
基于YOLOv4的轻量化口罩佩戴检测模型设计
2023-05-08 04:44王艺霏贺利乐
西北大学学报(自然科学版) 2023年2期
王艺霏,贺利乐,何 林
(西安建筑科技大学 机电工程学院,陕西 西安 710055)
呼吸道传染病是指病原体从人体的鼻腔、咽喉、气管和支气管等呼吸道感染侵入而引起的具有传染性的疾病,其主要通过空气飞沫传播,也可通过直接密切接触或间接接触传播,人群对多数呼吸道传染病普遍易感,特别是儿童和体弱多病者。在公众场合是否佩戴口罩是预防呼吸道传染病毒传播的重要因素。因此,疾控管理部门需要实时监控民众的口罩佩戴情况并进行有效的防控措施,但在人员密集的公共场所,人员众多、活动范围广,仅靠人为监控口罩的佩戴情况费时费力。因此,应用机器视觉技术设计人脸口罩佩戴检测系统,对于无接触检测呼吸道传染病的预防具有重要意义[1-2]。
卷积神经网络(convolutional neural networks,CNN)在提取图像特征以及实现目标检测方向是机器视觉领域的热点之一[3-4]。根据现有研究,目标检测分为两阶段(two-stage)和一阶段(one-stage)检测,前者检测过程由粗糙到精细,其发展成果有R-CNN[5]、Fast R-CNN[6]、Faster R-CNN[7]等。后者通过检测可直接得到结果,其代表有SSD[8]、YOLO系列[9-13]等。大多数常见的目标检测算法都适用于口罩检测任务,但基于深度神经网络的通用目标检测模型由于要适应较多的检测类别,模型参数量和计算量较大,对处理器硬件有较高的要求[14],不利于成本控制和部署。针对人脸口罩佩戴检测问题,学者们做了大量研究,并取得了一定的成果。邓黄潇结合迁移学习和RetinaNet网络,使得训练后模型在验证集下的AP值为86.45%[15];肖俊杰采用YOLOv3和YCrCb的方法,使得人脸口罩检测的mAP达到89.04%[16]。王兵等提出了一种改进的YOLOv4-tiny轻量化网络,使得mAP分别提升4.9个百分点和3.3个百分点[17];余阿祥等引入EfficientDet网络,使得平均精度达到93.81%[18]。这些方法使口罩检测精度有了一定的提升,但是没有考虑到嵌入式开发的应用需求,如模型参数量和计算量较大的问题。综上所述,现有的基于深度学习的口罩检测方法在模型参数和计算量上的控制还有待提高。
