
基于轻量型U-net的钢材金相图像晶界分割方法
2023-04-03 14:29胡海军李秀峰
计算机测量与控制 2023年3期
王 森,国 蓉,胡海军,许 勇,张 钰,李秀峰
(1.西安工业大学 光电工程学院,西安 710021; 2.西安交通大学 化学工程与技术学院,西安 701149; 3.长庆油气田开发事业部, 西安 710000; 4.陕西师范大学 计算机科学学院, 西安 710062; 5.中国特种设备检测研究院, 北京 100029)
0 引言
当机械设备长期在高温高压、腐蚀性介质等环境下服役时,材料会发生劣化,出现蠕变、疲劳、腐蚀、侵蚀等现象。金相检验是检测材料劣化情况,保障设备服役安全的重要手段[1]。其中,准确的评价金相检验图片中材料的晶粒度等级是最关键的任务。当前对金相图片晶界的提取主要由人工进行,结果易受人员检验水平的影响、一致性差,且晶界和晶粒之间的颜色差别、明暗差别等也会干扰人工判断,影响检测的准确性。对材料显微组织的识别属于图像识别问题,同时也属于计算机视觉等技术在材料科学领域的应用[2-4]。自动晶界提取如数字图像处理、机器学习、深度学习等方法可以克服人工晶界提取的弊端,受到学者们的广泛关注。
晶界提取属于图像分割任务,常用的图像分割方法[5]有基于像素的图像分割方法、基于轮廓的图像分割方法和基于深度学习的图像分割方法等。基于像素的图像分割方法主要包括聚类算法和阈值化[6]方法。阈值法首先求取阈值,再根据图像阈值实现目标物体和背景的分割。然而,全局最优阈值难以求取导致其分割结果较为粗糙。聚类方法思想简单、便于操作,但是该方法依赖于阈值和树的构建,容易忽略图像的深层信息,对边缘以及噪声的处理效果较差。基于轮廓的图像分割算法依据图像中的轮廓信息,将图像的边缘轮廓转化成能量泛函的最小值求解过程。该方法对强噪声,低对比度的目标边界分割效果较好,但是需要人为预选相关目标的轮廓,计算复杂度高。
近年来,随着计算机的算力和效率不断提高,机器学习和深度学习算法得以快速发展。相比于传统的分割方法[7],卷积神经网络分割方法是目前应用最广泛的图像分割方法,其在人脸识别、医学图像分割等方向已经比较成熟[8-10]。卷积神经网络(CNN,convolutional neural network)能够从数据集中自动学习相关特征[11],在计算机视觉领域有较为广泛的应用[12]。2014年,由Jonathan Long等人[13]提出的全卷积神经网络FCN(FCN,fully convolutional networks),开启了图像分割Encoder-Decoder的新纪元。但是,FCN得到的是二维的分割结果[14],其精度低、细节不明显、没有充分考虑像素和像素之间的关系,不适用于金相图像的分割任务。
对于金相图像的晶界分割,庚嵩[15]等提出了一种基于改进CV(Chan-Vese)模型与局部拟合项相结合的金相图像分割算法,实现了金相图像的分割。谢建林[16]等人通过根据晶粒之间灰度值的相似性来提取出完整的晶粒,再找出晶粒之间的边界就是晶界。周雨蓉[17]使用盒维数来描述铝合金的金相组织特征,提取晶粒度的相关参数并利用PCA(principal component analysis)降维、FCM(fuzzy c-means)聚类方法减少特征的维度,从而减少次要特征的干扰。张海军[18]等人采用双阈值法进行图像分割,其分割的阈值为图像的极大值区域。朱建栋[19]等人提出了Mean Shift参数自适应算法和基于结构化随机森林的钢材金相图像晶界提取算法。孙秋冬[20]采用自适应双门限法对金相图像分割。Chowdhury[21]和Decost[22]应用深度学习方法对钢材的显微组织识别进行了相关研究。
