
目标跟踪特征增强记忆唤醒网络
2023-03-15 03:50苏宏阳杨大伟
大连民族大学学报 2023年1期
苏宏阳,毛 琳,杨大伟
(大连民族大学 机电工程学院,辽宁 大连 116605)
当前目标跟踪主要面临目标遮挡、快速运动以及运动模糊等难题,主流目标跟踪算法分为生成式和判别式两大方向[1]。对于目标旋转问题,Deepak K. Gupta等[2]提出旋转等变孪生神经网络(Rotation Equivariant Siamese Networks,RE-SiamNets),该网络由可控制滤波器组成的等变卷积层构建。通过将跟踪目标旋转不同角度,学习不同旋转实例之间统一的特征,因此针对目标旋转问题取得了良好的效果。Qi Feng等[3]将自然语言处理和孪生跟踪器结合,提出一种新型的孪生自然语言跟踪器(Siamese Natural Language Tracker, SNLT),它将视觉跟踪的优势引入自然语言描述的跟踪任务,通过精心设计的孪生自然语言区域提议网络(Siamese Natural Language Region Proposal Network,SNL-RPN)架构,预测更精确的检测框,在速度方面略有降低的情况下,获得了良好性能。Siyuan Cheng等[4]提出一种新型的孪生关系网络,引入两个有效模块:关系检测器(Relation Detector,RD)和细化模块(Refinement Module,RM)。RD采用元学习的方式,获得从背景中过滤干扰物的能力,准确判别跟踪目标与背景;RM将RD整合到Siamese框架中,在面对背景杂波、快速运动和遮挡等场景时,具有良好的鲁棒性,获得了准确的跟踪结果。Dongyan Guo等[5]利用图注意机制将目标信息从模板特征输送到搜索特征,并且研发一种基于目标感知的区域选择机制,以适应不同对象的大小和宽高比变化,有效改善跟踪目标尺度变化问题。针对变形和遮挡问题,Bin Yan等[6]提出一种细化模块(Alpha-Refine,AR),AR采用像素相关、角点预测头和辅助掩模头作为核心组件,通过提取多尺度特征,尽可能提取和保护空间信息的细节特征,因此提高了基础跟踪器的性能。针对孪生跟踪器做了大量研究发现,孪生跟踪器将目标跟踪视为模板匹配问题,虽然取得了不错的成果,但都是针对目标旋转、尺度变化等特定问题,设计复杂的跟踪策略,通过大量数据计算以达到理想效果[7],无法适应各种目标跟踪挑战。
本文认为不同视频帧之间目标表观和状态变化的信息,反应了目标的运动趋势,而大多数基于模板匹配的跟踪器只注重利用视频中的空间信息,即使空间信息可以较好地定位目标位置信息,但忽略了时间信息对目标跟踪的重要性。因此,提出一种基于特征增强的记忆唤醒目标跟踪算法,通过对不同视频帧之间的目标信息进行有效关联,使网络自主学习目标在不同视频帧内表观信息变化的特征[8],预估下一帧目标可能出现的位置;通过特征增强,网络注重对目标局部特征的学习,使目标即使在被遮挡情况下也能预估所在位置,改善了在目标遮挡、消失或低分辨率等情况下出现跟踪漂移的问题,适用于视频监控和无人车等领域。
1 记忆唤醒网络
1.1 问题分析
