
基于高光谱数据和雷达融合的滑坡信息提取
2023-02-28 08:47:56李小来李海涛杨世强徐海章
长江科学院院报 2023年1期
李小来,李海涛,杨世强,徐海章,王 庆
(1.国网湖北省电力有限公司 检修公司,湖北 宜昌 443300; 2.长江大学 地球科学学院,武汉 430100)
1 研究背景
滑坡作为一种常见且频繁发生的地质灾害,对世界各地的自然环境、物质资源以及人类自身的安全造成了严重的破坏。近年来,滑坡灾害范围不断扩大,例如,从2013年到2017年,贵州省有超过200个人因滑坡灾害而失去生命。引发滑坡灾害的因素有很多,例如地震震动、强降雨和人类活动,以及岩石、土壤或土壤岩石组合物向下和向外运动等。随着遥感技术的飞速发展,利用高光谱图像检测滑坡得到了更多的关注。基于遥感数据的各种研究在滑坡监测、检测、潜在滑坡预测和减灾方面得到了广泛应用。
基于高光谱影像(Hyperspectral Image,HSI)的各种研究,是将滑坡检测作为一个图像处理问题,使用统计和机器学习方法进行处理。统计方法有模糊逻辑、逻辑回归、层次分析法、证据置信函数、加权线性组合方法、多元统计分析和模糊代数算子等;机器学习方法有支持向量机、随机森林、人工神经网络等,作为当前机器学习方法的主流,卷积神经网络(Convolutional Neural Networks,CNN)更是得到了充分的发展。利用遥感图像检测滑坡的性能在很大程度上取决于先进的机器学习方法。目前,凭借通过一系列卷积实现的强大表征学习能力,使得卷积神经网络在各种基于图像的任务中超越了经验特征的设计方法,包括图像分类、物体检测和语义分割。然而,为滑坡检测而设计的基于CNN的方法才刚刚开始,并且只有少数人研究。Ding等[1]使用CNN提取滑坡前图像和滑坡后图像的特征,计算两个特征向量之间的欧几里德距离,从而识别是否发生了滑坡灾害。Ghorbanzadeh等[2]分析了不同卷积层数、不同batchsize和输入数据通道对滑坡检测的影响。这些研究都采用了非常简单的网络架构,即一系列卷积层、池化层、全连接层,来检测滑坡。在未来的工作中,开发更复杂和特定的CNN架构以从复杂背景中提取滑坡区域的独特表示至关重要。
HSI能够用更精确的方法来描绘地物,但是其中却存在着异物同谱、同谱异物的现象,不利于地物的分类。雷达数据能够直接获取地物拓扑信息,从而可以构建地面3D模型,但激光雷达(Light Detection And Ranging,LiDAR)数据不能准确地识别地物[3]。
LiDAR与高光谱数据的特征融合,不仅可以保存丰富的高光谱光谱信息,还可以保存雷达数据准确的三位高度和强度信息,实现了两种数据的互补,利于地物的目视判读和计算机解译。因此组合使用不同滑坡监测技术对滑坡演变过程及特征进行分析是大势所趋[4]。
现在,通过遥感影像来提取滑坡、构建模型,大多是在多光谱的纹理、形状、颜色等浅层特征基础上进行的[5]。当目标区发生滑坡灾害时,若遥感影像特征不够明显,将极大影响滑坡提取的精度。随着传感器平台的不断发展,获取多源传感器、多角度、多时相的遥感数据变得越来越容易,更多的学者开始采用遥感数据融合处理的方法来解决问题。徐苗苗[6]针对高光谱和机载LiDAR融合的数据,采用分层融合残差网络分类算法,逐级对样本特征进行提取,实现了层间互补信息的融合。试验结果表明,与仅使用高光谱分类相比,融合数据提高了各种物体的分类精度和整体分类精度。李波[7]使用融合点云伪波形特征和高光谱的方法对空间特征进行提取,之后通过一组LiDAR点云和高光谱对该方法进行验证。试验结果表明,在面向对象决策级融合分类试验中,高程辅助分割方法的分类准确率达到94.05%,远远高于基于频谱的分割方法。张蒙蒙[8]以多种传感器采集的遥感影像为研究数据源,对收集的影像按照预处理、提取特征、分类器设计三个总体设计路线进行分类试验。试验结果充分证明了基于多态输入的空间光谱间信息提取是非常可取的。
考虑到多源遥感影像数据以及需要利用遥感数据进行滑坡检测的高级算法,本研究采用无人机航拍湖北宜昌部分地区的高光谱遥感影像和LiDAR数据作为数据源,并将高光谱遥感影像数据参量和机载LiDAR数据参量进行了融合,再对处理后的遥感影像数据进行信息提取,探索出一种分类精度最高方法。
2 关键技术
2.1 技术路线
本文的主要研究过程如下:
(1)LiDAR数据处理。点云数据去噪、过滤,将地面点与非地面点分开,生成数字高程模型(Digital Elevation Model,DEM)和数字表面模型(Digital Surface Model,DSM),并利用公式得到归一化数字表面模型(normalized Digital Surface Model,nDSM)[9-10]。
(2)高光谱数据的处理通常使用大气校正(Atmospheric Correction)、变换分析等方法,如主成分分析(Principal Component Analysis,PCA)和生成归一化植被指数(Normalized Different Vegetation Index, NDVI)。
(3)对高光谱数据参数与LiDAR数据参数进行融合,采用深度学习方法,结合CBAM(Convolutional Block Attention Modale),对生成的数据进行信息提取。
(4)选择用户精度 (User’s Accuracy,UA)、制图精度 (Producer’s Accuracy,PA)、Kappa系数来评价分类结果。
技术流程如图1所示。

