
基于聚类和LSTM的光伏功率日前逐时鲁棒预测
2023-03-27 02:04刘兴霖
计算机技术与发展 2023年3期
刘兴霖,黄 超,王 龙,罗 熊
(1.北京科技大学 顺德研究生院,广东 佛山 528399;2.北京科技大学 计算机与通信工程学院,北京 100083)
0 引 言
随着煤炭、石油、天然气等化石燃料的不断消耗,环境、能源问题成为世界关注的焦点。太阳能作为具有高可用性且用之不竭的清洁能源,被认为是最有前途的能源替代品之一,各国都十分重视太阳能产业的发展,特别是光伏产业[1]。建设光伏系统已经成为可持续发展的重要内容[2]。国际能源署发布的2020年全球光伏报告显示,截止2020年底,全球累计光伏装机容量760.4 GW,中国、欧盟和美国的新增光伏装机容量分别以48.2 GW、19.6 GW和19.2 GW的规模位列前三[3]。然而,具有高波动性和间歇性的太阳能会给电力系统的管理带来巨大挑战[4-5]。因此,随着全球光伏装机容量的不断提升,光伏功率预测的准确性对于电网管理和电力调度至关重要[6]。
预测方法中,有两类常用的方法,即物理法和统计法。物理法的优势在于不需要历史运行数据,但在对复杂天气的抗干扰能力方面有一定缺陷[7-8]。统计法包括线性算法如自回归等,还包括非线性算法如人工神经网络[9]、支持向量机(support vector machine,SVM)[10]、高斯过程回归(Gaussian process regression, GPR)[11]、深度学习(deep learning,DL)[12-14]等。深度学习具有较强的抗干扰性,能够更好地挖掘出数据之间的关系。而深度学习模型中的长短期记忆(long-short-term memory,LSTM)神经网络[15-16]是对循环神经网络(recurrent neural network,RNN)[17]的优化,引入了“记忆块”,可以使得LSTM对历史数据进行充分的学习。K-means算法是一种经典的聚类算法,文献[18]通过K-means算法对训练样本集进行聚类分析,在聚类得到的各类别数据上分别训练支持向量机,并根据预测样本的类别选择对应的支持向量机进行发电功率预测。
基于神经网络的预测模型通常以均方误差(mean square error,MSE)为损失函数训练模型[19]。以MSE为损失函数训练模型易于收敛,但MSE对离群点敏感。而光伏发电功率高度依赖于太阳辐射值,可在数分钟内剧烈变化,较易产生离群点。为此,以通过降低对离群点惩罚程度的Huber损失函数训练模型,可使得模型对离群点更加鲁棒[20]。在此基础上,可采用智能优化算法对Huber损失函数中的超参数进行优化。而高效的全局搜索技术才能更好地解决参数寻优问题。鲸鱼优化算法[21](whale optimization algorithm,WOA)是一种新型启发式优化算法,并且已被用于优化各个领域。相比于遗传算法等传统进化算法,WOA具有计算简单和收敛速度快等优点。因此,该文选择WOA作为Huber损失函数的优化算法。
