
基于WOA-XGBoost模型的网络入侵检测
2023-04-03 14:43:54闫海涛张之义朱晓明
计算机测量与控制 2023年3期
闫海涛,张之义,朱晓明,王 鹏
(中国电子科技集团公司 第54研究所,石家庄 050081)
0 引言
随着互联网技术发展和信息化建设的推进,使得政府和企业等组织机构越来越多的业务在线上处理,同时现有攻击方式发展的更加多样和隐蔽,来自内部和外部的网络安全事件频发,当前这些组织机构面临的安全风险变高。因此,需要更加高效的网络入侵检测技术[1]。对机构内部的用户和实体的行为检测,通过相应算法利用现有行为数据构建基线,能够高效的识别正常和入侵行为[2]。
网络入侵检测系统(NIDS,network intrusion detection system)根据所用的方法,可以分为基于误用的检测和基于异常的检测两类[3]。基于误用的检测是对攻击行为构建基线,符合该基线的行为都看作入侵行为,这类方法的误报率较低,但漏报率较高。基于异常的检测对正常行为构建基线,不符合基线的行为都看作入侵行为,这类方法能够识别未知的攻击模式,也是本文采用的方法。
相较于传统的防火墙系统,网络入侵检测系统对当前收集到的行为数据提取特征并与构建的正常行为基线进行比较,能够实时发现环境中的安全风险。最初的研究者基于统计学习方法,捕获并分析网络流量活动的统计特征进行入侵检测[4],但是误报率较高,而且经常需要专家经验辅助判断。
近年来,研究者通过引入机器学习,深度学习等技术进行入侵检测并取得了显著的提升效果[5-7],包括朴素贝叶斯算法(NB,naive bayes)[8],K近邻算法(KNN,k-nearest neighbor)[9],支持向量积算法(SVM,support vector machine)[10]和逻辑回归算法(LR,logistic regression)[11]等。然而在使用这些算法时,需要对数据的缺失值进行处理,在处理大规模数据时效率不高,仍然存在误报率较高和检测效率较低的问题。
集成学习(EL,ensemble learning)是近年来机器学习研究中的热门领域。极限梯度提升(XGBoost,extreme gradient boosting)是一种基于梯度提升决策树(GBDT,gradient boosting decision tree)改进的集成学习算法[12]。将XGBoost应用在网络入侵检测系统中得到了更高精度的检测效果[13]。文献[14]中,研究者将XGBoost算法应用到网络入侵检测,分析和评估了XGBoost模型相对于其他分类模型的优势。结果表明XGBoost相较于朴素贝叶斯,SVM和随机森林具有更好的准确率。
