
基于卷积神经网络的路面裂缝识别方法研究
2023-03-06 09:49王思源
智能城市 2023年12期
王思源 刘 杰
(桂林电子科技大学建筑与交通工程学院,广西 桂林 541000)
随着图像处理技术的迅猛发展,深度学习的方法在路面裂缝识别方面起到重要的作用。识别路面裂缝的研究人员采用神经网络方法进行实验并不断完善,以提高识别的准确性和实时性[1]。本文研究的识别模型可以识别裂缝,并将其区域按照二元值进行分类,可为公路养护的决策制定提供数据支持,保障公路运行的安全,降低维护成本。
1 数据准备
1.1 样本数据扩充
利用车载设备采集了裂缝图像,共得到2 000张原始图像,分辨率为3 024×4 032。考虑到裂缝图像尺寸过大不利于模型的训练,使用裁剪的方法将2 000张图像切割为大小为256×256的子图,并通过过滤得到包含裂缝像素数量大于1 000的图像,总共得到了685张含有裂缝的源图像和相应的标记图像。再通过图像扩充技术得到了4 000张裂缝的数据及其标签图像。按照4∶1的比例划分为训练集和测试集,包括3 200张训练集图像和800张测试集图像。Crack500数据集[2-3]包含500张裂缝图像及其标签,每张图像分辨率为2 000×1 500。为适合模型训练,每张图像被划分为16个不重叠的子图像。保存超过1 000像素的裂缝图像,共有1 286张作为训练集。通过数据扩展方法,共得到7 716幅裂缝图像和相应标签图像,按4∶1比例划分为训练集和测试集。训练集包含6 172幅图像,测试集包含1 544幅图像。
1.2 样本数据集标注
在监督学习算法中,必须在模型训练前对图像数据进行标注。标注是为了预先确定裂缝类型和位置,以便在模型训练和验证时使用。使用Labelme工具对地板裂缝图像进行注释具有易于安装、跨多平台、易于使用等特点。使用Labelme工具可以从头到尾勾勒出裂缝的多边形,并生成一个包含裂缝位置信息的“.json”文件。裂缝区域被标记为增强的多边形,标记通过端对端连接完成,随后生成一个“.json”文件,对该文件进行解码后可产生一系列包含与原始裂缝图像对应的标记图像文件。通过对数据集进行注释,可以对源数据进行注释。
Labelme图像标注如图1所示。
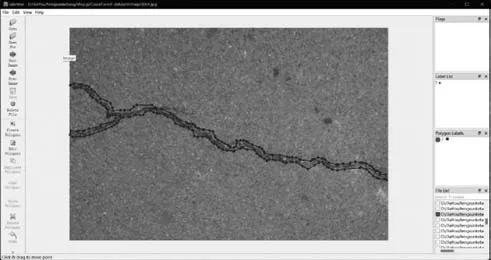
图1 Labelme图像标注
零件原图及对应标如图2所示。
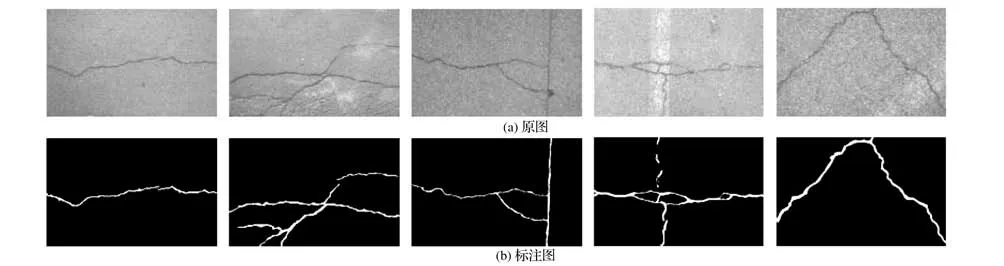