基于以上分析,该文提出基于K-means聚类分析和LSTM算法相结合的光伏发电功率日前逐时鲁棒预测模型。首先,基于K-means算法以天气预报数据为特征将光伏数据进行分类,再针对每一类数据分别建立基于LSTM算法的预测模型。为了提升模型的鲁棒性,使用Huber损失函数,并结合WOA训练模型。为验证提出的预测模型的有效性,以GEFCom2014能源预测竞赛[22]中的光伏数据开展实例研究。研究结果表明:(1)与MSE和一般的Huber损失函数相比,经WOA优化的Huber损失函数可有效提升模型的预测精度;(2)与传统的BP神经网络、LSTM、Autoformer[23]、时间融合Transformers (temporal fusion transformers,TFT)[24]及基于决策树算法的梯度提升框架模型LightGBM[25]相比,K-means与LSTM相结合的预测模型可进一步提升预测精度。
1 算 法
1.1 K-means算法
一般来说,天气状况分为两种类型:如晴空天气与阴雨天气,利用K-means聚类算法分析太阳辐照度、温度、降雨量等环境因素,按照晴空天气与阴雨天气各自聚类,以实现将数据集按照不同天气类型分类。该算法将样本根据相似度聚集到k个聚簇当中,最终实现各个簇内相似度高,簇间相似度低[26]。步骤如下:
步骤一:从数据集中随机选择k个样本数据,并作为初始聚类中心{μ1,μ2,…,μk};
步骤二:计算剩余样本到每一个初始中心点的欧氏距离,选择距离最近的初始聚类中心形成k簇。距离计算公式如式(1)所示:
(1)
式中,x为样本空间中的样本;μi为簇Ci的质心。
步骤三:对各个簇重新计算聚类中心。聚类中心计算公式如式(2)所示:
(2)
最后重复步骤二和步骤三直到条件被满足或者达到最大迭代次数而终止,终止条件为:
|μn+1-μn|≤ε
(3)
式中,ε为阈值条件。
1.2 LSTM算法
LSTM神经网络由输入层、隐含层和输出层组成,其中隐含层包含输入门、遗忘门、输出门和具有特殊记忆细胞的神经单元,其单元结构如图1所示。

图1 LSTM单元结构
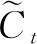
ft=σ(WfXt+UfHt-1+bf)
(4)
it=σ(WiXt+UiHt-1+bi)
(5)
ot=σ(WoXt+UoHt-1+bo)
