
基于场景表示中对象特征语法分析的视频描述
2023-02-21 12:53王咪咪
计算机工程与设计 2023年2期
付 燕,王咪咪,叶 鸥
(西安科技大学 计算机科学与技术学院,陕西 西安 710054)
0 引 言
早期的视频描述方法[1,2]主要包括基于模板[3]和基于检索[4]的方法。其中,基于模板的方法限制了描述语句的语义性,基于检索的方法生成的描述语句缺乏多样性。
近年来,研究人员提出了基于编码器-解码器模型的视频描述方法,该类方法可以有效提高生成描述语句的多样性和语义性。文献[5]提出了S2VT(sequence to sequence:video to text)模型,实现了端到端的视频描述方法,而且S2VT模型简洁,生成的句子准确性和语义性有所提升,因此,后续的工作大多是在S2VT模型的基础上进行。例如,文献[6]在编解码器中引入了注意力机制[7],通过关注不同的重要特征,生成具有多样性的描述语句。但该方法忽略了部分次要视觉特征。文献[8]在编解码器的基础上,分别提取视频的帧特征、时空特征及音频特征,通过融合多模态特征[9]生成文本描述,但是,会因为跨媒体而影响特征向量间的映射关系。文献[10]提出使用基于语法表达[11]和视觉线索翻译的视频描述方法,通过词性标签组成的句子模板对句法结构进行表达。但是,该方法过于依赖词性标签,限制了描述语句的语法构成。
针对上述方法存在的问题,本文提出一种基于场景表示中对象特征语法分析的视频描述方法。该方法通过构建一个新的编码器-视觉对象特征语法分析-解码器的模型,描述对象特征间的依赖关系,在此过程中,引入语法分析的思想,使生成的文本描述语句语法结构更加清晰。
1 视频描述模型
为了解决当前编码器-解码器方法中,因忽视特征语法分析而造成描述语句语法结构不清晰的问题,提出一种视觉场景中基于对象特征语法分析的视频描述方法。总体模型如图1所示,具体分为3部分:①基于编码的视觉场景表示阶段。该阶段又分为编码阶段和构建视觉场景表示,在对视频时空特征和对象特征编码的基础上,结合自注意力机制,构建视觉场景表示模型;②视觉对象特征语法分析阶段。在视觉场景表示中,分析每个对象特征在描述语句中的语法成分;③解码阶段。将分析得到的语法特征向量输入解码端,生成语法结构清晰的文本描述。该方法的关键在于构建视觉场景表示模型和构建对象特征语法分析模型。
