
基于信息对齐的半监督少样本学习方法
2023-02-21 12:54廖凌湘刘鑫磊张华辉
计算机工程与设计 2023年2期
廖凌湘,冯 林,刘鑫磊,张华辉
(四川师范大学 计算机科学学院,四川 成都 610101)
0 引 言
现有的少样本学习方法大多存在以下两个问题:①在目标域和源域数据分布差异不大的情况下,实验效果都取得了较好的成绩,但当目标域和源域分布差异较大,会导致过拟合,分类准确率不高,泛化能力差等问题。②当输入样本经由特征提取网络得到特征向量,可能会导致严重的模糊,因为可识别类的显著特征可能在图像上的任意一个位置,因此图像上的显著特征可能会与另一个图像上的其它位置的不显著特征进行对比。如图1所示,两张图片属于同一个类,但关键物体(动物),在图像上不同位置,如直接采用距离度量,就会导致分类错误。

图1 特征提取模糊示例
针对以上问题,提出一种基于信息对齐的半监督少样本学习方法(FSL-SIA)。本文主要贡献如下:
(1)采用自训练半监督的方法,通过引入未标注的数据样本辅助模型训练,即通过分类模型对未标注的数据集进行预测,将预测概率最大的类别对未标注的数据样本进行标注,将这种伪标签的数据集和源域数据集对模型进行协同训练,以此提升少样本学习模型的泛化能力。
(2)利用类原型空间的思想和注意力机制,使查询图片和支持图片上具有相同信息的局部区域信息对齐,以此解决少样本学习中特征提取网络得到的特征向量的模糊性问题。
(3)根据FSL-SIA模型在少样本领域的经典数据集上的实验,分析模型的跨域适应性、分类准确率和分类稳定性,研究表明,相比关系型网络[1]等主要方法的准确率均有提升。
1 理论基础
现有的少样本学习方法,可分为4类:
第一类是基于数据增强的方法,常用的方式有使用生成对抗网络来扩充训练数据;第二类是基于微调(fine-tu-ning)的方法,事先在大规模的数据集上做预训练模型,然后对目标数据集上对网络模型的全连接层进行参数微调,得到微调后的模型,在真实场景和实验中,目标数据集和预训练的数据集往往分布并不相近,采用微调的方式容易导致过拟合;第三类是基于元学习(meta-learning)的方法,它的主要思想是让机器学会学习,让模型学习到模型训练之外的元知识[2,3];第四类是基于度量学习的方法。在数学定义上,度量指的是元素之间的距离函数,通过确定的距离函数计算两个样本的距离,从而度量样本间的相似度[4]。
1.1 少样本学习
目前主要针对少样本学习问题,以任务task为基本单元,由多个meta-training任务训练一个模型F, 使F可以快速适应到少样本的新任务上。下面,以元学习中的监督学习为例,采用数学定义形式化的方式来阐述与本文相关的元学习定义。
设X为输入实例的特征空间。
定义1 meta-learning数据集:
一个meta-learning任务集Υ由多个meta-training任务Γtr与多个meta-test任务Γte组成,满足:
(1) Γtr, Γte~p(Γ);
(2) Γtr∪Γte=Υ, Γtr∩Γte=∅;
(3) ∀Γi,Γk∈Γtr, Γi≠Γk。
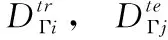
定义2 meta-training支持集与查询集:
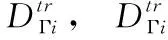

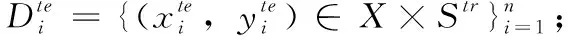
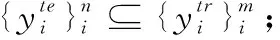
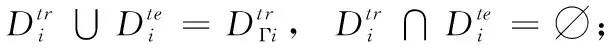
定义3 meta-test支持集与查询集:
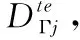
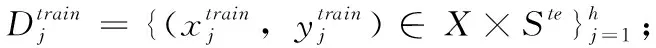
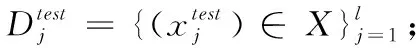
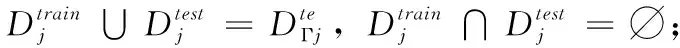
(4)Ste∩u=∅。
定义4 C-way K-shot数据集:
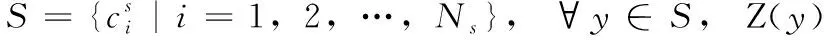
(1) |S|=C;
(2) |Z(y)|=K。
其中, |·| 为集合的势。
定义5 C-way K-shot元学习:
给定任务集合Γ={Γtr,Γte}, 元学习通过两个阶段的训练完成使模型适应任务分布p(Γ) 的目的。
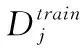
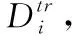

特别地,在训练F*的过程中,如果涉及模型超参数的调整,可以把训练任务集再划分为训练任务集与验证任务集。验证任务集可用于模型超参数的调整,也可用于对模型的初步评估,并监控模型是否过拟合。
1.2 注意力机制
计算机视觉中的注意力机制的基本思想是要模型学会注意力,能够忽略无关信息而关注重点信息,为信息处理提供了便利[5],可以帮助模型对输入的每个部分给予不同的权重,增强更加关键和重要的信息,对模型做出更加准确的判断[6]。
Fusheng Hao等[7]提出一种收集与选择的策略,利用卷积神经网络对图像特征进行收集,通过可变注意力对收集到的特征进行选择,以提高分类模型的准确率。Ilse等[8]使用嵌入级别的注意力方法,将两层全连接的神经网络嵌入到模型的输出,用神经网络确定注意力权重的加权方式,令H={h1,h2,…,hi} 表示输入到神经网络的向量,ai表示神经网络的参数,则可以表示为
