
基于对抗的一致性正则半监督辐射源个体识别方法
2023-03-04 13:25王天池赫德军
计算机测量与控制 2023年2期
王天池,俞 璐,赫德军
(陆军工程大学 通信工程学院,南京 210007)
0 引言
在现代战场上,作为“千里眼、顺风耳”的通信侦察技术早已是各国争相进行研究与攻关的关键领域,在实际通信对抗中,更是可以决定战场胜负的关键环节。辐射源个体识别作为通信侦察的一种技术侦察手段,在通信侦察乃至整个战场上发挥着至关重要的作用。辐射源个体识别技术在识别敌方设备、分析敌方目标个体、分析战场电磁态势、获取有价值的情报等方面,均有着十分重要的应用,同时对提高己方战备防御能力也非常关键。
不同辐射源个体之间,制造工艺、电子元件非线性的差异及信号调制方式的不同,导致了同一辐射源所发射信号的内在特征的不同。辐射源个体识别就是通过提取通信辐射源发出的信号中携带的个体细微特征信息,来识别不同的通信辐射源个体的方法[1-2]。随着深度学习的不断发展,辐射源个体识别技术由复杂繁琐的人工提取特征逐渐向深度神经网络提取特征发展,利用深度神经网络的优势提取区分不同辐射源个体的指纹特征,从而最终完成辐射源个体识别任务[3-4],相较于人工提取,往往精度更高速度更快。
由于传统深度学习依赖先验知识,而在战场实际环境中针对性采集辐射源信号十分困难,这就造成了带标签样本较少和无标签样本较为充足的现实困难,最终影响深度神经网络模型的识别精度。半监督学习作为一种经典的机器学习方法,可以有效缓解标签较少造成的识别精度问题。因此,也已被用来解决信号样本标签较少导致的辐射源个体识别精度下降问题[5-6],并取得了不错的效果。但是,在实际场景中,待识别目标信号往往因为不同信道的干扰,信号数据发生不同方式和不同程度的畸变,导致与前期采集到的信号样本数据分布发生不一致。因为传统的深度学习方法要求训练数据与测试数据分布一致,所以信号数据畸变的问题将最终导致由前期采集到的信号样本训练的神经网络模型,在待识别目标信号上识别精度的大幅下降。域适应方法作为迁移学习[7]最近几年的一个重点研究方向,提出了可以在具有分布差异的两个不同的数据“域”之间寻找“域不变”特征的具体方法,以缓解因为训练数据和测试数据分布不一致导致的模型精度下降,也就是最终实现数据“域”之间知识迁移。对于原采集信号和待识别信号之间数据分布不一致的问题,域适应方法理论上提供了一个可行的解决方案,并在通信辐射源个体识别任务上也有了相应的应用[8-9]。
综上所述,在实际环境中,辐射源个体识别精度不高往往是由于标签较少和信道变化这两个具体原因造成的,因此本文从问题本身出发,着眼基于一致性正则的半监督学习和基于对抗的域适应学习两个方向展开研究,并设计一种新的模型,同时解决上述两个问题,增强辐射源个体识别模型鲁棒性,从而最终提升辐射源个体识别精度。
1 相关工作
1.1 一致性正则半监督模型
半监督学习可以有效避免标签样本过少导致的模型过拟合的问题,基于一致性正则的半监督学习模型作为半监督学习的一个重要研究方向,已经出现很多成熟的具体模型。因此,本节主要介绍一致性正则以及3种基于一致性正则的半监督模型。
一致性正则是指模型对扰动的数据输出的分布预测一致性,也就是最小化训练过程中模型预测标签和实际标签之间的差异,通过缩小差异的过程让模型更易学习到样本内在的不变性[10]。一致性正则半监督模型对无标签样本进行多次预测,并最小化结果之间的差值,同时利用有标签样本有监督地训练分类网络,实现对于一个固定样本的输入,即使受到了噪声的扰动,模型对其预测的结果趋于一致,从而提升预测准确率。基于一致性正则的半监督模型通用结构如图1所示。

图1 基于一致性正则的半监督模型通用结构
该模型通过均方误差计算一致性损失Lconsistency,同时利用源域种有标签的样本监督训练标签分类器,得到标签分类损失Llabel。该模型的目标是最小化一致性损失Lconsistency和标签分类损失Llabel,模型总体损失函数为:
Loss=Lconsistency+ωLlabel
(1)
式中,ω是人工设置权重系数,平衡一致性损失和标签分类损失的训练权重。
本文主要介绍3种比较经典的一致性正则半监督模型:π模型、时序组合模型、师生模型。
π模型[11]是通过对同一个无标签样本分别进行两次数据增强,在π模型每一轮训练中,同一样本向前传播两次,由于随机扰动产生不同预测,通过最小化同一样本的两次预测差值,达到一致性正则的目标。π模型网络结构如图2所示。