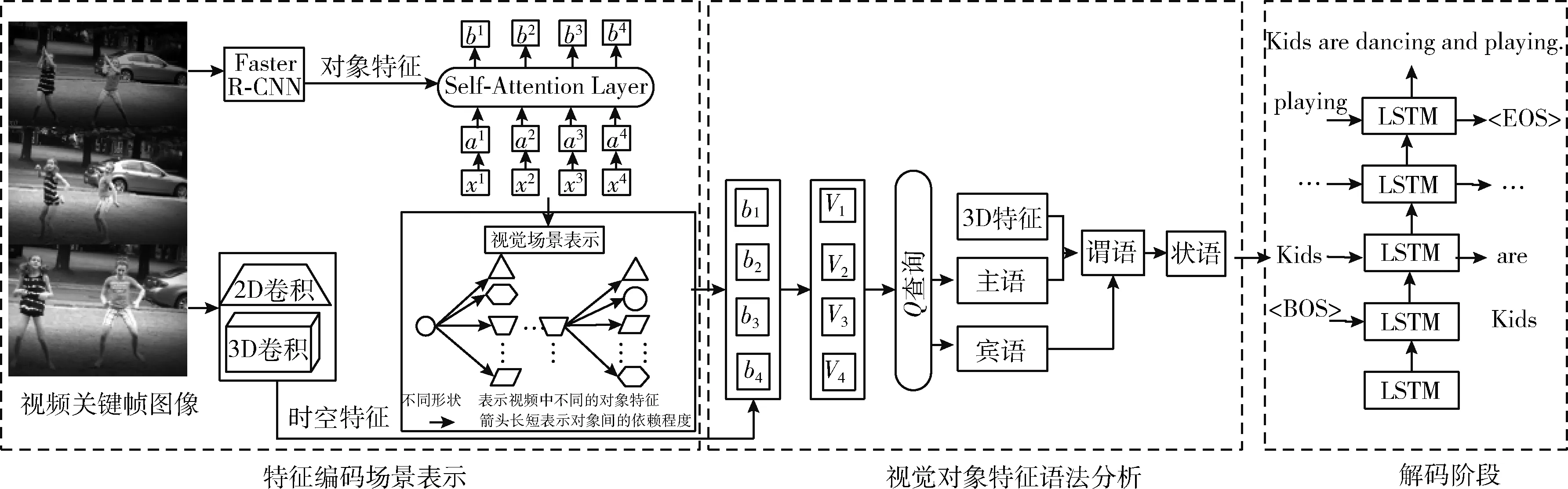
图1 基于场景表示中对象特征语法分析的视频描述方法
1.1 基于特征编码的视觉场景表示
目前,现有文献在视觉编码阶段主要关注单个视频帧的时空特征表示,而较少考虑具有丰富语义要素的视觉场景对视频特征表示的影响。为此,本文结合视觉特征编码和自注意力机制,构建了一种新的视觉场景表示模型,表示视觉场景的语义内容,具体可以分为视觉特征编码和构建视觉场景表示。
(1)视觉特征编码阶段。由于视频场景内容的丰富性和复杂性,无法直接构建场景表示,需要提取视频特征进行编码。首先,从输入视频中选择28帧等间距的视频帧作为输入数据,使用IRV2提取静态特征,表示为p, 使用3D ConvNets[12]学习时序特征,表示为t。然后,将静态特征和时序特征堆叠后的特征作为该视频的全局时空特征,表示为g,g=p+t。 最后,使用Faster R-CNN模型[13]抽取视觉对象特征,输出1×4096维的向量特征。视觉特征包含全局时空特征和视觉对象特征。
(2)构建视觉场景表示模型阶段。视觉特征编码阶段以向量的形式表示视觉特征信息,但缺乏视觉特征之间关联性的描述及视觉场景内容丰富性的表示。因此,在特征编码的基础上,本文构建了一种新的视觉场景表示模型,用于具体描述视觉场景内容及视觉特征间的内部关系。如图2所示,主要分为3个部分:①将抽取的视觉特征输入自注意力机制进行学习;②计算每个视觉特征的自注意力分数;③根据自注意力分数确定视觉特征间的相互依赖关系,构建视觉场景表示。
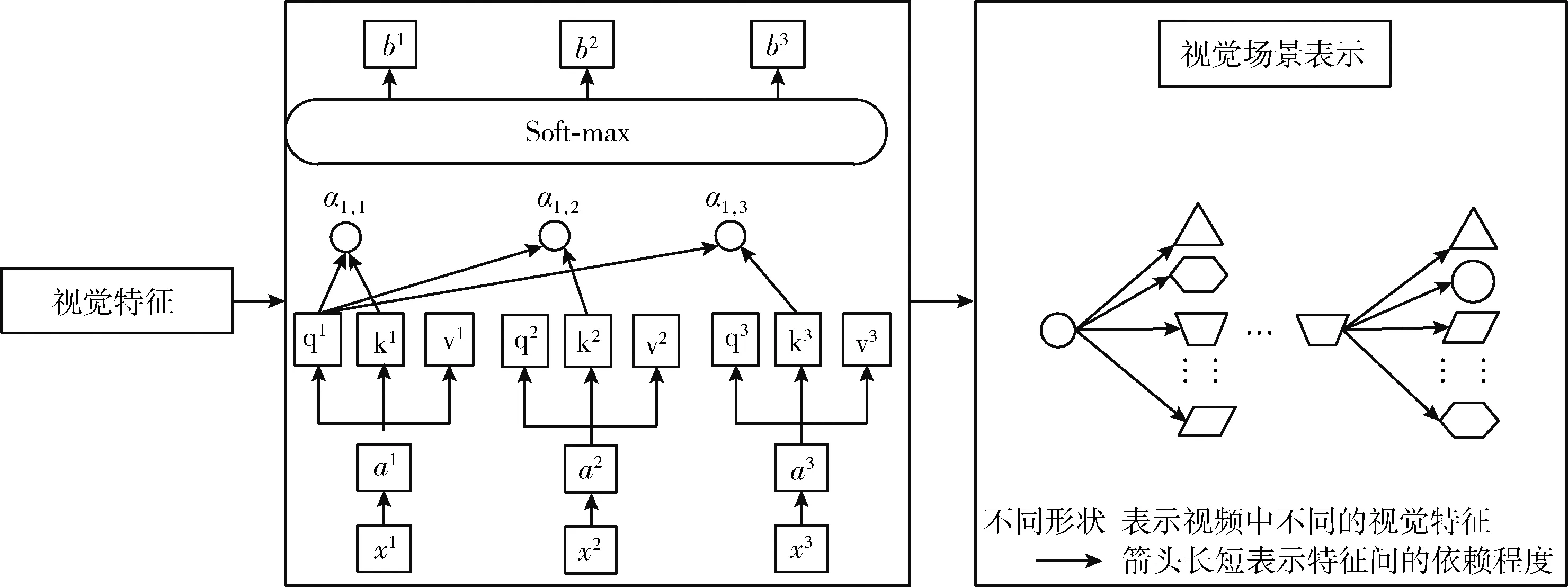
图2 基于特征编码的视觉场景表示模型
由于自注意力机制更擅长捕捉特征间的内部相关性,本文结合自注意力机制构建模型。自注意力机制先对输入信息进行学习,通过线性变换,得到关于对象特征的查询向量序列Q、 键向量序列K和值向量序列V, 如式(1)所示
