
基于LSTM网络与误差补偿的预测模型
2023-03-27 02:04王健,宋颖,吴涛
计算机技术与发展 2023年3期
王 健,宋 颖,吴 涛
(1.安徽大学 数学科学学院,安徽 合肥 230031;2.安徽大学 计算智能与信号处理教育部重点实验室,安徽 合肥 230039)
0 引 言
PM2.5作为大气中的一种细小颗粒物,具有粒径小、面积大、毒性强的特点,严重威胁着人们的健康。近年来,国家不断加大各项环境治理措施,PM2.5治理已取得很好的效果,雾霾天气已少有发生,但未来PM2.5的治理仍任重而道远。因此,对未来PM2.5的变化进行预测与模拟尤为重要。
当前,空气质量预测模型主要有两种类型,一种是基于大气动力学的数值预报模型,即基于大气内部运动的物理规律,通过污染源、化学动力学等相关知识,建立起空气污染浓度预测的动态模型,对大气情况进行模拟预测[1-2]。
另一种则是基于统计学、机器学习等方法,利用已有的数据,从数据中挖掘其中所蕴含的数理规律,建立预测模型,实现对未来情况的预测。常用的统计方法与机器学习方法有多元线性回归[3]、ARIMA[4]、支持向量回归[5]等等。而随着深度学习的快速发展,神经网络得到了各个行业的关注。由于神经网络在拟合非线性关系上的优越性,也被广泛应用于空气质量预测当中。常见的网络结构有BP神经网络[6]、卷积神经网络[7]、循环神经网络[8]及其相关变种LSTM[9-10]等,并通过神经网络,建立了相应雾霾预警系统[11]。在污染物预测建模过程中,通过历史污染物数据,对网络进行训练,建立相应的网络预测模型,取得了不错的效果。
同时,为了进一步提高预测的准确率,很多学者通过时空变化的规律进行分析建模,提高原有预测模型精度。例如:空间方面,李燚航[12]通过引入历史风场数据,将离散的PM2.5插值成网格图的形式,然后使用U-net网络对未来时刻进行预测,提高了对PM2.5的突变情况的预测能力;宋飞扬[13]通过KNN算法为所需预测的站点选取与其相关的空间相邻站点,得到其空间特征,再对目标站点建立LSTM预测模型,以达到对空间影响因素的利用。
时间方面,张怡文[14]通过对不同的季节分别进行建模的方式,通过季节性预测方法提高了预测准确率;蒋洪迅等人[15]通过序列分解的思路,分解为若干子序列,提取出不同时间尺度的周期序列,再利用LSTM网络对各子序列进行预测得到预测值,使得预测精度得到了提升;Wang等人[16]采用的基于区间值的二元分解与最优组合集成的学习方法,将日均值浓度转变为区间数,并将不同年份的同季节数据进行重构,采用二元经验分解对序列进行分解,再利用区间多层感知机进行预测,使得预测精度有所上升。
该文主要从时间方面入手,首先选择了对序列数据预测表现较好的长短时记忆网络(LSTM)作为初步预测模型,完成多因素影响下PM2.5的初步预测。然后利用PM2.5浓度变化所具有的季节性与周期性,探索相邻年份历史预测误差分布特点。通过模糊聚类的方法,分析比较当前数据与历史数据的相似性,对当前预测数据的预测误差进行估计,并做出相应的误差补偿,以提高当前预测结果的准确性。
1 理论与模型
1.1 长短时记忆网络(LSTM)
LSTM神经网络[17]大体结构与传统循环神经网络结构相同,主要为了解决长时间序列问题中的梯度爆炸和梯度消失的问题,在神经网络内部结构中引入了“记忆细胞(cell state)”这一概念。LSTM单元中存在三个门控单元,即遗忘门、输入门、输出门。这三种门控单元均为非线性单元,其中遗忘门决定了从上一个状态中舍弃什么信息,即遗忘阶段;输入门决定了当前状态保存什么信息,即选择记忆阶段;而输出门决定了从记忆细胞中输出什么信息,即输出阶段。相关计算公式与网络结构(见图1)如下:
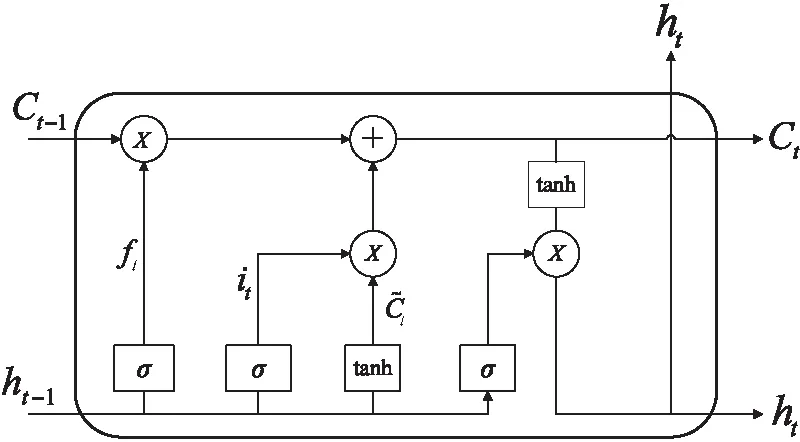
图1 LSTM网络结构
遗忘门:
ft=σ(Wf·[ht-1,xt]+bf)
(1)
输入门:
it=σ(Wi·[ht-1,xt]+bi)
(2)
Ct=tanh(WC·[ht-1,xt]+bC)
(3)