然而,上述方法普遍应用于图像特征较为简单的金相图像,未对晶界与晶粒的像素级特征进行深入的研究,其应用于低对比度、复杂晶界的金相图像时对晶界的分割效果较差。针对该问题,本文提出了基于轻量型U-net的金相图像晶粒分割方法,主要内容有两方面。
1)网络设计:采用加入多层卷积以及在上采样过程中采用跳跃连接策略以融入更多浅层特征层,强化了网络的浅层特征提取能力;通过减少一层下采样层并在特征提取过程中增加了一次卷积过程,从而减少网络的参数量和计算量并使网络轻量化,同时提高了网络的预测准确率。
2)对比实验:将本文提出的轻量型U-net图像分割网络模型与现有的在少量数据集上常用的图像分割网络模型U-net、U-net++及Attention U-net进行对比实验,验证了本文提出的卷积神经网络模型对金相晶界分割的有效性和优越性。
1 模型设计和相关理论
1.1 U-net系列图像分割网络
CNN的全连接操作将图像的特征图变成一个向量,使得特征图丢失了图像的空间信息,FCN将传统CNN的全连接层更换成了卷积层,使得网络的输出为热力图而并非类别,即其可以从抽象的特征中恢复出每个像素所属的类别,从而实现对输入图像延伸到像素级分割。同时,采用上采样的方法解决了卷积和池化使得图像尺寸变化的问题。FCN的网络结构主要包含两个部分:即全卷积部分和反卷积部分,全卷积部分为一些经典的CNN网络,用于提取图像特征,其网络的输入可以为任意尺寸的彩色图像。反卷积部分主要为上采样过程,通过该过程可以得到与原输入图像尺寸相同的语义分割图像,最终的网络输出通道数为n(目标类别数)+1(背景)。
U-net[23]是在FCN的基础上进行改进得到的,设计的初衷是为了解决医学图像分割中的问题。其通过扩大网络解码器的容量改进了全卷积网络结构,并给编码和解码模块添加了收缩路径(Contracting path),实现更精准的像素边界定位,同时采用与FCN不同的特征融合方式:拼接(Concat),其将图像特征图按照通道维度进行拼接,从而形成更厚的特征图,该操作可以在上采样过程中融入更多有效特征层信息。其优点主要是:网络越深,感受野越大;网络更关注于全局特征;浅层网络更加关注纹理等局部特征;可以通过上采样和图像拼接来进行边缘信息的特征找回。该网络适用性好,近年来U-net被应用于多种场景的图像分割任务中。
由于U-net中的Encoder和Decoder网络特征层采用长连接方法直接连接,该过程会产生语义鸿沟,使得对医学图像分割缺乏更高的精确性,为了减少语义差别,Zhou等人[24]依据U-net网络结构基础提出了U-net++网络,U-net++在U-net直接连接的基础之上增加了类似于Dense结构的卷积层,并融合了下一阶段卷积的特征。采用大量的跳跃连接来保留各网络层的特征信息,将高分辨率的特征图从Encoder网络逐渐地和Decoder网络中相应的语义特征图进行叠加整合,由于不同深度的感受野对大小不同的目标敏感程度不一样,浅层的对小目标更敏感,深层对大目标更敏感,通过特征拼接将浅层信息和深层信息融合到一起,可以整合二者的优点。同时用小感受野的特征信息来补充下采样过程中的边缘信息丢失,使得位置信息更加的准确。
Oktay[25]等人在2018年提出的Attention U-net网络通过跳跃连接将抽象的深层特征和包含上下文信息的浅层特征融合,强化了网络的浅层特征提取能力,并在U-net的基础上引入注意力机制重新调整了编码器的输出特征,用门控信号来控制不同位置处图像特征的重要性,提高了对医学图像分割的准确率。其与U-net最大的区别就是Attention U-net中经过卷积后的特征层在进行通道拼接的特征融合之前都需要先经过注意力机制Attention gate模块而原始的U-net网络直接将同层的下采样产生的特征图采用通道拼接方法拼接到上采样层中,Attention gate的结构如图1所示。

