
电力系统主子站传输通道数据质量评价
2023-02-20 13:03季金豹袁晓峰汉新宇厉文秀杨波
山东电力技术 2023年1期
季金豹,袁晓峰,汉新宇,厉文秀,杨波
(1.国网山东省电力公司日照供电公司,山东 日照 276800;2.国网山东省电力公司五莲县供电公司,山东 日照 262300)
0 引言
电力系统的数据收集与利用对电力系统的安全运行具有重要作用[1-3]。采用高质量的数据对电力系统的生产运营和管理具有不可替代的作用,是电力调度自动化系统高质量决策的重要保障[4-5]。然而,数据的准确性、时效性和完整性等受到调度自动化系统主子站通道数据传输的影响[6-7]。因此,在电力调度自动化系统中,数据筛选方法、数据质量管理方法和评价方法被广泛研究。
在辨识数据传输质量的方法中,应对多个数据传输通道进行综合评价,筛选出数据传输质量高的传输通道,提供最大可靠性的数据。文献[8]提出了一种储能电站接入电网的电能质量评估分析方法,判断数据是否在数据分布的置信区间内,从而完成数据质量辨识。但是,基于分布的数据质量评价对数据的规律性和数据量要求较高,并存在数据量大和数据分布不明显的问题。文献[9]利用相似性原理对数据进行横向和纵向对比,针对传输数据的完整性和准确性等指标进行评估,确保数据传输质量。文献[10]根据密度聚类和相关性分析方法对电力系统数据进行分析。虽然通过数据的相似性能够很好地进行数据的对比,但是大量传输数据横向和纵向的对比对服务器的计算和处理能力是一个严峻的考验。
文献[11]通过灰色关联分析数据的周期性规律,对数据进行重组,分析数据因通信损失、仪表故障等问题致使数据质量下降的现象。文献[12]采用基于灰色关联分析和模糊聚类分析识别典型负荷曲线,辨识数据传输质量,避免因信道错误、仪表故障、设备停运等因素导致的异常数据与缺失值。灰色关联分析法能够根据关联度对专家的主观赋权进行综合评判,但是对于客观上的评价,灰色关联分析法无法给出。文献[13]利用层次分析法、熵权法和CRITIC 法对数据进行多方面综合评价,评估数据传输的质量。文献[14]针对评价指标的主观与客观权重的权衡问题,构建了基于层次分析法和指标相关性的方案评价方法。虽然,熵权法能够针对不同的指标客观地赋予权重,但是在当某一类指标数据偏离度较大的情况下,可能会造成对应的权重也过大,从而导致其他指标被弱化的现象[15-16]。
针对灰色关联分析只能应对主观赋权的问题,利用熵权法和自适应线性神经元算法确定指标的客观赋权,提出多属性评价方法和D-S 证据推理的主观和客观证据融合推理方法,从而完成对主子站通道质量的准确评价。该模型同时考虑不同的准则性质和不同的主客观风险偏好,同时对多个数据通道指标综合评价,以确保主子站通道数据传输质量。对山东某地区的主子站传输进行仿真和分析,验证本文所提模型的有效性。
1 主子站数据传输通道多属性评价指标
为了量化主子站各数据传输通道的多方面性能以及对于数据传输通道的需求,从数据传输通道的稳定性和可靠性两个方面建立多属性指标体系。
1.1 数据传输通道的稳定性评价指标
数据传输通道的稳定性评价指标反映的是数据通道的数据带载能力和数据传输稳定程度,从传输通道的自身出发,提出了通道延迟上送次数(Delayed Delivery,DD)、通道数据不刷新次数(Data Not Refreshed,DNR)和传输通道投退次数(Switch Fall,SF)作为主子站传输通道的稳定性评价指标,并设三者指标值分别为IDD、IDNR和ISF。
不同的数据传输通道的DD、DNR 和SF 存在差异,IDD、IDNR和ISF的数值越小,则在数据传输的过程中表示数据的带载能力强,数据传输稳定。因此在分析拓扑结构时,DD、DNR和SF是很重要的指标,能够反映电力系统主子站传输通道传输数据的能力。
1.2 数据传输通道的可靠性评价指标
电力系统主子站传输通道的可靠性指标是定量评价传输通道的基础,反应数据传输中的异常状态。基于IEEE 的主子站传输通道可靠性评价指标选取了3 个指标:平均跳变数据(Average Jumping Data,AJD)、异常数据数目(Number of Abnormal Data,NOAD)和平均异常数据出现次数(Average Frequency of Abnormal Data,AFOAD)建立可靠性指标体系,并设其指标值分别为IAJD、INOAD和IAFOAD。
1)AJD 反映的是电力系统中主子站因为网络的传输bug 而产生数据跳变的平均水平。当电力系统主子站数据传输通道发生波动时,在低可靠性网架结构中会造成数据跳变的情况,直到线路稳定后数据恢复正常。因此在评价可靠性时,AJD 是一个比较有参考价值的指标,其指标值为

