
一种竞争自编码器的半监督异常检测方法
2023-02-17 06:23汪子璇关东海汤丽君袁伟伟燕雪峰
小型微型计算机系统 2023年2期
汪子璇,关东海,汤丽君,袁伟伟,燕雪峰
(南京航空航天大学 计算机科学与技术学院/人工智能学院,南京 211106)
1 引 言
随着信息时代的发展,各个领域的数据以时间序列的形式被采集,时序数据呈爆炸式增长,但是其中存在的异常数据可能发展为严重故障,所以对时序数据进行异常检测至关重要.如果能够提前检测出时间序列的异常,以便工作人员及时采取措施并解决潜在问题,避免严重事态发生,减小损失.
根据实际应用情况,异常数据很难收集和判定.目前同于时间序列异常检测的方法主要包括随机森林传统的最近,深度学习展现出了强大的表示能力,已有的研究通常从有监督、无监督的角度出发,使用卷积神经网络(CNN)[1]、长短期记忆网络(LSTM)[2]、循环神经网络(RNN)[3],深度神经网络DNN[4]等基本的神经网络在时间序列上进行建模,实验取得了不错的结果.但综合检测指标F1效果不佳.分析原因有以下几点:首先,样本固有的不均衡性,异常样本的占比非常低,不足以支撑模型训练学习异常数据分布,使得模型极易陷入过拟合,降低其泛化能力;其次,有监督的方法过分依赖标签数据,数据标注是个问题,人工标注耗时耗力,无监督的方法大多通过线性投影和变换建立的,不能处理时间序列隐藏的内在相关性中的非线性;最后,它们进行异常检测的判定方法通常均需要设定阈值,然而最佳阈值的选定较为困难,不能使模型达到最优状态.
近些年,自编码器框架被提出,通过减小样本重构误差和潜在向量间的距离来构建深度学习模型,同时受文献[5]中生成性对抗网络(GAN)思想的启发,为了解决上述的问题,基于半监督的思想,使用长短期记忆神经网络(LSTM)设计一种竞争机制的自动编码器,避免了设定阈值的问题,实现了时间序列的异常检测,该模型被称为LSNC-AE(based on LSTM Semi-supervised method with Non-threshold Competive AutoEncoder,后续简称LSNC-AE模型).相较于已有的研究,该模型无需使用带标记的异常样本进行训练就可以得到较高的召回率Recall、准确率Precision和均衡分数F1.
论文有4个主要贡献:
1)在时间序列异常检测中引入半监督机器学习方法,同时利用标签数据和无标签数据,学习过程无需人工干扰,也避免了数据集不均衡和模型泛化的问题.
2)提出一种新的自编码器结构,该编码器有一个编码器和两个解码器,两个解码器采用竞争机制对未标记数据进行训练,通过比较损失值大小判定是否异常,该过程无需设定阈值.
3)在数据处理中引入了滑动窗口的方法来丰富数据集,解决了异常样本少的问题.
4)针对上述提出的模型和方法,设计了多组对比实验,文中提出的模型都表现出了比传统方法更优异的性能.
2 相关工作
时间序列的异常检测(Anomaly detection)是从序列中识别不正常的点或片段,典型的时间序列检测示意图如图1所示.另外,有效的异常检测广泛地被应用在多个领域,例如网络安全检测、天气分析、大型工业设备维护等等,传统的方法有基于规则处理[6],通过判断行为是否和异常规则相似,但是它受限于专家知识,规则库可能不完善;基于统计学的方法[7]需要假设数据服从某种分布,然后利用数据进行参数估计,但对假设依赖比较严重.