Q=WQX;K=WKX;V=WVX
(1)
其中,WQ、WK和WV是大小为5×5的待学习参数矩阵,X代表待学习的输入向量。
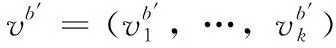
(2)
(3)
其中,dk是Q和K的维数。由于某些视觉特征空间位置信息对视觉内容的表示也至关重要。通过矩阵拼接的方式,加入视觉特征位置信息的嵌入,如式(1)和式(4)所示
(4)
其中,ReLU(·)是激活函数, [;] 表示两个矩阵的拼接,Rx=[X,Y,W,H] 为检测对象的中心坐标,vb为全局时空特征。
视觉场景表示如图3所示,图3(a)表示视频关键帧图像,图3(b)表示构建的关键帧图像的视觉场景表示。在视觉场景表示中包含了多个视觉特征及特征间的关系,视觉特征中的对象包含人、车、路、山和树;对象之间存在的关系为:人在路上开车,人可以看见路、路旁的山和山上的树。
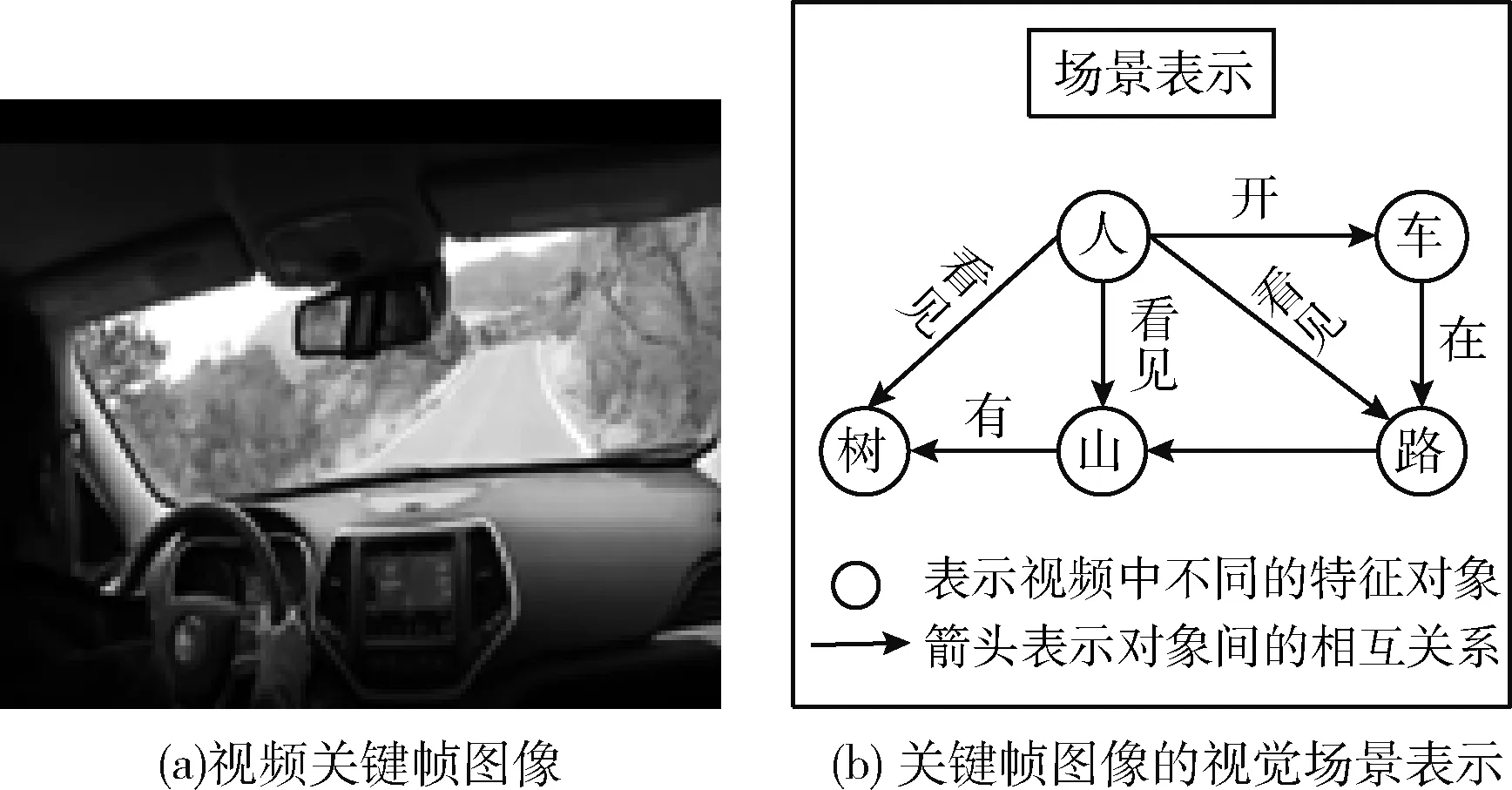
图3 视觉场景表示
本文通过构建视觉场景表示模型,描述视频特征间的内部相关性,较为详细地表示丰富的视觉场景内容,有利于对视觉场景表示中的对象特征进行语法分析。
1.2 视觉对象特征语法分析
尽管已有文献提出关于语法表达[14]的视频描述方法,但仍存在一些不足。以文献[14]为例,该方法依赖于词性标签,限制了生成描述语句的多样性。通过研究发现,目前有关语法表达的视频描述方法,过于依赖句子模板和词性标注,缺乏对同一个词在不同视觉场景描述语句中的语法成分分析过程,存在描述语句语法结构不清晰的问题。为此,本文在视觉场景表示的基础上,构建一种视觉对象特征语法分析模型,具体分析每个视觉对象特征在该视频场景描述语句中的语法成分,包括主语、谓语、宾语和状语。如图4所示,该模型分为3个部分:①通过设置视频主题查询主语和宾语对象特征;②结合C3D特征分析谓语特征;③根据主语、谓语和宾语对象特征分析状语信息。
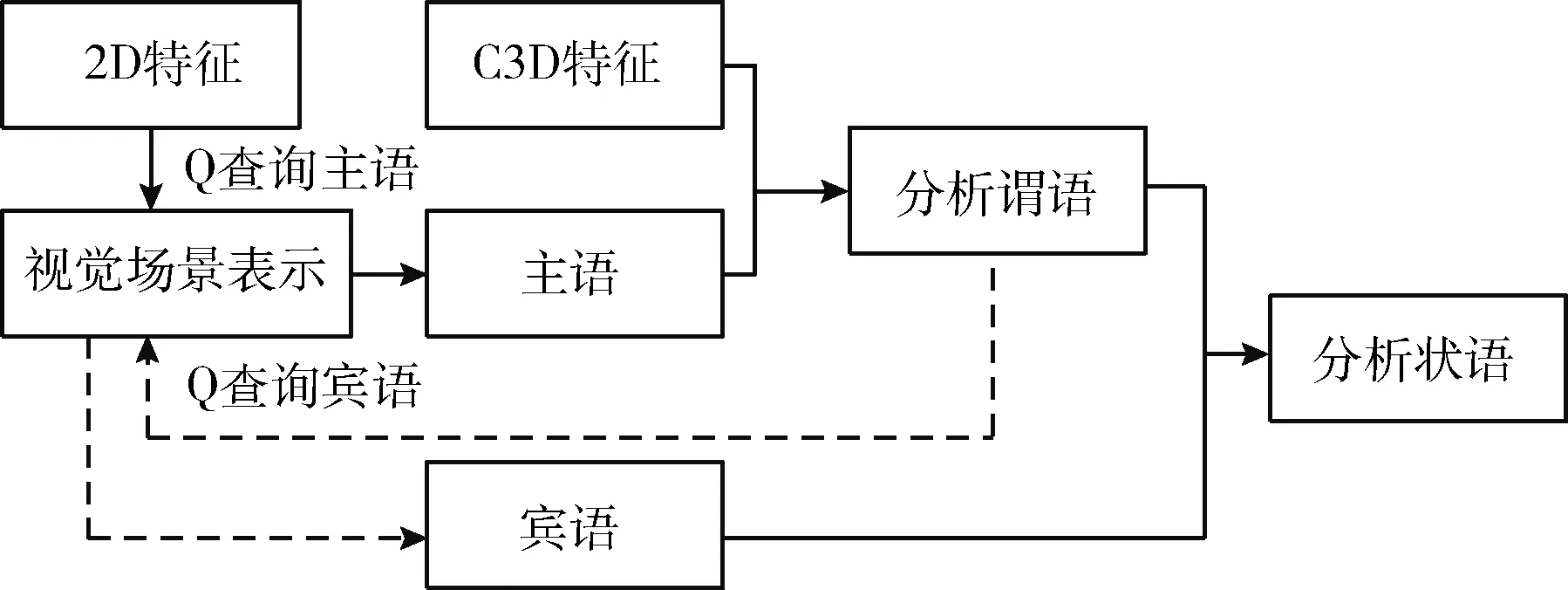
图4 视觉对象特征语法分析模型
