
基于时钟触发长短期记忆的多元时序预测
2023-05-06 03:17:04冯述放
华东理工大学学报(自然科学版) 2023年2期
冯 勇,冯述放,罗 娜
(华东理工大学能源化工过程智能制造教育部重点实验室, 上海 200237)
时间序列是指变量按照时间顺序记录的观测序列[1],广泛存在于金融[2]、交通[3]、工业生产[4]等多种场景。时间序列可以分为一元和多元时间序列,以多元时间序列场景居多。多元时间序列的变元之间存在复杂的耦合关系,呈现出明显的非线性、非平稳性[5]。
时间序列分析作为数理统计学的重要分支,其目的在于挖掘出时序数据的变化规律进而预测事物的发展趋势[6]。时间序列的预测结果有助于人们把握事物的变化方向,对于日常生活的安排、生产过程的控制、社会活动的调度都具有重要的参考价值,能够进一步实现资源分配的优化与经济效益的提升[7]。
在时间序列预测问题中,传统的统计模型如差分整合移动平均自回归模型[8]、向量自回归(Vector Auto-Regression, VAR)模型[9]均无法适应当今大量时序数据的建模需求。典型的机器学习模型如隐马尔可夫方法[10]、支持向量机回归(Support Vector mach ine Regression, SVR)[11]、人工神经网络[12]、极限梯度提升(XGBoost)[13]等虽已广泛应用,但面对海量数据处理时无法深度挖掘数据特征,容易陷入局部最优值[14]。递归神经网络(Recurrent Neural Network, RNN)[15]在序列特征中依靠自身隐藏层状态的迭代与每个时间步输入的获取,能够灵活地捕获建模变量与输出序列的非线性关系。传统的RNN 在输入过长时存在梯度消失问题,不能捕获长时间的依赖。为此,长短期记忆(Long Short Term Memory, LSTM)网络[16]和门控循环单元(GRU)网络[17]被相继提出,从而有效地把握了时间序列中的长期信息。
在循环神经网络的基础上,为进一步挖掘时间序列中的频率特性,Jan 等[18]提出了分割隐藏状态矩阵的时钟循环神经网络(Clockwork Recurrent Neural Network, CWRNN),其中隐含层被划分为多个独立的模块,每个模块按照自己的时间粒度处理输入,仅按照规定的时钟速率进行计算,依靠长周期单元对长期数据的保持和传递,在一定程度上解决了传统RNN 的长期依赖问题。由于引入了长期链的RNN网络,存在短期信息权重过低的问题,无法快速响应短期突变数据。Hu 等[19]在LSTM 基础上,提出了转换门控的LSTM 来提高捕获短期突变信息的能力,但由于转换门控机制在输入时序较长时会过度地丢弃远期信息,导致失去全局区域的信息特征。
由于测量噪声与环境干扰的影响,应用于实际场景下的时序预测模型需要提升在数据波动下的鲁棒性与泛化能力。Chen 等[20]提出了稀疏模态加性模型,将稀疏模型应用于高维数据分析,通过对模态回归度量、数据相关假设空间和正则表达式在加法器中的整合,确保了模型对复杂噪声的鲁棒性,有效消除了模型对非高斯噪声的数据敏感,实现了噪声环境下的有效预测。Zhao 等[21]提出了一种自适应稀疏量化核最小均方算法,将稀疏化规则、权重自适应调整、顺序异常值准则和量化预测相结合,在面对噪声数据时取得了较好的预测性能。时间卷积网络[22]通过在长时间序列上膨胀因子的设置,在数据提取上具有稀疏后归并的特性,经过多层时间卷积网路的运算,在时间序列预测问题上也呈现出良好的精度,但由于训练的神经元数目过多,容易陷入局部最优值。
总的来说,多元时间序列预测存在两个难题:一是如何平衡长期历史信息与短期突变信息,从而保证模型的精度[23];二是在环境变化时,模型如何排除噪声干扰,有效提取特征[24]。长期历史信息能够提供更丰富、全面的数据参考,从而保证预测结果符合长期趋势,减小预测误差,但长期信息也会对短期信息造成干扰。部分时间较远的历史数据对当前产品指标的影响相对较小,甚至会产生遗留噪声,造成错误的规律导向[25];另一方面,大部分的产品指标往往与近期的生产工况密切相关,历史信息过长也会降低模型对短期信息分配的权重,无法敏锐捕获短期信息会使得预测结果出现明显的滞后,无法及时反映生产工况带来的指标影响[26]。