图1 含有异常点的时间序列示意图Fig.1 Time series containing outliers
目前,对于时间序列的异常检测在深度学习领域开展了广泛的工作,归纳如表1所示.从模型的结构设计上,基于生成性对抗网络(Generative Adversarial Network,GAN)的方法是近些年研究的热点内容,文献[8]为捕获数据中的时间相关性,将原始多元时间序列输入转换成具有图像结构的多通道相关矩阵,并设计带有Attention机制的GAN网络来建立时间依赖关系;文献[9]中以LSTM-RNN为基础构造GAN模型,在多个数据集上进行实验,虽然能达到较高的召回率(Recall,R),但F1最高只有77%,有较高的误报率.其次,就“三个臭皮匠顶个诸葛亮”的集成思想,文献[10]首先提出独立集成框架,包含多个具有不同网络结构的自编码器,为进一步实现所有的自动编码器都重建相同的原始时间序列,紧接着提出共享框架,让不同的自编码在训练阶段能够交互;再者,文献[11]中先通过从未标记数据中找出可靠的正常数据和潜在的异常数据,再运用三元组损失,使同类样本之间的距离尽可能缩小,不同类样本之间的距离尽可能放大从而实现检测;与此同时,迁移学习和主动学习相结合,文献[12]中为实现跨时序数据集的异常检测,通过在现有的标记数据集(源数据集)上训练一个异常检测模型来检测新的未标记数据集(目标数据集)中的异常,但是最需要注意的是迁移学习要求源域和目标域有潜在的相似性,而不同数据集很难有较高的相似性.
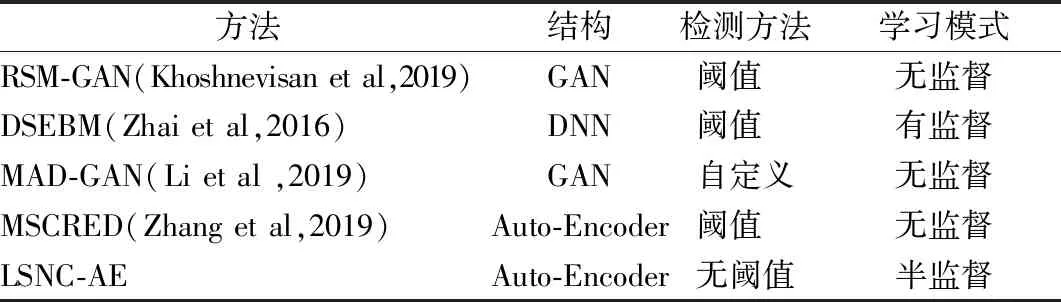
表1 模型对比表Table 1 Modle compare
从异常检测方法上,首先,通过设定阈值来实现,如文献[13]基于损失函数定义的异常分数,通过最优化准则来获得阈值;文献[14]对误差做加权平均的平滑处理,并自定义公式根据平滑后的数据计算阈值;也有通过取重构误差的中值作为离群点的阈值;文献[15]比较重构误差与通过分析发现,在阈值的选择和设定上很难找到最优值,其次,通过自定义评判机制,将GAN网络的鉴别和重构误差经过公式结合作为异常标准,最后,通过分类的方式来实现,将未标记数据传进训练好的k个独立模型当中,并计算未标记数据的不确定度并降序排列,从而正常或异常的概率而进行分类;文献[16]将测试数据传进训练好的模型后,再通过softmax函数,进行分类得到检测结果.以上都需要对数据进行较为复杂的迭代选择,所以本文想要选择无阈值且判定简单的方式来作为检测准则.
自编码器网络因为其特有功能,在时序数据的异常检测方面取得了一定的成果.文献[17]提出了一个孤立点检测框架,该框架包含了多个基于LSTM神经网络的自编码器;文献[18]构造了具有“编码-解码-编码”特殊结构的自编码器;文献[19]提出卷积神经网络和递归自动编码器相结合的异常检测模型,利用卷积层和池化层提取流量窗口的空间特征,这些方法在检测效果上表现出较好的性能,但需要对数据进行专业的特征选择和特征构建等复杂的预处理的过程.通过“编码器—解码器”的网络结构对输入数据压缩再还原的方式,训练时尽量减小重构样本与原始样本的重构误差,使模型学习原始样本的分布,而在测试阶段若重构误差大于设定的阈值则视为异常.
综上相关研究工作,本文模型使用长短期记忆神经网络(LSTM)设计了一种竞争机制的自动编码器模型,将其应用于时间序列数据的异常检测.
3 相关技术介绍
本章将对设计模型所涉及到的相关技术进行介绍.其中,3.1节给出LSTM网络的相关概念和网络结构介绍;3.2节对自编码器的构造功能等进行介绍;3.3对本章进行总结.
