
基于多源数据采集融合的食品安全风险模型研究
2023-04-13 17:24汪榕丁洪鑫周维
计算机时代 2023年4期
汪榕 丁洪鑫 周维


摘要: 食品安全的风险趋势分析对于及时发现食品安全隐患具重要意义。针对食品安全监管中数据零散、信息封闭、消息滞后所导致的效率难点问题,提出了结合多源异构数据的食品质量安全风险模型。以多源数据采集汇集技术为基础,利用数据治理方法,结合主题域模型、显著性分析模型和综合性评价分析模型,通过组合这三个模型,共同实现食品安全合规的自动预测,取得了良好的效果。
关键词: 多源数据采集汇集; 数据治理方法; 主题域模型; 食品安全风险模型
中图分类号:TS201.6;TP391.1 文献标识码:A 文章编号:1006-8228(2023)04-106-06
Abstract: The risk trend analysis for food safety has a significant meaning in discovering potential danger of food safety in time. To solve the efficiency problems caused by fragmented data, closed and lagging information, a risk variation tendency analysis model for food safety based on multi-source heterogeneous data is proposed. By using multi-source data acquisition technique and standardized methods of data governance, we combined the subject model, significance analysis model and comprehensive evaluation model to implement the automatic prediction for food safety. Good results have been achieved.
Key words: multi-source data acquisition technique; standardized methods of data governance; subject model; risk variation tendency analysis model for food safety
0 引言
国家对食品安全问题十分重视,制定了食品安全指标,但仍然存在零散性、封闭性和滞后性三个缺陷[1]。本研究结合多源数据采集汇集、数据标准化治理、数据融合分析、食品安全主题域模型、显著性分析模型和综合评价分析模型等技术,建立食品安全趋势分析模型进行风险控制,实现了将食品安全监管数据、食品安全舆情数据和新闻媒体报道数据的融合分析,使得食品安全的各领域质检人员直观地获得自己需要的食品安全风险趋势信息,提高食品安全风险预警的准确性和实效性,为食品流通阶段的风险控制创造有利条件。
1 大数据采集汇集与融合分析技术应用
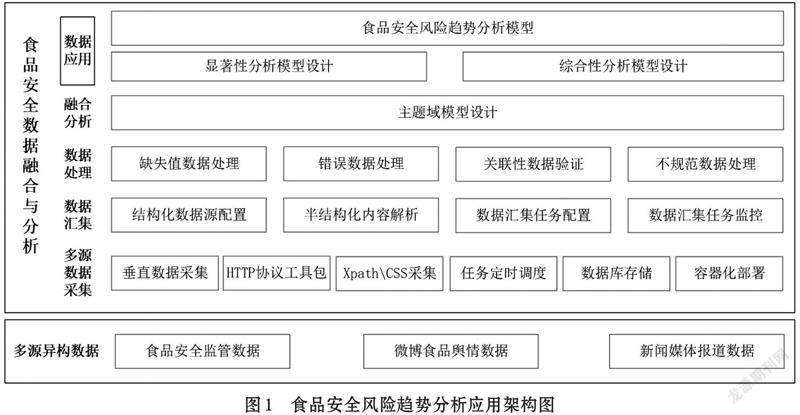
目前,大数据已基本应用到我国食品安全领域的各个角落,采用互联网采集技术、数据标准化治理技术和数据融合分析技术,可以解决食品安全数据的“采、治、管、存和用”的问题,实现对食品生产、加工、运输、包装、存储等方面质量问题的监管,理论上实现对食品全流通阶段的全面风险控制[2]。
根据图1可知,本研究的多源异构数据来源主要集中于食品安全监管数据、微博食品舆情数据和新闻媒体报道数据。利用互联网数据采集技术,去实时将各网站数据进行采集和存储到关系型数据库中,再通过数据集成组件将关系型数据库中的数据集成到大数据平台的数据湖中,并结合数据标准化治理的手段来进行缺失值数据处理、错误数据处理、关联性数据验证和不规范数据处理等,最终通过设计食品安全主题域模型、显著性风险模型和综合分析模型去构建完整的食品安全趋势分析模型。
1.1 多源数据采集汇集方法
针对食品安全数据采集场景,除了常见的食品安全监管局网站外,还有可能对微博数据开放平台进行接口采集,以及直接爬取各地方新闻媒体数据。因此,面对错综复杂的食品安全数据采集场景,针对不同数据源,选择合适的数据采集技术是至关重要的,具体场景下的采集技术选型如表1所示。
结合食品安全风险趋势分析的数据源情况及数据需求,设计数据采集解决方案技术架构如图2所示。
通过多源数据采集架构,完成数据采集、存储和管理,为后续标准化数据治理做好准备。
1.2 食品安全数据处理方法
食品安全多源数据采集完成后,接下来是食品安全数据的标准化处理[3],主要是针对食品安全数据中存在的缺失值数据处理场景、错误数据处理场景、关联性数据验证场景和不规范数据处理场景,具体的数据标准化处理流程图如图3所示。
