
基于小目标类别注意力机制与特征融合的AF-ICNet 非结构化场景语义分割方法
2023-03-06 06:17:22艾青林张俊瑞吴飞青
光子学报 2023年1期
艾青林,张俊瑞,吴飞青
(1 浙江工业大学 特种装备制造与先进加工技术教育部/浙江省重点实验室,杭州 310023)
(2 浙大宁波理工学院 信息科学与工程学院,宁波 315100)
0 引言
非结构化道路可行驶区域检测技术是计算机视觉与自动驾驶研究领域的热点之一。在实际道路驾驶、大型工程作业以及机器人野外工作场景中,存在大量非结构化道路场景。非结构化道路相比于结构化道路,具有道路与周边颜色差异较小,道路目标物种类较多、信息复杂等特点。使用传统方法检测非结构化道路区域,存在检测精度低、实时性差、小目标检测效果差等问题[1]。由于小目标障碍物和行人会对道路可行驶区域检测造成严重干扰,而小目标在图像中分辨率低、携带的信息较少而导致其特征表征能力较差,大型类别的主导也容易导致小目标类别被忽视[2],因此如何提升非结构化道路小目标检测能力是目前亟待解决的技术问题。
近年来,基于神经网络的道路图像分割方法得到了快速发展,比如FCN[3]、SegNet[4]、U-Net[5]、DeepLab[6]等经典网络。其中,张凯航等提出基于SegNet 的非结构道路可行驶区域语义分割[7],龚志力等提出基于改进DeepLabV3+的非结构化道路分割方法[8],这些分割方法虽然可以有效分割非结构化道路区域,但实时性较差,其中部分网络的实际分割速度FPS 小于1 帧/s,无法部署在实时性要求较高的系统中。而轻量型网络ENet[9]、ICNet[10]等虽然实时性较好,但对小目标物体的分割效果较差。为了兼顾网络的实时性与非结构化道路中小目标物体分割精度,本文提出基于小目标类别注意力机制与特征融合的AF-ICNet(Attention and Feature fusion ICNet)非结构化道路场景语义分割方法,该方法主要内容有1)修改网络特征融合,使用空洞卷积特征金字塔替代池化以减少池化对网络特征提取的影响,并使用不同尺度的特征融合以扩大网络感受野,提高整体网络对图像的分割精度。2)基于小目标类别建立CA 注意力机制(Coordinate attention)模块,形成通道和空间注意力信息的长期依赖关系,以提高网络对不同复杂道路及小目标物体语义分割精度。3)建立融合权重的损失函数,针对非结构化道路的样本类别不均衡问题,对图像样本类别赋予不同的权重,以进一步提升网络对图像中小目标类别的分割精度。
1 基于AF-ICNet 的非结构化道路语义分割方法
1.1 基于小目标注意力与特征融合的AF 结构
1.1.1 扩大感受野的空洞空间卷积特征融合
在ICNet 中,考虑到此前的基于FCN 的语义分割网络无法有效的融合全局特征信息,网络中使用了空间金字塔池化(Pyramid Pooling Module,PPM)模块,用于聚合不同区域的特征信息进而获取全局的特征信息。PPM 模块结构如图1 所示。PPM 通过融合上下层不同大小的特征信息,实现了多尺度的特征融合。PPM 虽然增强了特征表征能力,但是其中大量使用的GAP 全局池化操作,在增大感受野的同时也降低了图像分辨率,为保证网络可以正常训练,需要统一图像尺寸,这会导致上采样恢复至输入大小时,池化造成的细节信息的丢失无法恢复。

