
多模型融合的矿区地表沉降预测方法及适用性
2023-02-28 05:24:46原喜屯温永啸陈芯宇
大地测量与地球动力学 2023年3期
原喜屯 温永啸 陈芯宇
1 西安科技大学测绘科学与技术学院,西安市雁塔中路58号,710054
矿区开采引起的地表沉降易受多种因素影响,地表形变在时间域上通常呈现非线性特征,传统的线性模型难以描述、预测其复杂的动态变化过程。BP神经网络具有非常强大的非线性映射能力,可以进行自我学习和训练,对输入的多个影响要素进行非线性分析[1],更合理、科学地得到多个因素共同作用导致的预测结果。但BP神经网络要求训练样本质量较好,且其泛化能力不高,易陷入局部极小值[2]。鉴于卡尔曼滤波(KF)有较好的信息处理能力,本文将其与BP神经网络进行融合,构建KF-BP模型,并进一步融合AdaBoost算法,根据加权组合的方式提出AdaBoost-KF-BP强预测器模型。最后,通过MATLAB软件分别计算BP神经网络模型、KF-BP模型、AdaBoost-BP模型和AdaBoost-KF-BP模型预测矿区地表沉降的精度。
1 AdaBoost-KF-BP模型
1.1 BP神经网络
BP神经网络是一种由信息正向传播和误差逆向传播2个部分组成的多层前馈网络,其本质是将输入层的数据信息通过正向传递,经隐含层计算传至输出层进行输出,再根据输出值与真实值的差值进行误差反向传播,以对网络中各层神经元的权值和阈值进行调整修改,使误差函数沿负梯度方向下降,直到输出结果达到期望目标[3]。BP神经网络可对输入的多个要素进行非线性处理分析,一般分为输入层、隐含层和输出层,其拓扑结构如图1所示。

图1 BP神经网络拓扑图Fig.1 Topology of BP neural network
本文选取9种影响矿区地表沉降的因素和最大下沉值构建BP神经网络,输入层接受9种影响因素,输出层输出最大下沉值,故输入层节点数为9,输出层节点数为1。由Kolmogorov定理可确定隐含层节点数范围为[5,14],经多次测试,当隐含层节点数为8时,训练和预测效果最佳。
1.2 KF优化BP神经网络
BP神经网络对初始训练样本数据的要求较高[4],而获取矿区沉降监测数据时不可避免地会夹杂噪声数据,且作为单一预测模型,其稳定性与精度尚有优化空间。因此,本文将经典BP神经网络与KF进行融合。KF是一种最优化自回归数据的处理算法,可以应用于任何含有不确定信息且伴随各种噪声和干扰的动态系统中,根据对最新观测数据和前一时刻估计值的数据分析提出作用于系统的参数,估计出系统的历史状态和现在状态,再通过最优估计理论和滤波自身不断进行递推,对系统下一步走向作出有根据的预测[5]。KF的基本方程可分为状态方程(即动态方程)和观测方程,其离散化形式表示为:
(1)
KF算法可分为预测阶段和更新阶段。其中,预测阶段:
(2)
(3)
更新阶段:
(4)
(5)
(6)

