
数智驱动背景下全域产业数据治理能力提升路径研究
2023-03-29 00:00:53魏明珠郑荣雷亚欣等
现代情报 2023年4期
魏明珠 郑荣 雷亚欣等


关键词: 全域产业数据治理; 非对称创新; 定性比较分析; 必要条件分析
DOI:10.3969 / j.issn.1008-0821.2023.04.003
〔中图分类号〕G203 〔文献标识码〕A 〔文章编号〕1008-0821 (2023) 04-0017-11
数字经济时代, 数据作为要素积累、战略规划、模式创新等活动的动力之源, 成为经济发展中的关键生产要素。要发挥数字经济优势, 加快产业数字化、智能化转型, 提高产业链供应链稳定性和竞争力, 需充分发挥产业数据效能。全域产业是指某一省级或市级行政区的全部产业集合, 对全域产业进行数据治理, 能够促进数据发挥更大价值, 尤其是政府掌握更多数据资源的情况下, 基于数据协同与共享, 通过精准的数据治理, 促使数据对全域工业、金融、商贸及政务等各个产业均发挥重要作用。从宏观角度出发, 区别于以往的单一影响因素识别为基础的传统数据治理, 全域产业数据治理属于复杂治理问题。在多任务和多场景背景下, 省级产业科技资源优化的合理配置问题、信息技术应用深度推广问题和产业数据治理效能提升问题, 是我国产业发展优化和产业数字化转型的重点和难点,同样也是全域产业数据治理目标的重点与难点。从微观角度出发, 在“大物云智移” 等技术愈发成熟的今天, 我国各产业对于数据公开、共享、增值和利用的需求越来越大, 与此同时, 庞大的数据量也给政府、产业本身、产业中的企业等主体的传统数据治理模式及产业数据管理、整合、监督和分析带来了新的困难。我国各省级区域在产业发展阶段和资源储备上存在巨大差异的背景下, 如何有效利用庞大的数据量也成为全域产业数据治理的难点。因此, 本研究探索性地提出全域产业数据治理论题, 通过对整个区域产业运行过程中数据要素进行计划、监督和执行, 对“产业数据要素管理的管理”, 以解决当前存在的问题。以31 个省级行政区的全域产业(非某一特定产业)数据治理为实践背景, 探索不同省级区域之间的产业数据治理能力差异, 对各省级政府提升全域产业数据治理能力提供合理化建议, 赋能产业数字化、智能化发展。
1相关研究与相关概念
1.1相关研究
数据治理的概念最早诞生于企业和各类组织,一方面是对数据本身的治理; 另一方面是依数据的治理[1] 。目前, 大多数研究聚焦于政府数据治理。从政府平台、业务流程、信息基础设施等要素出发, 将政府数据碎片化管理提升至整体化数据治理[2] , 从而提出整体性政府数据治理的概念[3] ,由此构建数据治理标准化协同路径[4] 。同时, 以应用场景和治理困境为出发点, 剖析政府数据治理的发展方向[5] , 最终提出数据治理在治理主体层面、技术层面、数据层面、业务和服务层面遵循协同共享的发展路径[6] 。目前针对数据治理能力的研究大多集中在数字政府建设(技术管理能力、注意力分配)[7] 、政府公共卫生治理实践(技术、组织、环境)[8-9] 、政府数据治理绩效(物理维度、事理维度、人理维度)[10] 等多重影响因素方面。可以发现, 目前数据治理研究为政府各类治理工作提供了丰富的解释, 但大多聚焦于某一类型的数据治理, 侧重概念梳理和界定, 且更多体现于对数据本身的治理以及借助数据对具体问题的解决方案, 未能充分拓展数据治理的应用场景, 针对产业发展这一特殊场景的适用性还不够。