
基于时空注意力特征的异常流量检测方法
2023-05-08 03:01孟献轲
计算机应用与软件 2023年4期
孟献轲 张 硕 熊 诗 王 波
1(中国电子科技集团公司第二十八研究所 江苏 南京 210000) 2(解放军信息工程大学信息系统工程学院 河南 郑州 450002)
0 引 言
近年来,世界见证了互联技术在不同领域的重大发展,例如:物联网、智能电网、车辆互联网、移动互联网。据思科发布的《视觉网络指数》(VNI)报告预测,2022年的全球网络流量将超过之前的所有年份,IP连接设备的数量将是全球人口的三倍,每年将产生4.8 ZB IP流量。如此规模的流量信息通过各种设备和通信协议在互联网上交换,会引起严重的安全问题。网络入侵检测系统(Intrusion Detection System,IDS)是网络的一线安全系统,用于监视网络流量中的恶意活动,及时产生预警,从而采取相应安全措施。
按照检测方法,IDS可以分为基于签名的IDS(Signature-based IDS,SIDS)和基于异常的IDS(Anomaly-based IDS,AIDS)[1]。SIDS通过将被监控的行为与预先定义的入侵规则库快速匹配来实现检测,但在面对陌生攻击时,检测性能通常很差;AIDS为“正常”网络流量建立模型,检测到偏差时发出异常报警,性能取决于对网络流量正常行为建模的程度,该方法在检测未知异常攻击中具有巨大应用潜力。在众多AIDS的研究中,基于机器学习(例如人工神经网络[2]、朴素贝叶斯[3-4]、k近邻[5]和支持向量机[6-9])的AIDS研究最为广泛。例如Aburomman[7]和Natesan[10]通过构造多分类器对DoS、Probe、U2R和R2L等流量进行检测。Rastegari等[11]使用遗传算法(GA)改进了基于时间间隔的简单规则,进而提高异常流量检测性能。Kuang等[9]将基于内核主成分分析和遗传算法的支持向量机来检测网络入侵。然而,基于机器学习的AIDS方法严重依赖于人工设计的流量特征,限制了这种方法的通用性和准确性。
近年来,深度学习在图像识别、语音识别和自然语言处理等各大领域迅猛发展,不断刷新各领域的最优纪录。深度学习技术可以通过训练数据自动提取和选择特征,避免人工选择特征的繁琐工作,此特性使基于深度学习的方法成为流量建模领域的理想方法,引来了学术界的广泛关注。
