
机器学习预测化合物的雌雄激素受体活性
2023-03-14 07:55胡帅孔韧谢良旭
现代计算机 2023年1期
胡帅,孔韧,谢良旭
(江苏理工学院电气信息工程学院生物信息与医药研究工程研究所,常州 213001)
0 引言
许多天然或者非天然的化合物被广泛应用于人类的日常生活,如防腐剂、紫外线过滤器、增塑剂、香料、抗菌剂、杀虫剂和阻燃剂等个人护理和消费品,食品都有化合物的存在[1-2]。值得注意的是,许多化合物作为内分泌干扰物(endocrine disrupting chemicals,EDC),可过干扰人类激素的合成和作用,导致多种疾病,如生殖能力下降,癌症,甚至幼体死亡[3]。根据内分泌学会的定义,内分泌干扰化学物质是“一种外源性的非自然的化学物质,或化学物质的混合物,它能干扰激素作用的任何方面”[4]。目前国内外采取了许多方法来确定一种化合物是否具有内分泌活性。内分泌干扰者筛查计划和21世纪毒理学测试项目建立了各种体外或体内检测方法,以测量化学物质对人类或野生动物内分泌系统的潜在影响[5]。尽管细胞培养,特别是干细胞培养可以替代动物个体进行实验,从而缩短评估过程、提高实验的灵敏度,化合物毒性的实验评估仍然耗时费力[6]。使用数学模型来预测化合物的活性已经成为计算机辅助药物设计的研究热点。数据建模工具在一定的框架下对现有的实验数据进行扩展,可以减少人力物力消耗。
定量构效关系(quantitative structure-activity relationship,QSAR)被广泛应用于化合物对内分泌受体如雌雄激素受体的活性预测,如协同雌激素受体活性预测项目和雄激素受体活性协同建模项目构建就是通过不同QSAR方法训练的雌激素或雄激素受体活性预测[7]。该方法经常结合机器学习算法一起使用[8]。在综合国内外利用机器学习预测化合物的雌雄激素受体活性的基础上,本文采用支持向量机,随机森林等方法,采集来自Binding Database数据库的已知活性数据集,建立了定量结构-活性关系模型用于雌雄激素受体的活性预测,有利于实现化合物的高通量筛选。
1 材料来源
Binding Database(BindingDB)(https://www.bindingdb.org/bind/index.jsp)是一个公开访问的数据库[9],目前包含8185种蛋白质和超过920703个类药分子的2096653个活性数据。这些数据从科学文献中提取,数据收集的重点是作为药物靶点或候选药物靶点的蛋白质,其结构数据存在于蛋白质数据库中,数据的类型包括Ki、IC50、Kd、EC50等[10]。由BindingDB查询生成的数据集可以以带注释的mysql数据库的形式下载,以便进行进一步分析。研究发现,内分泌干扰物中的雌雄激素受体类似物可以跟雌雄激素受体结合,激活或抑制这些激素受体,从而干扰内分泌系统,影响人体健康[11]。BindingDB全面记录了雌雄激素受体类似物的数据情况[12]。本文所用的数据为从该数据库下载的有实验数据记录影响雌雄激素类似化合物,共计13190条数据,其中毒性评估准则以50%生长抑制浓度的对数log(IC50)单位nmol/L表示,经过去除重复数据清除IC50值相差大的错误数据后得到了8357条数据。为了进行量化分析数据,利用pandas画出了8357条数据的IC50值的大致分布,如图1所示。
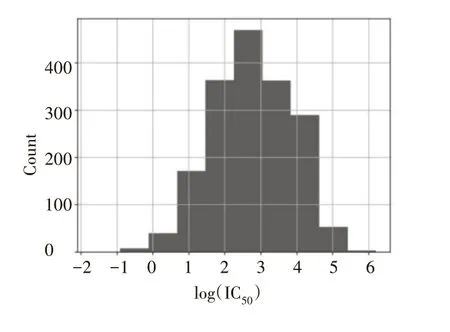
图1 数据分布