3.1 LSTM网络
LSTM(Long Short Term Memory)网络是改进的RNN神经网络,为解决梯度消失和爆炸问题而应运而生的,同时能够更好地解决长期依赖的问题.本文的研究对象是时间序列数据,时间点之间的关系非常重要,所以利用LSTM(Long Short Term Memory)网络可捕捉长距离时序数据之间关系的特点,将其作为模型的基本网络结构.
根据图2可知,通过几个门进行控制,可完成一个神经元的内部处理,对过去长期数据形成记忆.
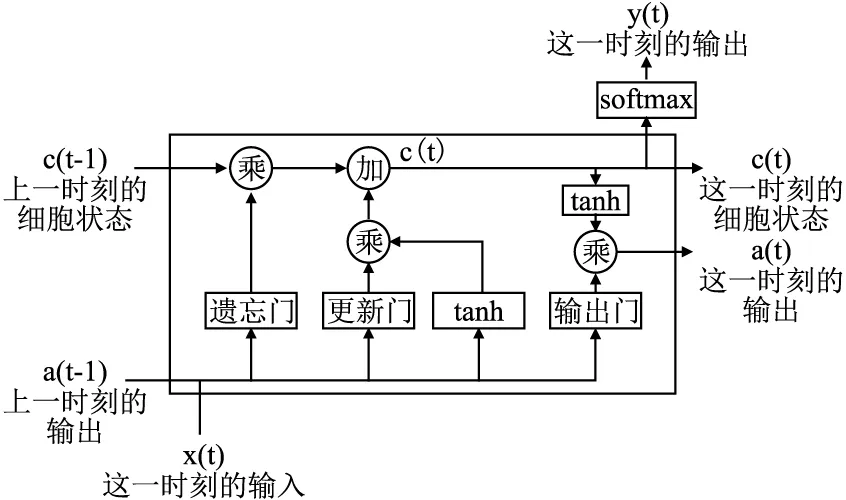
图2 LSTM模型的一个神经元结构Fig.2 LSTM model of a neuronal structure
LSTM网络虽然较RNN网络在性能上有一定的提升,但是在异常检测的过程中,异常数据的发现需要其他辅助,因此本文在使用LSTM网络结构的基础上引用自编码器进一步实现时间序列的异常检测.
3.2 自编码器网络
为了进一步提取时间序列数据的特征,在这里采用自编码网络,可通过重构后的时间序列与原始时间序列的误差来判断异常点.以为神经网络要接受大量的输入信息,输入信息量可能达到上千万,让神经网络直接从上千万个信息源中学习是一件很吃力的工作.所以,将数据进行压缩,提取数据中最具有代表性的信息,缩减了输入的信息量,再将缩减的中间数据放到神经网络中学习就能减小网络的负担,加快学习速度.
自编码器的结构是由编码器和解码器构成,主要包括编码层、隐含层、输出层.输入的数据经过编码转换为中间变量,接着又通过另外一个神经网络去解码得到与输入数据一样的生成数据,通过比较两个数据,通过最小化两者的重误差,进而训练网络的参数,在该模型中,我们使用的就是3.1节提到的LSTM网络.
3.3 小 结
本章节主要对文章使用的两个网络结构进行介绍,同时,鉴于LSTM网络可捕获长期数据的特征以及传统检测方法需提前设定阈值的局限,本文基于LSTM及自编码器网络设计一种无阈值的半监督竞争学习模型,具有一个编码器,两个解码器的构造,在第4章节会重点介绍异常检测模型.
4 异常检测模型
本章将对所涉及的模型进行详细的介绍.其中,4.1节给出一些基本定义,4.2节对数据处理进行了详细的描述,4.3节具体的介绍了模型结构,4.4是本章小结.
