
基于RISC-V 的AES 密码加速引擎设计与验证
2023-03-15 07:32:22张晓磊戴紫彬郭朋飞
电子技术应用 2023年2期
张晓磊,戴紫彬,郭朋飞,李 杨
(信息工程大学,河南 郑州 450001)
0 引言
随着物联网技术的快速发展,智能穿戴、自动驾驶、面部识别等应用场景成为现实,极大改变了人们的生活方式。物联网设备大量使用,人体生理指标、车辆行驶轨迹等用户隐私数据[1]也随之产生。由于大量用户数据需要传输到算力更强的计算终端,传输过程中的信息安全隐患[2]逐渐浮现并引起了人们的重视。因为受限于紧张的硬件资源,很多物联网设备并未运行必要的安全机制[3]。
密码技术[4]作为保障信息安全的核心技术,可在物联网设备中进行部署,传统的部署方案主要有两种[5],一种是通过运行软件实现密码算法,这种方法利用了处理器的通用指令来支持不同的密码算法,虽然较为灵活,但该方法存在计算速度慢、代码密度低的问题;另一种是专用的密码处理芯片,专用芯片虽然运算速度快但存在灵活性低、成本高的问题。由于智能手环等物联网终端存在计算资源紧张、存储空间有限和电池容量较低等问题[6],传统的部署方案不能很好地解决上述问题。扩展专用密码指令方案的出现则克服了上述两种方案的缺点,通过向通用处理器中添加密码运算单元,使处理器在不失通用性的同时,还获取了较高的密码运算性能。RISC-V 因为其短小精悍的架构和模块化的的设计理念已成为专用领域架构的首选[7]。
在专用指令扩展领域,学术界也有很多研究成果,李爱国等人[8]提出了利用MIPS 处理器中的乘法结果寄存器实现了对64 比特数据的操作能力,同时利用处理器的空闲流水周期缩短密码运算的关键路径,从而提升了密码运算速度,但该方案对处理器运算路径的修改增加了扩展密码指令的难度和硬件的复杂性。复旦大学的Wang Weizhen 等人[9]设计了基于Rocket 处理器的四级流水密码协处理器并通过ROCC 接口扩展了密码指令。该协处理器采用同时支持128 位和256 位数据路径的统一流水线结构,支持AES、ECC 和SHA 等加密算法。但该方案所集成的Rocket 处理器是通过Chisel 语言构造的,目前该语言还未在业界得到广泛应用,对只熟悉Verilog 的芯片工程师进一步研究和开发造成了困难。
本文通过分析基于RISC-V 的蜂鸟E203 处理器NICE 扩展接口及AES 密码算法,设计了基于蜂鸟E203处理器的密码加速引擎,并进行了仿真和FPGA 验证,实验结果表明,本文提出并实现的密码加速方案获得了较好的效能。
1 AES 算法分析及方案设计
本节主要针对AES 算法轮函数运算特点,结合蜂鸟E203 处理器结构,提出密码加速引擎设计及指令扩展方案。
1.1 AES 算法
高级加密标准(AES)[10]是由比利时密码专家Daemen J 和Rijmen V 提交的Rijndael 分组密码算法经过近3 年的激烈角逐最后胜出的对称密码加密标准。该算法具有高效能、易实现和灵活性高等特点。
AES 算法运算过程在一个4 × 4(4 行4 列)的状态矩阵上进行,状态矩阵如式(1)所示:
轮函数迭代lk轮完成运算,算法的分组长度为128比特,密钥长度Nr可以根据加密强度的需要设置为128、192 或256 比特,轮数lk取决于密钥长度,两者满足关系式Nr=6 +lk/32。AES 算法加密过程如图1 所示,轮函数包括字节替代变换、行移位变换、列混合变换和圈密钥加法四个运算,其中字节替代变换和行移位变换两步运算顺序变化不会影响运算结果,最后一轮轮函数没有列混合变换。

