
基于庞大算例变量提取的办公建筑能耗预测方法及应用
2023-03-17 01:34:02连会会陈永保谢静超刘加平
北京工业大学学报 2023年3期
姬 颖, 连会会, 陈永保, 谢静超, 刘加平
(1.北京工业大学城建学部, 北京 100124; 2.北京工业大学绿色建筑环境与节能技术北京市重点实验室, 北京 100124;3.上海理工大学能源与动力工程学院, 上海 200093)
我国承诺到2030年前停止增加二氧化碳排放,争取2060年前实现碳中和[1]. 我国公共建筑能耗及碳排放量呈增长趋势,截至2019年,公共建筑运行碳排放量为6.5亿t(以CO2计),占建筑运行总碳排放量的30%,碳排放强度高达48 kg/m2[2]. 设计优化、运行优化和节能改造都是公共建筑节能减排的主要途径. 合理的能耗预测是上述工作的重要环节,对公共建筑供需匹配和建筑能源系统智能控制有重要意义[3-4].
建筑能耗预测方法可分为能耗指标法、能耗模拟法和数据挖掘法. 能耗指标法是一种静态的能耗估算方法[5];模拟法应用专业软件,可计算动态能耗,结果准确,针对性强,但输入参数烦琐且建筑几何模型确定后往往无法更改[6];数据挖掘法又包括回归分析法、时间序列法、人工智能法. 相比之下,人工智能法具有计算速度快、适用条件多样等优点[7-8],但是大多数算法需要用到长时间历史数据进行训练,受到数据样本的限制.
Kawashima等[9]于1995年比较了传统机器学习方法和神经网络模型对冰蓄冷系统未来24 h逐时负荷的预测精度,表明人工神经网络模型的相对误差最低. 朱俊丞等[10]综述了传统机器学习算法、人工神经网络算法和深度学习算法在电力系统负荷预测领域应用,指出深度学习算法效果更优. 高英博[11]基于支持向量机算法、长短期记忆神经网络算法和XGBoost(eXtreme Gradient Boosting)算法建立能耗预测模型,并在4栋公建内进行试验,指出模型均有良好的预测效果. Wang等[12]用12个数据驱动模型(7个浅层学习、2个深度学习和3个启发式方法)预测建筑负荷,对比表明XGBoost算法和长短期记忆神经网络算法的负荷预测效果最好;针对长期预测,XGBoost模型预测效果更好一些. 综上可知,对于建筑能耗长期预测,XGBoost算法效果更好,但该算法仍存在一定的局限性,如模型训练过程中,因训练数据量和特征维度过大或过小会导致模型的过拟合或欠拟合现象.
目前,把建筑历史能耗数据作为训练集来建立预测模型已经可以取得很好的精度. 然而,在建筑历史能耗数据未知的情况下,仅依靠建筑自身特征、运行状况和气象参数来建立的模型的精度并不理想[13]. 同济大学许鹏团队等发起的“能耗侦探”建筑能耗预测竞赛,100个参赛队伍,在不知建筑历史能耗数据的情况下,最优队伍的模型预测准确性在30%左右[14]. Neto等[15]采集了1座实际建筑的54条样本建立模型,验证结果误差为21%. Massana等[16]选用4座实际建筑,采集了87 920条样本建立模型,验证结果误差为16.35%.
在上述分析基础上,本研究提出构建一种基于庞大算例变量提取的办公建筑能耗预测模型. 试图摆脱模拟软件物理建模和长时间历史数据获取需求的限制,并且保证良好的预测精度. 下面对该模型的研究方法、建立流程和应用效果进行详细阐述. 本研究模型建立和验证基于Python实现,并应用于北京市某办公建筑.
1 研究方法
如图1所示,通过文献调研和现有模拟软件分析,得到建筑能耗的影响因素集,利用EnergyPlus中已搭建好的物理模型,采用控制变量法逐一离散化地改变影响因素取值,获得模拟样本数据,每一条样本数据包含所有影响因素的取值和计算得到的冷、热负荷值和能耗值,最终得到模拟样本数据库. 利用搭建的数据库,采用轻量级梯度提升机(light gradient boosting machine,LightGBM)算法筛选出关键负荷影响因素并构建负荷预测模型. 结合EnergyPlus中空调设备能耗计算模型,实现只需要输入一些关键的建筑信息就可以预测建筑全年能耗的目标,并用实际建筑数据对模型进行验证.