从图1可以看出数据集里的数据基本符合正态分布,所以将数据集里的数据以中位数log2.28为分界点,分为两部分。小于中位数为雌雄激素活性强的数据,或称活性数据,在模型算法中用class1表示;大于中位数为雌雄激素活性弱的数据,或称非活性数据,在模型算法中用class0表示。
2 数据处理
2.1 分子指纹
在比较两个化合物之间的相似性时遇到的最重要问题之一是任务的复杂性,这取决于分子表征的复杂性。在一定程度上的简化或抽象可以使比较分子更加容易。分子指纹就是一种抽象化表征,它的流程一般为归纳提取分子的结构特征,再用哈希(Hashing)生成比特向量。本文采用的基于子结构的分子指纹为MACCS和ECFP。
MACCS密钥通过使用RDKit进行计算[13]。ECFP指纹由Pande开发的DeepChem开源软件包进行转换。然后利用交叉验证方法[14]将数据集分为训练集和测试集,二者的比例为8∶2。
2.2 方法
2.2.1 随机森林
随机森林(random forests,RF)是一种比较典型的机器学习模型。经典的机器学习模型神经网络虽预测准确,但是计算量很大[15]。为了解决这个问题,上个世纪分类树的算法被Breiman等科学家提出。2001年Breiman把分类树组合成随机森林[16],即通过对数据集的采样生成多个不同的数据集,并在每一个数据集上训练出一颗分类树,最终结合每一颗分类树的预测结果作为随机森林的预测结果。随机森林,被誉为当前最好的分类算法之一[17]。因为本文数据比较离散,所以选择了ID3(iterative dichotomiser 3)算法。下图为使用ID3算法构建随机森林的流程。

图2 RF模型的流程图
2.2.2支持向量机
支持向量机(support vector machines,SVM)是一种构建分类器的强大方法[18]。它的目的是在两个类之间创建一个决策边界,这个边界叫做超平面[19]。这个超平面是从每个类的最近的数据点获取。SVM算法最初是由Vapnik在1963年提出的线性分类器,针对非线性数据,它还有一个用途就是核函数。在非线性问题中,可以使用核函数向原始数据添加额外的维数,使用核函数求解的过程如下:
第一步:将问题转化为原始问题及变形,用到的公式为
第二步:原始问题对偶化,首先构建拉格朗日函数:
其中,ai≥0,μi≥0。
然后原始问题对偶化并选择核函数:
第三步:利用KKT条件求解,首先利用SMO算法求解a*,然后在向量a*中选一个0<aj<C,求解b*。
最后得到分类决策算法:
3 结果与讨论
3.1 评估标准
在本研究中,采用准确性(Accuracy)、精准率(Precision)、召回率(Recall)、精度和召回率的调和平均(F1_score)、对每个类别的精准、召回和F1_score加和求平均,即宏平均(Macroavg),对宏平均的一种改进,考虑了每个类别样本数量在总样本中占比,即加权平均(Weightedavg)这六种统计指标来评估所提模型的性能,计算公式如下:
对公式中出现的英文简写解释如下:
TP(True Positive):做出Positive的判定,而且判定是正确的,即检测为雌雄激素活性强且雌雄激素活性强的物质;FP(False Positive):做出Positive的判定,但判定是错误的,即检测为雌雄激素活性强但实际雌雄激素活性弱的物质;TN(True Negative):正确的Negative判定,而且判定是正确的,即检测为雌雄激素活性弱且雌雄激素活性弱的物质;FN(False Negative):错误的Negative判定,而且判定是错误的,即检测为雌雄激素活性弱但雌雄激素活性强的物质;雌雄激素活性弱的精准率用Pno来表示,雌雄激素活性强的精准率用Pyes表示;Support代表支持样本数,雌雄激素活性弱样本数用Supportno表示,雌雄激素活性强的样本数用Supportyes表示。