(4)
输出门:
ot=σ(W0[ht-1,xt]+b0)
(5)
ht=ot*tanh(Ct)
(6)
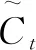

1.2 模糊C均值聚类(FCM)
传统的聚类分析是一种硬划分,即划分事物即是非此即彼的特性,而模糊聚类则采用的是一种软划分的方式,通过赋予每个样本点隶属度的方式,来衡量每个样本对每个类的影响,可以更好地衡量数据对所在类的影响。现假定有一个数据集,若把这些数据划分为c类,那么对应的就有c个聚类中心Ci(i=1,2,…,N),每个样本属于某一类的隶属度为uij,定义一个FCM目标函数(7)及约束条件(8)。
(7)
(8)
式中,uij∈(0,1),表示第j个数据对第i个类的隶属度。通过不断迭代,使式(7)取得最小值,从而确定聚类中心Ci和每个样本点对应聚类中心的隶属度uij:
(9)
(10)
1.3 基于LSTM网络和FCM误差补偿的PM2.5预测模型
下面对该文所使用的算法进行介绍,具体流程如下:
步骤1:将收集的数据集T的数据进行max-min归一化。对完整年度将数据集进行分割,分割成三个部分,用于神经网络训练的历史训练数据T1;用于模糊聚类实验的测试集T2;用于误差补偿后验证效果的验证集T3。并设置输入LSTM网络的数据窗口宽度为w。

步骤3:将测试集T2与误差数据e组成新的数据集(T2,e),并对数据集(T2,e)进行FCM模糊聚类。确定聚类中心L1(i)={c1,c2,…,ck},其中ci=(xi1,xi2,…,xim,ei)。


具体算法流程如图2所示。

图2 基于LSTM网络和FCM误差补偿的PM2.5预测模型
2 PM2.5浓度预测的实例分析
2.1 数据的初步分析
该文所使用的数据集为2017年1月1日至2021年12月31日安徽省合肥市的PM2.5、PM10、SO2、CO、NO2、O3这六种空气污染物日均值浓度数据(其中CO数据单位mg/m3,其余数据单位均为μg/m3),共收集数据1 825条。为充分利用PM2.5变化的周期性,分割数据集时,将前三年共计1 095条数据作为神经网络的历史训练集T1,用于训练神经网络;将数据集的第四年,即第1 096条至1 461条共计365条作为测试集T2,用于历史预测误差的模糊聚类实验;数据集的第五年,即第1 462条数据到1 825条数据T3作为经过误差补偿后的验证集,验证该方法的效果与可行性。
通过绘制PM2.5的浓度时序变化图(见图3),可以看出PM2.5的变化具有周期性,存在“秋冬高,春夏低”的现象,并且相邻两年之间PM2.5浓度的分布具有相似性。此外还可以看出五年的PM2.5浓度变化总体有一定的下降趋势,并且单日PM2.5含量激增的情况也大大减少,猜测应该与国家环境相关治理有关,城市整体空气质量正在逐年提高。

图3 PM2.5浓度时序变化
对该文所使用数据集的五种与PM2.5相关的污染因子进行Pearson相关因子检验,检验结果表明,PM2.5与PM10、CO有较强的正相关性,与NO2、SO2存在相关性,而与O3呈现一定的负相关性,说明了所选PM2.5影响因子的合理性。具体分析结果如表1所示。

表1 Pearson相关因子分析
2.2 数据预处理
(1)缺失数据填补。
由于收集的数据存在少量缺失值,且污染物的变化存在一定的趋势性,而线性插值可以对趋势性的数据进行很好的补充,故采用线性插值的方式对缺失的数据值进行合理填补。
(2)数据归一化。
为了提高神经网络在训练过程中的收敛速度和模型准确率,以及各污染物由于量纲不同对数据聚类所产生的影响,而max-min归一化处理可以有效解决这些问题,故对数据进行max-min归一化处理,使得数据范围为[0,1]。
(3)数据滑动窗口化处理。
在使用LSTM神经网络进行预测时,需要将时序型数据转化为监督型数据,建立一个输入X、输出Y的映射关系,而神经网络则是学习X到Y的模式,故需将数据处理为适合网络的输入形式。所以采用滑动窗口的方式建立这种映射关系,具体处理方式如下:
其中,yp,q为待预测第p天的PM2.5真实值。
2.3 模型参数设置
该文基于深度学习keras框架,搭建LSTM神经网络作为初步预测模型。在神经网络进行训练之前,需要对神经网络的超参数进行设置,所使用的LSTM网络超参数具体设置如下:两层LSTM,节点数分别为128和64;一层全连接层,节点数为32;训练所使用的损失函数为MSE(均方误差),优化器采用Adam优化器,batchsize设置为64。为了防止网络过拟合,在每个LSTM层后,设置丢弃率dropout为0.2。
在滑动窗口处理的过程中,不同的窗口大小会对实验结果造成影响。经多次实验,确定了最佳窗口大小,窗口大小为3。
2.4 模型评估指标
评估指标选用均方根误差(RMSE)、平均绝对误差(MAE),具体公式如下:
2.5 结果分析
2.5.1 LSTM初步预测结果分析
使用LSTM网络对测试集数据进行预测,对一年中不同的时间段的误差进行误差统计,并绘制相邻年间的误差时序变化图,具体结果如表2所示。

