
基于事实和语义一致性的生成文本检测
2023-04-29 19:46:50董腾飞杨频徐宇代金鞘贾鹏
四川大学学报(自然科学版) 2023年4期
董腾飞 杨频 徐宇 代金鞘 贾鹏


摘 要 :文本生成技术的恶意滥用问题日益严重,因此生成文本检测技术至关重要. 现有的检测方法依赖于基于特定数据集的统计异常特征,从而导致方法的泛化能力较差. 本文考虑不同种类生成文本均易出现的事实错误、语义冲突问题,提出了一种基于事实和语义一致性的生成文本检测方法. 该方法通过实体将文本和外部知识库进行比较,得到文本的事实一致性特征. 另一方面,该方法借助文本蕴含技术对文本上文与下文进行关系推理,得到文本的语义一致性特征. 最后将这两类特征与RoBERTa的输出隐藏向量拼接,输入到线性分类层进行预测. 实验结果表明,该方法比当前的检测方法具有更高的准确率和泛化能力.
关键词 :文本生成; 生成文本检测; 外部知识库; 文本蕴含
中图分类号 : TP391.1 文献标识码 :A DOI : 10.19907/j.0490-6756.2023.042002
Generated text detection based on factual and semantic consistency
DONG Teng-Fei, YANG Pin, XU Yu, DAI Jin-Qiao, JIA Peng
(College of Cyber Science and Engineering, Sichuan University, Chengdu 610065, China)
The malicious abuse of the text generation technology has becoming more and more serious, which makes the detection for generated text considerably important. The existing detection methods mainly rely on statistical anomalous features based on the specific dataset, which leads to the poor generalization ability. Considering the common problems of factual errors and semantic conflicts in the generated text, this paper proposes a generated text detection method based on the factual and semantic consistency. By using the text entity, the proposed method compares the text with the external knowledge base to obtain the factual consistency feature of the text. On the other hand, the text entailment technology is used to infer the semantic relationship between the text above and below to obtain the semantic consistency feature of the text. Finally, the above two types of features are spliced with RoBERTa output hidden vector and input to the linear classification layer for prediction. The experimental results show that the proposed method has higher accuracy and generalization ability than the existing detection methods.
Text generation; Generated text detection; External knowledge base; Textual entailment
1 引 言
文本生成技术是自然语言处理的核心技术之一. 它使用既定信息和文本生成模型(Text Generative Model, TGM),生成满足特定目标的文本. 文本生成技术有诸多正面应用,比如故事生成 [1]、会话响应生成 [2]、代码自动完成 [3]和放射学报告生成 [4]等. 但不幸的是,该技术被非法者恶意滥用于生成神经假新闻 [5-7]、虚假产品评论 [8]和垃圾邮件 [9]. 这些虚假信息通过互联网广泛传播,会对国家、社会和个人造成不利的影响. 同时文本生成技术仿真化发展,极大降低了人工检测的可能性. 而生成文本检测技术能够有效区分生成文本和人工文本. 因此,生成文本检测技术具有极高的研究价值.
目前较好的生成文本检测方法主要是基于机器学习和深度学习模型 [10-12]. 这些检测方法通常使用统计异常证据进行检测,例如通过神经网络学习到的密集向量和传统特征(TF-IDF、单词计数、段落平均长度). 但这些证据往往只是基于特定数据集的特征,导致方法的泛化能力较差. 解决该问题的关键,在于使用更加通用生成文本的特征. 目前一些研究表明,生成文本易出现事实错误 [13,14]和语义冲突问题 [15]. 事实错误为文本中的知识和事实知识不一致. 现有文本生成模型并不能很好地兼顾生成文本的丰富性和事实性,内容丰富的文本往往存在事实错误问题. 语义冲突为文本上文和下文的语义不一致. 文本生成模型生成的低频词会使文本出现语义偏差,当这种偏差持续累积会让文本上文和下文出现语义冲突问题. 这两类问题是由于文本生成技术不足导致的生成文本缺陷,相较于统计异常特征更具有代表性. 在Jawahar等人 [16]的实验中,基线检测模型RoBERTa超过10%的假阳性样本存在事实错误、语义冲突. 实验结果反应了RoBERTa无法较好地提取文本中这两类深层次特征.