本文采用CWRNN 原有的网络结构,将神经单元分成不同时钟激活周期的神经单元组,设计了时钟触发长短期记忆网络(CWTLSTM),主要改进如下:
(1) 根据不同神经单元组周期的划分,将神经元分为主干网络链(持续激活)与短期信息增强链(非持续激活)。主干网络链主要负责状态的计算与保持,短期信息增强链只在激活时负责对当前时间步的信息获取;通过链路传输结构的设计,只允许数据从短期信息增强链单向流动到主干网络链,在短期信息增强链激活时,加强该时刻对突变信息的捕捉能力。
(2) 对短期信息增强链而言,在当前时间不是神经元时钟激活周期的整数倍时,将对应的神经元状态置为0 而不是保持上一时刻的状态,形成算法上的稀疏结构,保证短期链不受长期信息干扰,增强当前输入的权重,加强噪声数据的淘汰概率。
(3) 将CWRNN 中神经元载体从简单RNN 单元变为LSTM 单元,以此保证在面对较长的时间序列时,加强主干网络链对长期信息的状态保持能力,使得模型进一步具备平衡长短期信息的能力。
1 问题描述
时间序列预测属于回归问题,对于单时序预测问题而言,设x∈R 为观测变量,在一个时间段{1,2,3,···,t}内,能够观测得到单变量时间序列xt=[x1,x2,···,xt]T,预测目标是预测时间序列的下一个值xt+1,预测完全依赖变量自身变化的规律延续性[27]。
多元时间序列是多个一元时间序列的复杂组合,多元时序预测中,有时间段 {1,2,3,···,t}内的目标变量序列yt=[y1,y2,···,yt]T,预测目标为yt+1;m个一元序列在该时间段内的观测结果可以表示为
其中:Xt为外生驱动变量矩阵;表示第m个变量的时序变量序列;表示第m个变量的t时刻的值;m为观测序列数量。
多元时间序列预测的基本思想是一方面根据事物自身发展的延续性,统计分析过往的时间序列数据,实现yt的趋势预测[28];另一方面,考虑到Xt对yt+1的影响,使用驱动变量的历史数据作为建模输入以增强预测的精度与可信度。因此,将作为驱动变量,时间序列预测模型如式(2)所示:
其中:F(·) 表示多元时序预测模型对Xt的运算过程;εt+1为t+1时刻模型的预测残差。由式(2)可知,多元时间序列预测的重点在于如何开发精确有效的模型使得残差最小,实现精准预测。
2 CWTLSTM 模型
CWTLSTM 的结构如图1 所示。将LSTM 单元分为若干组,网络中共有u个LSTM 单元,平均分配给g个拥有不同输出周期Tgroup={T1,T2,T3,···,Tg} 的单元组,每个组含有k=u/g个单元。
计算过程中,只有在输入时间步t是Tgroup的整数倍时,对应的神经元才能进入激活状态,接收当前时刻的输入xt、上一时刻隐藏层状态ht−1,完成神经元状态的更新与输出;否则该单元对应的细胞状态ct与输出ht均为0,输出无法传递至下一时间步的运算,称为未激活状态。
如图1 所示,CWTLSTM 一方面只允许右侧分组向左侧分组单向地传递状态信息,另一方面不同组具有不同的激活周期,根据周期的不同,在指定的时间步上激活并参与运算。最左侧满足Tgroup=1 条件的神经单元组为主干网络,在每个时间步上都能持续触发激活状态,接受上一时刻网络中所有神经单元的状态与当前输入,能够保存所有时间尺度上的信息。其余分组的神经单元一般设置Tgroup>1 ,构成短期信息增强链,只在t是Tgroup整数倍的时间步上激活,无法保持上一时刻的状态数据,激活时才能向下一时间步传递细胞状态与输出。模型中只有Tgroup=1的主干网络链能够长期存储历史信息,而短期信息增强链自身的历史信息流向会被强制切断,此类神经单元组可以视为不包含历史信息的输入增强模块,单向地将信息传递至主干网络链。因此,合理设置短期信息增强链的数目与周期能使模型增加近期输入信息的分配权重,便于捕获短期信息突变。