(6)
(7)
(8)
Ht=ottanh(Ct)
(9)
式中,ft为遗忘门;it为输入门;ot为输出门;C为记忆细胞状态的向量值;W为隐藏单元的输入权重矩阵;U为输出权重矩阵;b为偏置向量;下标t-1和t分别代表不同的时间步长;σ为sigmoid函数。
1.3 鲸鱼优化算法
在WOA过程中,每条鲸鱼都有两种行为。一种是包围猎物,鲸鱼会迅速包围猎物,螺旋形缩小圈。另一种是利用泡沫网,鲸鱼发现猎物后,排出气泡迫使猎物聚集。在每一个迭代过程中,鲸鱼会在这两种行为之间随机选择进行捕猎。为了模拟这些行为,根据随机概率q,在每一代鲸鱼中以50%的概率选择两种行为之一,并定义为:
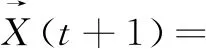
(10)
2 光伏发电预测模型
2.1 预测模型结构
该文研究基于日前逐时天气预报信息的光伏功率预测方法。主要天气预报信息包括:总液态水、总冰水、表面压力、1 000毫巴时的相对湿度、总云量、10米水平风分量、10米垂直风分量、2米温度、地面太阳辐射总量、地面散热总量、大气顶部的净太阳辐射总量、总降水量。这些变量都是基于卫星数据的预测量。
针对光伏功率特性,该文提出K-means和LSTM相结合的光伏发电功率日前逐时预测模型,即先用K-means算法以天气预报信息为特征将数据进行分类,再针对不同类的数据建立基于LSTM算法的预测模型。整体流程如图2所示,对关键步骤的描述如下:
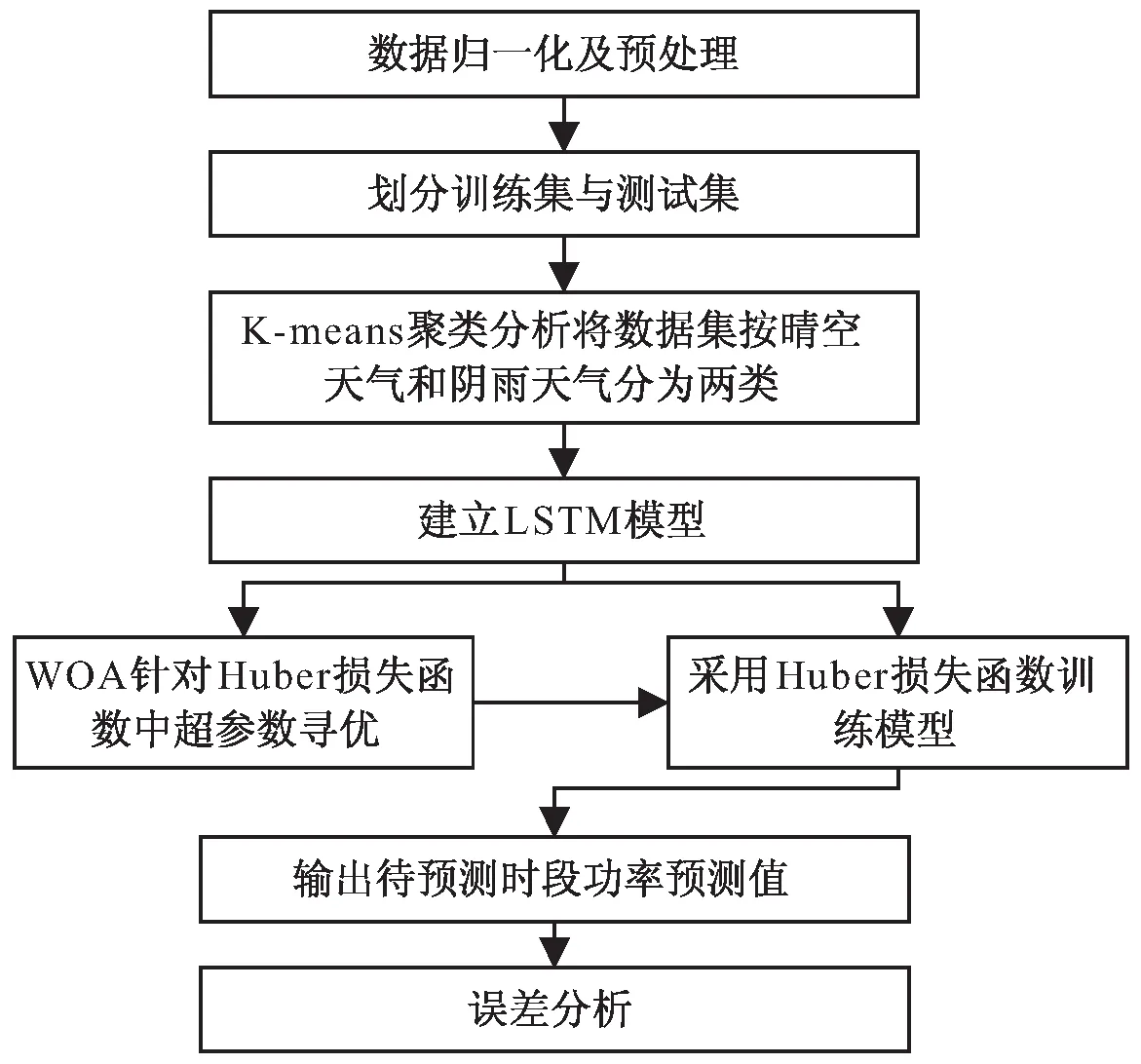
图2 光伏输出功率的预测过程
步骤一:数据预处理,如:数据归一化以及累积变量的预处理,并划分训练集和测试集。
步骤二:天气聚类分析。从样本数据集中总结并提炼出能够明显表现天气类型的特征数据,如单日日间的太阳辐照度和降雨量等。利用K-means聚类算法和提取后的特征数据,并根据晴空天气和阴雨天气设置k=2,将训练集和测试集分为晴空天气训练集、晴空天气测试集、阴雨天气训练集和阴雨天气测试集。
步骤三:建立基于LSTM算法的预测模型。模型输入为时间和日前逐时天气预报信息;模型的输入层神经元个数为输入数据维度;考虑到模型拟合效果和训练时间,隐含层的层数设定为3层,并设定Dropout值以防止过拟合;输出层的前一层为全连接层;模型输出为预测时刻的发电功率。
步骤四:采用Huber损失函数(详见2.2节)训练LSTM神经网络,同时引入WOA,针对各个模型中的Huber损失函数,优化得到对应的超参数δ,并将采用优化后所得到的结果与优化前和使用MSE的结果进行对比。