以SiamFC为代表的孪生神经网络,将目标搜索过程视为模板匹配问题,定义目标模板帧为z,待搜索图像帧为x,则目标跟踪过程可转化为z与x的相似性问题,计算相似性输出w:
w=f(δ(z),δ(x)) 。
(1)
式中:函数f是采取的计算相似度方法;δ代表孪生神经网络特征提取函数;w中每个元素代表z和x的相似性得分。
孪生神经网络通过空间搜索,检测待搜索图像与模板最相近的区域,能够较好地执行目标跟踪任务。但遇到目标遮挡、消失和快速运动等场景时,目标特征并不明显,只考虑空间信息,通常无法完成目标跟踪任务[9]。跟踪失败示意图如图1。图1a显示在目标消失时,孪生神经网络无法获得目标特征,因此模板匹配失败,无法预测目标位置,造成目标跟踪失败;如图1b、图1c和图1d分别显示在待搜索图像中,背景特征与目标特征相似,在目标表观发生运动模糊、遮挡和剧烈变化时,网络模板匹配发生了错误,导致跟踪漂移。

a)目标消失 b)速度运动 c)目标遮挡 d)表观形似图1 跟踪失败示意图
本文认为,不同视频帧之间潜藏着目标表观变化的信息,目标跟踪算法通过学习目标表观信息变化的特征,对预测下一帧目标位置具有指导作用;通过对目标局部特征的学习,能够改善目标遮挡、形变等场景下,目标跟踪不准确的问题。因此,本文将不同视频帧进行关联,将时间信息引入孪生神经网络,提出记忆唤醒网络。
1.2 记忆唤醒网络
与传统孪生神经网络不同,本文通过对多个记忆帧与跟踪帧计算相似性矩阵,对跟踪帧进行特征检索,实现特征增强,使网络更好地学习目标局部特征;同时引入时间信息,使网络自主学习目标运动状态变化规律,改善目标遮挡情况下跟踪不准确的问题。记忆帧与跟踪帧的交互过程称之为“记忆唤醒”,对“记忆唤醒”操作定义如下。
定义1:所谓“记忆唤醒”,是指孪生神经网络存在输入跟踪帧x和记忆帧z,通过计算x与z相似性矩阵,对x进行特征检索,筛选出与过去某一记忆帧z相似的特征,将相似特征作为特征增强信息,对初始跟踪帧特征增加局部注意力,“记忆唤醒”的输出Yq可表示为
Yq=δ(x)+ζ(w,δ(x)) 。
(2)
式中:w是z与x计算的相似性矩阵;ζ为特征检索函数,通过δ对x和z进行特征提取,获得跟踪帧特征δ(x)和记忆帧特征δ(x),利用δ(x)和δ(x)计算相似度矩阵w,将w作为权重,对输入的跟踪帧进行特征检索,获得相似特征ζ(w,δ(x)),为方便起见,令ζ(w,δ(x))为Δδ(x),公式(2)转写为
Yq=δ(x)+Δδ(x) 。
(3)
式中,Δδ(x)作为注意力与δ(x)相加融合,这一过程即为“记忆唤醒”的数学表达。
记忆唤醒网络由三个部分组成:相似性矩阵、记忆唤醒模块、历史映射模块。相似性矩阵作为两个模块的基础,分别对记忆帧和跟踪帧进行特征检索,记忆唤醒模块利用特征检索信息,增强算法在目标遮挡、消失等场景下的鲁棒性;历史映射模块则通过特征检索信息,使算法学习目标运动变化规律,更好地预测目标位置。
1.2.1 相似度矩阵
与SiamFC不同,记忆唤醒网络模板帧的输入不是单一帧,而是在过去所有历史帧中,挑选最具代表性的n帧,包括初始视频帧、跟踪帧的前一帧以及其他具有代表性的视频帧。将多个视频帧提取特征拼接为记忆帧特征,使其具有丰富的目标信息。获得记忆帧特征后,计算跟踪帧与记忆帧的像素级相似度w,这一过程可表示为