(1)
(2)
其中,ω∈L×1,V∈L×M。
如图2所示本文使用基于激活的嵌入级注意力机制提取支持集和查询集信息相关区域的特征,以实现信息对齐。
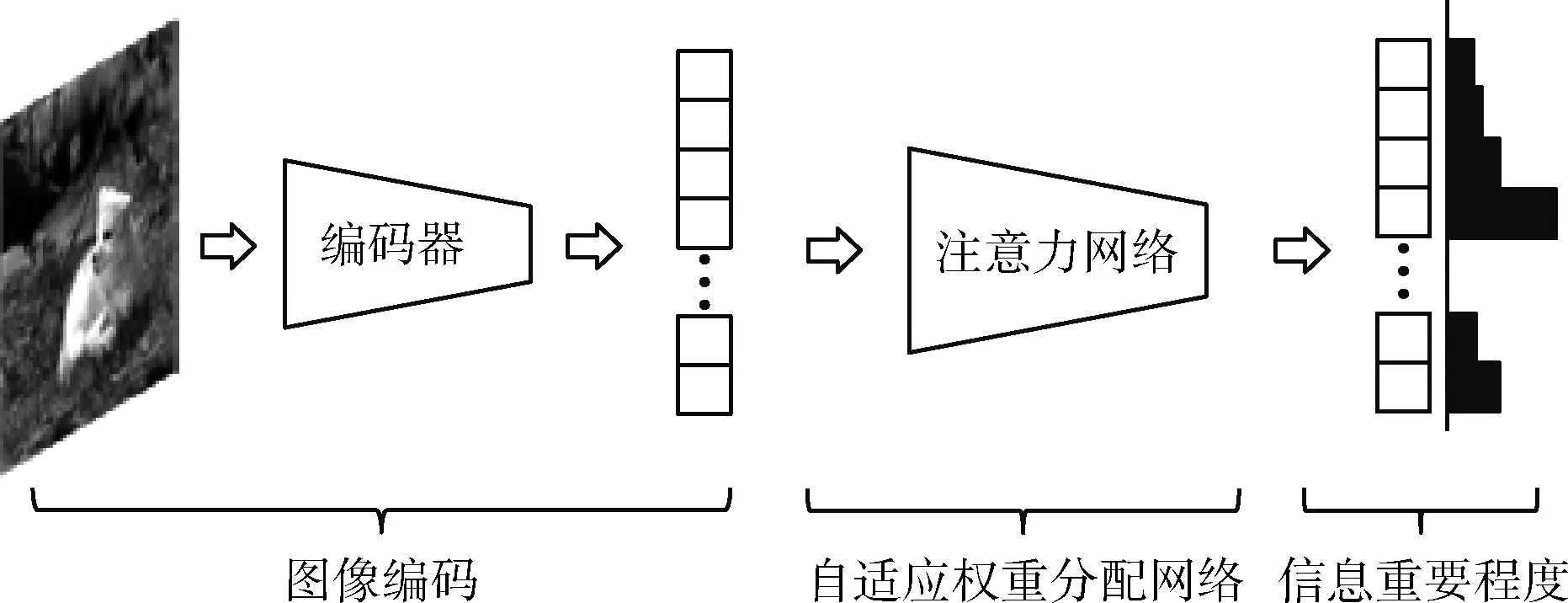
图2 自适应权重分配模块
1.3 半监督学习
区分有监督学习和无监督学习,是通过输入样本是否有监督信息,即输入样本是否有类的标签。半监督学习是有监督和无监督学习的结合[9],输入数据里中包含有标记数据集和未标注数据集。
Li等[10]提出一种半监督元学习方法,采用自训练模式标记无标签数据,通过软权重网络(SWN)为伪标签添加权重。David等[11]提出混淆匹配半监督学习模式,用熵正则化和伪标签思想对模型进行一致性调整。
以半监督学习过程为例,先使用有监督的数据估计出先验概率P(Ci), 再估计出每一个类有标记数据的分布P(x|Ci), 确定数据的分布是协方差矩阵的高斯分布,那么需要估计出μi之后就可以估计某个数据属于某一个类的概率,以二分类问题为例,有监督学习的计算公式如下
(3)
半监督学习[12]的前面部分操作与有监督学习的操作相同,以二分类问题为例使用有监督的数据xr估计出P(Ci) 和μi, 使用未标记数据集xu对得到的模型参数θ重新估计,估计过程按照EM思想分为两步:①根据参数θ计算出无标记数据的后验概率Pθ(C1|xu), ②更新模型参数θ
(4)
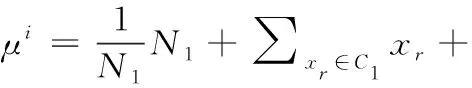
(5)
其中,N为全部的样本数量,N1为属于C1的样本数量。
本文采用一种伪标签的半监督学习方法,对未标注的数据通过预测值为其标注伪标签,设置超参数减弱伪标签所带来噪声的影响,在伪标签数据集的帮助下和有标注数据的协同训练分类模型和提高模型的鲁棒性。
2 FSL-SIA模型
FSL-SIA模型的流程如图3所示,分为特征提取模块、信息对齐模块、关系模块和半监督辅助4个部分。本章首先对特征提取模块、信息对齐模块、关系模块3个部分内容进行介绍,再对FSL-SIA模型算法进行详细描述,FSL-SIA算法策略如算法4所示。
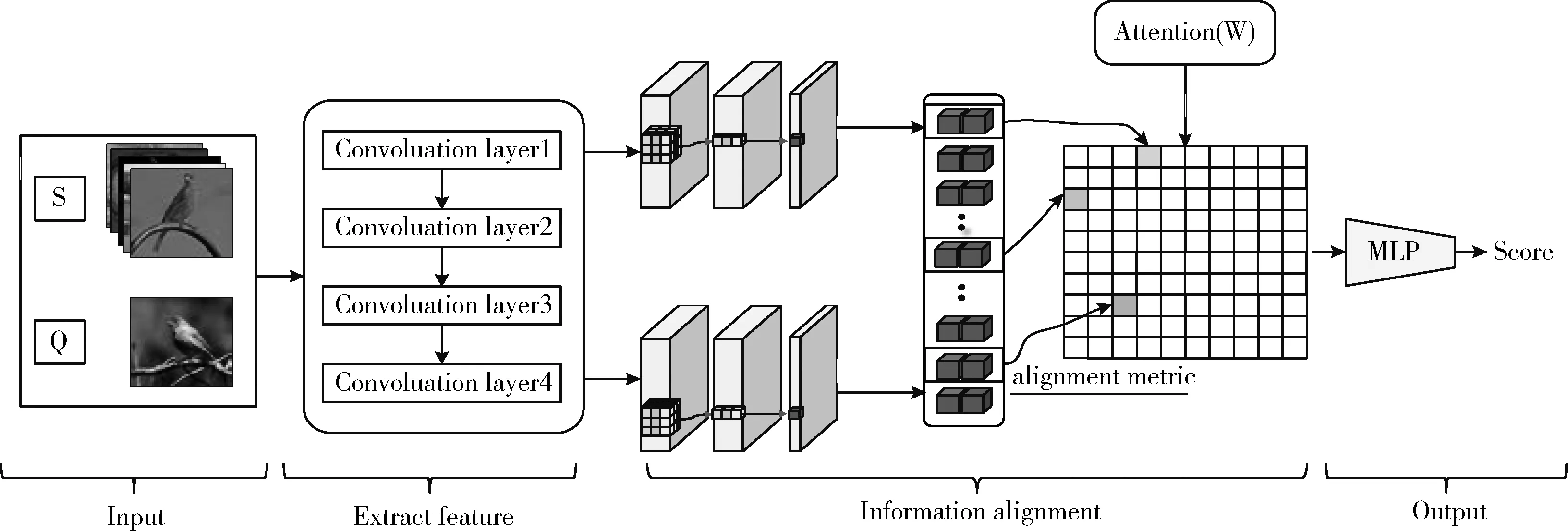
图3 自适应权重分配模块FSL-SIA流程
2.1 特征提取模块
将经过预处理的数据集按照定义2对其进行划分,输入到四层卷积神经网络提取特征向量,特征提取过程如算法1所示。
算法1:特征提取
输入:meta-training任务集Γtr
输出:特征向量Vx={Vxs,Vxq}
(2)随机初始化特征提取网络参数
(3)fori=0in|X×Str|do:
(4)根据式(6)得到通过特征提取网络后的特征向量Vx
(5)Endfor
