
基于像素级分治策略的超分网络加速方法
2023-03-17 07:28刘智轩陆善贵蓝如师
无线电工程 2023年3期
刘智轩, 陆善贵, 蓝如师
(1.桂林电子科技大学 广西图像图形与智能处理重点实验室, 广西 桂林 541004;2.品创科技有限公司, 广西 桂林 541004)
0 引言
图像超分辨率重建技术是将输入模糊、包含信息较少的低分辨率图像重建为清晰、包含更多信息的高分辨率图像,是计算机视觉领域的一个经典问题。 生成图像还可以为下游的计算机视觉相关任务提供服务,如目标检测[1-3]、目标定位[4-5]等,可以增强任务效果,提高识别正确率。 在现实生活中,图像超分辨率重建应用前景十分广泛,如医学成像[6-7]、安全监测[7]和图像压缩[8-9]等领域。
随着深度学习在计算机视觉领域取得巨大成功,基于深度学习的图像超分技术也成为现今研究的主流方向,如最早基于卷积神经网络(Convolution Neural Network,CNN)的SRCNN[10]、基于生成对抗网 络( Generative Adversarial Network, GAN) 的SRGAN[11]。 然而,基于深度学习的图像超分算法虽然性能较高,但其计算复杂度通常会随分辨率指数级上升,难以满足现在4K 或8K 的超分应用场景上对于轻量模型且低算力功耗的要求。 因此,算法加速是图像超分领域的一个重要研究方向。 当前的超分算法加速主要研究方向分为2 大类:基于轻量化网络结构设计的超分加速方法研究和基于分治策略的超分加速方法研究。 其中,基于网络结构设计的加速方法[12-13]针对超分网络的结构进行设计改进,往往要求超分算法使用特定的网络,难以根据应用场景中算力条件复杂多变的需求灵活地调整算法复杂度,而基于分治策略的超分算法加速研究[14]针对整个算法的流程框架进行设计改进,不限于特定的网络结构,因此灵活度较高,可适用于更广泛的超分算法和应用场景。 因此,本文选取基于分治策略的图像超分加速方法进行研究。
现有分治加速法将大图像的超分问题分解成不同子图像块的超分问题[15],并根据每个子图像块的超分难易程度,使用不同计算复杂度规模的网络分别进行超分处理。 具体来说,处于较平滑区域的子图由于信号强度变化缓慢且均匀,因此超分的难度较小,使用较小的计算复杂度即可对其超分过程进行建模。 而处于边缘区域的子图由于所含高频信号较多,需要较为复杂的数学模型才可建模出所需的超分过程,即需要设计复杂度较高的网络结构来实现较好的超分效果。 总的来说,分治加速法中对每个子图的超分过程采用动态的网络参数量分配策略,相比传统固定的参数量分配策略,有效减少了冗余计算。 然而,该分治策略仅将子问题分解到了子图像块级别,而每个子图中,不同子区域仍可进一步划分出不同的超分难度,因此传统基于子图像块级的分治加速法尚未达到最优的加速效果。
基于上述问题,将分治策略中所分解的每个子问题从子图像块级进一步细化到像素级,根据不同像素所在位置的超分难易程度采用不同复杂度规模的网络来分而治之,从而在同等计算复杂度的限制条件下,进一步挖掘网络的潜在能力,最终实现更为高效的加速算法。 现有基于分治加速的图像超分方法可分为2 个关键模块:一是子问题分类模块,用于估计每个子问题的超分难易程度;二是图像超分模块,用于对每个子问题进行处理,即对其所属的图像区域进行超分。 首先,针对模块一,需要对每个像素的超分难易程度进行估计,不确定度估计大图像的超分问题分解成不同子图像块的超分问题[16]是经典的用于研究如何估计网络对其认知结果不确定性的方法,本文引入该思想用于评估图像中每个像素所在位置的超分难度。 对于图像中的每个像素所在位置,预测一个不确定度用于代表该位置的超分难度。 其次,针对模块二,本文提出了一个自适应像素特征精炼模块,根据每个像素的超分难易度,对超分困难的像素点高层特征进一步修正,从而实现了为不同像素所在区域的超分分配了不同规模的计算量,相比现有基于子图像块的计算量分配策略,本文方法更加精细且合理,最终实现了更为高效的图像超分方法。