因此, 本文在政府数据治理研究基础上, 延伸产业数据治理的应用场景, 重点研究区域范围内产业数据的协同治理与应用效能的提升问题。由于产业相关数据治理隶属于数据治理体系, 数据对象虽聚焦在产业运行过程中的各类数据要素, 也同样可以借鉴政府数据治理的相关体系框架、模型及方法。本文从组态视角, 采用定性比较分析(QCA)与必要条件分析(NCA)相结合的研究方法解决多重因素的协同效应, 试图进行以下3 个方面的研究: ①探寻以“殊途同归”的方式推动各省级政府的全域产业数据治理能力提升的所有条件组态; ②探寻对全域产业数据治理能力提升更为重要的条件或条件组合; ③探寻条件变量之间的替代关系。
1.2数智驱动背景下全域产业数据治理能力的内涵
本文聚焦全域产业数据治理, 即各省级政府聚焦数据价值的挖掘, 利用“大物云智移” 等智能技术与工具, 通过对数据使用的过程进行监督、评估、指导和执行, 不断挖掘数据潜力, 促使数据赋能、赋智工业、金融、商贸及政务等全域产业发展的新业态与新模式。从治理主体来看, 是以政府为主导,由产业本身、产业中的相关企业个体、高校科研机构和第三方机构等多元主体共同参与; 从治理对象来看, 产业相关数据作为主要治理对象, 包括产业竞争情报文件、产业开源文本、政府或非政府组织数据相关政策、泛在数据等; 从治理手段来看, 从“技术支撑服务” 的角度将技术嵌入全域产业数据治理结构中; 从治理目标来看, 强调充分利用海量数据, 更好地解决復杂的产业发展和规划问题, 为全域产业发展提供数据支撑和数据源动力。数智驱动背景下全域产业数据治理能力是以“数据” 和“智能技术” 为驱动进行数据治理, 是在产业数字化、智能化转型过程中对全域产业数据治理水平的测度, 直接体现在各省级政府通过大数据的收集、加工、分析及应用, 赋能产业数字化发展的程度。
1.3数智驱动背景下全域产业数据治理能力的影响因素
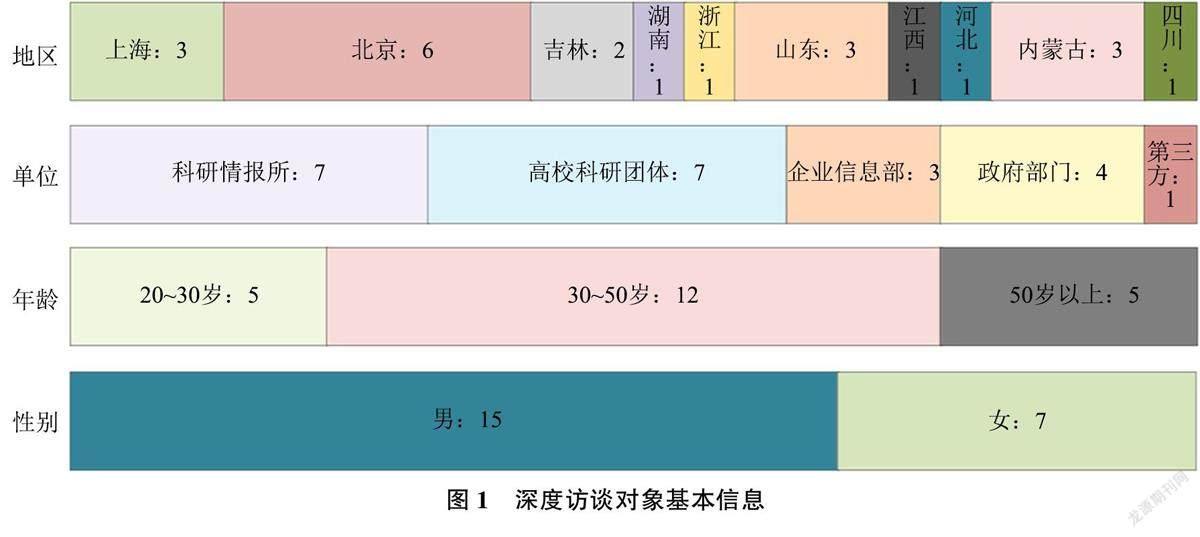
由于目前对全域产业数据治理能力影响因素的相关研究较少, 因此, 通过深度访谈提取其影响因素。访谈对象的限定条件为: ①有过开展产业数字化、智能化工作的相关经验; ②在产业数据“收集—加工—分析—服务” 4个环节中有过相关的经验; ③受访人员的职业、地域具有一定的差异性。最终选择研究或从事产业数据分析工作或从事数据治理工作的相关政府部门、企业信息部门、高校科研团体、科技情报所及第三方咨询机构的22名受访人员, 访谈对象信息如图1 所示, 访谈提纲如表1所示。
汇总访谈资料发现: 相关政府部门认为, 政策顶层设计、“双资(资源与资金)” 均会影响数据治理能力; 企业信息部门认为, 企业及产业的数字化发展是接受数据治理的关键; 高校科研团体、科技情报所及第三方咨询机构均认为, 用户对产业数据治理的重视程度、用户需求表达的准确程度是产业数据治理质量的决定性因素, 同时, 科技情报所强调大数据高精尖人才、专业复合型人才及资金投入是实现数据治理必不可少的“利器”, 高校科研团体强调技术设施及如何准确应用大数据智能技术解决问题也是全域产业数据治理过程中需要重点关注的内容。对访谈资料进行关键问题聚类和提取, 并借鉴前人研究, 最终总结出政策环境建设、资金投入强度、资源聚合水平、组织建设水平、产业数字化发展水平、用户意愿及需求、人才智力保障、技术基础设施及技术应用能力9个数智驱动背景下全域产业数据治理能力影响因素。为保证指标准确性, 笔者对保留的两份访谈资料进行分析, 未发现新的二级指标, 通过理论性饱和检验。