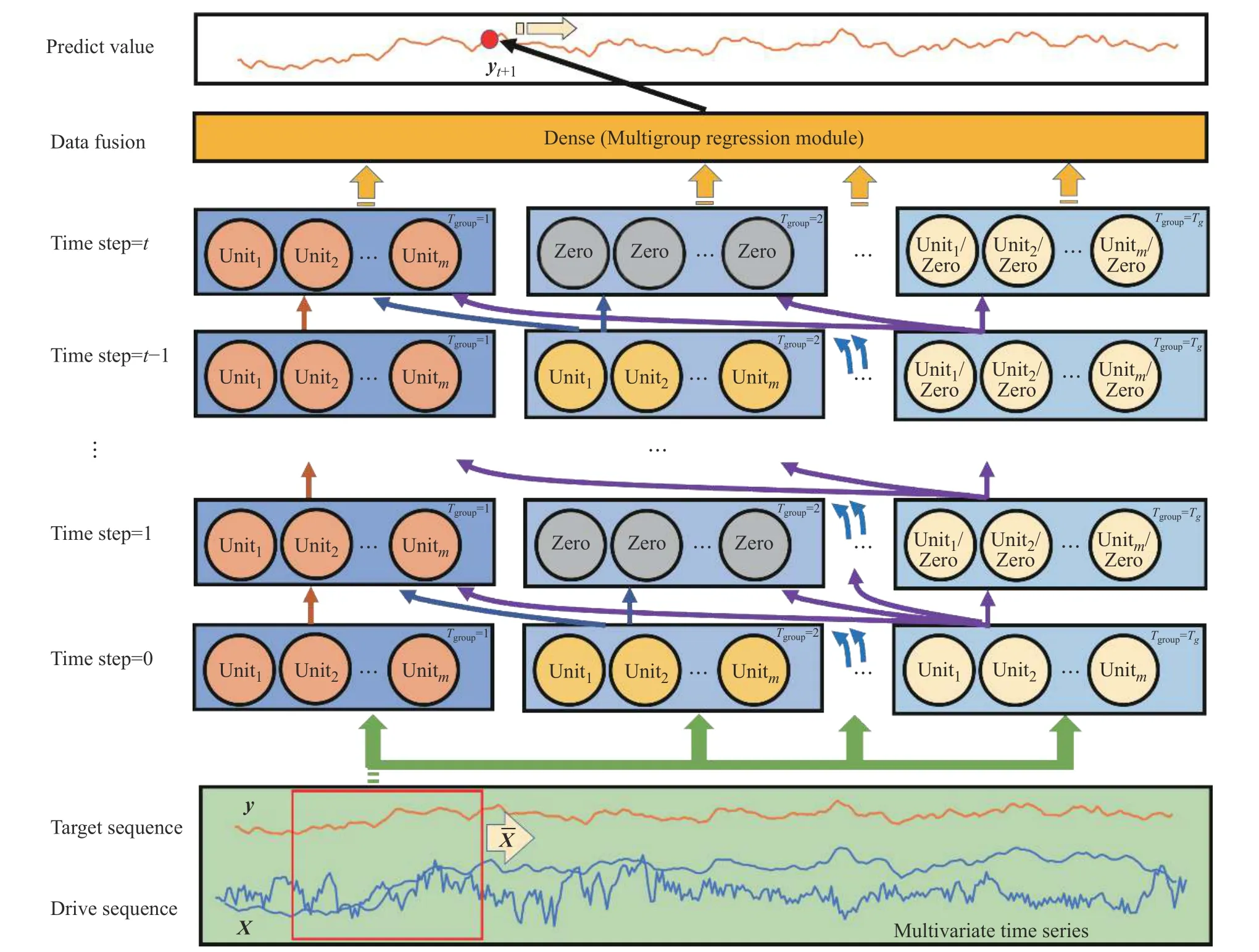
图1 CWTLSTM 结构图Fig.1 Structure of CWTLSTM
2.1 单元组内的权重更新方式
LSTM 单元各部分的计算如下:
式中xt、it、ft、c˜t、ot、ct、ht分别表示t时刻的变量输入、输入门结果、遗忘门结果、候选细胞状态、输出门结果、细胞状态、细胞输出;Wi、Wf、Wc、Wo分别表示输入门权重矩阵、遗忘门权重矩阵、细胞更新权重矩阵、输出门权重矩阵;σ(·)为对应位置的激活函数;b为对应的偏差。
CWTLSTM 在输入门、遗忘门、细胞更新策略、输出门这4 个位置同时设立时钟触发策略,对每个门进行调整。权重矩阵Wi、Wf、Wc、Wo均按照周期性激活的特性进行计算,各组的权重子矩阵在不是本组周期整数倍的时间步上均为 0 矩阵,以此表示未激活细胞的缺省状态。以第j组神经单元为例,运算规则如下:
其中:Wij、Wf j、Wcj、Woj分别表示第j组神经元的输入门、遗忘门、细胞更新与输出门的权重矩阵;Wjq(q∈){1,2表,···,示g}第组j内第q个神经元的权重矩阵;为t当前时间步;Tj表示第j组神经元的激活周期;表t%T示j=当0前时间步被第t组激j活周期Tj整除,即为tTj的整数t%倍Tj;≠0表示其他情况。根据式(3)和式(4)可知:在不考虑各门控单元偏移量bi、bf、bc、bo的情况下,对第j组神经单元而言,非周期整数倍的时间步上其输出hjt、cjt均为 0 矩阵。
当t%Tgroup≠0 时,ht与ct均为0,该LSTM 神经元不参与下一时间步的交互运算,从而形成该时刻该神经元在算法上的缺省稀疏。对于一个不向外界传递参数的非激活单元而言,其内部参数状态无法对网络其他部分造成干扰,因此可以通过给神经元的输出ht与ct赋零值来表达非激活状态下的神经元特征,以此封锁该神经元向下一时刻网络的状态传递,而不必修改数量庞大的权重矩阵。这样一方面保证了时间复杂度的降低,从对整个网络的所有权重矩阵的操作改为对非激活单元输出值的操作,其执行速度上有明显提升;另一方面也防止了各门控机制的权重在时间步上变化不连续的情况出现,避免了因矩阵不满秩而导致在梯度计算时出现求导错误的危险。
图2 为分频规则为[1,2,1]时的CWTLSTM示例。将神经单元分成3 组,分别赋予1、2、1 的激活周期,由于第1 组、第3 组的Tgroup均为1,因此持续激活始终参与运算,均为主干网络链;第2 组的Tgroup为2,因此只在偶数时间步时输出进行运算,而在奇数步时细胞状态与单元输出均为0,使得下一时间步该神经单元在计算输出时,从本单元接收的状态数值为0,进而使得加权求和时输入数据的权重增加。
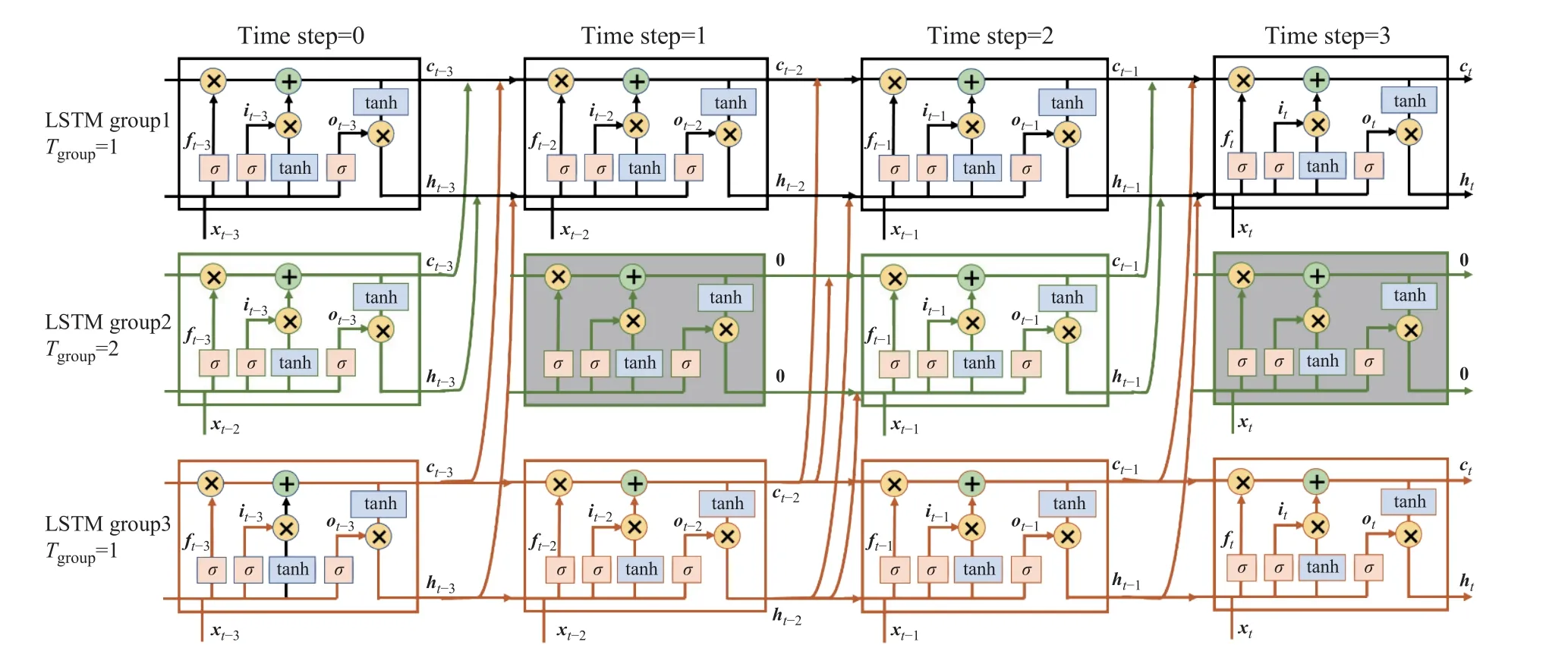
图2 分频规则为[1,2,1]的CWTLSTMFig.2 CWTLSTM with frequency division rule [1,2,1]
从数据捕获的角度看,CWTLSTM 存在不同时间步间的稀疏计算,如果主干网络神经单元数较少,在训练过程中可能会导致一定的数据损失,但是稀疏特性却能够保证模型在训练时不易陷入过拟合状态和局部最优值,因此在噪声环境中能够保持模型的泛用性与精确度。
2.2 单元组之间的权重更新方式
图1 中神经单元组被激活时,内部每个单元能够接受上一时刻同一组内所有单元的细胞状态与输出;但在各个分组间的交互上,每个神经单元组只允许神经元状态h单向地传给位于其左侧的神经单元组。同样,图2 中示出的各组间的信息交互只能从下向上传递,以此保证短期信息增强链的信息汇入主干网络链,并将训练重点放在最上侧的主干网络链上。
CWTLSTM 的另一个改进是对LSTM 网络中状态传递矩阵 Mask 的调整。在LSTM 网络中,原始的Mask矩阵为全1 矩阵,表示同一时间步上神经单元之间的全连接,每个LSTM 单元获取上一时刻所有LSTM 单元状态。以整个网络的遗忘门输出为例,分析Mask传递矩阵的作用。对LSTM 网络整体,数学表达式为