(6)输出特征向量Vx

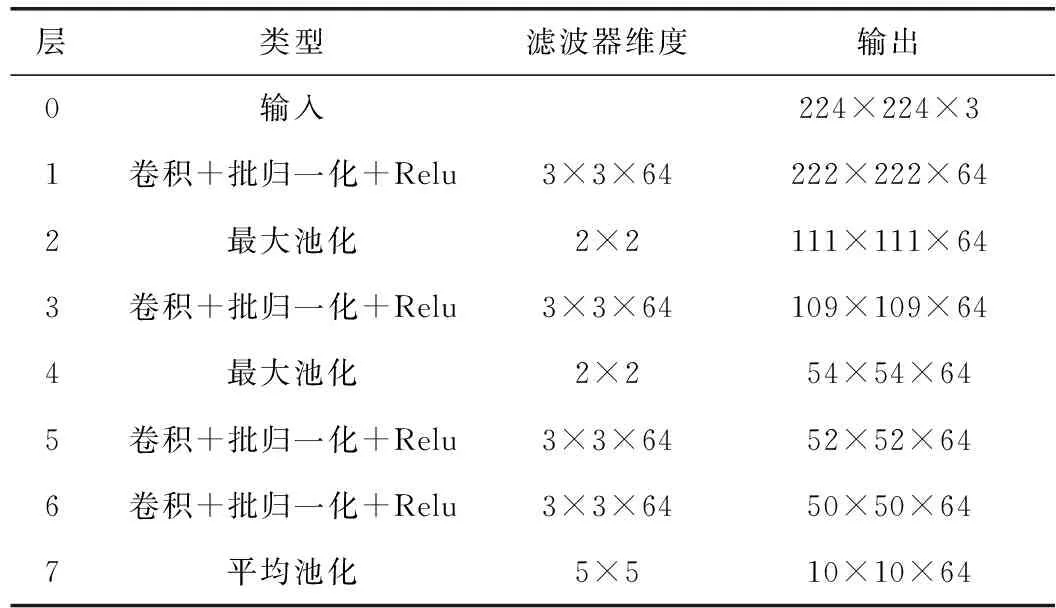
表1 特征提取网络结构
Vx=AP1(cv4(cv3(MP2(cv2(MP1(cv1(x,ω1)),ω2)),ω3),ω4))
(6)
其中,Vx表示图像的特征向量,cv1,cv2,cv3,cv4表示卷积层,ω1,ω2,ω3,ω4表示卷积核,MP1,MP2表示最大池化层,AP1表示平均池化层。
2.2 信息对齐模块
为了将不同区域内的显著信息进行对齐,提出一种信息对齐模块,该模块包含两个小部分特征对齐,联合关系矩阵,其过程如算法2所示。
算法2:信息对齐模块
输入:特征向量Vx={Vxs,Vxq}
输出:联合关系矩阵Vjoint
(1)fori=0in|Vxq|do:
(2)forj=0in|Vxs|do:
(3)根据式(7)、式(8)对Vxs和Vxq求原型表达
(4)根据式(9)、式(10),得到信息向量Vixs,Vixq
(5)将Vixs,Vixq根据式(11)、式(12)进行平铺
(6)平铺后的向量VIxs,VIxq根据式(13)、式(14)、式(15)计算重新加权后的联合关系矩阵Vjoint
(7)Endfor
(8)Endfor
(9)输出Vjoint
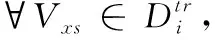
(7)
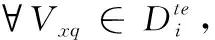
(8)
其中,Tq=|Str|。 得到基准向量后,采用特征向量和基准向量相减的方式进行对齐,得到支持集信息向量Vixs和查询集信息向量Vixq。 根据式(6)、式(7)和式(8),有
Vixs=Vxs-Vmeanxs
(9)
Vixq=Vxq-Vmeanxq
(10)
联合关系矩阵:联合关系矩阵目的是将不同信息向量整合在一起,以便于关系网络对查询集数据进行分类,如何构建高效的联合关系矩阵是本文的重点和难点。首先,为了提高信息向量对图像实例的表达效果,提升模型效能,根据Zagoruyko等[13]提出的办法,将Vixs,Vixq信息向量通过向量内叉乘的方式得到其平铺表达。根据式(9)和式(10),有
VIxs={C,H*W}
(11)
VIxq={C,H*W}
(12)
其中,VIxs转化为平铺表达后的支持集信息向量,VIxq转化为平铺表达后的查询集信息向量。然后,针对平铺表达后的信息向量,利用矩阵相乘的方式得到联合矩阵。根据式(11)和式(12),有
Vjoint=Matmul(VIxs,VIxq)
(13)
其中,Vjoint表示联合矩阵。为了得到在传递关系过程中更加高效的联合关系矩阵,本文利用注意力机制,计算多个感受野下的联合关系矩阵。针对支持集中不同的信息向量,通过感知机网络为信息向量设定不同的权重,增强关键信息区域的权重,减弱无关信息的权重,得到不同的注意力值。根据式(9)和式(10),有