2理论基础与研究框架
2.1非对称创新理论
非对称创新理论是由中国学者魏江等人提出,聚焦中国情境特征, 探索中國企业的非对称创新追赶路径[11-12] 。“非对称” 聚焦中国情境, 具有资源与路径两层含义。一方面是指强政府制度、大市场形态与弱技术体制3 个方面的特殊资源; 另一方面是指充分利用上述“非对称” 资源要素, 并将其发展为本身的竞争优势。强政府制度主要以政府为主导, 通过控制和分配资金、技术等核心要素供给驱动引领创新方向。14 亿人口红利带来宏大的市场规模, 区域间发展水平的“势能差” 满足从低端到高端的阶梯式全链条的市场。弱技术体制是中国长期以来技术落后的积弊[13] 。该理论想要突出强调的是中国情境下共通的价值, 不仅仅局限于企业或产业,聚焦全域产业数据治理的具体情境, 各省级政府同样拥有强政府制度、大市场形态与弱技术体制3 个方面的特殊资源。而具有差异性数据治理水平的省级政府需要充分利用非对称资源, 逐步提升全域产业数据治理能力, 从而促进产业整体发展。因此,非对称创新理论适用于我国全域产业数据治理的研究, 既能够有效体现相当长时间内我国产业创新发展的特殊国情, 又可以通过区域发展的差异性路径探寻今后我国产业数据治理能力提升的实施路径。
2.2研究框架
组态分析中TOE框架(技术、组织、环境)、WSR理论(物理、事理、人理)是较为常见的研究框架, 但都不能够完整地表征全域产业数据治理能力。根据前期的实际调研和访谈结果可知, 在数智驱动和复杂治理的大背景下, 全域产业数据治理离不开制度的规范、技术的牵引和市场的赋能, 因此基于非对称创新理论构建“制度—市场—技术”三维组态框架, 如图2所示。
2.2.1制度维度
制度环境是全域产业数据治理“施展拳脚” 的组织基础。制度环境细分为政策环境建设、资金投入强度、资源聚合水平及组织建设水平4 个二级指标。立足中国制度的特殊情境, 产业发展的部分核心要素掌握在政府手中, 政府通过组织建设、设计政策顶层导向、投入资金支持、聚合多方资源等方式宏观调控要素分配及约束产业主体行为, 赋能全域产业发展。产业层面的各项活动都与政策制度联系十分紧密, 对政策的变化和演化趋势更加敏感。资金投入强度能够间接体现重视程度。数据资源是产业发展新的生产力要素, 是产业数字化发展的重要利器。在政策环境复杂化、持续加大资金投入强度、聚合多种资源等多因素的共同作用下, 组织建设充分发挥了战斗堡垒的作用, 对全域产业数据治理能力具有推动作用。
2.2.2市场维度
立足中国情境, 大国市场优势明显, 我国数据治理市场具有较大的发展潜力, 但也具有不均衡性和动荡性。如不同区域的产业数字化发展水平差异显著, 大数据相关产业载体建设情况不尽相同, 因此, 影响决策主体对数据治理的观念意识, 从而导致产业主体对数据治理需求差异化。市场的高度动荡间接促使人才流动。产业数字化发展水平、多元产业主体意愿及需求、人才智力等各种市场要素联动并发挥交互作用, 进而触发或阻碍全域产业数据治理能力, 从而影响产业整体发展。
2.2.3技术维度
数字化、智能化的产业建设必然对技术水平有所依赖, 创新数据治理相关技术方法和工具是实现产业数字化发展的有力支撑。技术基础设施建设是全域产业数据治理发展的基础, 只有提升信息基础设施就绪度、优化数据平台构建, 才能确保相关技术手段与工具在全域产业数据治理过程中发挥有效作用。技术应用能力是数据治理目标完成质量的决定性因素。确保足够的技术积淀和保障条件, 有助于实现产业多元主体、多类型数据资源和产业创新深度融合, 有效提升对产业数据资源的鉴别、筛选、综合研判水平, 全面优化数据治理过程。