其中:Wfh为状态权重矩阵,表示LSTM 网络对上一时刻网络状态的响应能力;Wf x为输入权重矩阵,表示网络对当前输入的响应能力;运算符 ◦ 为哈达玛乘法,表示符号前后矩阵相同位置元素对应相乘构成新矩阵(C=A◦B⇔cij=aij∗bij)。由式(6)可知,LSTM 网络的 Mask 矩阵为全1 矩阵,每个LSTM 单元接受来自上一时刻的所有LSTM 单元输出并进行计算。
为实现CWTLSTM 的功能,将CWTLSTM 神经元之间的连接矩阵 Mask 划分为g×g个块矩阵组成的稀疏掩码矩阵,状态传递矩阵 Mask 为块上三角矩阵,表达式为
其中:Mij表示分组j向分组i的传递权重矩阵,大小为k×k(k为分组内的神经元数目),Mij= Ones 为全1 矩阵时,表示分组i能够接受分组j的神经元输出值hj;Mij= 0 为零子矩阵时,表示对应分组j无法向分组i传递神经元输出值hj。
将 Mask 矩阵与网络各门控机制的单元权重矩阵W·,h对应元素相乘,即可控制CWTLSTM 各个神经单元对上一时刻网络输出的响应能力。
其中:W·,h(Wi,h、Wf,h、Wc,h、Wo,h)表示CWTLSTM的各门控机制对所有上一时刻隐藏状态的权重分配;Wij= 0 矩阵表示分组i对分组j的神经元输出值h赋予的关注权重均为0,其子矩阵均表示正常运算。
如式(9)和图2 所示,网络只允许下层分组的神经单元向上层分组传递状态信息,一方面可以避免模型在短期信息增强链在未激活时进行无意义的计算,提升运算效率;另一方面也能保证底层神经元激活时只受输入影响,避免其他组状态值的影响导致W·h增大,保持神经元对当前输入的强相关性,保证模型增强输入的作用。
在图3 的示例中,将CWTLSTM 分为2 组,Tgroup分别为[1, 2],此时CWTLSTM 将主要以分组1 为主要运算模块,主干网络同时接受当前输入、上一时刻的自身神经元状态Hgroup1与增益网络的状态Hgroup2。Tgroup=2的分组每2 个时间步激活一次,对当前输入进行运算得到细胞输出与细胞状态后,才向主干网络传递一次本组的运算结果,显式地增强激活时刻输入的权重占比。显而易见,越远离输出时间步的输入,增益对网络整体的输出结果影响越小;越靠近输出时间步的输入,增益对主干网络的影响越大,因此,输入增强链主要增强了短期内的信息,称为短期信息增强链。短期信息增强链向主干网络链的单向传递结构,在主干网络保留长期信息的基础上,可以提升对短期信息的捕获能力。
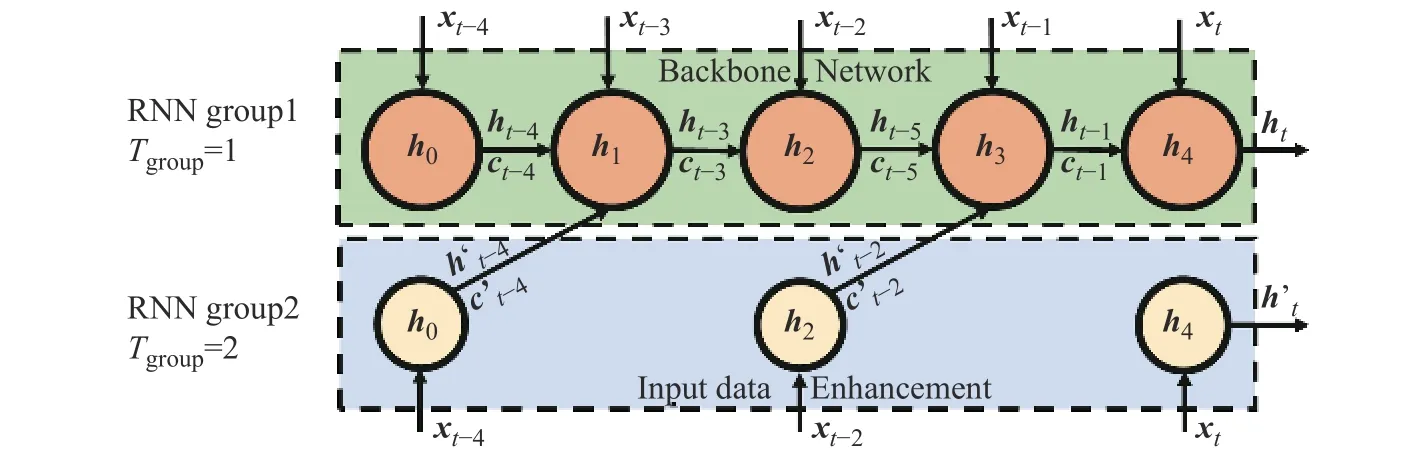
图3 短期信息增益说明Fig.3 Description of short-term information gain
2.3 CWTLSTM 的权重计算
CWTLSTM 整体的权重更新方式仍然遵从LSTM网络反向传播的训练规则,由于 Mask 与W,h始终保持对应位置元素相乘的状态,因此对W,h训练更新可以看作是对 Mask◦W,h整体的训练计算。本文使用梯度下降法更新以完成所有参数的寻优,关键点在于计算所有参数基于损失函数的偏导数[29],步骤如下:
(1) 按照网络的前馈运算公式(10)得到CWTLSTM在t时刻的输出值为ht:
已知损失函数为 Loss ,定义t时刻的状态梯度为遗忘门、输入门、细胞更新、输出门梯度分别为:
根据链式求导与导数乘法展开,得到:
(2) 将循环神经网络展开,通过t时刻的梯度反向计算神经元上一时刻的损失函数对单元输出的偏导数 δt−1;在LSTM 网络中存在梯度关系为
由此可以反向推导之前每一时刻的梯度数值,并可根据式(11)得到 δf,k、δi,k、δ~c,k、δo,t,便于后续运算。
(3) 计算得到t时刻每个权重的梯度:
对循环网络而言,最终的梯度是各个时刻的梯度之和,由此得到一个样本的损失函数对权重矩阵的梯度值:
使用相应的优化器来更新权重,向损失函数梯度小的方向进行迭代,使得 Loss 函数降低[30]。