本文方法的贡献分为3 点:
① 针对基于分治策略的图像超分加速问题,将现有方法中的子问题分解,从子图像块级进一步深入到了像素级,提出了基于像素级分治策略的超分网络加速方法,为不同像素所对应区域分配不同规模的计算量来实现超分过程,从而实现了更加高效的超分加速策略。 实验表明,本方法在相同计算复杂度的情况下,性能显著超越了现有基于分治策略的图像超分加速工作。
② 提出了一个联合困难像素挖掘的重建损失函数,损失函数可使得网络在重建超分辨率图像的同时,通过无监督自适应的学习预测出每个像素的超分难易程度,用于为每个像素点所在位置的超分分配更加合理的计算量。
③ 提出了一个自适应像素特征精炼模块,根据每个像素的超分难度,对超分困难的像素点特征进行采样,并通过一个共享参数的多层感知机结构对所选取的像素点特征进行特征修复,相比现有基于子图像块的计算量分配策略,更加精细且合理。
1 相关工作
尽管相关研究已经取得了重大进展,但现有的轻量级图像超分辨率模型还需要进行比较深入和广泛的研究,并且轻量级图像超分辨任务经常需要处理大型图像。 研究人员提出了多种技术,主要是基于插值的方法,如双线性插值、双三次插值、曲率插值和自适应图像插值;基于重建的方法,如迭代反投影法、凸集投影法和最大后验概率法;以及基于示例的学习方法,如邻域嵌入方法、稀疏表示方法和回归图像插值方法。 然而,传统方法不能重建图像的高频细节,因为轻量级图像的超分辨率是一个难以解决的问题。 随着机器学习在计算机视觉领域的发展,深度学习已广泛应用于轻量级图像超分辨率重建任务,并具有良好的重建效果。 如今,基于深度学习的轻量级图像超分辨率方法正逐渐受到关注。 下面介绍轻量级图像超分辨率的一些相关理论和技术成果。
1.1 基于局部线性回归的图像超分辨率
大多数轻量级超分辨率算法在重建过程中必须经常解决最小二乘问题,从而增加了系统的总体计算负载[17]。 为了解决这个问题,Hardiansyah 等[18]提出了“锚定邻域回归”(Anchored Neighborhood Regression,ANR)模型,该模型基于局部线性回归方法,显著提高了重建速度。 Choi 等[19]提出了基于局部线性映射和回归方法的基于GLM-SI 的局部回归方法。 该方法使用KNN 在执行局部回归以获得全局图像之前生成大量的局部候选,还可以进一步改善高分辨率图像块之间的映射关系,从而提高重建图像的质量。 此外,基于局部线性映射的全局回归算法在计算方面优于传统的CNN 轻量级超分辨率算法。
1.2 基于邻域嵌入的图像超分辨率
用于轻量级图像超分辨率的传统局部线性回归算法中的重建高分辨率图像仅来自训练集附近的相邻样本,因此该模型的表达能力非常有限,严重限制了重建图像的质量。 在某种程度上,邻域嵌入可以解决这个问题。 刘磊等[20]提出了一种基于邻域嵌入的超分辨率算法。 在轻量级图像的超分辨率问题中,在每个检测到的图像块的训练集中找到K个相邻点的低频图像块,并使用最小二乘法计算其重建权重,一定程度上解决了相关问题。
1.3 基于稀疏表示的图像超分辨率
当处理轻量级图像的超分辨率问题时,稀疏表示可以基于每个检测到的图像块自适应地确定对应字典单元的数量[21]。 为了获得更好的重建边缘和纹理,不需要预先确定相邻点K。 为了优化超分辨率重建问题,葛鹏等[22]提出了稀疏先验概念来约束超分辨率问题。 基于稀疏表达式的超分辨率技术能以比稀疏信号的奈奎斯特采样理论更低的频率进行采样,从而准确地重建信号[23]。