基于上述分析,本文在基线检测模型RoBERTa上进行改进,提出了一种基于事实和语义一致性的生成文本检测方法ConsistNet. 对于给定的文本,使用RoBERTa对文本进行编码,得到文本基于内容的单词表示. 接着对单词表示算术平均,计算出实体基于内容的实体表示. 使用实体链接工具Tagme标注出文本中的实体,并从维基百科知识库获取对应的维基百科描述. 使用BiLSTM编码实体的维基百科描述,得到实体基于维基百科的实体表示. 之后将每个实体的两类表示输入到实体比较网络,得到文本的事实一致性特征. 此外,待检测文本被分割成上文、下文两部分. 使用训练好的文本蕴含模型推理这两部分文本,将推理结果作为文本的语义一致性特征. 最后将两类一致性特征与RoBERTa的输出隐藏向量拼接,输入到线性分类层进行预测. 本文在多个公开数据集上进行实验,实验结果表明提出方法ConsistNet的准确率以及泛化能力要优于目前主流的检测方法.
本文的主要贡献如下:(1) 提出了事实一致性和语义一致性的特征提取方式. 事实一致性特征提取需要引入外部知识库作为真实知识. 以实体为桥梁比较文本知识和外部知识,得到文本的事实一致性特征. 语义一致性特征提取使用了文本蕴含技术. 通过文本蕴含模型推理文本上文与下文的语义逻辑关系,得到文本的语义一致性特征. (2) 提出了一种生成文本检测方法ConsistNet. 该方法细致地提取出文本的两类一致性特征,和检测模型RoBERTa的输出隐藏向量进行特征拼接,最后输入到线性分类层进行预测.(3)在News-style和Webtext-style数据集上的实验结果表明,提出方法ConsistNet较其他检测方法具有更高的检测准确率. 在Grover数据集上的实验结果表明,提出方法ConsistNet较其他检测方法具有更好的泛化能力.
2 相关工作
现有的自动化生成文本检测方法可以分为三类:基于概率规则的检测方法,基于机器学习的检测方法和基于深度学习的检测方法.
2.1 基于概率规则的检测方法
基于概率规则的检测方法采用TGM输出文本单词的分布概率作为检测依据,不需要样本进行训练. Solaiman等人 [10]使用TGM计算文本的总对数概率,依此来判断文本是否为生成文本. 比如,根据GPT-2模型计算出文本的总对数概率,如果该概率更接近于所有生成文本上的平均似然,则判定该文本为生成文本. Gehrmann等人 [17]设计了一个统计工具GLTR,可以突出显示生成文本和人工文本的分布差异. GLTR统计了待检测文本中高概率、中概率和低概率词数目,将结果可视化展示以辅助人类进行判断. 基于概率规则的检测方法不需要样本进行训练,但检测效果不如其他两类方法 [18].
2.2 基于机器学习的检测方法
基于机器学习的检测方法采用经典的机器学习模型,基于生成文本检测任务从头开始训练模型参数. 此类方法具有较少的参数,并且易于部署. Solaiman等人 [10]提出了一种基于TF-IDF特征的逻辑回归分类器,在较小TGM基于Top-K采样策略的生成文本上具有较好的识别能力. Badaskar等人 [19]训练了一个SVM分类器,使用高级特征来模拟文本的经验、句法和语义. 不过他们的实验仅限于已经过时的三元组语言模型. 之后Fr hling等人 [20]就当前的语言模型扩展了该工作. 根据生成文本存在的缺陷,Fr hling等人提出了五类特征,基于简单的分类模型进行检测. 该方法的优点在于模型简单,检测效果却可以逼近庞大的基于深度学习的检测方法.
