
基于RISC-V 的神经网络加速器硬件实现*
2023-03-22 07:23鞠虎高营田青周颖
电子与封装 2023年2期
鞠虎,高营,田青,周颖
(中国电子科技集团公司第五十八研究所,江苏无锡 214035)
1 引言
近年来人工智能(AI)算法不断取得突破性进展,各种复杂的深度学习算法已渗透到人类社会生活的诸多方面,如智能交通、无人驾驶、智慧医疗等[1]。目前大多数深度学习算法采用图形处理器(GPU)进行训练与推理,相比中央处理器(CPU),GPU 极大地提升了深度学习算法的训练与推理速度。尽管GPU 计算资源丰富,但是存在极大的功耗开销,在硬件资源和功耗受限的条件下,GPU 不是一个很好的计算加速平台。国内外公司都在积极推动AI 芯片的研发,英伟达推出了基于NVIDIA Volta 架构的NVIDIA Tesla V100GPU[2],可实现每秒120 万亿次的峰值运算能力。谷歌面向云业务推出脉动阵列架构[3],峰值计算能力达到每秒92 万亿次计算操作,增加了浮点计算单元和高带宽内存。国内在GPU 和现场可编程逻辑门阵列(FPGA)芯片领域基础相对薄弱,百度开发的云端AI芯片“昆仑”的峰值处理速度达到每秒260 万亿次定点运算。寒武纪发布的云端智能芯片MLU100 的最高峰值速度可达166.4 万亿次定点运算,可支持各类深度学习和常见机器学习算法。这类处理器大多基于精简指令微处理器(ARM)架构[4],ARM 架构虽具有良好的生态,但存在供应链不稳定、自主可控性弱等缺点。第五代开放精简指令集(RISC-V)[5-6]可基于应用场景,进行指令集的自主修改,因此研究基于RISC-V 的神经网络加速器[7]架构可为后续AI 芯片的研究和工程实现奠定基础。
本文基于RISC-V,生成了Linux 内核,构建了RISC-V 开发环境;定义了深度神经网络加速器指令集,实现了数据加载、计算和结果存储等操作;基于深度学习编译器,实现了对主流深度学习开发框架的支持;基于亚科鸿禹开发板以及接口扩展板,将深度神经网络加速器和RISC-V CPU 集成,并通过深度学习编译栈,完成了ZFNet 和ResNet20 神经网络部署,实现了图像分类演示的功能。
2 基于RISC-V CPU 的深度神经网络加速器
2.1 神经网络加速器架构设计
2.1.1 轻量级ZFNet 神经网络
ZFNet 神经网络在AlexNet 网络结构[9]上进行微调,提出了一个新的卷积神经网络可视化技术(反卷积),以辅助观察中间层及分类层的输出特征。ZFNet是一个8 层网络,采用修正线性单元(ReLU)替换Sigmoid函数作为激活单元,避免了梯度消失问题,同时,在计算上采用重叠的最大池化,以避免池化的模糊效果,提升了特征提取的丰富性。本文对ZFNet 进行轻量化处理以降低网络参数量,修改后的ZFNet(M-ZFNet)网络结构如图1 所示,包含6 层卷积和2 层全连接。