图1 金字塔池化PPM 结构Fig.1 Pyramid pooling module structure
针对此问题,本文参考DeeplabV2[11]模型,修改原网络中的特征融合模块,为减少大量池化的影响,替换网络中的PPM,使用空洞空间卷积池化金字塔(Atrous Spatial Pyramid Pooling,ASPP)。改进后特征融合如图2(a)所示,网络使用空洞卷积替代了大多数的池化。采样率的不同会对网络分割产生影响,经过实验分析,本文使用了效果最好的四种不同采样率的卷积,分别为一个1×1 卷积和三个3×3 的采样率为6、12、18 的空洞卷积,以有效的获取多尺度信息。三个带padding 的空洞卷积,使得卷积的感受野分别扩大到了23×23、47×47、71×71,如图2(b)所示,不同的感受野卷积结果进行Concat 操作,小感受野便于网络获取精细的特征信息,大感受野便于获取目标在图像中的整体空间信息,通过大小不同感知野的特征融合,提升了网络对非结构化道路的整体分割效果。
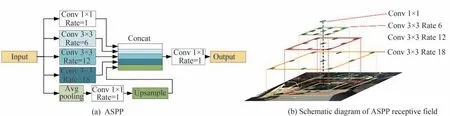
图2 空洞空间卷积池化金字塔ASPP 结构Fig.2 Atrous spatial pyramid pooling structure
1.1.2 增强小目标分割的CA 注意力机制
在非结构化道路环境中,注意到非结构化道路中的小目标类别数量较多,为进一步提升网络对小目标物体信息的获取能力,在网络中引入注意力机制。通道注意力经典网络SENet[12]仅仅考虑通道之间的关系来衡量每个通道的重要性,往往会忽略目标的位置信息。增加了空间注意力机制的CBAM[13]中通道注意力信息和空间注意力信息是相互独立的,相较于SENet 提升有限。为此,本文研究一种融合空间与通道信息的新型注意力方法——CA 注意力机制(Coordinate Attention)。将其与ICNet 网络语义分割结合,在保证实时性的基础上,进一步实现小目标类别分割精度的提升[14]。
将全局池化进行两个维度的分解,即使用(H,1)或(1,W)的池化核,使其分别沿着水平坐标与垂直坐标方向,对每个通道进行编码操作,即可将上述全局池化编码公式分解为
基于以上生成的两个特征,进一步将两个特征图进行结合操作,然后使用1×1 的卷积,对其进行变换操作
式中,F1为1×1 的卷积变换函数,方括号表示沿空间维度的结合操作,δ为非线性激活函数h-Swish。将中间特征映射f分解成两个单独的张量f h∈RC/r×H和f w∈RC/r×W,r为模块大小缩减率。分别将f h与f w变换为具有相同通道数的张量,并经过sigmoid 激活,得到的gh与gw为
最后得到的注意力模块输出为
在本文网络中,CA 注意力机制模块如图3 所示。将输入分别沿X和Y方向进行平均池化,经过维度转换后,将输入的C×H×W的向量转换为了C×H×1 和C×W×1 两个向量。池化后将两个方向的信息沿同一维度进行合并操作。使用r减少通道数以降低模型复杂度。经过批归一化(Batch normalization)和激活函数h-Swish 后,将网络再次沿先前维度分离、卷积以恢复到最初的大小。经sigmoid 激活后,与原输出合并进行reweight 操作。两个方向的单独分离处理可以使网络得到沿着两个空间方向的长期依赖关系,同时保留了精确的位置信息,有利于网络更加精确地定位到所需位置,提升网络对于非结构化道路环境中小目标物体类别分界处边缘的分割效果。

图3 坐标注意力机制结构Fig.3 Coordinate attention structure
1.1.3 注意力机制与特征融合组合模块(AF)
为了提升非结构化道路小目标类别的分割精度,本文基于ASPP 特征融合与CA 注意力机制,提出改进的AF(Attention and Feature fusion)模块结构,如图4 所示。模块以ASPP 为基础骨干,在每个支路嵌入CA注意力机制,使网络同时关注到不同感知野的注意力信息。ASPP 有效获取了不同采样率获取的图像特征,可以有效提升网络整体的分割精度,但针对小目标类别提升有限。因此通过在不同尺度特征信息后增添CA 注意力,弥补了ASPP 的不足。修改嵌入CA 注意力相比网络整体,参数不在一个量级,因此即使在每条支路均添加了CA 注意力,网络仍然处于轻量级,可以保证分割的实时性。

图4 AF 模块结构Fig.4 Attention and feature fusion structure
1.2 缓解类别不均衡的双权重交叉熵损失函数
道路类别像素数量统计如图5 所示。道路图像部分类别,如车辆、绿化带、道路等样本出现频次较高,而部分小目标类别出现频次则远低于平均值,数据集存在严重的类别分布不均衡的问题。出现频率较小的类别在交叉熵损失函数计算中权重占比较小,训练过程中占比较大的类别会很快达到较高的精度,而较小的类别精度很难再提升。ICNet 选用的是标准交叉熵损失函数。分别在三条支路上进行损失函数计算,总损失函数值由三条支路函数值叠加求得,标准的交叉熵损失函数并不能缓解类别平衡问题。