2.3 基于深度学习的检测方法
基于深度学习的检测方法采用深层次神经网络作为检测模型. Jawahar等人 [21]采用了一个基于三层LSTM的PARSEQ作为检测模型,利用段落间的一致性进行分类预测. 相较于传统的神经网络CNN和RNN,Transformer的特征抽取能力更强,因此基于Transformer架构的检测模型检测效果更好. 比如Zellers等人 [12]设计了一个基于Transformer架构的GROVER模型,该模型的检测效果超越了FastText [22]等模型. 此外,基于多层Transformer编码器叠加的RoBERTa模型在该检测任务中表现更加突出. 一些研究表明 [7,8],RoBERTa检测器在多个生成文本数据集上表现优异,检测效果优于其他检测器.
不过,RoBERTa检测器无法识别生成文本中存在的很多事实错误、语义冲突问题 [16],反应了RoBERTa检测器不能较好地挖掘出事实和语义一致性特征. 基于这种考虑,本文在RoBERTa模型的基础上进行改良,设计了一个基于事实和语义一致性的检测方法ConsistNet. ConsistNet会细致地抽取文本中的事实和语义一致性特征,用于指导生成文本分类判断.
3 提出方法
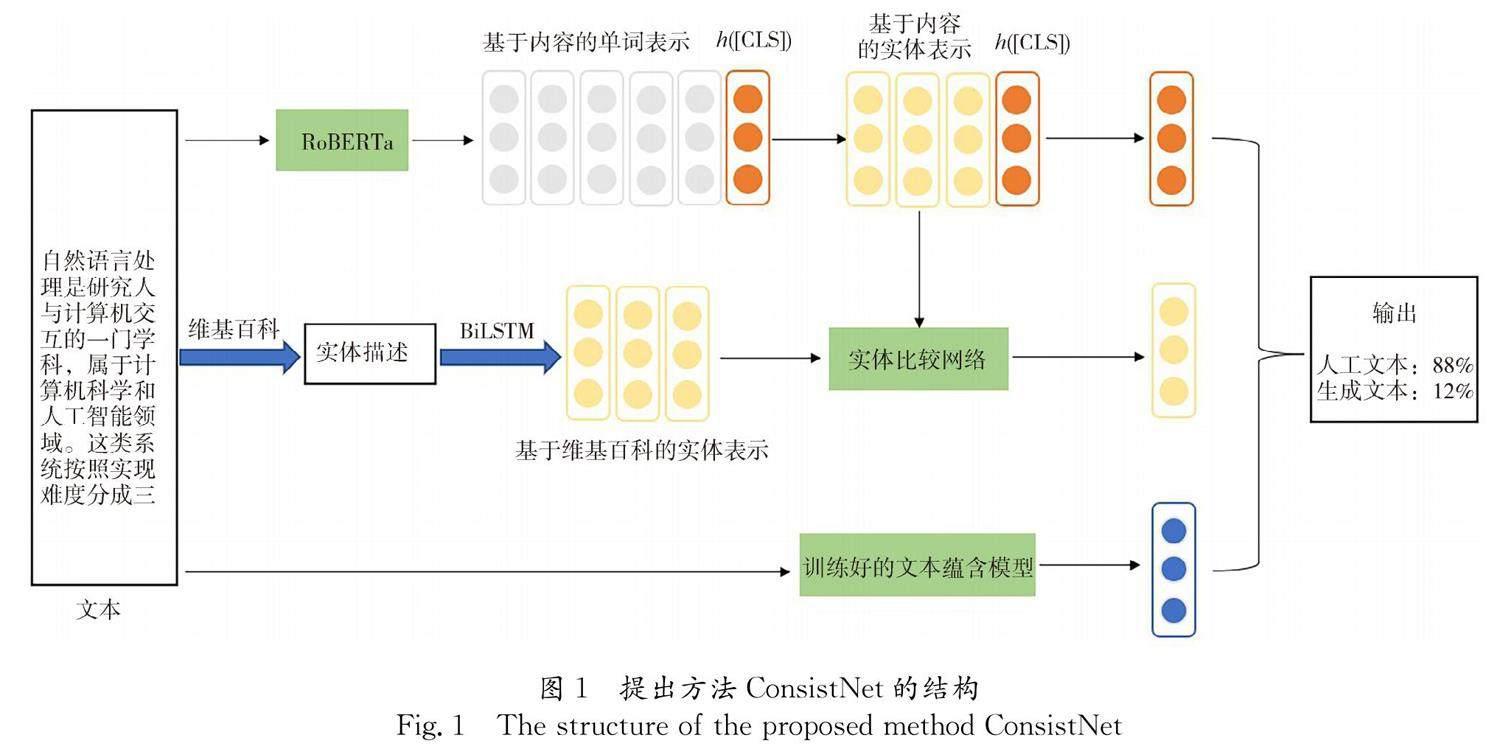
本节详细地介绍了本文提出的检测方法ConsistNet. 该方法提取文本中存在的事实一致性、语义一致性特征,结合基础分类模型进行最终的预测.图1给出了提出方法ConsistNet的整体结构.
