
改进PSPNet网络的舌图像分割方法研究
2023-04-06 01:45:09陈鑫王薇朱银东
电脑知识与技术 2023年5期
陈鑫 王薇 朱银东

关键词:舌体分割;PSPNet;轻量化模型;注意力机制;迁移学习;卷积神经网络
0 引言
望诊是中医四大治疗手法之一,主要通过观察患者面部、舌部进行初步诊断。而舌诊作为中医辨证论治的主要依据之一[1],在中医望诊中发挥着重要作用。它通过观察舌苔的颜色和形态变化对患者的疾病有初步的感知及判断,具有诊断便利、参考价值高的特殊优势[2]。但是,由于医生的主观经验不同且诊疗的客观条件参差不齐,导致诊疗结果在一定程度上存在误差,“人工智能+中医舌诊”因此应运而生。人工智能的本质是通过大量计算分析辅助决策,所以舌诊的智能化临床诊断离不开持续且规模庞大的数据支持,以达到计算机辅助分析舌象的效果[3]。近年来,随着中医计算机辅助诊断和舌诊客观化的加速发展,在中医舌象的提取、分析和研究方面图像处理技术和深度学习理论已广泛应用,有效地实现了舌象特征的准确识别与分析和量化结果,建立简单的舌象量化特征与中医症状的映射标准,初步实现了舌象特征分析与智能诊断[4-6]。
作为舌诊辩证化的重要环节,舌图像分割想达到的效果是将舌体与背景分离,使其不受面部、嘴唇的干扰,只保留可用于分析舌体细节和有效的舌体部位,使患者的舌体信息不受外界环境影响,准确将干扰舌体特征分析的背景分割出去是后续所有研究分析的基础[7]。
舌体分割方法主要包括:基于阈值的分割、基于能量泛函的分割以及深度学习方法等[8]。张灵等[9]采用Ostu法,确定舌体区域后自动选取阈值再进行分割,但准确率较低;陈宇等[10]提出改进Snake模型的舌体分割算法,引入了信息熵和Kapur的概念对经典的细菌觅食优化算法(BFOA) 进行优化,利用计算得出的最佳阈值将舌体图像二值化,在舌体对称的基础上对二值化图像的边缘轮廓进行关键点提取,最后将关键点的集合差值形成的B-样条曲线确定为Snake模型的初始轮廓,进一步计算出舌体轮廓,但不足之处在于计算量大,处理效率较低。
随着深度学习在图像识别领域被广泛应用,为特征图像中每个像素点打标签分类的基本思想贯穿于许多场景解析过程中,并取得了不错的效果[11]-[13]。深度学习与舌体分割结合本质上是基于舌体图像的语义分类,将舌体图像中不同的区域差异化处理,在利用卷积神经网络(CNN) 进行模型训练,实现在卷积和池化过程中集合并进一步增强语义特征,实现语义分割。颜建军等提出基于CNN的Mask-R-CNN的舌体图像分割方法。在边缘点识别过程中添加一个分模块,用来预测目标掩码,再分别对每个类别预测对应的二元掩码,并引入RoIAlign层,较少计算量,提高准确率。
目前来看,传统的分割方法仍然需要人为监督,进行干预以及控制迭代运算,从而导致自动化效果差、计算过程冗余性高、分割效果差等。而机器学习及深度学习的出现虽说在一定程度上弥补了传统方法的不足,但相关研究方法均存在边缘分割粗糙、分割准确度低、模型可解释性差等问题。针对以上问题,本文提出一种基于MobilNet的改进PSPNet的舌体图像分割方法。
本文工作的创新之处在于:
使用轻量化且经过预训练的MoblieNet神经网络建立模型主干网络,并引入改进后的注意力机制,保证准确度的条件下减少计算量,然后进行多次叠加的卷积操作后得到特征层;再通过PSPNet的金字塔模块搭建加强特征提取网络,对输入的特征图进行分层级的特征提取,得到不同尺寸的特征图后进行融合,充分保留图像有效信息特征。
利用迁移学习的理论特征,为模型设置预训练的权重参数,并对特定层参数进行冻结,极大减少了所需的计算资源,减少训练时间。经过实验验证,该模型在相对较少的训练时间的情况下分割效果仍然有保证。
1 网络模型概述
1.1 PSPNet
语义分割的本质是为图像中每一个像素点分类,目前主流的场景解析分析框架主要是基于全卷积网络(FCN) ,但由于场景的多样性以及信息特征连贯性,语义分割的应用目前仍存在许多不足。基于空洞卷积的金字塔场景解析网络(PSPNet) 发表于计算机视觉领域顶级会议(CVPR 2017) [14]。为有效解决衔接上下文信息特征的问题,该网络提出了融合不同尺度特征的金字塔池化模块,如图1所示。
该模块主要分为4个层级:第一层处理过程较为粗略,将输入的特征层全局平均池化,生成单个数据流输出;之后的第二、三层分别将特征层划分为2×2、3×3个子区域,再对每个子区域平均池化(Avgpool) ;第四层的处理过程最为细化,将特征层划分为6×6个子区域,再对每个子区域池化。而由于模块中层级不同输出的特征图尺度也不同,为了保证全局特征的权重,在每个层级的最后都使用一次1×1卷积核,即降维处理计算。最后再将低维的特征图上采样(upsample) ,使其与原始的特征图尺度相同。最后将不同的层级的特征图拼接成为模块的全局特征。