本文提出轻量化口罩检测模型G-YOLOv4,检测人脸是否佩戴口罩,显著减少模型参数量的同时,还提高了模型的识别准确率,可以广泛应用于各大公共场合。
1 YOLOv4目标检测算法
YOLO系列算法因其具有较快的推理速度,能够更好地满足现实场景的需求,在学术界与工业界引起关注。YOLOv4算法通过对YOLOv1算法一系列的改进与优化,在检测速度、检测精度和综合性性能方面展现了突出优势,在目标检测领域相较于其他主流算法有着广泛的应用[19]。
YOLOv4采用深层结构CSPDarknet53网络进行图像特征提取,获得3个初步的有效特征层。采用SPP网络、PANet网络增加感受野并进行加强特征提取,达到有效提升预测效果的目的。应用YOLOv3 Head作为检测模块,在进行最终预测的同时,生成识别边框并标注识别类别。
与其他目标检测算法相比,YOLOv4的多尺度预测算法在检测目标时更高效,在实时性方面的也有着突出表现,可满足人员密集场所的口罩佩戴检测需求[20]。但在口罩佩戴检测任务中,直接应用YOLOv4算法将面对如下问题:一是YOLOv4主干特征提取网络参数量大和特征提取不充分;二是在YOLOv4加强特征提取网络中,卷积块在上采样与下采样运算中计算量大。为减少上述问题对检测过程与结果的影响,本文通过实验研究与验证对YOLOv4算法进行改进与优化。
2 G-YOLOv4口罩检测算法
2.1 G-YOLOv4口罩检测算法原理
本文引入GhostNet卷积特征对YOLOv4目标检测算法进行改进, 包含3个部分: 主干特征提取网络、 特征融合网络、 图像特征预测网络。G-YOLOv4口罩检测算法框架图如图1所示。在口罩检测过程中,采用轻量化GhostNet[21]卷积神经网络实现特征提取,获取3个有效特征层。特征融合模块主要参考YOLOv4中的SPP和PANet作为Neck进行口罩检测的加强特征提取,并通过改进的GhostNet主干特征提取网络对特征进行深层次提取,得到3个有效特征层。图像特征预测模块应用YOLOv3 的多尺度预测模块,经过预测得到3个预测结果。根据预测框的位置、得分,进行非极大抑制操作,获得预测框在原图上的位置。优化后的口罩检测算法不仅保留了YOLOv4检测算法的SPP模块、FPN+PAN结构、CIOU-loss和DIOU-nms,还大大降低了网络模型的参数量和计算量。
