
基于贪婪算法的网络数据分级储存方法
2023-03-13 15:26熊国栋
信息记录材料 2023年1期
熊国栋
(荆楚理工学院计算机工程学院 湖北 荆门 448000)
0 引言
在网络数据集成化的背景下,数据量增长的规模日益壮大,因此对应的数据分级储存方法也面临着更多挑战[1]。异端服务器存储的模式,会对网络数据管理的权限造成影响[2]。分级储存方式则能够更好地实现负载均衡,实现网络数据资源调度。在传统的存储模式中对单机服务器的容量性能要求较高,一旦出现站点失效等故障则整个平台的集群存储模式也将遭到破坏。此外,利用外接扩容的方式无法满足网络数据的分级储存需求。
袁志琴等[3]通过欧式距离对数据进行空间划分,利用空间数据区域生长的方法解决数据密度聚类问题,采用规则对簇进行合并,实现数据的分级聚类。黄永生[4]采用模糊综合评价法评价数据价值,根据价值评估结果,通过固定阈值法和高低水位法实现数据分级与储存。但上述方法在进行网络数据分级存储的过程中,是分别将数据分配到网络节点中的,增加了网络数据检索的延迟时间,导致时间开销性能较差。
因此,为解决上述方法存在的不足,本文将贪婪算法应用到网络数据分级储存方法中,对此展开相关研究。
1 构建网络数据包捕获模型
当网络数据途经对应的计算机设备时,可先在网络端口中判断网络数据的应用价值[5]。再通过额外配置旁路端口的方式,将数据包进行过滤处理,并按照分级储存规则,同时匹配安全数据。为了避免数据包丢失,结合贪婪算法,实现网络数据由内核态至用户态的转变。在数据分级储存的过程中,零拷贝技术也能在一定程度上提高数据包的处理能力。同时,可以选择直接从存储器等设备中捕获网络数据包,并开设切换缓存区的通道,在途经缓冲区后自行将数据发送到存储空间[6]。在此基础上,数据包捕获间隔的表达式为
式(1)中:ϖ为数据包间隔大小;r为网络编码块要素的空间分布面积;δ为网络数据集合。当出现创建新资源需求时,可以通过数据读写的方式创建原始数据的副本,并在多个端口之间进行数据共享[7]。对于规模较大的数据包,则可以选择二次分割。出于捕获数据包的目的将存储操作的分类,编写步骤推迟到最后归类的环节。为了减少分级储存对网络资源的消耗,需要保证数据本身的应用态和内核态不遭受破坏。因此要想实现物理层与应用层之间的跨级储存,应处理好数据帧与网络节点之间的关系。在应用层中创建一个虚拟空间,并通过直接关联的方式,以传输协议作为通信介质,将网络数据包的特征,映射到虚拟空间中[8]。