图1 AES 加密算法
1.2 高效的密码加速实现方案
Ben Marshall 等人[11]针对不同架构处理器AES 算法加速方案进行了分析和对比,本文针对物联网场景下硬件资源紧凑的特点,在文献[11]的基础上,采用字节替代、列混合和行移位融合计算的方法实现AES-128 加速。
轮函数首先对式(2)中状态矩阵进行字节替代(S 盒替代变换用sbox 表示):
随后进行行移位,如式(3)所示:
之后进行列混合变换,它将一个状态的每一列视为有限域GF(28) 上的一个多项式且与一个固定多项式a(x)={03}x3+{01}x2+{01}x+{02}模x4+1 相乘:
最后与轮密钥key 相加:
将上述字节替代、行移位、列混合与轮密钥相加合并后可得:
针对AES-128,进一步换算后可得:
将式(7)分解为5 部分,即[sbox(a)·02 sbox(a) sbox(a) sbox(a)·03]T、[sbox(a)·03 sbox(a)·02 sbox(a) sbox(a)]T、[sbox(a) sbox(a)·03 sbox(a)·02 sbox(a)]T、[sbox(a) sbox(a) sbox(a)·03 sbox(a)·02]T和keyj。
分解之后发现,除了与密钥的异或运算外,其余四个部分的计算可以用4 条自定义指令完成运算,每条指令参与运算的系数分别为{2,1,1,3}、{3,2,1,1}、{1,3,2,1}和{1,1,3,2},通过4 条自定义指令完成一次轮函数中一个字的运算并存储于32 比特位宽的寄存器中,这样大大提高了运算效率,并且不会消耗太多的硬件资源,需要注意的是解密运算时参与有限域运算的系数不同,其系数分别为{b,d,9,e}、{d,9,e,b}、{9,e,b,d}和{e,b,9,d}。
1.3 密码指令扩展方案
RISC-V 指令集由基础指令集和扩展指令集构成,为了便于用户扩展,RISC-V 指令集设计之初便为用户提供了custom-0、custom-1、custom-2 和custom-3 四个用户自定义编码空间,蜂鸟E203 处理器识别到上述四个类型的指令编码后,就会把自定义扩展指令通过扩展接口派发给协处理器,由协处理器进行译码、执行和写回等操作。蜂鸟E203 处理器支持的扩展指令编码格式[12]如图2 所示,其中xd、xs1 和xs2 用来指示是否需要读取rd、rs1 和rs2。

图2 扩展指令编码格式
通过分析轮函数计算过程,四次计算中参与有限域乘法的系数不同,因此指令编码中包含的信息应当能够区分乘法系数的顺序;因为最后一轮轮函数仅需要完成字节替代函数和行移位运算,所以指令编码中也应当包括轮数信息以指示当前计算的轮函数是否为最后一轮。
综上所述,密码扩展指令编码空间使用custom-0,通过funct7 字段区分系数顺序和是否为最后一圈轮函数,所有指令均为R 型指令,源操作数rs1 为上一次运算结果,源操作数rs2 存储状态矩阵,目的寄存器存储本次运算结果。自定义扩展指令根据运算圈数和加解密状态分为四类,具体编码情况如表1 所示。

表1 自定义指令编码
2 基于蜂鸟E203 的AES 加速引擎设计
2.1 状态矩阵的表示与存储
AES 状态矩阵为一个4×4 的矩阵,每一个元素为一个字节,共16 字节。蜂鸟E203 处理器为RV32IMAC 架构,寄存器位宽为32 bit,因此,四个寄存器可以表示一个状态矩阵。
蜂鸟E203 处理器核的存储器子系统结构如图3 所示,通用访问指令首先通过地址产生单元(AGU)产生读和写指令的存储器访问地址,随后通过存储器访问控制模块(LSU)访问与自定义总线(ICB)相连的存储器。主处理器的LSU 为协处理器提供了专用访存通道,与通用访存指令类似,专用访存指令也是将地址信息送到LSU并通过ICB 访问存储器。两种方法不同之处是专用指令需要将主处理器分发的指令送到协处理器,协处理器需要进行译码后再进行访存操作,针对执行周期大于四个以上的指令,主处理器流水线会出现空泡。通过对访存过程对比后发现,一次读写多个数据相比一次读写一个数据而言,一条指令可以完成尽可能多的操作,但相应地增加了协处理器硬件复杂度和指令的执行周期,影响了主处理器的主频。因此,本文采用通用访存指令加载存储状态矩阵。

图3 蜂鸟E203 处理器核存储器子系统结构示意
2.2 加速引擎设计
蜂鸟E203 处理器将扩展指令通过NICE 接口派发到加速引擎,加速引擎通过对扩展指令译码获取必要的配置信息,AES 加速单元根据配置信息计算并将结果送至目的寄存器,加速引擎整体硬件结构图如图4 所示。