1.4 基于K-NN 的图像超分辨率
基于K-NN 学习的轻量化图像超分辨率重建技术使用马尔可夫网络建立高分辨率图像和高分辨率场景之间的关系模型,并使用信号传播算法对高分辨率图像进行最大后验估计[24]。 K-NN 算法通过对图像的初始值进行预处理,改善了图像的边缘、脊、角和其他区域,有效降低了轻量化图像的超分辨率重建的模糊性[25]。 然而,这类算法的重建质量严重依赖于样本的数量,这增加了计算负载,使其不适合实际使用。 此外,如果训练集中的输入图像与训练集的结构不一致,则重建效果将显著降低。
1.5 基于深度学习的图像超分辨率
随着近年来深度学习技术的快速发展和成功应用,基于深度神经网络的轻量级图像超分辨率重建方法引起了许多研究人员的兴趣[10]。 基于深度学习的轻量级图像超分辨率重建方法采用多层神经网络直接在低分辨率和高分辨率图像之间建立端到端的非线性映射关系[26]。 例如,LapSRN 使用渐进方法来提高图像分辨率,但它会在网络中间生成大尺寸的特征映射,导致网络计算显著增加[27];CARN通过级联机制集成了多个级别的信息,由于使用了密集连接,引入了许多参数和计算[28];IDN 使用信息蒸馏机制通过跳过连接传输一些特征,以减少网络参数的数量[29],但不能有效地过滤掉需要进一步细化的重要特征,模型性能还有进一步提高的空间。因此,基于深度学习的轻量级图像超分辨率技术仍是一个值得深入研究的课题。
2 基于像素级分治策略的超分网络加速方法论
2.1 基于分治策略的超分加速方法概述
针对分治加速,选取基于分治策略的图像超分加速算法进行研究,在该研究领域,最具代表性的方法是ClassSR[30],因此,选取该方法作为本文的基准,下面首先对ClassSR 进行简要的介绍。
ClassSR 通过将分类和图像超分结合在一个统一的框架中来实现分治加速策略。 具体来说,首先,将每张输入的原始图像划分成不同的子图像块,对每个子图像块的超分可看作一个单独的子问题进行处理;其次,使用分类模块根据每个子图像块超分的难易程度将其分类为不同的类别;最后,应用图像超分模块对不同类别的子图像块分别执行超分过程。其中,分类模块采用传统的分类网络,而图像超分模块是由待加速的原始超分网络及其通道缩减后的轻量化版本组成的网络集合。 经过联合训练,大部分被分类模块划为易超分的子图像块,将通过小规模的网络进行超分,因此可以显著降低计算成本。
ClassSR 将每个图像块的超分看作一个子问题,从而通过合理分配每个子图像块的超分计算量来达到网络加速的目的。 借鉴该工作的思想,认为当子问题被划分的更小时,整个超分网络的计算量会被分配的更为合理,从而得到更好的整体加速效果。 因此,在ClassSR 基础上把子问题进一步划分到了比图像块更精细的像素级,根据低分辨率图像中每个像素所对应子区域的超分难易程度,分配不同大小的计算量,从而得到更好的整体加速效果,子图像块级分治策略和像素级分治策略的精细程度对比如图1 所示。

图1 子图像块级分治和像素级分治策略的子问题精细程度对比Fig.1 Fineness comparison of sub-problem between image patch level divide-and-conquer strategy and pixel level divide-and-conquer strategy
2.2 基于像素级分治策略的超分加速方法
在ClassSR 所采用的分治策略下,为了实现像素级的分治加速法,首先要从原始低分辨率图像中估计得到每个像素所对应子区域的超分难易程度,进而设计不同复杂度规模的超分网络对其分而治之。