图2 π模型网络结构

时序组合模型[12]在π模型基础上进行了创新,在一个迭代周期中,π模型对同一无标签样本预测两次,而在时序组合模型中,一个迭代周期只需要预测一次。时序组合模型引入EMA(exponential moving average,指数移动平均)将当前迭代周期之前的所有周期预测结果加权平均,并通过偏差校正提高较近迭代周期预测值比重,最终得到的预测结果与当前迭代周期预测结果计算一致性损失Lconsistency,有标签样本同样被用作产生标签分类损失Llabel。时序组合模型网络结构如图3所示。

图3 时序组合模型网络结构
π模型和时序组合模型使用单一网络对无标签样本产生多个预测结果,与它们不同的是,师生模型[13]则是通过构建一个拥有两个深度网络的“教师-学生”模型,实现对无标签样本产生不同的预测结果,再结合一致性正则化,达到半监督训练的目标,师生模型网络结构如图4所示。

图4 师生模型网络结构
师生模型的核心思想是学生网络利用教师网络产生的不同预测进行学习进而提高识别准确度,教师网络不通过反向传播进行参数更新,而是通过学生网络之前迭代周期中的参数加权平均进行参数更新,整个模型形成一个师生知识传递和反馈的循环,最终提升分类准确率。
1.2 基于对抗的域适应方法
近些年来,GAN[14](generative adversarial network,生成对抗网络)受到国内外研究人员广泛关注并取得了很多有意义的成果。GAN由生成模型G和判别模型D构成,生成模型G提取数据特征并生成数据,判别模型D通过预测二分类标签来区分样本来自于生成模型G还是训练数据集。GAN通过最小化生成模型G的对比损失,同时最大化判别模型D的判别损失来优化整个网络,这种对抗思想在信号处理领域已有广泛应用,比如孪生网络[15]。
域适应方法是迁移学习的一个热门方向,它的关键是从不同分布的源域和目标域数据样本中学习到“域不变”也就是和“域”本身无关的特征表示,通过这些特征表示,最小化域间差异带来的影响,使得即使是在源域数据样本上训练的分类器依然可以在不同分布的目标域数据样本上使用。受到GAN中对抗思想的启发,域适应方法结合GAN中域对抗的思想,通过最大化混淆域鉴别器的方式提取特征表示,目的是通过深度网络提取的特征表示,无法根据其分清样本来自于源域还是目标域,此时的特征表示与“域”本身的差异无关,也就是“域不变”特征,从而实现域适应。该类域适应方法结合GAN中对抗的思想,因此称为基于对抗的域适应方法。
Ganin 等人[16]证明了在域适应过程中,若无法分辨由神经网络提取的特征是源域样本还是目标域样本,那么该特征更能体现类别特征而不是域特征,即“域不变”特征的假设;其次提出了DANN(domain adversarial neural networks,基于对抗的深度迁移网络)模型。该模型通过利用特征提取器对源域和目标域样本进行特征提取,之后域鉴别器判断经过特征提取的源域和目标域样本特征到底是来自源域还是目标域,同时利用源域样本有监督地训练标签分类器,模型结构如图5所示。

图5 基于对抗的深度迁移网络
该模型通过域鉴别器计算域鉴别损失Ldomain,引入梯度反转使得Ldomain向相反方向传播,达到混淆域鉴别器的目的,同时通过标签分类器对源域进行有监督的训练,得到分类损失Llabel。该模型的训练目标就是最大化域鉴别损失Ldomain和最小化标签分类损失Llabel。模型总体损失函数为:
Loss=Llabel-λLdomain
(2)
(3)
式(3)中,参数γ为可人为调整,以控制训练的倾向性,参数ρ为当前训练轮数与训练总轮数的比值。参数λ的目的是让 DANN 在训练初期将更多的注意力放到学习源域特征上,使模型更好地收敛。
DANN首次将域适应方法与GAN中对抗的思想相结合,作为基于对抗的域适应方法的开端,后续研究都是建立在该思想之上进行改进。Wang 等人[17]系统归纳了基于对抗的域适应方法,并根据是否使用生成器将基于对抗的域适应方法分为两类:有生成模型、无生成模型,根据本文着眼解决的问题,主要关注的是无生成模型与一致性正则半监督模型的结合。
2 模型设计
2.1 模型改进
通过分析一致性正则半监督模型和基于对抗的域适应方法的原理,提出在一致性正则半监督模型的基础上加入基于对抗的域适应方法的改进思想,并设计出适合本文场景下辐射源个体识别任务的基于对抗的一致性正则半监督模型。

