
基于IoTDB 的航空发动机试验数据清洗与升维方法
2023-03-26 00:34李晓瑜孙婧博
燃气涡轮试验与研究 2023年3期
陆 超,李晓瑜,孙婧博
(1.中国航发四川燃气涡轮研究院 高空模拟技术重点实验室,四川 绵阳 621000;2.电子科技大学 信息与软件工程学院,成都 610054;3.中国航发航空发动机研究院,北京 101300)
1 引言
充分有效地利用航空发动机试验产生的丰富数据资源,对发动机研发过程具有重大意义。但由于试验数据体量大、增速快,不同部门间数据传递效率低下;且传统的数据库技术侧重于存储,对数据应用的支持有限,不能有效地开展数据挖掘与分析工作。同时,发动机试验过程中还会产生一些非传感器的数据,如视频、图像、文档等形式的信息,而已有的平台和技术难以将这些多媒体数据与试验数据相关联,因此需要对数据进行清洗和升维,之后再使用数据融合技术,对这些来自各部门的多源异构数据进行整合关联。传统的关系型数据库(如Oracle)对结构化数据的存储较为有效,但随着数据体量的增加、发动机研发需求的提高以及大数据技术的兴起,这类数据库面向时序型数据时存在效率低下、功能单一等问题,难以满足发动机研发的业务需求。如试验中针对某次发动机故障,往往需要将常规测试、特种测试、视频音频、各专业的后处理图表等信息整合后进行综合分析,面对这种情况,关系型数据库就难以胜任,而通过人工手段将这些割裂的信息关联、整合,费时耗力且效果不理想。
本文简要介绍了航空发动机试验在数据存储和管理上的痛点和新需求,并对航空发动机试验过程中产生的时序型传感器数据的清洗和升维方法进行了研究,提出了一种面向航空发动机试验的多源数据融合平台,并对该平台进行了简要的测试和试验,验证了该平台的技术可行性。
2 技术方案
2.1 多源异构数据
航空发动机在试验过程中会产生大量的传感器数据,这些数据由各传感器以固定的采集频率获取,可将其称为时间序列数据。如果和普通数据一样采用关系型数据库对时间序列数据进行存储,将存在诸多弊端,如按时间区间检索数据的效率较低、支持的查询功能单一等,且这些传统的关系型数据库也难以应对传感器属性的升维要求。存储在数据库中的数据很难在时间轴上自动对齐,不同设备下的不同传感器在数据中难以管理。此外,试验过程中不止产生由传感器采集到的时序数据,还会产生一些视频文件、图像文件,以及某次试验后人为产生的分析报告等输出文档。如果对这些多源异构数据按属性、时间等信息关联,难以在现有数据平台下实现。正是由于传统数据库存在着上述弊端,加之航空发动机试验中又不断提出新的需求,就要求研发一种新的数据存储与管理平台,来提供高效的数据读写、查询、检索及分析功能,并支持对传感器型数据的灵活扩展[1]。
2.2 时序数据管理——IoTDB
IoTDB[2]是一种新型的针对时间序列数据的开源数据管理引擎。IoTDB 最早由清华大学大数据系统软件团队研发,并于2018 年捐赠给Apache,随后进行了为期近两年的孵化,最终于2020 年9 月,由Apache 软件基金会(ASF)宣布成为Apache 顶级项目。IoTDB 具有时序数据收集、存储与分析一体化的功能,以及体量轻、性能高、易使用的特点。此外,IoTDB 还提供了低硬件成本的存储解决方案,10 亿数据点硬盘成本低于1.4 元;高通量的时间序列数据读写,支持百万级低功耗连接设备数据接入;面向时间序列的丰富查询语义,实现跨设备、跨传感器的时间序列对齐;能完美对接Hadoop 与Spark 生态,适用于工业互联网应用中海量时间序列数据高速写入和复杂分析查询的需求。
航空发动机试验过程产生的数据为时间序列数据,由各传感器按照一定频率采集得到,这与IoTDB 中所存储与管理的数据类型基本一致。同时,由于IoTDB 国产自主可控,具有存储成本低、数据写入速度快(百万数据点秒级写入)、数据查询速度快(TB 级数据毫秒级查询)、功能完备(数据的增删改查、丰富的聚合函数、相似性匹配)、查询分析一体化(一份数据,满足实时查询与分析挖掘)、简单易用等特点,使用IoTDB 作为多源数据融合的基础数据存储与管理平台将大大提升数据存取效率。
2.3 其他相关数据管理