图5 Cityscapes 数据集与IDD 数据集的样本分布Fig.5 Sample distribution of Cityscapes dataset and IDD dataset
为此本文修改损失函数,设计带权重的交叉熵损失函数,以提升网络对占比较小类别的关注。带类别权重的交叉熵损失函数表达式为
式中,参数ωi用于平衡样本权重,针对像素较少类别,参数ωi应较大,以提升对其的关注。本文参考ENet 类别平衡方法[15],定义权重ωi为
式中,pi表示为相应类别i在图像中的像素占比。c为一设定超参数,用于限制权重间的间隔,c值越大,样本权重间的差值就越小。类别在图像中的像素占比越小,权重参数ωi就越大,也越有利于网络对这些类别的信息提取能力。
基于以上权重损失函数,改进后的网络总损失函数表达式为
式中,T表示支路数,在本文中T取3,λt表示支路权重,根据支路的不同分辨率图像,给定不同的数值,取值范围[0,1]。ωi表示类别权重,根据不同的道路复杂程度,c的值有所不同。
通过计算分析,c取值在[1,1.1]区间内,可以保证类别权重差值在合理范围内。c较小时,类别权重差异过大,网络对占比较大类别的关注度过低,会影响整体的分割精度。c较大时类别权重差异较小,会退化到标准交叉熵损失函数。本文在取值范围内对c与λ进行了参数敏感性分析,如图6 所示。
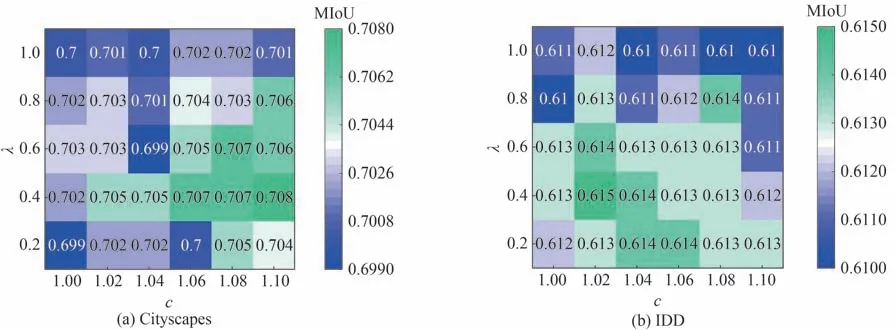
图6 λ 与c 的参数敏感性分布Fig.6 Parameter sensitivity distribution of λ and c
从图6 可知,对于参数λ,当λ在0.4~0.6 区间取值时,不同数据集的分割精度MIoU 均取得了较高值。对于参数c,Cityscapes 数据集在c=1.1 时MIoU 取得最大值,IDD 数据集则是在c=1.02 时MIoU 取得最大值。分析认为,对于复杂程度较高的非结构化道路,c的取值影响类别权重差值,而较大的权重差值会提升网络的分割能力,因此c的取值非常重要。改进的损失函数通过对不同类别赋予不同的权重,增强了网络对像素占比较少样本的特征提取能力,有效地提升了网络对小目标类别的分割精度。
1.3 AF-ICNet 网络整体结构
本文提出的AF-ICNet 网络整体结构如图7 所示,网络经由三个支路,分别对不同分辨率的图像进行特征提取。输入图像的分辨率基于Base size,分别压缩与扩张为0.5×Base size 与2×Base size,分辨率从小到大分别输入到三个支路中,记为Sub1、Sub2、Sub4。Sub1 采用较复杂的PSPNet 网络骨干,大量的道路语义信息均在此支路中获取,但是由于图像分辨率较低,网络对小目标的语义信息获取能力较差。Sub2 分支与Sub1 分支在骨干网络第一步的三层间共享部分卷积参数,通过低分辨率与中分辨率卷积参数的共享,加快了网络的分割速度。本文删除了Sub1 中的PPM 模块,修改Sub2 分支,将ASPP 与CA 注意力机制相结合,建立AF 模块。改进的Sub2 支路兼顾网络实时性同时,进一步提升网络对图中的小目标类别的特征提取能力。Sub4 输入分辨率较大,因此采用更少的网络层数。每个卷积后均连接批归一化(Batch normalization)及ReLU 激活函数。为融合不同支路间的特征信息,在层级间使用级联特征融合(Cascade Feature Fusion,CCF),输入双通道信息F1、F2,F1先进行双线性插值并使用大小为3×3,空洞率为2 的卷积核来精修上采样特征。F2使用1×1 的卷积使其特征数量与F1保持一致。F1、F2均进行批归一化操作,然后直接特征图相加并经过激活函数ReLU。经由三条支路以不同分辨率获取特征信息,网络有效地获取了不同分辨率的非结构化道路的语义信息。
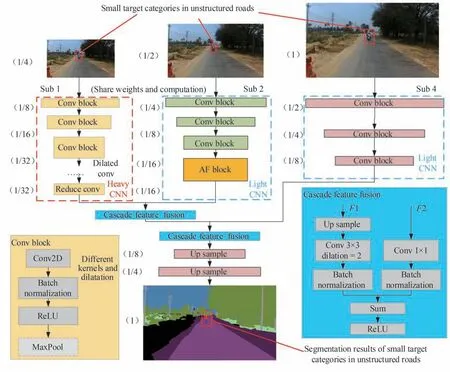
图7 AF-ICNet 网络整体结构Fig.7 The structure of AF-ICNet
2 数据集测试与分析
2.1 不同道路环境数据集选取
为满足多路况复杂道路环境检测的需求,本文使用了标准化道路数据集Cityscapes 及非结构化道路数据集IDD(Indian Driving Dataset)进行训练与测试。
Cityscapes 是一个关于城市街道场景的语义理解图像数据集,包括2 975 张训练集图像,500 张验证集图像和1 525 张测试集图像。原数据集包含19 个密集像素标注。由图8 可知,结构化道路图像中道路边缘较为明确,道路比较平坦,纹理基本一致。车辆、道路标志信号等较为明确。AF-ICNet 网络可以进一步提升对样本中小目标物体特征提取能力。