图1中对于给定的文本,使用RoBERTa得到文本基于内容的单词表示. 根据单词表示计算出实体基于内容的实体表示. 使用Tagme工具标注出文本存在的实体,从维基百科知识库得到实体的维基百科描述,然后用BiLSTM计算出实体基于维基百科的实体表示. 得到两种类型的实体表示后,将它们输入到实体比较网络,得到事实一致性特征. 另外将文本分割成两部分,上文部分和下文部分. 将这两部分文本输入到训练好的文本蕴含模型. 文本蕴含模型输出这两部分文本的推理结果,将其作为语义一致性特征. 最后将RoBERTa的输出隐藏向量、事实一致性特征、语义一致性特征输入到线性分类层,进行最终的分类预测.
ConsistNet结构由以下三部分组成:基础分类模型RoBERTa,事实一致性特征提取模块,语义一致性特征提取模块. 下文将详细地介绍这三部分以及模型训练过程.
3.1 基础分类模型RoBERTa
RoBERTa是由Facebook提出的基于Transformer的预训练模型,它在多个自然语言处理任务中达到SOTA的效果 [23]. RoBERTa为ConsistNet的基础分类模型. 它提供整个文本的语义表示,用于分类判断. 具体而言,模型在文本前插入一个[CLS]符号. 该符号在ROBERTa最后一层的输出隐藏向量 h [CLS]包含了文本的语义表示,用于指导最终的分类预测.
此外,RoBERTa同时作为词嵌入工具,得到每个单词基于内容的语义表示. 以文本 x 作为输入,RoBERTa将其映射为长度| x |的隐藏向量序列.
h(x)=[h (x) 1,h (x) 2,…,h (x) x ] (1)
其中,每个 h ( x ) i 为第 i 个单词基于内容的单词表示. 在事实一致性特征提取模块中,这些单词表示将用于计算每个实体基于内容的实体表示.
3.2 事实一致性特征提取模块
本节介绍如何从文本中提取事实一致性特征. 实体为客观存在并可相互区别的事物,主要包括人名、地名、机构名和专有名称. 实体作为文本内容的主体,可视为文本知识的载体,因此以实体为桥梁来比较文本知识和事实知识. RoBERTa对文本进行词嵌入后,可以计算实体基于内容的实体表示,作为实体的文本知识. 而实体在维基百科上的描述,作为该实体的事实知识. 最后将实体这两部分知识输入到实体比较网络,可以获取文本的事实一致性特征.
3.2.1 基于内容的实体表示 实体是由一系列连续的单词组成,所以通过基于内容的单词表示 h ( x )计算每个实体基于内容的实体表示. 假设实体 e 由 n 个单词组成,则实体基于内容的实体表示 E c 的计算公式为
E c= 1 n ∑ n i=1 h (x) e i (2)
其中, e i 为实体 e 中第 i 个单词在文本中的绝对位置.
3.2.2 基于维基百科的实体表示 使用实体链接工具TAGME识别文本中存在的实体,并获取实体的维基百科链接. 根据该链接,从维基百科知识库得到实体对应的维基百科描述. 然后使用BiLSTM编码实体的维基百科描述,得到该实体基于维基百科的实体表示. 对于实体 e ,它的维基百科描述为 e k b ,则它基于维基百科的实体表示 E k b 为:
E k b=BiLSTM(e k b) (3)
R N ×2 N 是一个变换矩阵;⊙为哈达玛积. 通过实体比较网络,可以得到文本所有实体 E ={ e 1, e 2,…, e n }的事实一致性特征 FC =[ v 1, v 2,…, v n ].
