
基于改进SSD算法的胃部息肉图像检测
2023-03-09 07:05:12范明凯肖满生胡一凡吴宇杰
软件工程 2023年3期
范明凯,肖满生,胡一凡,吴宇杰
(湖南工业大学计算机学院,湖南 株洲 412007)
gangxinjiaoyongg@163.com;349407041@qq.com;373502340@qq.com;2275128586@qq.com
1 引言(Introduction)
胃癌是最常见的消化道肿瘤之一,是一种严重威胁人的生命健康的重大疾病。胃中的大多数息肉具有恶性潜能,并且具有与胃癌相同的一些危险因素和机理,因此可能发生癌变[1-2]。胃息肉如果能在早期发现和治疗,对预防胃癌至关重要。然而由于胃结构复杂,息肉影像数据量大,小目标息肉不易识别,仅通过医生判别可疑病变息肉,效率低下,而且精准度不高[3-4]。人工智能系统可以自动勾画病灶,提高影像医生的诊断效率。作为人工智能发展的一个方向,深度学习(Deep Learning,DL)为自动病变检测的医学图像分析提供了新的思路[5]。DL模型对胃肠病学的主要贡献之一是其快速、可靠的息肉检测能力,提高了诊断质量[6]。
近年来,智能化图像识别技术在医疗诊断领域得到了极大发展,如DL方法在胃息肉检测中的应用。HIRASAWA等[7]利用13,584 张内窥镜图像数据集,通过训练One-Stage的目标检测模型[8](SSD)检测胃内镜照片癌变区域,同时用一套独立的测试图像集进行测试,共包括连续69 例患者的2,296 张胃部内窥镜图像,检测结果中含有77 个胃癌病灶,最终正确诊断为71 个,整体敏感性为92.2%,但没有改变SSD的任何细节。WANG等[9]使用改进的Faster RCNN[10]算法(Faster Region-based Convolutional Neural Network)检测息肉,在Faster RCNN中用ROI(Region Of Interest)对齐操作代替ROI池操作,用GIoU(Generalized Intersection Over Union)损失代替原有平滑L1损失,用Soft-NMS(Soft Non-Maximum Suppression)代替传统的NMS,在胃息肉图像检测中取得了良好的效果,但网络较为复杂;ZHANG等[11]提出了一种基于增强的SSD架构(SSD-gpnet)用于息肉检测的卷积神经网络方法(Convolutional Neural Network,CNN),共收集了215 名胃息肉患者的404 张内窥镜图像。经过增强处理后,随机选取708 幅图像和50 幅图像分别进行训练和测试步骤,该研究的平均精度(mAP)为90.4%;LADDHA等[12]提出了检测胃息肉的YOLOv3模型,数据集的来源为文献[10]采用的数据集,测试结果mAP为82%;XIA等[13]开发出基于Faster-RCNN的胃病变自动检测系统,用于检测糜烂、息肉、溃疡、黏膜下肿瘤、黄瘤、正常黏膜和无效图像。系统接收器工作特性(ROC)分析给出了84%的结果,使用787 名患者的1,023,955 张内窥镜图像数据集,得到准确率、召回率和调和平均指标(F1-Score)分别为78.96%、76.07%和77.49%,但准确率不够高。CAO等[14]使用1,941 张图像组成的私人数据集,使用YOLOv3进行胃息肉检测,该方法的计算准确率为91.6%,召回率为86.2%,F1-Score为88.8%。