式中:NAJD为所有数据跳变次数的集合;μx为第x次跳变持续的时间;IAJD,x为第x次跳变的数据。
2)因为外部原因和网络的设置不同,各种bug和数据乱码的情况时有发生,导致数据传输序列中出现异常数据。出现异常数据时,各个数据传输通道的异常数据不同,因此利用NOAD 和AFOAD 来综合衡量电力系统主子站传输通道数据传输的可靠性。NOAD 反映的是电力系统主子站因外部扰动或者系统bug出现的异常数据数目,其指标值为

式中:NNOAD为所有异常数据跳变次数的集合;ϑx为第x次异常数据持续的时间;INOAD,x为第x次异常数据数目。
3)AFOAD反映的是电力系统主子站因外部扰动或者系统bug出现异常数据数目的平均水平,其指标值为

2 数据通道多属性评价优选模型
2.1 基于聚类分析法的多方案赋权
在实际工程中,多位专家对于传输通道数据质量的评价方案存在差异化,因此需要对多位专家方案进行评估,确定最终统一的方案。采用数据处理速度快、计算简便的K-means 算法对多专家意见进行聚类赋权,对于所含方案数多的类型赋予一个较大的权重,相反则赋予一个较小的权重,使得方案的差异化能到充分评估。
假设有n个专家和m个评价指标,根据专家意见,构建n×m的数据评价矩阵[17],如式(4)所示。

式中:zij为第i个专家所提供方案的第j个评价指标数值。
通过K-means 算法将所提需求方案分为k类,第b类方案的聚类中心和所含方案数分别为cb和Nb。为了充分准确评估各个专家方案对于整体方案的影响,计算各方案的占比权重。假设专家i所提方案属于类别b,则该方案的权重可以表示为
对上述权重进行归一化处理,即
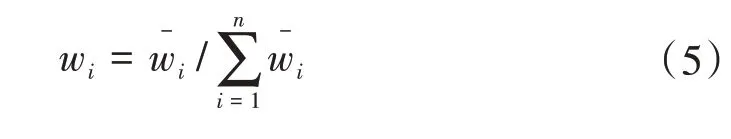
虽然,K-means 算法具有计算速度快,工程应用能力强的特点,但是在聚类时必须提前知道数据有多少类或组,不同的聚类数会直接影响聚类结果。因此,基于轮廓系数法,对K-means 算法进行改进,选出最优的聚类数值k。
轮廓系数法的核心指标是轮廓系数(Silhouette Coefficient,SC),在类别b下的轮廓系数定义如式(6)所示。