Attention=MLP(Vixs,Vixq)
(14)
其中,Attention为注意力值。利用注意力值对联合矩阵进行仿射变换得到不同感受野(不同注意力值)下的联合关系矩阵,根据式(10)和式(14),有
Vjoint=Attention*Matmul(VIxs,VIxq)
(15)
其中,Vjoint表示不同感受野下的联合关系矩阵。对不同感受野下的联合关系矩阵求和取均值得到最后的联合关系矩阵。根据式(15),有
(16)
其中,Vjoint表示不同感受野下的联合关系矩阵,m表示感受野个数(支持集类别数量)。
2.3 关系模块
关系模块是由输入层、输出层和两层隐含层的四层感知机,通过感知机计算支持集样本和查询集样本的相似程度。取出与查询集样本相似程度最高的类别标签作为当前样本的预测标签。关系模块如算法3所示。
算法3:关系模块
输入:联合关系矩阵Vjoint
输出:预测标签Y1
(1)将Vjoint输入到四层感知机根据式(17)得到相似度分数Score
(2)根据式(18)选取相似度分数Score最高的作为Vxq的预测标签
(3)输出预测标签Y1
FC1、FC2、FC3、FC4表示为4个全连接层,连接权重为W1、W2、W3、W4。偏置为b1、b2、b3。其表示为
Score=FC4(W3FC3(W2FC2(W1FC1(Vjoint)+b1)+b2)+b3)
(17)
其中,Score是经过关系模块后,查询集样本Vxq与支持集样本Vxs的相似度分数
Y1=Argmax(Score)
(18)
如式(15)所示选择与查询集样本Vxq相似度得分最高的支持集样本Vxs的标签作为Vxq的预测标签
(19)
通过式(19)将预测的标签与查询集样本Vxq的真实标签进行交叉熵,使用交叉熵损失函数计算出Loss1。
2.4 半监督训练
设信息对齐模块为I(), 关系模块为R(), 半监督任务集为Task,半监督任务是指通过无标注的数据集协助训练模型。半监督训练过程与有监督训练相似。其表示为
Score′=R(I(Task))
(20)
将验证集数据无标注数据集输入到预训练后的信息对齐模块和关系模块,得到一组相似度分数。根据相似度得分最高的位置对数据进行预测,为数据标记伪标签。表示为
Y′=Argmax(Score′)
(21)
再将已经标记伪标签的数据输入到信息对齐模块和关系模块中,得到Y2, 将其与Y′如式(21)所示,计算出伪标签数据的半监督损失,并通过梯度下降法继续训练网络参数
(22)
Losstotal=Loss1+λLoss2
(23)
其中,λ为协同训练系数,后续将在实验部分对协同训练系数λ进行讨论。
2.5 FSL-SIA模型算法描述
算法4:FSL-SIA模型策略。