根据对数据集标注描述语句的观察可见,主语和宾语更依赖于视频的外观特征信息,谓语更依赖于时间序列信息,状语信息在视频中不能直接捕获到,需要根据主语、谓语和宾语一起进行分析。因此,在对象特征语法分析模型中,通过在视觉场景表示中设置有关视频主题的2D特征进行Q查询,分析视频中适合做主语的对象特征,具体数学描述如式(5)和式(6)所示
s=argmaxps(vb′,g)
(5)
ps=softmax(faat(g,vb′))
(6)
其中,g为视频的全局时空特征,vb′是视觉场景表示中的所有对象特征,argmax(·)是求最大值函数,softmax(·)是激活函数,faat(·)是上述式(3)的注意力计算函数,s代表主语对象特征,ps表示主语对象特征的注意力分数。选择注意力分数最大的作为主语对象特征。谓语表示主语和宾语之间的主从关系,较为依赖时间序列信息,因此,根据主语对象特征和C3D特征分析谓语特征,具体数学描述如式(7)和式(8)所示
v=argmaxpv(s,t)
(7)
pv=softmax(faat(s,t))
(8)
其中,t为C3D时间序列特征,v代表谓语特征,pv表示谓语特征的注意力计算分数,选择最适合做谓语的特征。根据对标注描述语句的观察,宾语依赖于视频的全局特征,因此,该模型根据主语和谓语对象特征在视觉场景表示中选择一个注意力分数最大的作为宾语对象特征,具体数学描述如式(9)和式(10)所示
o=argmaxpo(s,v,vb′)
(9)
po=softmax(faat(s,v,vb′)
(10)
其中,o代表宾语对象特征,po表示适合做宾语的对象特征的注意力分数。由于状语信息是整个句子的修饰成分,表示视频发生的地点,较难在视频中直接获得。根据对标注语句的观察,状语对象特征,需要结合主语、谓语和宾语对象特征进行分析,具体数学描述如式(11)所示
adv=g(α*s+β*v+γ*o)
(11)
其中,adv代表状语的对象特征语法向量, g(·)是一个加权求和函数,α、β、γ是主语对象特征、谓语特征和宾语对象特征对应的权值参数。本文根据状语与主语、谓语在描述语句中的关联关系,分别设置α、β、γ为0.4,0.2,0.4。