2 基于贪婪算法优化缓存替换流程
贪婪算法主要是通过动态规划的方式进行求解,但最终得出的结果有可能是最优选择的近似解。在实际的应用场景中,贪婪算法往往能够依据当时的实际情况,得出解决当下问题的最佳结果。将贪婪算法应用在此次网络数据分级储存方法的设计中,主要是希望能够得出优化缓存替换流程的最优解[9]。缓存替换步骤,通常出现在数据包传输的流量低峰时段,而对于缓存替换的标准,基本都是网络数据的储存容量接近饱和的状态。针对不必要替换的网络数据,则可以略过缓存放置环节,直接进行数据内容交付。网络数据存在缓存替换需求的具体体现,主要是现有网络数据存在数据缺失或者生命周期达到阈值等情况。在有限的储存容量条件下,选取合适的缓存替换位置是十分重要的。在分级储存的场景中,不仅要考虑储存空间的容量,还要满足网络数据对节点分配属性的要求。由于网络数据通常包含相应的内容流行度,该指标能够直接地体现出网络数据源需要分级储存的概率。网络数据包的流行度计算公式为
式(2)中:H为网络数据包缓存替换请求次数;η为网络数据包;L为替换请求的总次数。假设式(2)的计算服从齐夫定律分布条件,可将式(2)修改为
式(3)中:T为网络数据包被用户(ε)请求访问的概率;μ为网络数据包流行度的偏斜率;σ为缓存替换速率。而作为数据统计的关键环节,内容流行度也集中体现了网络数据的实际价值。面对活跃度较高的动态缓存替换请求,需要额外掌握网络数据包的衰弱路径及时变特性。在不同的缓存位置条件下,还要结合数据包的捕获速率,及时优化更新缓存替换流程。基于上描述,完成利用贪婪算法优化缓存替换流程的步骤。
3 设计数据分级储存模式
网络数据分级储存,主要就是指在2个及以上的服务器节点中进行分级储存。同时,为了最大限度地降低总服务器的调度负担,根据贪婪算法的作用原理,将网络数据包分割成若干个数据集并分别进行求解。由于分级储存的基本原理与分布式存储具有一定的相似性,因此,在设计过程中,需要单独提取网络数据的标准序列。尽管网络数据的分级储存位置,不需要与全部的本地节点相关联,但为了保证数据的完整性,还应采用网络连接的方式设置网络数据的读取通道。同时,出于对储存空间的负载均衡性能考虑,如果有数据删除或属性修改的需要,就要不断提升储存策略的集群化程度。以最小化分级储存延时为目的,针对不同规模的网络数据,分别设立具有独立性能的储存策略。在网络数据的分级储存方法中,部分储存设备具有相似的运行代码,因此,能够小范围地实现网络数据共享。