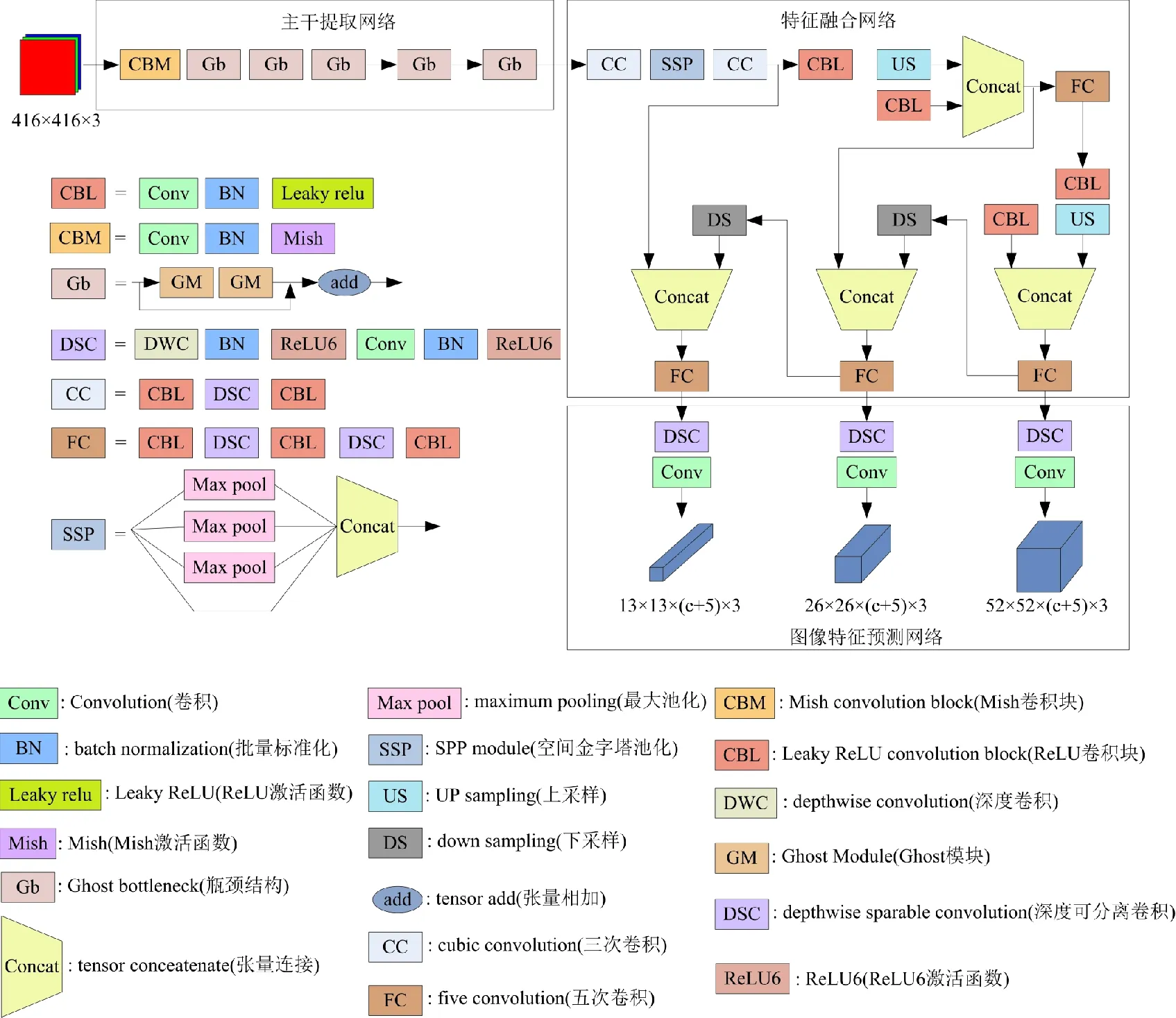
图1 G-YOLOv4口罩检测算法框架图
2.2 G-YOLOv4口罩检测算法网络结构
2.2.1 主干特征提取网络
在降低计算成本过程中,为了采用更少的参数来生成更多的特征,主干特征提取网络主要由16个Ghost bottlenecks组成,并采用Ghost module为构造块。通常在普通卷积层输出特征图中含有许多冗余信息,冗余特征图占用了大量的计算量,因此,引入Ghost module模块,如图2所示。将普通卷积层计算层拆分:一部分为总数有限制的普通卷积;另一部分应用简单线性操作,并利用第一部分特征图生成更多的特征图。实验结果表明[21],在保持原有输出特征图大小和识别性能的同时,使用Ghost module模块降低了神经网络的参数量和计算量。利用Ghost模块的优点,设计了Ghost bottlenecks瓶颈结构,如图3所显示。其中Ghost bottlenecks是由Ghost module所构成的瓶颈结构,类似于ResNet[22]中的残差块,本质上是用Ghost module来代替瓶颈结构里的普通卷积,其中包含了多个卷积层和残差连接。

图2 Ghost module结构图
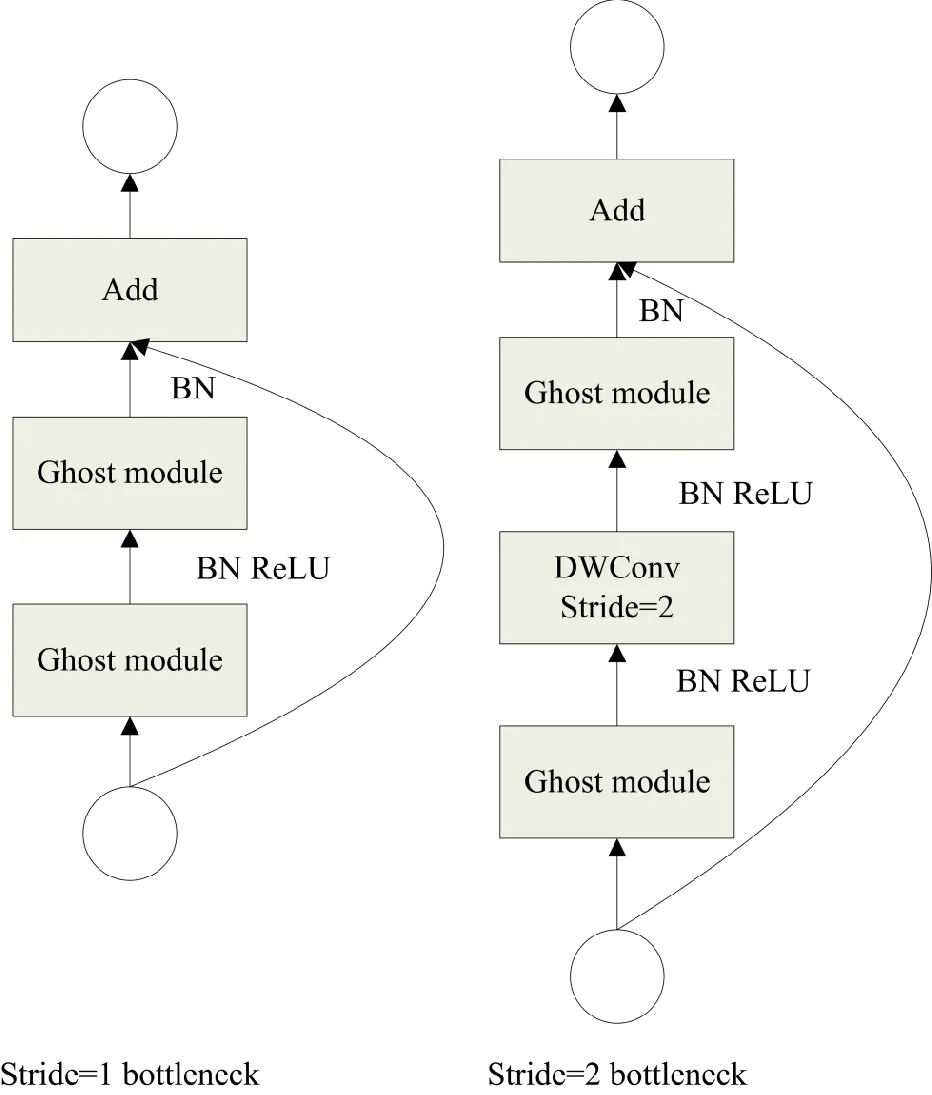
图3 Ghost bottlenecks结构图
基于Ghost bottlenecks瓶颈结构并在GhostNet网络的基础上调整特征提取网络的层级与数量,在多次试验后确定了主干特征提取网络结构,如表1所示。输入大小416×416×3的图像,对输入图像进行16通道的标准卷积层操作并逐渐增加通道数,通过扩大通道数获得不同特征,使得输入图像的特征提取更充分。为了提高人脸佩戴口罩的检测准确率,在特征提取网络中引入通道注意力机制,通过提高有用特征的通道权重,抑制无用特征对模型的干扰。在挖掘戴口罩人脸特征过程中,在第4、5、10、11、12、14、16层Ghost bottleneck中,使用squeeze and excite(SE)注意力机制模块,通过增加较少的计算量可以提升口罩检测精度。
在设计神经网络时,激活函数可以有效提高神经网络的学习效率和表达能力[23]。与深度神经网络架构中的ReLU相比,Mish的平滑、连续图像属性对于信息传播至关重要。Mish(式中简记为Mmish)激活函数如式(1)所示,