3研究方法与设计
3.1研究方法: QCA与NCA相结合
必要与充分因果关系是两种新兴的因果关系解释。QCA 以集合论为研究基础, 结合定性与定量方法, 探究研究问题因果关系的充分性与必要性,根据必要条件分析及组态分析解释结果背后的因果复杂性[14-15] 。NCA 是基于复杂因果关系的一种全新的必要条件分析法[16] 。QCA 虽然可以定向判断前因条件对于结果是否必要, 但无法定量表示必要程度,通过NCA 可以定量分析必要条件的效应量以及作为必要条件的瓶颈水平[17-18] 。因此, NCA 可以补充传统的基于回归的数据分析及QCA 方法[19-20] 。本文以NCA 为必要条件的辅助研究方法精准推断全域产业数据治理能力的瓶颈标准, 以QCA 为充分条件的主导研究方法探究制度—市场—技术三维组态下全域产业数据治理能力背后的因果复杂性。
3.2数据来源及校准
3.2.1结果变量
研究聚焦各省级政府的全域产业数据治理能力, 利用各省级政府的行业应用指数测度全域产业数据治理能力, 该指数包括政务应用、工业应用、民生应用及重点行业应用4 个维度, 表示各省级政府利用大数据技术, 融合多源产业数据, 提升工业、金融、政务、商贸、电信、制造业等各产业领域的竞争优势, 赋能全域产业数字化发展。
3.2.2条件变量
条件变量由研究框架的3个维度细分所得。参考已有文献, 依据国家统计局的《中国科技统计年鉴2021》、中国电子信息产业发展研究院、中国大数据产业生态联盟的《中国大数据区域发展水平评估报告2021》收集整理相关数据。
1) 政策环境建设。以政策环境指数测度各省级政府的政策环境建设, 该指数以相关政策数量、类别(规划、监管、激励)为测度内容。只有政策保障持续优化, 才能共同发力数据要素价值创造, 从而为全域产业数据治理提供更好的政策环境基础。
2) 资金投入强度。以R&D 经费投入强度来测度。R&D 活动是指为增加知识总量, 以及运用这些知识去创造新的应用而进行系统的创造性的活动。将R&D 经费与GDP 比值作为资金投入强度的衡量指标, 它反映了不同省级政府对全域产业数据治理的资金支持力度。
3) 资源聚合水平。以产业发展指数作为衡量指标。该指标计算包含了产业规模、企业数量、大数据技术与专利数量、数据开放平台等相关内容。它体现了各省级政府将传统产业基础与新兴技术演进趋势谋篇布局的程度, 即全域产业数据资源聚合水平。
4) 組织建设水平。以组织建设指数作为具体的衡量指标, 即各省级政府的大数据管理机构设立情况与工作内容。该指标以大数据管理机构不断下沉促进组织保障日益完善, 体现了不同省级政府进行全域产业数据治理时组织建设水平。
5) 产业数字化发展水平。以集聚示范指数作为衡量指标, 即国家大数据综合试验区、大数据相关产业载体、大数据新型工业化产业示范基地等建设情况, 以相关产业的数字化特色聚焦, 效应凸显, 体现了不同省级政府进行全域产业数据治理时产业数字化发展水平。
6) 用户意愿及需求。用户意愿及需求是从产业数据治理需求方出发, 产业主体对数据治理意愿越强烈, 资金投入比重越大, 采用R&D经费外部支出作为衡量指标, 该指标是指委托外单位或与外单位合作进行R&D活动而拨给对方的经费, 体现了产业数据治理需求方接受产业数据治理的意愿与需求程度。
