
融合实体信息的图卷积神经网络的短文本分类模型分析
2023-04-29 17:51:59王治学
信息系统工程 2023年9期
关键词:模型
王治学
摘要:基于融合实体信息,建立图卷积神经网络模型,该模型结构分别由类别输出、特征学习、嵌入输入以及实体链接四个模块构成,将其应用于短文本分类,在实际操作中,可以利用实体链接工具对短文本中实体进行抽取,并在图卷积神经网络支持下,进行建模、拼接以及融合处理,最后完成短文本分类。相较于传统文本分类方法,前者不仅可以保证极高的分类准确率,其分类性能也明显优于目前文本分类领域中现有主流方法,对后续自然语言处理更进一步研究有着重要现实意义。
关键词:融合实体信息;图卷积神经网络;短文本分类;模型
一、前言
通过对现阶段传统文本分类方法应用情况的调研与分析,相较于长文本分类,短文本由于具有句子不规则性、数据规模大以及语义稀疏性等特点,致使短文本分类相对困难,且现有模型难以满足短时间高效率准确分类短文本的要求。因此,提出基于融合实体信息的图卷积神经网络模型建立并应用于短文本分类的思路,从后续实验结果来看,这种分类方法在短文本分类方面的性能表现明显优于目前大部分主流方法,不仅准确率高,且能够起到丰富语义表达的作用,使表达精确度得到进一步提高。
二、短文本数据基本特点
现阶段自然语言处理过程中常用短文本分类,能够为舆情分析、对话问答以及情感分析等领域的文本信息处理提供针对性服务,不仅可以提升自然语言处理效率,又能起到极为重要的作用。相较于长文本,若以常规文本分类方法对短文本类型进行划分,整个操作过程具有较大难度,短文本数据基本特点具体表现在以下几个方面:
1.短文本语义呈稀疏性
与长文本不同的是,前者在内容方面并未包含过多单词数量,短文本分类目的是提取其中有用信息,而提取有用信息的前提是要保证短文本中具有实际语义的词语较多,才能将有用信息进行分类,但由于短文本语义呈稀疏性特点,在一定程度上加大了短文本分类难度。
2.数据规模大
网络中有大量短文本数据存在,以人工方式处理数据,既不能满足对数据处理时效性要求,同时也会投入较多成本,降低该项工作经济性。
3.短文本句子呈不规则性
如对话消息、新闻标题以及微博等均属于短文本句子范畴,句子内容与人们日常生活极为贴近,句子表述虽然较为简洁,但整个结构形式偏向口语化,句子内容中经常会出现较多网络热词或流行语,在文本信息处理过程中,难以保证分类器可以对短文本句子精准识别,识别难度较大。
三、基于融合实体信息的图卷积神经网络模型在短文本分类中应用可行性分析
一般情况下,对短文本分类定义,是指将未经过标记的大量文本,对其选择合适标签,其中基于深度学习、图神经网络以及基于统计的方法常应用于文本分类中。
1.基于深度学习的方法在短文本分类中应用。相较于传统文本分类算法,前者近些年在各种先进技术支持下,在该领域取得了显著成果,可以对更复杂文本的特征进行深层次的自动提取,满足端到端处理文本信息需求。卷积神经网络所提出的TextCNN算法,则是在多个卷积核利用基础上,将文本间的局部信息更加精准地捕获;TextRNN算法可以在较长的序列中捕获上下语义关系,但循环神经网络有可能在训练期间发生梯度消失现象,难以做到将长距离序列信息进行学习[1]。
