
NAND Flash协处理系统弹载记录仪
2023-03-07 02:43张桐林石云波曹慧亮张英杰
探测与控制学报 2023年1期
张桐林,石云波 ,曹慧亮,赵 锐,张 越,张英杰
(1.中北大学电子测试技术重点实验室,山西 太原 030051;2.山西北方机械制造有限责任公司,山西 太原 030009;3.中国船舶重工集团有限公司第七一〇研究所,湖北 宜昌 443003)
0 引言
随着导弹信息化、智能化、实战化发展,弹载信息处理器对非易失的大容量数据存储需求变得非常迫切,随着弹载飞行过程中需要记录的数据量不断增加,对存储设备的存储速度和数据可靠性提出了更高的要求[1],如何以更小的存储设备尺寸发挥更大的作用同样是不变的话题[2]。近年来,大多数存储装置采用多片Flash组成阵列,并采用流水线的存储机制来实现高速大容量存储[3]。例如:意大利美光半导体公司Luca Nubile等人提出了一种针对Flash存储阵列的多线程控制算法,该算法对系统的逻辑开销、存储速度和容量等性能进行了优化[4];俄罗斯的Puryga等人研发的汤姆逊散射诊断数据采集系统同样包含多片存储单元,它允许以5 GHz采样率采集八通道数据[5];类似的组建Flash阵列以增加存储容量的方式在一些嵌入式系统和大数据硬件神经网络系统领域同样存在广泛的应用[6-8]。目前所广泛采用的NAND Flash在使用过程中会存在坏块无法进行数据的存储与读取,且位置随机,这对于复杂Flash阵列的可靠性问题是极大的挑战[9];或者在大容量弹载记录仪读取数据的过程中,难以快速提取有用数据,降低数据处理效率;或者在复杂的测试环境下,传统存储系统的触发方式可能增加其发生误触发的风险[10]。
针对上述提到的坏块多、读取速度慢、误触发风险高等严重影响存储器可靠性与工作效率的问题,本文提出一种基于NAND Flash协处理系统的弹载记录仪。
1 传统弹载记录仪
1.1 传统弹载记录仪原理
传统弹载记录仪的电路模块主要包括控制器、信号适配电路、A/D转换器、存储器、接口电路以及电源控制等部分。控制器完成对采集电路的控制、数字量的解码、混合数据流控制和读写存储器。信号适配电路将待测量的模拟信号经过放大和滤波调理后送入A/D转换器,A/D转换器将模拟信号转化为数字信号,然后存入数据存储器,接口电路实现记录仪与上位机之间的连接与通信。传统弹载记录仪原理框图如图1所示。