7) 人才智力保障。以智力保障指数作为衡量指标, 即大数据相关领域专业人才培养情况和人才拥有数量, 体现全域产业数据治理的人才智力水平, 保障数据治理质量。
8) 技术基础设施。以信息基础设施就绪度作为衡量指标, 包括5G基站数量、IPV4 比例及固定宽带接入用户占比等, 它反映了各省级政府的技术基础设施水平。
9) 技术应用能力。以大数据发展水平指数作为衡量指标, 该指标主要包括基础环境、产业发展和行业应用等相关要素, 能够体现全域产业数据治理的技术应用能力。
3.2.3变量校准
数据校准是将原始数据转换成带有集合特点的数据, 校准后的集合隶属度介于0~1 之间。使用Ragin C C[21] 提出的较为常用的直接校准法, 分别将选取95%、50%及5%分位数作为集合完全隶属、交叉点及完全不隶属锚点, 具体如表3 所示。
4结果分析
4.1NCA必要条件分析
NCA 利用x-y散点图中的上限线(Ceiling Line)划分无观测值区与可观测区, 以上限线之上的空白区域(Ceiling Zone) 来判断x 条件的必要性(非充分)[7] 。换言之, NCA 是通过x 对y 的抑制效果来确定x 条件的必要程度, 即空白区域面积越大, x条件对y 的必要程度越大, 结果如图3 所示, 根据图中的空白区域可直观判断x 对y 的必要程度。采用回归上线技术(CR)与包络上限技术(CE)两种上线分析技术对前因条件进行分析, 如表4所示。
NCA 要求必要条件必须满足两个标准: ①效应量不低于门槛值(d =0.1); ②蒙特卡洛仿真置换检验显示效应量显著, 即d≥0.1, p<0.05[17] 。综上, GG2、GG3、MM1、MM2、MM3、TT1、TT2 均是全域产业数据治理能力的必要条件(不充分),其中TT1、MM3、MM2、GG3、GG2、TT2(以CR方法为准)尤为显著, 且效应量依次增大。
必要条件瓶颈水平结果通过瓶颈效应量表示当结果变量y 达到观测范围内的某一水平(%)时, 条件变量最少要满足的水平(%)。例如要达到总观测范围内全域产业数据治理能力水平的80%, GG1 至少要达到33.3%水平, GG2 至少达到63 4% 水平,GG3、GG4、MM1、MM2、MM3、TT1、TT2 分别至少要达到各自的71.9%、30.2%、54.8%、67.1%、65.6%、64.6%、77.6%的水平。而要满足全域产业数据治理能力的10%, 只有GG2 是必要条件,其他条件都不必要, 表明GG2 是提升全域产业数据治理能力的基础必备条件。
4.2 QCA 必要性检验结果
进一步采用QCA 方法检验条件变量的必要性,结果如表6 所示。一致性阈值设为0 9, 高于0.9的条件变量视为必要条件, 可以独立解释结果变量。由表6 可知, 不存在导致高全域产业数据治理能力的必要条件。
由于NCA 要求前因条件为真正的原始测量变量, QCA 需要将条件变量进行校准, 不是属性本身程度的量化, 而是判断某个性质是否存在的信心值, 因此NCA 与QCA 对必要条件的判断标准不同。其次, QCA 以散点图对角线为参考线, 而NCA 的上限线分析会形成带截距的参考线, 上限线可能会向上移动或旋转[13] 。因此, QCA 必要条件分析的结果集是NCA 的子集, 通常前者比后者少, 二者互证互补, 并不冲突[17] 。
4.3条件组态的充分性分析