由于基于深度学习的异常流量检测方法尚处于起步阶段,研究主要集中于基于卷积神经网络(Convolutional Neural Networks,CNN)[12-14]、循环神经网络(Recurrent Neural Network,RNN)[15-17]、自动编码器(Auto Encoder,AE)[18-20]、多种神经网络模型混合[21-22]的检测方法。基于CNN的AIDS方法通常将流量数据转换为灰度图,在灰度图上采用卷积、池化等操作提取流量空间特征进行异常检测。基于RNN的AIDS检测方法将流量序列依次输入长短期记忆网络(Long-Short Term Memory,LSTM)、门控循环单元(Gated Recurrent Unit,GRU)等,通过计算各流量元素之间的时序特征识别异常。基于AE的AIDS方法利用将流量数据压缩再恢复的训练过程,提取流量最显著的特征进行异常检测。以上三种方法单纯基于一种神经网络模型对流量特征的维度提取不足,因此Wang等[21]和Kim等[22]均将CNN和LSTM进行组合,同时提取空间和时序特征,虽然二者属于同一类模型框架,但Kim等[22]以单个数据包为处理单位,Wang等[21]则以网络流为处理单位,使得CNN和LSTM的层次模型真正合理地利用了流量结构信息。
然而,LSTM在当前状态的计算时需要依赖上一个状态的输出,不具备高效的并行计算能力;另一方面,整个LSTM模型(包括其他的RNN模型,如GRU)总体上类似于一个马尔可夫决策过程,难以提取全局信息,并且RNN模型以最后一个时刻的隐状态或者各时刻隐状态的拼接作为提取的时序特征,无法着重突出流量中某些数据包之间的关联关系。
Transformer[23]是机器翻译领域的前沿模型,包括编码器和解码器两大部分。Transformer编码器无循环结构,广泛应用了自注意力机制,可以并行处理序列中的所有元素,将序列某一位置的元素与全局元素结合起来,用于挖掘与当前预测元素关系紧密的全局上下文元素,Transformer编码器具有更强的特征提取能力。
考虑到Transformer以上优点,本文提出一种基于时空注意力特征的异常流量检测框架,该框架由卷积网络层、位置编码层、时序注意力编码层、全连接层和Softmax层串联而成。首先将网络流的数据包均转换为数据包灰度图,利用卷积网络层提取数据包灰度图的空间特征;然后,利用Transformer编码器对数据包空间特征的整体时序进行建模,通过多头自注意力机制计算各数据包的长距离依赖关系,挖掘网络流中的数据包之间显著的关联特征表示。最后,将该特征表示输入到全连接神经网络层和Softmax层,输出识别概率。
