
多尺度通道注意力机制的口罩佩戴检测算法
2023-02-21 12:54李丽宏
计算机工程与设计 2023年2期
李 莉,刘 阳,王 巍,耿 华,李丽宏
(河北工程大学 信息与电气工程学院,河北 邯郸 056000)
0 引 言
近年来,深度卷积神经网络在目标检测[1]领域取得了重大进展。其中YOLOv3算法凭借速度快、精度高、可实现性强等优势成为众多算法[2-5]中的佼佼者。但将YOLOv3算法直接用于某些特定场景下检测目标时,并不能满足检测要求,特别是口罩佩戴的检测,由于场景复杂、人群密集、行人占图像像素比例较小[6],是否佩戴口罩差异性小,导致检测难度大。因此,学者们相继对YOLOv3算法进行针对性改进。如文献[7]通过引入跨阶段局部网络精简特征提取网络来提升口罩检测速度,文献[8]通过扩建特征金字塔结构来提升对口罩小目标的检测精度,文献[9]通过添加浅层特征层来提高对口罩特征信息的利用率。这些通过复杂网络结构改进的YOLOv3算法虽有不错的效果,但并未解决口罩佩戴检测中遮挡、紧邻目标容易漏检的问题,尤其在密集人群场景下检测效果不佳。
本文针对以上问题,提出了基于通道注意力机制的YOLO-Mask检测算法。首先,利用多尺度通道注意力机制挖掘目标上下文关系,强调有用细节信息,抑制无效干扰信息。然后,针对数据集进行目标锚框聚类。最后,针对算法检测效果的评价标准IoU对目标物体尺度不敏感以及无法准确反映预测框与真实框重叠情况[10]的问题,以CIoU作为损失函数优化检测算法。实验结果表明,YOLO-Mask算法有效降低了遮挡、紧邻目标的漏检率,相较于SSD、Efficientdet、原始YOLOv3主流算法,检测精度更高,鲁棒性更强。
1 YOLOv3算法模型及原理
1.1 检测过程
YOLOv3算法由Joseph Redmon等提出,其网络框架包括主干特征提取网络Darknet53、特征金字塔加强网络以及预测网络YOLO Head这3部分,网络结构如图1所示。
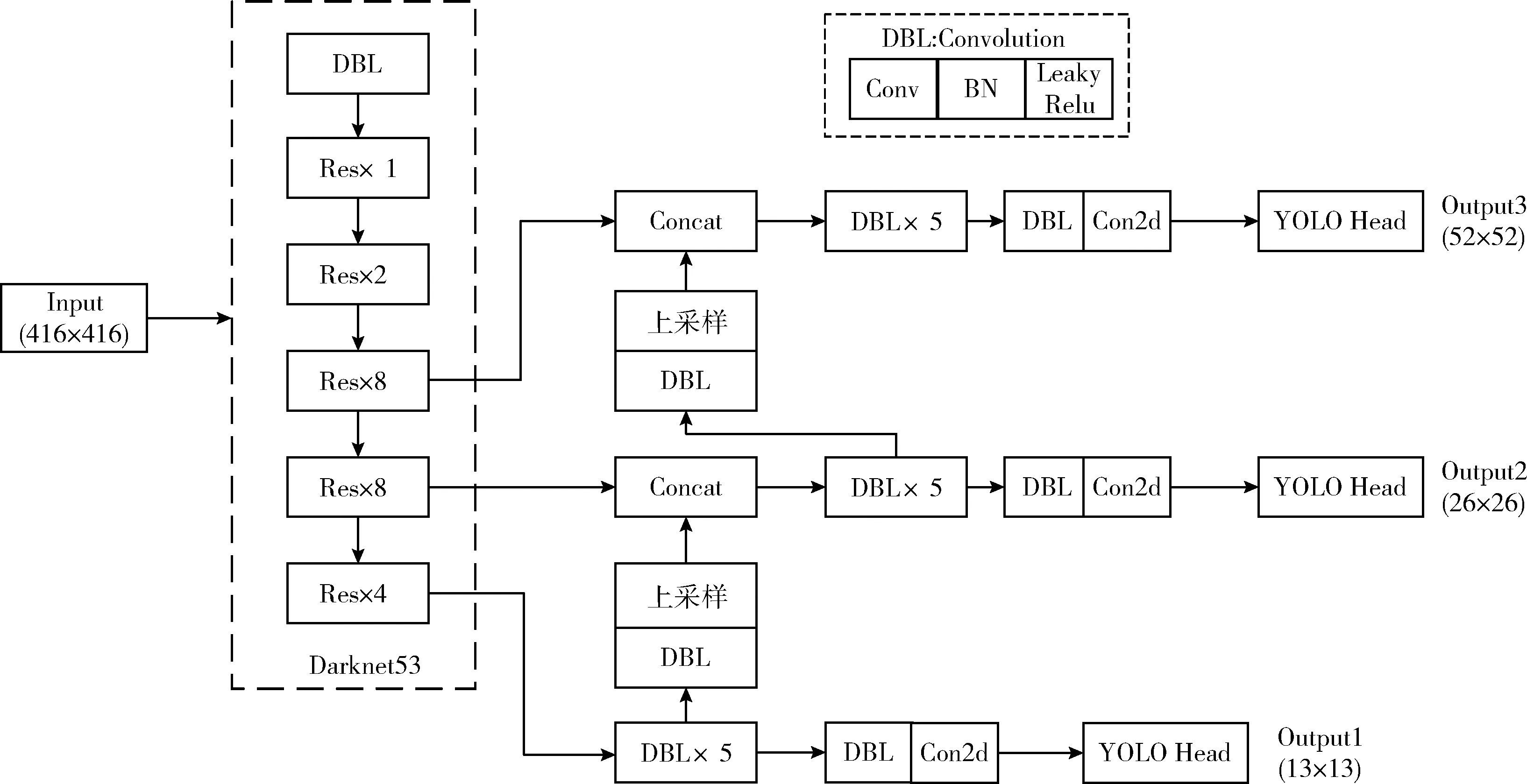
图1 YOLOv3结构