本文构建对象特征语法分析模型,增加了针对视觉特征文本语义分析的过程,根据自然语言的句法结构,分析场景表示中对象特征在描述语句中的语法成分,生成语法结构清晰的文本描述。
1.3 基于视觉对象特征语法分析的特征解码
在视觉对象特征语法分析模型中,对视觉场景表示中的每个对象特征进行语法分析,得到由主语、谓语、宾语和状语特征向量构成的特征元组 {s,v,o,adv}。 其中,由特征向量构成的特征元组包含描述语句中的不同语法成分,因此,解码器可直接对特征向量进行解码,输出描述语句。
本文解码器采用单层LSTM深度神经网络,LSTM连接语法特征元组 {s,v,o,adv} 的输入,如式(12)所示
ht=LSTM(xt,ht-1,mt-1)
(12)
其中,x∈{s,v,o,adv} 特征元组,具体表示特征元组中的每一个语法特征ht表示t时刻的隐藏状态,ct表示语法特征向量在t时刻的输出,记忆单元mt-1表示记忆单元。输出经过softmax层,依次转换成单词,在t时刻输出的文本语义描述表示,如式(13)所示
logp(yt|y1,y2,…,yt-1)=f(ht,ct)
(13)
同时,使用“BOS”和“EOS”作为LSTM生成句子的开始词和结束词,将每一时刻生成的词连接成为文本描述,作为输出结果。例如,一个视频的主要描述内容是孩子们在院子里跳舞,在经过编码阶段和视觉对象特征语法分析阶段后,可以得到由语法特征向量组成的语法特征元组 {s,v,o,adv}。 然后,将语法特征向量依次输入到LSTM单元中,出现“BOS”之后,表示描述语句开始生成,第一个时间点输出单词Kids,持续输出,直到出现结束词“EOS”,表示输出结束,生成最终的描述语句“
1.4 损失函数
由于本文方法是进行端到端的训练,要使语法分析损失和生成的视频描述损失的加权和最小。因此,损失函数定义如式(14)所示
L=Lc+βLp
(14)
其中,β是一个平衡两项的超参数,Lc是生成的视频描述损失函数,Lp是语法分析的损失函数。语法分析的损失函数公式表述如式(15)所示
(15)
