
Topic Controlled Steganography via Graph-to-Text Generation
2023-02-17 03:11BowenSunYaminLiJunZhangHonghongXuXiaoqiangMaandPingXia
Bowen Sun,Yamin Li,2,3,*,Jun Zhang,Honghong Xu,Xiaoqiang Ma and Ping Xia
1School of Computer Science and Information Engineering,Hubei University,Wuhan,430062,China
2Hubei Key Laboratory of Intelligent Vision Based Monitoring for Hydroelectric Engineering,China Three Gorges University,Yichang,443002,China
3Yichang Key Laboratory of Intelligent Vision Based Monitoring for Hydroelectric Engineering,China Three Gorges University,Yichang,443002,China
4Department of CSIS,Douglas College,New Westminster,BC,V3L 5B2,Canada
5College of Computer and Information Technology,China Three Gorges University,Yichang,443002,China
ABSTRACT Generation-based linguistic steganography is a popular research area of information hiding.The text generative steganographic method based on conditional probability coding is the direction that researchers have recently paid attention to. However, in the course of our experiment, we found that the secret information hiding in the text tends to destroy the statistical distribution characteristics of the original text, which indicates that this method has the problem of the obvious reduction of text quality when the embedding rate increases,and that the topic of generated texts is uncontrollable,so there is still room for improvement in concealment.In this paper,we propose a topic-controlled steganography method which is guided by graph-to-text generation.The proposed model can automatically generate steganographic texts carrying secret messages from knowledge graphs,and the topic of the generated texts is controllable.We also provide a graph path coding method with corresponding detailed algorithms for graph-to-text generation. Different from traditional linguistic steganography methods, we encode the secret information during graph path coding rather than using conditional probability.We test our method in different aspects and compare it with other text generative steganographic methods.The experimental results show that the model proposed in this paper can effectively improve the quality of the generated text and significantly improve the concealment of steganographic text.
KEYWORDS Information hiding;linguistic steganography;knowledge graph;topic controlled;text generation
1 Introduction
With the development of information technology,human society has entered the era of big data.While the new round of technological revolution has brought convenience to our work and life,many security issues have become increasingly apparent. In recent years, there have been frequent threats to existing information network structure security, data security, and information content security,especially in banking,transportation,commerce,medical care,communications,electricity,etc.,which are highly dependent on informatization.
At present, traditional information security is mainly realized by encryption technology and its application system.Encryption Techniques encode secret information into an incomprehensible form,which can ensure content security to a certain extent.However,with the development of data mining and machine learning technologies in the era of big data,encrypted data,as a kind of abnormal data,tends to make it easier to expose the existence of secret information,which makes it become a key goal of network data analysis.Information Hiding,also known as Steganography,is another key technology in the field of information security. It has a long history and is widely used in applications such as military intelligence secret communications, user privacy protection, and digital media copyright protection[1-4].Compared with traditional encryption technology,steganography embeds the secret message in the public information carrier to complete the communication, so as not to attract the attention of the monitors,reduce the possibility of being attacked and detected,and effectively ensure the security of information.
In today’s era of big data, various digital media such as images, audios, and texts have become important ways for people to transmit information. They are also ideal carriers for technical researchers to hide information[5-7].Many researchers have studied steganography in image,audio and other fields and published lots of related steganography[8,9]and Steganalysis[10]models.Text is the most widely used information carrier in our daily life, and the steganography method that uses text as an information hiding carrier has attracted the attention of many researchers.However,compared with images and audio, text has less redundant information, so it is quite challenging to hide the information inside.At present,there have been a large number of in-depth studies on the textbased steganography,which can be divided into text retrieval[11,12],text modification[13-15]and text generation[16-18]three types of methods.The text retrieval steganography method expresses different meanings by selecting different text characters. The steganography method of text modification is realized by making minor modifications to the text,such as adjusting the word spacing and replacing synonyms. However, the secret information embedding rate of these methods is very limited, which is not practical in actual application scenarios. Therefore, researchers began to try to use automatic text generation models to realize the reversible embedding of secret information.Since it can generate natural language text close to human communication and is not restricted by the text format, the generation-based linguistic steganography method has become a popular research direction in the field of information hiding.