图1 技术流程Fig.1 Technical roadmap
2.2 机载雷达数据和高光谱数据处理
无人机将激光点云数据和HSI数据通过数据传输单元和通信单元传输到地面站的中控系统后,用户需对激光点云数据和HSI数据分别进行处理。
2.2.1 LiDAR数据
LiDAR数据处理主要分为预处理和后处理,预处理包括数据的精确解算和点云转换等,主要由数据提供方完成。用户直接获取点云产品,并根据需要对LiDAR数据进行后处理。
点云产品的加工主要包括以下几点:数据的去噪和过滤;分离地面和非地面点,生成DEM和DSM,并由此生成nDSM[11],其步骤如下:
(1)点云数据去噪。由于机载LiDAR数据在采集过程中是随机的,因此会在数据源中产生大量噪声,例如飞鸟、物体在光滑表面引起的镜面反射、非常高或非常低的点等。这些噪声需要去除,因为它们会影响基础结果并显著降低准确性。
(2)点云数据滤波处理。滤波处理过程使用多种算法将航空LiDAR数据中的地面点与非地面点分开,再通过处理获取DEM和DSM。
(3)获得nDSM。nDSM是DEM和DSM的差,是相对于海拔高度的视觉表示。nDSM的地面灰度值为0,其余为其他特征信息,包括建筑和植被的高度信息。
2.2.2 高光谱数据
高光谱数据处理步骤如下:
(1)大气校正。大气校正可以准确得到目标物体数据的真实反射率,消除大气和辐射参数引起的各种误差。
(2)归一化处理。归一化处理是特征向量表达时的重要步骤,该操作可以把需要的数据经过处理后限制在一定范围内。其作用是消除数据量纲的影响,使数据指标之间具有可比性,便于模型的建立。
(3)主成分分析变换。主成分分析是对高光谱遥感影像进行数据压缩和信息融合的手段,它能够消除高光谱遥感影像中之间的相关性,在尽量不丢失信息的前提下,进行数据压缩和描述。
(4)生成归一化植被指数。归一化植被指数是表示土地覆盖植被状况的一种遥感指标。它以非线性拉伸的方式增强近红外波段(Near Infrared, NIR)[12]和红光波段R反射率的对比度。NDVI是植被覆盖度以及植被生长状态的最佳指示参数[13]。虽然NDVI增强了植被部分的监测,但是NDVI对高植被区域具有较低的敏感性。
2.3 基于LiDAR和HSI数据的滑坡信息提取
对高光谱数据的参数和LiDAR数据的参数进行融合,再对生成的数据进行信息提取。本研究采用深度学习的方法,结合Convolutional Block Attention Module(CBAM),对融合后的数据进行信息提取。利用CNN的特点,从深度训练的神经网络中提取出相应的多级空间元素集,建立一个从几何、颜色特征等对象语义识别的多层次滑坡模型[14]。
CBAM是一种高效的注意力模型,它同时使用通道和空间进行反馈。CBAM的模型网络结构如图2所示。