在预测阶段,根据前一时刻的状态估计值推算当前时刻的状态变量先验估计值和误差协方差先验估计值;更新阶段则负责通过先验估计和新的测量变量来完成后验估计的构造与改进。因此,KF算法是一个递归的预测-校正方法。
在实际矿区沉降预测工作中,KF-BP模型的作用机理是通过KF算法对获取的原始矿区沉降监测数据进行去噪处理,再将去噪后的数据传递到BP神经网络模型中作为训练集参与后续的处理分析[6];之后根据输出值与真实值的差值进行误差反向传播,对网络中各层神经元的权值和阈值进行调整修改,使误差函数沿负梯度方向下降,直到输出结果达到期望目标。这种方法能在一定程度上改善BP神经网络中训练学习样本的质量,因此可有效提高模型的预测精度。KF-BP组合模型预测流程如图2所示。
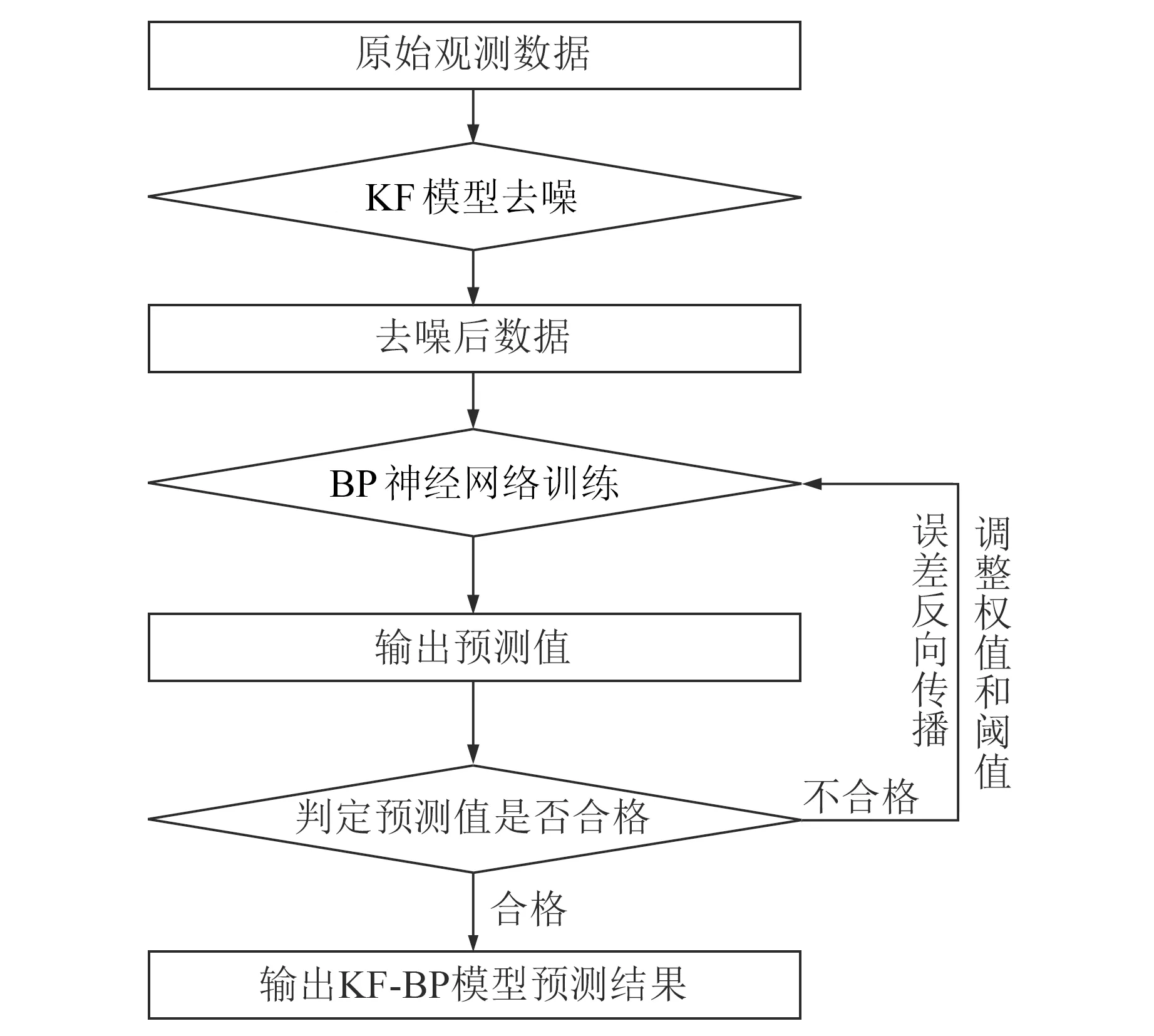
图2 KF-BP模型预测流程Fig.2 Prediction flow chart of KF-BP model
1.3 AdaBoost-KF-BP模型
AdaBoost算法由Boosting算法改进而来,两者核心思想均是将多个弱预测器组合成一个强预测器。不同的是,Boosting算法采用平均投票机制组合多个弱预测器,而Ada-Boost算法则重视误差较大的样本,通过改变其权重来改变样本数据分布,经过N次重复训练、测试,最终得到T个弱预测器及各自权重,根据加权组合的方式将T个弱预测器组合形成一个强预测器[7],这种方式得到的强预测器的精度更高。
突出基层平台建设,全县四级一体化行政审批体系建设走在全区先进行列。广西壮族自治区田阳县食品药品监管局注重乡镇行政审批的前置把关,在各乡镇的“一办三中心”设置窗口,严格开展申办指导、资质初审、现场核验、颁发许可等工作。通过网上审批,实现监管前置、重心下移,办件时限缩短,所有审批事项均比法定时限提速65%以上。在2015年自治区年中工作会议上,该局就食品药品监管工作做了典型发言并被自治区局授予“行政审批改革创新工作先进单位”。
根据上述理论,AdaBoost-KF-BP模型的作用机理是将KF-BP模型视作AdaBoost算法中的弱预测器参与后续训练、预测,若预测误差达不到期望,则将该样本作为加强训练样本,调整其样本权重并计算下一个弱预测器的权重。经多次测试,根据最终的各弱预测器权重分布,将多个弱预测器组合构成一个强预测器[8]。建立AdaBoost-KF-BP模型的基本思路如图3所示。