图8 Cityscapes 数据集训练样本图片Fig.8 Cityscapes dataset training sample image
IDD 数据集由VARMA G 等于2019 年提出,这是一个专用于非结构化环境中道路场景感知的数据集。它由一位于车上的前置摄像头在印度的海得拉巴、班加罗尔及其郊区道路上进行拍摄获得[16]。
本文根据实际道路与数据集标注情况,选取其中的9 947 张精细标注图像,将数据集分割为6 993 张训练集图像,925 张验证集图像和2 029 张测试集图像。数据集包含多级标签标注。考虑非结构化道路实际分割需求,选取3 级标签数据,将图像分割为26 个类别。图9 为IDD 数据集的样本图与标签图。由图可知,非结构化道路图像中道路边缘较不明显,道路纹理大都不一致,且车辆、行人等小目标物体较多,无明显的道路标志,因此提取非结构化道路特征信息难度较大。

图9 IDD 数据集训练样本图片Fig.9 IDD dataset training sample image
2.2 数据集训练环境配置
实验在一台CPU 为Intel i5-9400F、GPU 为GTX2070、内存16 GB 的计算机上运行。实验环境操作系统Ubuntu 18.04,语言环境为Python 3.6,编译环境为Pytorch 1.10.1,CUDA 版本11.3。
为了使网络可以正常训练数据集,在训练时设置Cityscapes 与IDD 数据集的Base size 为1 024,网络中Sub1 与Sub4 尺寸大小将被分别resize 为0.5×Base size 与2×Base size。Crop size 设置为960。两个数据集的Batch size 均设置为4。优化器采用随机梯度下降(Stochastic gradient descent,SGD)算法更新参数。为加速优化,采用动量梯度下降(Momentum SGD),在SGD 基础上引入一阶动量,减少震荡过程,在加速收敛的同时保证梯度下降的平稳性,其优化公式为
相比起传统的SGD,Momentum SGD 引入动量超参数γ,取值满足0≤γ<1,本文中选取γ=0.9。使用学习率衰减调度器,在提供更快的收敛速度的同时保证算法收敛。学习率η初始选取0.01,衰减率选取0.000 1。训练轮数选取200 轮,每一轮训练后均进行验证集验证。
2.3 数据集实验评价指标
网络分割精度评估指标为平均交并比(Mean Intersection over Union,MIoU)与像素精确率(Pixel Accuracy,PixAcc),实时性评估指标为实验测试速度FPS(帧/s)。
2.3.1 平均交并比MIoU
采用混淆矩阵统计模型分类的结果,分类结果混淆矩阵如表1 所示。