步骤五:算例验证与实验结果分析。将K-means聚类分析后的训练集和测试集,结合LSTM进行训练和预测,得到预测结果后,将其评价指标与BP、LSTM、Autoformer、TFT及LightGBM算法进行比较。
2.2 损失函数
采用Huber损失函数用于预测模型的训练。Huber损失函数是一种用于回归问题的带参损失函数,与常用的L1、L2损失函数相比,降低了对离群点的惩罚程度,并结合MSE和MAE的优点,对异常点更加鲁棒,以此来提高模型的鲁棒性。Huber损失函数如式(11)所示。当|pi-Pi|≤δ时,Huber损失等价为MSE;当|pi-Pi|>δ时,Huber损失趋向于MAE。
(11)
式中,pi为光伏发电功率实际值;Pi为光伏发电功率预测值;δ为阈值,用来判断模型应如何处理异常值。
3 实验研究
文中采用的实验环境为Windows10操作系统,在Pycharm2021.1的anaconda环境下使用python进行编程,版本号为3.6,并搭建TensorFlow框架,版本号为2.4。
3.1 数据预处理
所选数据集来自于2014年GEFCom2014能源预测竞赛。选择该竞赛中光伏预测方向的数据集,该数据集取自澳大利亚某个地区的三座太阳能发电厂,时间段为2012年4月1日至2014年7月1日,数据时间分辨率为1 h。在K-means聚类分类和建立LSTM神经网络之前对所有特征进行归一化处理,使得各数值统一取值为0到1之间。此外,光伏发电功率在原始数据中已做归一化处理,所以在后续的评价指标计算时,得到的均为归一化后的值。
数据预处理中首先要处理的是四个累积变量,即地面太阳辐射总量、地面散热下降总量、大气顶部的净太阳辐射总量和总降水量。这四个变量在每一时刻的数据都是单日内从零时起到某时的累积量,所以需要将这四个累积变量的各个时刻都处理为每小时的增量。处理后的四个新变量命名为每小时地面太阳辐射量、每小时地面散热量、每小时大气顶部的净太阳辐射量和每小时降水量。
其次要处理的是时间戳,将时间信息字符串处理为可以直接输入到模型中的年、月、日、小时四个变量。原始数据采用的时间是世界标准时间,但由于当地时间与预期的太阳辐射进程是匹配的,所以在后续实验中根据当地时间来处理更为便捷。最后,由于需要对三个电厂的所有数据进行实验,但电厂2和电厂3中存在部分无效数据。在剔除它们后,将2012年4月1日至2014年3月30日内的数据设定为训练集,将2014年4月1日至2014年7月1日内的数据设定为测试集。最终训练集以及测试集划分后的天数如表1所示。
3.2 聚类模型实验研究
