
时空大数据分析在人群聚集统计中的应用
2023-04-13 13:47郑晓东郑业爽宋思琪
计算机时代 2023年4期
郑晓东 郑业爽 宋思琪


摘 要: 分析移动通信时空大数据可以得到城市居民的出行情况和活动规律,从而为城市交通措施优化提供数据支持和科学依据。该模型首先清洗原始通信数据,并对已清洗的数据做必要转换。然后使用kmeans聚集算法和邓恩指数来计算最佳聚类区域,并结合实际逻辑判断,标识出人群的驻留或途经状态。最后利用Hadoop中的MapReduce和Hive组件对数据进行分析汇总,针对应用场景得到相应的人群聚集模型并以可视化的方式呈现出来。
关键词: 人群聚集; 时空大数据; kmeans算法; 邓恩指数; MapReduce; Hive
中图分类号:TP181;TP311 文献标识码:A 文章编号:1006-8228(2023)04-67-05
Abstract: By analyzing the spatiotemporal big data of mobile communication, we can get the travel situation and activity rules of urban residents, thus providing data support and scientific basis for the optimization of urban traffic measures. In this model, the original communication data is first cleaned, and the necessary conversion is made on the cleaned data. Then kmeans clustering algorithm and Dunn index are used to calculate the best clustering region and combine with practical logic judgment to identify the resident or passing state of the crowd. Finally, the MapReduce and Hive components in Hadoop are used to analyze and summarize the data, and the corresponding crowd gathering model is obtained according to the application scenario and presented in a visual way.
Key words: crowd gathering; spatiotemporal big data; kmeans algorithm; Dunn's index; MapReduce; Hive
0 引言
城市交通出行日益擁堵,节假日人群阶段性的大规模聚集越来越常见。如何优化交通,避免交通堵塞,决策者需要详实的人们出行和聚集数据作为制定政策的依据[1]。通过搭建Hadoop时空大数据存储分析处理平台,利用智慧城市建设中搜集的海量时空大数据,加以分析处理并以可视化的结果展示,可以使Hadoop相关技术在存储、管理、挖掘时空大数据等方面的优势很好地用于解决此类问题[2]。
Hadoop生态系统中最为主要的技术包括HDFS、MapReduce和Hive。HDFS实现的海量大数据分布式集群存储,大幅提高了计算机的数据存储能力和数据操作便捷性。MapReduce的分布式并行编程架构,使得无须昂贵的服务器,仅利用廉价的桌面计算机集群就可批处理HDFS上的非实时海量数据[3]。Hive是数据仓库工具,它把数据文件以数据表方式来解释,提供类似传统ER数据库的结构化查询语言HiveSQL,即HQL供用户使用,并在底层将HQL执行语句转换成对应功能一致的MapReduce任务来执行。Hive典型的功能是频繁分析数据并生成数据报表。
本文详细论述Hadoop框架中的HDFS和Yarn安装和配置,并通过MapReduce和Hive编程演示,结合kmeans聚集算法[4]和邓恩指数[5],来论述如何清洗并处理时空大数据,最终得到可视化展示结果。
1 Hadoop框架的分析模型业务架构
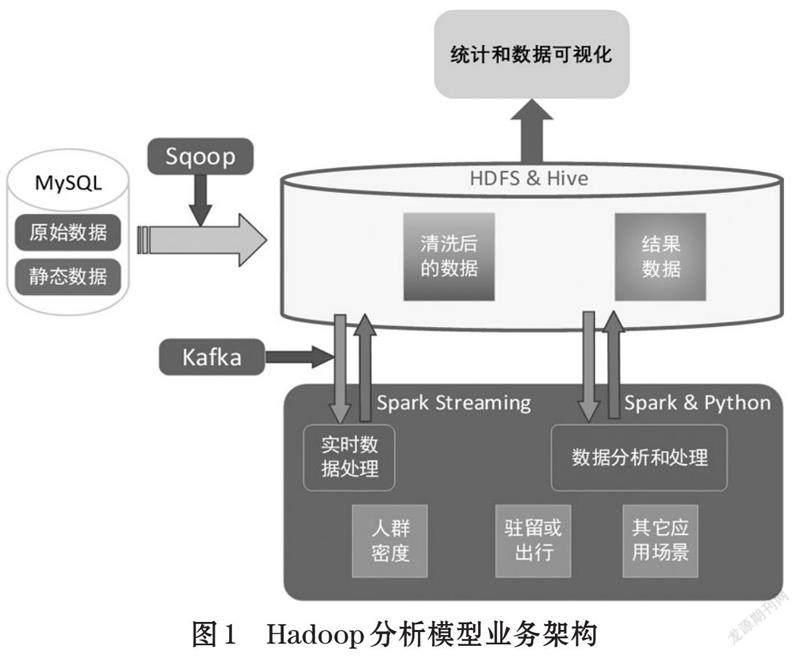