式中:kPCH为凝聚度,表示专家l所提方案与同簇的其他方案的平均距离;kDOS为分离度,表示专家l所提方案与最近簇中所有样本的平均距离。

式中:E(zi,z)l为专家l所提方案zl与同簇的其他方案zi的距离。
求出所有样本的轮廓系数后再求平均值就得到了平均轮廓系数。平均轮廓系数的取值范围为[-1,1],且簇内样本的距离越近,簇间样本距离越远,平均轮廓系数越大,聚类效果越好。因此,平均轮廓系数最大的k便是最佳聚类数。
2.2 主子站通道质量的客观评价
基于熵权法的客观赋权能够根据信息的重要程度来确定客观权重,熵值越小,表明信息量越多,相应的权重也就越大[18]。首先,数据评价矩阵中指标值越大表示越优秀指标定义为正向性指标,指标值越小表示越优秀的指标定义为负向性指标。因此,正向性和负向性指标的计算过程如式(9)和式(10)所示。
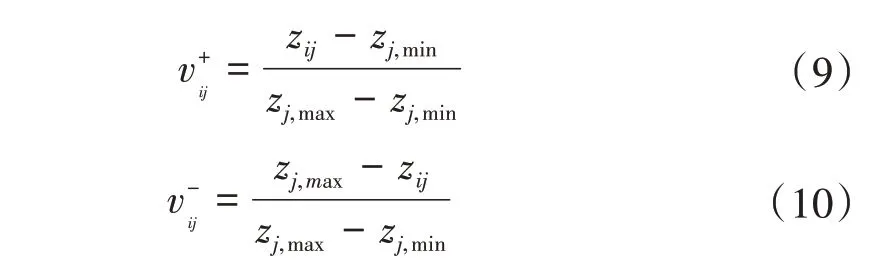
对正向性和负向性指标进行归一化处理,归一化后的第i个样本的第j项指标表示为

第j个指标的熵值ej表示为

式中:K=1/lnm。如果pij=0,则定义
因此,熵权值的表达式表示为

2.3 基于自适应线性神经元的熵权法
熵权法能够针对多个指标确定指标权重,但是可能会出现一类指标数据值离散程度大,从而导致指标的权重值过大,致使其他类型指标权重值偏小,出现数据淹没现象,严重影响数据分析。基于自适应线性神经元算法将熵值法确定的指标初始权重作为自适应线性神经元算法的初始权重,通过迭代校正确定数据指标权重[19]。改进后的熵权法算法流程如图1所示。

图1 改进后的熵权法流程
通过自适应优化得到权重的期望值Ej为

当实际值Rj和预测期望值Ej不等时,存在计算误差为

式中:ERR为实际值与预测期望值的预测误差。
采用误差梯度下降算法不断地调整权重为

式中:负号表示梯度下降;η为比例系数。

因此,权重的更新迭代表达式为

3 D-S证据融合
D-S 证据理论能够在无先验概率的前提下对信息进行融合和推理,为主观和客观证据的分析融合提供了理论基础[20-21]。基于主观和客观评价方法获得的各项指标权重wa和wb,通过夹角余弦函数表示两者之间的相似度,即
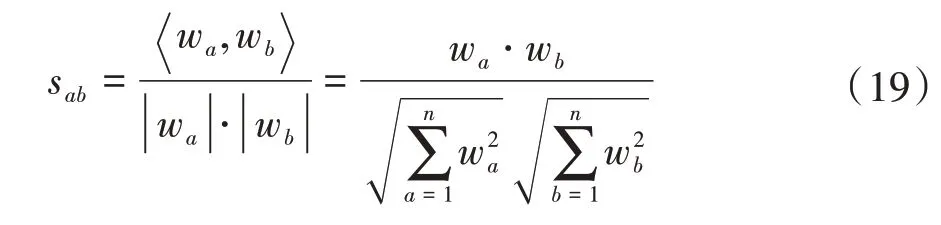
为了判定证据之间的矛盾程度,需先求得某一证据与其他证据之间的平均相似度


通过对权重进行重新分配,确定各个指标在整个数据评价中的占比权重为

结合主观和客观因素的电力系统主子站通道质量动态评价可以表示为

式中:Zn为样本通道的第n个评价指标值。
4 实例分析
将多属性评价优选模型和证据推理模型植入到主子站传输网关的边缘计算中,实现通道的优选。根据主子站的传输数据确定数据规范化后的系统指标数据参考值,如表1 所示。电力系统主子站通道的数据质量评估是高质量数据应用的基础。选取3个主子站通道数据进行评估,典型日的逐时电负荷曲线如图2所示。