对于机器学习来说,模型的参数会在很大程度上影响其性能表现,一般采用穷举法来找到使模型表现最好的参数,但这种方法效率较低。研究者受到群居动物通过合作来完成复杂的任务的行为启发提出了一系列群体智能优化算法来求解优化问题,在分类任务上取得了较好的效果[15]。文献[16]中提出基于粒子群算法(PSO,particle swarm optimization)对SVM进行参数优化,应用到进行入侵检测任务中,提高了模型训练效率并实现了较低的误报率。文献[17]采用遗传算法(GA,genetic algorithm)对SVM的惩罚因子、核函数进行优化,明显缩短了检测时间,并在检测准确率上有所提升。文献[18]用递归消除算法去除冗余特征后,利用遗传算法来优化轻量级梯度提升机(LightGBM,light gradient boosting machine)的关键参数。文献[19]针对轴承故障诊断问题,结合鲸鱼优化算法(WOA,whale optimization algorithm)提出了一种基于深度学习特征提取和WOA-SVM状态识别相结合的故障诊断模型。对比了PSO-SVM和GA-SVM模型,结果表明WOA-SVM具有较高的收敛精度和速度。文献[20]提出了一种将WOA算法与相关向量机(RVM,relevance vector machine)相结合的模型。将WOA-RVM模型应用于天然气负荷的短期预测,该模型在预测精确度高于其他模型。
WOA算法作为一种结构简洁易于实现且适应性较强的算法,能有效避免陷入局部最优解的情况[21]。有研究者将WOA算法应用到入侵检测领域[22]。文献[23]提出使用WOA算法来优化RVM来进行入侵检测。在两个常用的入侵检测数据集NSL-KDD和CICIDS2017进行测试验证,结果表明WOA算法相较于其他优化算法如粒子群算法,遗传算法和灰狼优化算法(GWO,grey wolf optimizer)有更好的效果。文献[24]组合WOA算法和遗传算子作为SVM的参数优化方法,提出了WOA-SVM模型来检测无线Mesh网络中的入侵行为,同遗传算法进行对比,实验表明该模型有效降低了计算复杂度和检测时间,并且在检测效率上有较好的提升。
研究者提出了很多结合智能群体优化算法和机器学习算法的入侵检测方法,仍有一定缺陷。这些研究大都对模型进行整体评估,仅评估了算法在数据集上的整体表现,如准确率,精确率,F-Score等,却未对数据集中的每种攻击类型的分类效果进行评估分析。
本文结合智能群体优化算法和机器学习算法提出了WOA-XGBoost模型。模型利用WOA良好的搜索能力对XGBoost模型中的参数进行适应性的优化。有效的提高了其在入侵检测中的性能,包括对不同类别攻击的识别能力。其次,在评估WOA-XGBoost模型的性能时,使用NSL-KDD数据集[25],不仅评估了模型总体性能,还评估了模型对各个攻击类别的识别能力,并与XGBoost算法和其他集成学习算法包括随机森林(RF,random forest)、Adaboost和LightGBM进行了性能对比。实验结果表明混合模型对大部分攻击类别具有较好的效果。
1 WOA-XGBoost算法模型
1.1 XGBoost算法
XGBoost算法基于集成学习中的Boosting算法,Boosting算法通过累加多个弱分类器来组合成一个强分类器。一般采用决策树作为基学习器。XGBoost是在GBDT算法的基础上进行了改进,在优化目标函数时使用二阶泰勒展开式作为模型损失残差,提高了模型精度。并引入正则化项,更好地防止过拟合。使用前向分步加法训练来优化目标函数,这意味着后一步的优化过程依赖于前一步的结果。第t次迭代要训练的树模型为ft(xi),则本轮迭代预测结果为:
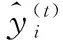
由于XGBoost是一个累加多个基学习器的模型,在模型的第t轮迭代中,目标函数可以表示如下:
(2)
式中,l表示第t轮迭代中损失函数,c为一个常数项,树的复杂度Ω将全部t颗树的复杂度进行求和作为目标函数的正则化项,正则化项的引入用于防止模型过拟合,Ω计算公式如下:
(3)
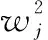
计算公式(1)的二阶泰勒展开式,得到如下结果:
obj(t)=
Ω(ft)+c
(4)
其中:g为损失函数的一阶导,h为二阶导,计算公式如下:
(5)
(6)
只要求出每轮g和h的值,然后优化目标函数,从而得到每轮迭代的决策树ft(x),最后累加所有的决策树,得到一个整体模型。
定义实例集:
Ij={i|q(xi)=j}
(7)
Gj=∑i∈Ijgi
(8)
Hj=∑i∈Ijhi
(9)
Ij表示将属于第j个叶子结点的所有样本xi划入到一个叶子结点的样本集合中,Gj表示叶子结点j所包含样本的一阶偏导数累加之和,是一个常量,Hj表示叶子结点j所包含样本的二阶偏导数累加之和,也是一个常量。
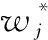
(10)
(11)
其中:wj表示节点的权重,obj表示损失函数的得分,分数越小,所得树的分类结果越好。
在建立第t颗树时,关键在于找到叶子结点的最优切割点,对目标函数obj,分裂后的收益Gain取得最大值时即为最优分割。分裂收益Gain的计算公式如下:
(12)
括号内前两项分别为左右子树的得分,第三项为不进行分割时的得分。
1.2 鲸鱼优化算法
鲸鱼优化算法由Mirjalili等人提出[21],他们受鲸鱼捕食猎物的启发,在观察鲸鱼群体搜寻、包围、抓捕和攻击猎物等过程后,提出了寻找猎物,包围猎物,螺旋泡网捕食的数学模型。每个鲸鱼的位置代表了一个可行解。最优解为猎物位置或者最接近猎物的位置。算法用搜索代理表示鲸鱼,在每次迭代中,搜索代理随机选择其他搜索代理的位置或当前最优搜索代理的位置作为目标来更新它们的位置。WOA算法的优化过程如下:
首先,随机初始化搜索代理位置Xi(i=1,2,…,n),其中,n为待优化参数的个数,计算每个搜索代理的Fitness。每一轮迭代中,按如下公式更新搜索代理位置:
X(t+1)=
(13)
其中:t是当前迭代次数,算法依概率p选择圆形围捕运动或螺旋运动接近猎物,参数b用于控制螺旋形状,l为[-1,1]的随机数。式中,D用于衡量当前搜索代理与目标搜索代理的距离,目标搜索代理为最优搜索代理或随机选择的搜索代理,D′表示当前搜索代理与最优搜索代理的距离,计算公式如下:
(14)
D′=|X*(t)-X(t)|
(15)
式中,X*(t)表示目前为止最优的搜索代理位置向量,Xrand(t)表示某个随机搜索代理位置向量,X(t)表示当前搜索代理的位置向量,A和C为系数:
A=2α·γ1-α
(16)