同理,可根据式(11)的前项公式与式(13)中梯度展开方法,推导得到各门控单元的输入权重矩阵W·x与偏移量b·的计算公式:
在训练阶段,CWTLSTM 根据式(14)~式(16)在每个迭代周期中利用梯度下降方向作为寻优方向,修改权重矩阵(模型的可训练参数)以减小误差,不断地在可行域中找到令损失函数最小的最优解,直至完成完整的模型训练。
2.4 CWTLSTM 空间复杂度分析
LSTM 的可训练参数有W·h、W·x、b·,假设存在u个神经单元,数据集的输入维度为d,共有d个特征数目,则每个单元共有 4u2个状态权重参数、4u×d个输入状态权重参数与 4u个偏移量参数,故LSTM的空间复杂度为O(4u(u+d+1))。此外LSTM 代码包中存在不参与训练的参数(如Mask 矩阵参数等模型底层支持变量),种类较多且不便计数,此类参数记为ot个,则LSTM 总的空间复杂度为O(4u(u+d+1)+ot)。CWTLSTM 的可训练参数与LSTM 数目相同,空间复杂度为O(4u(u+d+1)) ,为实现网络特有功能,每个神经单元增添的参数有:用以辨别激活时间步的周期参数 period、在非激活状态下的输出htemp=0 与ctemp=0=0 ,共计 3u个参数。额外参数量加上LSTM 的原有参数量,得到CWTLSTM的空间复杂度为O(u(4u+4d+7)+ot)。
LSTM 的底层运算设计非常繁琐且复杂,假设总体的时间复杂度为O(all)。已知在原始LSTM训练过程中,状态权重矩阵计算的时间复杂度为O(u3) ,输入权重矩阵相关计算的时间复杂度为O(ud) ,因此必然有 all>4u(u2+d)。在CWTLSTM中,当神经元处于非激活状态时需要设置临时输出htemp=0与ctemp=0,其最大时间复杂度为其中g为神经单元组数,可知因此,CWTLSTM 总的时间复杂度为O(all) ,可认为CWTLSTM 与LSTM 的时间复杂度基本相同。
3 案例研究
3.1 验证指标
本文首先采用开源的空气污染数据集[31]进行初步的模型性能探讨,再利用现场采集的水泥篦冷机数据集进行进一步的模型性能分析。
自相关函数(Auto Correlation Function, ACF)[32]描述了序列的当前值与其过去值之间的相关程度,描述随机变量X在任意不同时刻之间的相关程 度Rt1,t2[33]。
其中:Xt1、Xt2分别表示时刻X的观测序列;µt1、µt2分别为Xt1、Xt2的均值;σt1、σt2分别为Xt1、Xt2的标准差。Rt1,t2的数值越接近1,表示与两个时刻对应的观测序列相关性越高。
将CWTLSTM 与VARMAX[34]、SVR[35]、XGBoost[36]、CWRNN[37]、LSTM[38]等基准模型进行比较,观测本文模型的预测性能。为了量化预测模型的有效性,采用均方根误差(RMSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)、回归平方和与总离差平方和之比值(R2)这些分析指标进行数值验证,分别如式(18)~式(21)所示。
RMSE、MAE、MAPE 越小,表明预测值与真实值的误差越小,模型精度越高;R2越大表示预测值与真实值的相关性系数越高,模型的拟合效果越好。
3.2 空气污染数据集
空气污染数据集采集于意大利城市内严重污染地区,记录了包括一氧化碳、苯、二氧化氮在内共计12 种空气污染物的浓度,采样周期为1 h,处理后的有效数据总计7 865 条,预测变量为一氧化碳质量浓度。
将该数据集数据按照0.6∶0.2∶0.2 的比例划分为训练集、验证集、预测集,图4 分别示出了训练集、验证集、预测集在200 个采样时间步(200 h)的原始数据曲线与ACF 曲线。ACF 曲线具有明显的周期相关特性,而在一个周期的时间长度内,基本只有短期数据呈现较高的相关性。在实验中设定时间步长(Time step)为对照参数,分别设置为10、48(时长为空气污染数据集的两个显著周期),比较在该数据上短期信息增强能否提供有效的数据支持。其余参数batch 为128,epochs 为200,分频序列为[1,2,3]。