图1 研究技术路线图Fig.1 Framework of this study
1.1 数据库的构建
通过文献调研和EnergyPlus需要用的设置参数汇总[17-18],得到影响建筑能耗的因素分为以下5类:建筑基本信息,主要包括体形系数、建筑面积、高度、窗墙比、围护结构热工性能等;外部气象条件,主要包括温度、湿度、风速、太阳辐射水平等;用能系统性能参数,如照明功率密度、冷机COP、水泵效率等;室内环境控制条件,包括室内温度、湿度、新风量等;时间表,包括照明和设备时间表. 本研究旨在预测办公建筑的能耗,输出变量为逐时能耗数据. 该调研得到的重要因素可为构建模型数据库奠定基础.
为保证预测模型具有较好的精度及适用性,本研究选择业界认可、应用广泛的EnergyPlus软件构建模型的数据库,应用Python调用EnergyPlus中已搭建的物理模型,采用控制变量法逐一等间距离散化地改变主要建筑参数,生成6 000个建筑算例,覆盖不同几何特征的建筑形态,共生成1 048 575条模拟数据样本,每一条数据形式为同一时刻下所有输入变量和输出变量的具体数值,所有模拟数据样本构成模拟数据库. 该方法不仅可以保证模型的多样性,还可以保证训练数据的数量和质量. 实现流程如图2所示.

图2 模拟数据库生成路径Fig.2 Generation process of the simulated database
1.2 LightGBM模型
1.2.1 模型原理介绍
GBDT(gradient boosting decision tree)算法是被广泛使用的一种算法,XGBoost是该算法的典型框架,但当特征维度较高、数据量大时,存在效率和可扩展性的问题,主要原因是对于每一个特征的每一个分裂点,都需要遍历全部数据计算信息增益,这一过程在空间和时间上有很大的开销[19]. 针对该不足,微软团队于2016年提出LightGBM模型,LightGBM是实现梯度提升决策树算法的新型框架之一,具有准确率高、处理数据量大等优点. 该算法核心内容为
(1)
式中:f(x)为训练样本对应的目标值;Q为基学习器的个数;αq为第q个基学习器的权重系数;x为训练样本;θq为学习器分类的参数;T(x,θq)为参与学习训练的第q个基学习器.
损失函数和训练数据确定之后,算法的训练过程即为求解损失函数极小值的优化问题,其目标函数为
(2)
式中:H为样本个数;h为样本序号;yh为数据的实际数值;f(xy)为第h个样本对应的目标值;L(yh,f(xh))为第h个样本的损失函数值.
GBM为基于梯度下降算法得到的提升树模,在每一次加入新的子模型后,保证选取的损失函数不断朝向信息含量次高的变量梯度减小,即
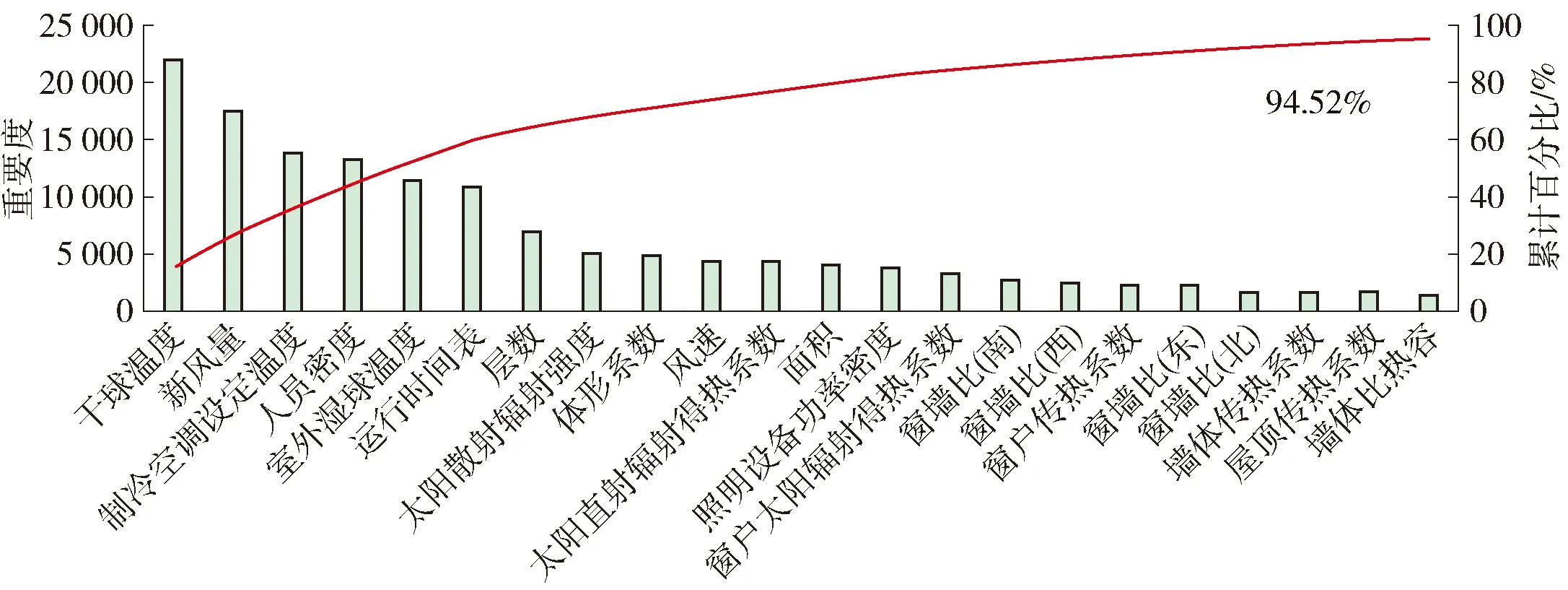
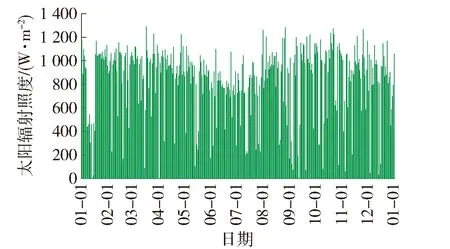
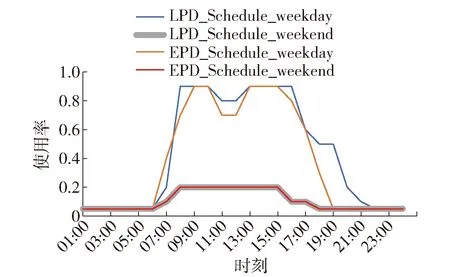