(4)

(5)
f(x)和f′(x)是样本x模型通过不同方式对样本x的两个预测值。

(6)

结合上述3个部分损失,定义模型总体损失函数:
Loss=Llabel+ωLconsistency-λLdomain
(7)
参数ω是人工设置权重系数,平衡一致性损失和标签分类损失的训练权重。参数λ的目的是让模型在训练初期将更多的注意力放到学习源域特征上,使模型对目标域也有一定的的识别精度,从而使模型更好地收敛,与式(3)定义相同。
2.2 模型结构
根据3.1节对一致性半监督模型的改进,设计适合本文场景下辐射源个体识别任务的基于对抗的一致性正则半监督模型网络结构如图6所示。

图6 基于对抗的一致性正则半监督模型
基于对抗的一致性正则半监督模型的训练过程具体如下:
1)将源域中少量带标签信号样本输入到模型,得到预测标签,利用交叉熵计算得到预测标签和真实标签的分类损失Llabel。
2)将源域中不带标签的信号样本输入到模型,通过经典的一致性正则半监督模型得到两个预测标签,利用均方误差计算一致性损失Lconsistency。
3)将目标域中的信号样本输入到模型,经过特征提取器提取出目标域特征分布,结合(1)中对源域带标签信号样本提取的源域特征分布,利用域鉴别器对两部分特征分布进行域鉴别,通过交叉熵得到域对抗损失Ldomain。
4)将三部分损失通过系数加权求和,得到模型总体损失,梯度反向传播更新网络参数(若是改进的师生模型,则教师网络不通过反向传播进行参数更新,而是通过学生模型之前迭代周期中参数加权的平均进行参数更新)。
5)重复步骤1)~4),直至网络训练结束。
3 实验与分析
本章主要介绍实验条件,包括数据集准备和深度模型训练过程中参数的设置,通过实验比较不同源域和目标域训练集设置条件下的不同模型的性能,并分析实验结果。本文实验硬件配置CPU为Intel(R) Xeon(R) Silver 4210 CPU @2.20 GHz,GPU为Nvidia Geforce RTX 2080 Ti,内存为DDR48G×2,使用PyTorch(1.7.1)平台和PyCharm开发软件。
3.1 数据集准备和参数设置
ORACLE射频指纹数据集[18]被广泛地作为辐射源识别研究的实验数据[19-20],该数据集对16台USRP X310无线电发射器的原始IQ样本进行无线采集。16台USRP X310无线电发射器发射的是MATLAB WLAN系统工具箱生成的符合IEEE 802.11a标准的帧。生成的数据帧包含随机有效载荷但具有相同的地址字段,然后流向选定的SDR(Software Defined Radio,软件定义无线电)进行无线传输。接收器SDR以5 MS/s的采样速率对输入信号进行采样,Wi-Fi信号的中心频率为2.45 GHz。
本文在ORACLE射频指纹数据集中随机选取10台USRP X310无线电发射器产生的IQ数据进行处理,根据辐射源的个数对信号数据进行类别标号,设置10类标签值。将信号数据按照一定比例分为源域和目标域,以及按照一定比例将源域分为有标签样本集及无标签样本集,并对目标域内信号数据添加高斯噪声用于模拟信道环境,测试集与目标域数据同分布。
每个样本由200个IQ两路载波信号数据点构成,图7所绘制的是一台辐射源设备产生的一个样本的数据波形图,横坐标为接收机采样次数。
图7 一台辐射源设备产生的一个样本的数据波形图
源域中无标签样本在输入模型前通过随机的数值遮挡进行数据增强,图8所绘制的是上文同一样本经过数据增强后的数据波形图。

图8 同一样本数据增强后的数据波形图
最终根据实验需要按照不同比例划分,完成样本数据集的建立。
本文所有实验在深度网络训练过程中,统一设置迭代次数为1 000次、batch_size为1 000、Adam优化器学习率为0.000 1。
3.2 不同模型性能对比
很多研究已经证明了师生模型在辐射源个体识别任务上的有效性[5],但其场景与本文场景有所不同,为了验证改进后的师生模型在本文场景下更具有优势,为后续实验奠定基础,本节将改进后的3种一致性正则半监督模型与全监督方法、改进前的一致性正则半监督模型进行对比。3种一致性正则半监督模型包括:π模型、时序组合模型、师生模型。
因为有标签样本和无标签样本的比例很大程度影响一致性正则半监督模型的性能,所以设置实验环境为源域有标签样本和无标签样本3种不同比例条件下,源域包含10 000个带标签样本以及若干无标签样本,目标域包含10 000个无标签样本,目标域信噪比为6 dB,测试集为与目标域同分布的2 000个样本,实验结果如图9所示,其中带*的为改进后的一致性正则半监督模型。
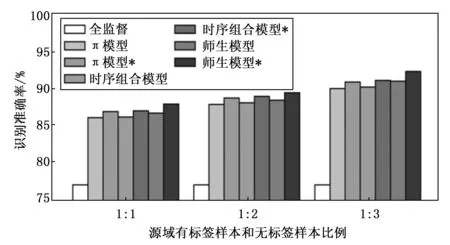
图9 不同模型改进前后性能对比