但在相似数据源提取的过程中,一旦网络节点出现了数据信息交换的现象,就会在无形中增加信令开销。即便是最终得出了其他层级网络数据储存状态,也无法以标准形式呈现给其他节点。在这种情况下就要根据贪婪算法的最优子结构特性,去判断网络数据的贪心选择特性。将网络数据的分级储存看作是待解决地输入问题,并假设在实际储存场景中,储存设备的容量无法满足需求,则得出解决该问题的时间:
式(4)中:k为贪婪算法中的任意常数;β为节点数量;g为分级储存空间容量集合。将式(4)看作是一个ILP(information leak prevention,信息泄露防护)问题,得出贪婪算法动态规划路径:
式(5)中:d为网络数据的大小;e为储存设备的背包容量。通常情况下,网络数据的储存节点所在位置,主要是依据相邻节点的空间信息决定。在此过程中,网络数据的分级储存端口,向距离最近的服务器发出连接请求。基于此,完成设计数据分级储存模式的步骤。
4 实验分析
4.1 搭建实验环境
由于本文设计的网络数据分级储存方法涉及服务器和数据分层存储平台,因此对实验环境配置要求较高。根据实验需求,搭建实验环境:3台内存为16 G及以上的服务器,硬盘容量不得低于1 TB。CPU选择INTEL Xeon、操作系统为Ubuntu,配备DPDK-stable和Hadoop 2.7.2及以上版本。在实验开始之前,要首先保证文中的网络数据分级储存方法能够检测到完整的数据存储协议,且错误率小于1%。
4.2 实验结果
为了能够得出此次设计网络数据分级储存方法的开销性能,分别选取面向变尺度密度数据的分级聚类算法与基于大数据分析的负载平衡数据分级存储方法作为对比方法,与文中的网络数据分级储存方法进行对比测试。由于网络中数量是从16~8 192不等,出于均衡角度考虑,将实验条件中的数据块数量设置为1 024,以生成Merkle树延迟开销时间、数据完整性认证开销时间与网络数据检索延迟开销实践作为测试指标,对比3种网络数据分级储存方法的时间开销性能。生成Merkle树延迟开销时间见表1,数据完整性认证开销时间见表2,网络数据检索延迟开销时间见表3。

表1 生成Merkle树延迟开销时间 单位:ms
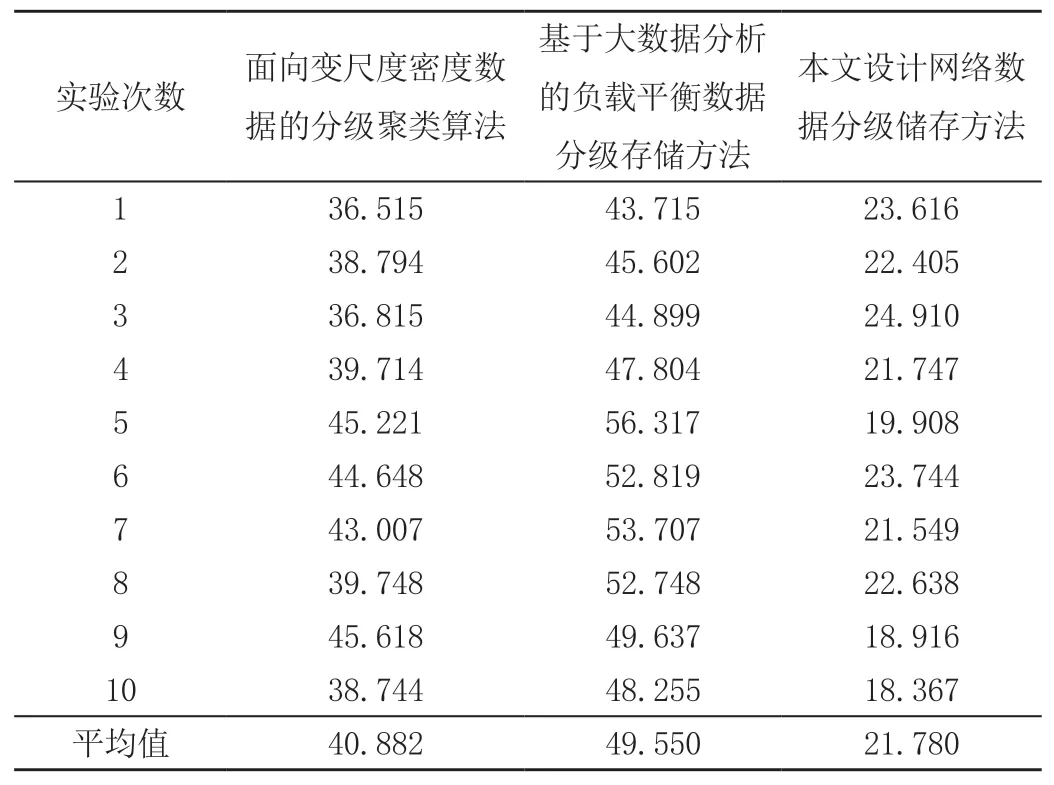
表2 数据完整性认证开销时间 单位:ms
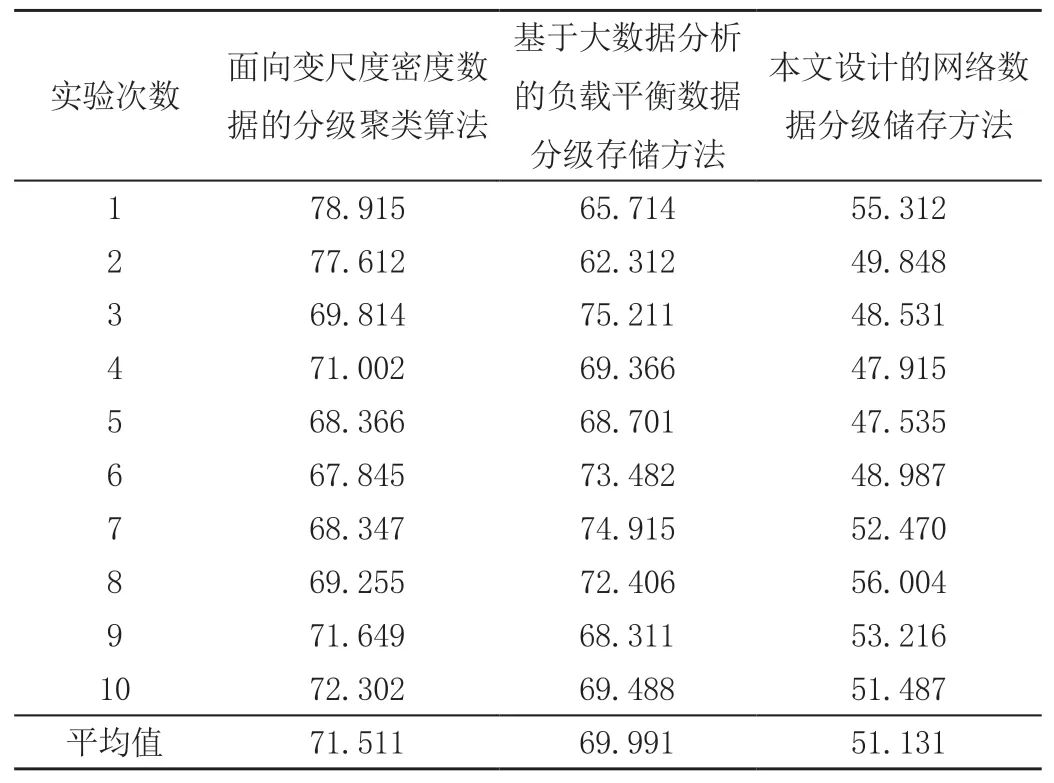