首先输入大小为416×416的图片,经过初始化后进入Darknet53中的第一个残差网络[11](Residual),通过下采样将宽和高压缩,通道数扩张,得到一个特征层,命名为layers1,Darknet53中有5个这样的残差网络,可以得到一系列包含图片特征的特征层,接着取后3个特征层进行特征加强网络的多尺度特征融合,最后利用YOLO Head得到3个尺度的预测边框,分别为13×13、26×26、52×52,用来检测大、中、小物体。以检测VOC数据集为例,输入一张416×416的图片,经过Darknet53的多层运算,取layers3、layers4、layers5用作特征金字塔的构建,最后利用YOLO Head进行特征整合和调整通道数后得到3个大小的输出层,分别为(13,13,75)、(26,26,75)、(52,52,75),其中75可以分为3×(20+1+4),3是YOLOv3针对每个特征层的特征点存在3个先验框,20代表了VOC数据集分20个类别,1代表了框内是否含有物体,4代表了预测框的调整参数:中心点坐标x,y和框的宽高W,H。 每个网格的类别置信度得分如式(1)
(1)
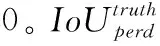
1.2 损失函数
YOLOv3的损失函数定义请参见文献[12],其Loss值计算如式(2)所示
Loss=Losscoor+Lossconf+Losscls
(2)
其中,目标定位损失Losscoor以均方误差(mean square error,MSE),即L2范数作为损失函数的目标函数。首先,计算预测框与真实框的IoU, 然后通过对预先设定的IoU阈值对预测区域进行筛选,选出IoU大于阈值的区域。
最后对筛选出来的区域,计算其对应的Losscoor值,如式(3)所示
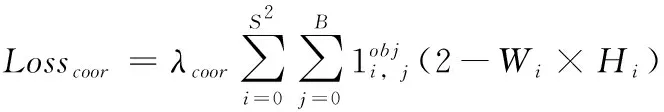
(3)
2 改进的YOLOv3算法
原始YOLOv3在多尺度目标检测上效果突出,但存在检测遮挡、紧邻目标时漏检和预测框与真实框无交集时无法优化的问题。本文从主干特征提取网络Darknet53、先验框尺寸以及损失函数3个方面对原始YOLOv3进行改进。