Mmish=xtanh(ln(1+ex))
(1)
与Swish、ReLU和 Leaky ReLU在计算机视觉中的不同任务相比,Mish 倾向于匹配或提高神经网络架构的性能,在图像深入特征提取的过程中,表现较优的准确性和泛化能力[24]。当输入为负数时,相较于主流的ReLU激活函数,Mish能更好地保持特征信息的完整性。因此,将Mish激活函数引入主干特征提取网络中,使得模型在提取图像特征过程中更深入、更好地传播信息。
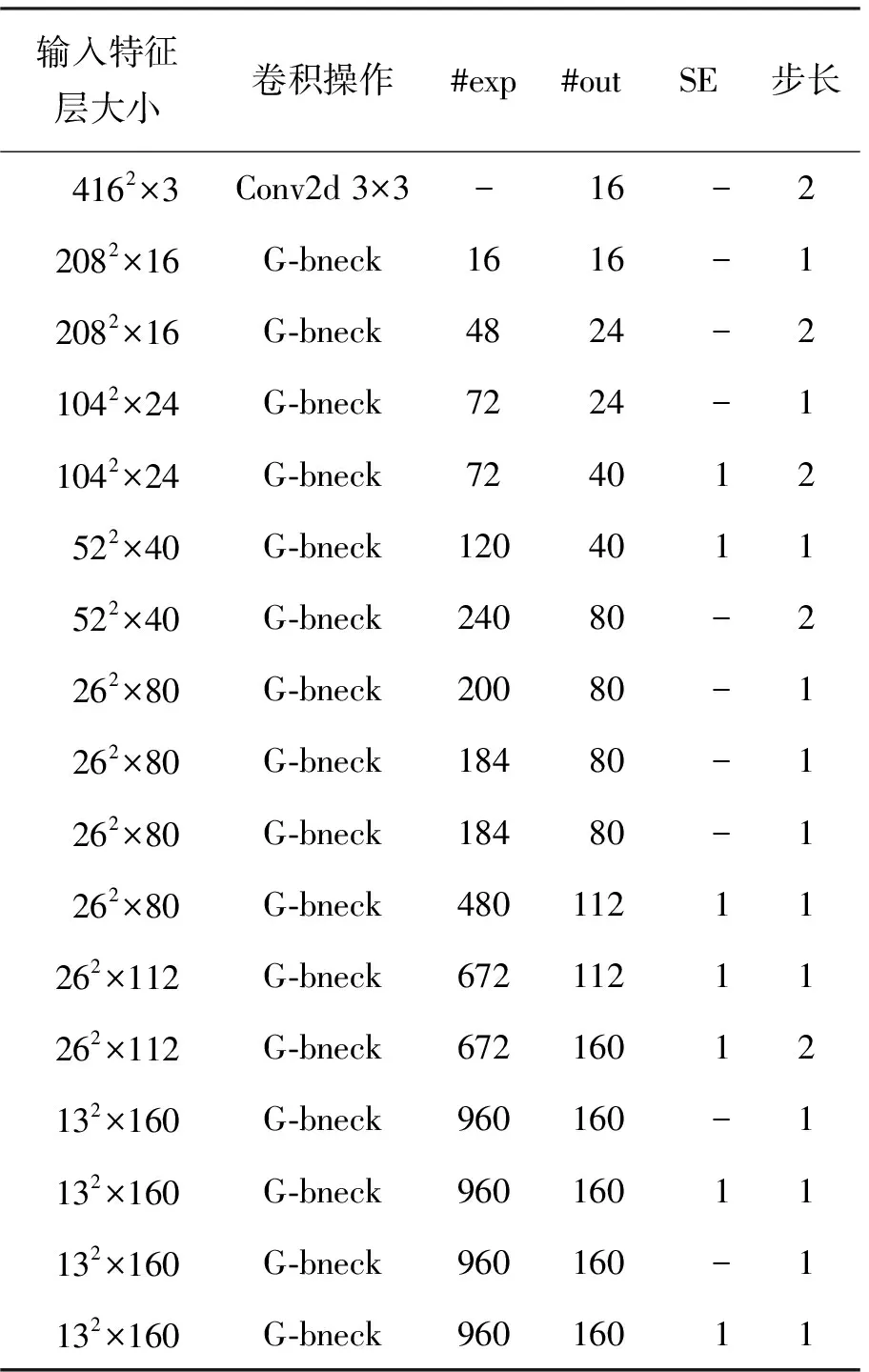
表1 主干提取网络结构Tab.1 Ghost bottlenecks structure diagram
2.2.2 特征融合网络
在目标检测中,融合不同尺度的特征是提高网络性能的重要手段。低层特征分辨率更高,包含更多位置、细节信息,但是由于经过的卷积少,其语义性更低,噪声更多。高层特征具有更强的语义信息,但是分辨率很低,对细节的感知能力较差。为了保留原有的特征信息,引入SPPNet(spatial pyramid pooling network),防止图像被裁剪或缩放后导致图片几何变形、原有信息丢失、预测网络置信度受到影响。将13×13×40特征层进行连续3次卷积,并进行池化核大小为5×5、9×9、13×13、1×1的最大池化处理。将处理后的特征层再进行3次卷积,最终将特征层输入到PANet中进行后续处理。本文将经过主干特征提取网络得到的26×26×112、52×52×160特征层和经过SPPNet加强特征提取得到的特征层接入PANet结构中,可以更有效地增加感受野。
深度卷积(depthwise Conv)和点卷积(pointwise Conv)结合而成的深度可分离卷积[25]在减少参数量和运算量方面取得了极大的成果,使得嵌入式应用发展更进一步。深度可分离卷积的运算量为深度卷积和 1×1 卷积的计算量之和,
DKDKMDFDF+MNDFDF
(2)
式中:DK为卷积核大小;DF为输入图像大小;M为输入的通道数;N为输出的通道数。
深度可分离卷积与一般卷积的计算复杂度之比为
(3)