3.3 语义一致性特征提取模块
本节介绍如何从文本中提取语义一致性特征. 文本蕴含技术可以推理两个文本间的语义逻辑关系,判断两文本的语义是否一致. 因此,本文采用文本蕴含技术推理文本上文和下文的语义逻辑关系,提取文本的语义一致性特征.
对于文本 x ,将其分割为文本上文 x above和文本下文 x below. 采用的分割方式为首句分割. 通过该分割方式, x above为文本的第一句, x below为文本的剩余部分. 如此分割的原因为:文本的第一句话通常为标题或主旨句,具有文本主旨的简练信息;而剩余部分为文本的主体,具有文本主旨的具体信息. 对于人工文本,这两部分文本的语义本质是一样的;而对于生成文本,这两部分文本的语义会出现分歧. 通过训练好的文本蕴含模型,推理两文本的语义逻辑关系,输出推理隐藏向量 v entail.
v entail =TEModel(x above ,x below ) (6)
其中, TEModel 为文本蕴含模型,采用RoBERTa模型. 该文本的语义一致性特征 SC = v entail.
3.4 模型训练
在得到输出隐藏向量 h [CLS]、事实一致性向量 FC 和语义一致性向量 SC 后,将它们拼接并送入 Sigmoid 线性分类层进行预测. 形式如下
p=Sigmoid(W o(h[CLS] FC SC)+b o) (7)
其中, W o和 b o分别为线性变换的参数矩阵和矢量;表示拼接. 模型训练的目标为优化损失函数. 本文的损失函数采用二分类的交叉熵损失.
L=- 1 k ∑ k i=1 y i log p i+(1-y i) log (1-p i) (8)
其中, k 为训练集的文本数目; y i 为第 i 个文本的真实标签; p i 为第 i 个文本的模型预测概率. 此外,使用Adam算法更加有效地更新模型权重.
4 实 验
4.1 实验设置
本文是在以下三个数据集上评估提出的检测方法.
(1) News-style数据集. 该数据集的文本均为新闻,总计64 000篇,其中人工和生成新闻各占一半. 人工新闻的来源为中国日报、CNN、BBC. 而生成新闻是由文本生成器GPT2-large-762M根据人工新闻的标题生成. 文本生成器的采样策略为核采样, p 取值为0.96,这是使生成文本质量更好的 p 取值 [25].
(2) OpenAI提供的Webtext-style数据集. 人工文本的来源为Webtext,而生成文本是由文本生成器GPT2-small-117M生成. 文本生成器的采样策略为核采样, p 随机取值于0.8~1.0. p 的不固定取值使得检测器的检测难度上升.
(3) Zellers等人 [12]提供的Grover数据集. 人工文本的来源为RealNews,而生成文本是由文本生成器Grover-base生成. 文本生成器的采样策略为核采样, p 取值为0.96.
上述三个数据集的统计数据如表1所示. News-style和Webtext-style数据集用于测试方法的检测准确性. Grover数据集采用了与前两个数据集不同的文本生成器,本文将其用于测试方法的泛化能力.
4.2 检测方法比较
本节将提出的方法ConsistNet与几种优异的生成文本检测方法进行了比较,分别是基于Transformer的预训练模型BERT [26]和RoBERTa、基于卷积神经网络的分类模型TextCNN [27]、基于文本单词及N-gram特征输入的分类模型FastText. BERT和RoBERTa的大小为Base级别.