4.1 基本定义
异常样本的定义:设在一个时间点t,该模型将在t时刻之前长度为Tw的数据(包含t时刻数据值)作为一个被检测的样本,如果在Tw的时间段中检测出异常点,则定义该样本是异常样本(正样本),否则就是正常样本(负样本)
数据集描述:设有一个时序数据集D,其表示如下:
D={(X1,Y1),(X2,Y2),…,(XN,YN)}
(1)
含有N个样本,Xi∈RTw表示一个时序数据的样本,Tw表示样本的长度,Yi∈{(0,1)}是数据集D每个样本的标签,Yi=1代表该样本为正样本,Yi=0代表该样本为负样本.这个大的数据集被训练和测试阶段分成以下几个小数据集,训练阶段有两个类型的时序数据集:正常数据的训练集Dn,以及含有正常和异常数据的未标记数据集Du,表示如下:
(2)
(3)
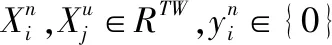
4.2 数据处理
对于本文所提出的模型,数据处理是至关重要的一部分,数据处理分为3大部分,划分数据集、数据归一化处理、滑动窗口处理.
4.2.1 划分数据集
因为模型本身的特点,根据3.1节的数据集描述可知需要对数据集进行多次处理,首先是数据集的划分,需要将数据集D划分成3个小的数据集,用于训练的两个数据集Dn1、Du1,同时要使两者大小的关系满足‖Dn1‖=‖Du1‖,还有用于测试用的Dt1.
4.2.2 归一化处理
由于雅虎数据集的特点,收集到的每条数据的值分布区间大有不同,为了能够在它们之间能够更加公平地比较,同时更准确分析异常样本的分布特点,需要对数据进行归一化处理,将所有的数据值控制在[0,1]范围内,对于每条数据的每个点进行如下的归一化处理:
(4)
其中,x是某条序列中正在被归一化处理的点的原始值,xmax,xmin分别是该条序列中最大和最小的值,x′是原始值x被归一化后的值.并更新数据集得到两个训练集Dn2、Du2和一个测试集Dt2.
4.2.3 滑动窗口处理
由于异常数据的珍贵性,在训练过程中,会出现适合做训练集的数据太少,不足以支撑运转构造模型,针对这一问题,同时为了有效地从时序数据中学习,使用滑动窗口的方法对其进行处理来丰富数据集,具体处理方式见图3.
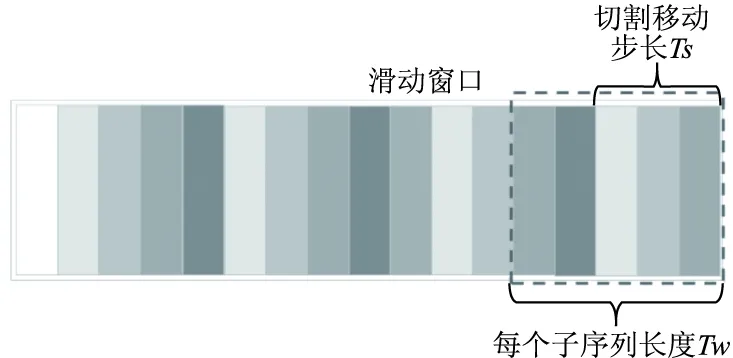
图3 滑动窗口用于富集化Fig.3 Sliding windows are used to enrich data sets
采用了窗口大小Tw和步长Ts的滑动窗口,将较长的时间序列X分成一组子序列:
X={Xi,i=1,2,3,…,m}
(5)
(6)
本模型使用不同的Tw和Ts来捕获时序的不同状态,最终选择最佳Tw、Ts,在这里Tw={50×i,i=1,2,3,…,10},Ts={j,j=1,2,3,…,10}.经过滑动窗口处理后,得到最终的训练集Dn、Du和测试集Dt.
4.3 无阈值竞争学习自编码器的模型结构
本章节将详细介绍无阈值竞争学习自编码器,4.3.1节首先介绍了LSNC-AE的体系结构,4.3.2节引入目标函数,4.3.3节展示了如何优化该模型,4.3.4是本章小结.
4.3.1 模型结构
提出的模型如图4所示.主要由3个模块组成:编码器网络Enc,正常数据解码器网络Dec1,异常数据解码器网络Dec2.其中,编码器使用长短期记忆网络(LSTM)提取时序样本的特征,并且使用了Relu激活函数优化中间层输出的分布,从而来提高训练速率,两个解码器有相同的网络结构并且与编码器呈对称,但是独立训练各网络的参数.