时空大数据Hadoop[6]分析模型业务架构如图1所示。先使用load命令将本地csv数据文件导入到MySQL中,再使用Sqoop将MySQL中的数据,导入到hdfs上存储。然后使用SparkSQL按照设计规则清洗数据,并将结果数据存储在hdfs上。如果需要实时数据处理,可以使用kafka模拟真实业务场景的实时流数据,再使用Spark streaming做实时运算处理,并将结果数据保存到hdfs上。其中数据分析和处理需要理解清洗后的真实数据,找出数据存在的特征并建立算法模型。例如为了实现途经或驻留应用场景分析,需要分析清洗后存储在hdfs上的数据,确定合适的算法模型,再通过聚类算法与逻辑相结合的方式实现途经或驻留的识别,将结果存储在Hive中[7]。统计和数据可视化是结合业务场景需求,将统计出的不同维度的结果数据以可视化方式展示给最终用户。
此系统架构主要分为两部分,业务程序部分和数据存储部分。业务程序部分主要是Hadoop的Spark离线处理和实时处理。Spark离线处理主要对之前1~2天的数据进行处理,并输出途经或驻留、人群密度以及其他业务场景。Spark实时处理主要对当前数据进行处理,输出人群密度热力结果数据。数据存储部分主要有两种存储方式:MySQL和HDFS&Hive。原始数据和静态数据存储于关系型数据库MySQL中。经Sqoop导入后的数据都存储在hdfs中,包括清洗数据和结果数据,结果数据存储在Hive中,便于组合分析和展示。
2 时空大数据的导入和清洗
交通时空大数据分析系统需要使用移动通信数据来处理和分析[8]。在可能出现人口大量聚集的城镇区域内,衡量人群聚集达到何种密度,采取何种举措来合理疏散人群,既缓解交通压力又不影响商业运行和区域價值体现,需要有科学客观的数据依据。通过和某市电信运营商合作,由其提供本地信令数据,并将我们实现的分析模型部署到该运营商的机房内,共同完成人群出行分析并将最终分析结果提供给某城市交通优化决策者。
本模型主要基于以下原始业务信息数据来完成分析:通信信息数据,基站经纬度数据和商业区数据。原始通信信息示例数据如图2所示。
逗号分隔的原始业务信息数据包含10个字段,分别是ts_end信息记录结束毫秒时间戳,imsi用户识别码惟一id,lac_id基站位置区编码,cell_id扇区编号,phone电话号,ts_start信息记录开始毫秒时间戳,tmp0一级行政区编号,tmp1二级行政区编号,nid信息类别1,npid信息类别2。基站经纬度示例数据和商业区示例数据分别如图3和图4所示。
基站经纬度数据包含字段longitude经度,latitude纬度,laci基站信息。商业区数据包含字段longitude经度,latitude纬度,area_name商业区名称。
原始数据清洗主要是针对通信信息数据。我们需要抽取ts_end,imsi,longitude,latitude四个字段,并去除imsi字段中包含特殊字符如‘#,*的数据条目。业务信息残缺的记录条目,即imsi、lac_id、cell_id字段值为空的记录条目需要删除。干扰数据条目即不是2022.06.03当天的数据需要删除。通信信息数据和基站经纬度数据关联后经纬度字段为空的数据条目需要删除。ts_end时间戳格式需要转换为年月日时分秒的形式,如‘20220603000035。以人为单位按时间正序排序后,以分钟为粒度单位删除重复数据,并删除同一imsi所关联数据条目小于10的所有该imsi关联数据。清洗后的实时流数据如图5所示。
3 时空大数据的数据建模分析处理
原始数据清洗和转化后,可以通过k-means聚类算法[9]和邓恩指数[10]对数据加以标识,以备后期数据抽取和展现的处理。但在正式对其分析和处理前,需要识别途经和驻留。途经和驻留识别结果数据的实现分三阶段,第一阶段是数据预处理,算法主要识别出驻留区域,将干扰性强的途经点先标注出来并输出。第二阶段读取清洗后的数据和第一阶段输出数据,将第一阶段标注的途经点暂时去除。然后以某人一天的数据为单位,利用无监督聚类的方法,设置多个聚类数目,通过聚类评分指标评价出效果最好的位置点,生成候选驻留点。这个阶段使用k-means聚类算法,先识别出人的驻留区域,通过逻辑算法再识别驻留区域内不符合条件的途经点,最后将途经和驻留的数据信息标签化。第三阶段通过逻辑算法,将不符合逻辑的候选驻留点判定为途经点。最后整合各阶段标注点,输出途经和驻留识别结果数据。