对于具体的食品安全数据标准化处理规则,它是开展数据标准化治理工作前期的预判断环节,通过预先配置的数据标准处理规则,一方面可以节省食品安全数据标准化处理的效率,另一方面可以评估食品安全原始数据源的数据质量情况。
而对于食品安全数据存在的四种治理场景,具体处理方法如表2所示。
1.3 食品安全风险主题域模型设计方法
在食品安全数据标准化治理完成后,需要先构建食品安全风险主题域模型。考虑到食品领域的种类非常复杂,具体包括主食、肉类、蔬菜、水果、水、饮料、各种调味剂等,本研究的食品安全主题域模型设计是参考国际食品法典委员会(CAC)食品分类标准,将食品安全风险主题域模型设计按照六个层次来分类,分别是生产地、检测地、检测时间、食品分类、检测指标和舆情监控。这种分类方式有利于不同时期,不同地域,不同种类的食品安全风险趋势分析的相互转换和组合,总体框如圖4所示。
加强食品安全风险信息的管理,有助于实现食品安全问题的早发现、早研判、早预警和早处理。
2 食品安全风险趋势分析模型建立
2.1 食品安全显著性分析模型建立
2.1.1 各类食品指标的标准化方法
在上述研究的基础上,要对不同食品种类的数据进行比较,可先将它们分别标准化,转化成无量纲的标准化数据,因而可以借助于标准化方法来消除数据量纲的影响。标准化公式为:
其中,[xi]指不同食品种类检测的实际数据,[yi]指标准化后的检测数据,而[x=1ni=1nxi]表示检测指标的求和平均值,[s=1n-1i=1n(xi-x)2]表示检测指标的标准差。因此指标实际值与评价值的最终关系如图5所示。
可以看出,无论指标的实际值如何,指标的评价值总是分布在零的两侧。指标实际值比平均值大的,其评价值为正,反之为负。为了更符合习惯,我们可以将食品种类的合格率转化为百分数形式,比如用公式:
均值转化为60,超过均值的转化为60以上,反之则在60以下。这种“百分数”还不同于一般的百分数,因为个别极端数值的转化只可能超过[0,100]区间。
2.1.2 显著性分析模型建立的准备
可信度(reliability),可以定义为统计测量的响应中可变性的比例。根据样本个数的不同,最初的可信度评价等级已经不能很好的诠释多样本下的指标权重比例,因此本文在原来的基础上做了如下改进:
其中,[ni]为每个样本数,公式中求其总数值。[ω]为标准权重水平,[ωi]为样本指标的权重值,[ωi]为改进后的划分权重值。
为了对可信度进行等级划分,利用式⑶和式⑷,表5给出了主观可信度的等级划分:
因此,从主观可信度矩阵可以看出,在给出可信度时,仅需给出主观可信度矩阵的上(或者下)二角的元素即可,由于主观可信度矩阵C与判断矩阵A的元素一一对应,对矩阵C作列和归一化操作,即可得到每一列判断的主观可信度权重,即
2.2 食品安全综合性分析模型建立
通过上述的求解结果,结合食品安全数据的分析,本文通过将不合格比率进行划分,从而确定每次抽检各类食品安全指标不合格的程度。
根据安全指标处理后的数据特点,我们结合Liker等级分类原理进行等级划分,其区间划分如表4。
在综合评价时,如果遇到定性的指标,这些指标必须经过处理才能与其他量化指标一起运用。因此,我们结合食品种类的风险监测指标进行变化趋势分析。
2.3 食品安全风险趋势分析模型建立
在上述步骤之后,挑选不同的食品种类,分析其食品安全风险趋势最大的影响因子,并通过Python对其变化趋势进行深入分析,最终决定选择指数平滑的时间序列算法作为食品安全风险趋势分析的技术实现[4],模型的建立具体如下。
3 实验与测评
3.1 数据准备
本论文以市场监督管理局网站的食品安全监管数据、微博食品舆情数据和新闻媒体报道数据[5]为研究对象,其数据范围覆盖了豆制品、熟肉制品、调味品、蔬菜、蛋制品、休闲食品和酒水类等食品种类的抽样检测数据。原始数据共包含了23552条数据,每条数据包含了生产地、检测地、检测时间、食品分类、检测指标和舆情监控等字段。针对食品安全风险趋势分析的预测需求,我们从原始数据中提取了所有字段用于构建数据集[6]。
我们对原始数据进行标准化数据治理,在大数据平台中构建了原始区、标准区、主题区和专题区,其中原始区构建目的是存储源数据,保持贴源1:1原则。标准区构建目的是为了针对原始数据开展标准化数据治理工作,提升食品安全数据质量。主题区构建目的是为了围绕食品安全对象去设计主题域模型,解决食品安全多源数据融合分析的问题。专题区构建的目的是為了支撑食品安全风险趋势分析模型的建立,提供数据服务支撑。
3.2 实验结果
3.2.1 显著性分析模型求解
在此基础上,为了支撑最终模型的构建,我们首先对各类食品检测指标数据进行了无量纲化处理,得到豆制品(A)、熟肉制品(B)、调味品(C)、蔬菜(D)、蛋制品(E)、休闲食品(F)和酒水类(G)等食品种类在最近三年不合格率的风险得分矩阵,再结合变量相关性模型公式(5)求解得到分类食品所占的权重比,最终筛选出显著性食品种类进行指标变化趋势分析[7]。