表1 TP、FP、FN、FP 含义Table 1 The meaning of TP,FP,FN,FP
交并比IoU 在语义分割中表示真实值和预测值两个集合的交集与并集之比。根据混淆矩阵,IoU 可以改写成式(12),MIoU 为对所有类别的IoU 求平均值。
2.3.2 像素精确率PixAcc
像素精确度PixAcc 表示图像中正确分类的像素所占百分比。根据混淆矩阵,PixAcc 可以改写为
2.3.3 每秒传输帧数FPS
FPS 表示画面每秒传输帧数,用于判断分割图像的速度,计算公式为
为测试图像分割帧数,在每次预测前后分别对当前时间进行记录,以获得时间差Δt,B表示Batch size。FPS 越高,网络的实时性越好。
2.4 数据集训练测试与结果分析
2.4.1 Cityscapes 数据集训练与测试
基于AF-ICNet 进行训练和验证实验,在训练过程中,模型每完成一个epoch,进行验证集验证,记录验证集的损失函数值、MIoU 以及PixAcc。通过以上操作,可以及时掌握模型的训练情况。
由图10 可知,改进损失函数的函数值在Cityscapes 数据集上随着迭代轮数的增加而降低,MIoU 整体呈现随轮数增加而上升的趋势,并最后达到了较高数值,证明改进的损失函数与训练策略在Cityscapes 数据集上的有效性。
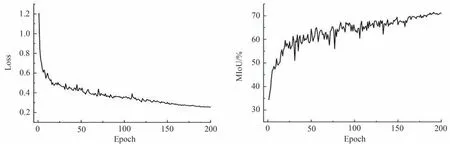
图10 Cityscapes 数据集训练过程曲线Fig.10 Cityscapes dataset training process curve
经过200 轮训练后,模型在验证集上的结果与现有模型结果对比如表2 所示。从表2 中信息可以看出,本文网络算法(AF-ICNet)在Cityscapes 数据集上有良好的表现。AF-ICNet 在验证集上的MIoU 达到了71.5%,高于SegNet 与ENet 网络,略低于DeepLabV3 Plus-MobileNet。本文网络的PixAcc 达到了81.3%。

表2 AF-ICNet 在Cityscapes 数据集上的测试结果Table 2 Test results of AF-ICNet on Cityscapes dataset
针对小目标类别,AF-ICNet 同样取得了更高的结果。Cityscapes 中占比较小的行人、交通灯、交通标志类别的IoU 分别从73.4%、55.5%、67.3%提升到了76.3%、61.2%、72.2%,证明了AF-ICNet 有效的提升了小目标类别的分割精度。FPS 达到了43.5 帧/s,虽低于ENet 与ICNet 网络,但远高于SegNet 与DeepLabV3Plus-MobileNet,满足实时性要求。本文网络的MIoU 达到了与高精度网络DeepLabV3Plus-MobileNet 相近的精度,但是参数量却远低于该网络,FPS 也远高于该网络。证明了改进AF-ICNet 能在保证实时性的情况下,实现高精度的道路语义分割。
图11 为ICNet 与AF-ICNet 对验证集的分割测试结果,图中虚线框为边界混淆区域,实线框为小目标类别区域。对于整体分割准确率,AF-ICNet 略优于ICNet,如图11 虚线框所示。AF-ICNet 分割边缘更贴近标签图像,对于相似类别的区分能力较强,例如道路与步行道类别。
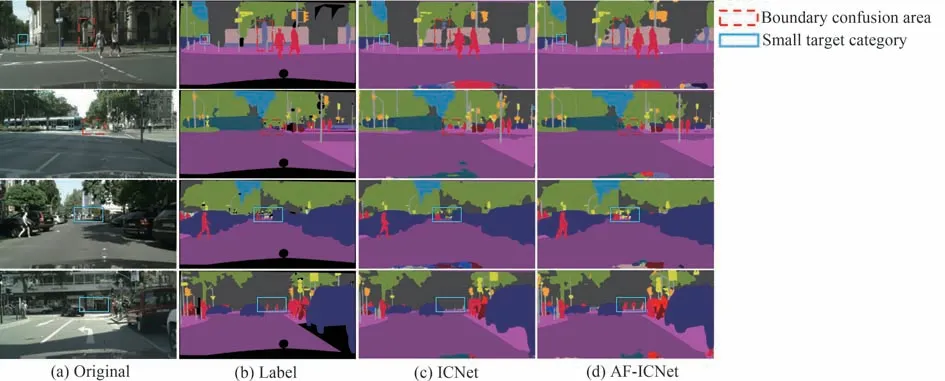
图11 Cityscapes 数据集分割测试结果Fig.11 Test result of Cityscapes dataset
AF-ICNet 对小目标类别分割精度明显优于ICNet,如图11 实线框所示。ICNet 对于远景的小目标提取能力较差,往往会将这类小目标类别归于远景中的大目标类别。AF-ICNet 则能够有效地将远景小目标类别提取出来,并且当图像中存在多种小目标类别混杂情况时,AF-ICNet 能够将小目标区分开来。
2.4.2 IDD 数据集训练与测试
基于AF-ICNet 进行训练和验证实验,模型每完成一个epoch,进行验证集验证,记录验证集的损失函数值、MIoU 以及PixAcc。
由图12 可知,改进损失函数的函数值在IDD 数据集上走势与Cityscapes 数据集类似,MIoU 最后同样达到了较高数值,证明改进的损失函数与训练策略在IDD 数据集上的有效性。经过200 轮训练后,模型在验证集上的结果与现有模型结果对比如表3 所示。