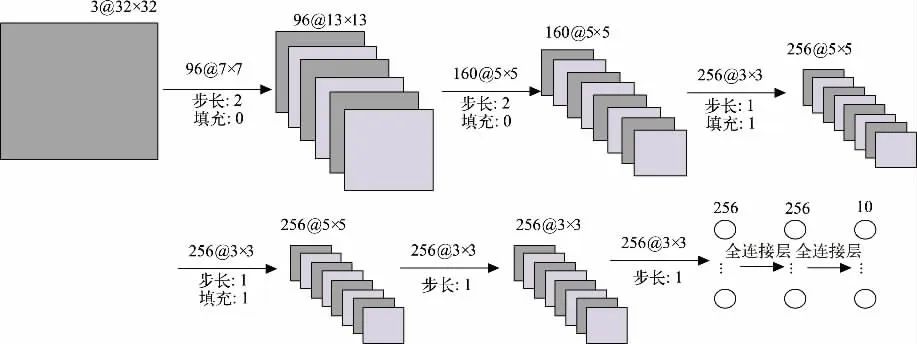
图1 M-ZFNet 网络架构
2.1.2 神经网络加速器核心模块设计
神经网络推理加速器采用可变张量加速器(VTA)架构[10]。
VTA 是围绕通用矩阵乘(GEMM)而构建的通用深度学习加速器,可进行高吞吐量的密集矩阵乘法操作。VTA 硬件架构如图2 所示,主要由获取、加载、计算和存储4 个模块组成,4 个模块通过队列和单写入/读取内存块进行通信。
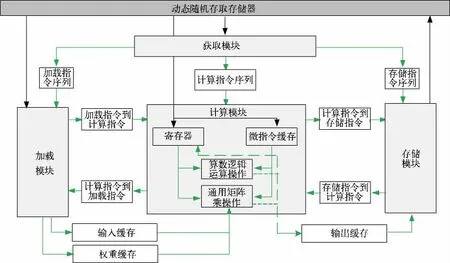
图2 VTA 硬件架构
为支持多种神经网络的推理任务,本文提出了基于宏操作的指令集。1)加载指令,将内存中输入和权重加载至缓存区或者片上寄存器;支持微操作指令加载至微指令缓存;支持动态填零。2)矩阵乘指令,执行微指令缓存中微指令序列,在输入张量和权重张量组成的矩阵之间计算矩阵乘积,并将结果暂存到片上寄存器中。3)算术逻辑指令,执行微指令缓存中的逻辑微指令序列,对片上寄存器的数据执行矩阵的算数逻辑操作。4)存储指令,将计算结果从输出缓存区存储到内存中。通过这4 条指令的组合,可灵活实现多种主流的深度神经网络推理任务,实现智能通用运算。
加载模块负责将存储器的输入和权重数据加载到加速器内专用输入和权重数据的缓存。加载、通用矩阵乘、算数逻辑运算及存储指令结构如图3 所示。加载模块支持在加载数据的同时,在数据周围的X 维度和Y 维度分别动态填零。计算模块采用通用矩阵相乘运算,将数据从存储器中加载到寄存器中,将微操作指令加载到微指令缓存中,计算模块包含两种类型的计算微指令:算数逻辑运算和通用矩阵乘。计算模块在两级嵌套循环内执行微指令序列,以减少微内核指令的占用空间,适用矩阵乘法和二维卷积。存储模块将计算模块的输出数据从片上内存取出并存储到动态存储器中,存储指令的译码执行过程与加载模块相似,支持从静态存储器到动态存储器的跨内存访问。
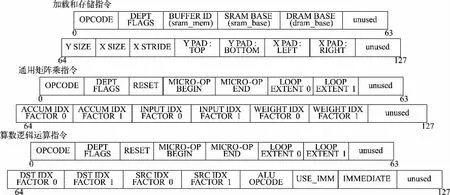
图3 加载、通用矩阵乘、算数逻辑运算及存储指令结构
2.2 基于RISC-V 的SoC 架构设计
本文采用开源RISC-V 处理器[11]作为系统级芯片(SoC)中的控制单元,并提出共享内存的设计架构,基于RISC-V CPU 的SoC 架构如图4 所示,整体架构通过一致性总线(TL)进行系统互联,利用TL 转高级可扩展接口(AXI)模块进行适配。RISC-V CPU 与神经网络推理加速器之间采用松耦合的互联方式,CPU 通过总线向神经网络推理加速器的AXI 从接口发送控制指令,控制加速器开始工作,并通过轮询方式检测加速器是否计算完成。针对如何快速处理在深度神经网络推理过程中的数据,提出共享内存架构,设计对应的连续内存分配函数(CMA),以动态分配较大的连续空间物理地址。本文将32 位ARM 处理器上的CMA模块移植到基于64 位RISC-V 的内核上,并针对RISC-V 架构调整虚拟地址到物理地址的映射方式,提高操作系统的内存使用效率。图4 中DDR 为双倍数据速率。