w=fm⊗fq。
(4)
式中:fm为记忆帧特征;fq为跟踪帧特征,fm与fq相乘;w代表了fm与fq之间像素级相似度,可帮助网络准确定位目标可能存在的位置,矩阵数值越大,表明这一位置与模板帧越相似。
记忆唤醒网络结构图如图2。
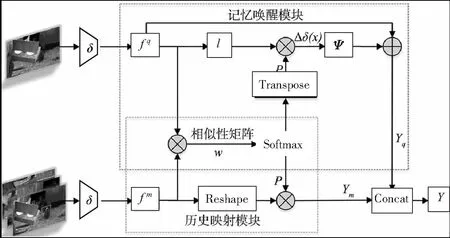
图2 记忆唤醒网络结构图
1.2.2 记忆唤醒模块
由于目标跟踪任务中存在目标遮挡等情况,跟踪帧特征提取不充分,导致模板匹配不准确,目标跟踪算法性能降低。为克服这一问题,通过局部特征增强,改善网络对跟踪目标局部特征的学习能力,提高算法在目标遮挡等场景下的鲁棒性。
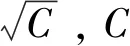
(5)
式中:THW和HW分别为相似性矩阵w的宽度和高度;wij为相似性矩阵中每个元素的索引;exp则将相似性矩阵中的每个元素指数化。
第二步,计算特征增强信息Δδ(x)。为了获得跟踪目标更高级的语义特征,对跟踪帧使用3×3卷积进行处理,随后将概率矩阵P作为权重,对处理后的跟踪帧进行目标检索,获得目标未被遮挡的局部或整体的语义特征Δδ(x)。Δδ(x)计算过程:
Δδ(x)=(P)T⊗(fq) 。
(6)
由于计算获得的特征信息Δδ(x)∈C×THW,而等待特征增强的fq∈C×HW,为使二者特征匹配,设计了矩阵压缩函数ψ,定义如下。
定义2:存在特征图M∈C×T×H×W,ψ(·)计算过程:
(7)
式中:M为4维特征矩阵,M1,M2,…,MT为M按照维度T进行切片获得的3维特征矩阵。
第三步,计算记忆唤醒的输出Yq。将多个记忆帧的特征增强信息Δδ(x)通过ψ()处理后与原始跟踪帧特征相加[10],增加目标未被遮挡部分权重,实现特征增强。Yq计算过程:
Yq=ψ(Δδ(x))+fq。
(8)
式中:ψ为矩阵压缩函数,将多个记忆帧的特征增强信息融合,再将其作为注意力作用于初始跟踪帧,增加了目标局部特征的权重,使网络着重学习目标局部特征,在目标遮挡场景下,有效改善目标跟踪不准确的问题。最终完成整个记忆唤醒操作,获得记忆唤醒特征映射Yq。
1.2.3 历史映射模块
为更准确预测下一帧目标位置,设计历史映射模块。将P视为权重,对记忆帧特征进行特征检索,确定目标的位置信息,通过检索目标在不同记忆帧间的空间位置信息和表观信息,使网络自主学习目标表观和位置变化的规律,对后续的检测、分类、边界框回归具有指导作用。历史特征映射Ym的计算过程:
Ym=fm⊗P。
(9)
将其与记忆唤醒特征映射Yq拼接作为记忆唤醒网络最终的输出:
Y=c(fm⊗P,ψ(Δδ(x))+fq) 。
(10)
式中:c表示将历史特征映射Ym和记忆唤醒特征映射Yq进行拼接;Ym代表过去目标表观信息、运动信息及状态信息;Yq为当前帧目标的特征信息。将Ym和Yq进行拼接送至后续检测头网络,后续网络通过将历史特征与当前目标特征一起学习,自主学习目标运动和状态的变化规律,利用这一特征信息,可以准确预测下一帧目标位置,联合跟踪帧记忆唤醒,可以有效改善目标遮挡、快速移动和低分辨率等情况下跟踪漂移的问题。