图10 全监督、师生模型以及本文模型输出的混淆矩阵
从图9可以看出,在3种源域有标签样本和无标签样本比例下,师生模型相较于其它两种模型在辐射源个体识别任务上呈现更好的性能。经过改进后的π模型、时序组合模型、师生模型相较于改进之前的模型识别性能均得到了提升,且经过改进后师生模型性能最好。
图10则给出了在源域有标签样本和无标签样本比例为1:1、目标域信噪比为6 dB的条件下,全监督模型、师生模型以及改进后的师生模型输出的混淆矩阵。全监督模型以及师生模型的混淆矩阵存在比较明显的错误,改进后的师生模型输出的混淆矩阵明显更加接近于单位矩阵,进一步直观体现了本文提出的改进对分类结果带来的明显改善。
总结得到,师生模型在改进前后均实现了较好的性能。因此在后续实验中,将改进后的师生模型作为本文提出的改进模型,简称本文模型,与全监督模型和改进前的师生模型,进行在目标域不同信噪比条件下的性能对比实验。
3.3 不同信噪比条件下模型性能
为了观察在目标域不同信噪比条件下全监督模型、师生模型和本文模型的模型性能,以及不同信噪比环境对模型性能的影响,设置实验环境为源域包含10 000个带标签样本和10 000个无标签样本,目标域包含10 000个无标签样本,依次给目标域样本添加7种不同信噪比的高斯噪声,测试集为与目标域同分布的2 000个样本,做7组对比实验,实验结果如图11所示。

图11 目标域不同信噪比条件下模型性能
从图11可以看出在不同信噪比条件下,本文模型相较于师生模型,识别性能均得到了提升。实验得出,在目标域信噪比12 dB时,本文模型相较师生模型提升性能0.41%,随着目标域信噪比的降低,模型性能逐渐提升,在信噪比0 dB条件下,本文模型性能相较于师生模型最高提升1.84%。因此,可以得出在目标域信噪比较低的环境下,本文模型相较于师生模型能够取得更好的性能提升的结论。
4 结束语
本文主要从辐射源个体识别任务在实际场景中前期采集信号样本标签数量少以及待识别信号与前期采集信号信道不一致的两个具体问题出发,分析了问题的根本原因,对相关领域展开研究,最终针对性的提出了解决方案。本文首先介绍了一致性正则的基本原理以及3种经典的一致性正则半监督模型,接着介绍了基于对抗的域适应方法的由来以及发展现状,并创新性地在一致性正则半监督方法中引入了基于对抗的域适应方法的思想,提出了基于对抗的一致性正则半监督方法的构想,并最终设计出一种基于对抗的一致性正则半监督辐射源个体识别模型。
本文在ORACLE射频指纹开源数据集上对模型的思想进行了充分的验证,并展开了模型性能的实验。通过在10台USRP X310无线电发射器数据上的分类性能的对比分析,可以看出经过基于对抗的域适应思想改进后的一致性正则半监督模型分类性能相较于传统方法有了明显的提升,验证了本文方法的有效性。接着,比较了在源域有标签和无标签样本3种不同比例下模型识别精度的实验结果,发现改进后的师生模型性能相较于该进前的传统师生模型有显著提升,证明了基于对抗的域适应思想对提升师生模型在辐射源个体识别性能的可行性。最后,分别在目标域不同信噪比条件下,模型分类性能的对比实验。实验结果表明,在目标域较低信噪比的环境下,本文模型可以获得更好的性能提升。
猜你喜欢
怀化学院学报(2021年5期)2021-12-01
计算机技术与发展(2020年11期)2020-12-04
北京航空航天大学学报(2020年10期)2020-11-14
数学年刊A辑(中文版)(2019年1期)2019-01-31
雷达学报(2018年5期)2018-12-05
数学杂志(2018年5期)2018-09-19
雷达学报(2018年3期)2018-07-18
雷达学报(2017年1期)2017-05-17
电子与信息学报(2015年12期)2015-08-17
纯粹数学与应用数学(2009年3期)2009-07-05