图2 零件原图及对应标注
2 模型结构
2.1 UNet神经网络
UNet神经网络模型如图3所示。
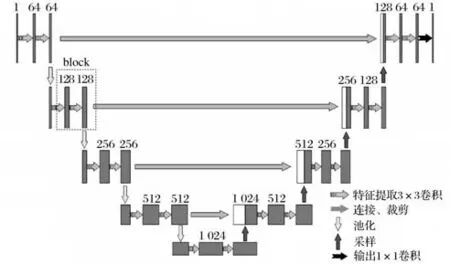
图3 UNet神经网络模型
编码器-解码器结构中,以SegNet和UNet为代表,其中UNet被广泛使用[4]。UNet是一种改进的全卷积神经网络,网络结构呈现“U”形。该网络通过复制和拼接的功能,将深层次神经网络的抽象特征与浅层次网络的图像信息结合,实现对图像的高效分割,精度较高。
UNet网络结构对称,两侧分别为编码部分和解码部分。编码部分用于提取特征,包含4个子样本、1个卷积层以及1个池化层。解码部分包含1个卷积层和1个去卷积层。连接、裁剪方法[5-6]利用编码部分的表面特征信息和解码部分的深度信息进行特征拼接,以保持特征数量和特征维度不变。网络可以通过采样操作保留图像中的精细特征。
2.2 改进的UNet网络
2.2.1 UNet改进思想
UNet本身的最佳深度尚无定论,因此需要广泛搜索网络架构或低效集成不同深度的模型测试[6]。跳跃连接对融合方案施加了限制,仅在编码器和解码器子网的相同比例的特征图上进行强制融合,因此在路面裂缝分割识别方面存在一定局限性。为解决此问题,提出了UNet++网络,借鉴了DenseNet的思想,将不同大小的UNet结构融入一个网络,通过短连接和上下采样等操作,简明融合多个不同层次的特征。该方法缺点明显,网络复杂,参数量大,速度明显下降。因此,本文提出用MobileNetV3网络取代UNet的编码器部分进行特征提取,以实现同时提高效果和速度。
2.2.2 MobileNetV3网络结构
MobileNetV3是由谷歌于2019年提出新版本的MobileNet,主要特点是引入了H-Swish激活函数与ReLU搭配使用,还引入了注意力机制的SE模块,使用NAS搜索参数的技术[7]。发布模型有两种,即MobileNetV3 Large和MobileNetV3 Small。本文使用MobileNetV3 Small网络结构作为UNet编码器结构。
(1)SE注意力机制。
SEBlock不是一个完整的网络结构,而是一个子结构,可以嵌入其他分类或检测模型[8]。SENet的核心思想在于通过学习的方式自动获取每个特征通道的重要程度,并利用得到的重要程度提升特征,抑制对当前任务不重要的特征,使有效的特征图具有更大的权重,无效或对任务影响较小的特征图权重较小。