2.1 改进的特征提取网络
2.1.1 SENet注意力机制
视觉注意力机制是人类视觉所特有的大脑信号处理机制。当人类在浏览一张图片时,视觉首先会快速浏览扫描全局,从而获得重点关注的目标区域,即注意力焦点,然后通过对这一目标区域更加仔细识别,来获得注意力焦点中更多有效的细节信息,抑制其它无效信息。深度学习中的注意力机制(attention mechanism[13])是机器学习中的一种数据处理方法,和人类的视觉注意力机制相似,其核心也是从众多信息中选择出更关键的信息。注意力机制可以将输入的每个部分赋予不同的权重,从中选取出更加关键的信息,使模型更加关注有效信息,从而做出更加准确的识别。注意力机制分为两种:一种是软注意力(soft attention),另一种是强注意力(hard attention)。
本文采用软性通道注意力机制SENet(squeeze-and-excitation networks),主要由两部分组成:Squeeze部分和Excitation部分。SENet结构如图2所示。
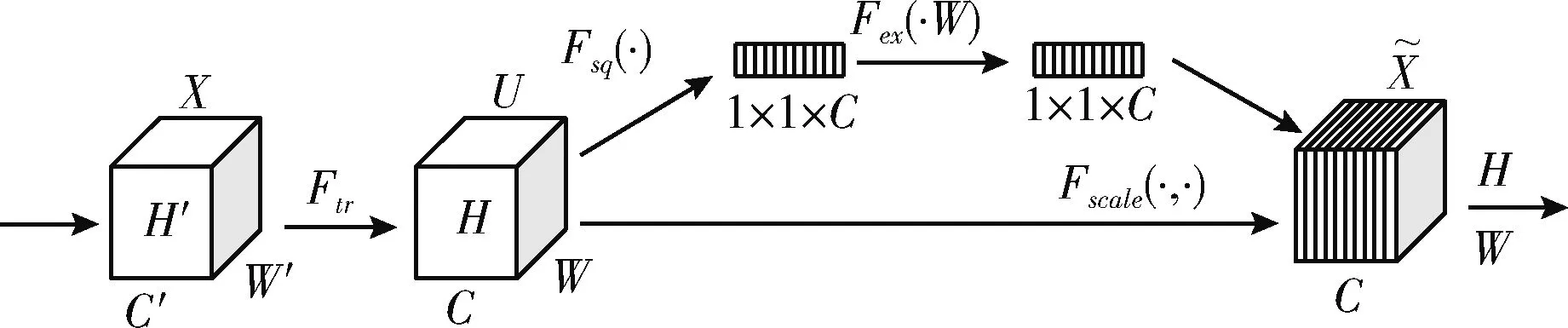
图2 SENet结构
图2中,C′个W′*H′的特征层X经过转换操作Ftr得到C个W*H的特征层U,实现过程为式(4),uc为特征U的第c个二维矩阵,vc表示第c个卷积核,Xs表示第s个输入
(4)
Squeeze操作是在得到U之后,采用全局平均池化操作对每个特征层的宽W和高H进行压缩,使其C个特征层转化为1×1×C的数列。如式(5)所示
(5)
Excitation操作用来全面捕获通道依赖性,如式(6)所示。为学习通道之间的非线性交互关系,使用了Sigmoid激活函数和ReLU函数。分别为式(6)中的σ,δ。w1为降维参数,w2为升维参数,s为各通道权重
s=Fex(z,W)=σ(g(z,W))=σ(w2δ(w1z))
(6)
最后通过式(7)进行Scale操作得到最终的输出。sc为第c个二维矩阵的权重
(7)
2.1.2 YOLO-Mask网络结构
