
基于关联规则的终端软件缺陷检测方法研究
2023-03-10 01:40:56吕华辉刘欣农彩勤
电子设计工程 2023年5期
吕华辉,刘欣,农彩勤
(1.中国南方电网有限责任公司,广东广州 510000;2.南方电网数字电网研究院有限公司,广东广州 510663)
随着互联网技术的快速发展,软件的应用范围迅速扩大。为了保证终端软件在使用过程中的安全性与稳定性,需要对终端软件缺陷进行检测。传统的软件缺陷检测方法主要应用了静态分析技术,通过这种检测技术可实现对软件代码的分析与评估,同时不需要执行运行程序,能够及时发现终端软件中存在的缺陷,但随着软件应用环境的日渐复杂与软件数量的激增,传统的软件缺陷检测方法在对终端软件的缺陷进行检测时,出现了漏报与误报情况[1-2]。
为此,国内专家学者对此展开相关研究。文献[3]提出基于N-gram 模型的终端软件缺陷检测方法,该方法建立了终端软件缺陷N-gram 模型,通过该模型提取终端软件的缺陷数据,将终端软件缺陷数据存储到数据库中,然后对模型进行优化,最后通过优化后的终端软件缺陷N-gram 模型实现了终端软件缺陷的检测,该方法容易实现,并且检测误报率较低,但检测漏报率较高。
为了解决以上问题,该文提出了基于关联规则的终端软件缺陷检测方法。
1 终端软件缺陷特征提取
在终端软件中,二进制软件的尾指令较为复杂,无法直接进行分析,需要对二进制软件赋予中间指令集,并增加代码量,从二进制软件的路径与汇编指令入手,提取软件缺陷特征[4]。
二进制软件基本块执行顺序根据软件底层指令确定,软件底层指令位于尾指令前面,由多个汇编指令构成,基本块在执行第一行代码时,不需要执行二进制程序,此时,基本块可表示为返回指令集合设置为a={b1,b2,…,bm},m为基本块a的地址长度,b1表示基本块a的跳转指令,bm表示基本块a的汇编指令。
二进制软件的第一行代码程序可表示为若干基本块的集合A={a1,a2,…,ai},i表示基本块的控制信息[5-6]。
为了提取终端软件特征信息,需要根据尾指令中的自定义函数将基本块分为条件跳转基本块与返回基本块,条件跳转基本块中的语句可通过jmp、je进行判断,如果归为同一类别,则条件跳转基本块的代码显示为true,如果条件条状基本块中含有库函数与自定义函数,不归为同一类别,则代码程序显示为false。
在划分完成后,自定义基本库中包含缺陷,需要提取自定义基本库中的缺陷特征信息进行分析。基本块通过自定义返回指令可由基本块an返回到基本块aj,基本块an与基本块aj之间的缺陷路径可由rn,j={an,aj,c|j∈An} 表示,其中,an为缺陷路径中点,aj表示缺陷路径终点,c表示缺陷路径变量,An表示基本块an的特征集合[7-8]。
在终端软件中如果多次进行循环与基本块判断,会导致终端软件的缺陷路径以指数形式增加,从而造成缺陷路径爆炸,为降低缺陷路径的增加速度,在提取缺陷路径特征时,只提取终端软件中相邻基本块的缺陷路径,并以自定义调用方式记录软件程序的判断与基本块循环。为了使缺陷路径迭代过程更优,采用广度优先的方式使缺陷路径循环。缺陷路径特征提取过程如下。