1.2 MobileNet
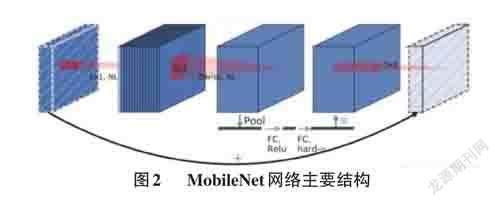
本文模型基于MoblieNet轻量级网络作为特征提取网络并保留其预训练权重参数实现迁移学习,MoblieNet网络如图2所示。
该神经网络主要由卷积层、批量归一化、relu激活函数组成的瓶颈模块与引入注意力机制的相同结构模块交替堆叠组成,因所需计算资源少且性能较高被称为轻量化模型。
MobileNet 的预训练数据来自开源的VOC 数据集。数据集(训练集和测试集)中包括21个类别的共21504张标注清晰,分割标签完整有效的图像。因此,得到的预训练权重具备较强的泛化性,在小样本数据图像处理任务方面可以达到迁移学习效果,从而提高特征提取的效率和精准率。
1.3 注意力机制
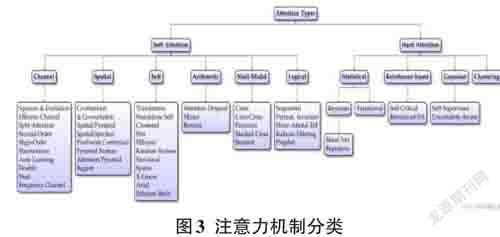
在认知领域,人类注意力会下意识地关注想要关注的部分,同时忽略掉其他部分,而这也为合理利用信息处理资源提供的理论基础。目前注意力机制需重点解决两个问题:确定需要关注的部分、如何将有限的资源分配到需要处理的重要部分。如圖3所示,注意力机制主要可以分为Soft Attention与Hard Atten?tion,进一步可以继续分为基于通道、多模态、聚类等多个角度的模块。
本文将讨论基于通道的几种模块类型:SE注意力模块通过全连接网络根据损失函数计算值(loss) 学习每个特征通道的重要程度(特征权重),并对特征进行提升且一直当前进程任务中不重要的特征;由于获取SE模块获取所有通道效率较低,ECA注意力模块完成了跨通道间信息交互且只需少量的参数,性能依然有明显提升;CBAM注意力模块在通道注意力机制的基础上引入了空间注意力机制(spatial) ,可以使神经网络更加关注图像中对分类起决定作用的部分,进一步提升了模型性能。
1.4 本文网络结构
受现实因素影响,医疗图像样本有限,因此在小样本分割任务的基础上,本文网络结构如图4所示,整体网络由主干网络(结构如图5所示)、加强特征提取及基于特征进行预测共三个部分来实现。在本文提出的网络结构s-PSPNet中,主干网络在卷积和池化简单堆叠的基础上融入逆残差思想,引入改进的注意力机制使得模型轻量化,并使用h-swishj函数代替swish 函数提高模型性能;加强特征提取采用PSP模块,实现将不同的区域的上下文信息特征聚合,提高获取全局信息特征的能力;最后对每一个像素点进行分类预测。
主干网络在卷积基础上使用具备线性瓶颈的逆残差结构(bneck) ,先利用1×1卷积进行维度提升,再进行3×3与5×5的深度分离可卷积,使主干网络具备残差边,通过卷积、批归一化、激活函数减少梯度消失的可能,加速网络收敛,模块交替进行特征融合。再通过对注意力机制进行改进来降低通道数,减少计算量;加强特征提取网络中将输入进的特征层划分为6×6、3×3、2×2、1×1 的区域,然后每个区域进行平均池化;最后先通过3×3的卷积核对特征进行整合,再利用1×1的卷积操作调整通道数匹配数据集,最后调整大小(resize) 进行上采样使最后的输出层的宽、高保持与数据集图像一致,再对最后一个特征层的每一个特征点进行分类,将背景和舌体区分开来,精准完成舌图像的分割。
2 实验及结果分析
2.1 实验准备
2.1.1 实验数据
本文实验数据集为Github网站的开源数据集,均使用标准舌象采集设备,数据完整且有效。数据集共300张舌象图片,分辨率为768×576,且包含相对应的掩膜图像。为提升模型的泛化效率,本文在原数据集基础上随机进行旋转、缩放等图像增强操作,最后得到400张图像,其中380张以8∶2分为训练集和验证集,而其余20张作为测试集验证模型,各数据集之间不存在重复数据。
图像分割方面,模型训练效果取决于舌体掩膜图像是否有效且符合医学规范,因此采用深度学习领域使用广泛的监督学习方法,对数据集进行人工标注。具体包括:将图像颜色深度统一为8位bit(像素值范围为0~255) ,仅仅保留0和1两个像素点,舌体部分为1像素点,其他无关背景由0像素点表示。本文使用LabelMe图像标注工具对数据集中舌体部分轮廓进行标注,从而得到图像的有效分割标签(GroudTruth) ,标记过程如图6所示。
2.1.2 实验环境
本文实验硬件环境:CPUIntel(R)Core(TM)i5-10200HCPU @ 2.40GHz、GPU NVIDIA GeForce GTX1650 Ti、显存8GB、内存16GB;软件环境:Windows10、Keras2.8.0 深度学习框架、TensorFlow 2.4.0、CUDA10.0。