然而,该问题的解并不直观,无法沿用ClassSR的方式直接将每个超像素单独输入到分类网络去预测超分难易度。 具体来说,单一像素所对应的子区域由于在图像中的覆盖范围极小,导致该范围内的图像信号变化均很微弱,因此,无法仅通过单一像素所提供的信息判别出其超分的难易程度,需要一定的上下文信息作为辅助。 为了解决该问题,在保留ClassSR 的主体结构,仍将原图像划为多个子图像块分别作为网络输入的同时,为每个超分网络额外增加一个分支,预测出一个与输入图像比例相同的得分响应图,该响应图每个位置的值即用于表示该位置像素的超分难易程度。 从结构上分析,由于该响应图在CNN 的高层预测得到,每个位置均具有较大的感受野,可以有效地利用到上下文信息,从而解决了单一像素上下文信息不足的问题。
在感受野足够的条件下,另一个核心问题是对像素超分难度的预测,受不确定度估计工作的启发,将原有图像超分网络所使用的L1像素重建损失函数改进成一个联合困难像素挖掘的重建损失函数,该损失函数可使得网络在重建超分辨率图像的同时,通过无监督学习预测出每个像素的超分难易程度。 公式为:
式中,fH(x)i为ground-truth 高分辨率图片上第i个位置的像素值;Hi为超分网络预测的高分辨率图片中第i个位置的像素值;fS(x)i为超分网络预测的不确定度响应图上第i个位置的响应值,即i像素所对应的不确定度。 可见,当目标像素所对应的子区域难以通过超分重建出来时,式(1)第1 项中重建损失的值会较大,此时,为了使得网络整体损失平衡在一个较小的值,需要牺牲第2 项,通过预测一个较大的不确定度值fS(x)i来减小第1 项的损失大小。可见,fS(x)i值的大小与训练样本中像素i的重建误差正相关,因此可用来表示该位置像素的超分难度。 在具体实现时,在网络的最后一层增加一个输出通道来表示不确定度的响应图,与高分辨率图像一起输出,使得不确定响应图与高分辨率图像具有相同的尺度和大小。
得到每个像素的超分难易度后,需要根据该超分难易度,为每个像素所对应子区域自适应分配合理规模的计算量进行超分,超分难度大的像素所对应区域应分配较大的参数量来进行计算,而超分难度小的像素所对应的区域应分配较小的参数量。 据此,提出了一个自适应像素特征精炼模块来实现该过程。 该模块首先根据不确定图响应图提供的信息,在网络中间层和最高层特征采样出超分较为困难的像素所对应的特征向量,之后对于每个采样到的特征向量,通过一个参数共享的多层感知机对特征进行进一步的融合和精炼,其框架如图2 所示。
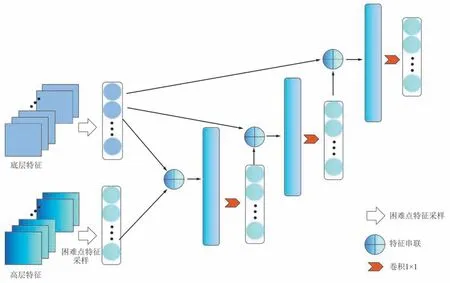
图2 自适应像素特征精炼模块网络框架Fig.2 Network framework of adaptive pixel feature refining module
相比于ClassSR 中对于整个子图像块中的每个像素使用同等计算量进行超分的方式,本文方法在每个子图像块内部进一步使得超分较为困难的子区域分配到了更多的网络参数进行学习,从而实现了对于每个像素级子问题分而治之的策略,最终使得整体超分网络更加高效。 对于困难样本的采样规则,采用了与经典图像分割算法PointRend[31]中相同的困难点采样方式,将不确定度大于0. 065 的像素视为超分困难像素,对重点像素进行采样的同时,结合一定比例全图均匀采样,以帮助在训练中提升适应像素特征精炼模块的鲁棒性。 算法的整个框架如图3 所示。
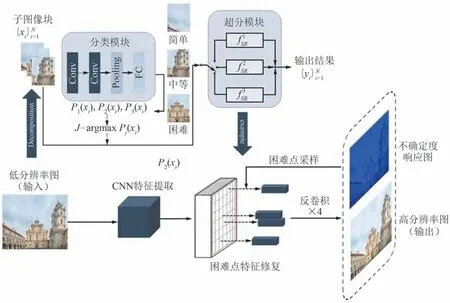
图3 基于像素级分治策略的超分网络框架Fig.3 Framework of super-resolution network based on pixel-level divide-and-conquer strategy