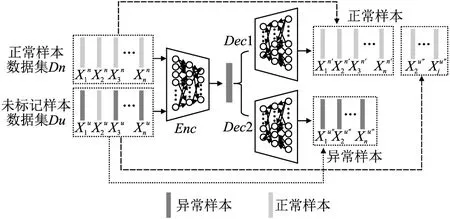
图4 LSNC-AE模型结构图Fig.4 LSNC-AE model architecture
(7)
(8)
(9)
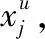
4.3.2 目标函数及模型训练
训练过程目的是为得到一个编码器两个解码器的相关参数,最小化重构样本与原始样本之间的重构误差来反向传播更新网络的参数,使每个模块达到性能最佳状态.训练过程中总的损失函数定义如下:
(10)
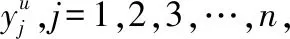
(11)
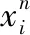
(12)
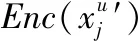
(13)
传进Dec2重构后得到的损失函数Loss2定义如下:
(14)
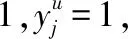
(15)
在这里,为了能够更大程度的区分正常样本和异常样本的分布,这几个损失值均采用均方值作为重建误差,它对异常更加敏感.
(16)
4.3.3 模型优化
在确定目标函数和训练过程之后,最重要是选择对模型的优化,其中,该模型采用了几种不同的优化器进行比较,最后采用了Adam优化器通过反向传播进行参数的优化.具体优化方式图5所示.

优化算法输入:正常样本Xn,未标记样本Xu,编码器参数θE,正常解码器的参数θDn,异常解码器θDu初始化相关参数repeat选择未标记数据集Du和正常数据样本集Dn,并且是使得这两个用于训练的数据集大小|Du|=|Dn|/∗前向传播∗/for 在正常数据集|Dn|中的每一个xni,do Loss0=‖xni - Dec1(Enc(xni))‖22/∗由Dec1得到的重构∗/for 在未标记数据集|Du|中的每一个xuj,do Loss1=‖xuj - Dec1(Enc(xuj))‖22/∗由Dec1得到的重构∗/ Loss2=‖xuj - Dec2(Enc(xuj))‖22/∗由Dec2得到的重构∗/ if Loss1 < Loss2 then: 将这个未标记数据xuj分配给正常编码器Dec1 else: 将这个未标记数据xuj分配给异常编码器Dec2end for使用Adam反向传播优化模型参数Loss0优化参数θE,θDn,Loss2优化参数θDuuntil 收敛
4.3.4 模型测试
测试阶段,采用和训练阶段雷同的方式,将所有的未标记样本分别传进训练好的正常解码器Dec1和异常解码器Dec2中,通过判断损失值的大小来判定数据是否异常,此过程只需比较大小,无需定义阈值.
5 实验与分析
本章将对上述所设计的模型展开详细的实验分析.其中,5.1节介绍了使用的实验数据集,5.2节介绍了实验评判标准,5.3节是具体的对比试验.
5.1 实验数据集准备
本文使用的数据集是Yahoo Webscope S5数据集是一个用于时序异常检测的公开数据集,选取其中的A1Benchmark类、A2Benchmark类(后面简称A1、A2)以及KPI数据集来验证所涉及的模型.A1数据集是从实际网络服务流量的测量值收集而来,异常值是在前期是通过手动标记的,A2数据集是在A1的基础上进行模拟合成的,所以两个数据集具有一定的通性,由于A2数据集里面的异常值过少,无法训练该模型,但因为A1和A2的通性,采用A1数据集训练好的模型来直接测试A2数据集即可.A1Benchmark有67个文件,共有94866个网络流量值,但是只有1699个异常点,考虑到本文设计的模型的特殊性,Dec2是从未标记数据中判别很大可能是异常数据的样本进行训练,所以在前期的数据处理过程中,对未标记样本数据集做了筛选,按照每个文件异常值个数不低于40个来进行筛选作为未标记训练集Du的组成,使得后期在模型训练的时候模型具有一定的稳健性,由表2所示的几个文件组成.