当样本图像中存在一些遮挡或紧邻的目标物体干扰时,现有目标检测网络会错误的“认为”该区域只有一类目标置信度较高的特征可能性较大,这种置信度分布不平衡会造成目标定位不准确和大量的漏检,导致检测精度降低。为了提高Darknet53的特征提取能力,可采取增强感受野的方法来使特征提取网络学习到全局特征[14],进而平衡不同区域的置信度。
SENet中全局平均池化的操作将输入特征图压缩为基于通道的一维向量,从而获得全局的感受野,使得感受区域更广,随后通过两个全连接层,在减少参数量的同时,通过Excitation操作学习通道间的依赖性,接着经过Sigmoid激活函数将通道间的权重值定在0和1之间,最终输入的特征与权重值相乘得到最后的输出。
考虑到如果改变主干特征网络的深层结构,需要将新的网络在ImageNet数据集上重新进行预训练,整个过程需要耗费大量的时间,而将SENet结构加在layers3之前,由于SENet结构不会改变特征层的大小,即改进后的模型与预训练模型的参数维度相匹配,可直接加载已有的预训练权重进训练。因此,本文选择将SENet嵌入在Darknet53中的layers2和layers3层之间,改进后的YOLO-Mask网络结构如图3所示。
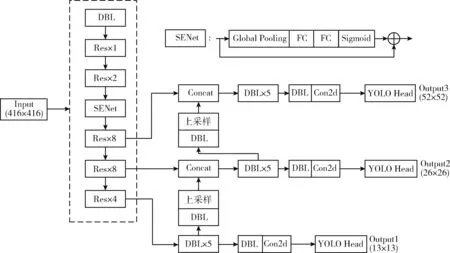
图3 YOLO-Mask网络结构
2.2 优化先验框
基于锚框的目标检测网络,需要合理的锚框设置,若锚框的大小与目标的尺度不符,则正样本数量会大大减少,导致大量漏检和误检情况发生。YOLOv3采用K-means算法对数据集中的目标进行聚类得到9个尺寸的先验框,分给3个不同的检测层,针对COCO公开数据集的先验框从小到大依次为(10,13),(16,30),(33,32),(30,61),(62,45),(59,119),(116,90),(156,198),(373,326)。而RMFD口罩遮挡人脸数据集中的目标偏小,公开数据集的先验框已不再适用。