首先,在二进制程序中将汇编指令集转换为跳转指令集,并将底层指令集进行返回操作,在返回过程中将其划分为多个不同的基本块,并根据基本块第一行代码的数量将其由高到低进行排序,标记为A={a1,a2,…,ai} 。通过反汇编技术[9-10]将基本块作为节点,基本块之间的返回作为特征变量,构建控制流图G={rn,j,A,Begin,Exit|n,j<A|},G表示二进制程序中代码的控制流信息。
然后,提取二进制程序中代码特征,将第一行代码中的底层指令转换为条件跳转指令,并提取特征变量。通过基本块中的缺陷路径提取路径复杂度,根据出入度的频率对基本块进行调用,挖掘自定义基本库函数的基本块数据,对数据进行静态分析,提取自定义基本库中的基本块出入度[11]。
最后,采用广度优先方法对缺陷路径进行遍历,根据基本块的复杂度与出入度特征提取缺陷路径特征,缺陷路径特征包括代码程序的汇编指令特征与底层指令特征,可以表示为:
其中,t表示基本块的缺陷路径特征维度。
2 基于关联规则的缺陷检测
根据以上缺陷特征提取结果,采用关联规则方法检测终端软件的缺陷。在检测过程中需要申请终端软件的匹配权限,并将基本块中的频繁项进行检测,权限匹配程度与基本块数量的比值能够体现终端软件缺陷的支持度,采用关联规则算法计算终端软件中基本块的缺陷度,计算公式为:
其中,L表示终端软件基本块的缺陷度;d表示终端软件中基本块的数量;Nd表示基本块与二进制程序代码的关联度;Td表示终端软件中基本块经过跳转指令与相邻基本块的缺陷路径[12]。
根据计算的基本块缺陷度判断终端软件在缺陷检测过程中是否存在缺陷家族,如果存在缺陷家族,需要计算软件缺陷检测的误报率,选取检测误报阈值p,将终端软件识别的基本块数量进行统计,并通过路径频繁项检测基本块的指令地址,采用关联规则算法计算终端软件缺陷检测误报率wFalsealarmrate为:
其中,M表示终端软件被二进制程序正确识别的数量;δ表示关联规则算法中的支持系数;K表示终端软件中被识别出来的缺陷家族。
根据数据计算结果以及提取出软件缺陷特征信息,采用关联规则算法对终端软件缺陷进行检测的流程如图1 所示。
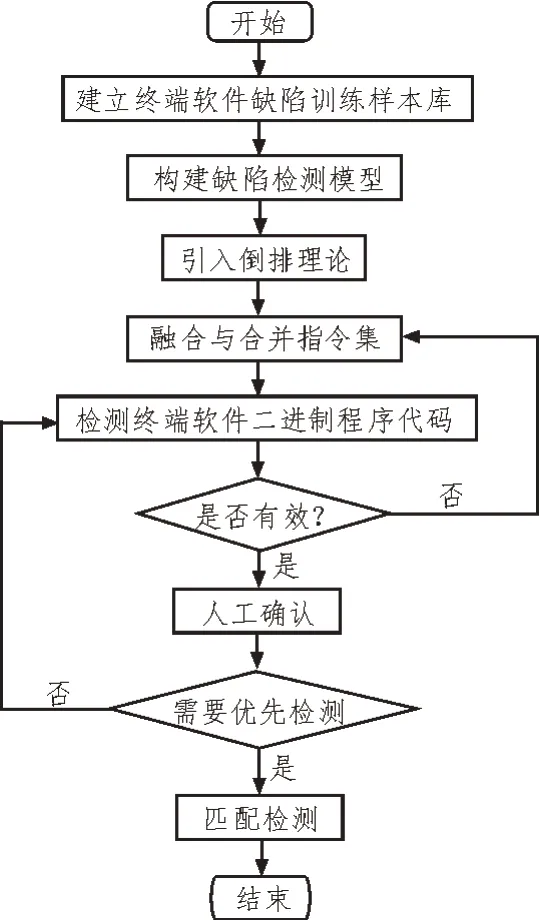
图1 终端软件缺陷检测流程
首先,建立终端软件缺陷训练样本库,样本库中包含若干个软件缺陷家族,缺陷家族中包含大量终端软件缺陷特征数据。采用静态检测方法对缺陷家族中缺陷特征数据反编译,获得终端软件中的缺陷文件,并从该文件中获得终端软件的缺陷申请列表[13-14]。
然后,采用关联规则方法构建缺陷检测模型。在关联规则方法中引入倒排理论,可以提升终端软件缺陷检测的速度,迅速生成缺陷路径中的频繁项,通过关联规则方法融合汇编指令集与底层指令集,根据软件缺陷支持度挖掘候选项集的缺陷数据集,采用静态检测工具为检测出的缺陷数据集提供缺陷可能值,以便识别出终端软件中非缺陷项,降低终端软件缺陷检测的误报率与漏报率。通过检测出的缺陷数据集建立缺陷检测模型图,如图2 所示。

图2 缺陷检测模型
通过该模型对终端软件二进制程序代码进行检测,输出检测结果,并利用一级处理程序输出Tool-i结果并生成优化结果,在优化过程中,根据二级处理程序标识出终端软件缺陷项,分析并查找软件缺陷项的描述项,作为误报规则,根据输出结果将缺陷重复项与重报项进行人工确认,并给予不同的确认级别,当可信度级别为1 时,表示标识出来的重复缺陷项的优先级别较高,此时需要对重复缺陷项进行优化检测。