图2 CBAM模型网络结构Fig.2 Network structure of CBAM model
CBAM模型有两个子模块,一个是通道注意力模块(Channel Attention,CA),另一个是空间注意力模块(Spatial Attention,SA)。CBAM的输入层为经过CNN卷积层后,提取得到的特征图,然后将该特征图通过每个子模块生成一个注意力特征,再和原来的特征图进行一个通道或者空间上的相乘,公式为
F′=Mc(F)⊗F;
(1)
F″=Ms(F′)⊗F′ 。
(2)
式中:⊗表示克罗内克积;F为卷板提取的特征;F′和F″分别表示经过通道注意力校正的特征和经过空间注意力校正的特征;Mc和Ms分别表示通道注意力和空间注意力。
2.3.1 CA模块
此模块的输入是通过CNN卷积网络提取特征得到的特征图,记录为输入特征图。然后特征图在空间上经过最大池化处理和平均池化处理2个过程,得到2个处理后的一维向量Vmax和Vavg。然后通过权重共享多层感知器 (Multiple Layer Perceptron,MLP)传递这2个一维向量,分别得到向量VMLP-max和VMLP-avg。然后将2个向量进行逐个像素相加,最后通过激活函数获得最终CA模块的注意力向量。 具体操作流程如图3所示,计算公式为
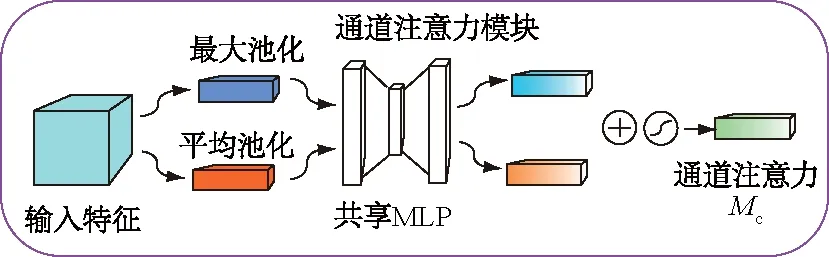
图3 通道注意力模块示意图Fig.3 Schematic diagram of channel attention module
Mc(F)=σ(MLP(AvgPool(F))+
MLP(MaxPool(F))) 。
(3)
式中:Mc表示通道注意力;F为卷积提取的特征;MLP为多层感知器;AvgPool为平均池化层;σ为激活函数。
2.3.2 注意力模块
其具体操作流程如图4所示。
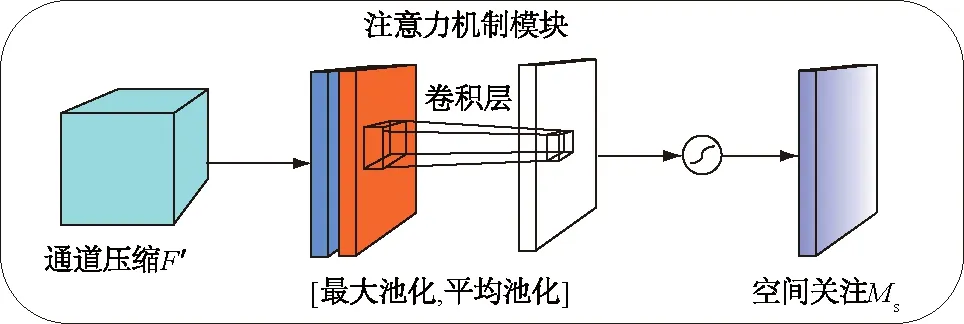
图4 空间注意力模块示意图Fig.4 Schematic diagram of spatial attention modulel
该模块的输入也是卷积网络提取特征得到的特征图或CA模块处理后得到的特征图记录,为输入特征矩阵。特征图在空间上经过最大池化处理和平均池化处理2个过程,分别得到2个处理后的特征图Fmax和Favg。然后根据通道的维度将两个特征图进行连接,最终得到通道数为2的特征图,再对该特征图进行卷积操作。卷积层是只包含一个卷积核的隐藏层。最终通过激活函数得到最终的SA注意力特征图。其计算公式为
Ms(F)=σ(f7*7([AvgPool(F);MaxPool(F)])) 。
(4)
式中:Ms为空间注意力;f7*7即卷积核大小为7*7; AvgPool为平均池化层,Maxpool为最大池化层;σ为激活函数。
3 试验过程
3.1 数据准备
本文试验数据位于宜昌市夷陵区某区域,分别获取该区域的LiDAR数据和高光谱数据,如图5所示。