为解决上述问题,优化检测效果,本文使用K-means++[15]聚类算法对口罩数据集的维度和宽高进行重新优化聚类,得到RMFD数据集可视化聚类结果如图4所示,其中横坐标表示目标的宽,纵坐标表示目标的高,黑色三角表示聚类中心,最后获得符合RMFD口罩遮挡人脸数据集的先验框尺寸设置数值,具体见表1。
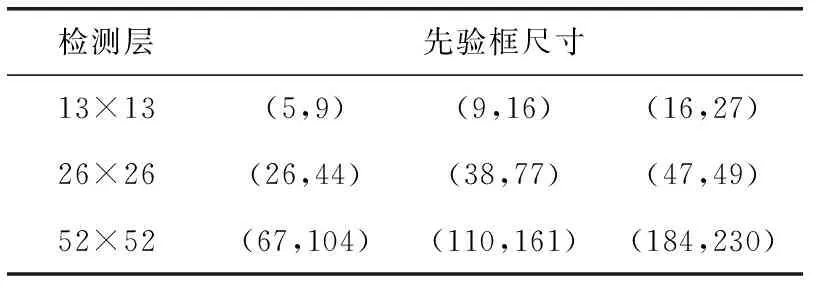
表1 优化后RMFD数据集先验框尺寸
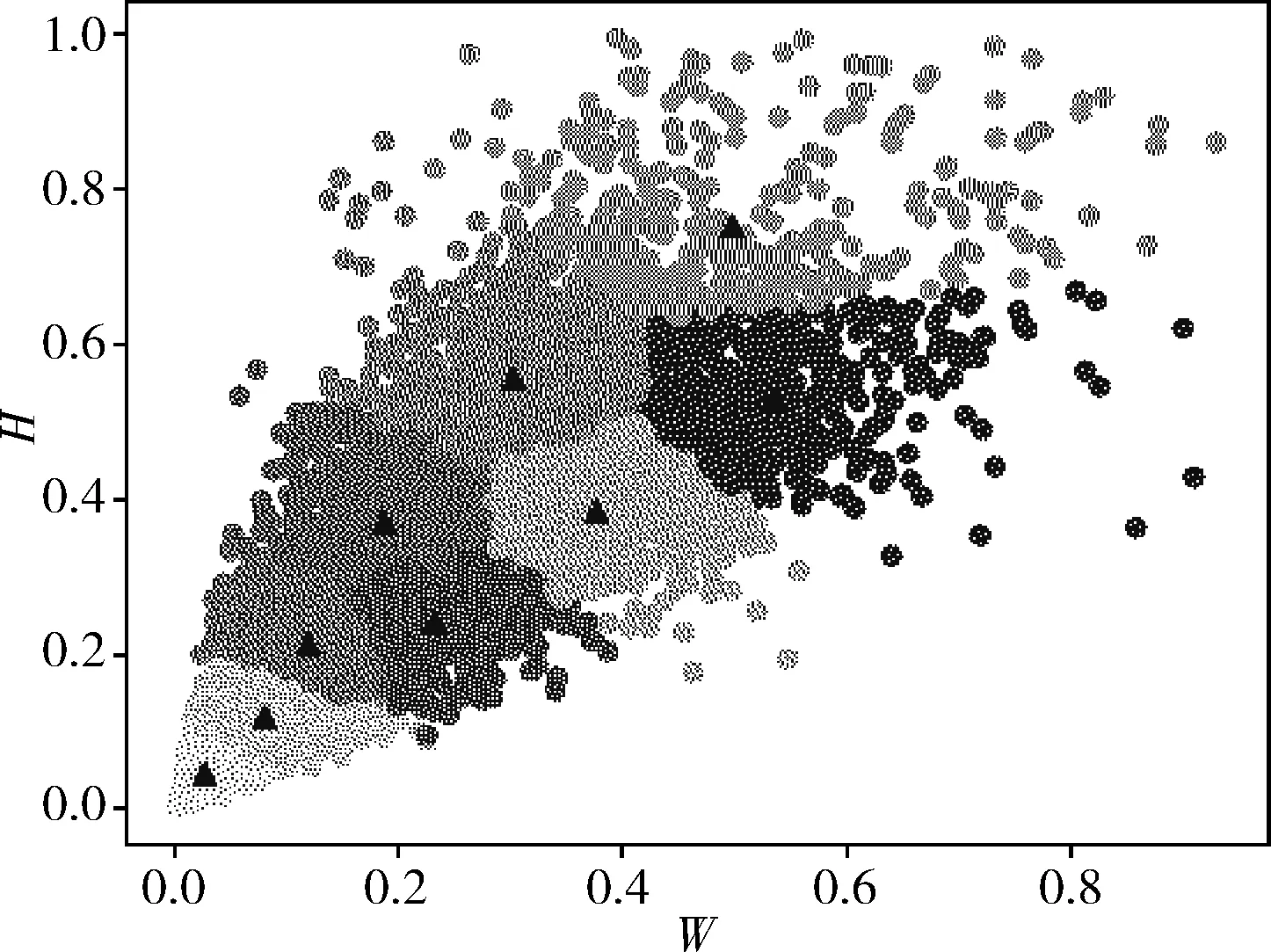
图4 RMFD数据集可视化聚类结果
2.3 改进的损失函数
采用L2范数损失来计算边界框位置坐标的回归损失,并使用IoU作为目标检测效果的评价标准时会出现两个问题:①当预测框与真实框之间无交集时,其无法衡量两个边框之间的距离。如图5所示。两个场景的预测框与真实框都未相交,虽然图5(a)的预测框离真实框更近,但两个的IoU均为0。②IoU值的变化不能反应MSE[16]的变化,如图6所示,图6(a)、图6(b)两组边界框角点坐标距离的MSE损失值相等,但IoU却不同,说明MSE与IoU之间不具有强相关性。
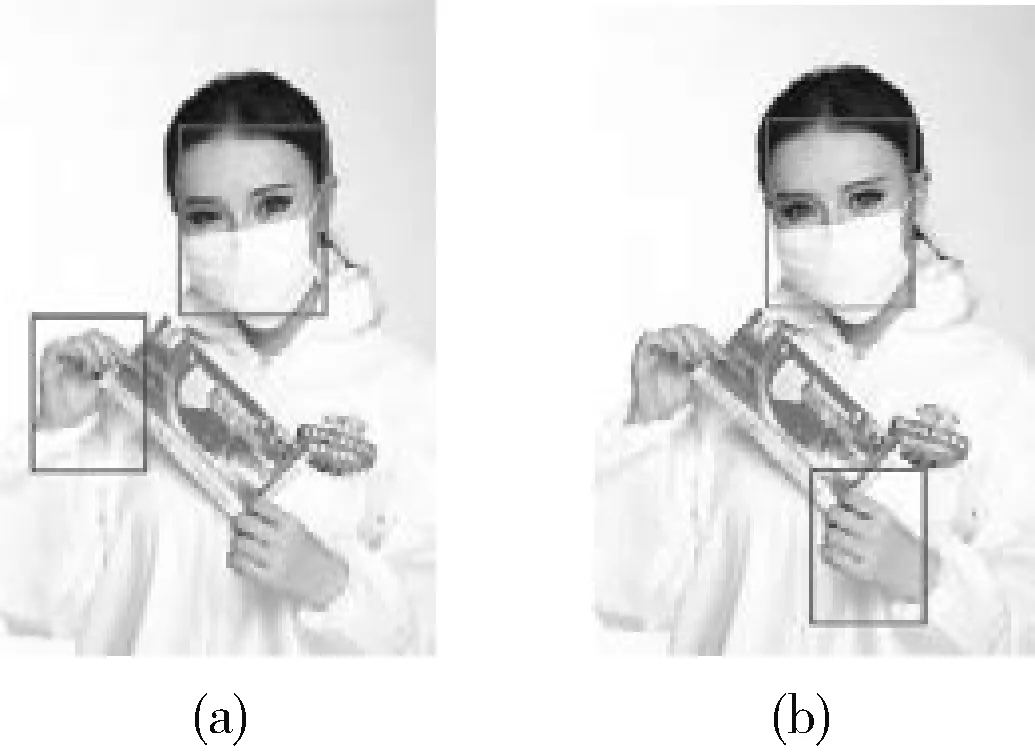
图5 IoU为0时的场景
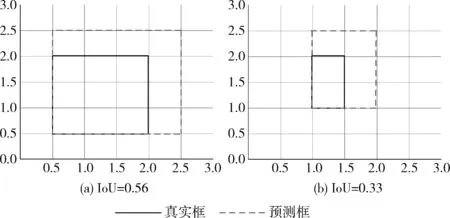
图6 L2范数损失值相等时IoU的变化
为解决上述问题,引入CIoU作为损失函数,CIoU将目标与锚框之间的尺度、距离、重叠率、惩罚项都考虑进去,避免了像IoU一样出现训练过程中发散等问题,使目标框回归变得更加稳定。CIoU如式(8)所示
(8)
其中,ρ2(b,bgt) 表示预测框和真实框中心点之间的欧式距离,c代表的是两个框之间最小闭包区域的对角线距离。α和v的式如式(9)、式(10)所示
(9)
(10)
CIoU的损失函数如式(11)所示
(11)
3 实验过程与结果分析
3.1 实验平台与训练设置
本文的实验环境配置如下:处理器为AMD Ryzen7 4800H,显卡为RTX 2060,16 GB内存,操作系统为Windows10。实验采用visual studio code编译软件,Python编程语言,深度学习框架为Pytorch。实验使用Adam优化器对网络进行优化,初始学习率设置为0.001,每30个epoch,学习率变为原来的0.1,batch size为4,共训练120个epoch。