图12 IDD 数据集训练过程曲线Fig.12 IDD dataset training process curve

表3 AF-ICNet 在IDD 数据集上的测试结果Table 3 Test results of AF-ICNet on IDD dataset
从表3 中信息可以看出,本文网络算法(AF-ICNet)在IDD 数据集上同样有良好的表现。AF-ICNet 在验证集上的MIoU 达到了62.5%,高于其他网络。PixAcc 达到了89.8%。针对小目标类别,AF-ICNet 同样取得了更高的结果。非结构化道路中占比较小较难分割的的的行人、骑者、交通信号类别的IoU 分别从58.8%、70.0%、26.3%提升到了60.4%、72.0%、34.3%,证明了AF-ICNet 有效的提升了小目标类别的分割精度。FPS 达到了41.7 帧/s,虽低于ENet 与ICNet 网络,但仍远高于SegNet 与DeepLabV3Plus-MobileNet,满足实时性要求。AF-ICNet 在IDD 数据集上的MIoU 超出DeepLabV3Plus-MobileNet 1.3%,证明了本文改进AF-ICNet 对非结构化道路的分割精度提升很大。
由于非结构化道路复杂程度更大,ICNet 与AF-ICNet 对验证集分割精度差距进一步加大,如图13 所示,图中虚线框为边界混淆区域,实线框为小目标类别区域。对于整体分割准确率,ICNet 分割图像中出现了更多的相似类别的混淆情况,与标签图像相比错误率显著增大,AF-ICNet 的整体分割精度则高于ICNet,如图13 中的虚线框所示。
AF-ICNet 对远景图像中的小目标分割能力比ICNet 更强,如图13 中的实线框所示。即使在图像中占比极小的远景小目标物体,AF-ICNet 仍然有很强的能力将其分割出来,而ICNet 的小目标分割效果则明显劣于AF-ICNet。

图13 IDD 数据集非结构化道路分割测试结果Fig.13 Test result of unstructured road segmentation of IDD dataset
2.5 消融实验
消融实验类似于控制变量的思想,在机器学习领域常使用消融实验来分析不同的因素对神经网络实验产生的影响[19-20]。为进一步分析各改进模块对原始模型ICNet 的影响,将本文的方法分别裁剪成4 组进行训练。其中,第1 组为原始的ICNet 模型,第2 组增加使用权重交叉熵损失函数,第3 组在第2 组基础上增加改进ASPP,第4 组在第3 组基础上增加CA 注意力机制,即为本文的AF-ICNet 方法。消融实验结果如表5 所示,其中“√”表示实验中包括该结构,“×”表示实验中未包括该结构。

