词向量,它们被表述为(a,b)=(c,?)形式的语义类比问题。Mikolov等[14]提出了一种基于余弦距离的向量偏移方法来解决这些类比任务。假设关系是用向量偏移表示的:给定两个词对(a,b)和(c,d),这两个词对的关系在多大程度上相似。将该方法应用于通过框架关系连接的框架对,研究框架表示是否包含框架关系。
关系预测任务源于知识图谱补全(KGC),并被称为“链路预测”[15-17],可以把这一任务转移到框架对的框架关系预测中。Bordes等[17]提出了TransE模型,该模型在知识表示学习中是最为经典的模型,将关系建模为对实体表示的翻译。在翻译模型中,将头实体、关系和尾实体(h,r,t)三元组中的所有实体和关系投影到一个潜在向量空间中,把关系看作从头实体到尾实体的翻译。形式化地讲,对于一个关系三元组tr=(h,r,t)来讲,该模型认为h+r=t,该方法弥补了传统方法训练复杂、不易拓展的缺点,对实体和关系的建模十分简单明了,可解释性也很强,本文借用该方法获得基于知识的框架表示和框架关系表示用于后续研究。
答案选择是问答(QA)中的一个重要任务,该任务是对给定问题的一组可能的候选答案通过计算向量表示之间的余弦相似性对候选答案进行排序并选择最佳答案。Feng等[18]和Tan等[19-20]提出的问答模型共同学习了问题和答案的向量表示,在同一空间中,计算相同维度的向量表示之间的余弦相似性。可以把该思想应用于框架关系预测,在框架关系预测中,一个框架对对应于一个问题,一种框架关系对应于一个候选答案,选择不同方法预先训练的框架表示作为框架关系预测的输入。
2 篇章框架关系图的构建
框架关系预测不是随机给定两个框架去预测它们之间的关系类型,本文通过标注篇章中多个句子框架(词元所属框架)之间的关系并对篇章构建框架关系图发现图中有孤立框架,存在框架间关系缺失的问题。一篇文章表达的是一个语义整体,框架间关系缺失阻碍了篇章句子之间建立联系,因此本文基于构建的篇章框架关系图,去预测图中孤立框架与其他框架之间的关系,使篇章框架关系图构成一个完整的连通图,从语义场景角度为篇章句子之间建立联系。
给定一个篇章,根据篇章语义识别句中的目标词并标注其所属框架,用n表示框架总数,d表示两个框架之间的最短路径,s表示最短路径d生成的矩阵,通过搜索CFN的框架关系知识库计算任意两个框架之间的最短路径,生成行(列)数为n的矩阵s,为了进行框架关系预测,根据矩阵s构建d=1、d=2的初始框架关系图,通过遍历篇章中的所有框架与初始框架关系图中的框架查看是否还有框架在图中没有出现,若有框架在图中没有出现就将该孤立框架添加到初始篇章框架关系图中,构成非连通图,需要预测孤立框架与图中其他框架的关系。图2为篇章框架关系图的构建流程。

图2 框架关系图的构建流程
由于CFN中的词元没有覆盖篇章中的所有词语,篇章中存在未登录词(暂未被收录到CFN框架的词),未登录词无法进行框架标注,因此本文只讨论已登录词(主要是动词)框架之间的关系。如图3所示,选择已标注框架的2008年北京高考语文I卷里的一篇文章为例,构建了篇章框架关系图,方框中为文章词元激起的框架,方框中的斜体加粗词为篇章框架关系图中的孤立框架,框架与框架之间的连线是将框架通过框架关系最短距离进行连接,连线上的数字是指框架之间通过几层关系连接起来。本文预测图中孤立框架与其他框架之间的关系。