图3 AdaBoost-KF-BP模型预测流程Fig.3 Prediction flow chart of AdaBoost-KF-BP model
AdaBoost-KF-BP模型的具体步骤为:
1)导入样本数据。划分训练样本和测试样本,初始化各训练样本权重:
(7)
式中,Di为第i个训练样本的初始权重,n为训练样本的个数。
2)构建KF-BP模型。生成T个KF-BP弱预测器模型,并对样本进行训练、预测。
3)计算KF-BP弱预测器模型预测训练样本得到的预测误差ec。
4)比较预测误差ec与预设误差e,调整训练样本权重Di。
5)计算第t个KF-BP弱预测器模型的权重σt:
i=1,2, …,n;t=1,2,…,T
(8)
(9)
式中,et为第t个KF-BP弱预测器模型的预测误差率;T为弱预测器的个数。返回步骤2),进行下一次迭代,直到迭代T次后,结束训练。
6)输出AdaBoost-KF-BP强预测器模型。经T次训练,得到T组弱预测器模型及其弱预测函数ft(x),根据权重分布,将弱预测函数加权组合成强预测函数F(x):
(10)
2 实验分析
2.1 实验数据
已有研究表明,矿区地表沉降过程具有一定的时间性与随机性,其复杂性主要受地质和采矿等因素的影响[9]。考虑到矿区地表沉降规律受影响因素及其取值的不同而表现出较大差异性,本文选取9个主要影响因素:弹性模量、泊松比、内聚力、内摩擦角、采深、采高、倾角、覆岩平均单向抗压强度及松散层厚度,其中覆岩平均单向抗压强度和松散层厚度代表覆盖层的岩石特性和地质构造对矿区地表沉降的影响。选取某矿区40组监测点数据进行最大下沉值预测实验(实验1),样本数据如表1所示。
地表沉降机理表明,采深对地表沉降影响较大[10],故将原始40组数据根据采深是否大于300 m分为2组进行不同采深区域的矿区最大下沉值预测实验(实验2)。通过对比实验,分析AdaBoost-KF-BP模型在不同采深区的适用性,并验证采深对地表沉陷规律的影响。实验2中,采深小于300 m区域与采深大于300 m区域的样本数据如表2和3所示。
2.2 数据处理
实验1中,选取表1前30组数据作为BP神经网络模型的训练样本,后10组数据作为测试样本,使用MATLAB建立BP神经网络预测模型进行训练、预测。在BP神经网络的基础上,采用KF对原始训练样本集进行降噪处理后,再输入到BP神经网络中[11],构建KF-BP预测模型,以验证KF优化BP神经网络的可行性。将BP神经网络视作弱预测器模型,以此来构建AdaBoost-BP预测模型,分析AdaBoost算法对单一BP神经网络模型精度的提升。最终,为达到进一步优化的目的,构建AdaBoost-KF-BP组合模型,将原始样本数据输入该预测模型进行训练、预测。为更好地对比优化效果,将AdaBoost-BP模型和AdaBoost-KF-BP模型中的弱预测器个数均设置为9。

表1 实验1样本数据Tab.1 Sample data of experiment 1
实验2也采用与实验1相同的4种模型,不同的是,分别将表2和3前15组数据作为训练集,后5组数据作为测试集。