可用于天气聚类分析的信息包括日内24个时间点的气象变量,数据维度较高。为提升天气分类的准确度,天气预报数据中选出或衍生出更具代表意义的特征。通过分析特征与光伏发电量的相关性,选择以下气象变量用于天气聚类分析:单日最高地面太阳辐射量、单日最高净太阳辐射量、单日日间最高降水量、单日日间最高液态水量、单日日间最高冰水量、单日日间平均云量,其中单日日间设定的时间段为6:00-18:00。结合K-means聚类算法将光伏发电日的天气类型分为两类,即晴空天气和阴雨天气。三个电厂的训练集和测试集天气聚类分析结果如表1所示。
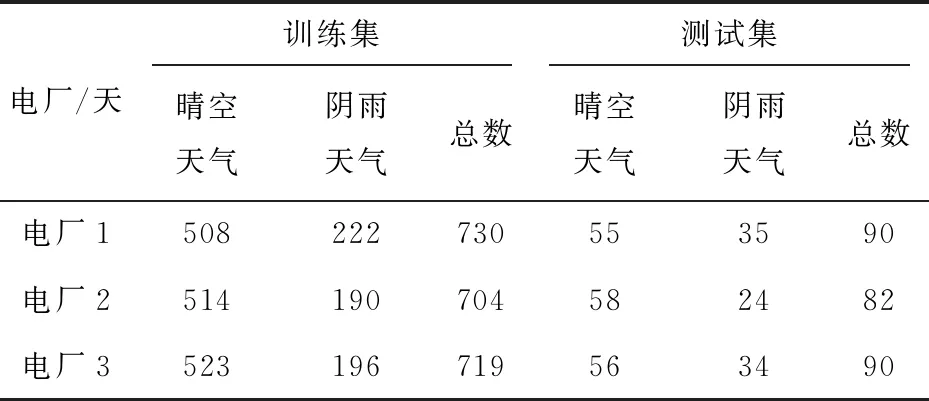
表1 各电厂训练集和测试集的划分和聚类分析结果
3.3 LSTM预测模型实验研究
根据3.2中的聚类结果,针对晴空天气类型训练子集和阴雨天气类型训练子集以及完整训练集分别训练LSTM预测模型,并依次命名为LSTM1、LSTM2和LSTM3。根据2.1中的LSTM网络结构,基于Python的TensorFlow框架中的keras.layers.LSTM搭建LSTM神经网络。预测模型的输入包括时间与气象特征,共13个:小时、总液态水、总冰水、表面压力、1 000毫巴时的相对湿度、总云量、10米水平风分量、10米垂直风分量、2米的温度、每小时地面太阳辐射、每小时地面散热下降量、每小时大气顶部的净太阳辐射量和每小时降水量。同时,三个LSTM模型参数设置为:第一层LSTM神经元个数及其dropout均为50和0.4;而第二层的神经元个数以及dropout分别设置为LSTM1:100、0.2,LSTM2:80、0.4,LSTM3:100、0.2;第三层神经元个数均为50;batch_size均为32;最后的Dense层神经元个数为1。
在LSTM模型的训练阶段,选择Huber损失函数并采用WOA优化其超参数δ来提高模型的性能。由于该文预测任务中的光伏发电功率数据为归一化值,可将需要优化的δ的搜索范围设定为[0.000 01,1],然后进行迭代优化。WOA参数设置为:种群规模为80,最大迭代次数为500。同时,与使用MSE和一般Huber损失函数获得的结果进行对比。
3.4 评价指标
以平均绝对误差(mean absolute error,MAE)、均方根误差(root mean square error,RMSE)、决定系数R2为指标进行误差计算,计算公式为:
(12)
(13)
(14)

4 预测结果分析
为展示损失函数对光伏功率预测性能的影响,分别采用MSE损失函数、一般Huber损失函数和WOA优化后的Huber损失函数来训练LSTM1、LSTM2和LSTM3。表2比较了基于不同损失函数训练的模型在测试集上的预计精度(RMSE值)。

表2 采用不同损失函数时的RMSE误差结果对比