2.2 实验设置
2.2.1 迁移学习
由于医疗数据集在数量规模小,影响模型训练效果,为了提高小样本模型学习效率,本文将在VOC 数据集上的预训练权重进行迁移学习。同时使用微调(fine-tune) 的训练方法,预训练权重参数载入之后对神经网络特征提取层的网络参数采取冻结操作,在根据效果不断调整学习率训练未冻结层的参数,完成加码层训练后,将所有参数解冻训练,迁移学习可使得模型训练效率以及图像分割精度都有显著提升。
在本文提出的模型中,将学习时期个数设置为100(Epoch) ,在前50个Epoch中,将模型的前3个小模块(bneck1-3) 的参数冻结,将主要的训练资源集中到bneck3后的s-Mobilenet模型未训练的神经网络参数,提取出与当前数据集相关度更高的特征。而在后50 个Epoch中解冻所有神经网络参数,且当前數据集中进行一个微调操作,已达到提升分割精度的效果,以重新分配计算资源的方式平衡了网络训练时间,并提高了特征提取准确度。
2.2.2 训练参数设置
在本文模型中,首先将图像尺寸大小调整(resize) 为(224,224,3) ,以免造成网络对图像尺寸不兼容。模型训练的过程中,Epoch设置为100,由于计算机显卡计算性能有限,批尺寸(BatchSize) 设为2,初始学习率为0.0001,根据内存需求,选择呢Adam优化算法,除初始学习率外均使用默认参数。本文使用的损失函数(Loss) 包含两部分:交叉熵损失(Cross Entropy Loss) 与集合相似度度量函数(Dice Loss) ,计算方式如下:
可以看出,网络损失与训练次数呈正相关并逐渐趋于稳定。
2.2.3 实验评价指标
本文实验选取平均像素精度(MPA) 和平均交并比比(MIOU) 两个指标作为分割模型的评价指标[15]。两个指标是语义分割任务的经典评价指标,其中MPA 表示每个类别中得到准确预测像素点的比例,MIOU 在混淆矩阵的基础上提出,指真实值与预测值两个集合的交集和并集的比例,计算公式如下:
其中,N为分割过程中需要被分割部分的类别,本文中1(舌体)、nii为第i 类语义类别的真实像素点的数量、nij 为第i 类被模型错误预测为j 类的像素点的数量。
2.3 结果分析
为验证本文提出的模型在舌象上方法的有效性以及分割表现,采取进行多次实验进行对比,选择传统的PSPNet网络、MobileV3-Net网络与本文提出的神经网络在相同数据集下进行分割效果评估的对比实验。采用MPA、MIOU 作为评估指标,结果如表1 所示。由于传统PSPNet网络的特征提取层无法准确地勾勒出舌体外廓,丢失了很多边缘信息,导致精度下降,分割效果较差;MobileNetV3由于其轻量级的特点模型参数显著减少,但准确率与本文方法相比较低。本文的实验模型从模型参数规模、模型训练时间、分割精准率方面经过对比均有提升,客观证明实验有效可行。
可以看出,本文方法在保证分割精度不受较大影响的情况下,显著降低了训练时间。
3 结束语
舌象分割是否精准对后期识别分析有决定性作用,是进行舌象自动化研究与辅助中医诊疗的基本条件。本文针对传统舌象分割自动化程度低,将背景与舌体分割开后舌体边缘细节严重丢失等问题,在深度学习和经典语义分割模型(PSPNet) 的基础上提出了针对舌象的改进PSPNet 分割模型。本文使用Mo?bileNet网络的轻量化特征提取结构代替原有的卷积模块,并使用了迁移学习提高模型学习效率,再通过注意力机制的改进,降低了特征提取过程中的通道数及参数量,融入金字塔模块有效保留了特征提取全过程的特征层信息。经过实验对比证明,本文提出的网络模型在中医舌象数据集分割具有良好表现,在保证了精度的前提下,训练时间降低了23%。但是该模型在处理特殊舌象,例如舌体齿痕严重,强曝光等,存在边缘细节处理不当的情况。因此,未来将从多个角度对非标准舌体的分割进行研究,有效提高识别率是重中之重。
猜你喜欢
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
知识管理论坛(2016年6期)2017-05-27 19:44:03
振动工程学报(2017年1期)2017-04-21 10:24:46
计算机应用(2016年12期)2017-01-13 20:26:21
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
电脑知识与技术(2016年10期)2016-06-16 21:27:26