图1 Attention gate结构
其中,g为深层网络特征图(跳跃连接的输入,包含上下文信息),xl为浅层网络特征图(前一个block的输入),α为与特定分割任务相关的注意力系数,可以抑制与本分割任务数据不相关的图像特征信息表达,将注意力系数与浅层特征图xl逐元素相乘即可得到输出特征图。加入Attention gate模块可以增强对前景像素的敏感性,Oktay等人的实验结果证明,其提出的Attention U-net在总体的Dice系数的结果上比原始的U-net有较大的优势,同时在计算成本上的增加较少。
1.2 晶界分割轻量型U-net网络设计
金相图像的对比度较低、部分区域亮度低、晶粒边界复杂,经过图像预处理的方法虽然可以增强图像对比度,但是分割复杂的晶界仍然十分困难。为了提高对晶界的提取准确率,需要在原U-net网络的上采样解码过程中融入更多的有效特征层信息。本文结合U-net++的设计思路,在图像的上采样过程中融入更多的跳跃连接特征图来改进U-net卷积神经网络模型,提高了该模型的浅层特征提取能力,图像特征层的拼接策略示意图如图2所示。

图2 图像特征层拼接策略示意图
其中,C为特征层的通道数,H和W分别为特征层的高度和宽度,朝右的黑色空心箭头为特征提取过程(采用卷积方法),朝下的空心虚线箭头为下采样过程(采用最大池化方法),朝上的黑色实心箭头为上采样过程(采用Up-Conv方法),黑色虚线单箭头为特征层的跳跃连接过程。同时,为了减少网络的参数量,本文将原始U-net的四次下采样过程改为三次下采样,减少了一次下采样过程使得网络总体参数量大幅减少,网络更加轻量,计算速度更快。总体的网络结构图如图3所示。

图3 改进的U-net图像分割网络
该网络模型分为左右两部分。黑色虚线左边为收缩路径(Contracting Path),该路径由3个模块组成。每个模块都采用3个3×3卷积(图中朝右的空心虚线箭头)操作和1个2×2最大池化(图中朝下的空心箭头)操作。卷积的Padding策略采用Same模式(即在卷积图外面一圈进行填充),从而保证经过卷积操作之后的特征图尺寸不变。卷积的激活函数采用神经网络中使用最多的[26]ReLu激活函数,该激活函数具有稀疏性,在输入大于0的区域上不会出现梯度饱和及梯度消失等问题,稀疏后的网络模型能够更好的挖掘输入数据特征信息,拟合训练数据,计算复杂度较低。采用最大池化对输入的图像进行降采样操作,其输出的特征图尺寸是输入特征图的一半。经卷积和池化运算后,得到图像中的浅层特征信息。
黑色虚线右侧为扩展路径(Expansive path),也由3个模块组成。每个模块前都采用1个2×2的反卷积操作(图中朝上的黑色实心箭头)和3个3×3的卷积操作。反卷积将特征图的尺寸乘2,通道数减半。同时,在扩展路径中将下采样过程中生成对应的尺寸相同而通道数不同的特征图进行复制和拼接操作(图中黑色虚线箭头)。将3个大小相同而通道数不同的特征图进行拼接合并后,再进行3×3的卷积和反卷积上采样操作,提取深层特征信息。直至将特征图恢复到和原始输入图像尺寸大小相同后,对得到的特征图进行1×1的卷积操作(图中朝右的黑色实线箭头),最终输出一个2层的语义分割图像。
2 实验验证及结果
2.1 数据集
在进行模型训练之前,需要先建立相应的金相图像分割数据集。由于现阶段暂时没有公开的金相晶粒分割数据集,本文采用由中国特种设备检测研究院提供的金相图像数据来制作数据集。
首先对由金相显微镜采集到的原始金相图像进行灰度化操作,灰度化的公式如下:
Gray= 0.299*R+ 0.587*G+ 0.114*B
(1)
再对灰度化后的金相图像依次进行自适应直方图均衡化(AHE,adaptive histogram equalization)、双边滤波(bilateral filter)操作。自适应直方图均衡化方法通过计算图像的局部直方图,重新分布图像亮度来改变图像对比度的方法,该算法更适用于改进图像的局部对比度来获得更多的图像细节。双边滤波算法是一种在高斯滤波的基础上进行改进的非线性滤波方法,其通过结合图像的空间邻近度和像素相似度进行折中处理,同时考虑图像的空域信息和灰度相似性,能够对图像起到保边去噪的作用,其通常具有简单、非迭代、局部的特点,双边滤波操作所包含的空域核函数的运算公式为:
(2)
相应的值域核函数计算公式为:
(3)
根据上述两式相乘所得的双边滤波权重函数为:
w(i,j,k,l) =
(4)
双边滤波的数据计算公式为:
(5)
其中:p(k,l)为模板窗口的中心坐标点,q(i,j)为模板窗口的其他系数的坐标(也即在模板窗口内,除去中心点的其他点的坐标),σd为高斯函数的标准差(也即坐标空间滤波器的sigma值),对应的像素值为f(k,l),σr为高斯函数的标准差(也即颜色空间滤波器的sigma值)。
整个预处理过程中,原始金相图像如图4(a)所示,经灰度化后结果如图4(b)所示,经自适应直方图均衡化后结果如图4(c)所示,再经过双边滤波后的结果如图4(d)所示。