表2 采深300 m以下区域的样本数据Tab.2 Sample data of areas with mining depth below 300 m
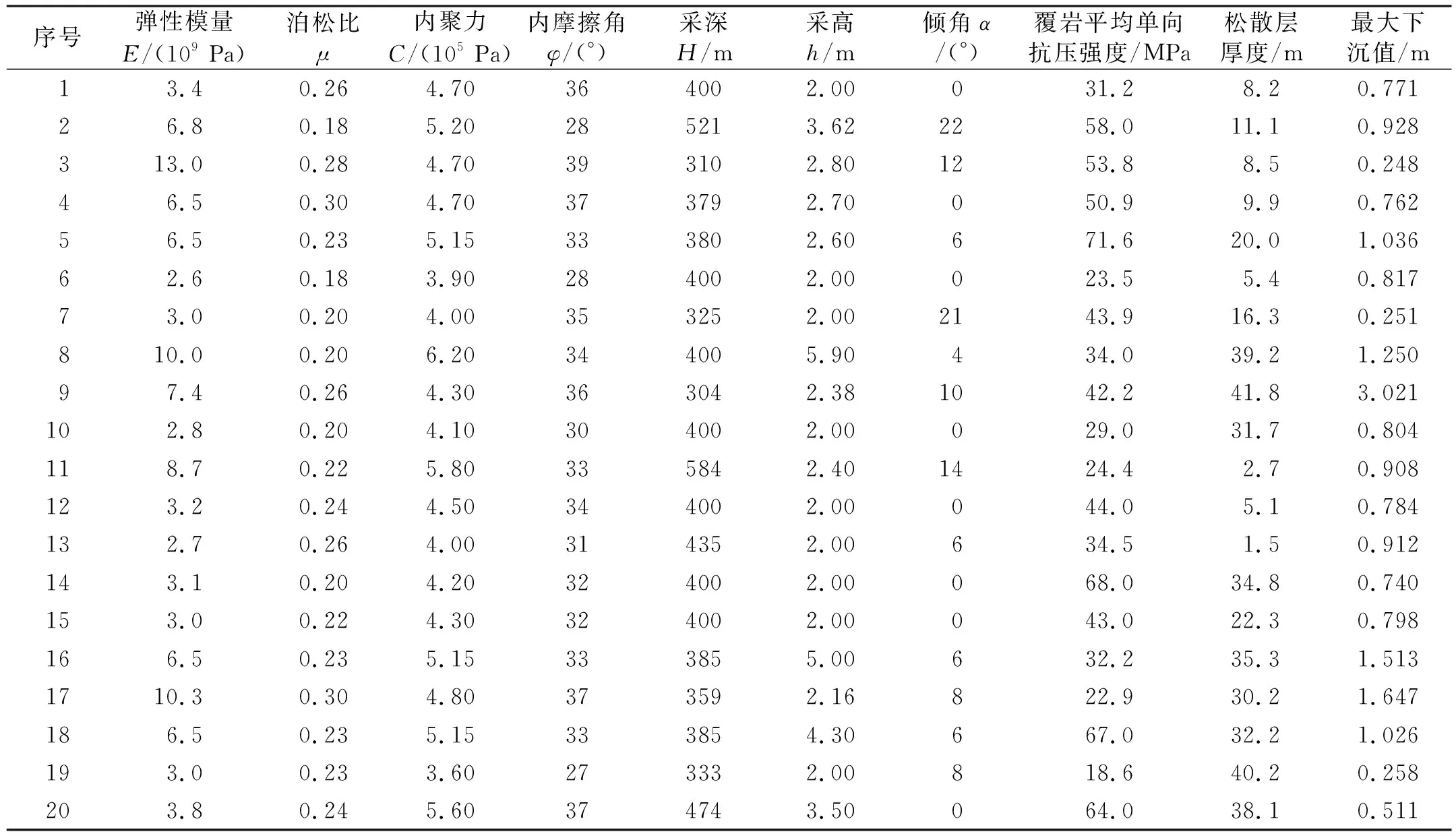
表3 采深300 m以上区域的样本数据Tab.3 Sample data of areas with mining depth above 300 m
2.3 结果与分析
实验1中,利用各模型预测矿区最大下沉值,并将预测误差绝对值进行对比分析,结果如图4所示。从图4看出,BP模型的预测精度较差,得到的误差绝对值最大达到1.600 m,最小值为0.561 m;KF-BP模型和AdaBoost-BP模型的精度相比于BP模型有所提高,两者的预测误差绝对值最小分别为0.106 m和0.209 m;AdaBoost-KF-BP模型整体的预测精度最高,其预测误差绝对值最小为0.013 m,且在10次预测实验中,AdaBoost-KF-BP模型的提升效果比KF-BP模型和AdaBoost-BP模型稳定。