表2 未标记训练集Du异常值分布Table 2 Outlier distribution of unlabeled training set Du
为了进一步验证本模型的普适性,又选择了KPI数据集来证实.KPI由AIOPS数据竞赛发布,它是从各种互联网公司收集的异常标签,包括搜狗、腾讯、易趣等.
模型的新颖性要求正常样本训练集Dn与未标记样本训练集Du集合大小相等,在确定好Du以后来确定Dn,由于A1Benchmark有大量的正常数据,所以Dn能够很快得出,同时由于异常点的缺少,紧接着对在相关数据集进行的上文4.2节的数据处理.KPI数据集数据量大且异常点多,在数据集的划分比较好处理,同样也需要进行归一化等数据处理,这几个数据集在训练集和测试集的划分,如表3所示.
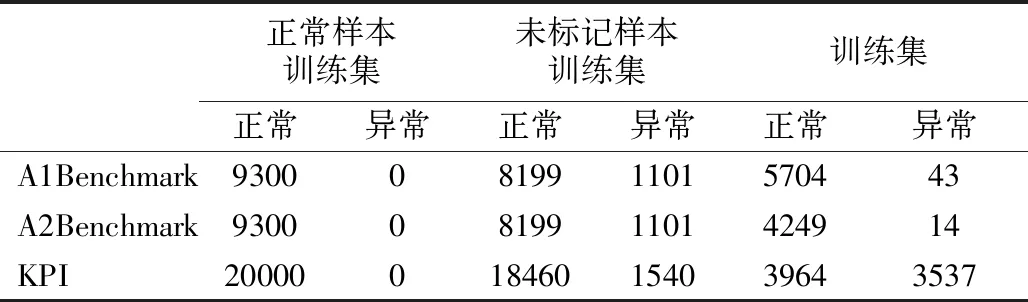
表3 数据集划分Table 3 Dataset partition
5.2 实验设置
实验使用Python3.7作为编程语言,使用Tensorflow1.14版本作为神经网络框架,窗口大小设置为Tw=400,并采用了小批量训练的方式,同时用Adam优化器对模型进行优化,训练轮数根据比较实验结果,Yahoo训练时epoch=125,KPI训练时epoch=100.
5.3 实验评判标准
本实验使用准确率(Accuracy,Acc),精确度(Precision,Pre),召回率(Recall),均衡分数(F1-Score,F1)作为异常检测指标.
其中,Acc表示所有样本中,所有判定结果与真实结果相匹配的占比,表示如下:
(17)
Pre表示在预测为异常的结果当中,有多少是真的异常样本,表示如下:
(18)
Recall表示在所有的异常样本中有多少被真的检测出来了,表示如下:
(19)
由于异常点分布的不均匀且稀少,会出现精确度和召回率在某些情况下可能是矛盾的,因此引入一个综合评价指标
F1分数(F1-score),又称为平衡F分数,是精确率(Pre)和召回率(Recall)的调和平均数,能够更加公平地去评价实验结果,所以本文在以上两个指标的基础上,更着重于观察F1的实验结果,它的表示方式如下:
(20)
其中,TP(TruePositive)表示的是正样本被判定为正样本数;TN(TrueNegative)表示负样本被判定为负样本数,FP(FalsePositive)表示的是正样本被判定为负样本数;FN(FalseNegative)表示的是负样本被判定为正样本数.
针对本文目的是实验异常检测,异常往往会带来严重的损失,所以在时间序列的异常检测中更关注异常样本的召回率(Recall,R)和综合评价指标F1分数(F1-score),同时为了更全面的评价模型的性能,将准确率(Accuracy,Acc)和精确度(Precision,Pre)作为辅助标准.
5.4 实验比对
在本文设计的异常检测模型中,为突出模型创新点的意义,如滑动窗口的有效性,无阈值设定的模型检测的性能等,在本小节设计多组实验比对进行验证.
在LSNC-AE检测模型中,使用了滑动窗口是一大亮点,在丰富数据集的同时能够帮助LSTM网络捕获时间依赖性,实验设计是否使用滑动窗口的实验来评估滑动窗口对时序异常检测的效果.