表4 消融实验Table 4 Ablation experiment
分析消融实验,各改进模块对于网络分割精度均有明显提升。对于Cityscapes 数据集,使用权重交叉熵损失函数,MIoU 提升了1.1%。增加ASPP 特征融合,MIoU 进一步提升了0.2%。在ASPP 基础上增加CA模块,形成AF-ICNet 网络,MIoU 再次提升0.5%,达到71.5%,而PixAcc 为81.3%。对于IDD 数据集,使用权重交叉熵损失函数,MIoU 提升了0.6%。增加ASPP 特征融合,MIoU 进一步提升0.6%,证明了ASPP 有效提升了非结构化道路分割精度。在ASPP 基础上增加CA 模块,形成AF-ICNet 网络,MIoU 再次提升0.4%,达到62.5%,而PixAcc 为89.8%。AF-ICNet 网络的FPS 虽略低于原网络,但是仍满足实时性要求。综上,AF-ICNet 与原ICNet 相比,能在保证实时性要求的同时,大幅提升网络的分割精度。
3 实景测试实验
3.1 实验测试系统
为验证AF-ICNet 网络模型在实际环境中的测试效果,本文进行了非结构化道路的实景测试实验。搭建了实验测试系统,如图14 所示。实验测试系统由TurtleBot 机器人底盘、笔记本电脑、Microsoft KinectV1相机等组成。使用笔记本电脑控制TurtleBot 机器人的移动,并采集相机图像。笔记本电脑配置如下:CPU为Intel i7-9750H、GPU 为GTX1660Ti、内存16 GB。电脑操作系统为Windows11,语言环境为Python 3.8,编译环境为Pytorch 1.10.1,CUDA 版本11.3。使用实验测试系统对非结构化道路进行实景测试,如图15 所示。实验中相机拍摄RGB 图像分辨率为1 280×960,拍摄速度FPS 为12 帧/s,满足实时性需求。实验选取非结构化程度较高的场景,其具有道路边线不明确,纹理不一致等问题。同时为验证本文方法对小目标的分割效果,人为增加小目标障碍物。

图14 实验测试系统Fig.14 The experimental testing system

图15 非结构化道路现场测试图Fig.15 The image of field work on unstructured roads
3.2 现场测试实验分析
利用搭建的实验测试系统在现场拍摄图像,选取了非结构化程度较高的道路,并按照非结构化数据集训练的模型结果,使用AF-ICNet 网络进行语义分割,结果如下图16 所示。

图16 现场测试非结构化道路分割结果Fig.16 Segmentation results of unstructured roads tested in the field
从图16 中可知,AF-ICNet 网络能有效分割出非结构化道路类别,其中关于小目标类别与边界混淆区域的分割效果比ICNet 网络更好。图16 实线框为小目标障碍物区域。对比分割图像可以看出,AF-ICNet 在小目标分割中取得了更好的效果,小目标障碍物的边缘更加平滑,与原图像的匹配度更高。图16 虚线框为边界混淆区域,从图中可知,AF-ICNet 能将道路中的边界混淆区域准确地分割出来,从而可以有效地获取非结构化道路的语义信息。在移动测试平台上,AF-ICNet 网络单帧1 280×960 高分辨率图像的分割速度为17 帧/s,这证明本文网络在性能配置一般的计算机上对高分辨率图像的处理速度同样较快。当分辨率为1 280×720 时,分割速度达到了31 帧/s,完全满足道路实时性检测要求。实景测试实验表明,AF-ICNet 在测试场景应用中取得良好的检测效果,具有很强的实际应用价值。
4 结论
本文针对非结构化道路环境语义分割存在误检率较高、边界容易混淆、小目标检测能力较差等问题,提出基于小目标注意力机制与特征融合的AF-ICNet 复杂道路语义分割方法。采用空洞空间卷积池化金字塔融合不同尺度特征感受野以增强网络的全局感知能力。利用CA 注意力机制模块提升了网络对图像中占比较小类别的信息提取能力。修改交叉熵损失函数提升了网络对出现频次较少类别的关注。数据集测试实验表明,AF-ICNet 对Cityscapes 数据集分割精度MIoU 与PixAcc 分别达到了71.5%与81.3%,对IDD 数据集分割精度MIoU 与PixAcc 分别达到了62.5%与89.8%。搭建实验系统进行了实景测试。实景测试证明,AF-ICNet 网络对小目标类别与非结构化道路整体分割能力提升显著,与ICNet 网络相比,在保证测试实时性的情况下,实现了更高精度的语义分割。未来研究工作中将增加道路环境的复杂度,如增加雨、雪、雾等复杂天气条件,在进一步优化网络结构基础上,实现更加复杂非结构化场景的语义信息提取和分割。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
河北理科教学研究(2021年4期)2021-04-19 13:34:44
计算机教育(2020年5期)2020-07-24 08:53:00
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
新校长(2016年8期)2016-01-10 06:43:59
计算机工程(2015年8期)2015-07-03 12:20:35
商事法论集(2014年1期)2014-06-27 01:20:42
电视技术(2014年19期)2014-03-11 15:38:20
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