表2表明,与MSE损失函数相比,采用一般Huber损失函数训练LSTM神经网络,大多数情况下都能获得1 %左右的精度提升。而相比于一般的Huber损失函数,采用WOA优化后的Huber损失函数能够更加适应模型,并且RMSE值也降低了1%~2%。由此可以得出对于一般的光伏功率预测问题,不仅一般的Huber损失函数能够通过提升模型的鲁棒性,得到比MSE更加精确的预测结果,采用WOA优化后的Huber损失函数可以得到优于前两者的实验精度。说明光伏数据中离群点的存在会影响模型的精度,并且再经过WOA的优化,可以使得Huber损失函数更加贴合模型,提高其学习能力。为此,后续实验结果分析都基于WOA优化后Huber损失函数训练的预测模型。
表3比较了各预测模型在测试集上对不同天气类型的预测精度。测试结果表明:在晴空天气下,LSTM3模型比LSTM1模型的表现更优,即选用完整训练集训练预测模型可提高晴空天气条件下的预测精度;在阴雨天气条件下,LSTM2模型比LSTM3模型的表现更好,即选用阴雨天气训练子集训练预测模型可提高阴雨条件下的预测精度。

表3 不同天气条件下的预测性能
图3展示了2014年4月23、24日晴空天气下三个电厂的LSTM3预测结果;图4展示了2014年5月4、5日阴雨天气下三个电厂连续五天的LSTM2预测结果。所使用的数据集为两年以上的数据,由于K-means分类为晴空天气和阴雨天气两类数据时存在分类不够准确的情况,如:在分类后的晴空天气数据集中存在2%左右的阴雨天气数据。所以在晴空天气下,使用完整训练集得到的模型能够对小部分的阴雨天气有着更好的拟合效果。同理,分类后的阴雨天气训练子集与测试子集也存在小部分晴天数据,但数据中都仍以阴雨天气为主,所以相比于以晴空天气为主的未分类训练集,采用分类后的阴雨天气训练子集可使测试数据达到更好的拟合效果。但又限于阴雨天气条件下的功率预测会受到更加复杂的因素影响,如单日内波动较大的降雨量、降雪量、温度、总云量等,其总体误差均比晴空天气条件下的偏大。
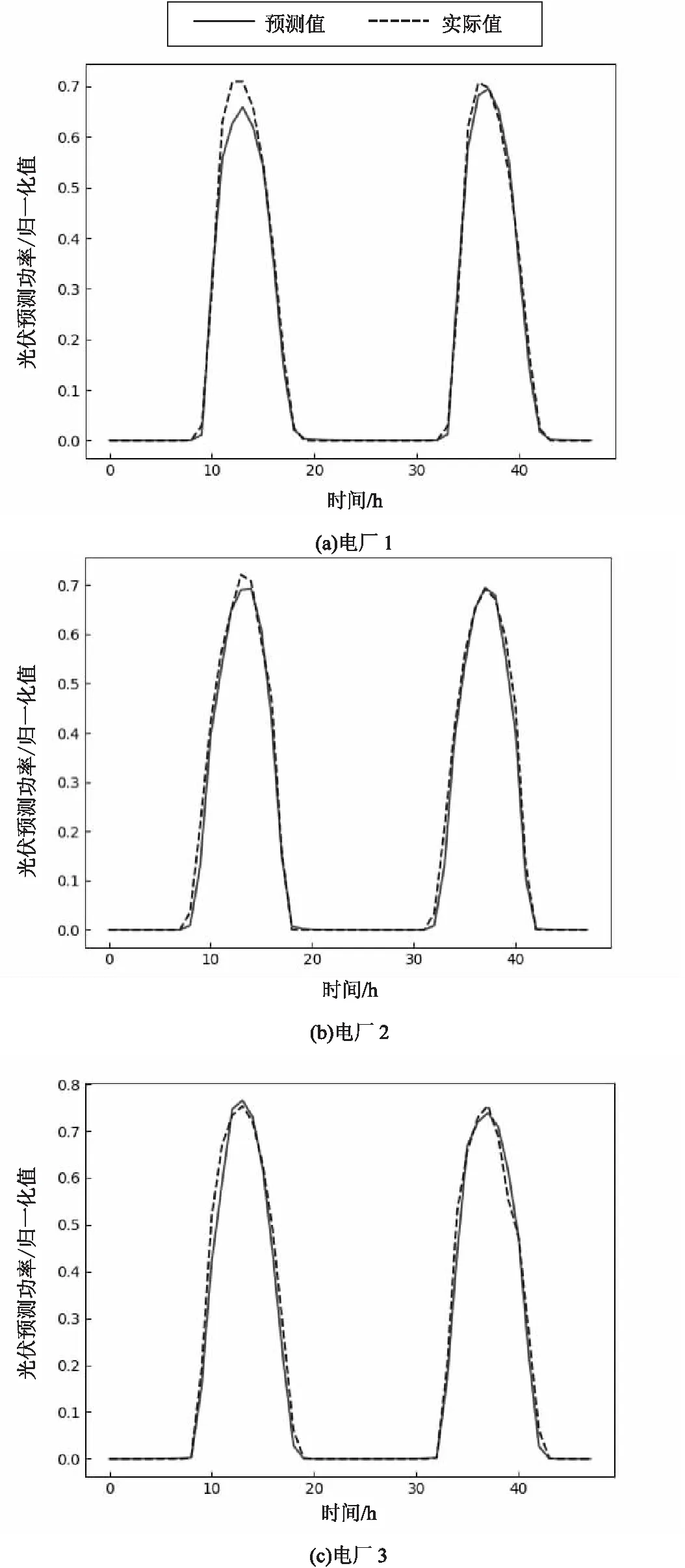
图3 三个电厂在晴空天气条件下连续五天的光伏功率预测结果

图4 三个电厂在阴雨天气条件下连续五天的光伏功率预测结果
以上分析表明,基于K-means聚类分析结果,LSTM2与LSTM3结合即LSTM2用于聚类分析后的阴雨天气预测和LSTM3用于聚类分析后的晴空天气预测两种方法的结合可提高整体的预测精度。表4中展示了基于K-means和结合后的LSTM模型方法在整个测试集上的预测性能。
为进一步验证提出的K-means天气聚类分析与LSTM预测模型相结合对光伏发电功率预测的有效性,比较了所提出的预测方法与传统BP和LSTM算法以及Autoformer、TFT和LightGBM算法,结果如表4所示。所有对比方法的训练均基于未进行天气分类的完整训练集,预测结果均为相应模型在整个测试集上的表现。