其中, {s′,v′,o′,adv′} 表示是由自然语言处理工具集nltk[15]生成的语法特征向量组件。视频描述损失函数公式表述如式(16)所示
(16)
其中,yl表示人工标注的句子,l表示句子中的词语,y表示生成的视频描述语句,N表示生成的句子数量,M表示单词数量。
本文方法在训练过程中,所有样本的目标数K是固定的,允许进行小批量训练。从每个视频的关键帧提取K个对象区域的区域空间特征,生成视觉场景表示。在本文的实验中,设置K=10, 如果检测到的对象超过K, 则选择置信度最高的K个对象。如果小于K, 则其中一些区域会出现多次,这时可以利用位置信息来区分重复区域。在测试过程中,输入视频的K可以是任意的,如果出现对象缺失的情况,在选择的对象区域中加入额外的空区域进行弥补。
2 实验分析
2.1 数据集和实验设置
本文分别在公共数据集(MSVD数据集和MSR-VTT数据集)上进行实验。其中,MSVD是一个开放域视频描述数据集,包含1970个视频,并配备了80 839句英文描述,视频内容较为简单,多是单一生活场景或动作(如切菜、锻炼)。本文选用1200个视频作为训练集,100个视频作为验证集,测试集包含670个视频。MSR-VTT包含10 000个视频片段,本文采用了数据集原有的分割方法,训练集有6513个视频,交叉验证集有497个,测试集有2990个视频。
本实验采用 Python3.6编程并使用Pytorch1.1进行模型训练,实验在Linux操作系统上进行。实验中GPU为NVIDIA Titan XP,内存大小为62 GB,硬盘大小为100 GB,批量大小设定为64,固定的学习率为1×10-4,采用CUDA10.0与cuDNN加速。
2.2 评价方法
本文选择目前主流的评价标准BLEU[15]和SPICE[17]。其中,BLEU通常在机器翻译中使用,通过计算生成的语句和候选短语之间n-gram的相似性。CIDEr将生成的每个句子看成文档,表示成TF-iDT向量形式,计算参考句子与生成句子间的相似度。SPICE基于图的语义表示来描述对象和对象关系。以上3个评价指标结果与人工判断的结果具有较高的相关性。
2.3 实验结果与分析