运用fsQCA3.0软件对导致高全域产业数据治理能力的条件组态进行分析。可以得到简单解、中间解和复杂解, 为了保留必要条件, 防止被简约解简化, 最终报告中间解。简约解与中间解同时出现的条件为核心条件, 仅在中间解中出现的条件为边缘条件[22] 。借鉴以往研究, 设置充分性的一致性阈值为0.8; 频数阈值为1; PRI(子集关系一致性)阈值为0.7, QCA 组态结果如表7 所示。根据6个组态的核心条件及背后案例的解释逻辑, 本文确定了5 条数智驱动背景下全域产业数据治理能力的提升路径, 下文将结合相关理论和对应的案例进行具体诠释。
5数智驱动背景下全域产业数据治理能力提升路径
5.1结构优化型路径
组态1和组态2均显示了资金投入强度、资源聚合水平、用户意愿及需求和技术基础设施作为核心条件, 产业数字化发展水平与技术应用能力作为边缘条件存在时, 通过人才聚集作用弥补政策环境建设与组织建设水平时, 带来高全域产业数据治理能力。“制度—市场—技术” 3 个维度均突出作用。首先, 强大的资金支持及丰富的数据资源是数据治理的发展筑基, 资金与资源双驱动体现强政府制度的服务优势; 其次, 成熟完善的大市场机制为资源合理配置营造了良好的环境。在高速推动产业数字化发展的加持下, 服务需求方对产业数据治理的重要性认识进一步加强, 用户多方面、多层次、立体化的需求明确, 为实现数据精准赋能产业发展奠定基础; 第三, 成熟的竞争性市场机制驱动人力要素与资金要素聚集整合, 使得全域产业数据治理过程实现良性循环; 最后, 良好的技术基础设施与技术应用能力是稳步推进数智驱动背景下全域产业数据治理能力的重要保障, 为数据治理能力的提升提供了要素支持。充足的人才要素禀赋补充了政策环境建设与组织建设的不足, 此时, 既有的技术能力实现了对政策与组织环境的“智力服务补偿”, 使得政策环境和组织建设整体作用不显著。该路径结果验证了“制度—市场—技术” 三维要素对全域产业数据治理能力的积极作用, 符合该路径的省份主要围绕东部地区及川渝经济圈分布并呈区域聚集性。包括以北京为中心的环渤海经济圈(北京、天津、山东), 以上海为中心的长三角经济圈(上海、江苏、浙江), 以广东为中心的泛珠三角经济圈(广东、福建), 以成都和重庆为中心的川渝经济圈(四川、重庆)。以江苏省为例, 沿海经济发达,政府资金丰厚, 产业发展势头迅猛, 在“制度—市场—技术” 三方面发展尤为均衡, 发布《江苏省工业大数据发展实施意见2020》, 充分释放工业数据价值, 建设南京雨花软件园等新型工业化产业示范基地, 相关从业人员规模逐年上涨, 并在数据资源聚集中具有先发优势, 全域产业数据治理在工业及重点行业应用中凸显“头雁效应”, 相互协同均衡下, 由此形成具有辐射效应的全域产业数据治理能力。湖北省毗邻川渝经济圈, 有着相类似的发展特征, 伴随国内大数据重点企业的落户和人才培养体系的完善, 大数据发展潜力巨大, 有望成为产业数据发展应用新增长点。可借鉴四川、重庆的做法, 推动产业数字化从无到有、由大变强, 从进企业、入园区到联通更多产业集群, 同时政府与公共服务部门充分考虑服务需求, 推动大数据发展应用, 从而进一步提升全域产业数据治理能力。
5.2用户需求牵引下资金和技术驱动型路径