3.2 评价指标
为评价YOLO-Mask对数据集中遮挡、紧邻目标的检测效果以及预测框的回归效果,本文选取由精准率P(precision)、召回率R(recall)、平均精度AP(average percision)计算得来的F1得分和平均精度均值mAP(mean average percision)来评价模型的检测效率。计算公式如式(12)~式(13)
(12)
(13)
其中,F1是P和R的调和平均数,是用来衡量二分类模型精准度的指标。对所有类别求AP并取平均值即为mAP, 其是反应网络模型整体性能的重要指标。
3.3 数据集
实验所用数据集为PASCAL VOC(2007+2012)和口罩遮挡人脸数据集(real-world masked face dataset,RMFD)。其中VOC数据集共16 551张图片,分20类。RMFD数据集是武汉大学于2020年3月免费开放的全球首个口罩遮挡人脸数据集。共8565张图片,分Face和Face_mask两类。为验证改进后YOLO-Mask模型的检测效果,本文分别在上述两个数据集进行对比验证。
3.4 网络参数量分析
统计网络参数与帧速率,结果见表2。
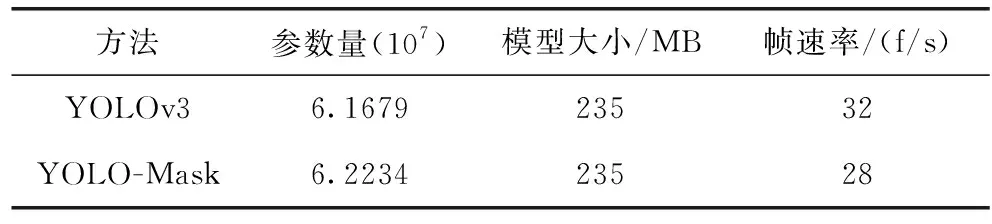
表2 网络参数量对比
3.5 实验结果分析
3.5.1 PASCAL VOC数据集结果分析
为了评估YOLO-Mask的性能情况,对主流经典目标检测网络Faster R-CNN、SSD 以及原始YOLOv3,在PASCAL VOC数据集进行训练和测试。实验结果见表3。
结合表2和表3得出,YOLO-Mask在仅增加0.9%的参数量且不影响模型检测实时性的前提下,在PASCAL VOC数据集上有13个目标类别取得了最优结果,其中在“Boat”、“Table”、“Plant”、“TV”等易遮挡、紧邻的目标上,相较原始YOLOv3取得了明显的精度提升。在“Cow”、“Sheep”等样本数量少,未得到细节特征信息加强的目标上表现不佳,但总体mAP较YOLOv3提升了3%。说明本文算法有效加强了对目标物体的特征信息利用率,使得样本中可正确识别目标的数量增加。实验结果表明,YOLO-Mask 的mAP均优于当下主流的目标检测网络。