表4 不同预测方法预测性能比较
根据表4给出的结果,可以看出与其他算法相比,除Autoformer与文中模型在电厂1中的误差比较接近,提出的预测模型的评价指标在三个电厂的数据集中均为最优。与传统的LSTM相比,提出的模型在电厂1、电厂2、电厂3中的平均RMSE与MAE分别降低了4.86%与4.33%;与Autoformer算法相比,提出的模型在三个电厂中的平均RMSE与MAE分别降低了2.35%、1.85%;与TFT算法相比,文中模型的平均RMSE与MAE分别降低了1.88%与2.91%;与LightGBM算法相比,文中模型的平均RMSE与MAE分别降低了6.06%与1.89%。结果证明了文中模型和数据处理方法的可行性与有效性,并且在预测精度和稳定性方面均表现出较好的性能。
5 结束语
该文提出基于K-means的天气聚类分析和LSTM相结合的光伏发电功率日前逐时预测方法,并从损失函数和训练集的选择上做出研究分析,结果表明:
(1)在光伏发电预测模型中损失函数的选择上,Huber损失函数相比于MSE具有更强的鲁棒性,能更好地处理光伏数据中的离群点,在此基础之上,选择鲸鱼优化算法对Huber损失函数中的δ实现进一步的优化,从而能有效地提高光伏预测模型的准确度,总体可将预测精度提高2%左右。
(2)基于K-means算法将数据分类为晴空天气类型和阴雨天气类型,在聚类得到的各类别训练集上分别训练LSTM,并根据测试集的类别选择对应的LSTM进行光伏发电功率的预测。研究结果表明,提出的K-means与LSTM相结合的预测方法比单独的LSTM以及LightGBM的预测效果更好,预测精度提升在4%左右,同时对比Autoformer算法和TFT算法,预测精度提升约2%。
(3)基于K-means算法对天气进行聚类分析时,存在对一小部分天气数据分类错误的情况。在后续的研究工作中,可结合其他机器学习算法,提高分类的准确率,进一步提高预测精度。
猜你喜欢
广西农学报(2021年4期)2021-12-20
中老年保健(2021年11期)2021-08-22
当代水产(2021年6期)2021-08-13
东坡赤壁诗词(2021年1期)2021-03-24
小哥白尼·趣味科学画报(2020年4期)2020-10-20
文苑(2020年7期)2020-08-12
读友·少年文学(清雅版)(2019年1期)2019-05-09
小资CHIC!ELEGANCE(2018年34期)2018-11-13
动漫星空(兴趣英语)(2018年9期)2018-10-30
扬子江(2017年1期)2017-05-04