组态3中, 高资金投入强度、非高产业数字化发展水平、高用户意愿及需求、高人才智力保障及高技术基础设施为核心条件, 互补高组织建设水平、非高政策环境、非高资源聚合水平及非高技术应用能力为边缘条件, 可以产生高全域产业数据治理能力。该组态中, 以用户需求为牵引, 政府发挥积极作用, 给予足够的资金支持, 以人才及技术为抓手, 满足用户需求, 实现全域产业数据治理。处于这类全域产业数据治理的省份主要为湖南省。尤其在深度访谈时, 湖南省科学技术信息研究所的工作人员强调, 湖南情报所通过检验检测、文献服务等引流方式强化用户接受情报服务意愿, 细化不同产业的数据治理需求, 同时汇聚产业协会、第三方机构等专业人才, 形成“资金扶持—用户需求牵引—技术人才保障” 的良好产业数据治理模式,符合本文用户需求牵引下资金和技术驱动型全域产业数据治理能力组态解的典型特征。黑龙江省与吉林省在产业数字化发展水平方面仍有较大进步空间, 因此可借鉴该路径, 以地域特色需求為牵引,通过人才+技术的双轮驱动, 发展农业生产数字化、农业农村信息化等, 推动全域产业高质量发展。
5.3产业数字化助力下制度与市场强化型路径
组态4指出, 高政策环境建设、高资金投入强度、高用户意愿及需求、高人才智力保障及高技术基础设施为核心条件, 互补高产业数字化发展水平、非高资源聚合水平、非高组织建设水平及非高技术应用能力为边缘条件, 可以产生高全域产业数据治理能力。该组态中, 产业数字化的辅助作用凸显, 通过相关政策大力扶持, 推动市场要素铺进,在制度和市场双驱动下, 利用高人才智力及相应技术基础设施, 充分发挥产业大数据价值, 促进产业数字化发展。符合该路径的省份为河北省。河北省雄安新区的智慧城市建设在国家大数据综合试验区和数字经济创新发展试验区的“双区” 政策环境支持下, 产业资源集聚和政策“洼地效应” 十分突出, 由此强化市场要素资源的全力推进, 包括产业主体借助高端引智助力产业转型升级、组建河北省连翘产业技术研究院, 有效整合省连翘研究和产业开发等企事业单位的技术优势、人才优势、科研条件等, 打破单位藩篱, 形成强大合力, 针对全产业链发展的关键问题, 开展研究攻关和集成示范推广, 由此提升产业数据治理能力。辽宁省发布《沈阳市政务数据资源共享开放条例2020》, 依托大数据综合试验区推动产业数字化发展, 可进一步借鉴河北省做法, 通过该路径以政策或产业特色为导向, 吸引大数据相关人才与企业, 围绕本地发展需要, 形成特色化发展驱动力, 促进区域协同发展, 实现经济提质增效。
5.4技术主导下政策资源加强驱动型路径
组态5显示, 高政策环境建设、高资源聚合水平、高人才智力保障、高技术基础设施及非高产业数字化发展水平作为核心要素存在, 组织建设水平及技术应用能力作为边缘条件存在, 资金投入强度、用户意愿及需求作为边缘条件不存在时, 能够带来高全域产业数据治理能力。该路径表明, 技术资源投入的确可以带来技术、人才、知识溢出效应, 并补偿用户需求和资金不完善状况, 同时, 低产业数字化发展也为全域产业数据治理提供了更自由宽松的发展空间。符合该路径的省份是河南省。河南省具有国家大数据综合实验区, 同时构建多个市级大数据管理局, 政务数据高效汇聚、公共数据开放共享、工业数据价值释放、数据要素交易流通, 强化数据资源汇聚与共享应用, 着力释放数据价值, 由此持续提升一体化数据治理能力。依托良好的政策基础环境及聚合资源, 河南省对大数据优秀人才的吸引力也显著增强, 加强新型技术基础设施建设, 尤其为工业数据治理效果显著, 提升了当地工业产业的发展优势。贵州省同样具有国家大数据综合试验区作为先导试验, 因此可借鉴河南省做法, 通过该路径, 强化基础设施统筹, 开展系统性试验, 有效打破数据资源壁垒, 充分发挥高水平政策环境与资源聚合的作用, 进一步通过高层次人才引进, 对产业数据使用的过程进行监督、评估、指导和执行, 从而赋能工业、金融、商贸及政务等产业发展的新业态与新模式。