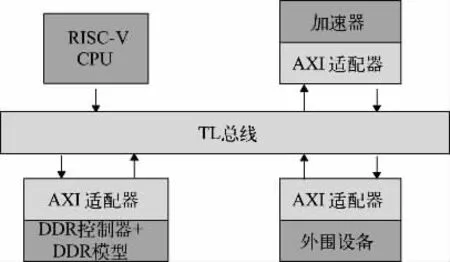
图4 基于RISC-V CPU 的SoC 架构
2.3 SoC 与神经网络加速器的集成设计
VTA 各模块与RISC-V 处理器通过AXI 总线协议[12]连接,AXI 互联模块包含AXI InterConnect 模块和AXI SmartConnect 模块,可将一个或多个AXI 内存映射的主设备连接到一个或多个内存映射的从属设备,更紧密地集成到硬件设计环境中,且能自动配置并适应所连接的AXI 主模块和从属模块,每一个被实例化的AXI 互联模块都包含一个AXI Crossbar 模块,用于多个主接口和从接口的连接。RISC-V SoC 内部总线互联架构如图5 所示,获取、加载、计算和存储模块的标准AXI 从属接口经过AXI InterConnect 模块与RISC-V 处理器的主接口连接,通过AXI 总线接收CPU 的控制信号;各模块的主接口通过AXI SmartConnect 模块与处理器经过AXI Crossbar 模块对动态随机存取存储器(DRAM)进行读写指令和数据的操作。VTA 内部提供了传输指令的指令队列、执行同步并发任务的依赖队列以及存储数据的片上缓存区(包含输入数据、权重值和输出数据)。
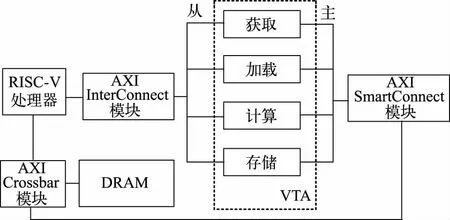
图5 RISC-V SoC 内部总线互联架构
3 基于RISC-V CPU 的神经网络加速器FPGA 实现
3.1 应用演示系统搭建
SoC 设计平台包括RISC-V SoC 生成器、编译工具链和系统仿真工具。SoC 架构采用共享内存的设计架构,并通过TL 进行系统互联。CPU 配置方案为单核100 MHz 顺序流水线、64 位RISC-V 架构CPU、片上独立的指令高速缓冲存储器和数据高速缓冲存储器,并配有Xilinx UltraScale DDR 控制器、安全数码卡(SD)控制器和通用异步收发传输器(UART)接口。
VTA 硬件架构的环境搭建主要分成以下几个阶段:1)构建加速器调用底层函数接口,用于调用VTA IP 核,配置传输参数;2)获取控制寄存器映射到用户空间的虚拟地址,对加速器的控制寄存器进行读写;3)获得各种虚拟地址对应的物理地址,传递给加速器的控制寄存器;4)将处理数据对应指令长度和物理地址通过AXI 接口写入控制寄存器;5)将加速器的控制信号通过AXI 接口写入其控制寄存器,加速器读取信号之后开始计算;6)CPU 通过轮询的方式监测加速器的工作状态,直至加速器计算结束或者用时超标;7)统计VTA 的计算时间,释放内存。