图4 协处理器整体结构图
蜂鸟E203 处理器的NICE 接口由请求通道、响应通道、存储器请求通道和存储器响应通道四个通道组成,主处理器通过NICE 接口向加速引擎发起调用请求。NICE 接口采用valid-ready 机制实现同步握手,完成握手后,协处理器将会获得完整的扩展指令编码、源操作数1和源操作数2 的值,当协处理器完成运算后,将会通过接口发送运算完成信号,握手时序如图5 所示。

图5 NICE 接口处理时序图
通过对扩展指令编码的func7 字段分析,运算系数顺序编码、是否为最后一轮等编码信息和原操作数共同送到配置寄存器。配置寄存器的值只有在完成译码后才会更新,AES 运算加速部件根据配置寄存器的值运算并将结果送到目的寄存器。
AES 加速部件首先根据加密工作状态判断进行S 盒或反S 盒变换,传统的S 盒查表方法[5]是通过计算索引地址来加载替换信息,该操作一般需要四条通用指令完成,而本文通过边计算边查表的方式极大地节省了指令数目,加快了运算速度。完成式(1)即字节替代操作后将得到的结果进行列混合运算,运算时将式(1)得到的字节与2、3、9、11、13 和14 相乘,根据加解密工作状态选择相应的乘数,随后依据系数顺序信息选择相应的运算结果,最后将运算的结果与密钥异或得到状态矩阵一列的运算结果,密码运算部件结构如图6 所示。
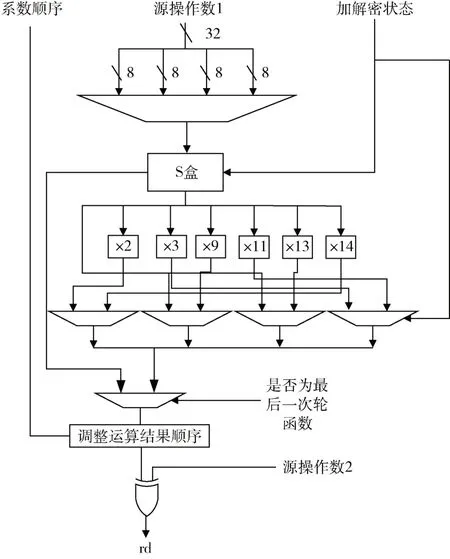
图6 AES 加速部件结构图
3 FPGA 实现及性能评估
3.1 仿真环境和FPGA 验证环境搭建
本文设计的密码加速引擎需要编写软件代码,以自定义指令的形式调用密码加速引擎完成密码运算加速。首先使用IC 前端仿真软件完成对密码扩展指令的实现和验证,通过仿真工具仿真处理器密码运算过程,完成协处理器的功能验证。最后在FPGA 平台上进行实现并对协处理器资源占用、功耗、性能等做出评估,图7 为FPGA 验证环境。

图7 FPGA 验证环境图
为AES 密码算法设计加密子密钥生成,解密子密钥生成、加密运算和解密运算四个函数,使用在C 语言中内联汇编的方式进行编程,需要按照GCC 编译器的规定将参数存储到约定的寄存器中。
如图8 所示,软硬件协同工作的流程如下:以加密运算为例,密钥固定在程序中,待加密的明文通过串口输入。按照约定的格式从存储器中加载状态矩阵,加载操作需32 条指令完成。调用自定义密码运算指令完成16轮轮函数,一轮轮函数需要调用自定义运算指令16 次,完成一次状态矩阵更新需要160 条指令完成,因此,加密一次长度为128 比特的明文需要不足200 条指令,可见采用该方法效率较高。

