
基于智能眼镜的手语识别系统设计
2023-03-24 15:11:29刘又瑜谢本齐江焕姜林
电脑知识与技术 2023年4期
刘又瑜 谢本齐 江焕 姜林

关键词: 智能眼镜; 云服务; 手语识别; 听障人士; 智能系统
1 概述
根据世界卫生组织2020年3月统计[1],全球患有残疾性听力障碍人口高达4.66亿人。人数众多的听障人士群体间交流以手语为主。因手语普及率低,导致听障人士难以融入正常人生活。针对该问题,基于人工智能的手语识别技术相继研究,经过多年的发展,穿戴式传感器手语识别和机器视觉手语识别逐渐成为主流技术。
穿戴式传感器手语识别系统利用物理传感器如数据手套、数据臂环、智能手表,记录手部在运动过程中产生的物理信息,再将运动信息传送至接收设备进行处理分析,得以实现对手语动作的识别。最早的穿戴式传感器手语识别方案来自1983年Grimes等人发明的数据手套[2],听障人士单手戴上手套展示美国手语的字母动作,并将数据传送至接收设备,实现对基本动作的识别。2010年Fu等人[3]提出利用数字手套操控虚拟键盘的方式帮助听障人士进行交流;2021年冉孟元等人[4]利用带有九轴惯性传感器的数据手套获取30个汉语拼音字母的手语动作信息,并采用K-邻近算法和前馈神经网络实现了基于惯性传感器融合控制算法的手语识别。
机器视觉手语识别系统通过录制手语动作视频,利用图像处理、深度学习、计算机视觉相关算法等技术对连续帧中的画面信息以及信息的变动规律进行总结学习,实现对输入视频的分类,得出相应的手语释义。现有机器视觉手语识别以深度神经网络技术为主,通过建立视频信号到手语分类的网络结构,提高手语识别精度[5]。在手语特征学习方面,常用的网络结构有VGG[6]、AlexNet[7]、ResNet[8]等,在视频动作识别方面,2D卷积神经网络模型有Two-stream方法[9]以及在此基础上改进而来的TSN(Temporal Segment Network) 网络[10]。2D-CNN方法的重点在于如何更好地提取视频时空信息[5],3D-CNN方法在2D的基础上引入了时序信息,增加了对时间维度帧间运动信息的关注度。常见方法有C3D[10]、I3D[11]、P3D[12]等。在基于GNN的方法中,常与人体骨架坐标识别进行结合,Amorim等[13]在得到手语动作视频中的每帧人体骨架坐标后引入时空图卷积神经网络ST-GCN,建立了连续帧之间节点变化的相互关系,实现对手语视频的识别。
现有技术中,穿戴式传感器手语识别技术可准确获取手部动作,识别率较高,但存在成本高、用户体验感差等问题;机器视频手语识别方法虽克服了穿戴式传感器的不便问题,但却因移动设备端算力资源不足、各框架兼容条件苛刻等问题影响了其应用。
本项目沿用机器视觉技术,使用智能眼镜平台进行手语识别,识别过程中将深度学習模型部署在云端,可解决深度学习模型在智能设备上部署所需算力资源过大的问题,同时因智能眼镜舒适的体验感和便携性,可为听障人士与正常人交流提供应用方案。
2 基于智能眼镜的手语识别系统架构
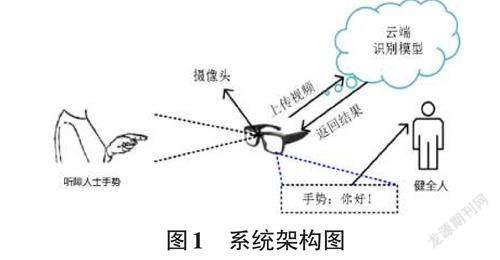
基于智能眼镜的手语识别系统架构如图1,该系统以智能眼镜作为硬件平台,主要负责采集听障人士手势,并将手势视频以图片帧的形式上传至云端,由部署在云端的深度神经网络识别模型将手势的结果返回到智能眼镜,由智能眼镜呈现识别结果,当正常人戴上眼镜后,即可实时识别听障人士手势。
本文智能眼镜平台采用Epson BT-300(图2) ,该平台内置了安卓系统,操作系统界面可显示在镜片中的光学显示器,有利于呈现手势识别结果,眼镜搭载了500万像素摄像头,可高清捕获听障人士手势。云服务平台采用百度EasyDL,本项目将事先训练好的深度神经网络识别模型部署在云端,通过EasyDL提供的API接口进行识别系统的调用。
3 手语识别设计
3.1 构建手语识别神经网络
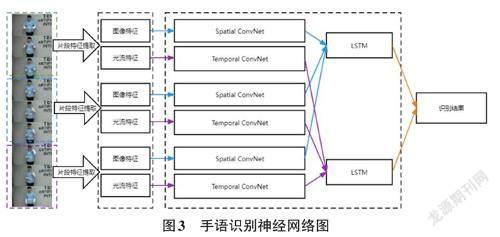
本文手语识别神经网络为TSN与LSTM交叉模型(如图3所示)。Limin Wang等[10]提出的TSN模型是视频分类领域经典的基于2D-CNN的解决方案。该网络常被用于解决视频分类中的长时间行为判断问题。它通过稀疏采样视频帧的方式代替稠密采样,希望捕获整段视频中的概括性动作趋势,该方法有效降低了计算量。
