
基于国产化边缘计算设备的警用机器人视频结构化应用
2023-02-26 13:06:50公安部第一研究所孟博
中国安全防范技术与应用 2023年4期
■ 文/ 公安部第一研究所 孟博
关键字:边缘计算 模型 机器人
1 引言
人工智能技术在安防领域的应用越来越广泛。随着视频结构化分析、语音识别和智能翻译等人工智能技术的引入,智慧安防已经能够精确管控人、车、物,将传统安防的事后处理变为智慧安防的实时与主动预警,并实现应急联动处置。2023年1月,工信部等十七部委联合印发了《“机器人+”应用行动实施方案》,其中明确提出推动机器人在安保巡逻、缉私安检、反恐防暴、勘查取证、交通边防、治安管控、特战处置、服务管理等社会安全场景的应用。
边缘计算(Edge Computing)是相对云计算(Cloud Computing)而言的一种新兴计算模式[1]。随着物联网特别是智能物联网(AIoT)的发展,各种新型智能设备不断涌现,产生了海量的数据。全球安防摄像头每年产生超过10 的17 次方量级的图片和视频流。如果把这些视频数据都传输到云中心上进行处理,将会消耗大量的网络带宽资源和计算资源。相比之下,边缘计算可以在前端对这些数据进行就地处理,大大降低了数据传输量,减轻了云中心的计算压力,提高了计算效率。
边缘计算在智慧警务场景下有较广泛的应用价值和市场。一般来说,派出所或警务站点分布分散,如果将视频数据传输至中心节点统一处理,不但对网络带宽需求大,而且实时性较差。同时,警务场景的智能分析需求也是相对变化的,需要灵活配置分析的视频源,算法和业务逻辑。通过基于边缘计算的视频结构化技术,可以轻松应对这些变化的需求,同时将监控视频中有价值的信息提取出来,上报到上一级部门做进一步的综合应用。
边缘计算也是AI 国产化较好突破的一个重要方向,相对通用GPU 或AI 推理芯片,边侧AI 芯片的只负责推理,算力较小,芯片的研发难度较低;此外,边缘计算在AI 算法落地上较容易,能做到场景、算法封闭,软硬一体快速交付,具有易推广,高性价比等特点。
边缘计算设备搭载在警用机器人上,通过部署图像,视频和语言等领域的人工智能算法赋予警用机器人更多的智能化功能,提高异常事件响应的实时性,且可将结构化信息和数据上传到云平台做数据的综合治理和应用,降低视频传输对网络带宽造成的压力,进一步优化和提升人机协同作业模式。通过数据驱动、科技集约、精准发力,为警务工作提供更强战斗力,运用科技力量来防范化解风险。
2 基于小站Atlas 500 的警用机器人视频结构化方案
Atlas 500[2]智能小站是面向广泛边缘应用场景的轻量边缘设备,具有较强计算性能、大容量存储、配置灵活、体积小、支持温度范围宽、环境适应性强、易于维护管理等特点。Atlas 500 智能小站依托于昇腾AI 处理器,可为多种边缘计算的图像、视频智能分析场景打造基础AI 计算平台,增强边缘侧图像、视频分析的实时性,降低对网络带宽的依赖度,并可不断升级算法来提升应用体验。
由于它体积小、环境适应性强、配置灵活,而且具有较强计算性能和可扩展的大容量存储,再加上便于管理维护的优点,因此满足了在智慧城市、各类机房、交通、商场、园区等区域的应用需求,被广泛用于数据存储、分析以及智能视频监控等方面。
2.1 环境与数据准备
本文方案对cuda 框架和Python 有详细的版本要求,详情如表1 所示(“——”)表示没有具体要求。本方案需要安装10.2 版本的cuda 框架和3.5 版本及以上的Python。

工具 版本Python v3.6 及以上cuda v10.2 Anaconda/miniconda ——git ——
本文使用的Objects365 数据集是由北京智源人工智能研究院与旷视科技于2019 年共同推出的一项基准数据集,旨在促进计算机视觉领域中的目标检测研究。Objects365 在180 万余张图像上标注了365 个对象类,包含人、衣物、居室、浴室、厨房、办公/医疗、电器、交通、食物 、动物、运动/乐器等。训练集中有超过2900 万个边界框,超越了Pascal VOC、ImageNet 和COCO 数据集。数据集示例图片如图1 所示。