将各层的特征图提取出这样一个特征张量,通过一个全连接网络进行精炼,训练将学习超分困难点的修复。 具体实现为3 层1×1 卷积网络,每次将倒数第2 层特征与其前一层特征按第一维拼起来,通过1×1 卷积后得到的新特征再次重复拼接,再次通过卷积,然后输出通过一个1×1 卷积将通道数恢复为倒数第2 层网络的原通道数,并将新特征覆盖原特征图,最后通过超分网络原本的反卷积层恢复重建图像,训练所使用的损失函数为上述LHCS。
经过实验分析,最终发现选取第2 层和最高层特征加入提出的自适应像素特征精炼模块会得到最好的性能。
3 实验结果与分析
3.1 数据集与实验设置细节
3.1.1 数据集
实验过程中使用到的数据集有DIV2K,DIV8K,Set5,并且有对这些数据集做了重新划分再使用,先分别简单介绍3 个数据集的相关信息,再从训练、验证和测试的角度分别介绍重新划分使用的情况。
DIV2K[32]:NTIRE2017 超分辨率挑战赛发布的用于图像复原任务的高质量(2K 分辨率)图像数据集。 DIV2K 数据集包含800 张训练图像,100 张验证图像和100 张测试图像。
DIV8K[33]:DIV8K 是AIM2019 新构建的一个数据集,它包含1 500 张分辨率最高达到8K 的图像,相比 DIV2K,具有更多样性的场景,用于进行16 pixel 和32 pixel 超分任务的训练。 此外,还分别有100 张用于验证和测试的高分辨率图像。
Set5:该数据集是由5 张图像(“婴儿”“鸟”“蝴蝶”“头部”“女人”)组成的数据集,通常用于测试图像超分辨率模型的性能。
对以上数据集进行了重新划分,以便适应实验需要。 在SR-Module 中使用DIV2K 训练集作为单分支预训练的训练数据,首先将DIV2K 训练集中索引为0001~0800 的图像分别进行0. 6,0. 7,0. 8,0.9,1.0 降采样因子的尺度变换,得到4 000 张原始高分辨率图像。 接着,将原始高分辨率图像进行模4 取整,再进行降采样4 倍得到4 000 张原始低分辨率图像。 然后,将原始高分辨率图像和原始低分辨率图像分别进行裁剪成1 594 077 张的128 pixel×128 pixel 的高分辨率子图像,以及1 594 077 张的32 pixel×32 pixel 的低分辨率子图像,根据这些子图像通过MSRResNet[34]的峰值信噪比(Peak Signal to Noise Ratio,PSNR)值,将子图像平均分为3 类(高分辨率子图像和低分辨率子图像分别各自分类)。最后,获得用于SR-Module 预训练的“简单、中等、困难”数据集。 SR-Module 使用的验证集为Set5。
将DIV2K 验证集高分辨率图中索引为0801~0900 的图像,以及低分辨率图中索引为0801×4~0900×4 的图像,进行裁剪得到高分辨率128 pixel×128 pixel 以及低分辨率32 pixel×32 pixel 的子图像,根据这些子图像通过MSRResNet 的PSNR 值,将子图像平均分为3 类(高分辨率子图像和低分辨率子图像分别各自分类)作为SR-Module 测试集。
本文方法的分类模块使用上述步骤中生成的1 594 077 张的128 pixel×128 pixel 高分辨率子图像,以及1 594 077 张的32 pixel×32 pixel 低分辨率子图像作为训练集,不需要将子图像进行PSNR 值的分类,Class-Module 将通过训练学习将子图像自适应分类。 从DIV2K 验证集中选择了10 张图像(索引为0801~0810)在Class-Module 训练期间作为验证集。