通过如上的表格,利用公式⑸计算出豆制品、熟肉制品、调味品、蔬菜、蛋制品、休闲食品和酒水类的权重如下所示:
(0.0944,0.0179,0.4549,-0.0093,0.0320,0.1599,0.1075)
通过分析所划分后的权重值大小,我们得到在食物种类的豆制品,调味品,休闲食品和酒水类样本中,他们的可靠性评估标准为非常有把握和完全有把握,因此本文接下来将对这四类食物种类进行风险趋势变化分析。
3.2.2 综合性分析模型求解
通过上述的求解结果,我们将挑选四类食品的风险指标在最近三年内的不合格比例统计出来,再结合采用Liker四级量表,将食品指标的合格程度分成四级,分别是:第I类、第II类、第III类和第IV类,相应赋值为4、3、2、1。在综合评价时,这些定性指标的信息必须经过处理才能一起使用,因此我们利用上述定性指标的量化公式⑹进行处理[8],最终得到安全指标在剩余四类食品所影响的风险趋势得分如下所示:
通过上述表所给的信息,我们可以得到在豆制品,调味品,蛋制品和酒水类食物中,其显著指标分别为微生物、食品添加剂、抗生素和微生物,因此,我们结合所筛选出来的指标进行变化趋势分析。
3.2.3 风险趋势分析模型求解
结合上述步骤并考虑求解过程的一致性,我们这里只针对酒水类进行求解,对酒水类中所给的风险趋势指标数据进行曲线拟合[9],考虑到数据的正负号,首先通过公式⑵进行负向指标正向化处理,最后再利用Python求解结果如下所示:
由图6可知,预测的检测指标合格变化趋势呈现缓慢增长,基本与实际情况相吻合。反推可知食品安全不合格率的趋势变化情况,为食品安全流通各环节提供有力的监管支撑[10]。
4 结束语
本文采用多源数据采集汇集技术、数据治理方法、食品安全显著性分析模型和食品综合性分析模型结合的方法实现食品安全风险趋势分析的自动预测。其中多源数据采集汇集技术和数据治理方法是本文研究的核心,通过对多源异构数据进行采集、汇集、治理和融合处理,保障了数据处理的实效性以及数据质量的可靠性。同时在模型构建的环节,本研究没有使用单一的模型对问题进行分析求解,而是综合运用了多种数学模型,并增加了一定的检验环节,提高了数据的合理性,同时也增加了研究的价值。实验表明,本文提出的多源数据采集融合的食品安全风险模型在合格率预测中表现较好,即本文模型对食品安全监测达到良好的分类效果。但经扩展后的数据与真实数据仍存在差异,这也是后期模型待解决的问题,后续我们将工作重点投入到有效的数据扩展中,提高预测的准确率。
参考文献(References):
[1] 郝记明,马丽艳,李景明.食品安全问题及其控制食品安全的措施[J].食品与发酵工业,2004,30(12):63-66
[2] 肖辉,任鹏程,肖革新,等.食品安全健康大数据平台构建[J].医学信息学杂志,2016,37(5):28-31
[3] 郭曙超,龚方,昃向君,等.食品安全检测数据仓库技术的应用于研究[J].食品研究与开发,2013,34(17):125-127
[4] 王雅洁,杨冰,罗艳,等.大数据挖掘在食品安全风险预警领域的应用[J].安徽农业科学,2015,43(8):332-334
[5] 张晓勇,李刚,张莉.中国消费者对食品安全的关切——对天津消费者的调查与分析[J].中国农村观察,2004,9(1):14-21
[6] MITCHELL R.Web scraping with python:collecting more data from the modern web[M].2nded.Sebastopol:O'Reilly,2018:122-125
[7] MAATEN L,HINTONG.Visualizing data using t-SNE[J].Journal of Machine Learning Research,2008,9(86):2579-2605
[8] KRAWCZYK B.Learning from imbalanced data:open challenges and future directions[J].Progress in Artificial Intelligence,2016,5(4):221-232
[9] ETHEM A.Machinelearning:the new AI[M].[s.l.]:MitPress,2016:1-30
[10] Yongming Han. Food quality and safety risk assessment using a novel HMM method based on GRA[J]. Food Control,2019(105):180-189
*基金項目:国家自然科学基金项目(U20B2069)
作者简介:汪榕(1993-),男,贵州安顺人,学士,工程师,主要研究方向:大数据技术、数据挖掘、数据治理。