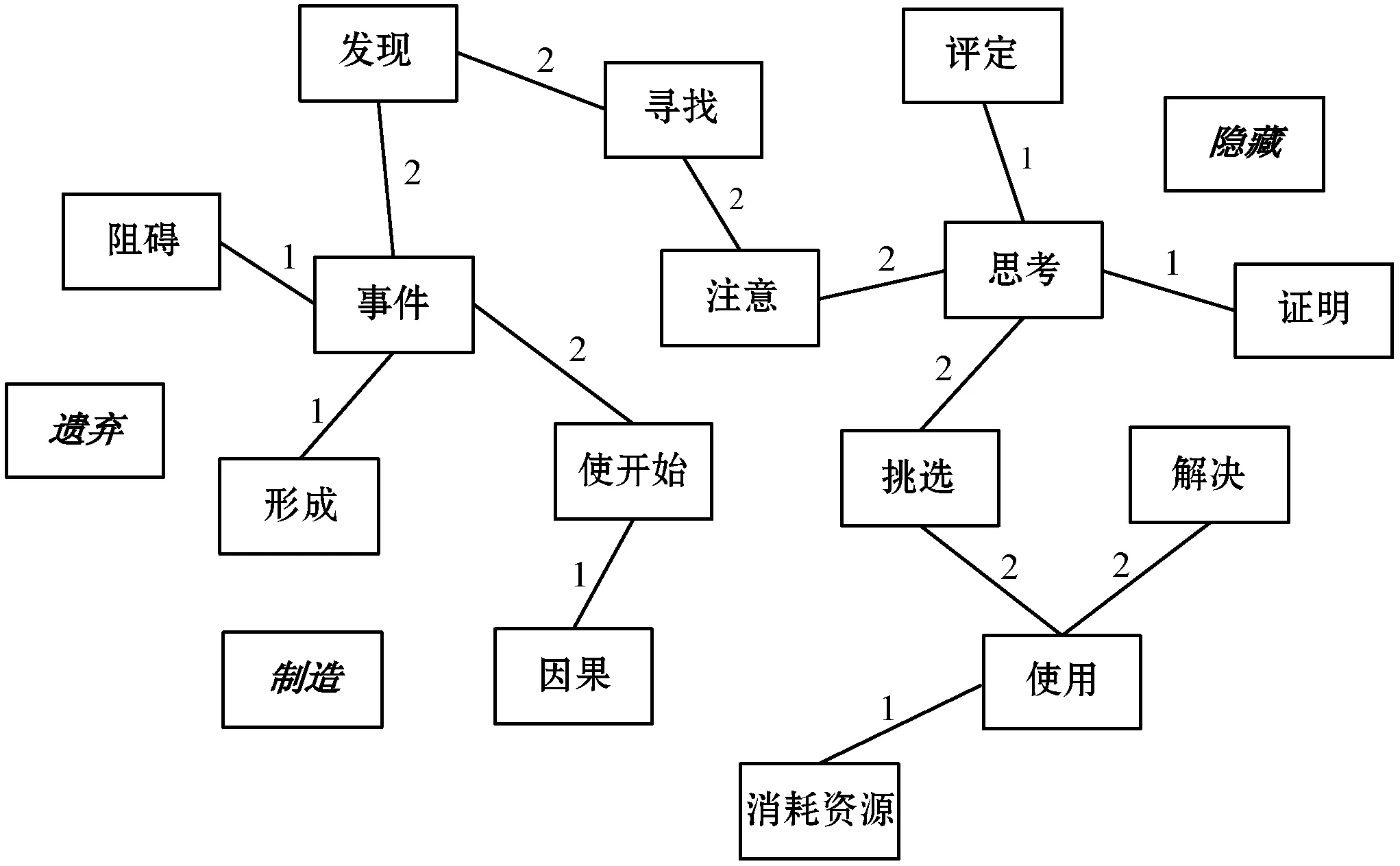
图3 篇章框架关系图
3 框架关系预测
3.1 基于文本的框架表示及框架关系表示
本文使用WSABIE和Word2vec两种基于文本的方法进行框架表示和框架关系表示的学习。
WSABIE方法是Weston等[12]提出的框架表示的矩阵分解方法,Hermann等[21]用该算法学习出一种框架表示,本文使用WSABIE算法将框架和谓词及其上下文词语投影到相同的潜在空间中,使谓词的向量表示与正确框架的向量表示之间的距离最小化,得到框架表示。该算法超参数选择:向量维数100,优化算法为随机梯度下降法,epoch为1 000,最大迭代次数2 000,学习率为0.001,负例样本个数为100。
使用Word2vec[22]经网络方法学习基于文本的框架表示,Botschen等[10]将例句库中所有句子作为Word2Vec训练语料,同时将每个句子的目标词替换为它所激起的框架,获得了框架表示。例如,“老师花费了一个星期准备考卷”,将句子中的核心动词“花费”用所属框架“耗时”替换。该算法超参数选择:训练算法为skip-gram模型,向量维数300,最小词频为5,初始学习率为0.025,窗口大小为5,迭代次数为100。
框架关系表示:本文把学习到的框架f的表示定义为E(f),使用向量偏移方法通过框架表示学习框架关系表示E(r),具体步骤如算法1所示。
算法1框架关系表示的学习算法
Input:同一种框架关系r的框架对的集合,Or={(f1,f2)1,(f1,f2)2,…,(f1,f2)n}以及框架表示
Output:E(r)
//E(r)为框架关系r的表示
1. 在训练好的框架表示中分别查询框架f1,f2对应的表示E(f1)∈Rd,E(f2)∈Rd;
2. 求每对框架对的向量偏移量:E(offset)=E(f2)-E(f1);
//所有框架对的向量偏移量
//求和再平均作为E(r);
4. Return E(r)
3.2 框架关系预测模型建立
知识图谱中链接预测是将知识图谱中的实体和关系映射到连续向量空间中,对知识图谱中的实体或关系进行预测,即(h,r,?)、(?,r,t)、(h,?,t)三种知识图谱的补全任务。本文的目标是通过给定两个框架,找到它们之间正确的框架关系。本文利用链接预测思想构建了框架关系三元组(f1,r,f2)数据,使用基于知识图谱的表示学习方法在三元组数据上训练得到框架表示及框架关系表示进而进行框架关系预测。
本文的框架关系预测模型将使用不同方法预先训练的框架表示作为输入进行实验,除了基于文本的框架表示之外,本文还使用Lin等[23]提供的TransE模型在框架关系三元组(f1,r,f2)中学习到框架和框架关系的低维向量表示,向量维数为100,框架关系三元组是从CFN的框架关系知识库中抽取出来构建成(f1,r,f2)的形式。
本文使用一个以Hing-loss函数为优化目标的神经网络模型去预测框架对(f1,f2)之间的框架关系r。给定一个训练实例(f1,r,f2),将每个元素使用不同方法训练的框架及框架关系表示输入到模型中,本文还使用Le等[24]出的Doc2vec方法把每个框架对应的定义训练为固定长度的向量表示记为E(df),将框架自身的属性框架定义融入到框架表示中,把两者拼接输入神经网络,如式(1)所示。