1 相关背景
注意力机制的本质是将一个查询向量和一组键值向量对映射到输出,查询向量与键向量用于计算每个值向量对应的权重,值向量的加权和为注意力输出。点积注意力[24]利用矩阵乘法运算,既高效又节省空间,计算流程如图1所示。

图1 放缩点积注意力计算流程

(1)
2 基于时空注意力特征的异常流量检测
本文根据网络流的结构特点,构建了基于时空注意力特征的异常流量检测框架,其结构如图2所示。该框架主要由卷积网络层、位置编码层、时序注意力编码层、全连接层和Softmax层串联而成,[CLS]是网络流的标签符,表示网络流中是否有异常流量攻击。
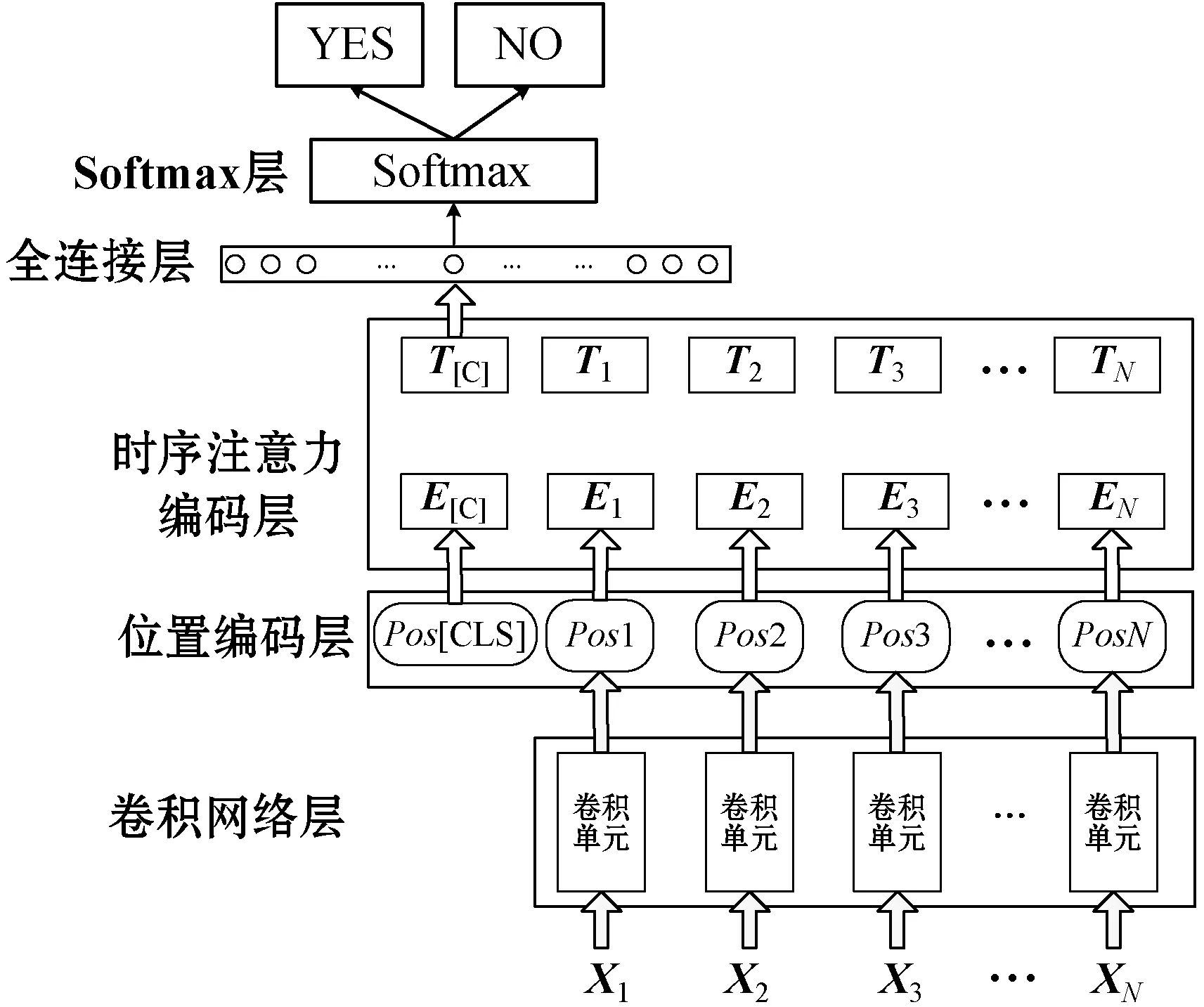
图2 基于时空注意力特征的异常流量检测框架
2.1 卷积网络层
卷积网络层由相同结构的卷积单元组成,训练参数共享。卷积单元的具体结构如图3所示。

图3 卷积单元结构

(2)

(3)
式中:hl-1为第l-1层数据包特征图的大小;zl表示第l层卷积核的大小;λl是卷积核移动步长;ρl表示前一层特征图边缘补零的列数。在子采样层,采用重叠采样方法对特征图进行最大值采样,既提高特征的准确性,又防止训练过拟合。
2.2 位置编码层
Transformer编码器没有循环或者卷积结构,无法使用网络流中数据包的位置信息,因此需要位置编码层添加位置信息,即图2中的Pos操作,其过程如图4所示。

图4 位置编码层添加位置信息的过程
图4中,Epkt表示卷积网络层提取的数据包空间特征向量,Epos表示数据包相对位置向量。位置编码层的Pos操作将二者求和,相对位置向量的计算如式(4)、式(5)所示。
E(p,2i)=sin(p/10 0002i/dmodel)
(4)
E(p,2i+1)=cos(p/10 0002i/dmodel)
(5)
式中:p代表位置;dmodel表示特征向量的维度;i代表dmodel中的某一维度。
2.3 时序注意力编码层
时序注意力编码层由三层的双向Transformer编码器构成,具体结构如图5所示。
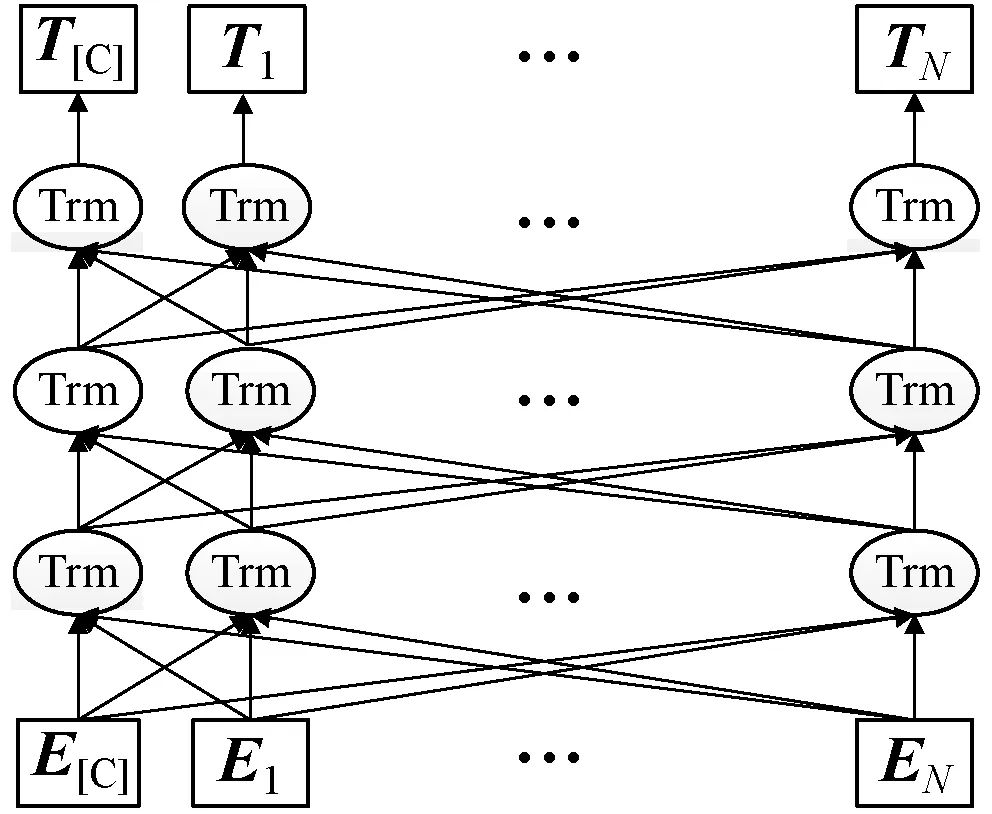
图5 时序注意力编码层