C=2·γ2
(17)
(18)
γ1,γ2为[0,1]之间的随机向量,收敛因子α在迭代的过程中线性的从2降到0,max_t表示最大迭代次数,α从2降到0的过程,控制了搜索代理从搜寻到捕猎的转换过程,与之对应的,当|A|≥1时,对应搜寻和包围猎物的过程,选择随机搜索代理更新当前代理位置。当|A|<1时,对应围捕过程,选择最优搜索代理更新当前代理位置。最后,WOA算法满足终止准则而终止。
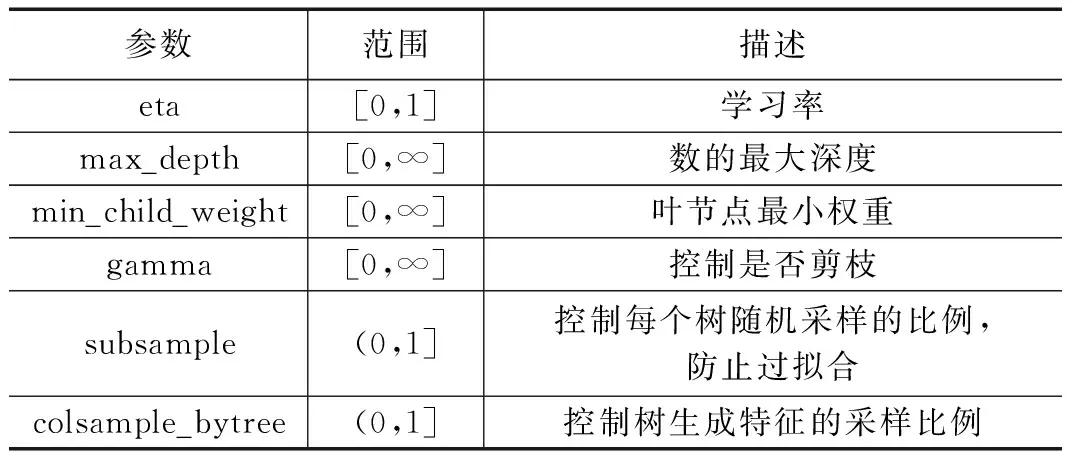
1.3 数据集和数据预处理
作为KDD-CUP99的优化版本,NSL-KDD数据集克服了数据集的固有问题。通过去除冗余和重复记录,降低了数据集中不平衡数据的影响。重新调整训练集和测试集中样本到合适的数量。数据集包括正常行为和四种攻击:Probe、拒绝服务攻击(DoS,denial of service)、本地未授权访问(U2R,unauthorized access to local super user)和远程未授权访问(R2L,unauthorized access from remote to local machine)。在每个攻击类别下包括多种攻击行为,如Probe类包含Nmap扫描、MScan扫描等。DoS类包含Neptune攻击,Teardrop攻击等。U2R类下包含缓冲区溢出攻击、Perl脚本攻击等。R2L类包括FTP密码猜解等。训练和测试数据中类别的分布分别如图1所示。
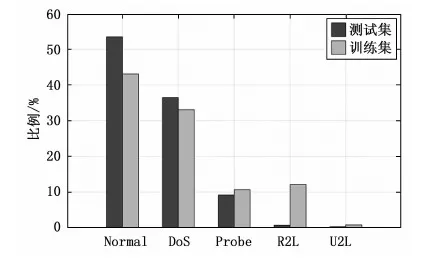
图1 数据样本分布统计图
数据集中包括了网络连接的基本属性特征和内容特征、基于时间和基于主机的网络流量统计特征。在数据集的41个特征中,有9个离散特征和32个连续特征。因为不同的特征可能有不同的测量方法,由于量纲的不同,数值型数据的数值偏差较大会影响梯度下降算法求最优解的速度,需要进行数据标准化处理。
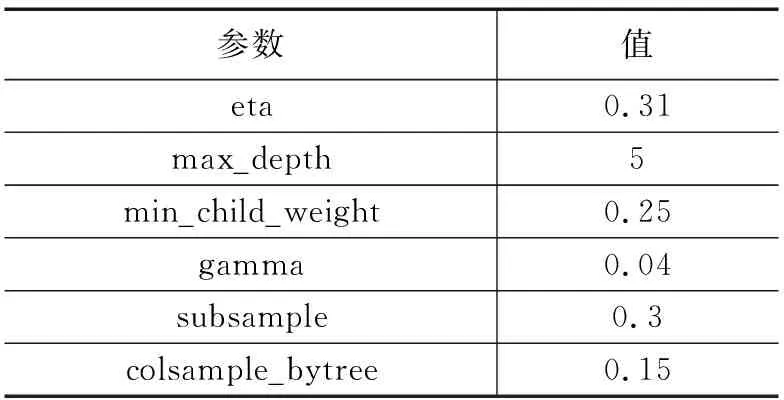
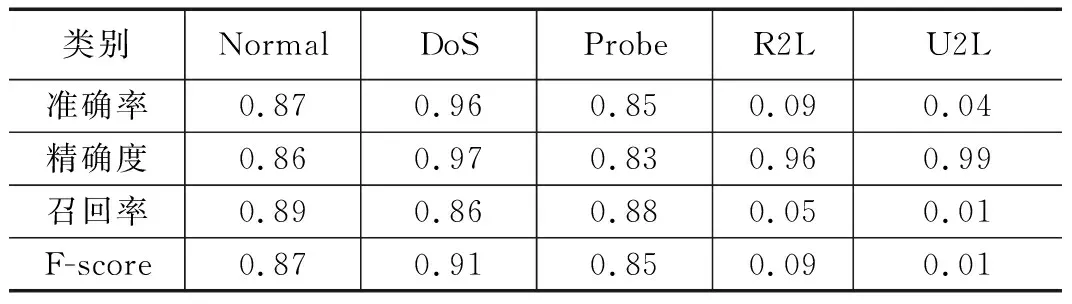
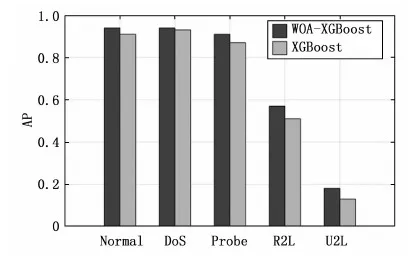
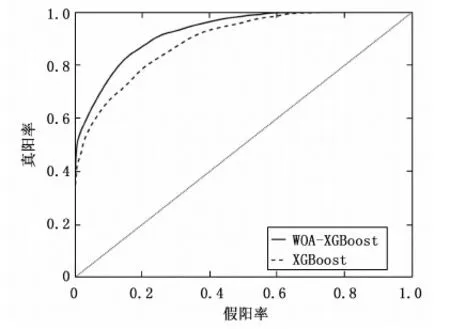
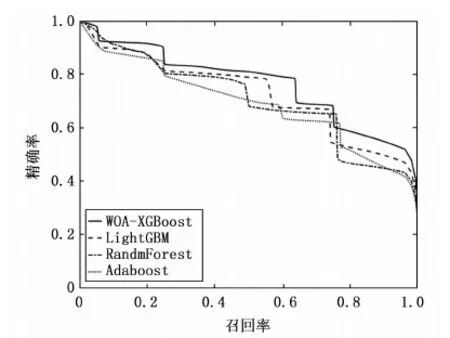
原始特征集合中第j个特征类型集合Xj中第i个元素的特征值xij其中1 (19) 式中,AVG(Xj)为第j个特征的均值,STAD(Xj)表示该特征的平均绝对值误差。 (20) 入侵行为的检测可以看作分类任务,将行为分为正常行为和入侵行为两类,对应分类任务中的正类和负类。本文除了使用分类任务常用的评价指标包括精确率(P,presession),召回率(R,recall),F-Score对模型进行评估,还使用了查准率-查全率(P-R,presession-recall)曲线和受试者工作特征曲线(ROC,receiver operating characteristic curve)进行评估。