使用深度可分离卷积代替一般3×3卷积时,在精度损失很小的同时大大减少了计算量[25],随着深度可分离卷积的提出,使得轻量级神经网络兴起与发展。为了进一步降低模型参数量和计算量,在加强特征提取网络引入深度可分离卷积,具体操作为:①使用深度可分离卷积代替SPPNet前后3次卷积中的3×3一般卷积;②使用深度可分离卷积代替PANet卷积块中的3×3卷积;③在下采样过程中应用深度可分离卷积。
2.2.3 图像特征预测网络
特征图经过PANet特征融合后得到3个输出,继而经过回归预测与分类预测得到3个预测结果,包含中、中下和下层预测框,分别对应52×52×40、26×26×112、13×13×160 3个特征层。对3个特征层基于VOC数据集进行处理,输出大小分别是52×52×255、26×26×255、13×13×255的矩阵。通过解码、得分排序、非极大抑制筛选操作,分别对佩戴口罩和没有佩戴口罩这2类进行判别。通过对预测框的筛选,直接在图片上绘制最终的口罩检测结果。
3 实验与结果分析
3.1 数据集
实验数据集使用公开的MAFA数据集和WIDER FACE数据集。训练集包含6 043张照片,验证集包含671张照片,测试集包含1 240张照片。数据集中图像分别标注为mask、unmask,表示佩戴口罩和未佩戴口罩的人脸图像,部分数据集图像如图4所示。

图4 部分数据集展示
3.2 实验环境及模型训练
实验使用Windows 10操作系统,TensorFlow 2.4深度学习框架。运用Adam算法进行模型训练,设置学习速率或步长lr=0.001,第1次估计的指数衰减率β1=0.9,第2次估计的指数衰减率β2=0.999,epsilon=1e-8,batchsize=16,拟训练50个epoch,每个epoch耗时约30 min。
主干网络初始化权重采用在VOC2007数据集训练的权重,其余层的初始化方式为Xavier。以验证集上的损失值作为监测信号,连续3个epoch值不下降,学习率衰减为原来的1/2,连续10个epoch值不下降则实现早停,防止模型产生过拟合。
3.3 评价指标
本文通过对比平均精度(AP)、平均精度均值(mAP)、查准率(Precision)和查全率(Recall)4种性能指标来评估G-YOLOv4算法的性能。其中,坐标轴与P-R曲线所围大小称为预测类别的AP值;mAP则是所有类别AP的均值,mAP的大小可以反应算法性能的优劣,其值越大,性能越好,具有较高的识别精度;查准率为预测结果为正例中实际正例的占比;查全率为真实情况为正例中预测正例的占比。
