
基于改进时延神经网络的说话人识别方法*
2023-03-18 18:00:52胡贵超
计算机与数字工程 2023年12期
胡贵超
(南京理工大学计算机科学与工程学院 南京 210018)
1 引言
说话人识别分为说话人辨认和说话人确认,本文的实验是后者。首先用大量不包括识别集在内的其他说话者的语音特征训练本文提出的网络得到一个通用模型,注册时通过PLDA 训练获得待识别说话人的特征表达,在测试阶段,本文使用随机生成的1∶1 确认表,来判定两段语音特征是否是同一人。
传统的说话人识别大多使用i-vector[6]加PLDA 打分的方法,随着深度学习的发展出现了d-vector[7]和x-vector[1],d-vector首次尝试将深度神经网络(Deep Neural Network,DNN)应用在文本相关的说话人识别领域,因其识别效果能够达到传统的i-vector,且训练参数大为减少,成为了广泛应用的说话人识别方法。后来提出的TDNN 是DNN 在说话人识别领域的实现并改进,称为x-vector,该方法设计了一个包含多帧的神经网络,可以结合前后多帧同时提取特征,这在表达语音特征的时间关系上非常有帮助,多层网络的设置也使网络对特征有较强的抽象能力。x-vector 分为帧级别(frame-level)和段级别(segment-level)两种不同层的处理,时延体现在帧级别,中间的statistics pooling层将帧级别转换成段级别,之后得到特征表达。
本文使用x-vector 作为基线系统,在其结构上增加纹理增强模块(Texture Enhancement Module,TEM),TEM 中利用了QCO 获取细节特征的能力,来使网络结构提取特征的能力进一步增强。这种纹理统计的方法最初由文献[3]提出,首先应用在图像识别领域,统计化的纹理作为一种低层信息,在许多传统方法中均有广泛使用,类似于数字图像处理中经典的直方图均衡化,该方法对每个特征相对于平均特征的距离进行量化统计,得到统计的高维特征。本文应用纹理增强模块的目的是充分利用低层纹理特征部分,因此在x-vector 帧级别开始阶段即引入,将得到的纹理特征表达与x-vector 段级别特征表达融合后输出。
2 系统结构
2.1 传统x-vector系统
该系统结构是基于[1]中所实现的TDNN 网络,这里使用帧长25ms和帧移10ms的汉明窗在400帧长度的语音片段上进行滑动分帧处理,使用的特征为提取出的13 维mfcc 特征,在此基础上获得一阶和二阶差分组合得到包含39 维特征。x-vector 系统分为frame层和segment层,前五层是frame层,第一层处理时连接前后5 个帧长,第二层连接3 个帧长并且每帧中间间隔一帧,因此第二层连接了前后9帧信息,第三层连接3个帧长中间间隔两帧,共连接前后15 帧信息。之后经过4 层和5 层处理后输出维度由39维扩充到1500维。后面两层结构属于segment层,在进入segment之前,先由statistics polling层获取到1500 维的均值和方差,将这共3000 维的均值方差输入到两个segment 层,最终得到的是512*N维特征表示,N表示实际的说话人数量。
2.2 改进x-vector系统
改进后的系统增加了量化和计数算子(QCO)的统计方法[3],本文称之为qco-vector,结构如图1所示。QCO将输入特征量化为多个层次,每个级别都可以表示一种纹理统计信息,通过它可以很好地采样连续的纹理,以便于描述。量化后,计算每一层的强度,进行纹理特征编码。本系统所使用的特征处理方式同上,输入的39 维mfcc先进入frame层处理,第一层frame 可得到前后5 帧时间序列的信息,第二层得到前后9 帧时间序列的信息,第二层得到的结果送入第三次frame 的同时,也将其输入到纹理增强模块(TEM),TEM模块处理后得到的即为QCO 统计的纹理特征。TDNN 过程中,前5 层frame 处理后,同样进入statistics pooling 层计算出均值方差,等待TEM的输出。

图1 改进的x-vector网络结构
TEM 模块结构如图1 虚线框内所示。输入的是由frame2 得到的512 维特征表示,先进入1 维(1-d)QCO,输入先经过两层Conv1D+ReLU+BN 把512 维度降为128 同时特征位置移到中心,此时的输入记为A∈RC×H×W,计算得到全局平均特征g∈RC×1×1。随后计算特征图A中的每个特征点Ai,j(i∈[1,W],j∈[1,H]) 与g的余弦相似度,得到S∈R1×H×W:
之后把S量化成N等级的L=[L1,L2,…,LN],从S的最小值和最大值中均分出N个量化等级。Ln的计算:
对每个特征点Si∈R(i∈[1,HW])本文将其量化编码为Ei∈RN(i∈[1,HW]) ,最终得到E∈RN×HW,Ei,n的计算公式为
得到量化编码矩阵E之后,进一步得到计数图C∈RN×2:
Cat表示连接操作。
量化计数图C反映的是输入特征图的相对统计,为获取绝对统计信息,把全局平均特征g编码进C得到D,g需要先上采样至RN×C:
MLP表示扩大C的维度。MLP包含两层操作:第一层是经过Conv1D+ReLU+BN,再用LeakyReLU激活得到64 维,第二层是Conv1D+ReLU+BN 把维度扩展到128 维输出。128 维的C与g连接后再输入Conv1D+ReLU+BN,维度由256 降到128,D最终维度是128。