对高空试验数据进行综合分析和处理时,通常涉及到试验传感器产生的时序数据以及相关试验场景下产生的视频文件、图像文件、分析报告等其他相关数据文件。在确定时序数据存储和管理平台的基础上,也需要选择合适的数据平台对这些非时序型数据文件进行存储管理,为此选择Hadoop 作为数据融合的分布式平台。
Hadoop[3]是一个开源的、高效的分布式计算平台,可在分布式环境下为用户提供海量数据的存储和处理能力。HDFS[4]是Hadoop 的核心模块之一。当1 个文件被存储到HDFS 中时,它不是作为1 个完整的单一实体存储,而是被切分成了多个较小的部分(称为“数据块”),且这些数据块通常具有相同的大小。如HDFS 可能将每个数据块的大小设定为128 MB,这意味着1 个500 MB 的文件将被切分成4 个128 MB 的数据块和1 个88 MB 的数据块,且这些数据块被存储在HDFS 集群的多个节点上。通过将文件的不同部分存储在不同的节点上,从而实现数据的分布式存储。为了提高可靠性,每个数据块通常会在集群中的不同节点上进行多次复制。如1 个数据块可能有3 个副本,每个副本存储在不同的节点上。这样,即使某个节点发生故障,文件的该部分数据也不会丢失。这种将文件切分成等大数据块的方法,使得HDFS 能够有效地处理和存储大型文件,同时也便于在集群的不同节点上并行处理数据。通过这种方式,Hadoop 能够进行高效的大数据分析和处理。
IoTDB 可无缝支持Hadoop 生态,为此可以通过结合IoTDB与Hadoop生态搭建多源数据融合平台。
2.4 多源数据融合分析架构
基于IoTDB 处理时序数据时的各种优势以及Hadoop 成熟的生态及应用,提出了一种面向航空发动机试验的多源数据融合平台,该平台架构如图1所示。数据采集端按照一定的采集频率收集各个传感器的通道数据,采集段所获取的数据通过JDBC接口将数据存入时序数据库IoTDB 部署的服务器中;IoTDB 可以将存储的数据定时以TsFile 文件的形式上传至Hadoop/Spark 集群中,方便后续进行各种数据挖掘与数据分析操作。为了不影响已有业务,存入IoTDB 的数据来自于原来存储时序数据的数据库,这样IoTDB 中的数据并不是实时的,因此IoTDB 中的数据主要用于数据挖掘与分析。虚线方框部分为平台的大数据集群框架,图中只给出了4个节点,包括3 个数据节点和1 个主节点,实际应用中节点数量可以根据自身需求和数据量来分配[5]。
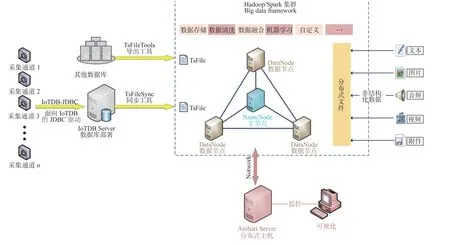
图1 发动机简化模型Fig.1 Simplified engine model
对于文本、图片、视频、音频、附件等非结构化数据,可直接存储在Hadoop 生态下的分布式文件系统HDFS 中。使用MapReduce 或Spark 对平台下存放的各种数据进行分析处理,整个平台提供数据存储、数据清洗、数据融合、机器学习、大数据分析等功能。通过Ambari[6-8]对集群进行管理。Ambari 是一种支持Hadoop 集群部署、监控和管理的开源工具,相较于传统手工部署方式,其极大地提高了Hadoop 集群部署的效率。在本文提出的多源数据融合平台中,Ambari 被单独部署在另外1台服务器中(分布式集群的监控主机)。Ambari 对服务器性能要求不高,通过Ambari 可监控集群状态和进行节点管理,如节点的新增和删除,以及集群组件的部署安装。Ambari 以Web 形式提供相应的服务,通过外接显示器可视化展示集群状态。
3 功能测试结果
3.1 IoTDB 存储性能测试
为了验证IoTDB 存储成本低的特性,对存储在IoTDB 中时序数据所占硬盘容量的大小进行相应的测试。假设传感器数目为500,且1 min 采样50 次,对500 个传感器的插入进行测试,插入10 000条数据大约32.4 MB,平均插入1条数据约3.3 KB,为了直观地展示500 个传感器在采样频率为50 Hz 的情况下所产生的时序数据在IoTDB 中的存储容量随时间变化的特点,表1 以不同刻度的时间对比展示出了容量变化。可看出,传感器无休止地采集数据1 年,数据所占硬盘容量仅需82 GB。显然,在实际的航空发动机研制过程中,传感器并不是无休止地采集数据,因此实际所占容量只会比这更小,由此验证了IoTDB 低存储成本的特性。