3.4 实验结果分析
本次实验训练50代,以验证集上的损失值作为监督信号,连续10个epoch损失值不下降则实现早停,4种模型均在第50代之前实现早停并收敛。为了分析不同的网络对整体网络的影响,采用深度学习领域常用的消融实验方法进行验证与分析[26]。本文对YOLOv4复现网络和3种修改网络进行消融实验,通过表2设计的消融实验进行对比验证,得到表3的实验结果,并进行网络性能分析,证明算法的优越性。
如表2所示,曲线1代表YOLOv4网络;曲线2代表在YOLOv4中使用深度可分离卷积的初步优化模型;曲线3代表在曲线2的基础上利用轻量化GhostNet网络进行提取特征的网络模型;曲线4代表在曲线3的基础上引入Mish激活函数得到的进一步优化网络模型。

表2 消融实验设计Tab.2 Design of ablation experiment
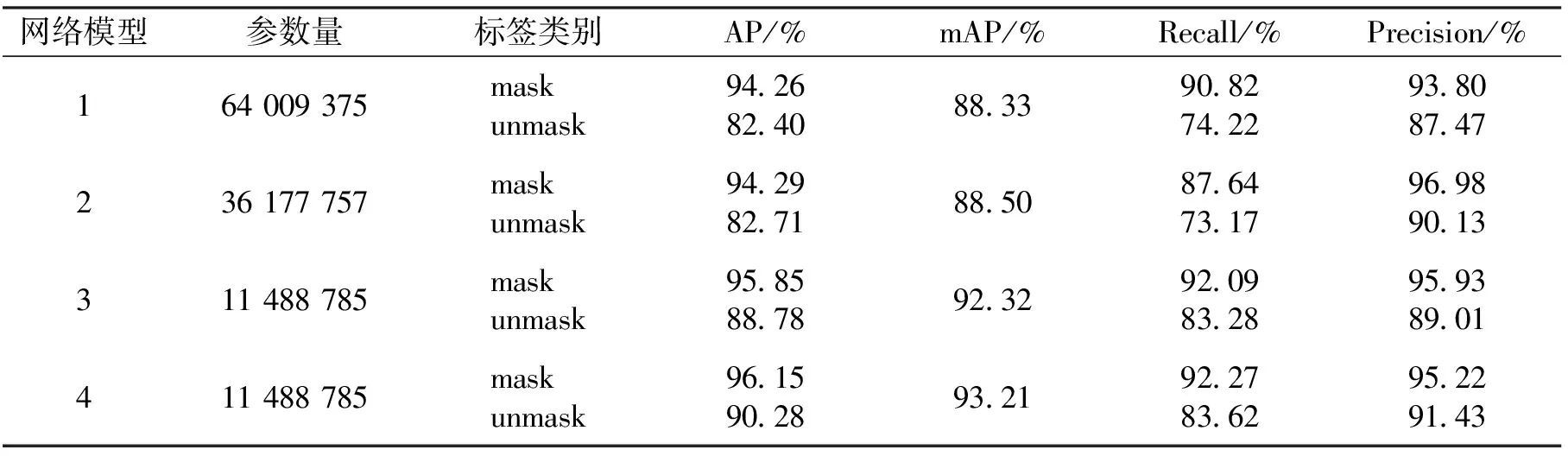
表3 消融实验结果Tab.3 Ablation experimental results
对比模型1和模型2, 模型2的mAP从88.33%上升到 88.5%, 上升了0.19%,模型参数量从64 009 375减少到36 177 757, 减少了27 831 618,虽然模型精度提升不高,但大大降低了模型参数量。对比模型2和模型3,模型3的mAP从88.5%增加到92.32%,提升了4.31%,模型参数量从36 177 757减少到11 488 785,减少了26 688 972,说明模型在提高检测精度的同时也减少了模型参数量。对比3和模型4,模型4的mAP从92.32%增加到93.21%,提升了0.96%,在模型参数量基本一致的情况下精度有所提高。口罩佩戴检测任务中综合考虑模型的参数量和检测精度,可知模型4为优化模型中综合性能表现最好的,具有较高检测精度,满足了口罩佩戴检测任务的要求。
各模型所有类别AP值对比如图5所示。从图5和表3可知,采用改进后的GhostNet主干特征提取网络和改进后的加强特征提取网络对模型进行训练,优化后的G-YOLOv4模型在mask、unmask和整个数据集上的平均精度是4个模型中最优的。