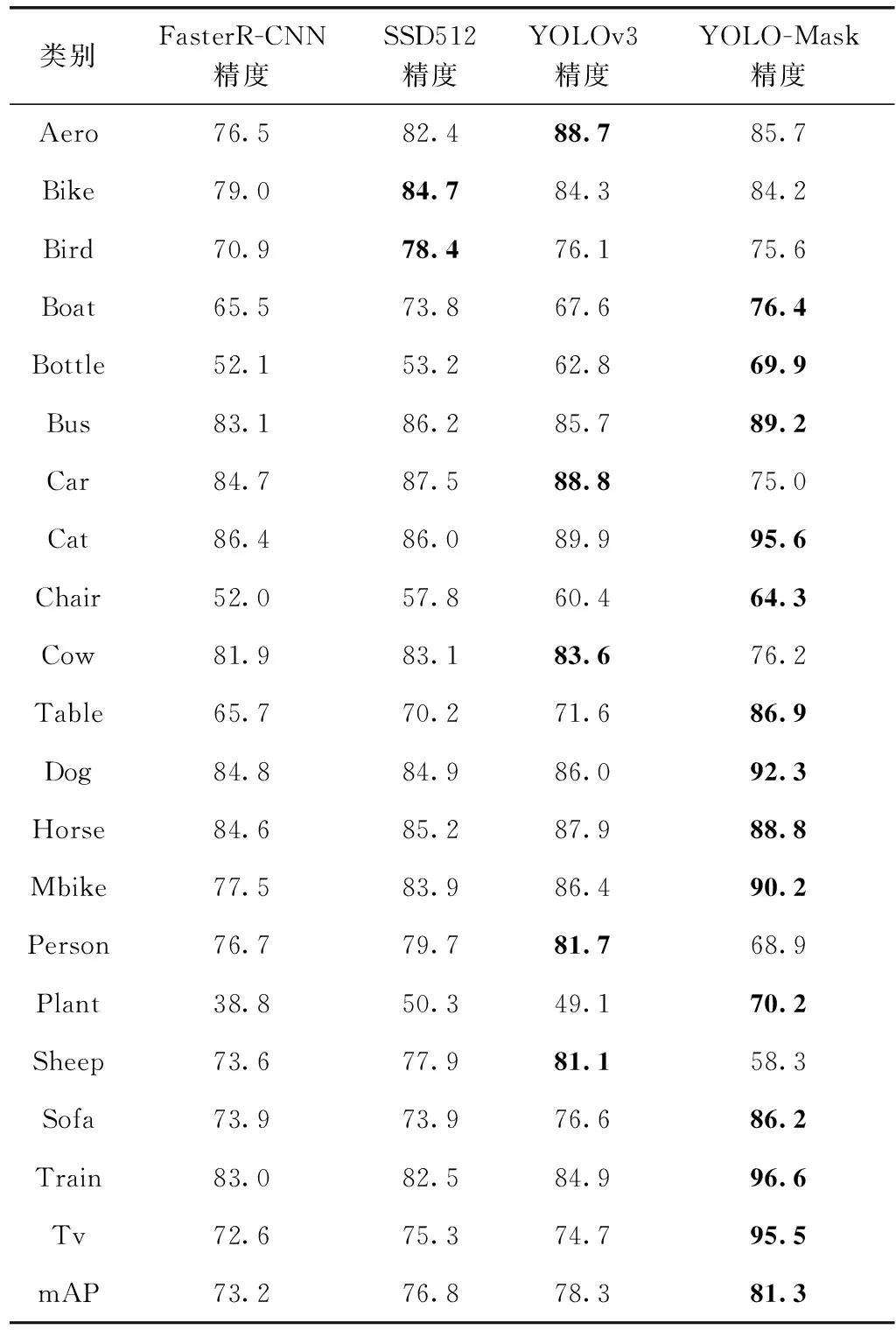
表3 VOC实验数据/%
3.5.2 RMFD数据集结果分析
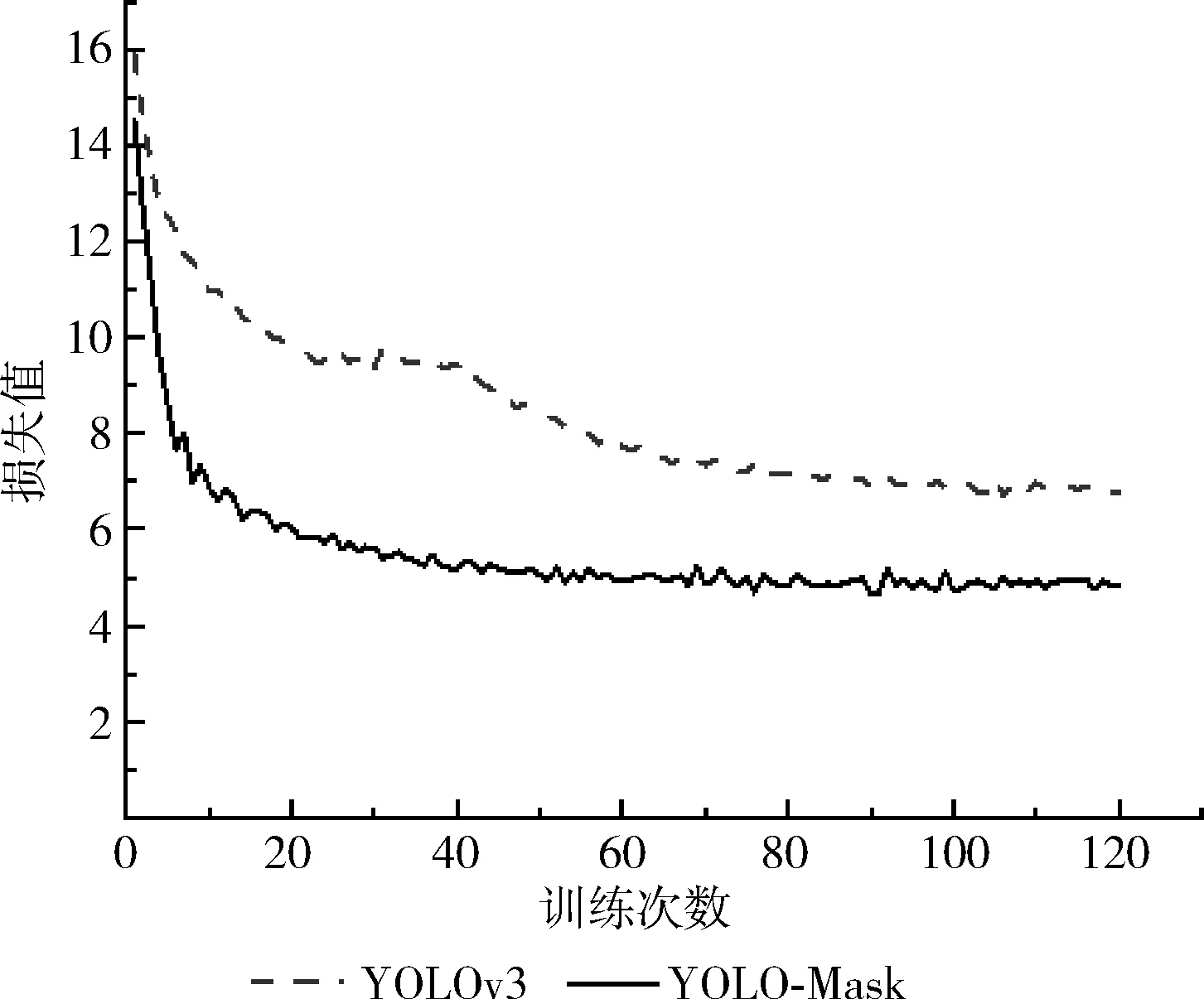
图7 loss下降曲线
表4为YOLO-Mask算法在RFMD数据集上的测试结果,相较SSD、Efficientdet和原始YOLOv3算法,改进后YOLO-Mask算法的召回率R达到了最高值87.7%,精准率P低于SSD、Efficientdet算法,而召回率和精准率往往是一对矛盾的指标,F1分数综合了P和R两个度量值,分值越高说明模型效果越好。YOLO-Mask的F1分数相较其它3个主流算法分别提高了0.12、0.2、0.02,mAP分别提高了10.7%、6.4%、3.8%。实验结果表明,YOLO-Mask算法的检测精度最高,模型效果最佳。
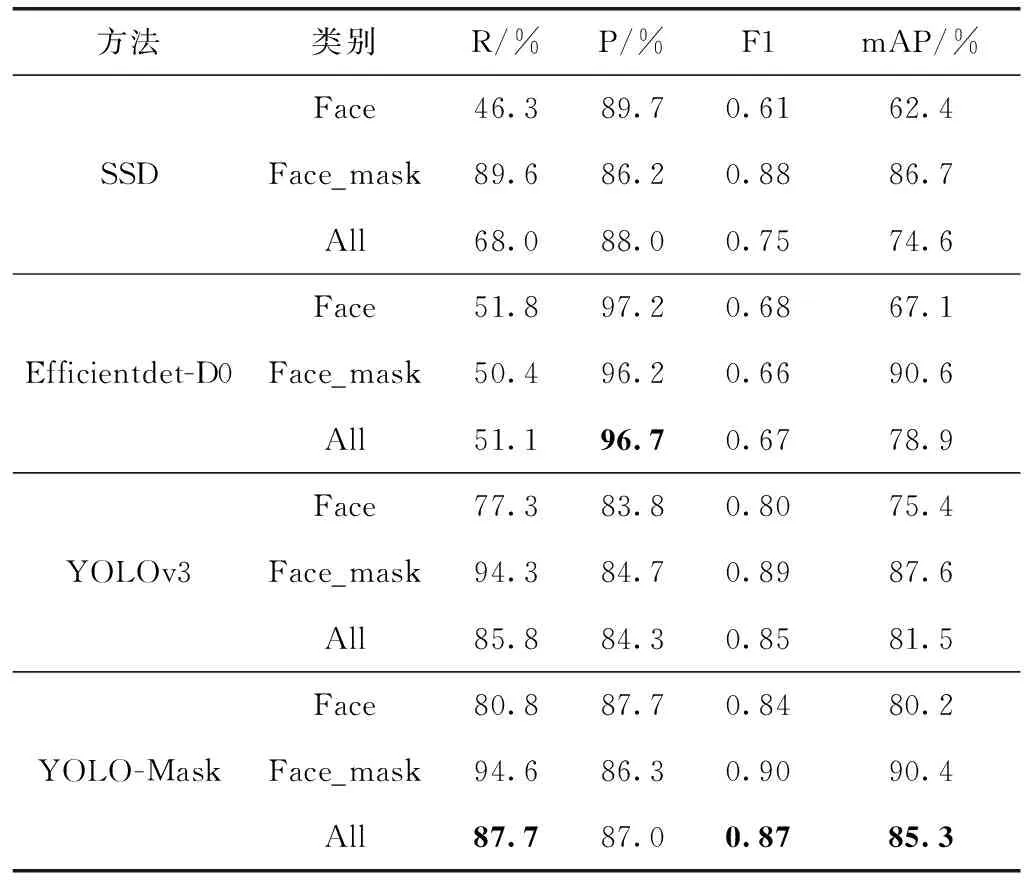
表4 RFMD实验数据
3.5.3 消融实验
为了进一步分析本文提出的改进方法对YOLOv3模型的影响,设计了消融实验,将本文算法分为4组实验分别在RMFD数据集上进行训练,消融实验的结果见表5。

表5 消融实验结果对比
由实验A和原始YOLOv3算法对比可知,加入通道注意力机制的网络模型性能得到显著提升,mAP提升了2.7%,说明改进后的特征提取网络加强了特征信息的利用率,提高了检测精度。实验B在实验A的基础上对锚框进行了K-means++聚类优化,mAP提高了0.7%,最后YOLO-Mask在实验B的基础上使用了CIoU,使得mAP提高了0.4%。总之,本文对YOLOv3的改进方法在密集人群场景下的口罩检测任务中均是有意义的。
3.5.4 定性分析