Fdf=[E(f);E(df)]
(1)
如图4所示,对于给定的一个框架关系三元组(f1,r,f2),首先把他们使用不同方法预先训练的向量表示作为输入,然后经过全连接层后进行相加进入f层,最后分别计算f层得到的向量表示与r(框架对(f1,f2)之间存在的正确框架关系)和r′(随机选取一个错误的框架关系r′,构造负例)的余弦相似度,并使用Hing-loss函数为优化目标式使其最小化,即最小化如式(2)的目标函数,该目标函数试图使框架对与正确关系的相似度最大,与错误关系的相似度最小,使神经网络能识别出框架对间最好的关系。
loss=max{0,m-cos(f,r)+cos(f,r′)}
(2)
式中:m是边距,本文为0.1,cos是余弦相似度函数,使用该损失函数使模型最大限度地提高框架对与正确关系之间的相似性,最小化框架对与错误关系之间的相似性。
4 实验与结果分析
4.1 实验数据
文本数据:为了使用WSABIE算法和Word2Vec方法学习基于文本的框架表示,使用CFN例句库中已标注699个框架并且已分好词的92 759条句子,用f表示框架,f∈Ft(Ft是所有框架的集合)。
三元组数据:为了学习基于知识的框架及框架关系表示,在CFN现有的3 190条框架关系三元组数据上进行学习,本文用G表示框架关系三元组(f1,r,f2)的集合(框架“f1与f2之间的关系是r),每种框架关系统计数据如表1所示。

表1 每种框架关系对计数

续表1
4.2 评价指标
本文采用链接预测评价指标,有三个重要指标如下所示,分别对测试框架对的每种框架关系进行打分排序(降序),若排名第一的框架关系与测试框架对的框架关系一致,表明预测正确。
Accuracy:在所有测试框架对中,框架关系预测正确的比例,计算公式如式(3)所示,N为测试框架对的总个数,C为框架关系预测正确的框架对的个数。
(3)
Mean rank:求每个测试框架对之间正确框架关系的排名,再对这些排名求平均,计算公式如式(4)所示,Ri为第i个测试框架对正确框架关系的排名,N为测试框架对的总个数(rm越低越好,最优为rm=1)。
(4)
Hits@5:在所有测试框架对中,正确框架关系排在前5的比例。
4.3 结果分析
将表1中的每种框架关系三元组个数按8∶2分割,分别用来训练和测试。为了探索框架关系是否能从基于文本学习的框架表示上预测出来,本文比较了基于文本学习的框架关系表示之间的余弦相似度和框架对向量偏移量与对应关系之间的余弦相似度,结果如表2所示。

表2 框架关系表示间的余弦相似度
结果表明,不同框架关系之间(相互关系)的余弦相似度大于框架对的向量偏移量与其对应关系之间(内部相关)的相似度,即属于同一框架关系的两个框架对之间的差异比它们与另一种关系的框架对之间的差异还大。因此,这些基于文本学习的框架表示不能被用来可靠地推断框架对之间的正确关系。
除了基于文本的框架表示之外,本文还使用最经典的知识图谱补全方法TransE模型学习了基于知识的框架表示和框架关系表示,把不同方法训练的框架及框架关系表示作为输入,使用余弦相似度方法和以Hing-loss函数为优化目标的神经网络进行实验,并在神经网络模型中融入框架自身属性——框架定义。实验结果如表3所示。

表3 框架关系预测的结果