图5中,每个Trm均代表一个Transformer编码器;Ti表示Ei在经过时序注意力编码层处理之后得到的特征向量。Transformer编码器结构如图6所示。
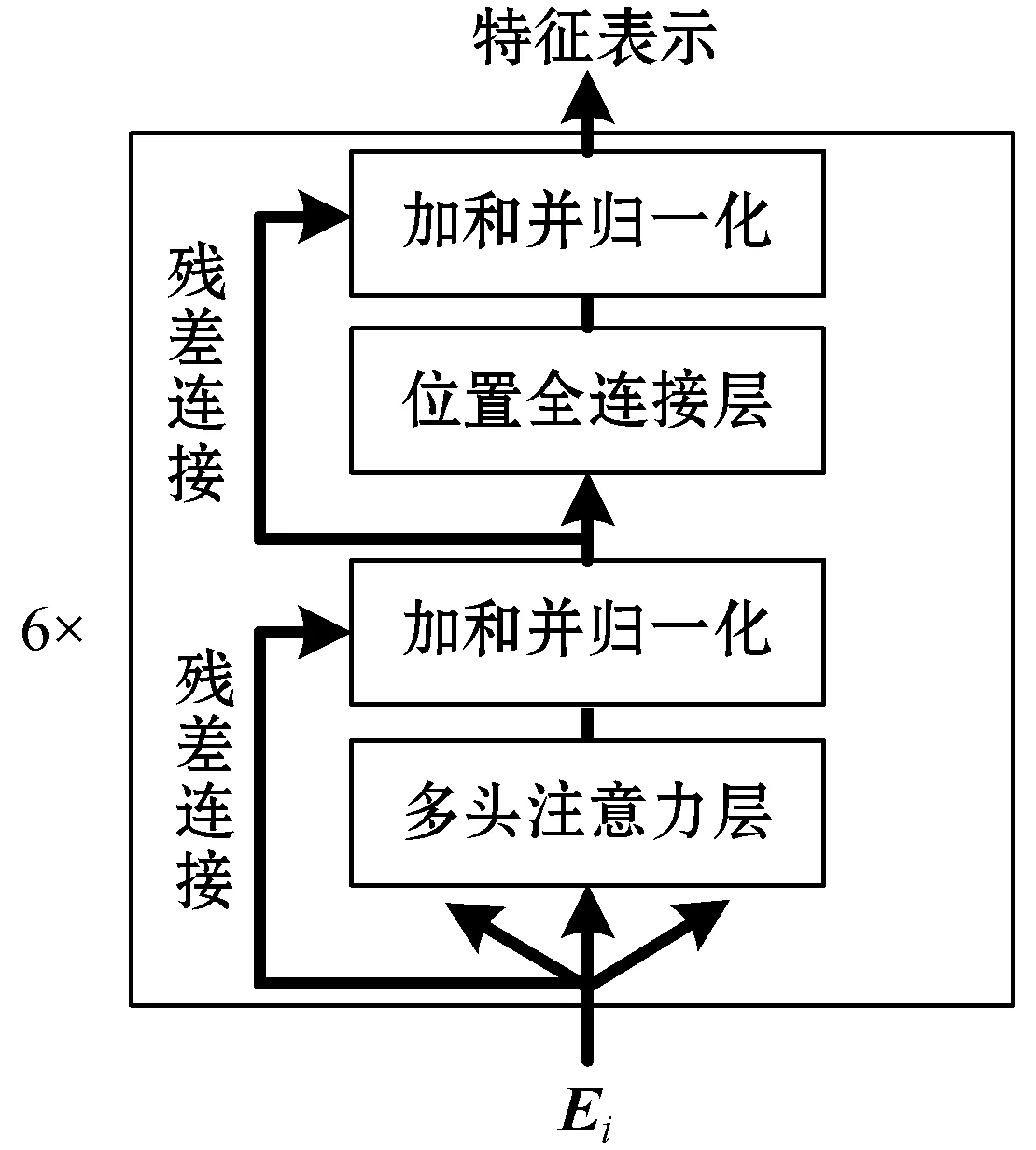
图6 Transformer编码器
Transformer编码器由6个相同的编码层堆叠而成,每个编码层又包括多头自注意力层和位置全连接层两个子层,残差连接和层归一化用于优化网络训练深度。每个编码层和所有子层的输出维度均相同,记为dmodel。
(1) 多头注意力机制。网络流中数据包之间的时序特征关系多样,因此需要多头注意力使编码器同时关注来自不同数据包的不同表示子空间的信息,其具体计算流程如图7所示。

图7 多头注意力机制计算流程
首先将Q、K和V线性变换后进行h次放缩点积注意力计算,h为多头注意力的头数。然后将h次的注意力计算结果通过拼接和线性变换得到多头注意力的结果,如式(6)和式(7)所示。
Multihead(Q,K,V)=Concat(head1,head2,…,
headh)WO
(6)
(7)
(2) 位置全连接前馈网络。位置全连接前馈网络(FFN)分两层,用于处理每个位置的多头注意力计算结果,其输入和输出的维度相同。第一层的激活函数是ReLU,第二层是线性激活函数,如果多头注意力层输出表示为M,则FFN可表示为式(8)。
FFN(x)=max(0,MW1+b1)W2+b2
(8)
式中:W1、b1和W2、b2分别是两个激活函数的参数。Transformer编码器利用多头注意力层和位置全连接层不断交叠得到最终的输入序列表示。
2.4 全连接层和Softmax层
对于训练集C,给定一个输入网络流x1,x2,…,xN和对应标签y,[CLS]在最后一个Transformer编码器的隐藏层输出记为T[C]∈Rdmodel,经过全连接层和Softmax层后对y进行预测,如式(9)所示。
P(y|x1,x2,…,xN)=softmax(CWf+b)
(9)
式中:Wf是全连接层的权重矩阵;b为偏置;P(y|x1,x2,…,xN)是Softmax层计算的概率结果,记为y′。则模型训练的目标为最小化交叉熵损耗函数L(C),如式(10)所示。
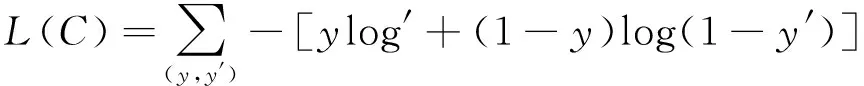
(10)
3 实 验
3.1 实验数据