图1 传统弹载记录仪原理框图Fig.1 Schematic diagram of traditional bomb-borne recorder
1.2 传统弹载记录仪的优化方向
1.2.1坏块管理方式
NAND Flash出厂携带的坏块被称为固有坏块,在使用过程中,对块的擦除或编程操作失败,或是发生超出数据校验算法纠错能力的块被称为使用坏块。好的坏块管理策略是保证存储数据可靠性的关键[11]。
为了在使用过程中不受坏块影响,若采用传统的坏块管理手段,即提前对Flash进行坏块检测,并产生相应的坏块管理表[12-13],在数据写入Flash的块存储单元前,同坏块表进行预匹配,若验证该块为好块则开始记录数据。这种方式会限制Flash的存储速度,而且占用大量的设计资源,效率过低;若采用已优化的方法如页粒度管理方法,对于整个Flash的页错误率进行考虑,并采用DAM_FTL算法进行替换块适配,实现又过于复杂[14-16]。
如果能实现一种坏块管理策略,既能省去预匹配操作的时间,又能以相对简单的方式实现,这将大大提高数据存储效率。
1.2.2数据回读方式
弹载记录仪通常用于高冲击试验中记录弹道参数相关的高过载加速度信号。在侵彻试验中,需要实时完成对膛内发射与着靶侵彻过程中加速度信息的采集与记录,这一过程持续时间通常5~15 ms。为保证弹体发射和着靶侵彻过程被完整记录,需要保证弹载记录仪不间断地记录数据20~30 min。弹体回收以后,由计算机对记录仪中数据进行回读与分析。
弹体发射过程中会记录大量的数据,而其中膛内与侵彻数据却仅有亿分之一为有效数据。若采用传统方案,虽然通过引出多根数据线传输多bit数据,或者通过更换通信协议,可以提高数据传输速度,但这些方式或占用接口较多,或占用记录仪体积较大,且同样需要分析大量无效数据,并不能较好地解决问题。
如果系统在回读数据时,能够快速定位有效数据位置并设置任意起始地址,这将大大提高读数和数据处理的效率。
1.2.3触发与数据记录方式
传统弹载记录仪的触发方式主要有两种,第一种是设置触发时间,第二种是设置触发阈值。
设置触发时间方式,可以为炮弹装载入膛等准备工作留出时间,这种触发方式具有较高的可靠性,适用于有效数据少,测试环境复杂的侵彻信号的采集与存储。然而该方式的灵活性较低,如果弹体装载等准备工作超时或者发射时间推迟,此时炮弹已无法取出,记录仪却开始工作,等到Flash中数据计满后,系统自动断电,最终可能会导致试验失败。
设置触发阈值方式,即当系统实时检测的敏感信号大于阈值电压时,存储器使能,开始记录数据。首先,侵彻过程的测试环境较为复杂,各种谐波噪声叠加,且有效数据长度过短,因此在高过载测试环境中,这种触发方式的可靠性有待加强;其次,为避免丢失触发时间节点之前的数据,在系统对敏感信号和阈值电压的比较之前,需要暂存固定长度的预采样数据。FPGA内部RAM资源有限,可存储的预采样数据也很有限。这种触发方式的灵活性较高,适合应用于远距离弹飞行姿态等数据的采集与存储。
如果存在触发和数据记录方式,同时具备高的可靠性和灵活性,将大大提高弹载记录仪的性能。
1.3 基于NAND Flash的协处理系统
协处理器是一种与主控制器件协同工作,辅助其完成特定计算任务的专用处理芯片或器件。对于相对简单的系统,可以利用FPGA并行执行特点,针对NAND Flash设计协处理模块,配合主控制模块完成对存储系统的设计与优化。对于弹载记录仪来说,既可以实现单个主控制器难以胜任的功能,又在成本和空间上有着明显的优势。
2 基于NAND Flash的协处理系统
2.1 基于协处理系统弹载记录仪的整体框架
图2为基于协处理系统弹载记录仪的原理框图。相比传统弹载记录仪,系统中多了协处理模块与存储阵列。结合NAND Flash的特点和传统记录仪待优化的方向,协处理系统的设计主要包括以下模块:以整合好块地址为基础的坏块管理策略,以可控起始地址为基础的数据读取方式,以Flash存储阵列为基础的“边擦边写”的二级流水操作。主控制系统与协处理系统协同工作,共同完成数据的采集与存储。
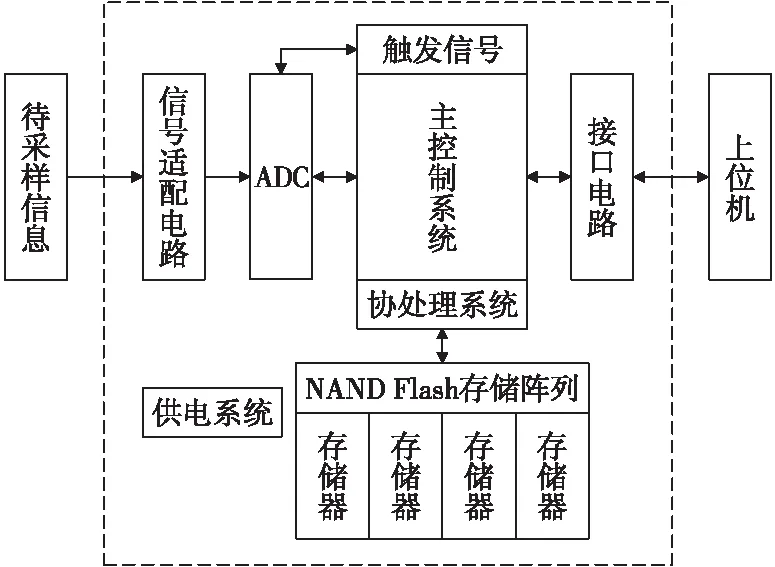
图2 基于协处理系统弹载记录仪原理框图Fig.2 Schematic diagram of Missile recorder based on co-processing system
2.2 NAND Flash简介
本文选用三星NAND Flash器件K9WBG08,其存储结构为:NAND Flash数据以bit方式保存在memory cell,一个cell只能存储一个bit。这些cell以8个为单位,连成bit line,形成Byte。这些Byte line会再组成page,每64个page形成一个block。block是NAND Flash中最大的操作单元,擦除按照block为单位完成,编程/读取按照 page 为单位完成[17]。
2.3 基于整合好块地址坏块管理
基于整合好块的坏块管理策略的操作流程如图3所示。在块擦除操作的同时,判断该块是否为好块,则是将好块地址存入FPGA的RAM核中,否则跳过该块。NAND Flash芯片在出厂时会保证第一块为好块,因此将block0作为存放好块地址的固定区域,等待全部块擦除完毕后,将整合好的好块列表写入其中,即使系统下电数据依然存在。在执行页编程或数据读取操作前,首先从NAND Flash的固定区域中读取好块地址,并将其存放在FPGA的RAM核中,当需要向Flash发送待操作块地址时,可以快速从表中读出好块地址,从而实现以整合好块为前提的坏块管理。