2 实验结果分析
2.1 性能指标
算法使用Got-10k[11]数据集进行仿真测试,Got-10k数据集共有4个评价指标,其中3个为类平衡度量指标:真值与检测框的平均重叠率(mAO)、重叠阈值为0.5的检测成功率(mSR0.5)、重叠阈值为0.75的检测成功率(mSR0.75)和算法运行速度(FPS)。以mAO为例,类平衡度量指标计算过程:
(11)
式中:C是视频的类别序号;SC是视频类别C中的图片,而|SC|是类别C中图片的数量。首先,计算类别中每个图片的真值与检测框重叠率(AOi);其次,对所有图片的AO取平均值,获得单个视频类别的mAO,对其他视频类别进行相同计算,获得每个视频序列的mAO;最后,对每个视频类别mAO相加取平均值,就得到了最终的mAO。同样的原理也适用于SR,SR重叠阈值分为0.5和0.75两种情况,分别计算mSR,重叠阈值为0.75时对检测器的要求更加严格。mAO为评价跟踪器第一指标,在Got-10k官网作为算法性能评估的第一标准。
2.2 实验设计
算法使用1张NVIADIA GeForce 1080Ti显卡,在Ubuntu16.04环境基础上,应用PyTorch深度学习框架进行训练和测试。特征提取网络采用inception v3,使用无锚检测器进行检测、分类、回归和跟踪。选用Got-10k数据集进行仿真。Got-10k视频片段超过10 000个,手动标记的边界框超过150万个,跟踪器可以在Got-10k数据集上实现稳定的训练和评估[11]。
2.2.1 实验设置
在训练阶段,记忆帧设置为3帧。在STMTrack的预训练模型基础上,每个周期仅使用3 800张图片,180组视频进行训练,整个训练过程为9个周期,批尺寸设为8。在训练开始前冻结主干网络反向传播过程,在第4个训练周期开始前解冻。
2.2.2 学习率分析
学习率的设计采用分段式学习率,为探究不同训练策略对mAO的影响,进行9组消融实验,选择3组具有代表性的学习率训练策略进行对比,结果见表1。第1列中:L代表线性学习率;C代表余弦学习率。第2列中的参数表示对应训练方式的持续周期,每组实验共进行9个周期的训练,并且每个周期训练完成后,对生成的模型进行评估,取9轮评估中最大mAO作为实验结果。
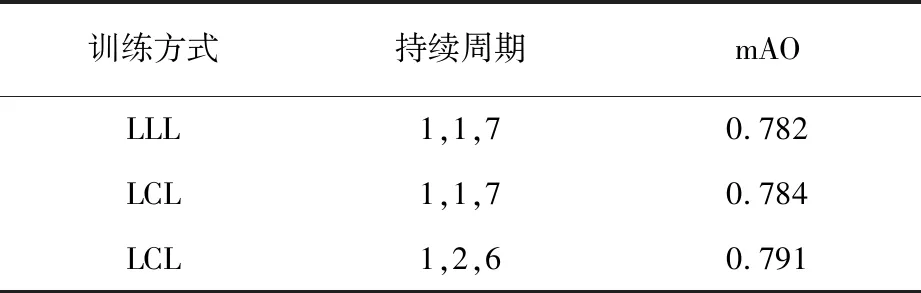
表1 不同学习率训练策略对mAO的影响
当训练方式为LLL时,在第1个周期,学习率从1×10-6线性增长至6×10-3;在第2个周期中,学习率从6×10-3线性下降至1×10-6;在后面的7个周期中,学习率保持1×10-6不变。最终在Got-10k评估集上获得了0.782的准确度。
将第2个周期的训练策略替换为余弦学习率时,学习率在第2个周期呈余弦变化从6×10-3线性下降至1×10-6,mAO增长至0.784。将余弦学习率扩大至第2、3个周期时,即学习率在第2、3个周期呈余弦变化从6×10-3线性下降至1×10-6,获得了实验中所有学习率策略中最高的mAO,在Got-10k评估集上获得了0.791的准确度。