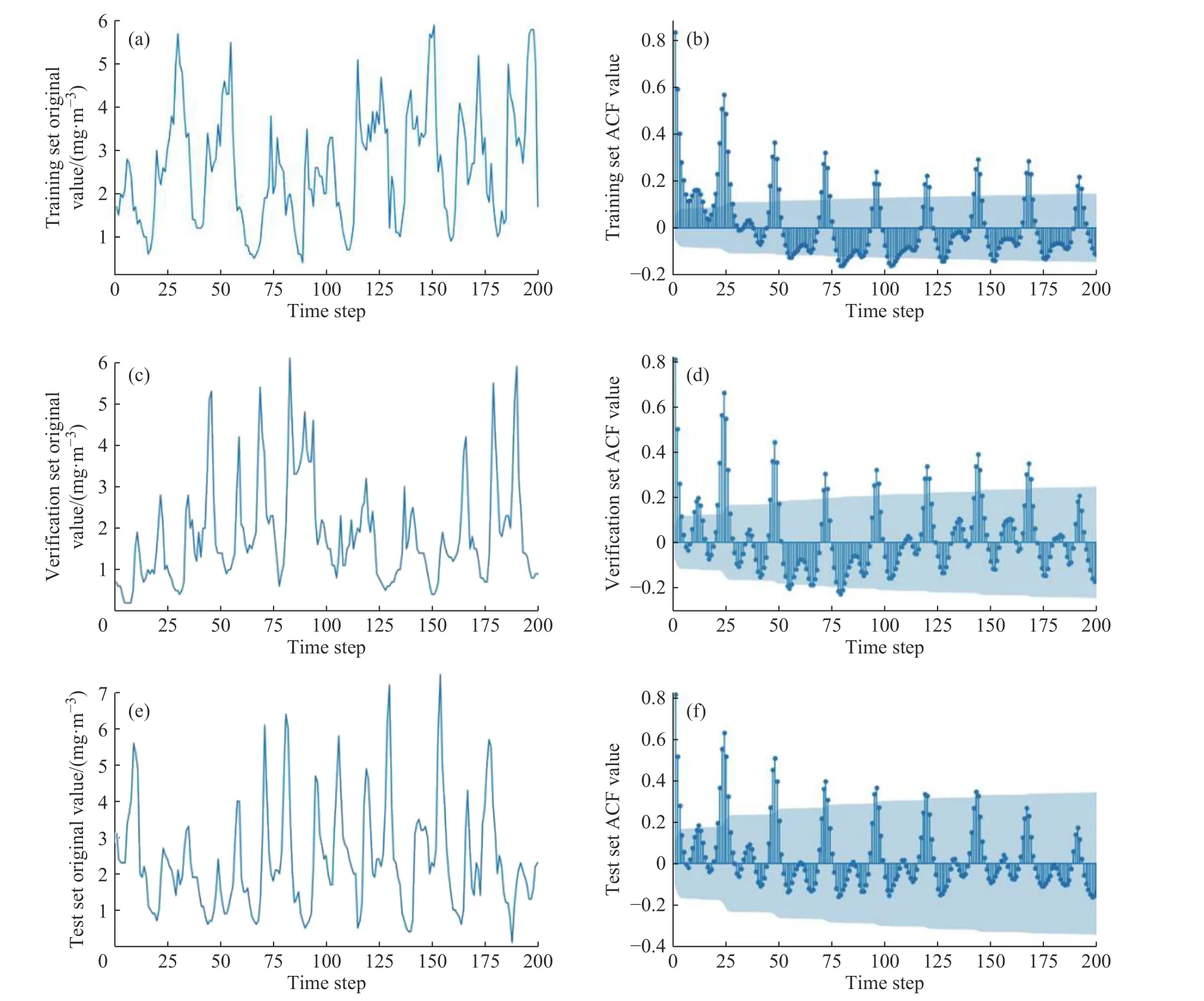
图4 一氧化碳质量浓度的原始数据曲线与ACF 曲线Fig.4 Original data curves and ACF curves of CO mass concentration
设置XGboost 的最大树深度为20,弱估计器的数量(树的个数)为80;SVR 的参数为高斯核函数,惩罚系数(C)为0.5,核参数gamma 为0.3;LSTM、CWRNN、CWTLSTM 均设置96 个神经单元加一层单个神经元的全连接层。
对不同模型进行训练,预测结果见表1,表中的加粗部分表示最优指标(取自多次调参后的最优结果),前100 个点的预测曲线如图5 所示。
由表1 可得,当Time step=10 时,CWTLSTM 取得了所有模型中的最好性能;当Time step=48 时,CWTLSTM 的RMSE、MAE、R2均最小,但MAPE 的结果逊于SVR 与XGBoost。观察图5 可以看到,SVR 与XGBoost 均有明显的预测滞后,在明显的数据波动时是使用前一时刻的观测变量值代替预测值,数值结果上MAPE 较小,但预测趋势的跟随性能较差。CWRNN 与CWTLSTM 的跟随速度较快,在80 到100 样本区间中,CWTLSTM 面对频繁变化小波动仍然能够获得更加精准稳定的预测表现。
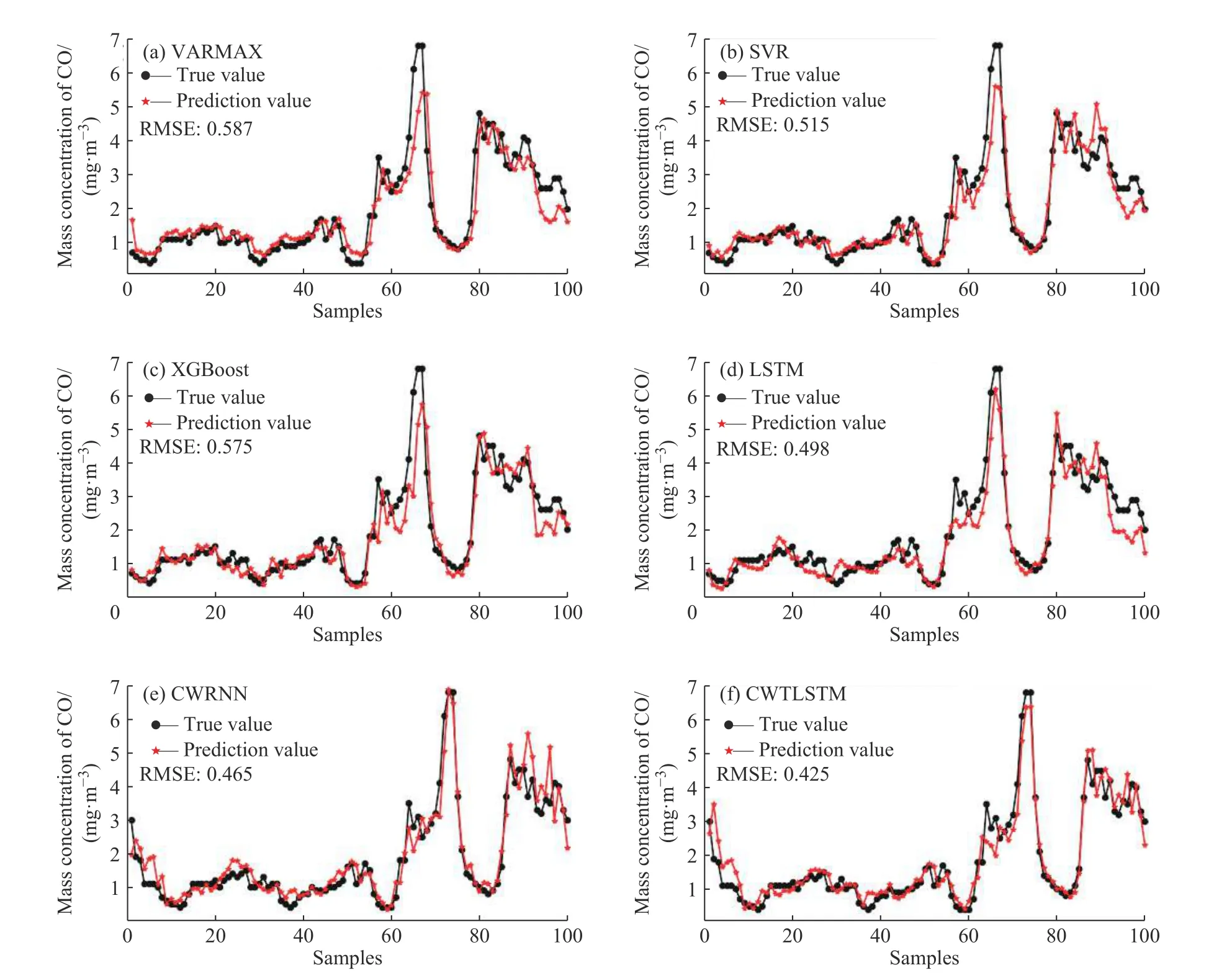
图5 空气污染结果对比 (Time step=48)Fig.5 Comparison of air pollution results(Time step=48)
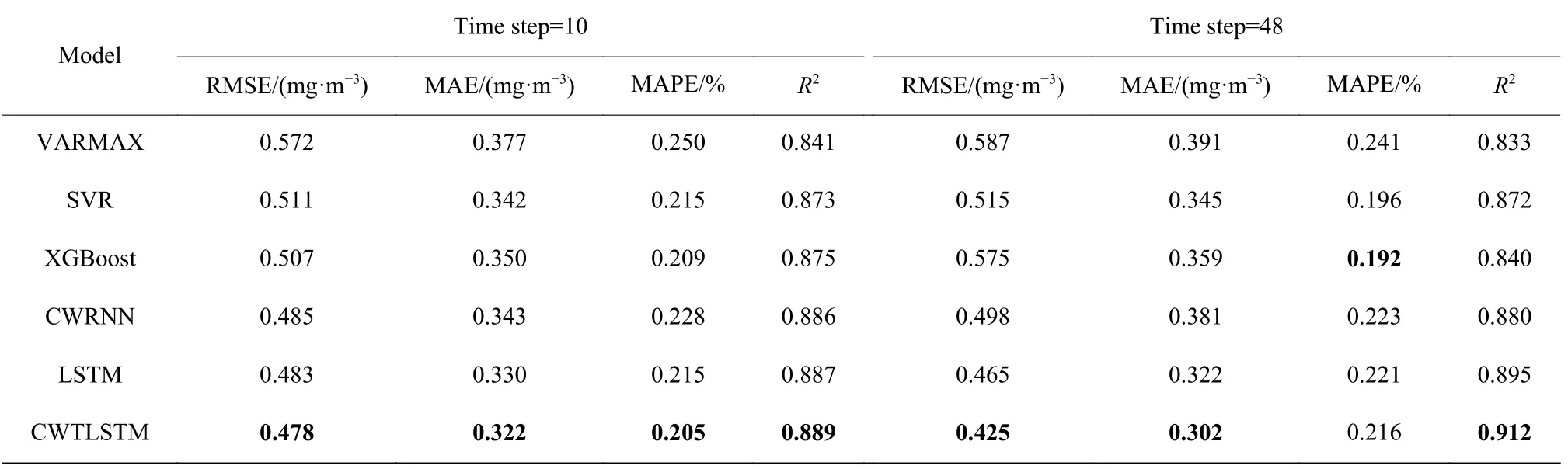
表1 空气污染数据集上各模型的预测结果对比Table 1 Comparison of prediction results of various models on the air pollution dataset
比较时间步长为10、48 条件下的预测结果,使用长时间序列预测的结果普遍较好,一定程度上证明空气污染数据集合具有长期信息的依赖性。CWTLSTM 在能够快速响应数据变化的同时,也能充分利用整个时间步长上的数据,使得预测性能有所提升。
3.3 水泥篦冷机数据集
篦冷机在水泥生产中占有相当重要的地位,其热分布是评价水泥生产的能量利用效率重要指标。Geng 等[39]通过对某水泥厂炉排冷却器的热量分布计算,计算出了篦冷机换热系统中二次风、三次风、熟料排出热和表面散热分别占系统总热量的50%、40%、9%和1%,回收热量具有重要的商业价值。
篦冷机数据集记录了某水泥生产工厂篦冷机在换热过程中的实际数据,采样频率为1 min,总计54 个状态观测变量与操作变量,如二次风温度、三次风温度、多个位置的风机频率、一二级活动篦床篦速、生料流量等。目标预测变量为二次风温度,是衡量水泥生产中废热回收率的主要指标[40]。
将篦冷机数据集按照0.6∶0.2∶0.2 的比例划分为训练集、验证集、预测集,图6 示出了训练集、验证集、预测集在200 个采样时间步长(200 min)的原始数据曲线和ACF 曲线。观测二次风温度的ACF曲线,可得该预测指标没有显著的周期特性。以自相关函数值大于0.3 为标准,当时间步长约小于50 时,该预测序列在所有数据子集均具有较高的数据相关性(且验证集与预测集的ACF 曲线在时间步长为50 时有明显拐点)。在各数据子集中,该预测序列在时间步长约20 以内的自相关函数值均大于0.5,因此在模型比对实验中分别取时间步长20 与50 作为建模时间步长,以验证CWTLSTM 的鲁棒性及抗噪声能力。其他参数设置为:batch 为128,epochs为200,分频序列为[1,2,3],将总计14 000 条记录进行最大、最小归一化处理。