输入:meta-learning任务集Υ,以及参数C、K、λ、epsiodes;/*根据定义4,C表示分类种类,K表示类别中的样本数,epsiodes模型训练次数,λ表示协同训练次数。
输出:FSL-SIA分类模型Ω与分类精度。
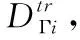
步骤2 随机初始化模型Ω中各网络层参数;
步骤3
forkinepsiodesdo:
(4)根据式(7)、式(8)、式(9)、式(10)的方法,对Vxs和Vxq进行信息对齐得到对齐后的向量,记为VIxs,VIxq。
(5)将VIxs,VIxq根据式(14)和式(15),计算重新加权的联合矩阵Vjoint。
(6)将Vjoint送入到关系模块,根据式(17)计算每一个Xs和Xq的相似程度,即Score
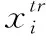
(8)取Score′中每行最大的相似度得分作为对应半监督样本图片的预测标签。
(9)利用式(19)和式(22)计算损失L1和L2
(10)根据梯度下降算法反向传播L1+λL2, 调整模型的参数
Endfor
步骤4 选取meta-test数据集,进行(2)到(6),根据Score进行预测,得到分类精度。
步骤5 输出分类模型Ω与分类精度。
3 实 验
为了验证FSL-SIA的效果,设计了如下4个部分实验:①与现有主流的少样本学习算法的对比实验;②不同尺寸图片的对比实验;③分析协同训练系数λ对FSL-SIA分类能力的影响;④消融实验。
3.1 模型对比
实验1的目的通过与现有主流的少样本学习算法的实验对比来测试FSL-SIA模型的分类性能。
对于Omniglot数据集,设定5way-1shot、5way-5shot、20way-1shot、20way-5shot问题定义。实验参数与结果见表2,从表中可以看出FSL-SIA的准确率在Omniglot数据集下上升空间有限,在20way-1shot提升1.6%,验证FSL-SIA在面对灰度图目标域时,具备良好的泛化能力,对于目标域也表现出较好的准确率。
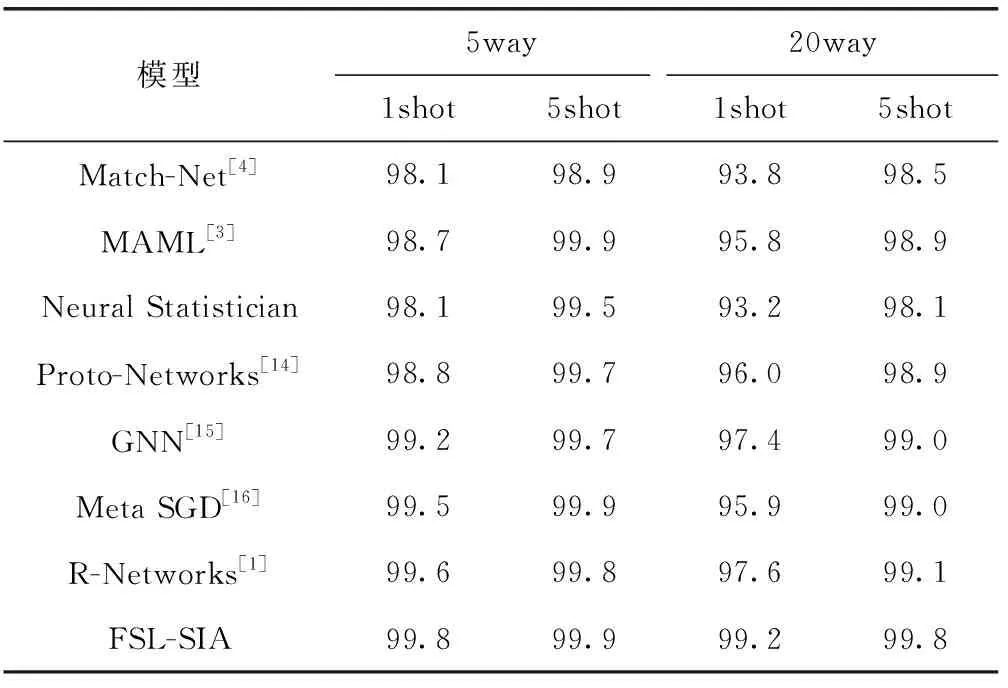
表2 Omniglot数据集下与主流少样本学习方法对比/%
对于miniImageNet数据集,FSL-SIA模型的准确率在5way-1shot问题下达到了62.11±0.69%,且在5way-5shot问题下达到80.19±0.41%,比Relation Networks的准确率分别高出了11.67%和14.77%,也均超过了其它主流的少样本学习方法,且实验验证FSL-SIA模型通过信息对齐模块可以更有效拉近源域与目标域之间特征分布的距离,使得模型具有较强的鲁棒性与泛化性。相比于Relation Networks和Pro-networks直接比较两者关系或者计算出在原型空间上的欧氏距离,FSL-SIA模型通过关系模块和信息对齐的方式可更精确区别不同类别间的差异性。实验参数设置见表3,训练次数epsiodes=60 000,学习率=0.001,根据定义4分别设置5way-1shot和5way-5shot两组实验。