5.5政府助力下依托用户需求的政策与人才驱动型路径
组态6指出, 高政策环境建设、高人才智力保障、非高产业数字化发展水平为核心条件, 互补高资源投入强度、高资源聚合水平、高组织建设水平、高用户意愿及需求、高技术应用能力及非高技术基础设施为边缘条件, 可以产生高全域产业数据治理能力。在政府资金、资源及组织的“帮助之手” 作用下, 全域产业数据治理能力提升效果明显。组态6 表明, 在产业数字化发展水平不高的省域, 政府提高效率, 给予资金资源的助力, 通过打造高的政策环境、吸纳多的专业人才, 可以产生高全域产业数据治理能力。处于这类路径的省份为安徽省。例如, 安徽省为统筹数据资源, 发布《安徽省政务数据资源管理办法2021》等相关政策文件, 同时通过人才引进政策集聚包括高精尖、技能型、复合型区域人才, 发挥辐射带动作用, 通过科技对口帮扶项目、国家火炬特色产业基地推荐等数字服务, 建立政府引导下集群产业链协同机制, 提升主导产业在细分领域的发展优势。内蒙古自治区地域广袤, 电力资源丰富, 气候条件优越, 国家助力打造基础设施统筹发展类的大数据综合试验区,在数据中心存储服务、软件与信息技术服务等方面具备独特优势。因此可借鉴安徽省做法, 充分发挥能源优势, 加大资源整合力度, 强化绿色集约发展; 加强与东、中部地区合作, 实现跨越发展。
6结论
本文在政府数据治理研究基础上, 延伸产业数据治理的应用场景, 重点研究省级范围内全域产业数据的协同治理与应用效能的提升问题。基于组态视角, 采用定性比较分析(QCA)与必要条件分析(NCA)相结合的研究方法解决多重因素的协同效应, 以非对称创新理论构建研究框架, 综合制度—市场—技术维度, 形成条件组态并分析得到以下结论: ①我国产业数据治理能力水平分布呈现明显的区域差异性和集聚辐射效应。自北上廣和江浙地区到中部地区、川渝和东北地区, 再到中西部地区、西南地区依次递减; ②资金投入强度是数智驱动背景下全域产业数据治理能力的关键瓶颈。NCA 方法显示, 技术基础设施、人才智力保障、用户意愿及需求、资源聚合水平、资金投入强度、技术应用能力的必要性尤为显著。QCA 必要条件分析显示,不存在单一要素构成高全域产业数据治理能力的必要条件, 说明促进全域产业数据治理能力的因素是多发性的, 需要同时关注多要素组合的综合均衡作用; ③存在5 条提升全域产业数据治理能力的路径。结构优化型路径、用户需求牵引下资金和技术驱动型、产业数字化助力下制度与市场强化型、技术主导下政策资源加强驱动型、政府助力下依托用户需求的政策与人才驱动型路径均具有“异曲同工” 的等效性, 为其他要素基础相似但全域产业数据治理能力不高的省份提供了“殊途同归” 的路径借鉴。
本文贡献如下: ①拓展数据治理的应用场景,针对产业的具体情境, 提出全域产业数据治理能力的提升问题, 并将中国特色的非对称创新理论应用其中, 扩展了非对称创新理论的使用情景, 将全域产业数据治理研究情境具象化, 更具有实际意义;②运用多维组态视角研究各省级政府的全域产业数据治理能力提升路径, 为数据治理研究提供了整合视角。本文不足之处: 研究仅针对固定时间的截面数据分析, 后续研究将从纵向发展角度分析面板数据, 深入探讨全域产业数据治理能力的动态演变;本文涉及的条件衡量标准较为多样, 后续研究可以采用其他指标作进一步检验, 以证实本文结论。