表1 评价指标的参考值
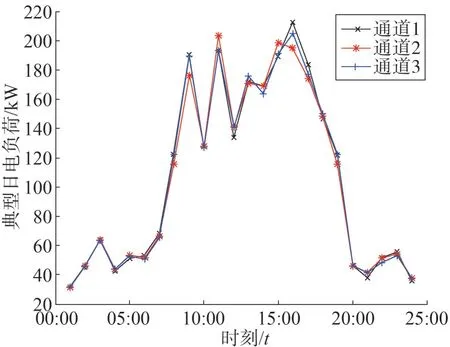
图2 典型日传输通道的负荷
图2 中只展示24 h 整点的数据,其中,每小时内还包含60 个数据,因为数据量庞大,不做详细展示。此外,通过选取6 个指标来评价通道数据质量,具体包括:数据的延迟上送、通道数据不刷新、数据跳变、异常数据数目、异常数据出现次数和投退次数。此外,根据专家意见,获得评价指标的数据评价矩阵如表2所示。

表2 评价指标的数据评价矩阵
通过多属性评价优选模型和证据推理模型计算得到6 个评价指标的权重,得到6 个主观评价的证据源信息,如表3 所示。表3 中,wal为第l个主观评价获得的指标权重,l∈{1,2,3}。

表3 六个评价指标的主观权重
通过改进的熵权法计算得到各个评价指标的客观权重值,如表4 所示。表4 中,wbu为第u个主观评价获得的指标权重,u∈{1,2,3,…,6}。

表4 客观评价的指标权重
通过对3 个主子站通道的动态质量的主观评价、客观评价和本文方法的3 种情况进行对比,评价结果如表5所示。从表5中可以看出,通过证据融合可以看出对于“通道样本2”的数据支持度最高。按照信度函数值最大化的原则,选择通道样本1 作为当前数据传输通道的最优选择。此外,从表5 中可以看出,本文所提出的主观和客观相融合的证据推理的结果支持度更高,能够更全面评价数据并给出结果。

表5 通道样本的评价值
为了验证所提方法的有效性,将本文方法与网络大数据评价、最大流方法、熵值法和CRITIC 4种评价方法结果进行比较。图3和表6分别展示了上述5 种方法的评价值及本文方法与其他4 种方法的数据评价值和相对误差。从图3和表6中可以看出,本文提出的方法与其他4种数据动态评价方法相比,数据比较接近,能够保持一个比较高的数据精度。此外,本文方法与其他4种方法的数据相对误差也较小。

图3 5种评价方法的对比

表6 本文方法与其他4种方法的相对误差 单位:%
5 结语
提出一种基于多属性评价分析和D-S 证据推理的主子站通道质量动态评价模型,依据D-S 证据推理方法,结合主观和客观评价的信息进行融合,对主子站通道的数据质量进行动态评估,相比于主观或者客观的单一评价方法,考虑主观和客观相融合的多属性评价分析方法能够克服单一因素对于系统数据评价的影响,使得评价结果更加可靠有效,避免单一方法的局限性和片面性。此外,通过与不同的数据质量评价方法结果进行对比,验证了本文所提模型在主子站通道数据质量评价中能够保证所选择的传输通道具有较好的数据质量,为决策者提供可靠的数据支撑,避免不良数据对决策的影响。
猜你喜欢
中共云南省委党校学报(2022年1期)2022-04-26
当代陕西(2020年17期)2020-10-28
小学生优秀作文(低年级)(2020年4期)2020-07-24
上饶师范学院学报(2020年3期)2020-06-05
人大建设(2018年5期)2018-08-16
东坡赤壁诗词(2018年3期)2018-07-16
宠物世界·猫迷(2017年9期)2018-01-22
浙江师范大学学报(自然科学版)(2016年2期)2016-09-05
应用科技(2015年5期)2015-12-09
语言与翻译(2015年1期)2015-07-18