图4 预处理操作图
通过对原始金相图像进行预处理操作有效的提高了图像亮度、加大了细节对比度、滤除了部分噪声,使得金相图像中的晶粒边界和晶粒之间更容易区分,晶界更加的清晰可见,更有利于卷积神经网络进行特征学习。原始金相图像局部和预处理后的金相图像局部(如图4(a)、(d)中黑色框对应部位)对比如图5所示。

图5 原始金相图像和预处理后图像的局部对比
在对原始金相图像进行预处理之后,需要手动绘制对应的晶界图像作为数据集标签,本文采用Ipad iOS上专业的绘图软件Procreate进行对应的晶粒边界标签绘制,绘制得到的晶粒边界标签经过灰度化及二值化操作后得到二值晶界标签。原始金相图像及对应的手绘晶界标签示例如图6所示。

图6 原始金相和对应的手绘晶界标签
将预处理后大小为1 536×2 048像素的金相图像和对应的晶界标签按每隔128像素裁剪出1张512×512像素的图像。依据此方法可以将原始图像集中12张1 536×2 048像素的金相图像裁剪成1 404张512×512像素的金相图像。预处理裁剪后的金相图像如图7(a)所示,对应的手绘晶界标签如图7(b)所示,将这1 404张金相图像和对应的标签图像作为本文的训练集。

图7 预处理裁剪后图像与其对应的晶界标签
由于有重叠的裁剪方法会导致图像数据部分存在重复,为使测试集和训练集保持特征一致性和个体独立性,本文测试集采用与训练集不重复的一张1 536×2 048像素的金相图像,并按与训练集相同的预处理方法进行预处理、晶界标签绘制和图像裁剪,得到117张512×512像素的金相图像和对应的晶界标签图像,实际的训练集图像和测试集图像的比例为12:1。
2.2 损失函数
对于本金相晶界分割数据集的训练学习,采用BCELoss(二分类交叉熵函数)作为损失函数,该损失函数常用于二分类任务中的损失计算,其计算公式如下:
loss(Xi,yi) = -wi[yilogxi+(1-yi)log(1-xi)]
(6)
其中:xi为模型的预测值,网络最后一层输出经sigmoid激活函数后取值范围为(0,1)。yi为标签值,取值为0或1。wi为权重值,一般为1。
2.3 实施细节
实验在Nvida Xp GPU(12 GB内存)的卡上进行,使用Pycharm 2020进行模型网络的训练和测试,使用Pytorch框架搭建U-net、U-net++、Attention U-net及前述轻量型U-net模型,初始学习率设置为0.000 1、批大小(Batch Size)设置为1、迭代轮次(Epochs)设置为30、采用BCELoss损失函数及Adam(adaptive moment estimation)自适应矩估计梯度优化器自动更新迭代网络内部参数。设置基于上述网络的金相图像晶界分割的对比实验,统计其相关的网络评价指标。
2.4 相关评价指标
本分割方法中由卷积神经网络分割出的晶界图像中包含两类目标,分别为前景(也即晶界,白色,像素值为1)以及背景(也即晶粒,黑色,像素值为0),统计预测得到的晶界图像以及测试集中对应的手绘晶界标签图像中各像素点的像素值,生成对晶界预测结果统计的像素值混淆矩阵,如表1所示。