以上方法各有优势,但都存在不足,特别是精确度可以继续提升。检测中的主干网络CNN模型在训练过程中,数据集过小、含有大量噪声等,或者模型过于复杂、训练参数过多、训练过度等,都极有可能使模型陷入过拟合。基于此,本文在充分分析CNN特点及目前国内外学者对CNN模型过拟合问题的研究基础上,提出了一种面向最大值池化Dropout与权重衰减过拟合问题算法,并将该算法与SSD[8]网络相结合,并通过理论推导与实验对比,证明了该方法能有效避免检测中主干CNN模型训练过程的过拟合问题,提高了模型的泛化能力,进一步提高了目标的检测能力。
2 传统的SSD检测算法及其局限性(Traditional SSD detectionalgorithmanditslimitations)
SSD算法是一种目标检测算法,由LIU等[8]在欧洲计算机视觉国际会议(ECCV2016)上提出。SSD借鉴Faster-RCNN[10]中的锚框机制,在特征图上生成具有不同长宽比例的默认框进行预测,并使用金字塔结构,在低层检测小尺寸目标,在高层检测大尺寸目标。
2.1 SSD基本原理
SSD网络结构如图1所示,该结构由两个部分组成,一部分是VGG16[15]基础网络,另一部分是附加特征层。其中,基础网络用来提取低尺度的特征映射图,附加特征层用来提取高尺度的特征映射图。SSD将VGG16网络中的全连接层FC6和FC7替换成卷积层,去掉DropOut层和FC8层,将池化层pool5从2×2的大小及步长为2更改为3×3的大小和步长为1。VGG16中的Conv4_3作为第一个特征图,经过多次卷积得到大小不同的特征图Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2,通过对多个特征图同时进行分类预测和位置回归,最后经过非极大值抑制(Non-Maximum Suppression,NMS)策略过滤掉重叠度较大的预测框,完成对不同大小目标的检测。
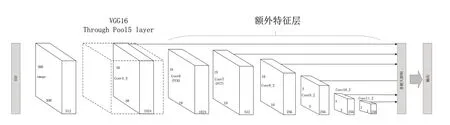
图1 SSD模型图Fig.1 The SSD model diagram
SSD借鉴了Faster-RCNN中的预定义边框(Anchor Box)的理念,为每个单元设置了宽高比不同的先验框。每个单元有k个先验框,每个先验框会预测c个分类的分数和4 个位置偏移量,大小为m×n的特征图将会产生(4+c)×k×m×n个预测参数。
先验框架的比例随着特征图大小的减小,其线性增加,设Sk表示第k个特征图先验框和原图大小的比例,m是特征图的个数,则默认框大小计算公式(1)如下:
在模型训练过程中,需要确定真实目标匹配的默认框。第一,每个默认框找到与其交并比(Intersection over Union,IoU)最大的先验框,作为正样本,如果一个先验框没有与任何默认框匹配,则作为负样本;第二,在未匹配的先验框中,如果存在与某个默认框的IoU大于一个阈值,那么也作为正样本。设真实目标的默认框大小为SGT、先验框的目标大小为SPB,则IoU计算如公式(2)所示:
2.2 SSD的局限性