图1 数据集示例

图2 YOLOv5 算法性能测试图[3]
图6 准备文件列表
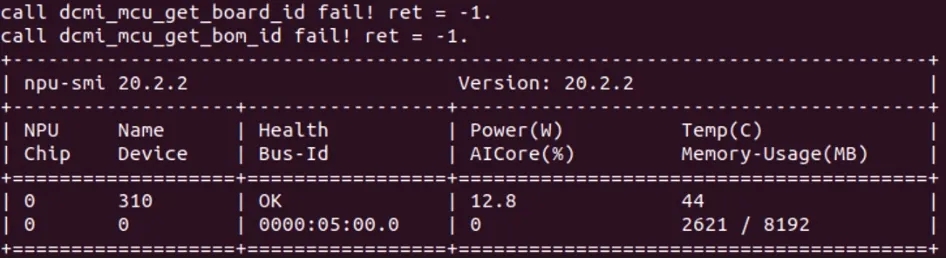
图7 npu 信息
2.2 模型选择与训练
目标检测是计算机视觉领域中一项重要的任务,其目标是检测出图像中物体的类别并将其定位。随着卷积神经网络的兴起,基于深度学习方法的目标检测进入了新的阶段。主要的技术发展路线有anchor—based和anchor—free 系 列 方 法,anchor—based 方 法 包 括 一阶段和两阶段检测算法。两阶段检测算法精度更高,如Faster—RCNN 系列,但是一阶段算法计算速度更快,如YOLO、SSD 等。
YOLO(You Only Look Once)系列模型是经典的一阶段算法,在精度满足要求的同时,保证了模型的速度,使得实时目标检测得以广泛应用。Ultralytics 团队提出了YOLOv5,由于其速度更快、精度更高、体积更小等优点,成为世界上最受欢迎的视觉AI 模型。综合考虑部署场景检测实时性、高召回、低误检要求,本文选择YOLOv5 作为检测模型。YOLOv5 共有4 个版本可供选择:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x。其中,s、m、l、x 分别代表模型大小,模型越大,精度越高,速度越慢。下图是YOLOv5 的算法性能测试图。
2.2.1 深度学习目标检测模型YOLOv5 算法介绍
YOLOv5 的网络结构由输入端、 主干网络(Backbone)、连接层(Neck)和输出端(Prediction)四个部分组成。
2.2.1.1
YOLOv5 输入端主要完成了数据增强、自适应锚框计算和自适应图片缩放工作。
数据增强方法:通过对四张输入图像的随机缩放、裁剪以及随机排布方式将其拼接成一张,这种数据增强方法既丰富了检测背景又提高了模型对小目标的检测能力。
自适应锚框计算:YOLOv5 在训练时集成了K—means方法来获取不同训练数据集中的最佳锚框值,此功能也可以关闭。
自适应图片缩放:在目标检测任务中,输入图像的尺寸通常需要被统一,以便模型可以批量处理。然而,不同尺寸的图像如果直接缩放到相同的尺寸,往往需要在图像的周围填充一些额外的像素,这些填充的像素通常为黑色,即所谓的“黑边”。如果填充过多,不仅会增加计算量,还会引入一些冗余的信息,影响模型处理的效率。YOLOv5 通过自适应图片缩放技术,优化了这一过程。它可以根据输入图像的原始尺寸,智能地添加最少的黑边,使得图像在高度方向上的两端黑边减少,从而减少了信息的冗余和计算量的浪费。
2.2.1.2
Focus 结构:主要是对图像进行切片操作,如下图所示,将4×4×3 的图像切片成2×2×12 的特征图。
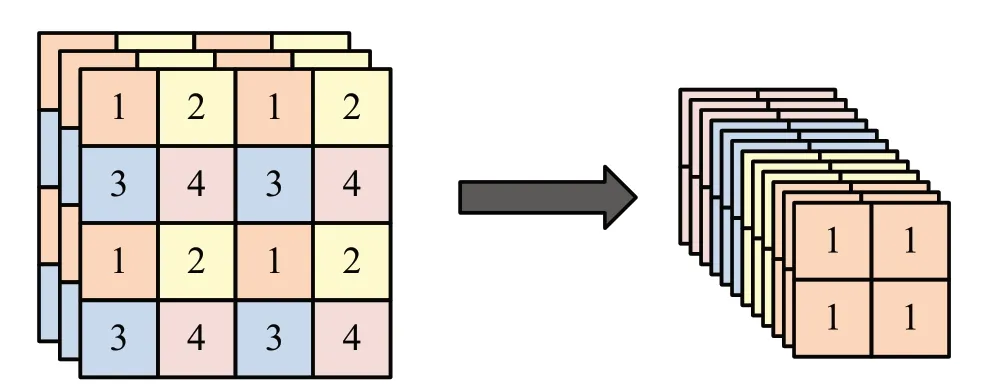
以YOLOv5s 为 例, 尺 度 为640×640×3 的 输 入图像经过Focus 结构首先进行切片操作得到尺度为320×320×12 的特征图,再进行一次卷积核数为32 的卷积操作,得到的特征图尺度为320×320×32。
CSP 结构:YOLOv5 中设计了两种CSP 结构,以YOLOv5s 网络为例,CSP1_X 结构应用于主干网络中,另一种CSP2_X 结构则应用于连接层中。
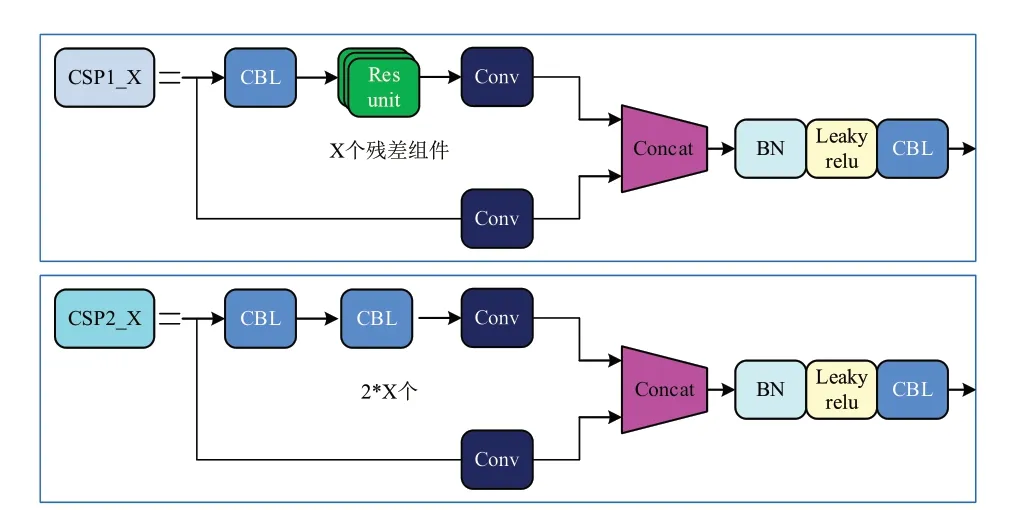
2.2.1.3
网络连接层用于连接主干网络与头部,采用FPN+PAN 的结构进行特征融合。
FPN 结构将语义特征从上而下传递,PAN 结构接在FPN 之后,从下而上将定位特征传递上去,这样可得到了既含有丰富语义又含有定位信息的特征。
2.2.1.4