UNSW-NB15数据集由澳大利亚网络安全中心(ACCS)2015年利用IXIA PerfectStorm工具创建,包含真实正常活动和合成的当代攻击行为,原始流量数据为约100 GB的.pcap格式文件,共有记录2 540 044条,包含九种类型的攻击,即Fuzzers、Worms、Backdoors、Analysis、DoS、Generic、Exploits、Reconnaissance和Shellcode。由于网络攻击更新变化较快,该数据集较DARPA、KDDCUP 1999和NSL-KDD等传统数据集更具研究价值,数据集的具体分布如表1所示。

表1 UNSW-NB15数据集类别分布
利用以上数据设置两类实验,(1) 将所有异常流量看作一类,对正常和异常流量进行二分类,记为A实验;(2) 将所有异常流量分为九类,对正常异常流量进行十分类,记为B实验。
3.2 数据预处理
首先进行数据切分,使用pkt2flow和Wireshark工具将原始pcap流量数据集以会话为单位切分为多个流,以下统称为网络流。每个网络流中的数据包按照通信时间的先后排序,其组成结构如图8所示。
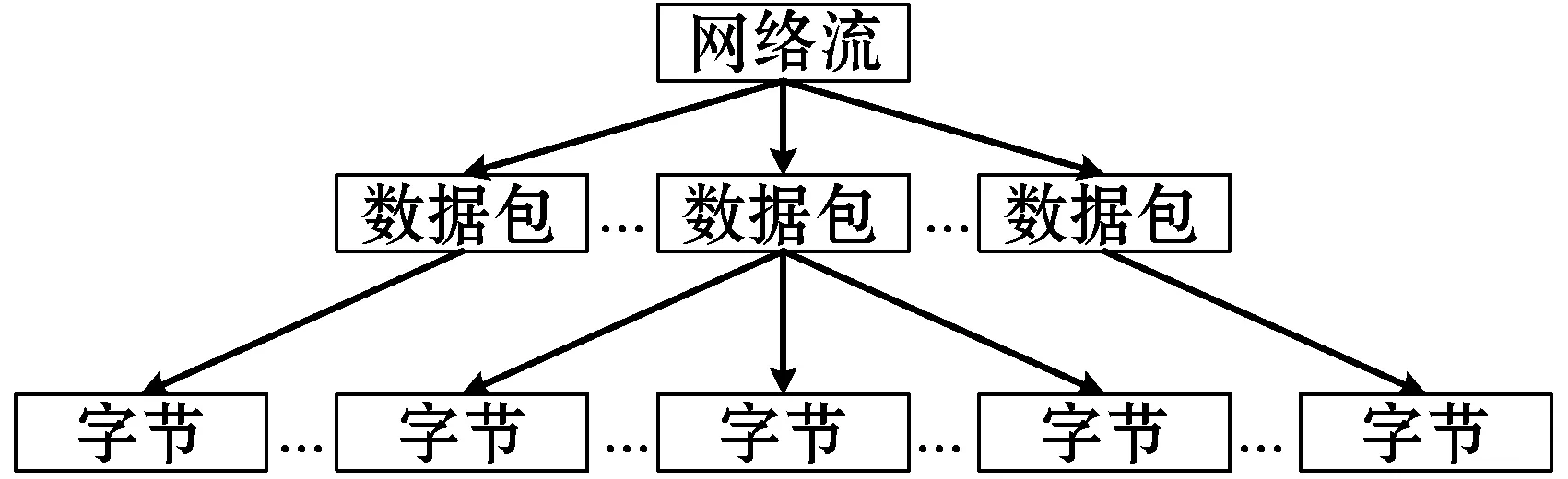
图8 网络流组成结构
假设一个网络流中有r个数据包,每个数据包取前p字节,独热编码为q维,则该网络流向量化为r个p×q的二维图像。
然后进行流量清理,舍弃网络流中只有头信息而无载荷的数据包,将每个数据包的IP地址以及MAC地址进行匿名化处理,消除无用信息对特征学习的干扰。
最后进行归一化处理,每个字节都由8 bit组成,转化为十进制数的取值范围为[0,255],除以255将每个十进制数归一化到[0,1]的范围内,从而提高模型收敛速度。
3.3 评测标准
本文采用准确率(Accuracy,Acc)、精度(Precision,P)和误报率(False Alarm Rate,FAR)三个常用评测指标验证本文方法的可行性和有效性,准确率用于评价整体性能,精度用于评价对异常行为检测性能,误报率用于评价对正常行为的误判情况。首先定义以下变量:
真负类(Ture Negative)表示将正常网络流正确地识别成正常网络流的数量,记为Tn。假负类(False Negative)表示将异常网络流误识别成正常网络流的数量,记为Fn。真正类(Ture Positive)表示将异常网络流正确地识别成异常网络流的数量,记为Tp。假正类(False Positive)表示将正常网络流误识别成异常网络流的数量,记为Fp。