表2展示了各检测方法在News-style、Webtext-style数据集上的检测准确率. 对于News-style数据集,ConsistNet取得最好的检测效果. 最好的基线为RoBERTa模型. 在两种不同的文本序列长度,ConsistNet的准确率较RoBERTa均有一定的提升,分别为1.28%、1.21%. 对于Webtext-style数据集,ConsistNet同样取得最好的检测效果. 最好的基线为RoBERTa模型. 在两种不同的文本序列长度,ConsistNet的准确率较RoBERTa均有一定的提升,分别为1.83%、0.85%. ConsistNet在两个数据集两种文本序列长度均好于基线RoBERTa,反应了一致性特征的有效性. 此外,基于Transfomer架构的检测方法效果优于基于传统神经网络的检测方法.
表3展示了在News-style数据集(或Webtext-style数据集)上训练的方法在Grover数据集的准确率,反应了方法的泛化能力. 在训练于News-style数据集的情况下,ConsistNet取得最好的检测效果. 文本序列长度为100时,ConsistNet的准确率较最好的基线RoBERTa提高了1.78%. 而文本序列长度为200时,ConsistNet较RoBERTa提高了1.35%. 在训练于Webtext-style数据集的情况下,ConsistNet同样取得了最好的检测效果. 文本序列长度为100时,ConsistNet的准确率较最好的基线RoBERTa提高了3.08%. 而文本序列长度为200时,ConsistNet较RoBERTa提高了2.35%. 各基线检测方法的泛化能力较为一般,这是基于单个数据集的统计异常特征失效导致的. 而ConsistNet会挖掘更深层更通用的生成文本缺陷特征,所以方法的泛化能力有较大提升.
4.3 消融实验
本节进行了消融实验研究. 因为主流检测模型在Webtext-style数据集检测效果更好,所以选择在该数据集上进行实验. 通过对直接基线RoBERTa和ConsistNet的两种变体实验,验证一致性特征提升方法检测能力的有效性.
(1) RoBERTa-Base是实验的直接基线,没有考虑文本中任何一致性特征;(2) ConsistNet(FC)抽取文本的事实一致性特征,结合ROBERTa进行分类判断;(3) ConsistNet(FC + SC)抽取文本中的事实和语义一致性特征,是本文提出的完整方法.
如图2所示,事实一致性、语义一致性特征都可以有效地提升方法的检测准确率. 在两种文本序列长度上,事实一致性特征平均提升0.72%的准确率,最高提升1.3%的准确率. 而语义一致性特征平均提升0.62%的准确率,最高提升0.71%的准确率.
如图3所示,事实一致性、语义一致性特征都可以有效地提升方法的泛化能力. 在两种文本序列长度上,事实一致性特征平均提升0.69%的准确率,最高提升1.33%的准确率. 而语义一致性特征平均提升2.025%的准确率,最高提升3.03%的准确率.
5 结 论
本文提出了一种基于事实和语义一致性的生成文本检测方法ConsistNet. 该方法分别计算出实体的两种表示,即基于内容的实体表示和基于维基百科的实体表示. 每个实体的两类表示输入到实体比较网络,得到文本的事实一致性特征. 该方法使用文本蕴含模型推理文本上文和下文的语义逻辑关系,将模型输出的推理隐藏向量作为文本的语义一致性特征. 最后将两类一致性特征和RoBERTa的输出隐藏向量拼接,输入到线性分类层进行预测. 本文在多个公开数据集上进行了实验. 实验结果表明,该方法的准确率和泛化能力均优于目前的生成文本检测方法.
不过,该方法存在两个不足之处:(1) 该方法对短文本的检测准确率不够高.短文本提供的有效信息较少,使得该方法很难挖掘出特征线索进行判断.(2) 该方法不具有鲁棒性,无法有效地抵抗目前的攻击方法.因此,本文下一步的研究为提升检测方法对短文本的检测准确率以及鲁棒性.
参考文献:
[1] Fan A, Lewis M, Dauphin Y. Hierarchical neural story generation [C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2018: 889.
[2] Zhang Y, Sun S, Galley M, et al . DialoGPT: Large-scale generative pre-training for conversational response generation [C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 270.
[3] Cruz-Benito J, Vishwakarma S, Martin-Fernandez F, et al . Automated source code generation and auto-completion using deep learning: Comparing and discussing current language model-related approaches [J]. AI, 2021, 2: 1.