表3 网络数据检索延迟开销时间 单位:ms
由表1可知,在数据块数量为1 024时,本文设计的网络数据分级储存方法,以及另外2种方法生成Merkle树的平均延迟时间分别为:616.268、899.378、899.030 ms。由此看出,本文设计方法的延迟开销时间最短。这是由于本文设计方法在生成Merkle树开销方面,将Merkle树中包含的叶子节点看作是数据碎片,可以根据实验数据,推测出网络数据与缓存命中率之间的关系。
由表2可知,本文设计的网络数据分级储存方法,以及另外2种方法的数据完整性认证平均时间分别为:21.780、40.882、49.550 ms。由此看出,本文设计方法的数据完整性认证开销时间最短,基于大数据分析的负载平衡数据分级存储方法次之,面向变尺度密度数据的分级聚类算法最差。说明在验证数据完整性层面,设计的网络数据分级储存方法性能最佳。
由表3可知,本文设计的网络数据分级储存方法,以及另外2种方法的网络数据检索平均延迟时间分别为:51.131、71.511、69.991 ms。说明本文设计方法的网络数据检索延迟开销时间最短,数据分级储存效果较好。
5 结语
综上所述,面对大量网络数据在分级储存时存在时间开销过大的问题,本文以贪婪算法为技术基础,构建网络数据包捕获模型,优化缓存替换流程,设计新的数据分级储存模式,完成基于贪婪算法的网络数据分级储存方法的设计。并通过实验验证了设计方法的延迟开销时间较短,数据完整性认证开销时间较短,网络数据检索延迟开销时间较短,能够解决网络数据分级储存过程中时间开销过大的问题,数据分级储存效果较好,具有较好的实际应用性能。本文方法的设计拓宽了贪婪算法的应用场景,同时也丰富了数据处理领域的研究成果。未来将把更多的精力放在数据处理权限方面,争取在专业方向取得更高的成就。
猜你喜欢
中国交通信息化(2022年4期)2022-06-17
电脑与电信(2021年9期)2021-12-21
今日农业(2020年24期)2020-12-15
网络安全和信息化(2018年4期)2018-11-09
中国公共安全(2017年5期)2017-09-04
装备学院学报(2017年3期)2017-07-21
装备学院学报(2017年2期)2017-06-05
装备学院学报(2017年1期)2017-03-25
中国现代医学杂志(2015年26期)2015-12-23
电子设计工程(2011年24期)2011-06-09