TextCNN算法与TextRNN算法应用的前提均要先完成对每条文本的建模处理,但在该环节极易将语料库的全局特征忽略。针对上文所提出的短文本数据呈语义稀疏性特点,为降低该方面情况对短文本精准分类干扰影响,提出不需要语料库外部支持建立主题记忆网络的一种算法,并应用于文本分类中,通过自动挖掘主题完成文本分类。从整体上看,上述所提及的各类算法,仅能做到对文本局部信息进行建模处理,仍是无法满足文本全局信息重点关注的要求。
2.基于统计的方法在文本分类中应用。目前包含设计工程特征与分类两种形式的算法,前者对需要进行处理的文本数据进行特征提取,并作后续分类器输入词条使用,获取数据特征时,常用词袋模型。分类算法是以梯度提升决策树、支持向量机等模型为基础提出并用于文本分类的算法。针对复杂程度较高的文本特征工程,仍要以人工方式处理数据。海量数据均依靠人工处理,使得整个数据处理过程耗时多。同时,人工处理也会额外增加成本,加上这种传统方法获取的文本均呈现高稀疏性、高维度特点,特征表达能力较差,直接影响短文本分类任务完成质量。
3.通过对目前文本分类中图神经网络应用情况的调研与分析,依赖语料库所提出的异构文本图(TextGCN),其中包含了文档与单词节点,再借助图卷积神经网络模型进行学习,能够将图内相邻节点信息聚合处理,并用于表示文档与单词节点。在应用TextGCN前提下,搭建TensorGCN模型,该模型同样可以使用语料库中所包含的文档和单词节点完成基于语义、句法及序列三种不同形式的异构图建立。相较于TextGCN,TensorGCN可以融合两种传播学习方式,分别是图内信息传播,对单图上相邻节点信息进行聚合;另一种则是图间信息传播,起到对不同类型图的异构信息进行协调作用。基于融合节点及边权值建立图注意力网络,可以满足为各个文本进行同构图建立需求,再借助引力模型对整个语料库所包含单词节点的重要性进行评估,同时在掌握节点间点互信息基础上对边权重获取,进而达到基于图注意力网络分类整图目的。
上述方法在实际应用过程中同样需要语料库支持,利用语料库中包含的信息完成文本图建立,再通过全局信息对文本表示强化处理,该过程不会涉及使用外部信息扩充文本操作以达到降低短文本稀疏性影响目的。
结合以上内容,提出基于融合实体信息的图卷积神经网络模型建立,镜文档中单词对应实体通过实体链接引入,该单词链接则是实体置信度,作为文档和实体之间边的权重,同时基于文档、实体、单词三种节点建立异构图[2]。通过图卷积神经网络进行传播学习,可以向文档节点和单词节点传递实体信息,使节点特征能够被更加准确地表示,实体节点被引入后,除了可以对短文本起到扩充作用以外,又能对文本单词进行消歧处理,实现短文本特征空间稀疏性影响被有效降低。
四、基于融合实体信息的图卷积神经网络模型建立与分类性能验证