表1 时序数据在IoTDB 中容量变化Table 1 Time series data capacity changes in IoTDB
3.2 IoTDB 数据检索效率测试
对IoTDB 的数据检索效率进行对比测试,对比数据库为MangoDB,对比结果如表2 所示。MangoDB 从1 个表中随机查询150 条数据,总共耗时596 s,平均查询1 条数据耗时4 s。而IoTDB 的数据查询效率为毫秒级,随机以时间戳为条件查询1 条数据,耗时在10~100 ms。相较于被广泛使用的NoSQL 数据库MangoDB,查询效率明显提高,由此验证了IoTDB 高效的时序数据检索效率[9-10]。

表2 IoTDB 与MangoDB 检索耗时对比Table 2 Comparison of retrieval time between IoTDB and MangoDB
3.3 基于IoTDB 的时间序列数据管理
使用IoTDB 创建时间序列时,可以为其添加别名及额外的标签和属性信息。在IoTDB 中,标签和属性的唯一区别是,IoTDB 为标签信息在内存中维护了1 个倒排索引,可以通过设置的标签信息作为查询条件对通道信息(即传感器信息)进行查询。为此,可以使用IoTDB 提供的标签存储数据升维后的各个属性,标签值为对应的属性值。在实际的试验测试中发现,IoTDB 在通道数为2 000 时以标签信息来查询所匹配的通道的效率也是毫秒级,单次查询平均为几十毫秒。
4 基于IoTDB 的数据清洗与升维
航空发动机试验数据在进入IoTDB 数据库存储与管理前,需要经过数据接入、数据清洗及数据升维3 个步骤,如图2 所示[11]。数据升维是数据由单一“数值”变为“多维数据”的蜕变过程,其主要内容是通过什么样的方法和规则、对数据增加哪些属性。原有数据系统在设计和存储形式上难以对数据属性进行升维,也无法提供快速的针对航空发动机试验数据的基于属性的查询。根据航空发动机专业特点拟定了升维属性条目,主要包含基本属性、测试属性、表达属性、应用属性、关联属性等类别,并对原始数据库的属性进行扩充,以此构建内涵更加丰富的数据,为实现多数据检索数据功能及数据关联研究提供了保证。而属性升维通过IoTDB 提供的标签点功能来实现,IoTDB 为标签信息在内存中维护了1 个倒排索引,据此可使用标签作为查询条件快速检索内容。通过对升维后的属性进行关联,可以将包含相同属性内容的传感器关联起来,并提供基于升维后属性的多条件查询功能。
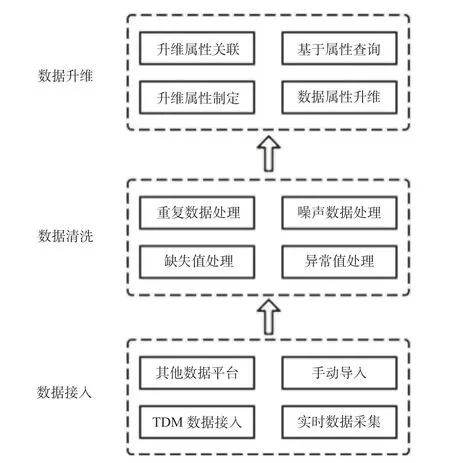
图2 基于IoTDB 的数据清洗与升维流程图Fig.2 Data cleaning and dimension improvement flow chart based on IoTDB
5 结束语
为解决传统航空发动机试验过程中多源异构数据难以得到充分、有效利用的不足,提出一种面向航空发动机试验的多源数据融合平台。该平台以开源时序型数据库IoTDB 和大数据存储与分析平台Hadoop/Spark 为核心组件构建,不仅能对传感器采集的时间序列数据进行高效的存储、检索、管理和分析,还能对发动机试验中产生的各种非结构化数据进行分布式存储和处理。对IoTDB 性能和功能的测试表明,IoTDB 能满足面向航空发动机试验的多源异构数据融合的需求。最后,基于IoTDB 数据平台,对航空发动机试验过程中产生的时间序列型数据的清洗、升维方法进行了测试和验证,证明以该平台为依托,可以构建面向航空发动机试验的大数据生态。
猜你喜欢
中国农业信息(2023年3期)2023-03-18
中国石化(2022年5期)2022-06-10
房地产导刊(2022年4期)2022-04-19
中国农业信息(2021年3期)2021-11-22
趣味(作文与阅读)(2021年11期)2021-03-09
趣味(语文)(2021年11期)2021-03-09
中国信息化(2019年10期)2019-11-20
当代党员(2017年18期)2017-09-30
电子制作(2016年15期)2017-01-15
IT时代周刊(2015年7期)2015-11-11