图3 坏块管理流程Fig.3 Bad block management process
相比传统的坏块管理策略,本文方案更容易实现,且每执行一次擦除操作,便重新生成好块RAM表,不仅做到随时更新,还可以将处理坏块的时间集中在擦除操作期间,为页编程操作省去预匹配的时间,相比传统方案大大提高数据存储速度;不仅如此,构建的好块RAM表还可以串联协处理系统的其他模块,使整个系统更加简单。
2.4 基于起始地址可控的数据读取方式
基于起始地址可控的数据读取方式操作流程如图4所示。以构建好块RAM表的方法为前提,PC端可随意设置起始地址;系统上电以后,自动从NAND Flash的固定区域中读取好块地址;当读取的地址等于和起始地址时,将之后的好块存放在FPGA的RAM核中;当读到16位结束标志“ABCD”后停止,至此建立好了以起始地址为首的好块RAM表。在回读数据的过程中,待读取的块地址从好块表中取出,当表中所有好块地址读完或接收到停止读数指令时,整个数据读取操作结束。
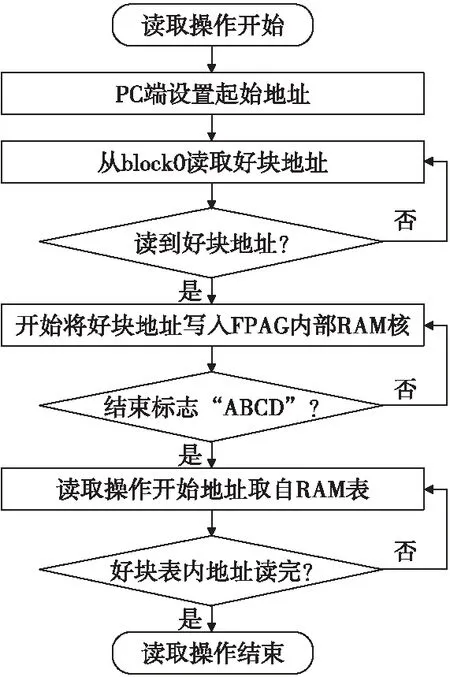
图4 起始地址可控的数据读取流程Fig.4 Data read process with controllable start address
2.5 基于NAND Flash存储阵列的二级流水操作
2.5.1二级流水式的并行操作
图5为NAND Flash执行单次操作的时间划分,在加载时间内,FPGA向Flash发送指令、地址和数据;在忙碌时间内,NAND Flash不响应任何指令,此时Flash与FPGA之间的总线空闲,可通过软硬件的协同合作,利用忙碌时间对另外的Flash进行加载操作,这也称为对存储阵列进行流水操作。

图5 NAND Flash单次操作时间划分Fig.5 Time division of single operation of NAND Flash
K9WBG08由两个相同型号的小容量Flash基片组成,分别称为chip1和chip2,除片选和等待信号外,其他端口均可共用。每个基片在读、写、擦操作的过程中存在忙碌时间,在此期间Flash不进行其余操作,这样在存储过程中,必然会造成时间的浪费,影响操作速度。利用Flash内部的两个基片组成存储阵列,在存储记录的过程中引入流水线式的并行操作,可以提高NAND Flash的使用效率。
与传统的并行操作不同,本文方案利用Flash内部的两个基片chip1、chip2交替地执行块擦除和页编程操作,形成一种“边擦边写”的记录方法,如图6所示,该方法可以在检测到敏感信号之前不断地进行数据更新。敏感信号到达后,FPGA总控模块发送start record指令,随后系统脱离“边擦边写”的循环状态,正式开始记录数据。