分类模块的测试集来自DIV8K,共300 张原始图(索引为1201~1500)。 索引1201~1300 的图像下采样为2K 分辨率的高分辨率图,并再次下采样4 倍作为低分辨率图。 索引1301~1400 的图像下采样为4K 分辨率的高分辨率图,并再次下采样4 倍作为低分辨率图。 索引1401~1500 的图像直接作为高分辨率图,并再次下采样4 倍作为低分辨率图。所有图像均通过与训练阶段一样的裁剪得到子图像,但不需要将子图像进行PSNR 值的分类,以此得到分类模块的测试集。
3.1.2 实验参数设置
在实验中,同ClassSR 类似,本文方法分为超分模块和分类模块。 超分模块训练与测试使用的图像均为32 pixel×32 pixel 的子图像,分类模块训练使用的图像为32 pixel×32 pixel 的子图像,测试使用的图像是2K/4K/8K 的大图像。 本实验分为2 阶段训练:先是超分模块的预训练,然后是分类模块的联合训练。 超分模块预训练使用的网络结构为FSRCNN原超分网络并入PRM 模块,3 个分支(simple,medium,hard)的中间层卷积层通道数分别是16,36,56,训练batch 大小设置为64,网络使用的学习率下降策略为CosineAnnealingLR,初始学习率为10-3,训练周期为500 000 个iter,最小学习率为10-7。 分类模块网络结构选用ClassSR 原网络结构,训练batch 大小设置为96,网络使用的学习率下降策略为CosineAnnealingLR,初始学习率为2×10-4,训练周期为200 000 个iter,最小学习率为10-7。 实验过程中,先对超分模块进行3 个分支(simple,medium,hard)的预训练,然后先固定分支超分网络权重联合训练分类模块,最后再进行finetune。 算法实现所采用的深度学习框架为PyTorch,并在一块NVIDIA GeForce RTX 3090 上进行实验。
3.2 对比实验
DIV2K:将自划分的DIV8K 的子集(test2K,test4K,test8K)作为测试集,将本文提出的方法与现有主流方法进行性能对比,如表1 所示。
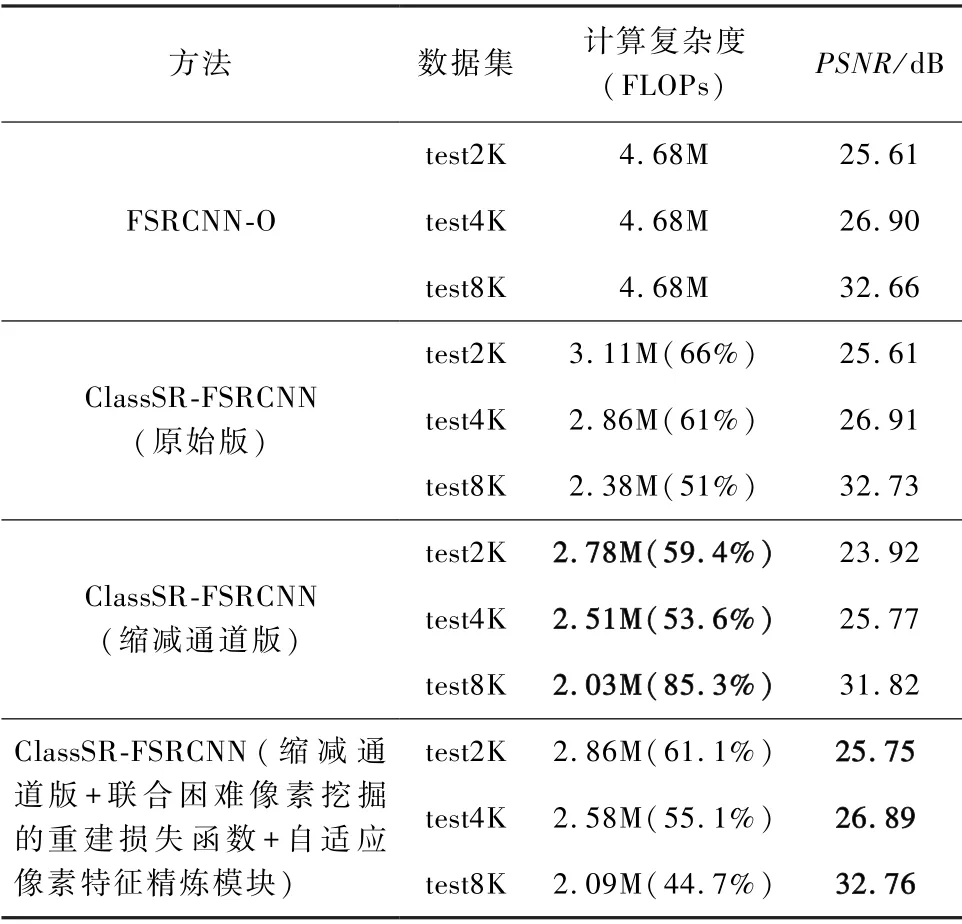
表1 不同超分加速算法在DIV8K 测试集上PSNR 性能对比Tab.1 Comparison of different super-resolution acceleration methods on DIV8K test set in terms of PSNR
同其他基于分治策略的超分加速方法类似,本文的主干网络均支持任意结构和参数量的网络,为了公平,所有方法中用于加速的原始网络均采用FSRCNN 方法[35]中的超分网络。 同时,由于本文方法相比ClassSR 增加了少量计算量,在实验中采用了通道数更少的ClassSR 版本用于本文的基准方法,使其整体计算复杂度不高于原始的ClassSR 方法,从而便于对比各方法的加速效率。 由表1 可以看出,本文方法在计算复杂度更低的前提下,性能仍不低于原始版本ClassSR 方法,该现象说明了本文方法所使用的像素级分治策略相比子图像块级的分治策略,可更为精细地对不同局部区域分配合理且不同的参数量进行超分计算,最终有效提升了超分网络的加速效率。
3.3 算法各模块分析
为了验证提出的基于像素级分治策略的超分网络加速方法中各个模块发挥的作用,通过控制变量配置了3 组不同的实验并在DIV8K 的子集(test2K,test4K,test8K)上进行了测试和分析。 为了公平对比各个方法,本文实验中所使用的主干网络均为ClassSR-FSRCNN 网络,输入图片的尺度均为32 pixel×32 pixel,通道缩减后的轻量化FSRCNN 组合的通道数分别为14,32,50,其中14 用于简单子图像块,32用于中等子图像块,50 用于困难子图像块。