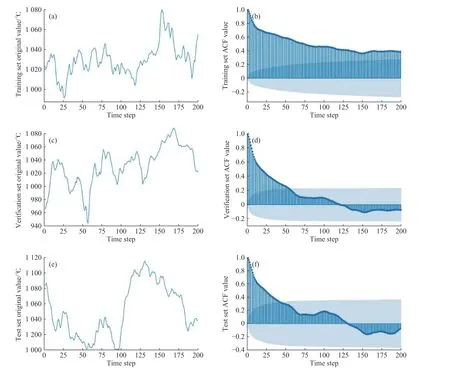
图6 二次风温度原始数据曲线与ACF 曲线Fig.6 Original data curves and ACF curves of secondary air temperature
设置XGboost 的最大树深度为30,弱估计器的数量(树的个数)为150;SVR 的参数为高斯核函数,惩罚系数C 为0.9,核参数gamma 为0.5;LSTM、CWRNN、CWTLSTM 均设置96 个神经单元加一层单个神经元的全连接层。
各模型对二次风温度的预测结果见表2,表中加粗部分表示最优指标(取自多次调参后的最优结果)。前100 个样本的预测结果如图7 所示。
从表2 可知,当时间步长为20、50 时,CWTLSTM的RMSE、MAE、MAPE、R2均最优。从图7 可以看出,VARMAX 的预测差异较大;SVR 有明显的数据滞后;XGBoost、LSTM 与CWRNN 在波峰处的跟随效果较差;CWTLSTM 在跟踪和数据误差上都有不错的表现。
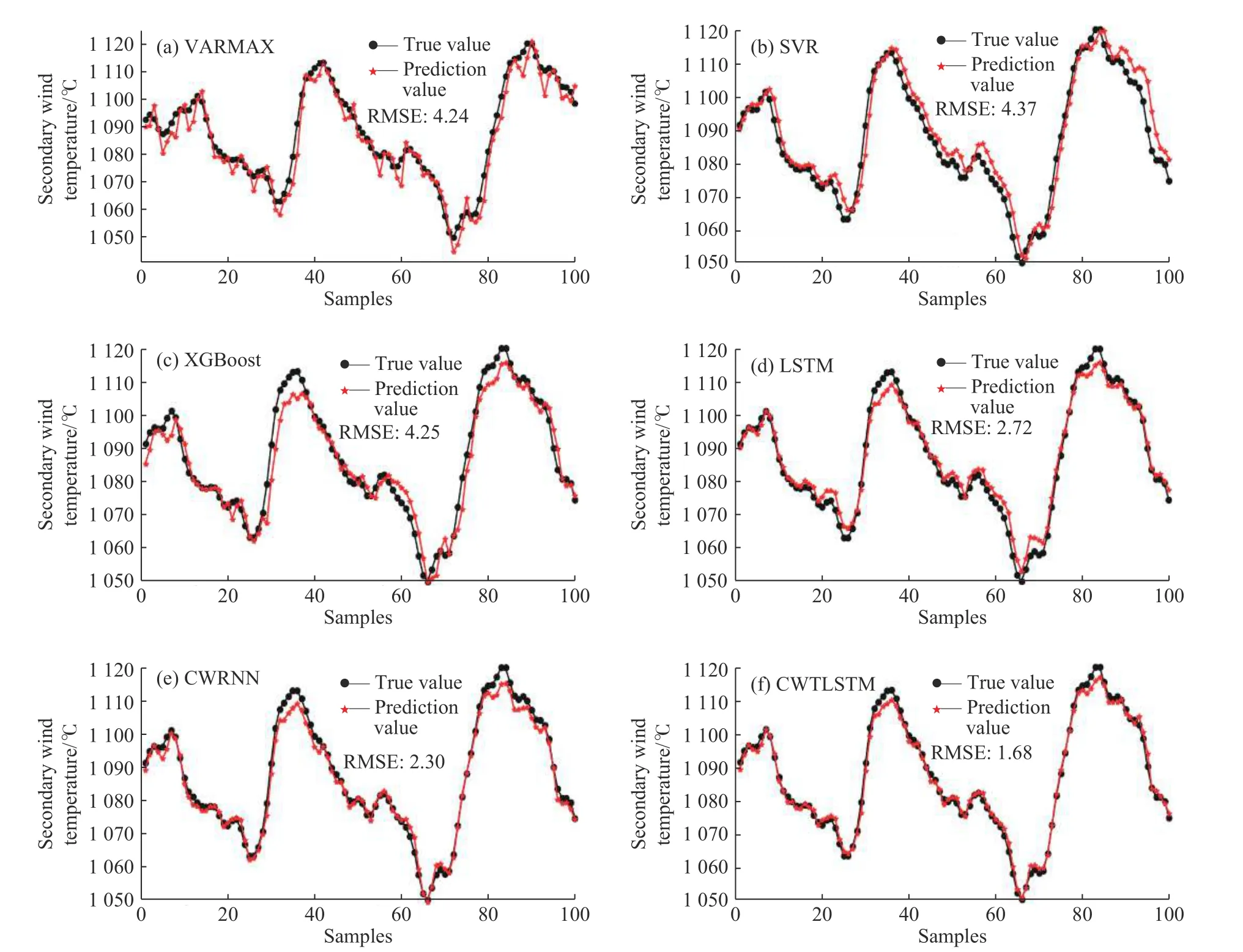
图7 二次风温度预测结果对比(Time step=50)Fig.7 Comparison of prediction results of secondary air temperature(Time step=50)
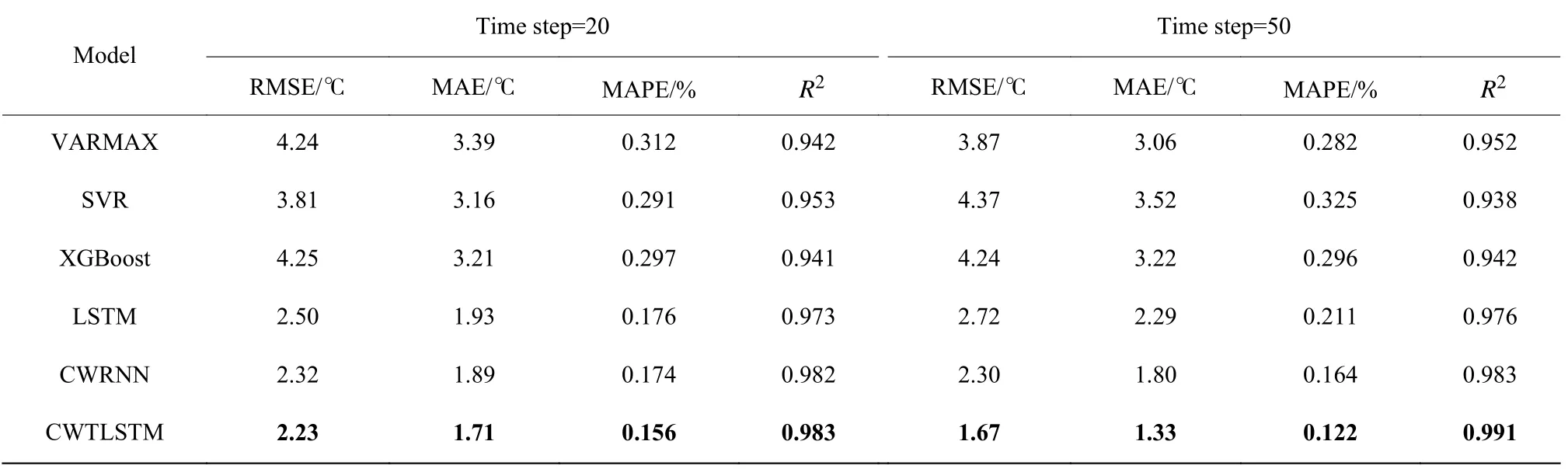
表2 二次风温度预测结果对比Table 2 Comparison of prediction results of secondary air temperature
3.4 结果分析
由图4 与图6 可知,空气污染数据集与篦冷机温度数据集的共通性在于目标变量的短期自相关性较高,但更长时间跨度的数据也能具备参考价值,因此,CWTLSTM 接受长输入时的预测结果比短时间步输入效果更好。同时CWTLSTM 的预测值对真实值波动的跟随性能较好,表明CWTLSTM 既可以有效挖掘长期序列的信息特征,也具备增强短期信息的采样优势,可以快速响应驱动变量的突变。
图8 为不同时间步长下各模型对二次风温度的预测RMSE 结果(每个时间步条件下取10 次实验结果的均值)。当时间步长大于25 后,各个多元时序模型的指标数据基本维持不变,该数据集中,短期数据即可完成精确有效的预测结果;面对时间步较长的输入时,长期记忆能力较差的CWRNN 影响较小,而LSTM 的效果较差,一定程度证明过多的长期数据(无用的历史工况)对于模型可能会起到干扰的作用。当CWTLSTM 接受长期输入时,既可以充分利用长期数据信息,也能适应短期数据变化对结果的影响,从结果上初步证明该模型能保持长短期数据的平衡。
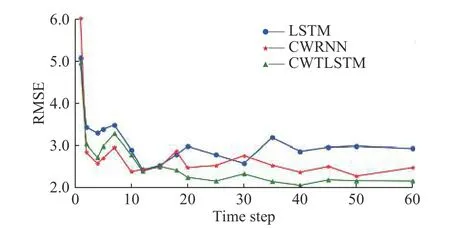
图8 不同时间步长的结果比对Fig.8 Comparison of results of different time step lengths
图9 示出了实际工业数据集中的批次误差结果。由图9(a)可得,训练集上LSTM 训练曲线最好,CWRNN 曲线最差,而CWTLSTM 在稀疏分布矩阵的影响下也未显著降低训练时的精度;在验证集上CWTLSTM 的误差反而小于LSTM 的误差。生产工况的变化与噪声干扰会造成训练集与验证集数据分布的不同,这导致LSTM 网络出现过拟合情况,使得验证精度降低;由于CWTLSTM 里稀疏矩阵的设置,加强了CWTLSTM 的噪声淘汰概率,保证了CWTLSTM的泛化能力。
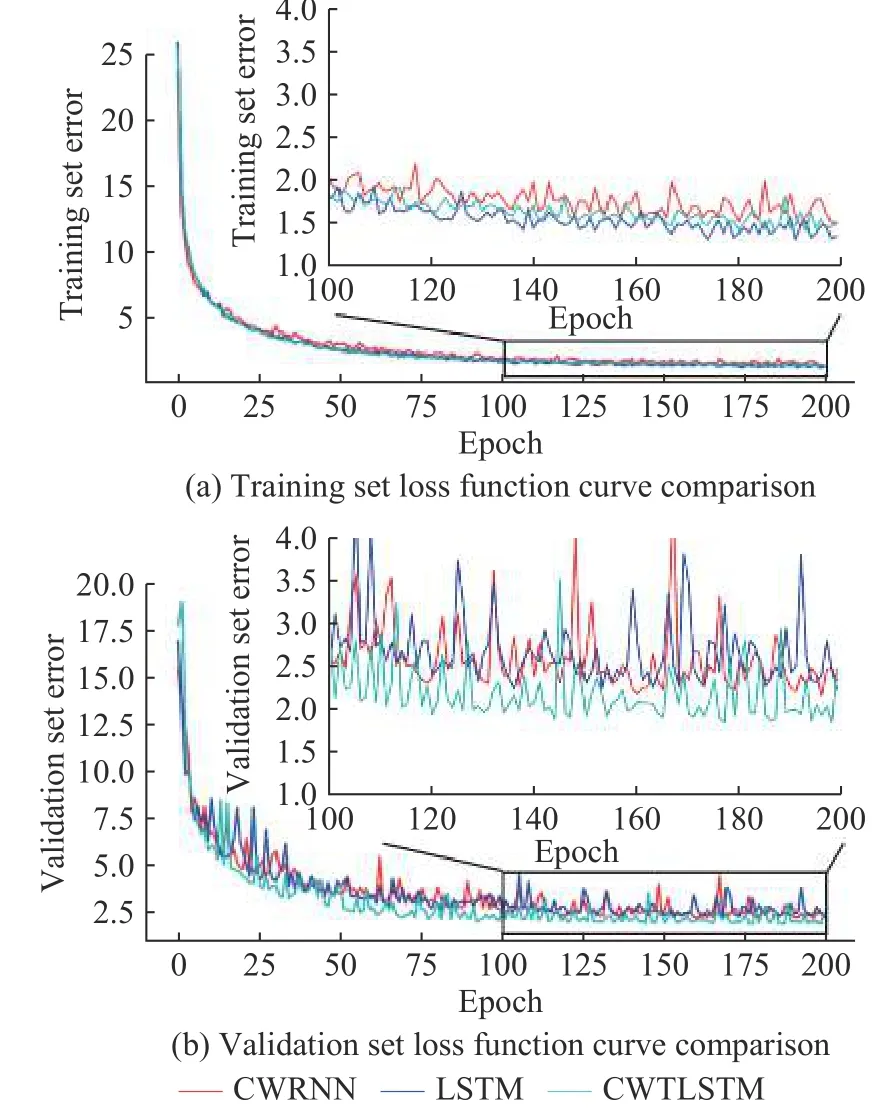
图9 不同批次结果比对Fig.9 Comparison of results of different batches