ROC曲线一般只能对模型的整体性能进行评估[26],P-R曲线相较于ROC曲线能够反应出模型在数据集中各个类别上的性能表现[27]。 受试者工作特征曲线通过设定范围从0到1的一系列阈值,得出的模型的一系列假阳率和真阳率数值对,作图得到ROC曲线,曲线越靠近左上角,ROC曲线下的面积(AUC,area under curve)也就越大,模型的整体表现也就越好。 P-R曲线通过设定范围从0到1的一系列阈值下,得到的精确率和召回率数值对的连线。相较于ROC曲线,P-R曲线能够反映出样本分布对模型的影响。平均精确度(AP,average precision)即为P-R曲线下的面积。某一类的AP值越大,表明模型在该类上的分类性能越好。使用平均精度均值(mAP,mean average precision)曲线和宏平均曲线描述模型在所有类别上的综合识别性能。 XGBoost模型包含通用参数和模型参数,通用参数包括booster、silent、nthread,这些不需要参数优化。模型参数作为本文优化的目标,对模型的性能有重要影响。实验中,使用鲸鱼优化算法对模型性能影响最关键的6个参数进行搜索优化,包括学习率eta,最大树深度max_depth、最小叶权重min_child_weight,剪枝参数gamma、样本随机采样参数subsample和样本列采样参数colsample_bytree。关于XGBoost这6个待优化模型参数的取值范围和参数的作用介绍见表1所示。 表1 XGBoost参数介绍 WOA-XGBoost模型的训练和参数的优化过程如图2所示。 图2 模型训练流程 首先,根据待优化参数个数确定搜索代理的维度,每个维度的分量对应不同的XGBoost参数,因此,这里每个搜索代理是一个6维向量。各维度参数的取值范围限定了WOA的搜索空间。第i个搜索代理在t轮迭代的位置向量可以表示为: (21) 然后将位置向量赋给模型的相应参数,并将训练集上的表现作为初始Fitness值。第i个搜索代理在t轮迭代中,根据当前的系数A,C,p和公式(13),更新位置,并计算当前的Fitness值为: Fi(t)=(Xi(t)→XGBoost|trainset)[metric=PR-curve] (22) 每轮迭代后确定当前最优搜索代理: Xbest(t)=max(Fi(t),Xbest(t-1)) (23) 算法不断迭代直到满足终止条件,输出当前最优搜索代理的位置向量,即为XGBoost模型具有最好分类能力的参数。 鲸鱼优化算法本身的参数主要包括a,b。关于实验中主要参数的初始设置和介绍如表2所示。 表3给出了经过鲸鱼优化算法搜索得到的XGBoost模型的最优参数。这组参数将用于后面的实验环节。 表2 鲸鱼优化算法参数 表3 XGBoost最优参数 实验所用的配置介绍如下:CPU为Inter Xeon E5-2666v3@2.5GHz,内存64GB,操作系统为Centos7 64位,使用Python3.7和Matlab2016进行编码实现。利用1.5节中所得XGBoost模型的最优参数进行实验评估。将WOA-XGBoost算法在NSL-KDD测试集进行验证,在各类样本上的性能指标如表4。 