为了验证所提出的联合困难像素挖掘的重建损失函数的有效性,在原始基于子图像块分治加速的ClassSR 方法中将L1重建损失函数替换为提出的联合困难像素挖掘的重建损失函数进行实验,并采用DIV8K 测试集进行评估,结果如表2 所示。
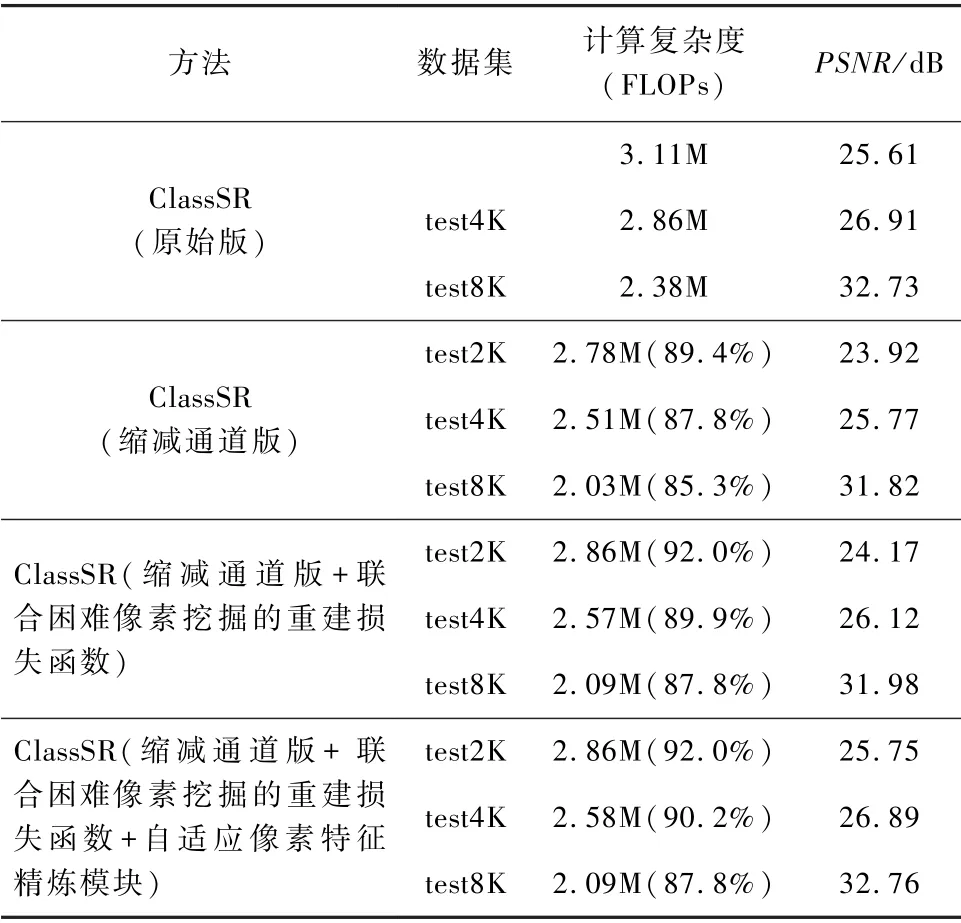
表2 各模块对整体算法性能的影响Tab.2 Influence of different modules on the overall algorithm performance
加入联合困难像素挖掘的重建损失函数将ClassSR 在test2K,test4K 和test8K 三个测试集上的PSNR 值分别提升了0. 25,0. 35,0. 17 dB。 该现象说明,在重建学习的过程中引入不确定估计可动态自适应地调节困难像素点的学习权重,使得网络更专注于容易优化的误差,从而更好地发挥网络的拟合能力。
为了验证所提出的自适应像素特征精炼模块的有效性,进一步在联合困难像素挖掘的重建损失函数所训练的ClassSR 网络的基础上加入该模块对困难像素点进行挖掘和特征修复。 由表2 可以看出,加入自适应像素特征精炼模块后,本方法在test2K,test4K 和test8K 三个测试集上的PSNR 值分别进一步提升了1.58,0.77,0.78 dB。 可见,由于2K 测试集分辨率最低,其超分困难像素点的数量占比也相对最多,因此,加入困难像素的特征修复对该测试集的性能提升更为显著。 同时, 相比原始版的ClassSR,在不损失PSNR 精度的前提下,在test2K,test4K 和test8K 三个测试集上的分别节省了8%,9.8%和12.2%的计算复杂度。 可见,本文方法可实现在复杂度更低的条件下,得到更高的性能。
3.4 分析实验
困难像素点采样阈值分析:根据网络预测的不确定度响应图判断每个像素点的超分难度,并按照固定的采样比例,将超分困难度最高的前N个像素点特征通过多层感知机进行特征修复。 为了分析困难点采样比例对性能的影响,统计了不同采样比例下最终模型的性能表现,并用DIV8K 的test2K 子集进行评估,如表3 所示。
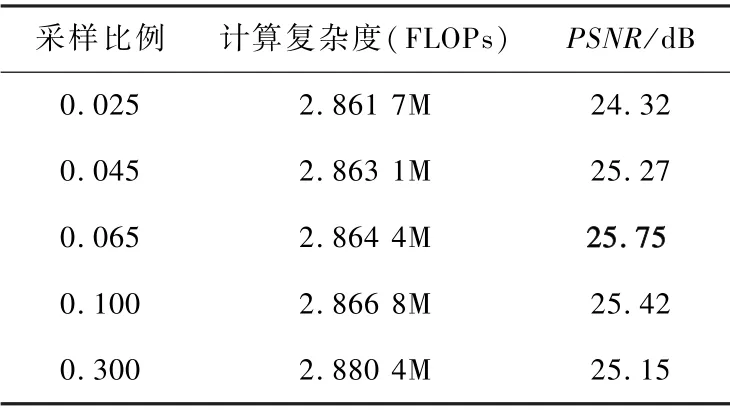
表3 不同超分困难像素点采样比例对性能和计算复杂度的影响Tab.3 Influence of different difficult pixel point sampling rate on performance and FLOPs
提升困难样本采样率对计算复杂度的影响不大,且当困难像素点特征的采样率达到0.065 时,取得了最优的性能25.75 dB。 当采样率更高时,性能逐渐退化,由于特征修复模块的参数量较小,因此,过多的困难像素点加入训练影响了其网络的泛化能力。
特征修复层选取分析:由于困难像素点特征的修复可选用网络的任意中间层与最高层进行融合,为了分析不同特征层的选取对算法超分性能的影响,实验了在不同层加入自适应像素特征精炼模块后对像素特征进行修复后网络的性能表现,并采用DIV8K 的test2K 子集进行评估,结果如表4 所示。发现使用第2 层的特征进行融合修复后取得了最优的性能,此时可以更好地结合低层和高层的特征信息进行全局的优化。
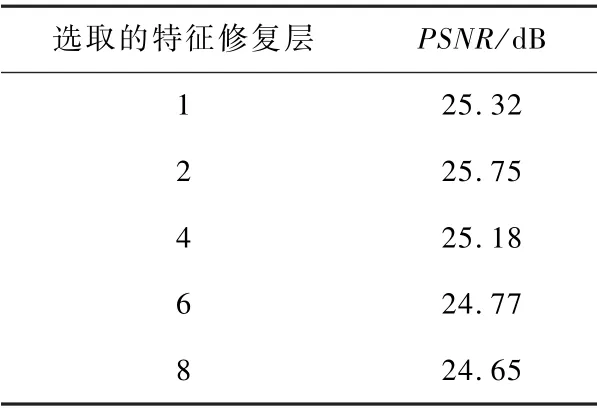