L(Fj(x),Y) (3) 式中:L(Fj(x),Y)、L(Fj-1(x),Y)分别为第j次和第j-1次迭代的损失函数值;Fj(x)、Fj-1(x)分别为第j次和第j-1次样本对应的目标值;Y为样本真实目标值. LightGBM算法主要改进在于引入直方图算法和带深度限制的按叶子生长(Leaf-wise)策略[20].直方图算法是将连续的浮点特征离散成k个离散值,并构造宽度为k的直方图,然后遍历训练数据,统计每个离散值在直方图中的累计统计量.在对特征选择时,只需根据直方图的离散值,遍历寻找最优的分割点,提高了模型的鲁棒性和计算速度.Leaf-wise是一种更高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环,使得模型在保证精度的同时具有较小的计算代价.该方法在保证与传统GBDT相同精度的同时训练速度提高了20倍以上. 1.2.2 数据集的划分方法 为避免模型在数据集训练时过拟合,降低模型的泛化性能,训练时按照制冷季和供暖季对原始数据进行均分的5折交叉验证.5折交叉验证是指将原始数据集随机等分成5份,轮流将其中1份作为测试集,其余4份数据作为训练集,如图3所示.在每次试验中计算正确率等评价指标,最终通过k次试验后取评价指标的平均值来评估该模型的泛化能力[21]. 图3 5折交叉验证的原理示意图Fig.3 Schematic diagram of 5-fold cross validation 合理地选取变量可直接提高负荷预测的准确性和实用性[22].根据1.1节的调研,从中筛选出30个影响负荷的因素,分别为面积、层数、体形系数、4个朝向的窗墙比、墙体比热容、墙角线性透过率、墙体传热系数、楼板线性透过率、玻璃线性透过率、外墙太阳辐射吸收系数、屋顶传热系数、屋顶太阳辐射吸收系数、内遮阳开启程度、窗户太阳辐射得热系数、窗户传热系数、干球温度、室外湿球温度、风速、太阳散射辐射强度、太阳直射辐射强度、新风量、人员密度、照明功率密度、设备功率密度、供热空调设定温度、制冷空调设定温度、运行时间表. 为简化模型,应用LightGBM模型对变量的重要度进行分析,进一步筛选出24个变量,用于建筑全年负荷预测.其中,供热空调设定温度和制冷空调设定温度分别影响建筑热负荷和冷负荷. 图4为冷负荷预测参数的重要度百分比累计图.可以看出,在冷负荷预测中,影响最大的3个因素为干球温度、新风量、制冷空调设定温度.筛选出的23个因素影响度累计达94.52%. 图4 影响冷负荷预测精度的参数重要度分布Fig.4 Parameter importance distribution of cooling load forecasting 图5为热负荷预测参数的重要度百分比累计图.可以看出,热负荷预测中,与夏季相同,干球温度、新风量仍是影响度占前2位的因素,排名第3的为人员密度.筛选出的23个因素累计影响度占到了91.48%.综上,得到影响负荷预测的特征变量,参考相关规范标准[23-25],得到模型输入变量和取值范围如表1所示,参数变量的取值范围即模型数据库覆盖的参数区间,在该范围内本模型适用. 图5 影响热负荷预测精度的参数重要度分布Fig.5 Parameter importance distribution of heating load forecasting 表1 建筑负荷影响因素筛选结果及取值范围 基于庞大训练数据库,选取上述影响建筑负荷的特征变量,应用LightGBM算法,构建负荷预测模型. 