SENet通过Squeeze模块和Exciation模块实现所述功能[9-10]。假设输入为U,SELayer首先对U进行全局平均池化1×1×C,再进行squeeze打平,经过两层全连接,最后用sigmoid限制到[0,1]范围,把这个值作为scale乘入输入通道,作为下一级的输入。MobileNetV3结构如图4所示。
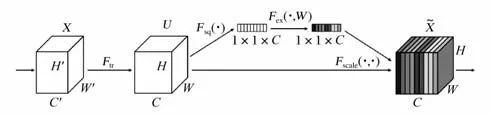
图4 MobileNetV3结构
(2)Hard Swish激活函数。
MobileNetV2使用ReLU6激活函数。目前常用的是swish激活函数,即乘上sigmoid激活函数。使用swish激活函数能够提高网络的准确率,但也存在问题,包括计算和求导时间复杂、量化过程不友好,特别是移动端的设备,为了加速一般都会进行量化操作,所以MobileV3使用Hard Swish激活函数。将swish激活函数替换为h-swish,sigmoid激活函数替换为h-sigmoid激活函数,能够提高网络的推理速度,对量化过程也比较友好。
2.2.3 UNet-MobileNetV3改进效果
(1)创新点。
使用MobileNetV3结构代替原来UNet编码器结构,原UNet编码器使用标准卷积层Conv+BN+Relu进行特征提取和下采样,改进后使用倒残差结构进行编码器部分的特征提取操作,标准卷积层为DW Conv+BN+Hard Swish,特征融合部分使用concat方式,在解码器部分上采样使用双线性插值法代替转置卷积,进一步减小参数量,加快模型训练和推理速度。使用Dice+CE损失函数。
(2)UNet-MobileNetV3网络结构。
改进后编码器部分使用倒残差结构进行特征提取,使用stride=2的卷积进行下采样操作。UNet-MobileNetV3网络结构如图5所示。
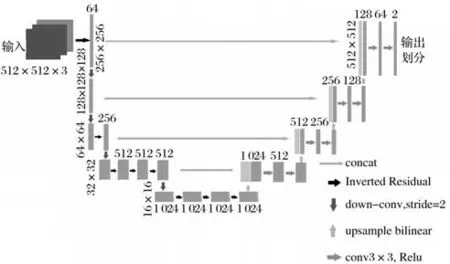
图5 UNet-MobileNetV3网络结构
倒残差结构如图6所示。
3 模型的实现与结果对比
3.1 实验开发环境
研究过程中选用Python作为主要的开发语言,使用谷歌的开源深度学习框架Tensorflow和Keras作为开发环境。模型使用的计算环境主要是Linux、Windows系统。实验的笔记本电脑配置为:GeForce GTX 3070ti,8 G显存;Intel(R)Core(TM)i7-12700h,2.3 GHz,16 G内存。
3.2 实验评价指标