表2 一年不同时间段误差统计
通过表2,可知一年间不同时间段的误差分布不均匀,表现为年初和年末误差较大,年中误差较小,这个特点也可以在图4中得到体现。由图4可知,相邻年间误差分布具有相似性,且PM2.5变化具有季节性,故推断,相似数据的误差分布是相似的。

图4 相邻年份预测误差变化
2.5.2 预测结果与误差
由2.5.1节的结论,对测试集及对应误差组成的数据集进行FCM模糊聚类。利用聚类中心,对验证集数据进行分类。根据分类结果,对属于不同类的预测数据进行相应的误差补偿,得到最终预测结果。并与其他的实验方法进行对比,结果如表3所示。
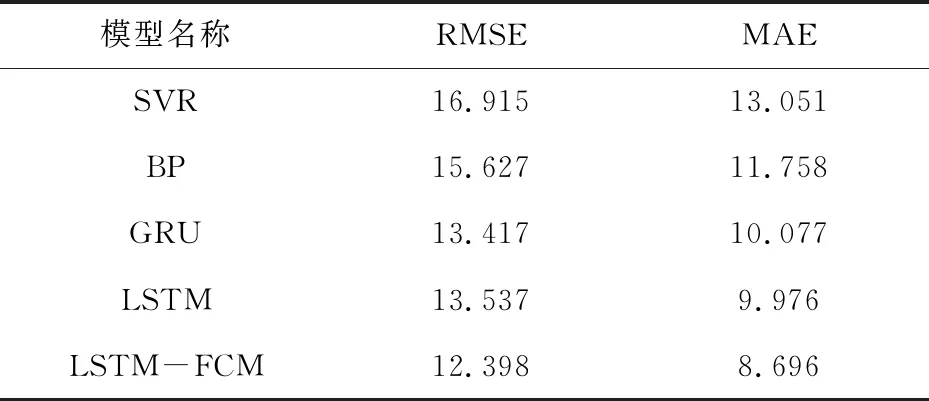
表3 实验预测误差结果
由表3可知,经过误差修正后的预测结果相较于其他对比的实验方法,效果最佳,从而验证了该方法的有效性。相关预测结果如图5所示。

图5 全年PM2.5预测结果
3 结束语
使用合肥2017年1月1日至2021年12月31日的空气质量六因子的日均值数据进行了PM2.5的浓度预测。实验过程中,首先对少量缺失数据进行了线性插值填补,并进行归一化处理。归一化后,对数据集进行滑动窗口化处理,处理成适合LSTM神经网络输入的滑动窗口数据,并完成LSTM网络的训练以及初步预测。通过实验,发现PM2.5预测误差存在相邻年份误差分布相似,但整年误差分布不均匀,呈现出年初、年末误差较大,而年中误差较小。
根据此特点,采用了FCM对测试集数据进行聚类。根据聚类结果对验证集分类,并根据聚类中心做出相应的误差补偿。最终实验结果表明,均方根误差(RMSE)与绝对平均误差(MAE)均得到了降低,总体取得了不错的效果。
但仍存在很多不足。在研究初期,仅对污染因子进行了相关性分析,验证了所选特征之间所具有相关性,并未对诸如风速、风压等气象因子进行分析和考虑。
在模糊聚类方面,通过模糊聚类确定当前数据与历史预测数据相似的部分,利用对应类的聚类中心作为误差补偿值,可以对LSTM初步预测结果进行很好的补偿。但由于误差存在正负,聚类并不能很好区分误差的正负,可以在接下来的研究中考虑如何确定误差的方向,以进一步提高预测精度。
时间因素方面,本次实验采用的为城市的日均值数据,而天气情况具有实时性,若将数据更换为以小时为单位的数据,则模型的预测精度应该会更好,并更具有实际意义。在后续的研究中,可以针对以上问题进行一定的改进,取得更好的预测效果。
猜你喜欢
哈尔滨轴承(2020年2期)2020-11-06
今日中国·法文版(2020年7期)2020-07-04
电子制作(2019年19期)2019-11-23
中国特种设备安全(2019年1期)2019-03-13
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
重型机械(2016年1期)2016-03-01
山东青年(2016年2期)2016-02-28
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