深度神经网络编译工具链是用于深度学习系统的编译器堆栈,面对不同的深度学习框架和硬件平台,实现了端到端的统一的软件栈,能够高效地把前端深度学习模型部署到CPU、GPU 和专用的加速器上,为了实现对深度神经网络的支持,本文设计了基于指令包裹的编译框架,通过将神经网络推理运算解耦成卷积运算和标量运算,基于所设计的指令集,定义卷积运算指令打包函数,能够自适应地生成卷积层的指令代码,同时用户可以在C 开发环境下,调用打包函数,进行运算的灵活分配。深度神经网络编译流程如下:1)导入前端基于数据流图的深度学习模型,并转换为计算图;2)计算图优化层,重构原始计算图,包括操作符融合和数据布局转换;3)张量优化层,包含张量描述、硬件源语调度优化等;4)根据优化目标探索搜索空间,找到最优解;5)生成对应的硬件平台代码与部署。
3.2 图像分类演示
CIFAR-10 数据集由60 000 张彩色图像组成,其中有50 000 张训练图像和10 000 张测试图像,共有飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车10 类,每类6 000 张,用作图像识别的数据集。
在硬件模块设计上,基于开源项目生成SoC 源码,基于Vivado 综合工具生成对应的比特流,使用RISC-V 64 位编译工具链生成对应的Linux 操作系统,并对操作系统以及应用程序进行仿真测试。在软件模块设计上,针对卷积运算测试,按照VTA 硬件配置对输入和权重进行循环拆解、重组补零,同时,在单个卷积层中,将大矩阵分块进行矩阵乘(分块大小为64 个),编译生成可执行的文件并上板验证,卷积运算验证结果如图6 所示,实现了3 种不同尺寸矩阵的GEMM 计算,试验结果表明,本设计能保证卷积运算的正确性。
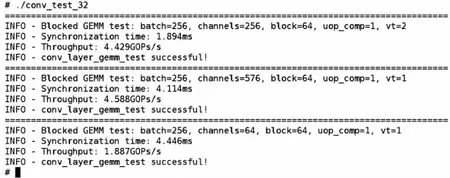
图6 卷积运算验证结果
为实现图像分类演示,首先,基于CIFAR-10 数据集完成了M-ZFNet 神经网络算法训练、权重量化与分割,量化长度为有符号的8 位整数(INT8),并将权重和输入数据解码处理生成bin 文件;其次,基于深度神经网络编译工具链将深度卷积神经网络转换成加速器运行的操作指令,编译生成可执行文件;最后,将bin 文件和可执行文件上板验证,依次完成12 张输入图像,输出维度为10×1,对应CIFAR-10 数据集中的10 个类别。同时,验证所设计的架构是否可灵活实现多种主流的深度神经网络,选取ResNet20 神经网络,为降低网络参数量,对开源ResNet20 进行微调(M-ResNet20),具体网络结构如下:1~7 层的卷积核大小为16@3×3,步长为1;8~13 层的卷积核大小为32@3×3,卷积层8 的步长为2,其他卷积层步长为1;14~19 层的卷积核大小为56@3×3,卷积层14 的步长为2,其他卷积层步长为1;平均池化层和全连接层均为1 层。FPGA 演示步骤同M-ZFNet。