1 维QCO 之后,经过Conv1D+BN 层处理,计算出均值和方差,连接后再经过BN+Conv1D 得到最终的纹理增强模块(TEM)特征输出。TEM 处理结束后,其输出同frame5层计算的均值方差连接得到的维度为256,经过BN+Conv1D 后维度保持不变,这里得到的即为qco-vector 结果,训练时需要得到说话人数量的结果输出,此时通过最后一层全连接层,我们将得到说话人的预测输出,维度256*N。
两种网络结构的打分模型本文均使用概率线性判别分析(Probabilistic Linear Discriminant Analysis,PLDA),这种方法由文献[5]提出,最初用在图像识别领域,后来引入到语音识别和说话人识别。
测试时本文用PLDA 模型中训练好的参数打分,计算两个语音片段的对数似然比:
式中两个语音片段来自同一空间的假设为Hs,来自不通空间的假设为Hd,得分越高,则两个语音片段来自同一说话人的概率越大。
3 实验设置
3.1 数据集准备
本文使用北京希尔贝壳科技有限公司开源的Aishell中文语音集作为训练和识别数据集,该数据集共包括有400 个说话人,每个说话人有300 到400 个语音,语音时长在10s 以内,音频分成了训练集340 人,验证集40 人,测试集20 人,彼此之间没有重合的说话者。音频均为16kHz采样率,采用单声道16bit的wav音频文件。
3.2 特征提取
特征提取操作在训练网络之前即准备。本文使用的音频特征为2.1节提到的39维mfcc特征,将同一人的所有音频文件均分成400 帧长的的特征保存。本文把训练集的340人按8:2的比例分成神经网络的训练集和验证集,共得到训练集272 个说话人108861 个特征片段、验证集68 个说话人26989 个特征片段。PLDA 打分和测试过程使用的特征从语音集的验证集和测试集得到,验证集的40 人用于PLDA 参数训练,测试集的20 人用于PLDA 打分测试最后的识别效果,特征片段同样是400 维分割后保存。测试随机生成的确认表由测试集的20 人产生,第一列为待测试的特征片段,第二列为随机选择的其他特征片段,第三列为数字0和1,0 表示前面两列为不同说话人,1 表示前面两列是同一个说话人的不同特征片段,按一行是同一说话人一行是不同说话人间隔产生测试确认表,最终产生23944行对比数据。
3.3 实验结果
本文在文献[1]的x-vector 系统基础上做了改进和对比实验外,还选用了文献[14~15]两种改进版d-vector 来对比,由于最初提出d-vector 的文献[13]是文本相关说话人识别,这里选用文献[14~15]提出的文本无关说话人识别系统,文献[14]的d-vector是基于长短期记忆(Long short-term memory,LSTM)和Attentive Pooling Networks 的DNN 网络改进版本的实现,文献[15]则是基于CNN 实现的DNN 网络。实验设置了每次训练的批处理数为32,工作线程数为6,训练总轮数20 次,使用Adam优化器,学习率初始0.001,每一轮结束按0.9 比例衰减,20轮后学习率最终为0.000135。识别效果用等错误率(EER)来表示。
作者选用了几种不同数据量的实验来做对比,首先在Aishell 的Train 文件夹内选择一半的数据170人来做训练,PLDA选择Dev文件夹下的一半人数20人和全部人数40人分别进行实验。EER的结果如图2 所示,170 人的对比中d-vector(LSTM)、d-vector(CNN)、x-vector 和qco-vector 在20 人的PLDA 下EER 分别为15.16%、14.77%、13.50%和11.28%,在40 人的PLDA 下EER 分别为14.31%、14.43%、10.56%和8.65%,变化量均有降低。由图2的柱状图可以看出qco-vector 整体EER 较其他模型识别等错误率更低,识别效果更好。
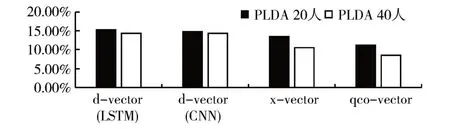
图2 Train170人各模型不同PLDA的的识别等错误率(EER)
然后在Aishell的Train文件夹内选择全部数据340人来做训练,PLDA仍然选择Dev文件夹下的一半人数20人和全部人数40人来进行实验。EER的结果如图3 所示,340 人的对比中d-vector(LSTM)、d-vector(CNN)、x-vector 和qco-vector 在20 人的PLDA 下EER 分别为11.62%、10.87%、11.91%和10.84%,在40 人的PLDA 下EER 分别为10.01%、9.28%、9.81%和7.18%。由图3 的柱状图可以看出qco-vector 整体EER 较其他模型识别等错误率更低,识别效果仍然更好。
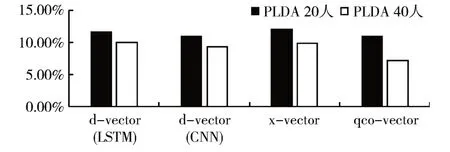
图3 Train340人各模型不同PLDA的的识别等错误率(EER)
4 结语
从3.3 节可以得出,不同的人数对几种神经网络模型和PLDA 打分效果均有影响,图2 和图3 可以看出,在神经网络模型训练人数不变时,PLDA人数由20 人增加到40 人,各种模型的识别效果均有提高。结合这两组实验,保持PLDA 训练人数不变时,训练网络结构的人数由170增加至340人,识别效果同样会增加,且两组对比实验里,本文所提出的qco-vector 结构均获得更低的等错误率,识别效果均为最高。本文的实验说明qco-vector网络结构在增加了QCO 模块后,QCO 的量化和统计功能可以从较浅的网络里提取语音的细节纹理特征,这在小数量训练集上即可以体现出优势,当网络模型和PLDA 的训练人数进一步增加时,这种纹理增强的效果体现则更为明显。