SSD不同层提取的特征图感受野如图2所示,图2(a)为低层特征图的感受野,图2(b)为中层特征图的感受野,图2(c)为高层特征图的感受野,模型的低层特征由于经过的卷积运算较少,所以特征图包含更多的纹理和细节信息,但语义信息不足,难以区分目标和背景,高层特征图包含较多的语义信息,但是在层层卷积下采样过程中丢失了大量细节信息。SSD采用金字塔结构的特征层进行目标检测,利用大感受野的高级特征层预测大目标,利用小感受野的低级特征层预测小目标。然而,不同类别的特征层是独立的,低层特征图没有利用高层特征图的语义信息,导致真实目标与先验框难以匹配,无法满足检测小目标更加精确的要求。同时,每个特征层是独立的,信息不能共享。综上,SSD算法对于小目标的检测并不理想。

图2 特征图感受野示意图Fig.2 Schematic diagram of receptive field on the feature map
3 改进的SSD(The improved SSD)
上文介绍了传统的SSD模型,本部分在上述基础上设计一种最大值池Dropout与权重衰减CNN模型,与传统的SSD模型相结合,以求在模型训练过程中最大限度地避免过拟合情况的发生,并且将高层语义信息与底层细节信息进行融合,通过反卷积将SSD网络结构中富含语义信息的高层特征映射到低层网络,以求模型能更好地检测小目标。
3.1 最大值池化Dropout
第二部分已说明,最大值池化是CNN池化层常用的方法,为了在模型训练过程中避免过拟合,本文在CNN池化层引入最大值池化Dropout。
分析公式(3)可知,在池化区域执行最大值池化Dropout时,通过多项式排列选择池化区域中经过递增排列的第j个激活值,作为该池化区域的输出值,即
假设第l层有r个Feature Map,每一个的大小为s,池化区域大小为t×t,又设池化步长为t,即不考虑重叠池化,则有rs/t个池化区域,则第l层要训练的模型参数为 (t+1)rs/t(其中加一个偏置),即最大值池化要训练的模型数量与输入池化层的池化区域单元数量呈指数关系。引入最大值池化Dropout后,池化单元被随机抑制,即t减少,要训练的模型参数量则呈指数减少,这样有效降低了模型复杂度,因而能更有效地抑制过拟合。
3.2 权重衰减计算
在训练大型CNN时,除了使用上述最大值池化Dropout抑制单元避免过拟合,如果模型在某些区域里函数值变化剧烈,则意味着函数的参数值(权重)偏大,使得该区域里的导数值绝对值大、模型也变得复杂,权重衰减通过约束参数的范数使其不能过大,以此降低模型的复杂度,减小噪声输入的影响,从而在一定程度上减少过拟合发生,该方法也叫正则化方法。
设模型的损失函数L0如公式(5)所示,进行权重衰减计算时,在原损失函数L0中加一个惩罚项,即
公式(6)中,L0是原损失函数,w是网络权重,即神经元的连接系数,λ(λ> 0)是惩罚项系数,用来衡量惩罚项与L0的比例关系,1/2是为了求导方便而设计的。上述惩罚项为网络权重w的平方和,对公式(6)进行求导:
公式(7)中,b为网络神经单元(如卷积核)的偏置,其包含在L0的on中,即on=w·xn-1+b,可以发现加上惩罚项后,对偏置b的更新没有影响,设η为学习率,对于权重值w有公式如下:
分析公式(8)得出,在没加惩罚项前,权重值w前的系数为1,即,加上惩罚项后,w前的系数变为1-ηλ,由于η、λ都为小于1的正数,所以1-ηλ< 1,即公式(8)的作用是为了减小w值,这就是权重衰减的理论意义。注意公式(8)中项是反向传播的权重变化梯度,无论加不加惩罚项,其表达式都一样。因此,这里所说的权重衰减项不包括此项。进一步对公式(8)进行分析,当w为正时,更新后的w'变小,当w为负值时,更新后的w'变大,由于|w|< 1(网络归一化后的权重),因此公式(8)的效果就是让w向0靠近,即|w|→ 0,使w的值尽可能变小,也相当于减小了网络的权重,降低了网络复杂度,从而避免过拟合。需要指出的是,公式(8)中参数λ值的大小设置很重要,λ太大,权重w减小过快,可能会出现欠拟合,甚至无法训练,而λ太小,又会出现过拟合。λ大小设置可采用基于Bayes决策规则调整法,该方法假定网络的权重与偏置是具有特定分布的随机变量,用统计方法进行自动计算,其详细内容可参考文献[16],限于篇幅,此处不做详述。其中,权重衰减的计算流程如下。

3.3 反卷积
低层特征层包含的细节信息较多,丰富其特征细节信息可以更准确地检测小目标。本文采用反卷积[17-18]操作,通过参数调整将高层低分辨率特征图映射为高分辨率特征图,然后将高分辨率特征图和低层对应的高分辨率特征图进行拼接,使用于检测小目标的低层特征图的特征更加丰富,提高特征表达能力。反卷积操作过程与卷积操作相反,具体操作过程如图3所示。
图3(a)表示卷积过程,其将3×3卷积核作用于4×4特征图中,卷积得到2×2的特征图。图3(b)表示反卷积过程,其操作与卷积相反,输入2×2的特征图,通过填充补零,并将3×3卷积核作用于特征图,得到4×4特征图。
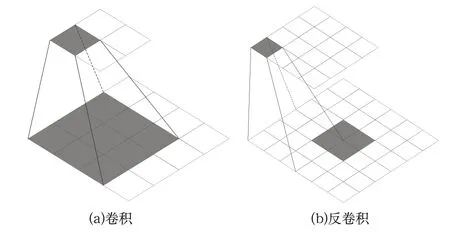
图3 操作示意图Fig.3 Diagram of the operation
为了表示方便,本文提出的最大值池化Dropout与权重衰减方法简称为MDWS(Maxpooling Dropout and Weight Scaled),并将此方法与传统SSD方法相结合,将传统SSD的池化操作替换为MDWS,如图4所示,网络的基本结构为VGG16,遵循特征金字塔进行目标检测,输入的图片经过改进的SSD网络(SSD+MDWS网络)主要提取出Conv4第三次卷积的特征,Fc7卷积的特征,Conv6、Conv7、Conv8、Conv9第二次卷积的特征,其中Conv4_3和Fc7提取到38×38、19×19的特征图是用来检测小目标的,为了让小目标检测效果更佳,将Fc7提取到的特征图进行反卷积,与Conv4_3提取到的特征进行融合,将Conv6提取到的特征图进行反卷积与Fc7提取到的特征进行融合,以增加特征,融合的过程如图5所示,并且在Conv4和Fc7的池化处理中设置MDWS模块,对于这两种特征图进行分类和回归预测,在训练的时候减少网络的复杂度,抑制过拟合,提高特征图内物体种类识别的精确度,有利于先验框参数的调整。
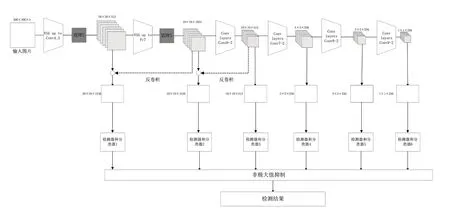
图4 SSD+MDWS网络模型图Fig.4 Diagram of SSD+MDWS network model
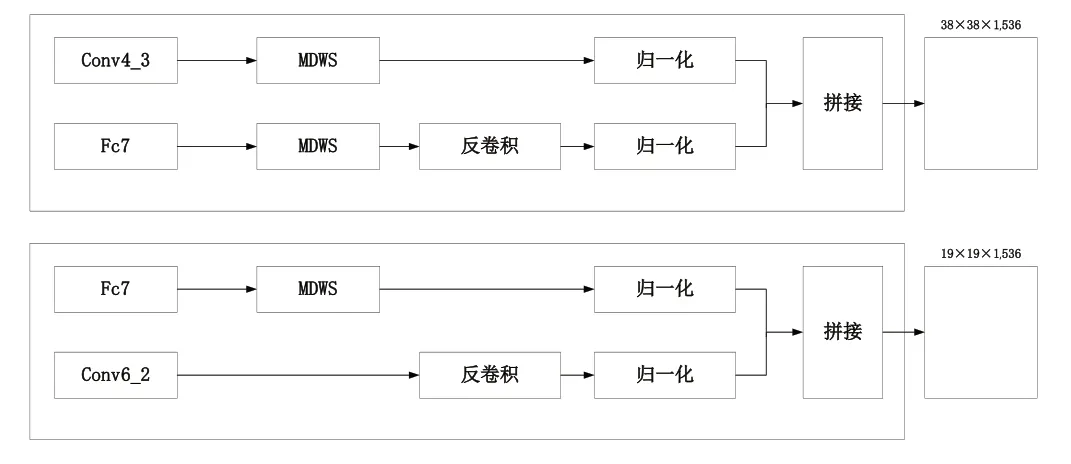
图5 特征融合模块Fig.5 Feature fusion module
4 实验结果分析(Analysis of experimental results)
4.1 实验环境
操作系统为Ubuntu 18.04;处理器为Intel Core i7 CPU@3.00,RAM 16 GB;GPU为NVIDIA GeForce GTX 1080Ti(11 GB);深度学习框架为Tensorflow;利用CUDA 10.1和cuDNN 9.1加速训练;使用Python作为主要编程语言。