图6 二级流水式的并行操作Fig.6 Two-stage pipelined parallel operation
2.5.2“边擦边写”的循环记录法
“边擦边写”循环记录的方法是指按照图6中箭头所指方向,将箭头所指的块称作next block,将箭尾所指的块称作block。图7为单次“边擦边写”操作,在Flash按块存储数据的过程中,先将next block中的数据擦除,等待块擦除操作进入忙碌状态后,再对block进行页编程操作,直到该块的64页全部记录满后,对后续的块执行相同操作。在整个过程中,chip1、chip2交替并行执行擦写操作,循环往复。

图7 一次“边擦边写”操作Fig.7 One “erase-and-write” operation
这种方法可以在记录数据至某块前,保证该块为空。同时如图6所示,可以通过代码设置参数“x”,保留敏感信号到达之前任意存储容量的数据,因此最终的结果一定包含全部的有用数据。在此基础上,系统可以有充足的时间对敏感信号进行实时检测与多次核对,进而大大提高检测精度,降低误触发的风险。
2.5.3存储器存储数据的具体操作流程
存储系统存储数据的具体操作流程如图8所示。上电后,首先对系统进行初始化;其次,自动从NAND Flash的block0中读取好块地址,并将其存放在FPGA的RAM核中;随后进入“边擦边写”循环状态。值得注意的是,在检测到敏感信号前,RAM表中的好块地址被读出使用后又会被重新写入,由此整个操作流程得以循环往复;检测到敏感信号后,RAM表中的好块地址只出不进,直到表中剩余好块数量为提前设置的x时,Flash存储记录操作结束。
采用二级流水操作令Flash内部的两个基片分时复用,可在宏观上达到存储效率最大化,使系统吞吐率接近理论值,不仅如此,该方法同样可以运用在多片NAND Flash组成的复杂阵列中,以实现四级、八级甚至更多级流水操作,在提升存储效率的同时,大大节约FPGA的引脚,节省PCB布线空间[18]。
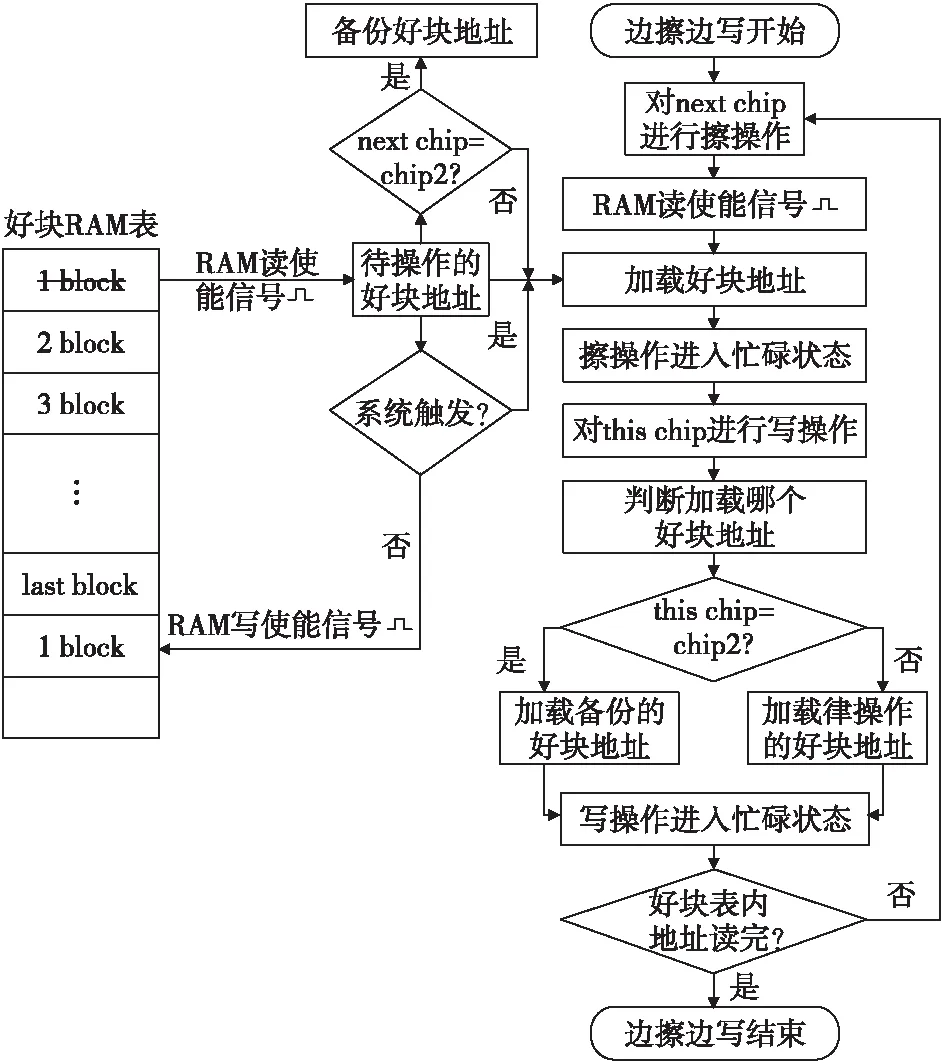
图8 弹载存储器记录数据的流程图Fig.8 The flow chart of the on-board memory recording data
3 验证与分析
3.1 仿真验证与分析
ChipScope软件是Xilinx公司提供的一个校验FPGA设计的工具。它的本质是一个虚拟的逻辑分析仪,能调用FPGA内部的逻辑资源对代码中的各个变量进行抓取分析。与ModelSim等一些其他的FPGA仿真工具不同的是,ChipScope可以直接反映代码在实际硬件上的执行情况,从而能够更加有效地定位设计中的问题。
实现坏块管理的逻辑电路仿真时序如图9所示,已知第2 589块为坏块(0x0A1D),上电以后进行遍历检测,发现可以有效地跳过坏块。同时发现rd_goodb_in_vld信号翻转,表示好块地址被写入FPGA的RAM核中,形成好块表。