表1 混淆矩阵
其中,晶界的像素值为1,晶粒的像素值为0,晶界为正样本,晶粒为负样本。则TP代表标签值为1,预测值为1;TN代表标签值为0,预测值为0;FN代表标签值为1,预测值为0;FP代表标签值为0,预测值为1;依据此混淆矩阵计算下述常用图像分割结果的评价指标:
2.4.1 准确率
准确率(Accuracy)是预测正确的样本数相对于所有的样本数的百分比(即预测对的像素点个数相对于所有像素点个数的百分比),对应语义分割的像素准确率PA,公式如下。
(7)
2.4.2 类别平均像素准确率(MPA)
类别平均像素准确率(mean pixel accuracy)为分别计算每个类别(即晶界和晶粒)被正确分类像素数的比例,然后累加求平均。
(8)
2.4.3 Dice系数
Dice系数是集合相似度度量指标,用于计算两个样本(即晶界和晶粒)的相似度。该系数取值范围为(0,1),取值越高,分割结果越好。
(9)
2.4.4 特异度(Specificity)和灵敏度(Sensitivity)
其中,特异度表示所有负例样本中被正确预测的概率,衡量对负类样本的识别能力(即对晶粒的识别能力),灵敏度表示所有正例样本中被正确预测的概率,衡量对正类样本的识别能力(即对晶界的识别能力),相应的计算公式如下:
(10)
(11)
2.5 实验结果
根据上述实验的实施细节,用训练集分别在U-net、U-net++、Attention U-net、以及改进的轻量型U-net卷积神经网络上进行训练,各模型训练30个轮次在训练集上的损失函数值变化曲线如图8所示。

图8 损失值对比曲线
根据实际训练过程中的损失函数值曲线可以看出,本文所提出的轻量型U-net的训练过程更好,损失值下降快并能快速趋于平稳下降状态。为了更直观的评价本文所提出晶界分割方法的有效性和优越性,图9为各网络在测试集上的实际预测结果示例,其中图9(a)为经预处理后的测试集图像,图9(f)为对应的手绘二值标签图像,图9 (b),(c),(d),(e)分别为由上述4个网络训练得到重文件对测试集中的金相图像进行晶界预测得到的晶界预测结果。为了更清晰的展示不同网络对测试集图像预测结果的差异,图9(g),(h),(i),(j)分别为将预测图像采用大津法(Otsu)二值化方法进行图像二值化处理后的预测结果。