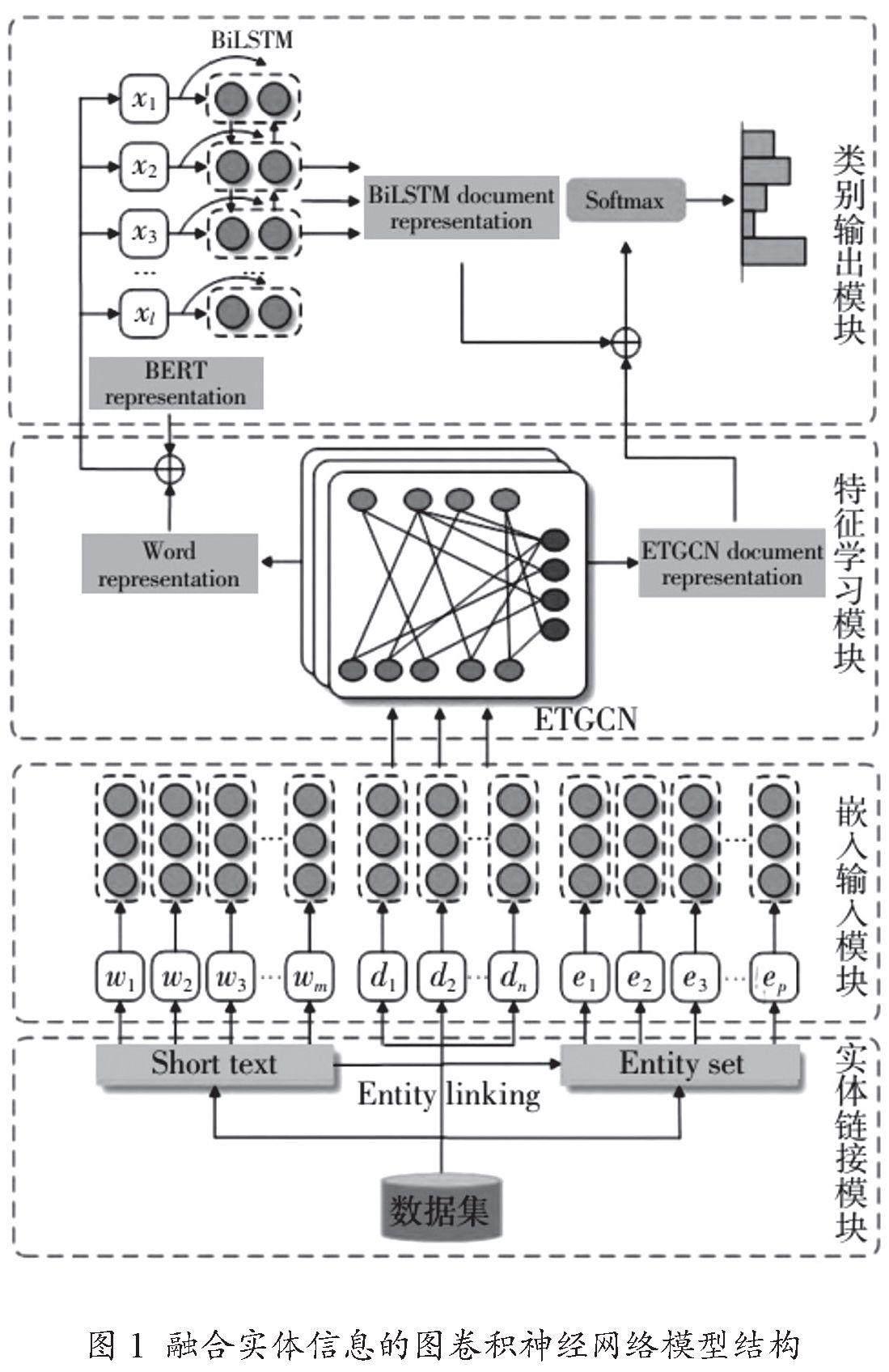
(一)融合实体信息的图卷积神经网络模型结构
如图1所示,融合实体信息的图卷积神经网络模型分别由类别输出、特征学习、嵌入输入以及实体链接四个模块共同构成。该模型结构中各模块功能作用如下:
1.实体链接模块
依靠实体链接工具,在维基百科实体上映射短文本中的单词。在该模块中,可以将短文本中词语概念歧义、标注问题等进行有效解决,并对原短文本内容扩充处理,起到丰富短文本表达的作用。在使用实体链接工具基础上,在维基百科实体上映射单词,再通过外部知识库,扩充短文本的单词概念。融合实体信息的图卷积神经网络模型结构参考图1。
2.嵌入输入模块
根据具体要求,对文档、实体以及单词进行嵌入处理,再分别映射到高维向量空间。下游自然语言处理任务对应表征,常用词嵌入表达,以数字形式将短文中词汇语义进行捕获,满足对过于抽象语义概念准确处理的需求,该方式被广泛应用于文本信息处理领域,如文本分类、知识挖掘以及问答系统等。现阶段文本分类中较为常用Word2Vec与Glove这两种词嵌入方式,前者对单词语义进行捕获时,需要通过包含局部上下文信息的滑动窗口,对单词间存在的相关性深度挖掘,获得单词表示;后者对单词的全局语义信息进行捕获时,则是要借助全局词共现矩阵,以完成单词的嵌入向量表示。
在高维向量空间映射单词、实体及文档时,要先将图卷积神经网络节点输入特征构成,以随机初始化特征进行单词嵌入,以预训练的维基百科实体特征作为实体节点嵌入;而文档节点,则是要将文档中所有单词的预训练词嵌入平均值进行计算,最终得到数值,即为表示文档输入特征。
3.特征学习模块
基于异构图卷积神经网络训练输入的嵌入特征,经过训练学习后,即可获得文档特征和单词特征表示。因短文本自身特殊性,仅从语料库中获取信息,无法保证可以获得足量具有实际语义的词语。基于此,本文提出在对外部实体信息加以利用的基础上,建立3种不同形式异构图{G=(ν,ε)},分别是单词节点:W={w1,w2,…,wm};文档节点:D={d1,d2,…,dn};实体节点:点E={e1,e2,…,ep};v=D∪E∪W[3]。节点间关系用ε边集中元素进行表示,文档中单词频率确定连接文档节点与单词节点的边数量,换句话说,是将词频—逆文档频率看作文档节点与单词节点之间边的权重,再由语料库中词共现信息确定连接2个单词节点的边。维基百科实体上映射文档中单词所对应置信度确定连接文档节点和实体节点的边。
4.类别输出模块
在该模型结构中负责融合特征学习模块学习的单词特征表示与BERT预训练获得的词嵌入特征,再利用BiLSTM对文本上下文特征捕获,拼接分别得到的隐藏状态特征与特征学习模块中的文本特征,线性变换后,即可确定短文本所属类别。在该模块中,需要对短文本中词序特点进行综合考虑,词序是影响短文本分类准确性关键要素之一,将图卷积神经网络学习达到的文档节点和单词节点表示,借助BiLSTM模型对其分类进行细化,目的是通过提高模型精度达到对短文本类别精准预测目的。