4.2 数据集和训练设置
实验采用两个数据集,分别是Hyper-Kvasir[19]和CVCClincDB[20]。Hyper-Kvasir是一个大型的多类公共胃肠道数据集,数据来自挪威Baerum医院,所有的标签都是由经验丰富的医生制作的;该数据集包含异常(不健康)和正常(健康)患者的110,079 张图像和374 个视频,共产生约100万张图像和视频帧。本文采用Hyper-Kvasir-Segmented-Images数据集,该数据集提供了来自息肉类的1,000 张原始图像,并提供了分割掩码和边界框,这个数据集是由制作Hyper-Kvasir数据集的作者提供的。CVC-ClincDB包含23 位病人的31 个序列的612 个标准清晰图片,每张图片的分辨率为384×288。部分样本如图6所示。
图6 部分数据集内容Fig.6 Contents of partial dataset
训练时将数据集按照8:2划分为训练集和测试集,输入图像分辨率设置为300×300,初始学习率为1e-4,如果损失连续在10 个轮次之后不降低,则自动调节下降学习率,本实验采用与传统SSD相同的图像增强方法。
4.3 评价指标
对于检测任务,使用精确率(Precision)、召回率(Recall)、F1分数(F1-Score)及平均精确率均值(mAP)作为评估指标。设TP(True Positive)表示被正确判定为正类的样本;FP(False Positive)表示被错误判定为正类的负样本;FN(False Negative)表示被错误判定为负类的正样本;TN(True Negative)表示被正确判定为负类的负样本。
精确率(Precision)表示预测的正样本的样本数占所有预测为正样本的样本数的比例。精确度越高,分类器的性能越好,其定义见公式(9):
召回率(Recall)表示正确预测为正样本的样本数占实际正样本数的比率,其定义见公式(10):
F1-Score表示调和平均指标,其定义见公式(11):
得到模型的精确率和召回率,绘制PR曲线,PR曲线下的面积代表平均精确率(AP)。计算方法是先确定目标的得分置信度阈值,然后计算出符合条件的各个置信度下,测试集各图像中每类目标的精确率和召回率,接着绘制PR曲线图,最后计算PR曲线图的曲线下的面积,得到该类目标在该图像上的AP值。将所有的图像样本求平均,即可得到该类目标的最终AP标准值,然后对所有类别的AP求平均,得到mAP,见定义公式(12)(其中N是类别数目):
4.4 实验结果
4.4.1 Hyper-Kvasir数据集实验
首先,将改进后的算法SSD+MDWS与其他四种流行的模型在Hyper-Kvasir的100 张图片的测试集中做对比,模型为传统SSD[7]、YoLoV3[12-13]、Faster R-CNN[9]和SSDgpnet[11]。相应的实验结果如表1所示。分析表1中的数据发现,SSD+MDWS的整体性能是最好的,并且取得了最高的mAP,为92.23%,虽然在召回率的表现上,Faster R-CNN比SSD+MDWS多了约2%,但是准确率和F1-Score,都是本文提出的SSD+MDWS的效果更好,也在一定程度反映出网络训练时能够更好地减少过拟合。