(1) 准确率(Acc)计算表达式为:
(11)
(2) 精度(P)计算表达式为:
(12)
(3) 误报率(FAR)计算表达式为:
(13)
3.4 实验设置与结果分析
本文选取文献[12]和文献[21]的方法作为对比方法,文献[12]仅采用卷积神经网络以数据包为单位提取空间特征进行检测,测试结果记为CNN。文献[21]采用CNN提取每个数据包的空间特征,LSTM模型提取数据包之间的时序特征进行检测,测试结果记为CNN-LSTM。本文的卷积网络层使用四个卷积层、四个池化层和一个全连接层,训练参数参考文献[21]的最优值,具体如表2所示。

表2 卷积网络层各层训练参数列表
时序注意力编码层由三层的双向Transformer编码器构成,按照文献[23]中的训练经验选择超参数,多头注意力的头数为8,dmodel=512,dk=dv=dmodel/h=64,全连接层的隐藏节点数量为768。优化算法选取Adam[25],令β1=0.9,β2=0.98,ε=10-9,epochs设置为200,每批数据batch_size大小为128,学习速率为1E-3。本文方法检测结果记为CNN-TRAN。
实验软硬件配置如下:软件框架为Keras和TensorFlow,操作系统Centos7.5 64位操作系统。硬件方面,CPU为16核Intel Xeon E5-2680 2.7 GHz,内存为128 GB,显卡为32 GB显存的Nvidia Tesla V100。
3.4.1 网络流数据包长度的影响分析
网络流中数据包的大小各不相同,卷积网络层以数据包为单位提取空间特征,需要将每个数据包截至固定长度,因此需要研究数据包长度对模型性能的影响,通过实验确定合适的数据包长度值。经统计,预处理后的网络流中,数据包的平均长度为698字节,网络流中所有数据包的中位数为22,令数据包长度在[100,1 200]内取值,数据包数量为22,以100为步长训练模型进行实验B,十类流量的综合Acc、P和FAR结果如图9所示。
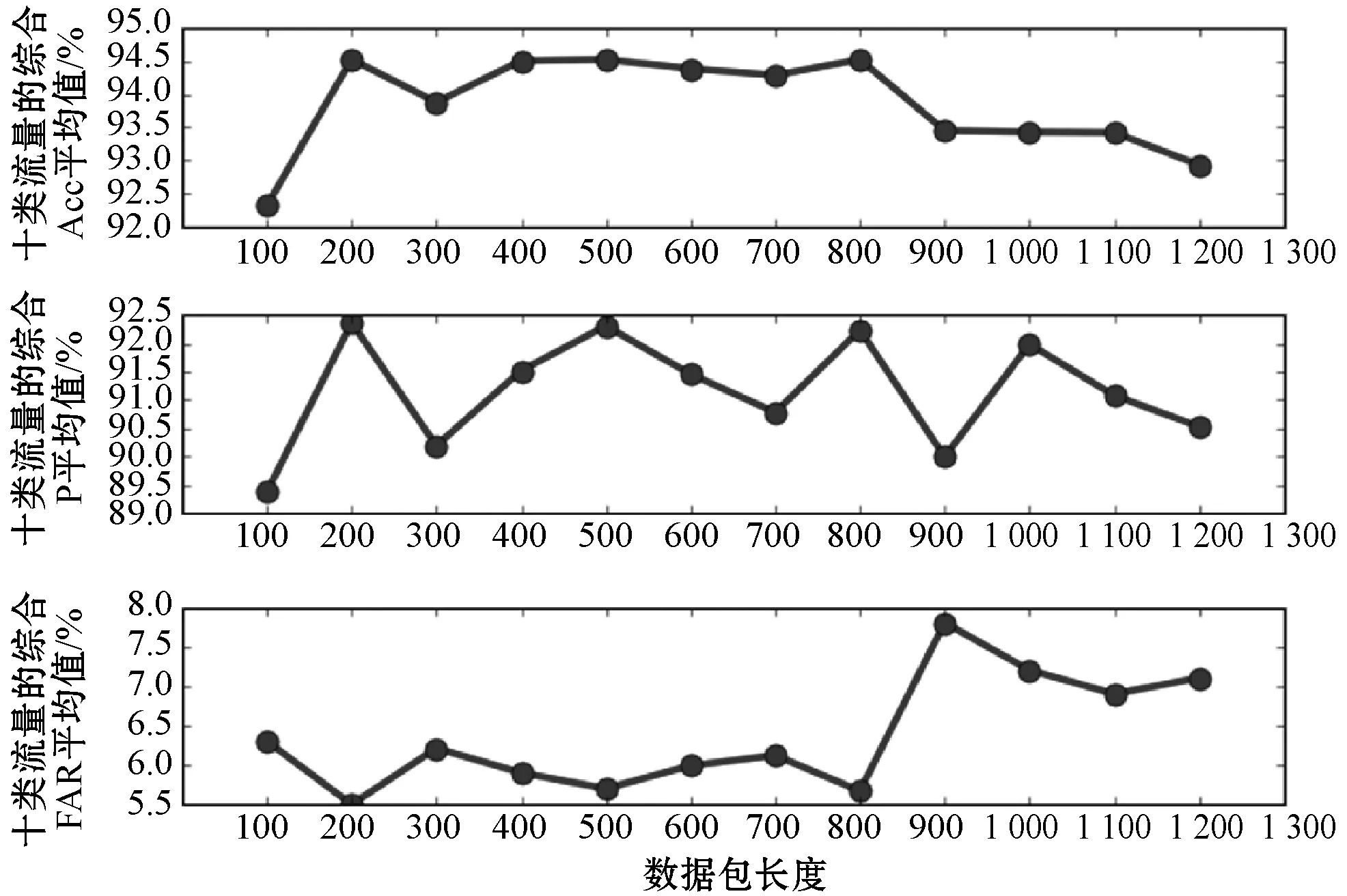
图9 数据包长度对检测性能的影响评测