图6所示是不同指标在3个数据集上的测试分数,通过实验柱状图,我们不难发现,绝大多数情况啊下,有滑窗的模型性能强于无滑窗的模型性能,下面进行具体分析:对于Yahoo的A1Benchmark、A2Benchmark两个数据集,使用滑动窗口后的3个指标分数均高于无窗口模型,能够体现带有滑窗的模型的检测异常的性能得到较大幅度提高;但对于KPI数据集上,虽有滑窗的召回率Reccall和F1高于无滑窗的,但无滑窗的精确度高于有滑窗的精确度,这是因为两个数据集的特点引起的,KPI的异常点均以较长的异常片段分布,比较集中,能够直接比较好的找到异常值的特征,所以在无滑窗的情况下也能较好的训练模型,但Yahoo的异常点分布较为零散且异常片段段,滑动窗口在丰富数据集的同时能够帮助LSTM捕获时间依赖性.
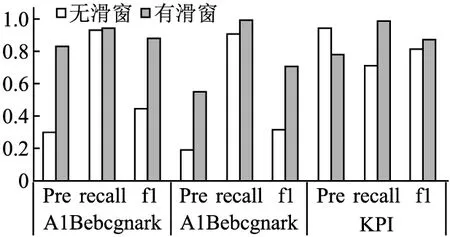
图6 有无滑动窗口对比实验Fig.6 Whether there is a sliding window contrast experiment
接下来,为了进一步验证获得滑窗合适的大小,由于时间序列的特点,不宜长度太短,这样自编码器在编码压缩的过程中无法提取得到时间序列的重要特征,从而分析效果较差;同时也不能太长,经分析,滑动窗口的大小Tw控制在500范围内即可,以100为间隔进行实验比对.
经图7的实验结果表明,滑动窗口Tw=400时,该模型的各项性能指标能够获得较好的检测效果.
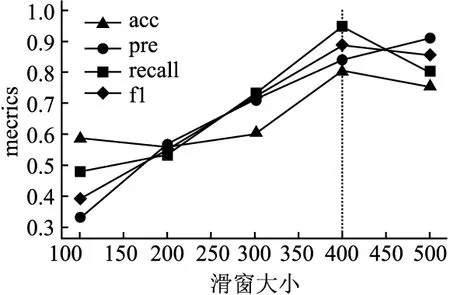
图7 最佳窗口大小对比实验Fig.7 Optimal window size comparison experiment
同时,该模型最大的创新在于使用两个解码器,相较于传统的异常检测方式,该模型避免了阈值的设定过程.最佳阈值的设定一直是大多数检测实验的问题,通常想要找到一个最佳阈值需要花费大量的时间成本和人力成本,而本文使用两个解码器竞争的方式进行检测,通过两个解码器解码出的结果进行比较而判定是否异常.为了突出这种新颖的自编码器的优势,将其与两种传统的自编码器进行比较,它们均只有一个编码器和一个解码器,使用标记的正常数据训练的自编码器模型称之为Normal_AE,使用未标记数据训练的自编码器称之为Unlabel_AE,将其与新型自编码器LSNC-AE进行实验比对,具体结果如表4所示.