图6为原YOLOv4算法和改进的G-YOLOv4算法检测P-R曲线图。P-R曲线可以直观地显示分类算法在整体上的查准率和查全率,通过P-R曲线下的面积大小对比性能的优劣,面积越大,性能更优。从图6可以看出, G-YOLOv4算法中佩戴口罩、未佩戴口罩两种类别的P-R曲线下的面积均大于原YOLOv4算法的P-R曲线下面积,因此,G-YOLOv4算法的性能更优。
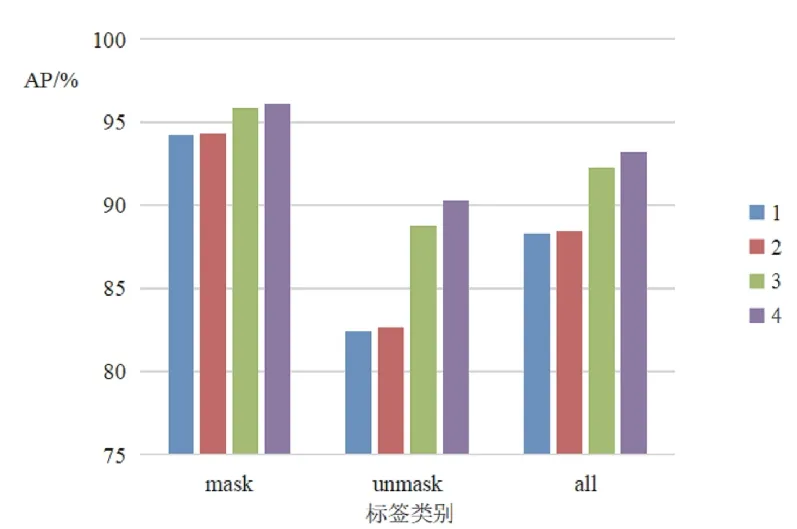
图5 各模型所有类别AP值对比
将本文算法与现有目标检测算法YOLOv3、YOLOv4和YOLOv4-tiny进行对比,所有算法均采用与G-YOLOv4算法相同的实验数据、实验环境和实验设备。以模型参数量、计算量、平均精度均值(mAP)和每秒可识别图像数量(FPS)作为评价指标,不同算法的实验结果如表4所示。为了评测模型的实时性,利用同一张图像对表4中4种模型进行预测,根据预测所消耗的时间计算出FPS。算法的检测速度可以通过FPS的大小进行准确地判断,检测速度越快,FPS值越大,人眼认为FPS大于24是实时的画面。

图6 各类目标P-R曲线
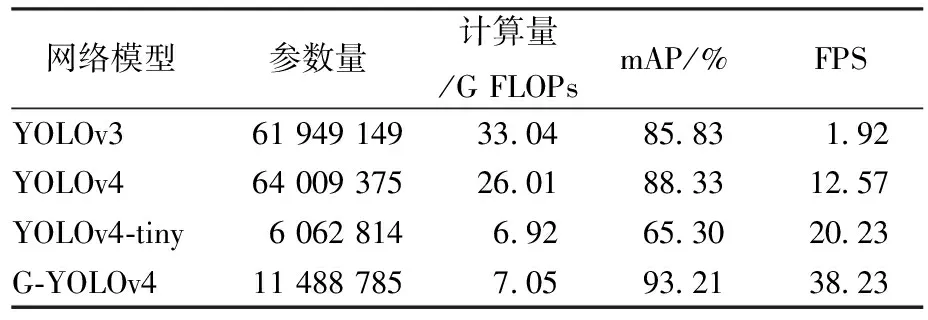
表4 算法计算量对比Tab.4 Algorithm calculation comparison
本文通过对YOLOv3算法、YOLOv4算法、YOLOv4-tiny算法的复现,得到与王兵等人[17]近似的实验结果,可以看出,本文算法在mAP值和检测速率上表现最好。由实验结果得出,相较于YOLOv3算法,YOLOv4算法mAP值从85.83%提升到88.33%,提升率为2.91%;模型参数大小从61 949 149增加到64 009 375,增加了2 060 226;模型的计算量从33.04 GFLOPs减少为26.01 GFLOPs,减少了7.03 GFLOPs;FPS从10.92增加到12.57,提升率为15.11%。说明YOLOv4算法通过改进DarkNet53特征提取网络和FPN特征金字塔,使得目标检测精度与速度有了较大提升。相较原YOLOv4算法,G-YOLOv4算法mAP值从88.33%提升到93.21%,提升率为5.52%;模型参数大小从64 009 375减少为11 488 785,相比于原YOLOv4算法减少率为82.05%,模型的计算量从26.01 GFLOPs减少为7.05 GFLOPs,相比于原YOLOv4算法减少率为72.90%;FPS从12.57增加到38.23,提升率为204.14%,说明检测速度的进步十分明显,且FPS达到24可以满足实时性的要求。