The problem to be solved by information hiding technology can be summarized by a classic model of“The Prisoners’Problem”[19]:Alice and Bob are separated in prison,and they need to complete the transmission of some secret information without being discovered by the guard Eve. Therefore,Alice and Bob need to hide the secret information in some kind of carrier.In this paper whose task is to generate steganographic text guided by the knowledge graph, Alice uses the knowledge graph to hide the secret information in the steganographic text embedded with the secret information.The mathematical description of this steganography task is:given a specific semantic subgraphg(g∈G)in the knowledge graph spaceGand a secret message to be hiddenm(m∈M)in the secret message spaceM,the task goal is to generate steganographic texts(s∈S),Sis the steganographic text space,and ensure that:a)steganographic text is a smooth natural language paragraph;b)expresses specific semantics;c)hidden secret messages can be extracted correctly.Therefore,the steganographic task can be expressed as

Among them,Embis the process of embedding secret information,Extis the process of extracting secret information,kaandkbare two keys in the key spaceK,fandgare the corresponding mapping functions.
The current text generation-based steganography method mainly relies on the Statistical Language Model in Natural Language Processing (NLP) technology, and it contains two parts: a) the text generation part that based on statistical language models;b)the encoding part based on conditional probability distribution. The text generation part uses a well-designed model to learn a language statistical distribution model from a large number of natural texts. Then during the process of text generation,the conditional probability distribution of each word will be coded according to the secret information.As many steganalysis methods keep developing,the concealment of the steganographic text needs to be improved,and the text generative steganography method based on the current method framework faces severe challenges.
First, it is important to design a model that can generate texts with high quality. Since this technical framework needs to encode the conditional probability of the generated text to embed information, as the secret information embedding rate increases, the quality of the generated text will decrease significantly,and even generate meaningless or grammatically wrong sentences.It means this method has the inherent defect that it cannot simultaneously increase the secret information hiding capacity and improve the concealment of the algorithm.Second,it is also necessary to improve the relevance and coherence of steganographic text in content, so that the text content can have a certain theme and complete semantics, thereby improving the concealment of the generationbased steganography method.Therefore,the generation-based steganography method should not only consider the similarity of the probability distribution between text characters to make the generated text more natural and smoother,but also ensure that the text content has a certain theme,complete semantics,and consistent emotions,which are closer to human communication.
In order to further improve the concealment of the text generative steganography method,and in response to the above problems and challenges, we attempt to break through the current generation-based steganography method framework. So that we can overcome the inherent defects of the text generative steganographic methods based on conditional probability coding. The main contributions of this paper can be summarized as the following three points: a) a topic controlled steganography method is proposed,which can automatically generate steganographic texts that carry secret information;b)we use knowledge graph to guide the text generation,combining with our topic matching method, we make the topic of the generated texts controllable. c) we get better quality of generated texts by encoding the secret information during graph path coding rather than using conditional probability,and the method of graph path coding is provided with detailed algorithms.
2 Related Works
The text generative steganography method has high concealment and security,which has attracted wide attention from researchers. It has long been the focus of information security and research hotspots in the field of information hiding.In early days,researchers tried some information hiding methods based on text generation,but the generated sentences did not have complete semantics and contained many grammatical errors [20]. Subsequently, the researchers tried to introduce syntactic rules to constrain the generated text. Chapman et al. [21] designed a kind of password privacy protection software based on syntactic structure, which can convert the ciphertext into natural text,and then extract the original ciphertext from the natural text.However,the steganographic sentences generated by this method are relatively simple and have a single structure,which can be easily detected and recognized by the monitors, and the security of the algorithm in the application cannot be guaranteed.
The traditional generation-based steganography framework is mainly composed of two parts:a text generation model based on statistical language models and a coding method based on conditional probability distribution.Based on this framework,some researchers use Markov chains to calculate the number of co-occurrences of each phrase and obtain the transition probability,and then use transition probability to encode words,so as to hide secret information in the process of text generation[22-24].The Markov chain model can be used to generate natural text that conforms to the statistical language model to a certain extent,and even poetry[25]with a fixed format.However,due to the limitations of the Markov chain model itself,unmeaning or grammatical sentences are often generated,and the quality of text generation is limited.Therefore,in practical applications,it can be easily detected and recognized by text steganalysis algorithms.