表4 选取不同层进行特征修复对性能的影响Tab.4 Influence of selecting different layer to apply feature refining on performance
参数量和推理时间:为了分析所提出的像素级分治加速法在参数量和实际硬件推理时间上的表现,与原始ClassSR 工作进行了对比,并采用DIV8K的test2K 子集进行评估,结果如表5 所示。
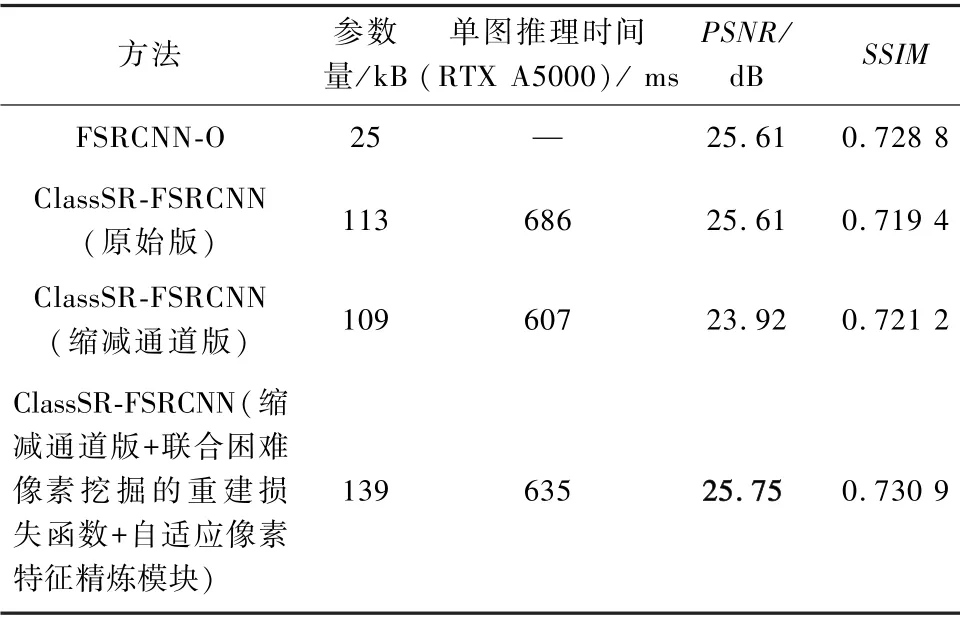
表5 不同超分加速算法的参数量及硬件推理速度对比Tab.5 Comparison of different super-resolution acceleration methods in terms of parameters and hardware inference speed
提出的方法由于引进了不确定度估计和像素精炼模块,在参数量上有一定的增加,但由于所增加模块的硬件友好性,在PSNR 和SSIM 性能不下降的前提下,仍然显著快于基于子图像块分治策略的ClassSR 方法,从而验证了本文方法在算法加速方面的有效性。
3.5 可视化分析
为了定性地验证本文方法进行像素级分治策略的实际意义,通过实验对不同像素点的超分困难度进行了可视化。 如图4 第3 列所示,本文方法很好地将塔尖、山峰等边缘高频信号位置的像素点作为困难点进行挖掘。 相比图4 第2 列中ClassSR 所使用的子图像块级别的子问题分类方法,本文方法更为精细,从而对整体的计算量进行了更合理地分配,最终实现了更为高效的图像超分网络加速方法。图5 展示了本文方法和基于子图像块级别分治策略的ClassSR 方法的超分结果对比,实验中2 个方法采用相同通道数配置的主干网络,可见本文方法在细节上的表现更优于ClassSR 方法。

图4 像素级子问题分解和子图像块级子问题分解对比示例Fig.4 Examples of image patch-level divide-and-conquer result and pixel-level divide-and-conquer result

图5 不同方法的超分辨率结果图示例Fig.5 Super-resolution results of different methods
4 结论
在现有基于分治策略的图像超分加速算法将大图像的超分问题分解成不同子图像块的超分问题,并根据每个子图像块的超分难易程度,使用不同复杂度规模的网络对其分别进行超分处理,然而,该分治策略仅将子问题分解到了子图像块级别,尚未达到最优的加速效果。 基于该问题,本文提出了基于像素级分治策略的超分网络加速方法,将分治策略的子问题细化到像素级。 引入不确定度估计思想,提出了联合困难像素挖掘的重建损失函数挖掘每个像素点的超分难度,并设计了一个自适应像素特征精炼模块对采样的困难像素特征进行修复,从而实现了为不同像素分配不同规模的计算量的方式来进行超分算法加速。 通过在DIV2K 和DIV8K 公开集上的实验验证,本文方法相比现有基于分治策略的超分加速方法得到了显著的效率提升。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
雷达学报(2020年3期)2020-07-13
红领巾·萌芽(2019年8期)2019-08-27
数学物理学报(2019年3期)2019-07-23
家庭影院技术(2018年9期)2018-11-02
中国与非洲(法文版)(2017年10期)2017-11-23
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
CHIP新电脑(2016年3期)2016-03-10
太空探索(2015年8期)2015-07-18