Simi计算框架对之间的向量偏移量,测量其与框架关系表示的余弦相似度,并根据相似度对框架关系进行排序,输出最接近的关系。
H-nn以Hing-loss函数为优化目标的神经网络,如图4所示,输入预先训练好的框架和框架关系表示(WSABIE、Word2vec和TransE)。
H-nn-Fdf在输入模型的框架表示中融入了框架自身特有的属性——框架定义(如式(1)所示)。
Simi方法中,把基于文本的框架表示(WSABIE和Word2Vec)与框架关系表示的相似性作为基线,由表3可以看出,使用TransE训练的向量表示得到的结果明显优于基于文本的向量表示,显示了基于知识的表示学习方法的优越性。
H-nn方法中,可以看到使用基于文本的向量表示的准确率与Simi方法相比没有显著提升,但是另两个指标却有明显提高,基于知识的TransE训练的向量表示作为输入在所有性能度量中取得了最佳效果。
H-nn-Fdf方法中,在输入模型的框架表示中融入了框架定义,与H-nn方法结果相比可以看出对于基于文本的表示没有起到作用,分析原因是从文本中训练的框架表示已经包含了语义信息,且框架定义与句子的语义信息不完全贴合,但是在基于知识的表示中融入框架定义信息,实验结果有所提升,其原因是外部知识与基于知识的表示学习方法的融合,结合了框架本身的属性信息。
4.4 预测描述
由图3可以看到,[隐藏][遗弃][制造]这三个框架是孤立的,所以需要去预测这三个孤立框架与其他框架之间的关系。由于一个篇章中的框架是很多的,孤立框架也没有都与其他剩余框架间有很强的联系,因此计算了孤立框架与其他剩余框架语义联系Top2的框架,如表4所示。

表4 篇章中与孤立框架语义联系Top2的框架
分别预测孤立框架与其语义联系Top2框架之间的框架关系,表5展示了框架关系预测排在前三的结果,预期的框架关系(加粗)确实是性能最好预测模型的前三个预测之一。该模型可用于对框架对的关系提出合理的建议,并由经验丰富的专家做出最终的决策。
5 结 语
本文面向篇章进行框架关系预测,把不同方法训练的框架表示作为输入,使用余弦相似度方法和以hing-loss函数为优化目标的神经网络预测篇章中缺失框架间的关系,并在神经网络模型中融入了框架自身的框架定义信息,实验结果验证了基于知识图谱的表示学习方法的优越性以及框架定义信息的有效性,提升了框架关系预测的性能。通过预测篇章中缺失框架间的关系,从语义场景角度为篇章句子之间建立了关联,有助于篇章语义理解及语义推理。
框架表示是框架关系预测的基础,有效提升框架表示是该任务的关键。下一步将结合框架其他属性,融合更多信息进行框架表示,从而进一步提升预测的性能。
猜你喜欢
小资CHIC!ELEGANCE(2022年1期)2022-01-11
山西大学学报(自然科学版)(2021年1期)2021-04-21
数学物理学报(2020年3期)2020-07-27
开放教育研究(2020年2期)2020-03-31
五邑大学学报(自然科学版)(2019年3期)2019-09-06
法大研究生(2017年1期)2017-04-10
现代语文(2016年21期)2016-05-25
计算机工程与设计(2015年1期)2015-12-20
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
大连民族大学学报(2015年2期)2015-02-27