第一阶段,即数据预处理阶段,读取清洗后的数据,抽取timestamp时间戳,imsi,经度,纬度四个字段创建临时表,然后获取每个imsi所出现经纬度点次数小于4的数据,即数据中出现频率三次以内的点,按照时间排序。这些数据条目在时间顺序上可能独立一行,也可能几行连续。上述过程需要通过Python脚本判断当前点的前后数据是否连续,并计算连续段的速度。处理的步骤如下。
⑴ 将统计好的数据转成list列表并遍历这个列表。
⑵ 如果当前点为起点数据,判断该点与下一个点的顺序是否匹配。如果是则算作连续点,如果不是则算作单点。
⑶ 如果当前点为尾点数据,判断该点与上一个点的顺序是否匹配。如果是则算作连续点,如果不是则算作单点。
⑷ 如果当前点为中间点数据,判断该点是否与上一个点和下一个点的顺序都不匹配,如果是则算作单点,连续段结束。如果与上一个点匹配但与下一个点不匹配,则算作连续点,连续段结束。如果都不是,则判断为连续点,并准备循环处理下一个点的数据。
第二阶段,即算法建模阶段,首先读取清洗后的数据和第一阶段处理后的数据,去除第一阶段判定为途经点的数据。这里需要将nid信息类别字段加上,方便第三阶段的业务逻辑处理。然后将数据以人为单位进行分割,并将数据转换成 kmeans算法需要的向量格式。之后遍历估算的最佳聚类数目,一般为3到9,每次计算当前数据单元的kmeans的聚类效果。算法实现为遍历数据列表,包含字段类簇、经度、纬度,并计算任意两个经纬度点之间的间距。相同类簇的在一个list列表,不同类簇在另一个list列表。在遍历聚类数目的同时计算其邓恩指数DVI,邓恩指数DVI的计算公式如下:
即:DVI=任意两个簇元素的最短类间距离除以任意簇中的最大类内距离。注意需要去掉同一个簇内两点最大间距为零的点。接着找出邓恩指数最大的类簇,通过聚类评分指标即邓恩指数确定好最佳聚类后重新计算。之后将类簇的类别和每个类簇的中心点经纬度插进计算好的数据中,格式为:ims,类簇,数据点的经度,数据点的纬度,类簇中心点的经度,类簇中心点的纬度。最后与第一阶段处理后的数据表关联以获取数据的时间,并保存计算结果。
第三阶段,为业务逻辑实现阶段。读取第二阶段算法建模得到的计算结果,按照imsi分组和时间字段排序。然后计算类簇中数据点的前后时间跨度和数据点距离类簇中心点的间距。处理方式如下:
① 将处理好的数据按照键值对分组,键key和值value分别为:
key:(imsi-cluster)
value:(time,longitude,latitude,cluster,cluster_longitude,
cluster_latitude,nid)
② 遍历分组后的数据点前后时间差,按照首点,尾点,中间连续点的规则来处理。如果是首点,该点与上一个点时间跨度为0, 该点与下一个点时间跨度为下一个点时间减去当前点时间;如果是尾点,该点与上一个点时间跨度为当前点时间减去上一个点时间,该点与下一个点时间跨度为0;如果是中间点,该点与上一个点时间跨度为当前点时间减去上一个点时间,该点与下一个点时间跨度为下一个点时间减去当前点时间。
在前面工作的基础上,根据数据中当前点与中心点的间距和时间跨度,来识别驻留分段和途经点。并加标识字段,0为驻留点,1为出行点。在第三阶段的最后,要把识别出的途经点和驻留点数据转成DataFrame临时表格。然后读取第一阶段途经点的识别数据,并整合所有的驻留和途经数据,按照新的数据格式输出。新的数据格式包含imsi用户惟一标识id,ts时间戳,lac_id,cell_id,tag途经或驻留标签。其中tag字段值0表示驻留,1表示途经。结果示例数据如图6所示。
4 MapReduce数据处理具体实现
MapReduce是基于Hadoop的数据分析和处理的核心组件,它可以将用戶编写的业务逻辑代码和自身组件整合成一个完整的分布式运算处理程序,然后并发运行在Hadoop集群上。人群密度应用场景的MapReduce实现使用图4所示的商业区数据和图5所示的清洗后时空数据。首先将两份数据以经纬度为连结字段做连表操作,忽略imsi字段,拼接经度和纬度作为键,统计本时间段内本经纬度点一共出现了多少人。MapReduce编程模型只能包含一个map处理功能和一个reduce处理功能,如果业务逻辑比较复杂不能一次性处理完,只能编写多个MapReduce程序,并以串行的方式来执行它们。比如将人群聚集密度从高到低排序,需要编写一个MiddleMapper,其map方法具体代码如下:
protected void map(LongWritable key, Text value,
Context context) throws IOException,
InterruptedException {
String line=value.toString();
String[] arr=line.split("\t");
if(arr.length==2) {
MyKeyPair myKey=new MyKeyPair();
myKey.first=arr[0];
myKey.second=Integer.parseInt(arr[1]);
context.write(myKey, new IntWritable
(Integer.parseInt(arr[1])));
}
}
此处MyKeyPair有两个字段属性,经纬度和汇总数量。MyKeyPair按第二个字段汇总数量作为排序标准,利用Mapper的自动排序功能,即可实现汇总数量由大到小降序排列。MyKeyPair主要代码如下:
public class MyKeyPair implements
WritableComparable
String first;
int second;
@Override
public int compareTo(MyKeyPair o) {
return o.second-second;
}
……
}
对应的MiddleReducer的reduce具体代码功能比较简单,此处不再展示。最终结果如图7所示,数据包含两个字段,第一个字段为经纬度,第二个字段为此经纬度人群密度数量。
5 Hive数据处理具体实现
由于MapReduce在处理连表操作和数据汇总的时候,代码相对繁琐,后续处理我们使用Hive来实现。Hive操作接口采用类似SQL的语法,避免编写MapReduce代码。由于Hive的执行延迟比较高,Hive优势在于处理大数据,对于处理小数据没有优势,因此 Hive适用于数据分析且对实时性要求不高的场合。我们将图4和图7所展示的数据存入Hive两张新建的外部文本文件表中。图4所示数据表名和字段命名为region(la string, lo string, lname string),图7所示数据表名和字段命名为lac_cnt(lac string, cnt int),则统计每个区域人群密度的汇总HQL语句如下:
select r.lname, sum(l.cnt)
from lac_cnt l
inner join region r on l.lac=concat(r.la,'-',r.lo)
group by r.lname;
该HQL语句以经纬度点为连表条件,得到每个经纬度点的人群数量。再以区域名称为分组字段,通过sum()聚合函数统计出每个区域的人群数量。
为了处理图6驻留或途经分析结果数据,和前面一样,我们将其存入Hive新建的外部文本文件表中,数据表名和字段命名为stay_pass(imsi,ts,lac_id,cell_id,tag)。需要关联的基站对应区域数据表名和字段命名为area_lac(aname, lac)。则统计每个地区人群驻留或途经的汇总HQL语句如下:
select a.aname, s.tag, count(s.tag)
from area_lac a
left outer join (select imsi, lac_id, cell_id, tag from
stay_pass group by imsi, lac_id, cell_id, tag) as s
on a.lac=concat(s.lac_id,'-',s.cell_id)
group by a.aname, s.tag;
该HQL语句先做stay_pass表上的分组操作去除同一个人的重复数据。然后和area_lac做左外连表操作,并以区域字段和驻留或途经状态字段分组,通过count()聚合函数得到每个区域的留或途经人数。注意Hive外联结操作不会生成空值数据,如果要保证结果数据的完整性需要使用Python或Scala脚本处理结果数据并补齐缺失的空值和0值数据。
前述结果可以保存到文件或者Hive数据表库中,读取并展示的过程同普通Web项目类似。通过SpringMVC读取文件或数据库中的结果数据,转换成Echarts可以直接使用的数据形式后,返回给Axios发起的数据请求。Axios收到数据后,交给集成在VUE中的Echarts組件直接显示即可。为了获取实时更新的数据,可以设置crontab定时任务定期生成Hive结果数据。然后用WebSocket推送数据到前端页面,展示实时更新的数据。