在图8中,本文选取了原始YOLOv3和改进后的YOLO-Mask在RMFD数据集上的表现。在第一组有紧邻目标的场景下,YOLOv3漏检了一个“face”目标,而SE-YOLOv3则可以顺利检出。在第二组人群密集、存在小目标和遮挡目标的场景下,SE-YOLOv3算法很好展示出对小目标检测精度的提升,正确检测出10个目标,比YOLOv3多检测出2个小目标和1个遮挡目标。在第三组场景中,YOLOv3算法将小目标“face”误检为“face_mask”。在第四组场景中,YOLOv3检测出7个目标,而YOLO-Mask检测出8个目标,降低目标漏检率的同时提高了目标预测置信度,表现优异。综上所述,本文算法的检测效果明显优于YOLOv3,更适用于密集人群场景下口罩佩戴检测。

图8 YOLOv3和YOLO-Mask的效果对比
4 结束语
本文在YOLOv3特征提取网络中嵌入通道注意力机制SENet,提高网络对关联目标特征信息的利用率。其次,采用K-means++算法对口罩数据集进行锚框聚类,提高检测效率。最后,使用CIoU损失函数,加速模型收敛。通过以上方法得到的YOLO-Mask算法在密集人群场景下口罩佩戴检测表现优异,有效提升了遮挡、紧邻目标的检测精度,超过其它优秀检测算法的同时,又保证了算法的实时检测速度。实验中同时发现,YOLO-Mask在检测背景模糊、目标重叠的场景下表现不佳,后续工作将继续改善算法的检测能力,提高检测性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
意林(2020年9期)2020-06-01
海峡姐妹(2020年4期)2020-05-30
铁道通信信号(2019年6期)2019-10-08
作文大王·笑话大王(2019年3期)2019-04-22
传媒评论(2017年3期)2017-06-13
雷达学报(2017年6期)2017-03-26
第二课堂(课外活动版)(2016年2期)2016-10-21
电子设计工程(2015年6期)2015-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