本文方法采用AdaMax优化器,在MSVD训练集为1200个视频,训练结果如图5(a)所示,训练次数大约在100次时开始收敛,我们认为是由于训练集数量较大,训练次数较多,模型收敛性较好。因此,在该数据集上未出现过拟合现象。在MSR-VTT训练集为6513个视频,训练结果如图5(b)所示,训练次数大约在150次时开始收敛,原因同上,因此,在该训练集上未存在过拟合现象。
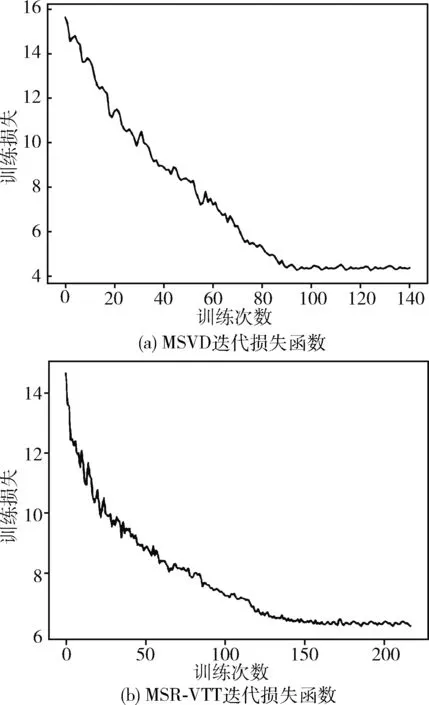
图5 迭代损失函数
表1和表2分别表示了本文方法和其它基于编解码器模型的视频描述方法在MSVD和MSR-VTT数据集上的对比结果,由于SPICE评价指标目前针对图像文本描述进行评价,因此,本文不作对比。由表1和表2可以看到,本文方法在BLEU_4和CIDEr都得到了较高的分数(评价分数越高,说明该方法越好),这是因为本文方法在编码阶段,利用2D、3D和Faster R-CNN模型抽取较为准确的视频特征,并且结合自注意力机制构建一种新的视觉场景模型,可以有效捕获特征间的依赖关系。在解码之前,提出对象特征语法分析模型,结合C3D特征,可以较为准确地分析主语和宾语之间发生的动作,即谓语特征信息,结合主语、谓语和宾语特征可以分析出视频发生的地点信息,即状语信息。因此,进一步优化了模型的描述效果。

表1 MSVD数据集多个方法实验结果对比

表2 MSR-VTT数据集多个方法实验结果对比
为了分析不谓语和状语对生成视频描述语句的影响程度,本文在MSVD和MSR-VTT数据集上进行了实验,实验结果见表3和表4。其中,SA代表自注意力机制,v表示对谓语的分析,adv表示对状语的分析。从表3和表4可以看出,同时对谓语和状语进行分析,评价指标分数最高。这是因为在描述语句中,主语和宾语依赖于视频外观特征,容易获取,但是谓语和状语不易直接获取,且谓语表示主语和宾语之间发生的动作,状语是对动作情况的说明,即动作发生的地点。因此,分析谓语和状语可以表示视频中对象间的相互作用关系,提升描述语句的完整性和准确性。
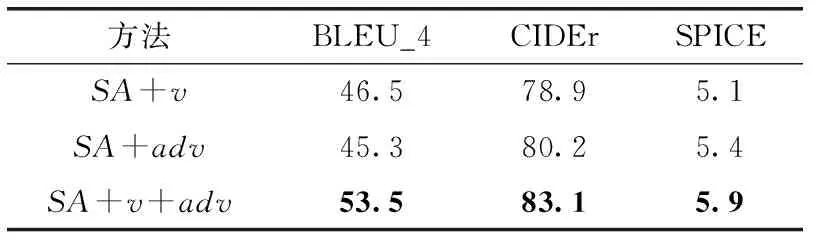