图9 坏块管理仿真时序图Fig.9 Bad block management simulation timing diagram
实现起始地址可控的数据读取方式的逻辑电路仿真时序如图10所示。PC端设置起始地址为第32块(0x0020),上电复位以后,从NAND Flash的固定区域中读取好块地址(如图10(a)),当读取到第32块时,rd_goodb_in_vld信号开始翻转,表示开始将读取到的好块地址存放于FPGA的RAM核中,直到读到结束标志“ABCD”后结束,至此建立好以第32块为首地址的好块RAM表。接下来读取操作开始(如图10(b)),首先向NAND Flash发送读命令“00h”,然后rd_goodb_out_vld信号的电平置1,等待从RAM表中读出待读取块地址,随后以5个周期发送至Flash,再发送命令“30h”,等待rb置0再置1后,忙碌状态结束,数据被读出 。

图10 起始地址可控的读操作仿真时序图Fig.10 Read operation simulation timing diagram
实现基于Flash存储阵列的“边擦边写”的二级流水操作方式的逻辑电路仿真时序如图11所示,chip_cnt高电平表示对chip1使能,低电平表示对chip2使能,“边擦边写”操作开始后,首先建立好块RAM表,当识别到好块地址结束标志“ABCD”时,使能chip2并向其发送“60h”块擦除指令,然后rd_goodb_out_vld信号的电平置1,从RAM表中读出待擦除块地址goodb_add,并将其分为3个周期发送至Flash中。值得注意的是,若此时未检测到敏感信号(如图11(a)),则rd_goodb_in_vld信号的电平置1,随后等待刚刚读出的goodb_add重新写入好块RAM表中;若此时敏感信号已到(如图11(b)),则RAM表中的好块地址自此只出不进。发送完地址以后,向Flash发送指令“D0h”,等待rb2电平置0,chip2进入忙碌状态后,使能chip1并向其发送“80h”和5个周期的待编程地址,等待该块全部页编程操作结束,便完成了一次“边擦边写”操作。

图11 “边擦边写”操作仿真时序图Fig.11 “Erase-while-write” operation simulation timing diagram
上述仿真结果表明,小型弹载同步NAND Flash存储控制器的三项关键技术的功能基本实现。
3.2 实弹试验弹载测试
仿真分析论证通过后,构建高过载测试环境,开展靶场炮击试验,在弹体内部搭载小型同步NAND Flash存储控制器,通过在高过载环境下存储记录加速度信息,验证记录器在实际应用中的性能。
弹载存储系统使用Endvco传感器和自研高量程谐振式陀螺仪分别对膛内和侵彻过程中的三轴加速度和角速度信号进行分解;采用16位的模数转换芯片AD7606 B,以单通道800 kHz的采样率对调理后的6路模拟信号加2路稳压信号进行采集转换;由协处理系统完成对转换数据的编帧、缓存以及同触发阈值的比较,进而控制系统的触发和数据的存储。如图12所示,将小型存储电路板、传感器和电池进行集成,然后依次灌封于内壳体、外壳体和试验弹体内。试验弹采用改造过的130 mm弹丸,存储记录单元搭载于弹体尾部。靶体规格为2 m×2 m×2 m,混凝土抗压强度为C15,使用钢筋束缚围压。