In recent years,researchers have combined text-generated steganography with statistical language models in natural language processing, and conducted a series of innovative explorations. Taking the advantages of Recurrent Neural Network (RNN) to extract sequence signal features, first learn a statistical language model from a corpus containing a large number of natural language texts.Then,at time t when the text is generated,the RNN can calculate the conditional probability distribution p of the t-th word based on the t-1 word.
Many researchers have adopted the RNN and put forward lots of valuable steganography methods.Fang et al.[16]proposed a text generative steganography system based on Long Short-Term Memory(LSTM)neural network at ACL 2017 in the NLP field.The system uses the LSTM network to learn statistical language models from natural text, and in the process of text generation, selects different words from the precoding dictionary according to the secret information to realize the hiding of the secret information.Compared with the method based on Markov Chains,this system has larger information hiding capacity and higher information embedding rate.Yang et al.[17]also used a multilayer recurrent neural network with LSTM units to perform steganographic text generation,which is the “RNN-Stega”method. By learning and training from a large corpus, they can obtain a better statistical language model,and estimate the conditional probability distribution of each word,encode the conditional probability of each word in the generated text through a fixed-length Perfect Binary Tree and a variable-length Huffman Coding, then output the corresponding word according to the secret information bit stream to realize the secret information hiding.The experimental results showed that the method had reached the highest level at the time in terms of the hidden efficiency,concealment,and hidden capacity.Then on the basis of the“RNN-Stega”method,Ziegler et al.[18]used Arithmetic Coding to encode strings of known probabilities, which is more effective than Huffman coding and has less damage to the probability distribution of the language.In addition,the system uses one of the best pre-trained language models in the experiment,the GPT-2 model[26],which can generate natural text that is more in line with the statistical language model. And then, based on arithmetic coding,Shen et al.[27]proposed a text-generating steganography algorithm“SAAC”that uses self-adjusting arithmetic coding. The method encodes the conditional probability to further reduce the Kullback-Leibler Divergence of steganographic text, thereby improving the concealment of the algorithm in language statistics. Also, Yang et al. [28] used Variational Auto-Encoder (VAE) to learn the overall statistical distribution characteristics of texts from the dataset,which further improves the ability of anti-detection of the generated steganographic texts.
After summarizing the relevant results that the former researchers have led to,we find that these algorithms based on the existing text generation steganography model framework which use the conditional probability coding still cannot avoid the inherent shortcoming:unable to increase secret information hiding capacity and improve algorithm concealment at the same time.In the latest study of Yang et al.[29],they revealed that due to the uncontrollable semantics of the generated text,even if the steganographic text is sufficiently concealed in terms of statistical distribution characteristics,there are still some risks.Especially in practical application scenarios,the content and topic of the generated text should also conform to the specific context,especially the long text paragraph containing multiple sentences. The text content must maintain a certain degree of relevance and coherence with the specific topic.However,in the current generation-based steganography method,it is still a challenge to generate controllable text content.
To control the semantics of generated text,Li et al.[30]proposed a Topic-Aware neural linguistic steganography method, which links the generated texts with specific topics by introducing the knowledge graph.As a result,their method performed better on text quality and anti-detection ability when compared with traditional framework. Furthermore, there are still many researchers [31,32]who have made great progress on steganography methods and improved the security performance of linguistic steganography.However,they still preferred to use traditional way rather than generating steganographic texts from the graph structure, so there is still room for improvement in the quality and concealment of the text.
In order to ensure the versatility of the steganography algorithm, we assume that the secret information to be embedded is arbitrary,that is,the content of the secret information is not restricted.Therefore,it will be quite a challenge to not only embed the secret information in the text generation process, but also realize the content control of the generated text. In this paper, to make the text content more coherent,so as to improve the concealment of the secret information,we use keyword matching in the knowledge graph and the graph path encoding,then complete the steganography of secret information by generating sentences corresponding to the KG triples.
3 Method
In this section,we will introduce the methods and model we use in this paper.The overview of our method is shown in Fig.1.We use“The Prisoners’Problem”model to show the whole transmission process of secret information under monitoring with a part of an example from the experiment,including encoding,generating and decoding.