在TSN模型中将输入视频分为K段,并从K段中分别随机抽取一定帧数图像,通过双路CNN 结构分别处理抽取帧的普通图像特征和光流特征,获取这一段视频的分类得分分布,最终通过片段共识函数将K个视频段的得分结果进行融合后得出整段视频的最终分类结果。
但在TSN模型的处理中缺少了对K段视频先后关系的处理,而手语动作作为一种动作语言,具有严格的上下文语义关系。为了解决这个问题,引入了LSTM模型替代TSN模型中的片段共识函数,增加神经网络对视频动作上下文关系的敏感度。根据笔者的实验测试,TSN-LSTM模型识别准确率相较于传统的TSN模型可提升20%的识别准确率。
3.2 模型训练及云端部署
手语识别模型所使用的训练数据集为明亮试验环境下用智能眼镜摄像头录制的数据集,包含10个常用手语动作,每个动作30个样本。测试集与训练集采用8:2比例划分。
模型训练及部署均采用百度EasyDL提供的模型在云端进行。在上传数据集及模型结构后进行云端训练,经百度云端测试TSN-LSTM模型在手语识别准确率达到95.37%。由于深度学习模型在安卓系统本地移植过程中占用资源过大,易出现闪退、转换速度下降等情况,破坏了项目的稳定性,最后采用百度EasyDL提供的深度学习模型云部署服务,在模型云端训练完成后部署为API供系统开发端直接调用。
经测试,在20段连续视频的识别中,每段视频手语识别返回结果平均耗时为3.33s,满足连续手语识别的实时条件。
3.3 模型调用
模型调用流程如图4所示,在用户启动手语识别功能后,openCamera()函数开启摄像头并配置相应的参数,onSurfaceChanged()函数将获取相机预览帧,当一句完整的手语短语结束,摄像头停止录制,queue.put() 函数将生成视频放置进待识别队列。VideoEn?coderThread处理线程将不断检测待识别队列中是否有未处理的视频,并将未处理的视频进行编码,通过getBase64() 函数将视频从mp4格式转换到base64格式,最后由callAPI将视频上传至手语识别模型接口,接口将返回对视频中手语动作的识别结果。系统将选择置信度在50%以上且得分最高的结果发送至前端界面显示。
在调用API得到手语识别结果的过程中要求设备联网,平均返回时间为3.33秒,此速度足够有效避免待处理视频栈积压,满足日常交流速度需求,无卡顿感。
4 系统实现效果
普通人佩戴一副智能眼镜,通过本系统与听障人士进行交流。本项目采用的智能眼镜EpsonBT-300由操控器与眼镜主体组成,操控器连接在眼镜上为眼镜提供电力支持同时充当控制器。启动本系统后,智能眼镜摄像头自动捕捉视频画面,并以每秒5帧的速率上传图片至云端服务器,云端服务器对图片进行识别后将结果返回到智能眼镜的程度中,其识别结果以对话框形式呈现到用户眼镜镜片上,系统运行效果如图5所示。
5 结论
本文以深度学习模型云部署方案为基本思路,基于智能眼镜平台实现了一款手语识别系统。云部署的思路突破了深度学习模型部署在移动端平台时的硬件资源限制,极大缩减了移动端神经网络模型应用系统的体积并提高了运行时的流畅度,避开了各式模型框架在安卓平台部署的兼容性问题,使得移动端神经网络模型应用系统的开发变得更为简便。同时,模型API的调用情况将被实时记录在云端管理系统,实现了模型管理、应用开发的隔离工作环境,增加了系统的可维护性。本文所提出的解决方案可为正常人识别听障人士手语提供帮助,对于解决听障人士融入日常社会生活具有重要意义。
猜你喜欢
吉林农业·下半月(2016年12期)2016-12-23 22:05:45
中国科技博览(2016年25期)2016-12-20 18:53:09
中国集体经济(2016年27期)2016-11-19 13:38:12
新媒体研究(2016年19期)2016-11-18 19:54:24
新媒体研究(2016年18期)2016-11-15 01:14:07
中国市场(2016年38期)2016-11-15 00:28:18
电脑知识与技术(2016年24期)2016-11-14 00:22:02
数字技术与应用(2016年9期)2016-11-09 23:34:32
数字技术与应用(2016年9期)2016-11-09 19:23:39
软件导刊(2016年9期)2016-11-07 21:43:49