卷积神经网络训练完样本后,需要一系列的指标来评价模型的效果,分别为像素精度、匹配集的平均交集[11-12]、查准率和召回率以及F1值[13-14]。总像素精度计算公式为:
式中:PA——总像素精度[15],所有正确预测的像素和所有像素的比率;TP——真阳性的例子,预测了一个阳性模式;TN——真阴性的例子,预测了一个阴性模式为阴性类别;FP——假阳性的例子,预测了一个阳性模式为阴性类别;mloU——意义总和系数,是评价语义分割的一个指标。
本文引入mloU衡量分割的水平,计算公式为:
式中:i——真实值;j——预测值;mloU——平均交并比;Pij——将i预测为j的概率。
式(2)也可等价为:
3.3 实验结果与分析
需要对改进模型进行稳定性验证分析。当用原始数据集训练UNet-MobileNetV3模型时,样本不足导致模型调整,其精度、召回率和F值较低。当UNet-MobileNetV3模型在扩充过的数据集上进行训练时,实验效果要比之前好,得到的指标也更高,没有发生过度调整或次调整。数据集扩增前后裂缝识别结果评价指标对比如表1所示。
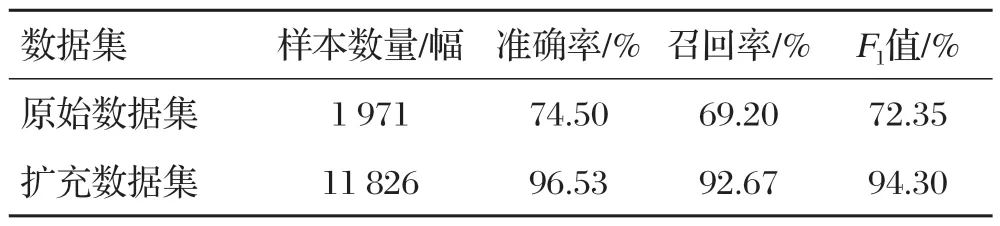
表1 数据集扩增前后裂缝识别结果评价指标对比
查准率P、查全率R以及F1的定义分别为:
式中:TP——正确识别的正例;FP——错误识别的正例;FN——未能正确识别出的负例。
由于准确率和召回率本身的限制,无法对裂缝识别结果进行全面评估[16]。本研究采用F1值[17-18]作为评价指标。
作为评估泛化能力的模型,测试数据集被分为三类。第一类,Crack500数据集和检测车获取的合并图像,表示为“Ⅰ”;第二类,分别通过Crack500的7 716张裂缝数据集的扩充,表示为“Ⅱ”;第三类,检测车获取的4 110张裂缝图像扩的扩充,表示为“Ⅲ”。在测试数据集包含被识别车辆获取的二维激光图像后,UNet-MobileNetV3模型的泛化能力得到了更好展现。UNet-MobileNetV3与传统UNet在数据集上的表现如表2所示。
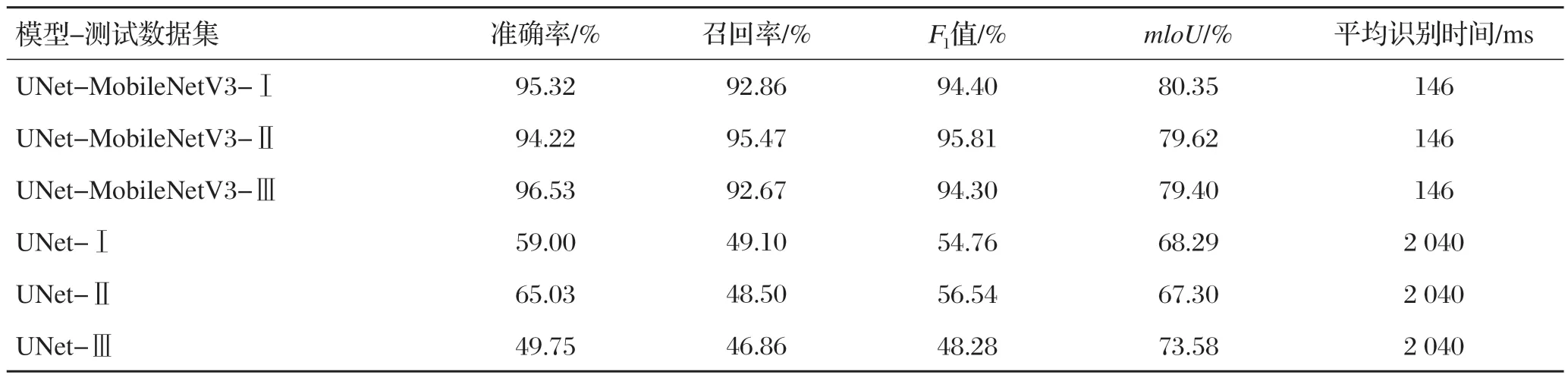
表2 UNet-MobileNetV3与传统UNet在数据集上的表现
当裂纹连续且接缝较宽时,两个模型都能识别出裂纹轮廓信息;但当裂纹较细且分散时,UNet-MobileNetV3模型仍能准确识别裂纹信息,而UNet模型在识别特定裂纹区的裂纹时效果较差;提出的方法在裂缝识别中没有出现裂缝。实验结果表明,用于道路裂缝识别的U型注意力网络模型具有较高的普适性。UNet-MobileNetV3与UNet的效果对比如图7所示。