G-YOLOv4在检测能力和减小模型参数、计算量方面优于原YOLOv4算法。根据实验结果可知,G-YOLOv4算法相较YOLOv4-tiny轻量化目标检测算法在参数量上虽然增加了5 425 971,但计算量上只增加了0.13 GFLOPs,且G-YOLOv4算法的mAP值提升了42.74%,检测速度提升了88.98%。
3.5 检测效果对比
图7为不同算法在相同的场景中的检测效果。在人员密集场景中,YOLOv3算法与YOLOv4-tiny算法存在错检、漏检情况,YOLOv4检测算法存在漏检情况,当存在人物侧脸和较模糊人脸图像时,这3种网络识别效果均不佳。改进后的G-YOLOv4算法提高了特征提取能力,在处理图像细节特征方面表现更好,检测效果明显提升,降低了检测结果的漏检、错检数目。

图7 各算法检测效果对比
4 结语
本文提出G-YOLOv4口罩佩戴检测模型,使用GhostNet作为骨干特征提取网络对人脸图像是否佩戴口罩进行检测,并在加强特征提取网络中引入深度可分离卷积,不仅保证了检测精度,还大大降低了网络模型的参数量和计算量,采用Mish激活函数作为GhostNet网络中激活函数,最终在原YOLOv4算法的基础上大幅减小了模型参数量并提升了mAP。实验结果表明,本文所提G-YOLOv4口罩佩戴检测模型性能无论是准确率还是模型参数量,相对于原YOLOv4算法都有了较大提升,可以使人脸口罩检测对处理器硬件要求更低、准确率更高。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
意林(2020年9期)2020-06-01
海峡姐妹(2020年4期)2020-05-30
电子制作(2019年11期)2019-07-04
作文大王·笑话大王(2019年3期)2019-04-22
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年11期)2017-04-04
噪声与振动控制(2015年4期)2015-01-01
电视技术(2014年19期)2014-03-11