表3 本文方法在MSVD数据集实验结果对比
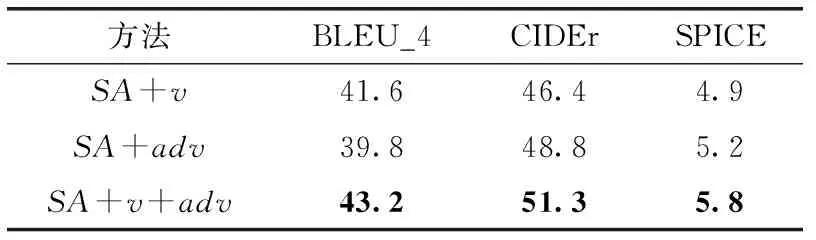
表4 本文方法在MSR-VTT数据集实验结果对比
本文方法分别选取了两个公共数据集进行视频描述的实验对比。如图6和图7所示,对MSVD和MSR-VTT数据集上的视频进行文本描述,通过实验结果可见,本文所提视觉场景表示模型,可以确定视觉特征间的相互关系,如“in a pat”,准确描述了食物和盆之间的包含关系,“tree on the mountain”表示树在山上,描述了两者的存在关系。对象特征语法分析模型,可以详细地分析场景表示中视觉对象特征在描述语句中的语法成分,如“in the kitchen”、“on the road”,表示视频发生的地点信息,即状语信息。因此,本文方法能够较为准确地描述视频内容,生成的描述语句语义性较强,完整性较高,语法结构较为清晰。

图6 MSVD数据集下的视频描述

图7 MSR-VTT数据集下的视频描述
3 结束语
本文提出了一种视觉场景中基于对象特征语法分析的视频描述方法。该方法通过构建视觉场景表示,较为完整地表示视频内容及对象间的依赖关系。此外,通过构建视觉对象特征语法分析模型,可以有效解决编解码器方法中忽略特征语法分析造成描述语句结构不清晰的问题。针对本文构建的语法分析模型中,存在不规则语法结构描述语句有限的问题,我们将在未来的工作中,研究针对不规则语法结构的视频描述方法,生成更加符合人类表达和理解的视频描述语句。
猜你喜欢
疯狂英语·初中天地(2022年1期)2022-07-07
考试与评价·高一版(2020年2期)2020-10-29
疯狂英语·初中天地(2020年9期)2020-10-28
新世纪智能(语文备考)(2020年4期)2020-07-25
疯狂英语·新阅版(2019年11期)2019-09-10
时代英语·高三(2014年5期)2014-08-26
渭南师范学院学报(2014年12期)2014-03-20
语文知识(2014年4期)2014-02-28
小雪花·初中高分作文(2009年8期)2009-11-16