图8 软硬件协同工作数据流图
3.2 测试结果分析
AES 算法程序的密钥为0x0f1571c947d9e8590cb7 add6af7f6798,单分组明文输入为0x0123456789abcdeffedcba9876543210,通过仿真得到加密结果为0xff0b844a0853bf7c6934ab4364148fb9,与标准向量一致。如图9 所示,区域A 为加密密钥扩展过程波形,区域B 为加密过程波形,区域C 为解密密钥扩展过程和解密过程波形。
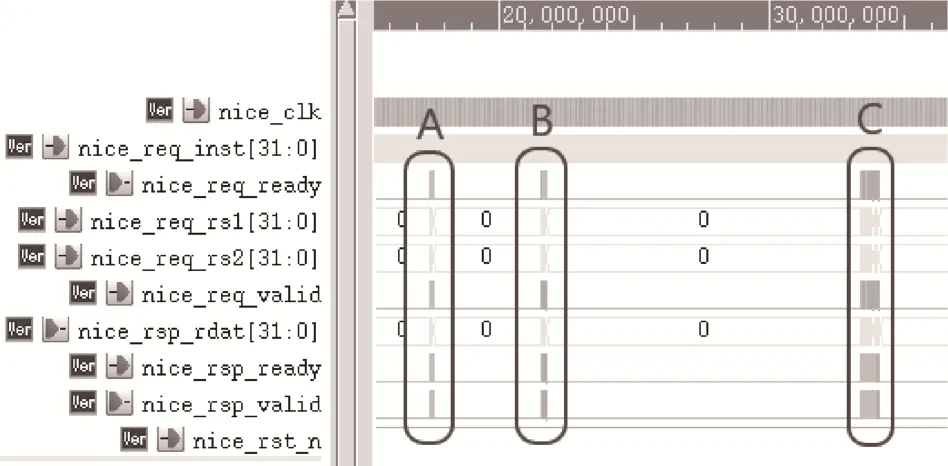
图9 加速引擎波形图
如图10 所示,通过执行4 条自定义指令计算完成了状态矩阵其中一列运算结果。

图10 完整加密过程
根据表2 所示运行结果可以看出,通过使用自定义指令,程序所需指令和周期数大幅减少。文献[7]中,同样以RISC-V 指令集为基础,通过扩展多种密码指令实现了多种密码算法。与本文AES 算法单分组明文加密性能作对比,如表3 所示,本文提出的加速方案需要更少的周期数,仍然获得了较好的加密性能。

表2 软件运行情况

表3 单分组明文加密性能
本文使用的 FPGA 验证平台为采用 Xilinx XC7A200T-2 FPGA 芯片的FPGA 开发板。对FPGA 工作频率约束在100 MHz,经Vivado 软件综合、布局布线后,内部资源利用情况如表4 所示,实验结果证明本文提出的设计方案消耗资源较少,适用于硬件资源紧张的场景。
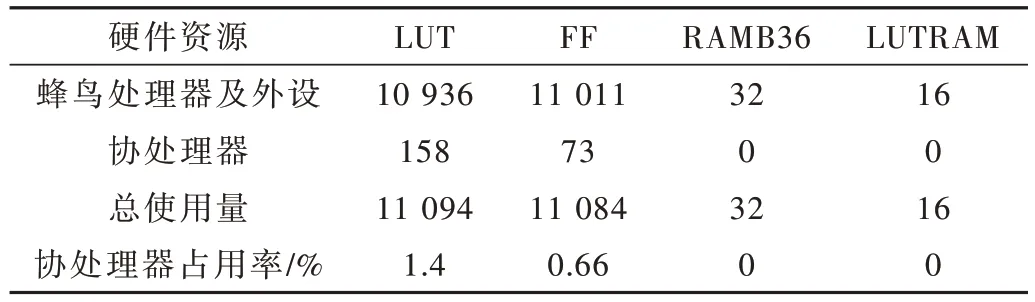
表4 FPGA 资源使用情况
4 结论
本文分析了AES 轮函数运算过程,本着节省硬件资源和提高并行性的原则,设计了基于蜂鸟E203 的AES加速引擎,运行对比了包含扩展指令的程序和不包含扩展指令的算法程序,通过对运行结果分析,本文实现的密码加速引擎取得了较好的加速效果。为了充分发挥蜂鸟处理器低功耗和可扩展的特性,下一步将进一步分析SM3 密码算法,提高杂凑运算速度,进一步完善身份认证、安全启动等功能,以构建一个较为完善的安全SoC 验证系统。
猜你喜欢
纺织科学研究(2023年9期)2023-10-23 11:17:56
科学与财富(2021年4期)2021-03-08 10:14:32
文苑(2020年4期)2020-11-22 13:45:55
北京电子科技学院学报(2020年2期)2020-11-20 01:44:06
科学与财富(2020年34期)2020-03-11 18:58:06
疯狂英语·初中天地(2019年2期)2019-07-28 07:39:44
软件导刊(2018年3期)2018-03-26 02:14:46
信息安全研究(2018年1期)2018-02-07 01:44:43
电信科学(2017年6期)2017-07-01 15:45:06
小说月刊(2014年8期)2014-11-18 20:18:37