6 结束语
本文通过具体的Haddop应用和编程实践操作,演示了时空大数据的导入存储、处理转换、分析以及结果展示,表明HDFS+MapReduce+Hive在集群计算平台上提供时空大数据的高阶应用可以有很强的实用性。结合Python、Scala、SpringMVC、VUE、Axios、Echarts等其他应用项目开发技术,文本完整的演示了大数据应用框架项目的开发流程。项目最终展示结果可为区域人群交通优化政策的制定和执行提供科学客观的数据支持。另外,该项目的应用场景还可以进一步扩充,包括通勤线路分析、出行目的分析,出行方式分析等等。随着智慧城市建设的不断深入,利用种类越来越多、体积越来越大、覆盖面越来越广的海量时空数据来高效管理智慧城市有着非常广阔的应用前景。
参考文献(References):
[1] 冯明翔,罗小芹. 基于时空大数据的公共交通关键指标计算方法[C]//中国城市规划学会城市交通规划学术委员会.绿色.智慧.融合——2021/2022年中国城市交通规划年会论文集,2022:11
[2] 冯兴杰,王文超.Hadoop与Spark应用场景研究[J].计算机应用研究,2018,35(9):2561-2566
[3] Bawankule, Kamalakant L, Dewang, et al. Historical data based approach to mitigate stragglers from the Reduce phase of MapReduce in a heterogeneous Hadoop cluster[J]. Cluster Computing,2022:1-19
[4] Awad F H, Hamad M M. Improved k-Means Clustering Algorithm for Big Data Based on Distributed Smartphone Neural Engine Processor[J]. Electronics,2022,11(6):883-883
[5] Ibrahim O A, Keller J M, Bezdek J C,et al.Evaluating Evolving Structure in Streaming Data With Modified Dunn's Indices[J]. IEEE Transactions on Emerging Topics in Computational Intelligence,2019,5(2):1-12
[6] 尹乔,魏占辰,黄秋兰,等.Hadoop海量数据迁移系统开发及应用[J].计算机工程与应用,2019,55(13):66-71
[7] 刘莉萍,章新友,牛晓录,等.基于Spark的并行关联规则挖掘算法研究综述[J].计算机工程与应用,2019, 55(9):1-9
[8] Wei J S. Geographic spatiotemporal big data correlation analysis via the Hilbert-Huang transformation[J]. Journal of Computer and System Sciences,2017,89:130-141
[9] Nigro L. Performance of Parallel K-Means Algorithms in Java[J]. Algorithms,2022,15(4):117-117
[10] Vara N. Application of k-means clustering algorithm to improve effectiveness of the results recommended by journal recommender system[J]. Scientometrics,2022,127(6):3237-3252
*基金项目:2021年度湖北省教育厅科学研究计划指导性项目(B2021423); 宜昌市2019年应用基础研究项目(A19-302-14)
作者简介:郑晓东(1982-),男,湖北宜昌人,硕士,三峡大学科技学院专任教师,主要研究方向:智能化信息处理、计算机网络与应用。