损失函数:采用CIoU_loss 作为损失函数,定义如下:
非极大值抑制(NMS):基于锚框的检测方法对于同一目标会产生大量冗余的候选框,我们需要利用非极大值抑制的方法消除冗余,筛选出最佳的目标边界框,公式如下:
2.2.2 模型训练
训练数据经过数据增强、灰度填充操作形成尺度统一、信息丰富的输入图像,再经过主干网络提取图像特征,得到的特征经过连接层的处理将语义和定位信息融合,最后经过检测头得到损失,进行反向传播。
训练过程在8 卡NVIDIA TITAN 24G 服务器上完成,epoch 设为200,batch—size 设为32,其余超参默认。
3 训练模型部署

模型训练完成后,可以将训练模型在Atlas 500 上对视频流进行推理检测工作,工作流程如图5 所示,首先在Ubuntu 系统中安装CANN—toolkit,包括安装工具包、下载CANN 软件包、准备用户并安装和配置环境变量。第二步是模型转换,主要是将训练得到的权重文件格式转换为om 模型。之后的操作便在Atlas 500 上进行,包括Atlas 500 固件升级、构建docker 镜像等。在完成了上述准备工作后,便可配置CANN—nnrt 和运行环境,执行detect脚本程序开始视频流的检测结构化工作。详细流程介绍如下。
3.1 在Ubuntu 服务器上安装CANN-toolkit
参考“技术支持—文档中心”中的《CANN 5.0.x 软件安装指南》等文档。
(1)安装anaconda 或miniconda,并创建虚拟环境。命令如下:
conda create —n atc_yolov5 python=3.7 # ascend—deployer 要求python 版本>=3.6
(2)安装git 和安装YOLOv5 所需的第三方库,如pytorch 等。
(3)获取ascend—deployer 工具
安装后“主目录”下会出现一个“ascend—deployer”文件夹(完整路径为“/home//ascend—deployer”)。
(4)下载CANN 软件包
在 官 网 下 载“Ascend—cann—toolkit_5.0.3.7_linux—x86_64.zip”、人工验证签名pgp、自动验证签名cms(需要下载权限)或者使用命令:
ascend—download ——os—list=Ubuntu_18.04_x86_64——download=CANN
(5)准备运行用户并安装,命令如下:
groupadd HwHiAiUser # 新建用户组HwHiAiUser
adduser {username} HwHiAiUser
cd ~/ascend—deployer
./install.sh ——install=toolkit
安装完成的toolkit 在“~/Ascend/ascend—toolkit”路径下。
(6)配置环境变量,配置前请确认set_env.sh 中的toolkit 的路径是否正确,如与安装路径不匹配,则需要修改。
# 安装toolkit 后配置
.~/Ascend/ascend—toolkit/set_env.sh
# 或者把set_env.sh 的内容添加到~/.bashrc 中
# 然后运行source ~/.bashrc
3.2 Ubuntu 服务器上进行模型转换
(1)安装onnx
conda activate atc_yolov5
conda install onnx
pip install onnx—simplifier
(2)利用ATC 工具转换为om 模型。生成的.om 文件在yolov5 根目录下。
3.3 Atlas500 固件升级
主要参考Atlas 500 智能边缘管理系统 (V2.2.200.010版本至21.0.2 版本),下载固件升级包“A500—3000_A500—3010—ESP—FIRMWARE—V2.2.209.020.zip”,浏览器访问Atlas500,选择“维护— 固件升级— 系统固件升级” ,上传固件升级包,升级,等待升级进度100%,重启生效。