表4 模型评估结果 从这些指标中可以看到模型在DoS类的检测的准确率最高,说明模型能准确区分DoS类和非DoS类。U2L类的检测精确度最高,说明被模型识别为U2L的样本都来自U2L类。Normal类上的召回率最高,意味着大部分正常行为都被正确识别,但U2R召回率最低,即大量U2R类的样本被识别为其他类,这与数据集中该类样本数量较少有关。F-Score可以很好地平衡精确度和召回率,能够评估模型的综合表现,可以看出模型在Normal,Probe和DoS上的分类性能较好,而在后两个样本数量较少的类上表现不佳。 根据模型在每个类别中的P-R曲线,计算得出每个类的AP指标。如表5所示。 表5 每个类别的AP指标 从表5中,可以看出,Normal、Probe和DoS上的AP值高于其他两个类。主要原因是NSL-KDD训练集中Normal、Probe和DoS样本占总数据的99%以上,而U2R和R2L占不到1%。导致模型能够对样本数量较多的类别学习更多细节特征,却无法学习U2R和R2L的一些潜在的特征,因不能很好地对U2R和R2L分类。此外可以发现AP值与F-Score呈正相关。类的F-Score越大,意味着模型对它的分类性能越好。 WOA-XGBoost和XGBoost在测试集上对各类行为检测结果的AP指标对比如图3所示。 图3 模型在各类上的AP指标 从图中可以看出,两个模型对Normal、Probe和DoS都有很好的识别效果,但在R2L和U2L上都表现较差。WOA-XGBoost模型相较于XGBoost在每个类中的AP值都更高,这说明通过WOA算法有效提高了模型性能。 为了对比两个模型在所有行为类别上的综合性能,统计了模型的宏平均曲线和mAP曲线如图4~5所示。 图4 宏平均曲线 图4和图5中,WOA-XGBoost始终在XGBoost的左上方或右上方,WOA-XGBoost模型的宏平均曲线和mAP曲线下面积均大于XGBoost,其中宏平均曲线下的面积比XGBoost大约3%,而mAP曲线的面积则比XGBoost大约4%,说明WOA-XGBoost在整体上优于XGBoost模型。 可以发现,WOA算法可以有效地优化XGBoost模型的参数,在提高模型训练效率的同时,学习更优的参数,提高模型的分类性能。在网络入侵检测任务中,对参数的进一步优化可以较好的提高系统检测能力,能够更准确的识别攻击类型以及更好的检测未知攻击。 为了验证模型的性能,本节对比其他机器学习算法包括随机森林,LightGBM和Adaboost算法,同样使用上述评价指标。选择NSL-KDD数据集,使用由P-R曲线计算的AP指标对每个类别的评估。结果如图6所示。 从图6中可以发现,在Normal、DoS和Probe类上,WOA-XGBoost、LightGBM和随机森林之间的性能差距不大。WOA-XGBoost在Normal和Probe类上的AP值最高,其次是LightGBM和随机森林。在DoS类上LightGBM和随机森林取得最高的AP值,比WOA-XGBoost高1%。在R2L和U2R类上,WOA-XGBoost比其他模型具有明显优势。