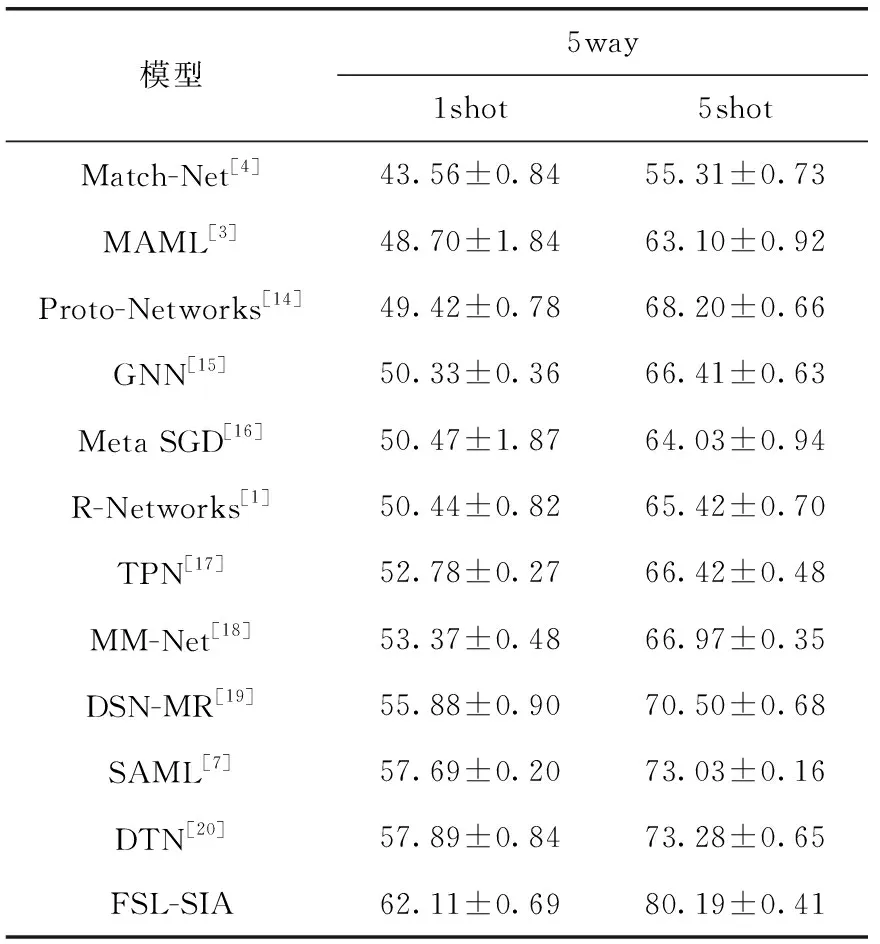
表3 miniImageNet数据集下与主流少样本学习方法对比/%
其中:所有方法均采取4层卷积结构作为特征提取网络,准确率A±B%,A代表多次测试过后的均值,B为标准差。
3.2 image
实验2的主要目的研究不同尺寸的大小对FSL-SIA模型分类效果的影响。为了更充分利用本文中的信息对齐模块,将miniImageNet数据集裁剪为尺寸大小224×224的图片,并没有对数据集进行扩充。为了作公平的比较,也将数据集裁剪为尺寸大小84×84的图片。将尺寸大小84×84的图片输入到FSL-SIA模型中与Relation Networks和SAML进行了比较,见表4,实验验证我们从图像尺寸的增加中,使得FSL-SIA模型在信息对齐模块和半监督训练获得收益更多,图像尺寸越大,在信息对齐模块中使查询集和支持集的图片在不同感受野下重叠区域越小,使两者个体独立性更强。
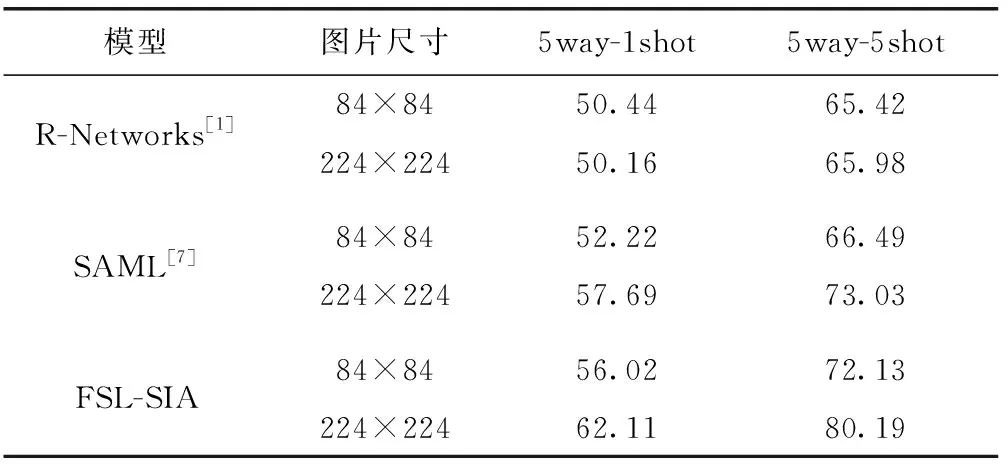
表4 不同尺寸图片对比/%
3.3 半监督参数
实验3的目的是研究协同训练系数λ对FSL-SIA模型分类能力的影响,我们采用miniImageNet数据集研究训练系数λ对模型的分类的作用。对于少样本5way-1shot的问题λ的取值为0.0、0.1、0.2、0.3、0.4、0.5。实验步骤如下:
步骤1foriin[0.0,0.1,0.2,0.3,0.4,0.5]:
令λ=i, 按照2.5节算法4步骤,输出FSL-SIA分类模型Ω的准确率;
步骤2 记录不同λ下的分类准确率,选择出最优λ。
实验结果如图4所示,λ的取值从λ=0.0开始,分类的准确率缓缓上升,在λ=0.3时达到峰值,分类能力达到最优,当λ=0.4到λ=0.5时,模型分类精度迅速下降。

图4 系数λ对1-shot模型的影响
对于少样本5way-5shot的分类问题,协同训练系数λ的取值为0.0、0.1、0.2、0.3、0.4、0.5、0.6。实验步骤如5way-1shot的问题相同,实验结果如图5所示,当λ=0.0开始模型精度缓缓上升,当λ=0.5时模型分类达到最优,当λ>0.5时,模型分类精度迅速降低。
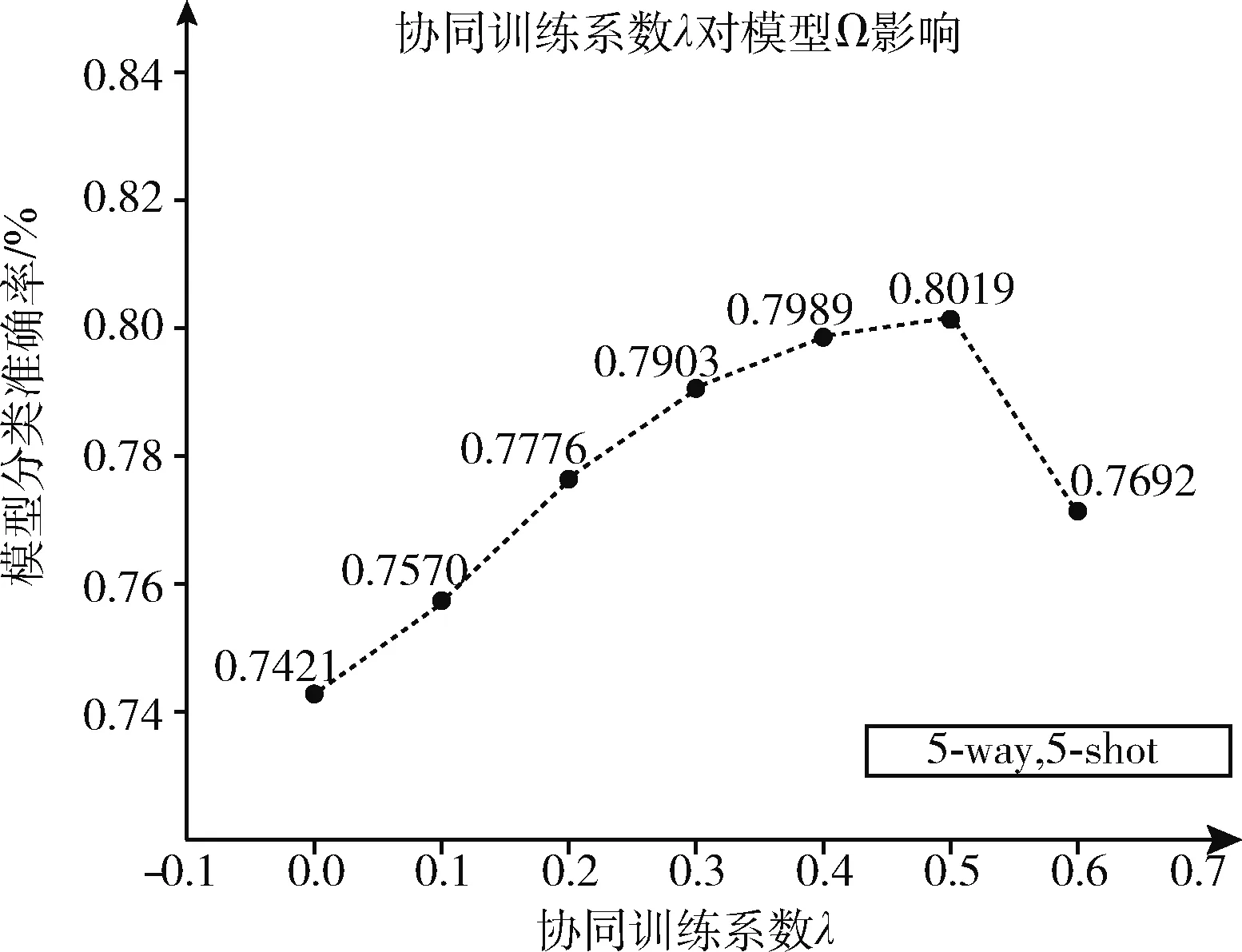
图5 系数λ对5-shot模型的影响