图5 试验区域示意图Fig.5 Map of the study area in Yichang
因需对试验区域的滑坡信息进行特征提取,即需要对该地进行地物分类,根据实地调查和高分影像数据结果,试验区域地类分布主要有4种,分别为:滑坡、植被、道路和裸土,因此将此4类作为本次试验的样本数据,并分为训练样本和验证样本。其中,样本以选择的像元为中心,32×32邻域大小范围作为模型的输入,不是传统单像元作为输入。为了保证最后的精度评价,训练样本和验证样本无重叠。其中样本数量如表1所示。
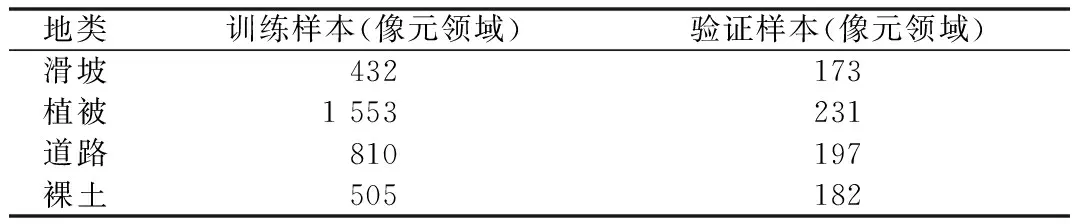
表1 试验区样本数量Table 1 Number of samples in the study area
3.2 数据处理
本文使用的HSI共有144个波段,因HSI和LiDAR点云数据均有噪声的存在,需对其进行降维处理,之后再进行数据融合。
3.2.1 机载LiDAR数据处理
原始LiDAR数据存在很多噪声,需要对其去噪、滤波、生成nDSM等处理才能使用,具体处理步骤如下:
(1)点云数据去噪。通过设置领域点个数、遵从3σ原则[即数值分布在(μ-3σ,μ+3σ)之间,其中σ表示标准差,μ代表均值],来执行去噪过程。经过去噪处理后,原始LiDAR数据去除了部分干扰,变得更加准确,使得滑坡信息提取更加方便。
(2)点云数据滤波处理。使用ArcGIS软件将LiDAR点云数据的地面点与非地面点分开。
(3)生成nDSM。由于机载LiDAR数据是点云数据,无法直接与高光谱数据进行融合,因此,需要将LiDAR数据转换为栅格数据。主要通过插值法得到DEM和DSM,并使用栅格计算器得到nDSM。
LiDAR数据的栅格化过程如下:
(1)采用基于不规则三角网(Triangulated Irregular Network,TIN)的渐进加密滤波算法,使LiDAR点云数据生成DEM。基于不规则三角网的渐进加密滤波算法,首先将原始LiDAR点云数据以一定大小的网格进行划分,在每个网格中选择高程最低的点作为种子点,并使用这些种子点生成一个稀疏的TIN,然后依次读取剩余激光脚点,计算该点到TIN的距离和角度等参数,若在规定的阈值范围内,则将该激光点纳入地面点集合,否则标记为非地面点,在迭代过程中三角网不断加密,直至对所有激光点完成判别。
(2)选择TIN插值方法对原始点云数据首次回波插值,生成DSM。DSM不仅反映了地面高程信息,还能反映地表建筑、植被、桥梁等地物的高程信息。
(3)利用得到的DEM与DSM相减,生成反映去除了地势起伏影响的地面要素的相对高程信息的图像,称为nDSM,如图6所示。

图6 已转换的nDSM 数据Fig.6 Converted nDSM data
3.2.2 高光谱数据预处理
将高光谱数据输入软件ENVI 5.1中,并对其进行大气校正模块的处理与运算,经过最小噪声分离特征变化后,高光谱数据为3个波段。
3.2.3 高光谱数据的变换分析
分别提取出每幅影像的特征是数据融合的基础,提取后通过多种方式融合这些特征,以达到预期的效果。
对高光谱数据进行变换分析,得到融合所需的各种图像特征参数。
(1)PCA特征生成。将预处理后的高光谱数据进行归一化处理,如式(5)所示。
Xnorm=(X-Xmin)/(Xmax-Xmin) 。
(5)
式中:Xnorm为归一化结果;Xmax为样本最大值;Xmin为样本最小值。再对归一化结果进行主成分分析(Principal Component Analysis,PCA),提取包含主要空间信息的成分。输出的PCA图像结果如图7所示。

图7 主成分分析图像Fig.7 Pincipal component analysis image
(2)NDVI生成。NDVI一般是用来表示植被的覆盖程度,如式(6)所示。它是通过非线性拉伸来提高近红外波段占比(植被在近红外波段有很强的反射能力,在可见光波段有很强的吸收能力)。
(6)
其中,近红外波段的反射值表示为NIR,红光波段的反射值表示为R。通常来说,NDVI的范围是[0,1],植被区的NDVI的范围通常是[0.2,0.8]。本文使用高光谱图像的第92波段(NIR)和第67波段(R)来计算NDVI。图8显示了NDVI图像。其中,植被区为高亮区域,滑坡区较暗。