在R2L类上,WOA-XGBoost的AP值比Adaboost高17%。在U2R上,WOA-XGBoost表现最好,其次是LightGBM,WOA-XGBoost的AP值比LightGBM高9%。综合来看所有模型在具有大量训练样本的Normal、Probe和DoS类都具有较好的识别效果,由于R2L和U2L类在训练集中的样本较少,导致所有模型在这两类上的识别效果都比较差。 对比四个模型在所有行为类别上的综合性能,统计了模型的宏平均曲线和mAP曲线如图7和图8所示。 图8 mAP曲线 在图7和图8中,WOA-XGBoost的宏平均和mAP曲线在其他模型的左上方或右上方。随后分别是LightGBM、Random Forest和Adaboost。可以看出,经过参数优化后的WOA-XGBoost模型综合表现较好。意味着WOA-XGBoost模型相比其他模型来说,对各类入侵行为的检测精确度高,误报率更低,识别未知攻击的能力较好。WOA算法提高了模型的整体性能。 XGBoost算法可以很好地完成对攻击行为的多分类任务。WOA算法能够简洁高效的完成机器学习算法中的参数优化问题。因此本文提出使用WOA来优化XGBoost中的参数。实验结果表明模型相较于其他算法LightGBM、随机森林和Adaboost,有较快的学习速度和较好的分类精度,模型的综合表现较好。 但研究仍存在可进一步改进的地方。XGBoost算法在选择最优分割点时遍历所有数据,进行基于逐层生长的策略,会产生很多分裂增益较低的叶子,增加了计算开销。对于WOA算法,算法中的自适应位置选择策略使WOA能够避免陷入局部最优。然而于随机机制的存在使算法存在收敛速度慢、收敛精度低等缺点,这些都是需要进一步改善的地方。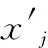
1.4 模型评估
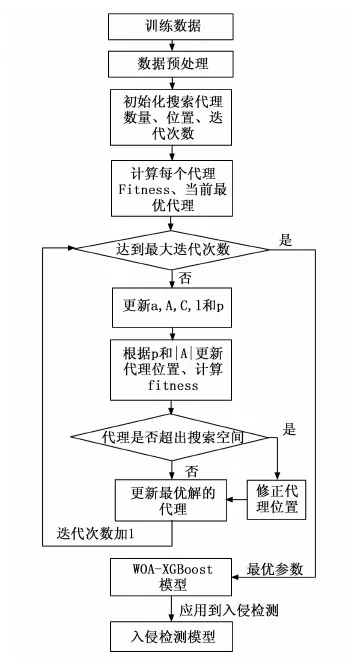
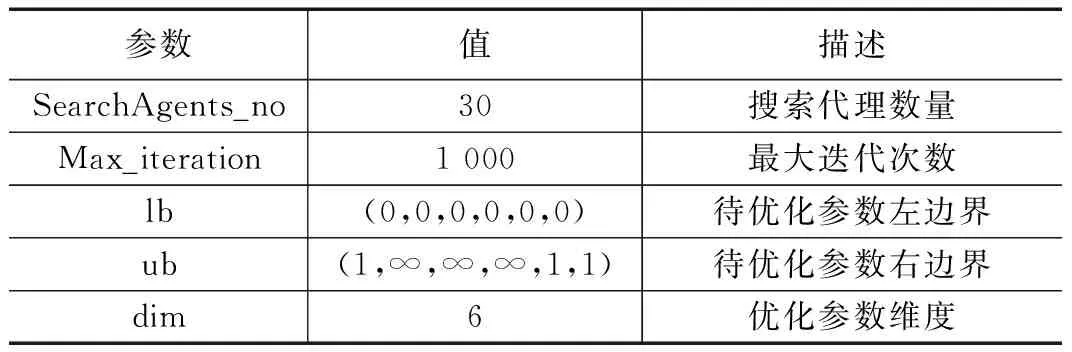
1.5 模型训练与优化
2 实验结果与分析
2.1 实验步骤

2.2 对比XGBoost模型
2.3 与其他模型的对比
3 结束语
猜你喜欢
幼儿100(2022年41期)2022-11-24 03:20:20
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
数学大王·趣味逻辑(2020年9期)2020-09-06 14:17:17
小天使·二年级语数英综合(2019年4期)2019-10-06 02:44:36
趣味(数学)(2018年12期)2018-12-29 11:24:00
动漫星空(2018年4期)2018-10-26 02:11:54
现代营销(创富信息版)(2018年8期)2018-09-08 08:51:50
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
数学学习与研究(2017年3期)2017-03-09 18:12:42
学生天地(2016年23期)2016-05-17 05:47:15