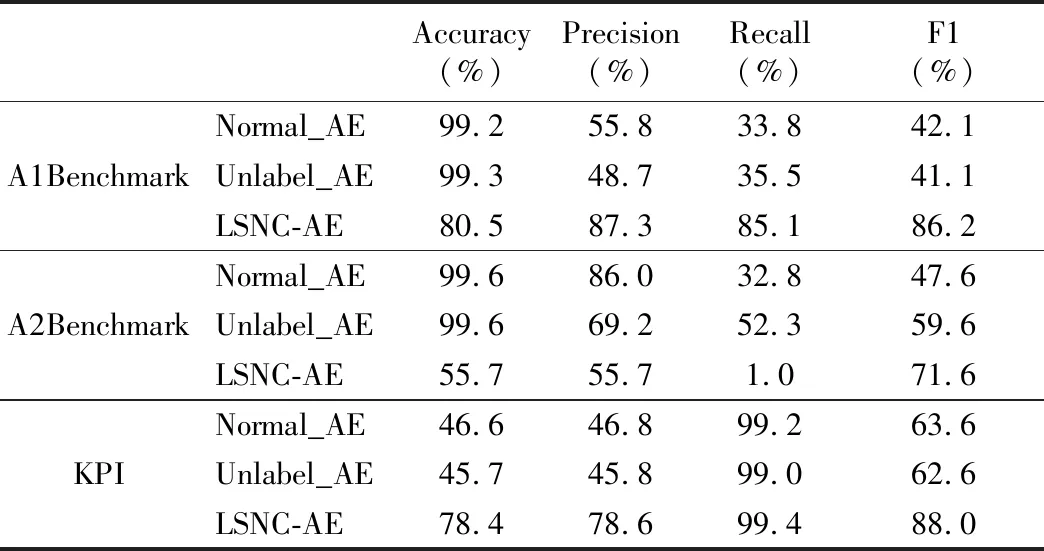
表4 基于LSTM不同自编码器对比实验Table 4 Comparative experiment of different autoencoders based on LSTM
经实验对比分析可知,该模型同传统的自编码器模型相比,具有更好的检测性能,对于3个数据集,LSNC-AE模型均能取得更高的召回率Recall和F1均衡分数,所以该模型基于传统的自编码器能够取得更优异的检测性能.
同时,为了进一步证明该模型的的有效性,依旧使用这3个数据集进行验证,将其与以下几个典型的异常检测方法进行了比较,比较的算法是孤立森林IForest算法(Isolation Forest)、局部异常因子LOF算法(Local Outlier Factor,LOF)、单类支持向量机(One Class SVM),实验结果如表5所示.
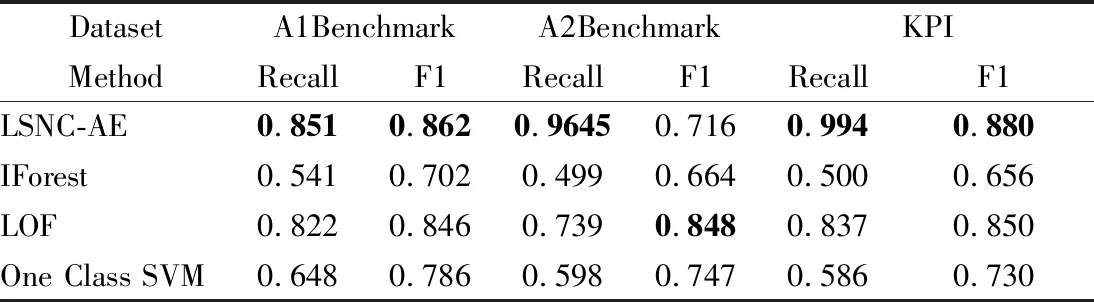
表5 LSNC-AE与其他3种典型算法的比较Table 5 Comparison of LSNC-AE and other three typical algorithms
从表5中的数据可以看出来,IForest和One Class SVM算法在这3个数据集上的表现都较差,主要是由于这两个算法受样本不均衡的影响,LOF是一种基于密度的离群点检测方法,能够较好地分离正常与异常,但是该方法对数据的处理速度较慢,而论文提出来的LSNC-AE总是有表现更好的性能.
6 结 论
本文提出一种无阈值的半监督竞争学习模型用于时间序列的异常检测.该模型(LSNC-AE)使用长短期记忆神经网络(LSTM)设计了一种竞争机制的新型自动编码器.该模型使用LSTM作为最基本的网络,可学习长期的时间依赖关系,同时,该模型在自编码器的基础上进行创新,可以很好的利用标记数据和未标记数据.总之,与传统的有监督和无监督的方法比,所涉及的模型在训练的时候能够充分利用大量的已标记的正常数据和含有异常样本的无标记数据,同时检测通过竞争的方式进行,不需要陷入最佳阈值选择的困境.通过在KPI、Yahoo的多个数据集上与传统方法及结构类似的方法做对比试验,验证了该模型的性能,进一步证明该模型具有较好的检测效果.
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
制造技术与机床(2019年9期)2019-09-10
西南交通大学学报(2018年6期)2018-12-18
成都信息工程大学学报(2018年3期)2018-08-29
河北遥感(2017年2期)2017-08-07
西安工程大学学报(2016年6期)2017-01-15