可以看出,三个指标在数据包长度为200、500和800时取得了相近的较好结果,数据包长度的增加不会明显提高检测结果,800字节后甚至出现检测性能明显降低的现象。由此可以推断流量重要的异常特征信息包含于数据包前200字节的头信息和少量数据中,通过查看数据集开源的特征类型分布可知,流量的内容特征(swin、dwin、stcpb、dtcpb等)、基本特征(state、dur、sbytes、dbytes等)和时间特征(sjit、djit、sintpkg、dintpkt等)基本都包含于前200字节中。800字节后的数据内容会引入噪声数据,降低检测效果。综合考虑训练效率和效果,统一将网络流中的数据包截至200字节。
3.4.2 网络流数据包个数的影响分析
每个网络流中数据包数量不相同,而时序注意力编码层对网络流的时序特征学习时,要求输入的网络流数据包个数必须是固定的。经统计,单个网络流中的数据包个数最多为183 259,平均值为95,最少为1,中位数为22。令数据包个数在[3,30]内取值,以3为步长训练模型进行实验B,数据包长度取200,十类流量的综合Acc、P和FAR结果如图10所示。
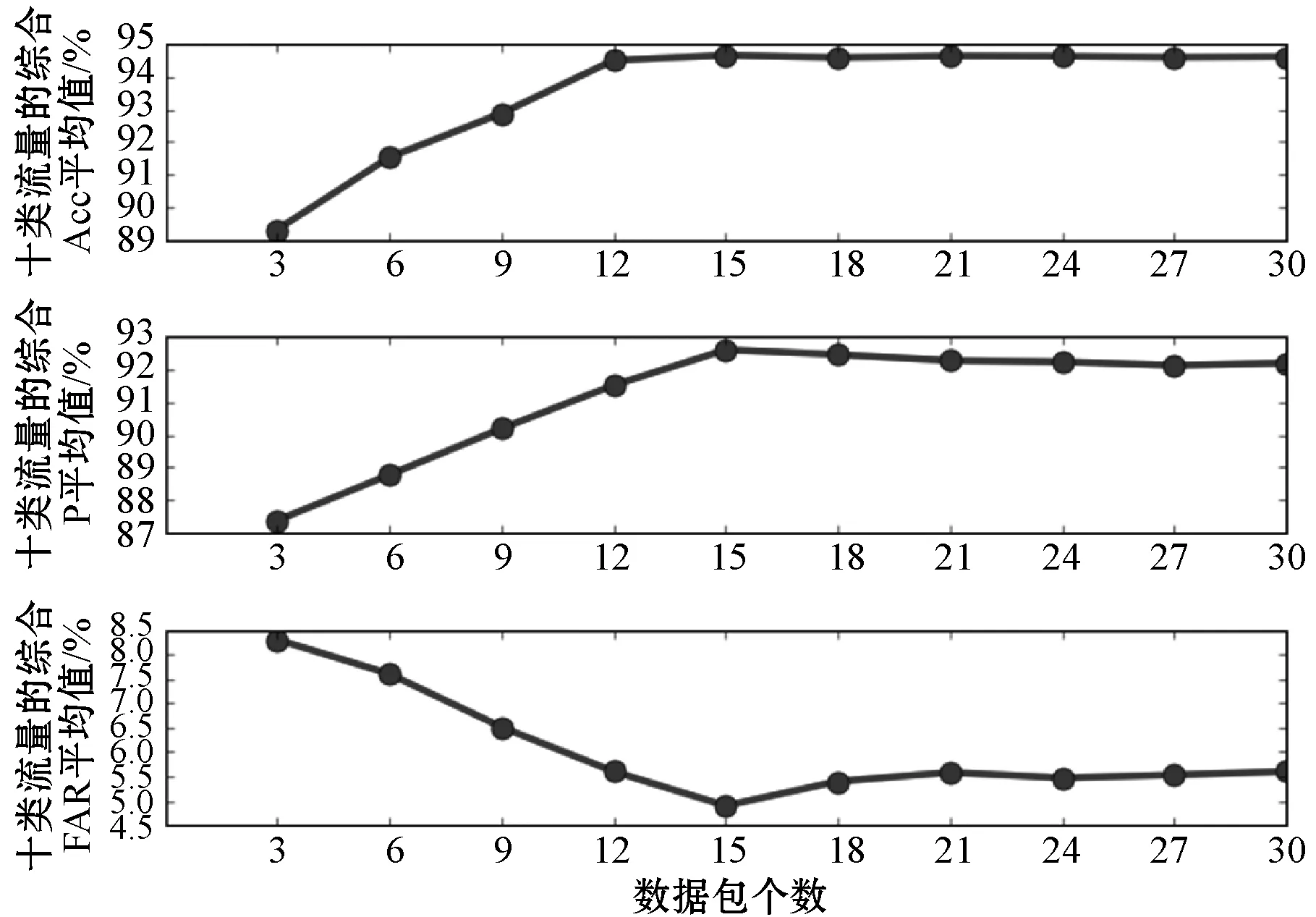
图10 数据包个数对检测性能的影响评测
可以看出,在[3,15]内,各项指标随着数据包数量增多而变优,当数量取15时各项指标最优。数据包继续增加时,各指标小幅震荡。由此可以推断,网络流前15个连续的数据包足以体现时间特征和连接特征。
3.4.3 综合实验分析
令网络流中数据包长度截至200字节,数据包选取15个,本文和两种对比方法进行A实验和B实验,测试结果如表3和表4所示。
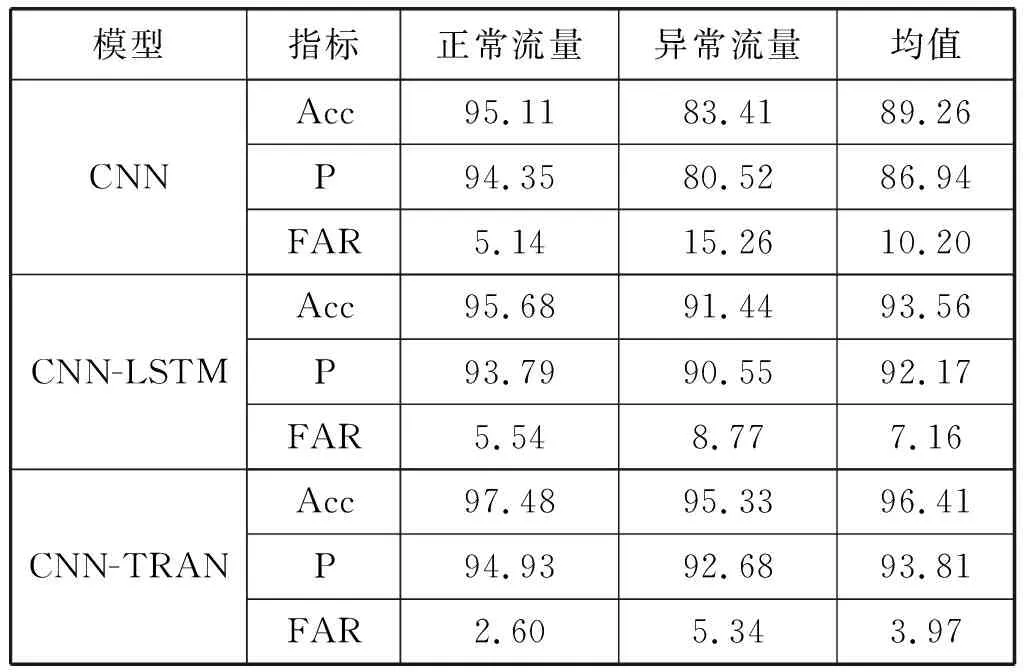
表3 三种方法实验A的评测结果(%)

表4 三种方法实验B的评测结果(%)
在表3和表4评测结果中本文方法均取得了最优结果,说明了本文方法的合理性和有效性。CNN-TRAN和CNN-LSTM较CNN的三项指标均有很大程度的提升,表明时序特征对流量的特征提取至关重要,结构化抽取网络流的空间和时序的综合特征更能代表网络流量特征。实验A中,CNN-TRAN较CNN-LSTM的Acc提高3.05%,P提高1.78%,FAR降低44.55%。实验B中,CNN-TRAN较CNN-LSTM的Acc提高7.64%,P提高9.64%,FAR降低55.04%。这是由于在时序注意力编码层中,注意力机制可以对输入的网络流中所有的数据包在不考虑距离的前提下进行全局建模,比LSTM的顺序建模更加有效,可以有效地挖掘网络流数据包之间显著的时序特征。