表2 在上述4个网络上的相关实验结果

图9 测试集在各个网络上的实验结果
根据上述在不同网络上对测试集进行预测所得的晶界图像结果和测试集图像及标签图像对比,可以看出本文提出的改进的轻量型U-net卷积神经网络的晶界提取效果相较于其他网络模型更准确、实际的分割效果更好。
在各个网络模型上对测试集中的图像晶界预测实验结果指标统计如表2所示。
将表2所列不同网络模型上的实验结果评价指标绘制在柱状图上如图10所示。
根据实验统计结果,本文提出的轻量型U-net图像分割网络的像素准确率、类别像素准确率、特异度、灵敏度系数等均略高于其他几个卷积神经网络的分割结果,Dice系数值与其他网络的结果持平,且其网络参数量仅为2.99M,与U-net和U-net++相比,其网络参数量分别减少了61.5%和66.9%,网络参数量的减少有效的减少了模型的计算量,提高了对晶粒边界的分割预测速度。
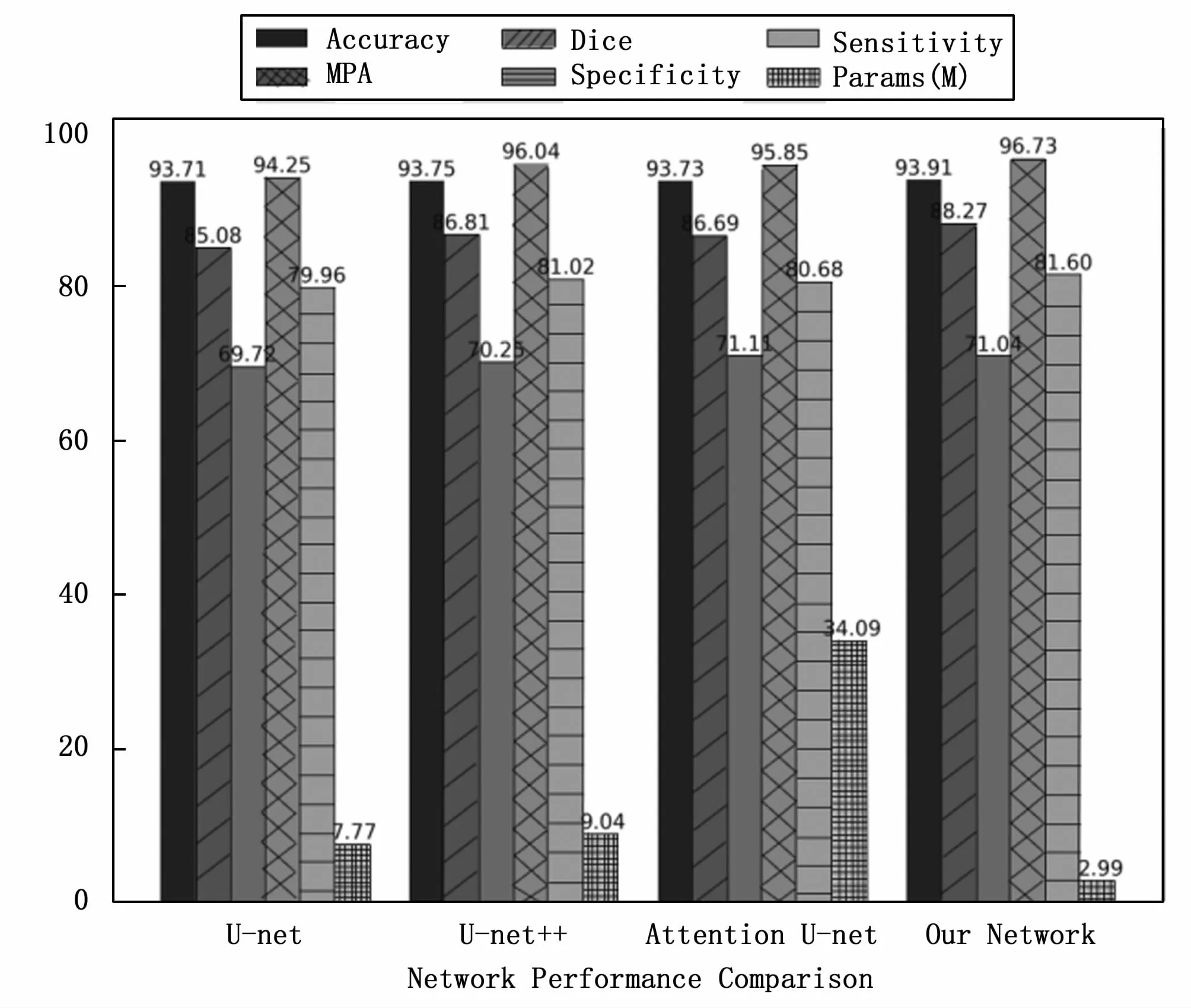
图10 网络参数指标对比
3 结束语
本文提出了一种基于轻量型U-net金相图像晶界分割方法,用于提高对钢材金相图像中晶粒边界的分割准确率和效率。主要结论如下:
1)针对U-net网络进行改进,减少了下采样层,并将每一个特征提取层中的两次卷积运算改为三次卷积运算,强化网络的浅层特征提取能力;在上采样过程中,对3个特征信息层进行跳跃连接,有效的减少了下采样过程中的特征信息丢失。
2)手绘了晶界标签,并对原始金相图像进行了预处理裁剪,建立了金相图像晶界分割的数据集,包含训练集图像1 404张,测试集图像117张。训练集和测试集的比例为12:1。
3)轻量型U-net图像分割网络在本数据集上的像素准确率(93.91%)、平均像素准确率(88.27%),Dice系数值(71.04%),特异度(96.73%),灵敏度(81.6%)。这些指标上均略高于Attention U-net、U-net++、U-net等图像分割卷积神经网络,同时其网络参数量大幅减少,仅为2.99M,网络参数量仅为U-net网络参数量(7.77M)的38.5%,网络参数量相对减少了61.5%;网络参数量仅为U-net++网络参数量(9.04M)的33.07%,网络参数量相对减少了66.9%。网络参数量的大幅减少可以有效提高网络的计算速度。
猜你喜欢
上海金属(2022年4期)2022-08-03
中国新技术新产品(2022年7期)2022-07-14
工程科学学报(2021年10期)2021-10-23
高技术通讯(2021年8期)2021-10-13
中成药(2019年12期)2020-01-04
世界有色金属(2019年4期)2019-05-11
山东工业技术(2017年9期)2017-05-16
凿岩机械气动工具(2016年3期)2016-03-01
上海金属(2015年6期)2015-11-29
上海金属(2015年1期)2015-11-28