图7 UNet-MobileNetV3与UNet的效果对比
经过训练可以发现改进后的UNet收敛速度明显快于普通UNet,训练速度和推理速度比普通UNet有明显提升,且从损失下降来看,UNet-MobileNetV3损失下降更快,而UNet损失下降上下震荡,达到一定阶段后梯度陷入局部最优。UNet-MobileNetV3与UNet的损失曲线对比如图8所示。
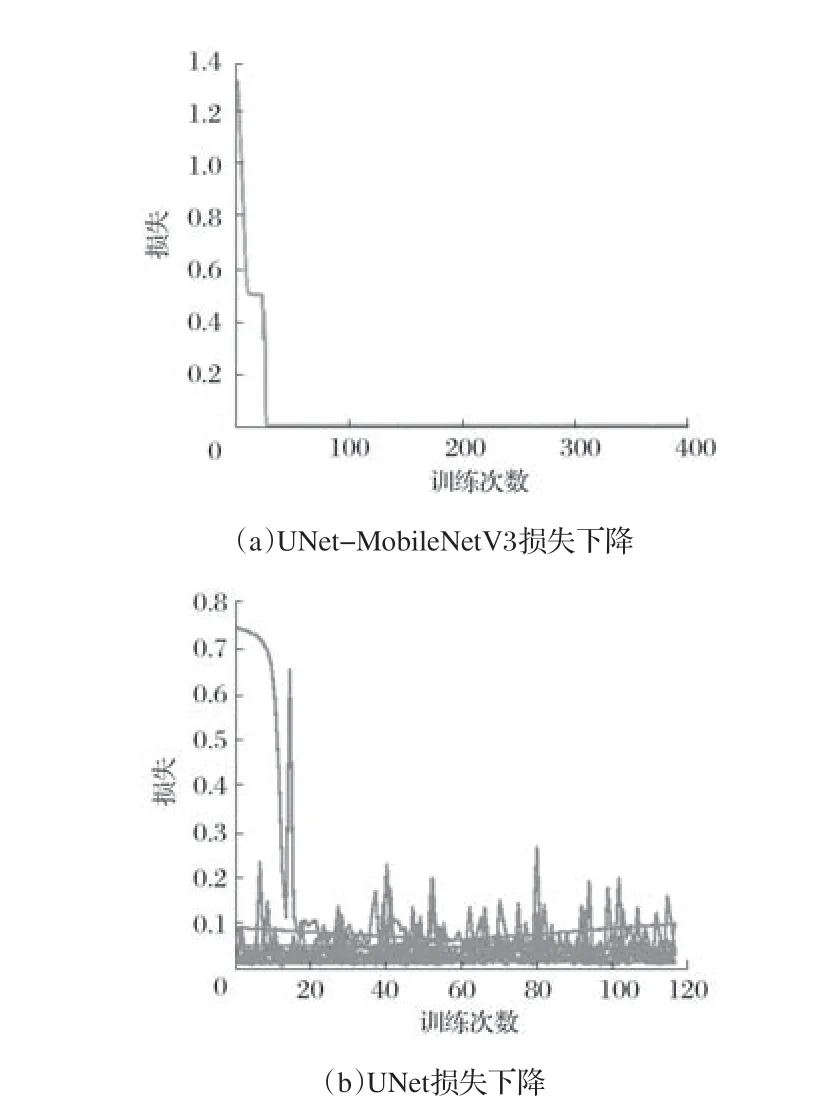
图8 UNet-MobileNetV3与UNet的损失曲线对比
4 结语
本文提出了一种基于深度学习的道路裂缝检测方法,通过深度学习模型可以自动学习道路裂缝的特征,自动识别和区分裂缝区域和非裂缝区域之间的差异,大幅提高了检测效率。为了更好地保留道路裂缝图像的边缘信息,可以结合使用高斯双边滤波器和最小滤波器的方法去除噪声;利用labelme工具对收集的裂缝图像进行标注,建立初始模型数据集;采用图像翻转、平移和色彩调整等方式扩展裂缝样本的数据;将所有扩充的数据样本组成最终的数据集,完成数据集的构建工作。经验证,并以道路裂缝问题为例,通过应用MobileNetV3网络替换UNet的编码器部分进行特征提取进而优化UNet网络模型,馈应达到更高的识别像素准确率、F1值和mloU,并提高算法检测的时间。研究结果表明,UNet-MobileNetV3网络模型在Crack500与识别车采集的裂缝融合数据集上的效果表现良好,在其他数据集上也取得了优异的实验结果。本研究已成功实现了路面裂缝的识别,通过改进经典的UNet网络模型完成了裂缝分割任务。但由于时间以及技术的限制,本文使用的裂缝识别算法并没有对裂缝的各个种类进一步区分。裂缝和非裂缝的区分识别是重要内容,需要先行判断出,但最好识别出不同种类的裂缝,需要后续深入讨论并完善。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
成都信息工程大学学报(2018年3期)2018-08-29
北京航空航天大学学报(2018年1期)2018-04-20
电子设计工程(2017年20期)2017-02-10
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
电子器件(2015年5期)2015-12-29
智能系统学报(2015年4期)2015-12-27