尤其在实验B中检测Analysis、Backdoors、DoS和Worms这四类数量相对稀少的异常流量时性能提升比较明显。另外,实验A中CNN-LSTM较实验B中CNN-LSTM的三项指标变化率大于实验A中CNN-TRAN较实验B中CNN-TRAN的三项指标变化率,说明本文方法的鲁棒性较强。
为了进一步直观地对比三种方法,以实验B中对Fuzzers检测为例,对照各方法的检测结果,找到了两个Fuzzers的会话流样本,如图11和图12所示。

图11 被三种方法正确检测的会话流样本

图12 仅被CNN-TRAN正确检测的会话流样本
每个会话流包括15个Fuzzers数据包图片,IP地址为184.82.139.38和192.168.0.251。第二个会话流的每个数据包图最后黑色图像是填充的0,比第一个会话流的有效数据少,第一个会话流被三种方法正确检测,第二个会话流仅被CNN-TRAN正确检测。CNN-TRAN在空间特征较少的情况下,利用多头注意力机制着重挖掘了数据包之间的时序特征,在一定程度上说明了多头注意力机制的全局建模能力优于LSTM。
4 结 语
本文提出一种基于时空自注意力特征的异常流量检测方法,通过引入Transformer编码器,解决了当前包含RNN结构的异常流量检测框架无法并行利用全局流量数据包挖掘时序特征的问题。该框架利用卷积网络层提取网络流中单个数据包的空间特征,时序注意力编码层利用自注意力机制提取数据包之间的显著时序关联特征,有效地提高了异常流量检测性能。虽然本文方法较对比方法有提升,但是个别异常流量类别的检测性能依然受到样本数量少的影响,下一步准备在该检测框架中引入条件生成对抗网络,生成小类别异常流量的对抗样本,丰富训练样本,进一步提高检测性能。
猜你喜欢
中国农业信息(2021年3期)2021-11-22
网络安全和信息化(2018年4期)2018-11-09
成都信息工程大学学报(2018年3期)2018-08-29
电子制作(2017年13期)2017-12-15
电子设计工程(2017年20期)2017-02-10
电子制作(2016年15期)2017-01-15
电子器件(2015年5期)2015-12-29
电测与仪表(2014年13期)2014-04-04
河南科技(2014年15期)2014-02-27
深圳信息职业技术学院学报(2013年3期)2013-08-22