本研究所开发的模型针对典型系统和设备形式,照明、设备和暖通空调模型均选自EnergyPlus. 照明和设备能耗根据照明功率密度和设备功率密度与相应建筑的面积的乘积计算得到. 暖通空调系统模型包括冷水机组+锅炉、地源热泵、空气源热泵等典型模型,空调系统能耗通过1.3节构建的模型预测的建筑负荷值计算得到.空调系统的能耗加照明和设备能耗即为建筑总能耗. 根据上述原理,应用Python编译,实现能耗预测模型的建立,模型测试集的逐时平均相对误差为95%. 本研究选取常见的能耗预测评估指标平均相对误差(mean absolute percentage error,MAPE)来反映预测值与实际值之间的平均偏差[17, 26]. (4) 式中:PA和PF分别为实际能耗值和预测能耗值,kW·h;N是样本的数量. 案例建筑为办公建筑,位于北京市顺义区,建筑面积57 400 m2,共7层,制冷和制热系统形式为地源热泵机组+AHU,机组为螺杆式地源热泵机组. 根据表1筛选的24个关键因素,在模型预测时获取参数分以下3类:建筑客观数据、气象数据和运行时间表.建筑客观数据包括几何参数、围护结构热工参数、运行及使用数据,该数据通过实际建筑采集得到;气象数据中实测的建筑气象参数是通过实验室气象站获得,全年气象数据选用标准年气象数据;运行时间表根据办公建筑的使用特征划分为工作日和周末,设定运行时间表后缀为“.xlsx”的文件,计算时直接调用该文件,时间表中的具体数值根据建筑实际运行状况设定. 为验证模型预测的精度,获取了实测的建筑机组功率、全年月能耗账单和建筑总能耗指标,数据由大厦持有方提供. 2.1.1 建筑客观数据 建筑客观数据包括建筑几何参数、围护结构热工参数、运行及使用数据,具体参数如表2所示. 表2 建筑模型输入特征变量——建筑客观参数 2.1.2 气象参数 气象参数包括干球温度、湿球温度、风速、太阳散射辐射强度和太阳直射辐射强度共5项指标.建筑室外天气数据由于仅采集了北京2020年11月24日—2020年12月6日的气象参数(见图6、7),故在进行全年能耗模拟时,选用北京地区标准年的气象参数(见图8、9),实测的2020年参数用于冬季能耗验证分析. 图6 实测室外干球/湿球温度Fig.6 Measured outdoor dry-bulb/wet-bulb temperature 图7 实测太阳辐射照度Fig.7 Measured solar radiation 图8 标准年室外干球/湿球温度Fig.8 Typical annual outdoor dry-bulb/wet-bulb temperature 图9 标准年室外太阳辐射照度Fig.9 Typical annual solar radiation 2.1.3 运行时间表 根据建筑的实际使用情况,时刻表设定结果如图10所示. 图10 建筑运行时间表Fig.10 Schedules 2.2.1 实测结果验证 应用本研究建立的能耗预测模型,输入实际采集气象参数、时间表及其他特征变量,预测机组的能耗.