LSTM、CWRNN、CWTLSTM 在10 次测试下的RMSE 对比如图10 所示。可以看到CWTLSTM 的预测精度明显优于LSTM、CWRNN 模型的预测精度,其最小值和均值均优于其他模型,并且RMSE 数据波动范围较小。初步认为,相较于LSTM 原始结构,CWTLSTM 的分频激活机制能够有效提高模型的预测精度。

图10 多组测试的RMSE 对比Fig.10 RMSE comparison for multiple tests
图11 示出了不同分组频率分配策略对CWRNN、CWTLSTM 的影响,数据为多次实验的平均RMSE结果。CWRNN 与CWTLSTM 受到分频特性影响的趋势基本相同,均对分频策略有一定依赖,但变化幅度不同。CWRNN 波动较小,源自其内部状态数据的自保留性,关注长期信息的存储,在未激活状态下仍然有隐藏层状态进行状态更新,因此分组与分频对其影响较小;CWTLSTM 在未激活时还会更极端地将所有状态置0,对短期信息的依赖较大,因此受分组频率的影响较大。
从图11 的结果看,短期激活更合适CWTLSTM的周期分配,建议在1、2、3 等较小自然数排列中进行选择,如{1,1,1}、{1,1,2}、{1,1,3}、{1,2}等。当某些分组的频率分配过于不合理时,如[1,8]中第二分组每8 个时间步才激活一次,输入增强链的触发次数会导致辅助网络一直缺失,RMSE 数值较大,所以CWTLSTM 应选择较小的激活周期作为输入增强链的周期。
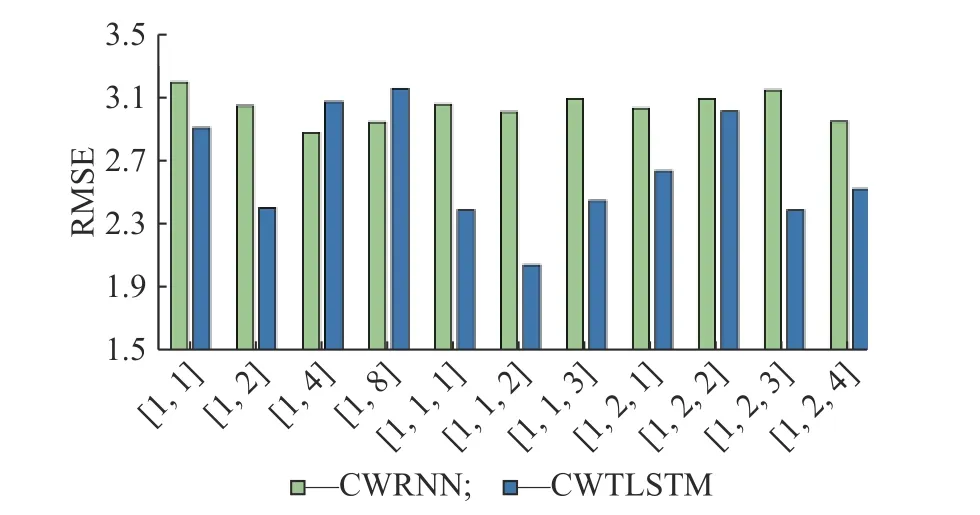
图11 不同分组频率结果对比Fig.11 Comparison of results of different grouping frequencies
周期为1 的单元组占比不能过小,防止主干网络链在整个网络模型中的输出占比不够,影响模型精度。从{1,1,2}、{1,2,1}、{1,2,3}周期排列的对比中看到,周期分组采用从小到大的排序方式,可以减少下方的短期增强链对上方短期增强链的状态值输入,防止中间层的状态权重矩阵Wh数值过大,影响神经元Wx的权重大小,干扰增强输入的功能。其中{1,1,2}周期排列的最底层周期为2 的输入增强链,上一时刻的输出为0,且无其他状态输出能够传递至该神经单元组,其输出完全取决于当前时刻的输入,因此能够更好地发挥短期信息增强的作用。
当分频策略为[1,1]或者[1,1,1]时,由于没有稀疏单元,相当于每个神经元在每个时间步都处于激活状态,无法起到增强短期输入数据的作用,因此比其他分频策略差。区别在于[1,1]将网络化为两个分组,第二分组只能单向传递状态给第一分组;而[1,1,1]具备3 个分组,第三分组单向地传递自身状态至第二与第一分组,第二分组单向传递状态至第一分组。两者之间存在性能差异,证明组间的单向信息流动结构也会对模型的噪声淘汰概率造成影响。实验结果证明,CWTLSTM 的性能受到分组策略的影响,合理分组并设置分组周期对CWTLSTM 模型的性能提升有重要作用。
4 结 论
现有的多元时间序列预测方法无法有效平衡短期突变信息的捕获与长期记忆信息的存储,造成预测结果精确度较低。为解决该问题,本文提出了能够在保持长期信息基础上增强短期信息捕获能力的CWTLSTM 模型。在空气污染公开数据集和水泥篦冷机数据集的实验结果可以证明:
(1)CWTLSTM 模型结构能有效增强近期的数据输入,保证对短期突变信息的敏锐捕获,实现模型在长短期时间序列数据上的计算精度。
(2)在算法层面上的稀疏处理使得CWTLSTM具有一定的鲁棒性和泛化能力,加强对噪声的淘汰概率,使得训练好的模型在不同数据分布下能够稳定预测。
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:48
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:42
小学生导刊(低年级)(2017年1期)2017-06-12 12:07:42
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