同时,在训练开始前,冻结骨干网络的全部参数,只训练骨干网络外的参数,学习率步长由小变大再变小,整个网络获得次优的参数。经过3个周期后,解冻全部参数,统一训练整个网络,学习率采用较小的步长寻找最优的参数。精心设计的学习率政策使训练采用很少的数据,便获得了提升。Tensorboard生成的学习率变化曲线如图3。
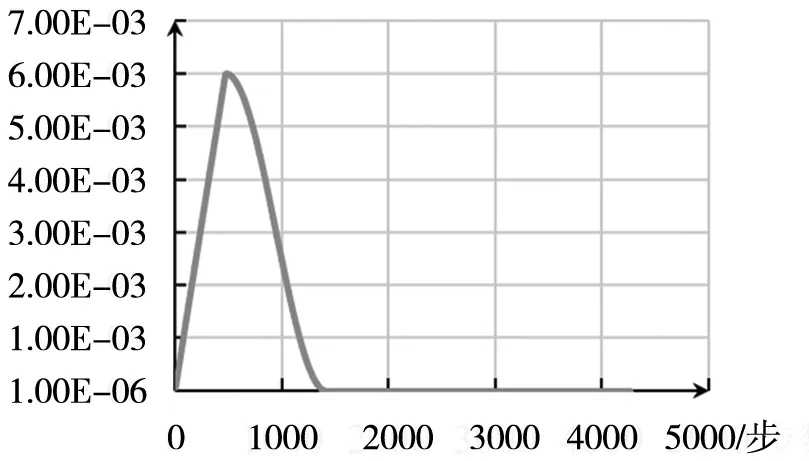
图3 学习率变化曲线
2.3 消融实验
考虑跟踪帧进行特征增强和3×3卷积处理后,会缺少背景信息以及目标细节特征,不利于预测目标位置,因此对是否引入初始的跟踪帧特征进行消融实验,网络结构对比图如图4。图4a、图4b分别为非并联和并联初始跟踪帧特征的记忆唤醒网络。
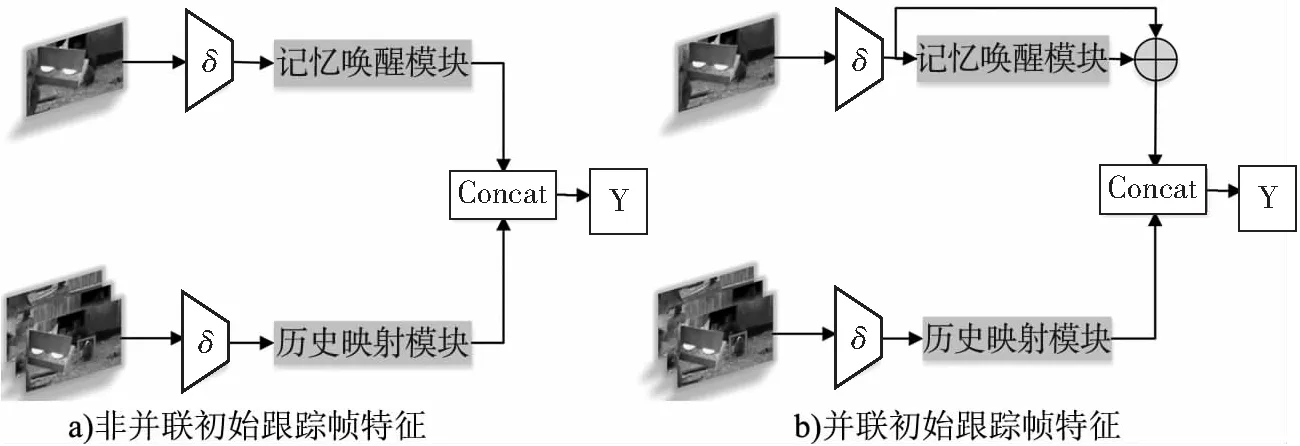
图4 网络结构对比图
对两种网络结构在Got-10k数据集进行训练与评估,获得的结果见表2。根据实验推测,特征增强后跟踪帧特征虽然使网络着重目标局部特征的学习,但是经过3×3卷积的处理,跟踪帧特征缺少目标纹理细节特征,而初始跟踪帧特征可以良好弥补这一缺陷。

表2 引入初始跟踪帧特征对网络的影响
2.4 算法对比
为直观体现算法性能的提升,选取具有代表性的两个场景对两种算法进行可视化对比如图5。图5a在目标完全遮挡场景下,基线算法STMTrack的检测框无法正确找到目标位置,出现检测框偏离;图5b中,同时存在着低分辨、目标快速移动和遮挡三种挑战,在目标没有被完全遮挡时,STMTrack没有跟丢目标,但是当跟踪目标进行快速运动时,出现运动模糊的情况,尤其是低分辨率条件下,STMTrack跟丢了目标,而记忆唤醒网络较好地克服了这个问题。

图5 记忆唤醒网络与STMTrack对比
为验证算法的提升效果,在Got-10k数据集上将记忆唤醒网络与原始网络STMTrack算法进行对比,结果见表3。将帧间信息引入目标跟踪算法,对跟踪帧进行“记忆唤醒”操作,使mAO提高1.6%,通过记忆唤醒模块的局部学习和历史映射模块的目标定位,有效提高了预测框与真值的重叠率,使mSR0.5提高2.5%,mSR0.75提高0.3%,并且没有影响算法运行速度。

表3 算法对比结果
3 结 语
本文针对目前目标跟踪算法面临的目标遮挡等挑战,提出记忆唤醒网络。通过记忆唤醒模块,改善目标遮挡等场景下出现跟踪漂移的问题;通过历史映射模块,增强网络定位目标位置的能力。与目标跟踪算法STMtrack相比,本文算法在目标受到遮挡时,可以准确定位目标所在位置,不会发生跟踪漂移等情况;在低分辨率情况下,目标进行快速
移动时,也可对目标实现准确定位,成功实现追踪。后续工作中将进一步提高算法的鲁棒性,使其在更多具有挑战性的场景下保持跟踪准确度。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
新湘评论·下半月(2016年4期)2016-05-05
新湘评论·下半月(2016年4期)2016-05-05
海外文摘(2016年4期)2016-04-15
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