3.4 在Atlas 500 上构建docker 镜像
(1)在Ubuntu 服务器上准备YOLOv5—image 文件
1)将以下文件放置到yolov5—image 文件夹下。其中下载Ascend—cann—nnrt_5.0.3.7_linux—aarch64.run 需要权限。
2)创建Dockerfile。
3)将“3.2 模型转换”的“yolov5”文件夹去除无用文件并打包。
4)创建install.sh。
#!/bin/bash
#进入容器工作目录
cd /root
#解压业务推理程序压缩包
tar xf dist.tar
5)创建run.sh。
#!/bin/bash
#进入业务推理程序的可执行文件所在目录
cd /root/dist
#运行可执行文件
#./main
python3./detect.py
(2)将上述文件复制到Atlas 500 上
1) 浏 览 器 访 问Atlas 500, 新 建 分 区 为“/opt/mount/docker01”。
2)在Ubuntu 服务器(非昇腾设备)上,通过scp命令,将yolov5—image 文件夹完整传输到Atlas 500 的/opt/mount/docker01 路径下。命令如下:
# 访问yolov5—image 文件夹的上层目录
s c p —r./y o l o v 5—i m a g e/vision@172.23.0.111:/opt/mount/docker01/
(3)ssh 远程Atlas 500
1)在Ubuntu 服务器(非昇腾设备)上,ssh 远程访问Atlas 500。登录后,需要通过timeout 0 和TMOUT=0 重置超时时间,否则超时后,会话会自动关闭,退出操作窗口。
2)查看npu 信息。
npu—smi info
其中的 NPU Chip 代表 NPU 芯片,这里的device id为 0 ,Name Device 为 310 ,代表Ascend 310 。Health Bus—Id 为 OK ,则说明正常可以使用。
(4)在Atlas 500 上制作镜像
1)查看docker 版本和现有镜像。
2)构建docker 镜像。
3.5 YOLOv5 在docker 容器中检测视频流— —Atlas 500
具体流程如下:
(1)启动docker 容器
(2)配置CANN—nnrt
(3)查看npu 是否可用
(4)配置代码运行环境
(5)改写detect.py 文件并运行
4 模型推理
在完成上述模型训练以及边缘计算设备部署后,可以开始对视频流进行测试,这里使用验证集或测试集数据进行推理分析,可视化预测结果如图8 所示,画面中人、海鸥、建筑等物体均可使用不同颜色的目标框进行标识,实现了图像中人、物等目标的提取,为进一步开展视频结构化提供了基础。

图8 模型推理结果示意
5 结语
综上所述,基于国产边缘计算设备Atlas 500 的视频结构化研究,可以使机器人具备前端智能,为机器人赋予“小脑”,实时分析前端探测设备采集数据,提高机器人对异常行为异常事件的响应处置能力,解决警用机器人实战应用的“最后一公里”,助力警用机器人的普及推广。
猜你喜欢
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
通信产业报(2016年44期)2017-03-13 08:41:45
少儿科学周刊·少年版(2015年4期)2015-07-07 21:13:44
少儿科学周刊·少年版(2015年4期)2015-07-07 21:09:31
少儿科学周刊·少年版(2015年4期)2015-07-07 21:08:08
少儿科学周刊·儿童版(2015年4期)2015-06-17 03:37:19
雕塑(1999年2期)1999-06-28 05:01:42