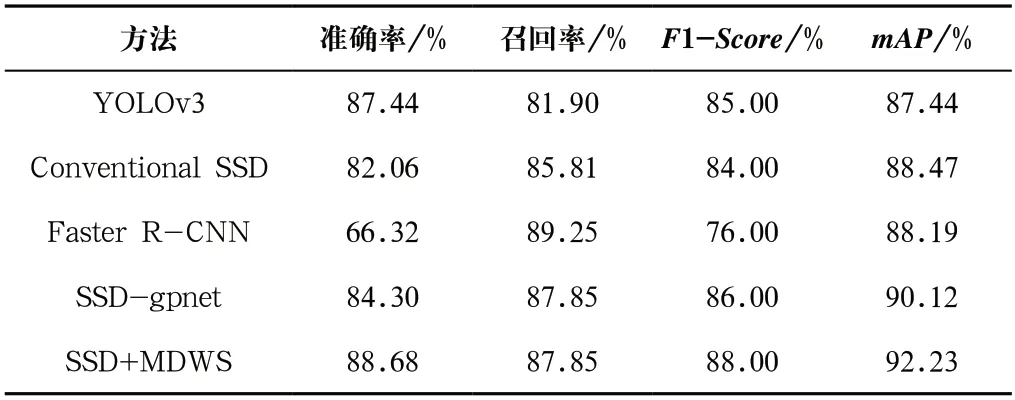
表1 Hyper-Kvasir实验不同算法测试结果对比Tab.1 Test results comparison of different algorithms in Hyper-Kvasir experiment
4.4.2 CVC-ClincDB数据集实验
同“4.2”部分介绍的实验,采取上述四种模型(SSD、YoLoV3、Faster R-CNN和SSD-gpnet),用划分好的测试集在各自训练好的网络中测试,得到的结果如表2所示。分析表2中的数据发现,SSD-gpnet的mAP、F1-Score、召回率分别为96.26%、94.00%、95.35%,比其他四个模型表现更好,但YOLOv3、Faster R-CNN、SSD-gpnet的准确率比SSD+MDWS表现更好,最高的多出4.66%。综上所述,SSD+MDWS算法的综合表现最好。图7展示了本算法的检测效果。
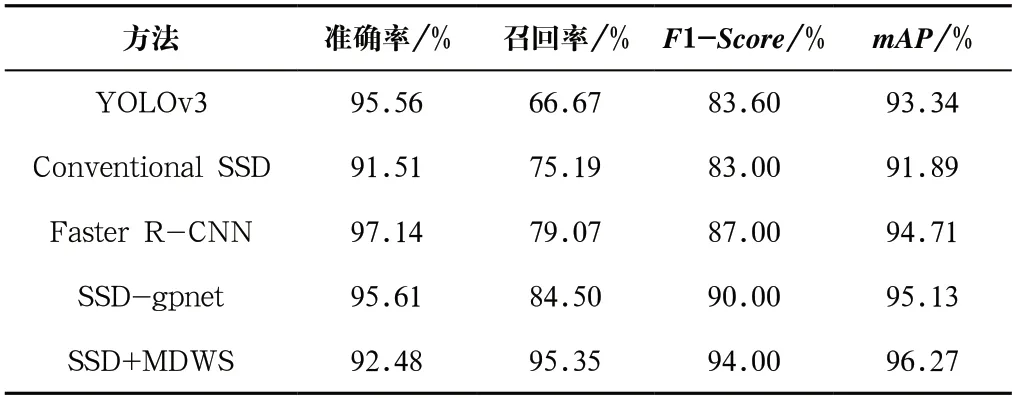
表2 CVC-ClincDB实验不同算法测试结果对比Tab.2 Test results comparison of different algorithms in CVC-ClincDB
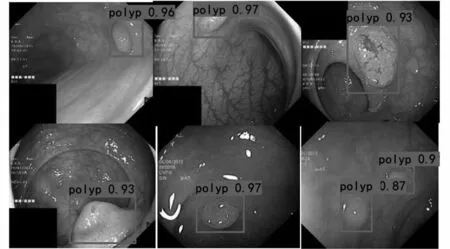
图7 检测效果图Fig.7 Detection rendering
5 结论(Conclusion)
本文采用改进的SSD算法检测息肉,在模型设计中,通过反卷积将低层和高层的语义信息进行融合,提高对小息肉的检测能力,并且通过在池化层设计一个最大池化Dropout方法及在反向传播中引入权重衰减机制,减少模型的复杂度,进而避免了模型训练中的过拟合现象。本文的创新点主要有两个:一是最大值池化Dropout的设计,采用池化区域单元值排序设计单元(神经元)丢弃方式,二是在反向传播中引入惩罚项设计权重衰减的执行过程。通过理论分析与实验对比验证了本文提出的方法能有效避免过拟合现象,提高网络泛化性能。通过实验评估,本文设计的网络显示出更大的息肉检测潜力。在每个评价指标中,都取得了比以前其他方法更好的结果。并且,良好的召回率和F1-Score表明本文提出的方法可以降低胃镜检查中误检和漏检的风险,可以为医生和患者提供更多的帮助。下一步,将该方法与更好的分类网络相结合,以期准确分析息肉的类别,通过改进CNN架构和功能模块实现更好的性能。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
软件导刊(2022年3期)2022-03-25 04:45:04
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
家庭医学(下半月)(2020年3期)2020-05-30 12:42:10
电子制作(2019年11期)2019-07-04 00:34:38
中国生殖健康(2019年3期)2019-02-01 06:12:08
计算机技术与发展(2019年1期)2019-01-21 00:56:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中国当代医药(2015年31期)2015-03-01 02:08:23