其中BERT预训练模型可以将包含上下文语义信息的词嵌入有效生成,此时拼接处理从特征学习模块所获得单词节点表示与BERT预训练的单词节点表示,拼接完成后,将作为BiLSTM的输入。拼接BiLSTM输出的节点隐藏状态和GCN学习获得文档节点特征,其通过softmax后,即可获得文本预测标签。再以交叉熵损失方式训练最终的分类结果,训练所得即是短文本对应的真实标签[4]。
(二)融合实体信息的图卷积神经网络模型分类性能实验结果
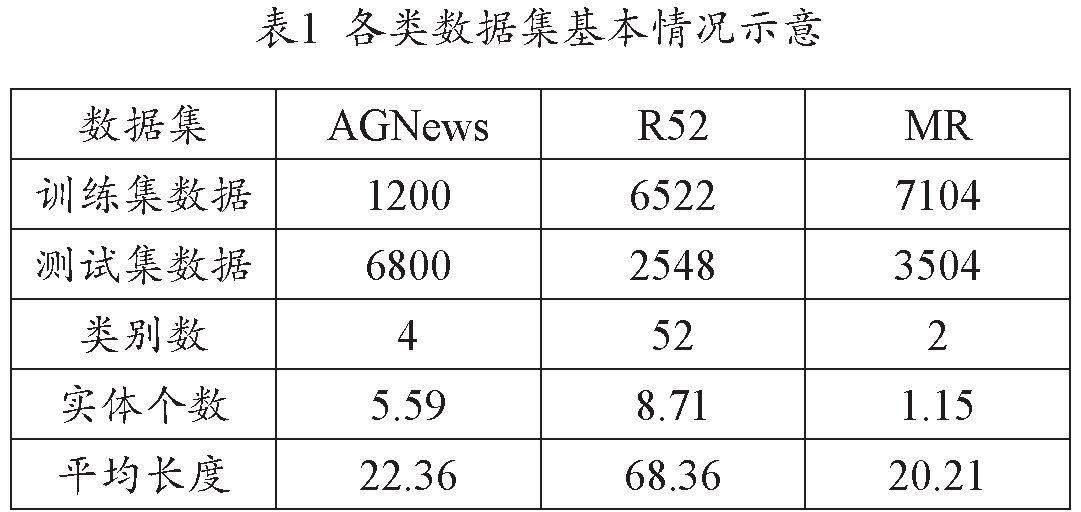
1.为更进一步验证本文所提出融合实体信息的图卷积神经网络模型在分类性能方面所表现出的效果,将选用3个短文本基线数据集,用作分类性能实验研究对象,分别是AGNews、R52及MR。其中AGNews由4个类别的英文新闻数据集组成,不同类别数据集均包含上万条训练样本以及约2000条测试样本,随机从不同类别数据集中抽取任意300条数据,并标记训练集,1700条数据标记测试集。R52由52个类别数据集组成,训练样本超过6500条,测试样本超过2500条。MR则是电影评论中二分类情感数据集,包含正负面评论语,总计超过10000条,训练集约7000条,测试集约3500条。
使用NLTK库将AGNews与R52数据集中的停用词进行去除,出现频率不超过5次的词均要全部去除;因MR数据集中文本略短,可以省去停用词或低频词去除环节。各类数据集基本情况示意参考表1。
2.参数设置:基于PyTorch框架应用,在训练和测试环节,将词嵌入维度调整至150,学习率设置为0.001。利用Adam完成随机梯度优化,检测经过200次迭代处理后的数据集,其模型性能是否达到预期效果,模型性能保持10次以上无任何变化时,即可提前结束训练。
3.从实验结果来看,发现AGNews与R52数据集上所反映出的模型性能表现均优于传统模型。该情况出现原因与图结构满足不同类型相邻节点间信息相互传递要求有着直接关系,通过将节点上信息进行聚合处理,实现以更丰富信息表示对应特征。使用单词间的词共现特征为边的权重时,可用全局共享方式,且优于传统模型的局部信息共享[5]。
分析MR数据集,TextGCN模型准确率未超过CNN和BiLSTM模型,该情况出现与TextGCN模型没有考虑情感分类中词序所产生影响相关,后者在实际操作过程中均完成了连续词序列构建。相较于其他数据集,前者因文本太短,所构成的文本图并不大,进而对节点间信息传递产生一定制约。
AGNews、R52、MR数据集在ETGCN模型中均反映出较高准确率,准确率明显高于其他模型,虽然R52数据集在ETGCN模型中的准确率低于其他2个数据集,但其准确率与TenserGCN模型相近,R52数据集的准确率略低表现与自身文本长度较长有关,将句法特征引入TenserGCN模型后,可以使该模型对文本较长数据集的适用性进一步提升。