此外还应用了受试者工作特征曲线(receiver operating characteristic,ROC)和曲线下面积(area under curve,AUC)来评价模型的分类性能:ROC曲线的Y轴为真阳性率(true positive rate),X轴为假阳性率(false positive rate);AUC的值越大表明模型的预测结果越好[20]。
3.2 预测结果和分析
本文采用了二组分类模型RF和SVM,分别结合两种分子指纹做预测,在使用Sklearn.metric.classification_report工具对模型的测试结果进行评价时,整理输出结果,如表1~表4(图3)所示。

图3 集受试者工作特征(receiver operating characteristic,ROC)曲线
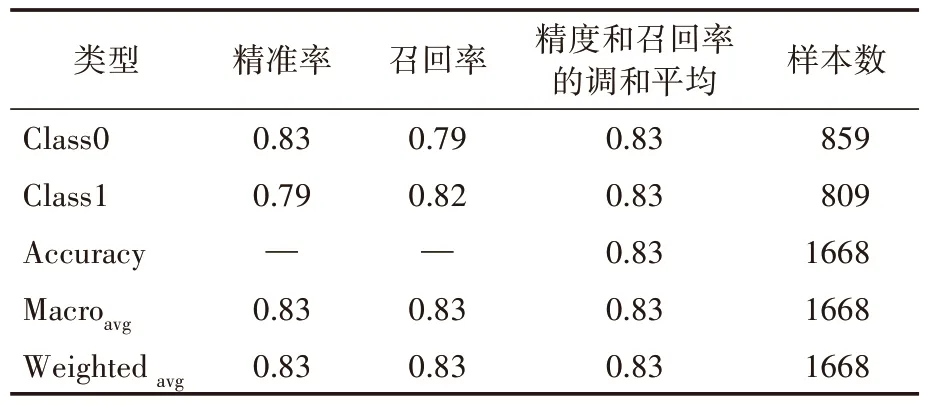
表1 随机森林(RF)结合ECFP指纹

表2 随机森林(RF)结合MACCS指纹

表4 支持向量机(SVM)结合MACCS指纹
从表1~表4可以看出,RF,SVM算法结合ECFP指纹模型准确率和AUC值要分别高于RF,SVM结合MACCS,主要是因为ECFP可用来表示功能基团是否存在,对于分析分子活性至关重要。RF的结果要好于其他结果,从直观现象来解释,主要是因为RF的每棵决策树都相当于一个分类器,对于输入的每一个样本来说,M个分类器就有M个分类结果。RF集成了所有结果,最终把类别中的结果做为输出成果,RF是一种最容易达到好的分类结果的算法。RF结合ECFP指纹在对化合物的雌雄激素活性的预测上可以达到0.83的准确率,AUC值可以达到0.896,且ROC曲线光滑,说明数据样本空间分布合理,模型预测结果优良。其次,SVM结合ECFP结果稍逊于RF,从侧面证明了SVM适用于样本空间小的数据。SVM结合ECFP,由于样本小,ROC曲线略有凹凸。在对化合物的雌雄激素活性的预测上可以达到0.83的准确率,AUC值可以达到0.882,证明模型的预测能力良好且广泛。
4 结语
本文对8357条雌雄激素受体毒性值有影响的小分子化合物进行分子指纹的转换,选择学习方法建模并进行了毒性的预测评估,RF模型结合ECFP指纹明显优于参比模型。本文构建的雌雄激素受体预测模型,因纯粹选用理论计算参数而不依赖实验测定,故较方便、省时且节约费用,可对环境分布的化合物进行快速的激素受体干扰能力判断,为环境内分泌干扰分子的风险管理提供基础。
本文所使用的数据和源码可访问https://gitee.com/code-mk/classification获取。
猜你喜欢
今日畜牧兽医(2022年10期)2022-12-23
保健医苑(2022年4期)2022-05-05
猪业科学(2022年2期)2022-04-21
山西林业(2021年2期)2021-07-21
小哥白尼(趣味科学)(2021年11期)2021-02-28
中国生殖健康(2020年2期)2021-01-18
小天使·一年级语数英综合(2020年10期)2020-12-16
中国生殖健康(2019年8期)2019-01-07
自动化学报(2016年8期)2016-04-16
Coco薇(2015年12期)2015-12-10