图8 NDVI图像Fig.8 NDVI image
3.2.4 LiDAR图像与高光谱图像的配准
由于LiDAR影像和高光谱数据获取时间不同,所以在数据融合之前需要配准,即需要使相同地物可以重叠。
将nDSM作为参考影像,HSI生成的PCA和NDVI作为校正影像,通过ENVI的Image Registration Workflow,选择Mutual Information,对其进行配准。试验共选取了43个控制点进行误差计算。将误差较大的控制点删除或重新选择并微调,直到总的中误差(Root Mean Square,RMS)值变小,不超过1个像素。
具体配准过程分为3个步骤:选择控制点、建立映射关系和重采样。
(1)选择控制点。在图像配准中,首先在图像中选择要配准的控制点。所选择的控制点分布必须均匀,以满足配准精度要求。因试验区域较大,所以在综合PCA和NDVI与nDSM后,随机选取地面特征较为明显的控制点(如道路、山脉等)。
(2)建立映射关系。确定控制点对后,使用最小二乘法建立两幅图像之间的线性映射关系。所使用的二阶映射公式如式(7)、式(8)所示:
x=a0+a1i+a2j+a3ij+a4i2+a5j2,
(7)
y=b0+b1i+b2j+b3ij+b4i2+b5j2。
(8)
式中:(i,j)为参考图像的坐标;(x,y)为待校正图像的坐标;ak和bk(k=0,1,2,3,4,5)为线性映射的系数。
(3)重采样。将参考图像的像素坐标值映射到待校正图像坐标系的坐标值上,从待校正图像中选取最接近该坐标值的灰度值作为像素灰度值。
3.2.5 基于机载LiDAR和高光谱数据的融合
高光谱数据丰富的光谱信息和LiDAR数据独特的高程信息在滑坡信息的提取中起着非常重要的作用。对高光谱数据的PCA和NDVI与LiDAR数据nDSM融合成一个数据集。
3.3 滑坡信息提取
CNN对图像空间特征具有非常好的提取能力,并且提取的特征具有旋转、平移和缩放的不变性。在大规模图像识别领域,深度学习将CNN逐层叠加,通过特征组合获取高级抽象特征,从而提高识别精度。
从研究区的影像分析来看,将图像分为道路、植被、滑坡、裸土四部分进行信息提取。本文通过综合利用滑坡光谱信息和高程信息,用深度学习方法,结合CBAM,从融合数据中提取滑坡信息。图9显示了信息提取的结果。

4 精度评价
为了验证CBAM法对滑坡的提取效果,试验对比了传统方法,如:光谱角(Spectral Angle Mapper ,SAM)、光谱信息散度(Spectral Information Divergence,SID)法和支持向量机(Support Vector Machines,SVM)法。 试验结果如图10所示。
从图10中可以看出,传统方法的检测结果比结合CBAM的CNN的结果更加碎片化。灾害提取中的斑块碎片现象会导致信息混乱和错误,减灾救灾部门通常使用数量和面积信息作为判别滑坡灾害信息的依据。因此,结合CBAM的CNN在满足实际需求方面具有多种优势。

图10 不同方法对滑坡的提取结果Fig.10 Results of landslide information extracted by different methods
为了验证本方法的有效性质,试验从UA、PA、Kappa系数等常规遥感影像分类验证指标来评估不同分类方法的检测精度。

表2 不同分类方法的精度分析结果Table 2 Accuracy analysis results by different classification methods
试验结果表明,在分类精度方面,结合CBAM的CNN与方法各类精度均可达到90%以上,与传统方法相比具有明显优势。
5 结 论
本文选取一种有效的方法,利用高光谱数据参数和LiDAR数据参数进行融合,并对融合后数据进行信息提取。主要结论如下:
(1)与遥感监测滑坡变化相比,航拍数据采集所需的成本较高,但其精度、空间分辨率高,采集时间和采集方式灵活,所以较适用于灾害应急响应监测。与此同时,如果能够获得数据的时间序列,就可以提取出高精度的滑坡动态变化信息。
(2)研究发现,HSI+LiDAR组合具有较高的分类准确率。下一步将继续关注高光谱和LiDAR数据的融合分类,注意将集成学习方法引入对二者融合特征的分类中,进一步研究提高分类精度的有效框架。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:58:58
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
河北地质(2021年1期)2021-07-21 08:16:08
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
北方交通(2016年12期)2017-01-15 13:52:59
水利科技与经济(2016年6期)2016-04-22 05:07:30
山东青年(2016年3期)2016-02-28 14:25:50
中国光学(2015年5期)2015-12-09 09:00:28
食品工业科技(2014年23期)2014-03-11 18:18:54