4.综合所有模型准确率平均值,其中ETGCN模型分类性能显著增强,在实际应用过程中,能够将文本中单词对应实体信息融入异构图中,再通过图卷积神经网络向相邻文档节点和单词节点传递实体信息,起到对文档节点和单词节点语义表达进行丰富的作用。引入实体信息后,也使单词本身所存在的二义性问题所产生影响得到有效缓解,极大地提高了语义表达的精确度。经过BiLSTM模型处理后单词节点和文档节点特征表示,可以将文档的上下文语义信息更加准确地捕获,以强化短文本分类效果,特别是在情感短文本分类方面有着出色表现。
5.在维持上述其他参数不变前提下,仅调整词嵌入维度,词嵌入维度调整至150时,ETGCN模型的分类准确率最高,词嵌入维度调整至50时,ETGCN模型的分类准确率最低,准确率由低向高排序:150>100>200>250>300>50。说明词嵌入维度调整过高,不会对模型分类性能起到提升效果;嵌入维度调整过低,则会限制图内节点信息传播。
五、结语
综上所述,基于融合实体信息的图卷积神经网络模型建立,并将其应用于短文本分类中,相较于常规文本分类方法,前者在模型分类性能方面明显优于现阶段文本分类中所应用的已有模型,不仅具有极高准确率,其中外部实体信息引入,对文档和单词节点语义表达起到一定丰富作用,也解决了单词所存在的二义性问题,进一步提高了语义表达精确度,尤其是依赖语序进行文本分类方面,有着明显的应用效果,从而打破传统文本分类方法对短文本分类难度大的困境。
参考文献
[1]李文静,白静,彭斌.图卷积神经网络及其在图像识别领域的应用综述[J/OL].计算机工程与应用:1-25[2023-05-25].
[2]王永贵,邹赫宇.多任务联合学习的图卷积神经网络推荐[J/OL].计算机工程与应用:1-9[2023-05-25].
[3]孙隽姝,王树徽,杨晨雪.附加特征图增强的图卷积神经网络[J/OL].计算机学报:1-20[2023-05-25].
[4]王佳宇,李楹,马春梅.融合实体信息的图卷积神经网络的短文本分类模型[J].天津师范大学学报(自然科学版),2023,43(01):67-72.
[5]李享.基于图卷积神经网络的文本表示与文本分类研究[D].北京:北京交通大学,2022.
猜你喜欢
童话王国·奇妙逻辑推理(2024年5期)2024-06-19 16:03:38
网络安全与数据管理(2022年1期)2022-08-29 03:15:20
导航定位学报(2022年4期)2022-08-15 08:27:00
中学生数理化·中考版(2022年8期)2022-06-14 06:55:24
新世纪智能(数学备考)(2021年9期)2021-11-24 01:14:36
成都医学院学报(2021年2期)2021-07-19 08:35:14
新世纪智能(数学备考)(2020年9期)2021-01-04 00:25:14
中学生数理化·七年级数学人教版(2020年10期)2020-11-26 08:24:50
数学物理学报(2020年2期)2020-06-02 11:29:24
光学精密工程(2016年6期)2016-11-07 09:07:19