图4 实验1预测结果Fig.4 Prediction results of experiment 1
选取平均绝对误差、均方根误差和均方误差3种误差评价指标对各模型预测精度进行分析,结果见图5和表4。可以看出,BP模型由于网络泛化能力不高、易陷入局部极小值及初始数据中存在随机误差和噪声等原因,其各项评价指标的值最大,平均绝对误差、均方根误差和均方误差分别为0.938 m、1.166 m和1.388 m;KF-BP模型

表4 实验1各模型精度对比Tab.4 Comparison of precision of each model in experiment 1
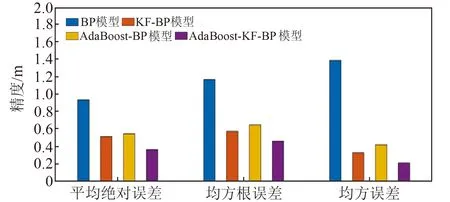
图5 实验1预测精度Fig.5 Prediction accuracy of experiment 1
通过利用KF对数据降噪处理优化BP神经网络,其精度相比于BP模型有所改善,平均绝对误差下降到0.516 m;AdaBoost算法通过将多个弱预测器组成强预测器的方式优化BP神经网络,其平均绝对误差为0.548 m;本文改进的AdaBoost-KF-BP模型集成了KF和AdaBoost算法各自的优点,预测精度最高,且明显优于前3种预测模型,其3种精度评价指标分别为0.367 m、0.460 m和0.212 m,相比于BP神经网络模型,平均绝对误差提升60.9%。
实验2的预测精度见表5和6。对比表5和6可以看出,AdaBoost-KF-BP模型对2个区域的预测结果的平均绝对误差分别为0.296 m和0.247 m,且采深300 m以上区域的各项评价指标的值均略低于采深300 m以下区域。该结果也验证了大采深区域的地表最大下沉速度更稳定,形变更缓慢、均匀[12],导致该区域的AdaBoost-KF-BP模型预测精度也会略有提高。在实际应用中,在对大采深区域进行矿区地表沉降预测时,可优先考虑AdaBoost-KF-BP模型。

表5 采深300 m以下区域预测精度分析Tab.5 Prediction accuracy analysis of areas with mining depth below 300 m

表6 采深300 m以上区域预测精度分析Tab.6 Prediction accuracy analysis of areas with mining depth above 300 m
3 结 语
1)KF-BP模型和AdaBoost-BP模型的预测精度均优于传统BP模型,而AdaBoost-KF-BP模型同时融合了KF和AdaBoost算法的优点,预测精度最高,比其他3种模型更适用于矿区地表沉降的预测。
2)实验2中,将原始数据根据开采深度分为2组进行对比。结果表明,在采深跨度接近时,本文融合预测模型更适用于大采深区域。
3)值得注意的是,AdaBoost-KF-BP模型在3号预测样本的精度较差,相较于BP模型提升不大,造成这种现象的原因需进行更深入的研究。
猜你喜欢
河北大学学报(自然科学版)(2022年3期)2022-06-16 01:30:10
矿产勘查(2020年6期)2020-12-25 02:42:12
矿产勘查(2020年5期)2020-12-25 02:39:06
矿产勘查(2020年5期)2020-12-19 18:25:11
矿产勘查(2020年5期)2020-12-19 18:25:11
科技创新与应用(2020年6期)2020-02-29 10:39:27
辽宁工业大学学报(自然科学版)(2020年1期)2020-01-07 01:09:48
北京理工大学学报(2016年6期)2016-11-22 11:17:22
电视技术(2016年9期)2016-10-17 09:13:41
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