两种网络的图像分类演示结果如表1 所示,输出向量最大值所在位置对应数据集中的类别,在本轮试验中,两种网络识别准确率均为91.67%(在CPU 端选取的12 张测试数据集和权重均为浮点型,且测试准确率为100%,对输入数据和权重进行的量化操作导致精度损失)。
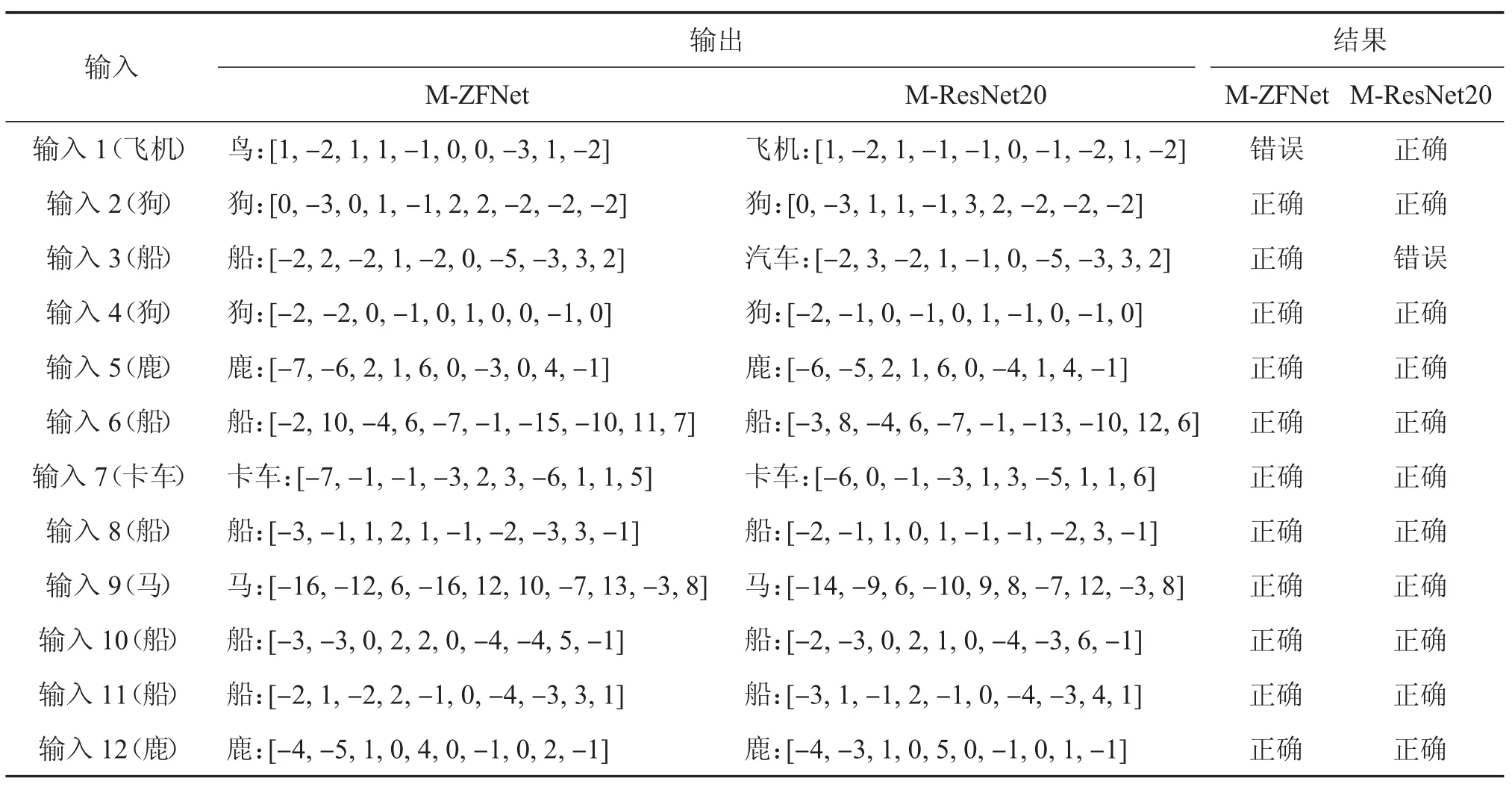
表1 两种网络的图像分类演示结果
在CIFAR10 测试集上推理,所提出的架构总体准确率预测如表2 所示。在CPU 端统计的M-ZFNet 和M-ResNet20 的整体准确率分别为86.36%和91.73%,而在FPGA 端统计的准确率分别为78.95%和84.81%。因为对输入数据和权重进行的量化操作导致了精度损失,所以FPGA 端低于CPU 端的统计结果;因为M-ResNet20 的网络层数较多,所提取特征的抽象程度较高,所以M-ResNet20 的预测准确率比M-ZFNet 高。试验结果表明,所设计的架构可实现主流的深度神经网络推理任务,实现智能通用运算。
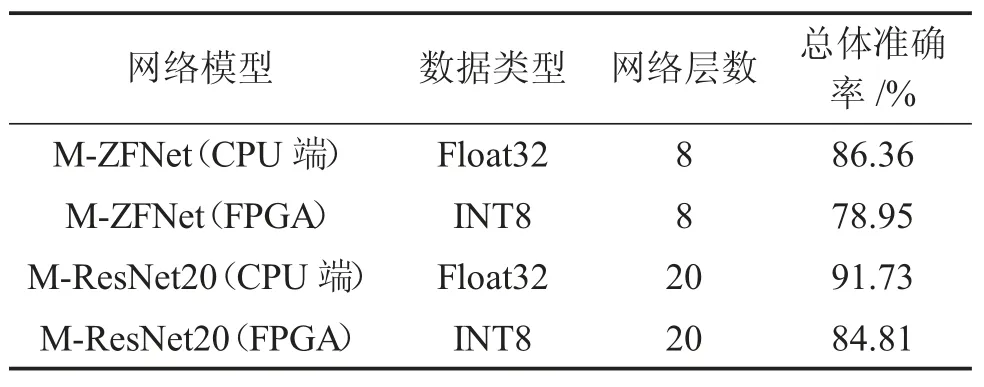
表2 两种网络总体准确率预测
4 结论
本文探索了基于RISC-V 处理器的神经网络架构设计与FPGA 实现,所设计的架构可灵活实现多种主流的深度神经网络推理任务,MAC 数目可达到1 024,量化长度为INT8,编译栈支持主流卷积神经网络的编译,最终完成卷积运算、ZFNet 和ResNet20 神经网络算法的部署,并完成CIFAR-10 图像分类演示,试验选取了12 张测试集,准确率均达到91.67%,且在FPGA端M-ZFNet 整体准确率达78.95%,M-ResNet20 整体准确率达84.81%。为了支持多种不同的神经网络推理任务,创新地提出了由4 条指令组成的基于宏操作的指令集,依据指令类型的不同可以分别完成数据加载、计算和结果存储等操作,利用这4 条指令的组合,可实现智能通用运算。
所设计的神经网络推理加速器在精度损失和加速性能方面还有一些方面可以进一步改进:1)由于目前的量化方案精度损失较大,后续工作可考虑将量化和训练相结合,在量化后通过微调训练来弥补量化的精度损失;2)未对神经网络加速器设计的数据吞吐量、计算速度、功耗、资源消耗等方面进行研究,后续将主要研究神经网络加速器的加速效果。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
少先队活动(2021年6期)2021-07-22
汽车工程(2021年12期)2021-03-08
测控技术(2018年5期)2018-12-09
计算机测量与控制(2017年6期)2017-07-01
电信科学(2016年10期)2016-11-23
电测与仪表(2015年22期)2015-04-09
科技传播(2015年20期)2015-03-25