图12 内壳体(左)、外壳体(中)和试验弹(右)Fig.12 Inner case (left), outer case (middle), test bomb (right)
试验现场如图13所示,发射平台采用130 mm口径加农炮,激光测速装置布置在炮口19 m处,靶体布置在距离测速装置29.4 m处,使用高速摄影记录弹丸的整个侵彻历程,弹丸穿过靶体之后由后面的夯土靶回收。

图13 侵彻实验现场Fig.13 Penetration experiment site
侵彻测试结束后,回收弹体并取出弹体内部的存储器(如图14),通过外露接口将数据上传至上位机并进行数据处理。

图14 回收弹体(左)和取出内部存储器(右)Fig.14 Recovering the projectile (left) and removing the internal memory (right)
用HEX Edit软件打开读取到的原始数据,如图15所示。左侧方框中4 B数据为帧计数,右侧方框中的0xEB90为数据帧尾标志,由图可知数据帧格式正确。上位机绘制的过载信号原始波形如图16所示,从图中可以看出,膛内与侵彻过载信号均为半正弦状脉冲,侵彻过载包括弹体的结构震荡以及噪声,用Matlab对数据进行处理,得到膛内与侵彻过程中的过载和脉宽,同理论值进行比较后得出本次试验数据无误。至此证明了小型弹载存储测试系统在实际测试环境中的工作性能稳定、可靠性高,能够完成大量原始数据的高速记录。

图15 读取的原始数据Fig.15 Raw data read
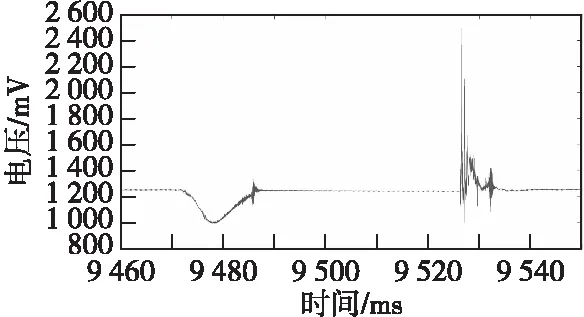
图16 过载信号原始波形Fig.16 Original waveform of overload signal
4 结论
本文通过对影响弹载存储系统可靠性的因素进行分析,从坏块管理、数据读取和多级流水操作3个方面入手,通过建立以整合好块为基础的坏块管理策略,以可控起始地址为基础的数据读取方式,以Flash存储阵列为基础的“边擦边写”的二级流水操作方式,实现了3项基于NAND Flash的关键技术功能,设计了一种功能更加全面的小型弹载存储控制器。相比于传统的弹载存储系统,该方案存在以下几点优势:
1) 构建好块RAM表的方法可以作为几项关键技术的前提,使整个系统得以串联,更加简单高效。
2) 坏块管理方式不但更加简单,而且不以牺牲数据存储速度为前提,将构建好块RAM的时间集中在擦除操作期间,省去了页编程前的预匹配操作,相比于传统方案数据存储地速度更快。
3) 数据读取方式更灵活,读取速度更快。
4) 降低误触发的风险,提高存储系统的可靠性。
本文提出的设计方案可以大大提高存储设备在复杂环境中的可靠性,为高速、灵活、小型化存储系统的研究提供思路,具有一定的实用价值。但系统同样存在一些不足,比如:构建好块RAM表虽然可以省去预匹配时间,却也不得不消耗部分FPGA资源来存储好块地址;在存储速度上,存储阵列擦写交替操作不比存储阵列交替页编程操作,如果要求系统搭载极高的采样率,则不利于数据的超高速存储。解决这些问题是后续研究的重点。
猜你喜欢
工业设计(2022年8期)2022-09-09
军民两用技术与产品(2021年10期)2021-03-16
考试与评价·高一版(2020年6期)2020-11-02
装备制造技术(2019年12期)2019-12-25
发明与创新·小学生(2019年5期)2019-06-14
中国生殖健康(2019年3期)2019-02-01
成都信息工程大学学报(2018年4期)2019-01-23
制造技术与机床(2017年10期)2017-11-28
家庭影院技术(2017年9期)2017-09-26
凿岩机械气动工具(2016年3期)2016-03-01