该机组存在间歇运行情况,逐时功率波动不规律,故将模型预测的逐时值累计为逐日值,并与实际机组的运行能耗进行对比,如图11所示.可以看出预测值与真实值基本一致,机组逐日平均相对误差值为8.27%. 图11 逐日机组能耗预测值与实测值对比Fig.11 Comparison of daily predicted and measured energy 2.2.2 全年模拟结果分析 选用本研究建立的能耗预测模型和北京标准年的气象参数,其他变量不变,预测建筑全年能耗值.预测得到,建筑的总能耗指标为36.25 kW·h/(m2·a);根据物业提供的电耗账单,计算得到实际的建筑总能耗指标为35.20 kW·h/(m2·a),相对误差为2.98%. 建筑逐月模拟能耗值与实际建筑的每月能耗账单进行对比,如图12所示.计算得到建筑逐月的平均相对误差为10.37%. 图12 逐月能耗预测值与月能耗账单对比图Fig.12 Comparison of monthly simulated energy consumption and energy consumption bill 本研究结合EnergyPlus中的物理模型和LightGBM算法提出了基于庞大算例特征提取的办公建筑能耗计算方法.在实际建筑中进行应用和分析,得到如下结论: 1) 筛选出24个影响负荷的特征变量,并给出24个变量的取值范围和影响权重,模型测试集的精度为95%. 2) 在北京某办公建筑中应用效果展示,冬季机组逐日能耗预测平均相对误差为8.27%;应用标准年气象参数预测全年建筑能耗,能耗指标平均相对误差为2.98%,逐月能耗预测平均相对误差为10.37%. 3) 模型的训练数据库庞大,气象参数、运行时间表、HVAC设备形式可灵活调用,且给出了特征变量影响权重和取值范围,在建筑输入参数未知的情况下,可参考给定的取值范围.本方法摆脱了传统模拟软件物理建模和建筑历史数据的限制,使用简便、计算速度快、精度良好,具有普适性. 由于实际条件限制本研究未能对夏季工况和更多建筑进行实测验证,今后我们将继续开展研究工作.
1.3 影响负荷的特征变量提取


1.4 能耗预测模型的建立
1.5 预测模型的评价方法
2 实例分析
2.1 数据获取




2.2 模型预测结果分析


3 结论
猜你喜欢
昆钢科技(2022年2期)2022-07-08 06:36:14
当代水产(2021年10期)2022-01-12 06:20:28
小学生学习指导(高年级)(2021年4期)2021-04-29 02:17:10
建材发展导向(2021年23期)2021-03-08 01:05:38
河北理科教学研究(2020年2期)2020-09-11 06:15:48
华人时刊(2018年15期)2018-11-10 03:25:26
东北电力技术(2016年2期)2016-05-17 04:32:46
中国化肥信息(2016年35期)2016-05-17 04:25:50
数学年刊A辑(中文版)(2015年2期)2015-10-30 01:56:14
核科学与工程(2015年2期)2015-09-26 11:56:59