通过两组实验结果,协同训练系数λ对FSL-SIA模型分类能力具有一定的影响,λ的值过小可能对模型的分类效果提升不大,而过大的λ会对模型产生消极的影响,故λ是一个经验值,选择合适的λ值对模型的分类能力有着举足轻重的作用。实验结果表明, ∃λ∈(0.3,0.5) 能使FSL-SIA模型的分类能力取得不错效果。
3.4 消融实验
实验4的目的是为了验证信息对齐模块和半监督辅助训练对于模型的作用,在miniImageNet数据集下采用控制变量法进行消融实验。实验结果见表5,①在只有半监督辅助训练的情况下,模型分类精度在5way-1shot的问题下相比于Relation Networks提升了5.11%,在5way-5shot的问题下分类精准提升了6.87%。②仅在信息对齐模块的作用下,在5way-1shot的问题下的模型分类精度相比于Relation Networks提升了7.88%,在5way-5shot的问题下分类精准提升了8.89%。
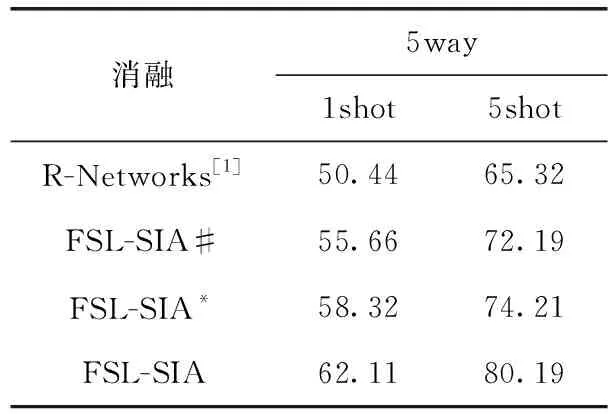
表5 消融实验对比/%
实验验证,信息对齐模块和半监督辅助训练分别单独作用于模型对分类精度的提升是显著的,当两者结合在一起,在5way-1shot的问题下分类精度可达62.11%,在5way-5shot的问题下分类精度可达80.19%,由此可见,两者共同作用FSL-SIA模型,可有效的帮助少样本分类任务。
其中#代表只有半监督辅助训练时的分类准确率。*代表只包含信息对齐模块的分类准确率。
4 结束语
从数据集上可知,能区分类别的主体部分可能在图片上的任一位置,因此直接计算图片的特征向量之间的距离可能会导致严重的歧义,原因是错误地比较图片见的信息不相关的局部区域。
本文针对遇到的问题,提出一种信息对齐的方式,将局部区域的显著信息对齐,然后利用注意力技术来选择和放缩信息相关的局部区域对。
另外采用伪标签的半监督训练方式协同整个模型的训练。实验结果表明FSL-SIA模型可行性,对于少样本学习分类任务具有更高的分类精度和泛化能力,在基准数据集上的大量实验验证了FSL-SIA模型与目前主流的少样本学习算法的优势。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
车迷(2018年11期)2018-08-30
知识经济·中国直销(2018年8期)2018-08-23
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
海峡姐妹(2018年3期)2018-05-09
初中生世界·七年级(2017年9期)2017-10-13
数学学习与研究(2017年3期)2017-03-09
公民与法治(2016年10期)2016-05-17