[4] Liu G, Hsu T M H, McDermott M, et al . Clinically accurate chest x-ray report generation [C]//Machine Learning for Healthcare Conference. New York: PMLR, 2019: 249.
[5] Schuster T, Schuster R, Shah D J, et al . The limitations of stylometry for detecting machine-generated fake news[J]. Comput Linguist, 2020, 46: 499.
[6] Brown T, Mann B, Ryder N, et al . Language models are few-shot learners[J]. Adv Neural Inf Process Syst, 2020, 33: 1877.
[7] Uchendu A, Le T, Shu K, et al . Authorship attribution for neural text generation[C]//Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2020: 8384.
[8] Adelani D I, Mai H, Fang F, et al . Generating sentiment-preserving fake online reviews using neural language models and their human-and machine-based detection[C]//International Conference on Advanced Information Networking and Applications. Switzerland: Springer, 2020: 1341.
[9] Weiss M. Deepfake bot submissions to federal public comment websites cannot be distinguished from human submissions[J]. Techn Sci, 2019, 12: 1801.
[10] Solaiman I, Brundage M, Clark J, et al . Release strategies and the social impacts of language models[EB/OL]. [2022-06-18]. https://arxiv.org/ftp/arxiv/papers/1908/1908.09203.pdf.
[11] Bakhtin A, Gross S, Ott M, et al . Real or fake? learning to discriminate machine from human generated text[EB/OL]. [2022-06-18]. https://arxiv.org/pdf/1906.03351.pdf.
[12] Zellers R, Holtzman A, Rashkin H, et al . Defending against neural fake news [J]. Advances in Neural Information Processing Systems, 2019, 32: 9051.
[13] Li J, Galley M, Brockett C, et al . A diversity-promoting objective function for neural conversation models [C]//Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2016: 110.
[14] Wiseman S, Shieber S M, Rush A M. Challenges in data-to-document generation[C]//Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2017: 2253.
[15] Holtzman A, Buys J, Du L, et al . The curious case of neural text degeneration [C]//Proceedings of the 8th International Conference on Learning Representations. [S. l.]: OpenReview.net, 2020.
[16] Jawahar G, Abdul-Mageed M, Lakshmanan L V S. Automatic detection of machine generated text: A critical survey [C]//Proceedings of the 28th International Conference on Computational Linguistics. [S. l.]: International Committee on Computational Linguistics, 2020: 2296.
[17] Gehrmann S, Strobelt H, Rush A M. GLTR: Statistical detection and visualization of generated[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2019: 111.
[18] Ippolito D, Duckworth D, Callison-Burch C, et al . Automatic detection of generated text is easiest when humans are fooled[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 1808.
[19] Badaskar S, Agarwal S, Arora S. Identifying real or fake articles: Towards better language modeling[C]//Proceedings of the Third International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2008: 817.
[20] Fr hling L, Zubiaga A. Feature-based detection of automated language models: tackling GPT-2, GPT-3 and Grover [J].Peerj Comput Sci, 2021, 7: e443.
[21] Jawahar G. Detecting human written text from machine generated text by modeling discourse coherence [EB/OL]. [2022-06-18]. https://www.cs.ubc.ca/~carenini/TEACHING/CPSC503-20/SOME-FINAL-PROJECTS/GANESH-503_Report-GC.pdf.
[22] Bojanowski P, Grave E, Joulin A, et al . Enriching word vectors with subword information [J]. Tacl, 2017, 5: 135.
[23] Liu Y, Ott M, Goyal N, et al . Roberta: a robustly optimized bert pretraining approach[EB/OL]. [2022-06-20]. https://arxiv.org/pdf/1907.11692. pdf.
[24] Hu L,Yang T, Zhang L, et al . Compare to the knowledge: graph neural fake news detection with external knowledge[C]//Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL 2021: 754.
[25] Zhong W, Tang D, Xu Z, et al . Neural deepfake detection with factual structure of text [C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2020: 2461.
[26] Devlin J, Chang M W, Lee K, et al . Bert: pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2019: 4171.
[27] Kim Y. Convolutional neural networks for sentence classification[D]. Waterloo: University of Waterloo, 2015.