最后,进行匹配检测。与模型中重复缺陷项与描述项进行匹配,如果匹配的程度大于检测的程度,则终端软件缺陷项被成功检测出来,此时输出检测结果[15-16]。
3 实验分析
为验证该文提出的基于关联规则的终端软件缺陷检测方法的有效性,选用该文提出的方法与传统的基于N-gram 模型的终端软件缺陷检测方法和基于数据挖掘的终端软件缺陷检测方法进行实验。设置实验参数如表1 所示。

表1 实验参数
根据上述参数,选用该文提出的检测方法和传统方法进行检测,为了确保实验结果的权威性,分别对已知缺陷软件和未知缺陷软件进行检测,分析缺陷终端检测结果的命中率,非缺陷终端软件的误报率。命中率计算公式为:
其中,wHitrate为检测的命中率,T表示缺陷软件被准确识别的数目,F表示存在缺陷的终端软件被错误识别成非缺陷软件的数量。命中率实验结果如图3 所示。

图3 命中率实验结果
根据图3 可知,随着检测样本数量的增加,检测命中率呈现下降趋势,这种趋势在检测软件未知缺陷上尤为明显。对于软件已知缺陷,数据挖掘检测方法的检测命中率最高,当检测样本数量为70 个时,命中率仍然在80%以上,该文提出的检测方法检测命中率为70%,而基于N-gram 检测方法的检测命中率则降低到40%。对于软件未知缺陷,该文提出的检测方法检测命中率要远远高于传统检测方法,当检测数量为70 个时,该文检测方法命中率高达90%,基于N-gram 检测方法的检测命中率则降低到40%,数据挖掘检测方法的检测命中率降低到15%。
根据式(3)计算缺陷检测的误报率,得到的误报率实验结果如图4 所示。
根据图4 可知,对于软件未知缺陷,三种方法的误报率均比软件已知缺陷的误报率要高,但是传统误报率最高,已经超过用户要求,而该文提出的检测方法误报率始终低于5%,验证了该文提出的检测方法实用性更强,更适合应用于实际工作中。

图4 误报率实验结果
4 结束语
随着软件数量的增加及应用环境的复杂,软件缺陷逐渐暴露。为满足终端软件缺陷检测的需求,并解决传统软件缺陷检测方法出现的问题,提出基于关联规则的终端软件缺陷检测方法,实现对终端软件的缺陷检测,该文检测方法可有效检测出终端软件的缺陷,使终端软件的运行更稳定。
猜你喜欢
电子产品世界(2023年10期)2023-12-21 11:59:21
计算技术与自动化(2023年3期)2023-10-16 19:12:26
小型微型计算机系统(2022年5期)2022-05-10 08:45:42
煤气与热力(2021年6期)2021-07-28 07:21:40
计算机工程(2021年3期)2021-03-18 08:03:34
计算机与现代化(2020年8期)2020-08-17 13:59:50
黑龙江工业学院学报(综合版)(2020年6期)2020-08-11 07:16:08
成都信息工程大学学报(2018年3期)2018-08-29 01:08:44
电子元器件与信息技术(2017年4期)2017-03-08 02:15:59
现代电子技术(2015年21期)2015-11-09 21:46:26