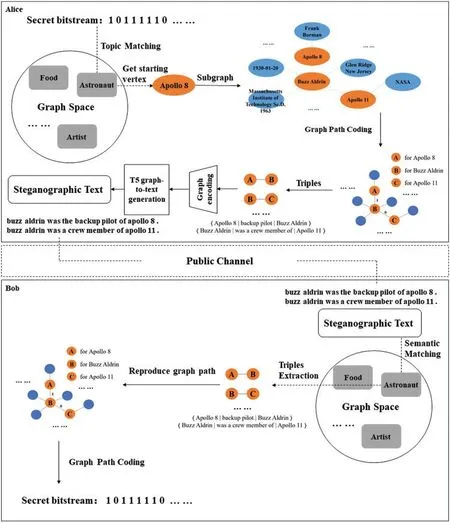
Figure 1:The overview of proposed method
3.1 Topic Matching
In order to control the semantics of the generated text, we use the knowledge graph to guide the semantic expression of the steganographic text.Comparing with the traditional methods,we can decide the topic of generated texts,so that when the length of the generated text increases,the topic of generated texts will not be jumping, which improves the concealment of the steganographic text.We construct a topic list,add a large number of different topic keywords contained in the knowledge graph to the topic list, then randomly select a topic keyword from it each time, use the method of string matching[33]to find the matching subgraph with specific semantics,and use this keyword as the starting node of the subgraph.In this way,we can ensure the topic consistency of the generated text.
3.2 Graph Path Coding
First,we define a graph structure to represent the knowledge graph,which is a directed graph with entities as vertices and relations as edges,and there is no self-loop and Parallel-edges.A graph with N vertices is defined as:

Among them,V and E respectively represent the vertex set and edge set of the graph,that is,the entity set and relation set of the knowledge graph,Ei,jrepresents the edge from vertexVito vertexVj.Therefore,the edge setwith vertexVias the starting vertex is:

For any entity vertexViin the graph structure,there areedges with it as the starting node,and each edge connects to another vertex. In the knowledge graph, such a triple composed of two vertices and one edge can express certain semantic information,so that multiple connected triples can express the trend of related semantic information.
When encoding the graph structure of the knowledge graph,we convert the path encoding of the subgraph to the encoding of the edge set of the starting vertex. However, the size of the edge set of various starting vertices are quite different,that is,the value ofis uncertain and not necessarily a multiple of 2,it is not recommended to simply use binary fixed-length coding to encode its edge set.
Therefore,in this paper,we intend to use Huffman coding to encode the edge set of each vertex,and its weight is the frequency of appearance of the adjacent entity vertex in the corpus.The process of path coding and secret information hiding on a subgraph based on Huffman coding is shown in Fig.2, and the corresponding algorithm is shown in Algorithm 1, which contains the detailed logic and measures of our coding method.
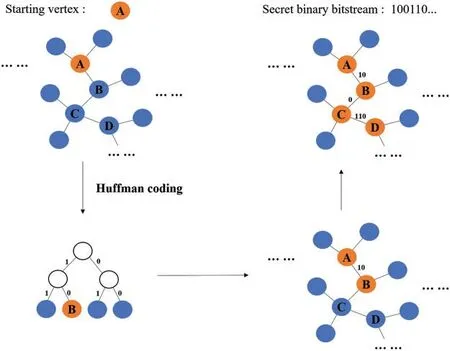
Figure 2:The process of path coding

Algorithm 1:Information Hiding Input: subgraph g,starting vertex V0,secret binary bitstream:B={100110...}Output: chained subgraph gc={}1: Add V0 to the chained subgraph gc;2: while not the end of B do 3: Get the edge set E0out of the starting vertex V0;4: Construct a Huffman tree according to the weights of each edge;5: if weights of each edge are the same then 6: The vertex of the entity word in the front is regarded as the left child node;7: else 8: The vertex with a larger weight is the left child vertex;9: end if 10: The code of the left child vertex is 1,and the code of the right child vertex is 0,get the Huffman code of each edge,that is,the code of each path;11: Select the corresponding path according to the secret binary bitstream B,get the next vertex V1;12: Remove the edge Ei,j from the subgraph g that connects the previous vertex V0;13: Add V1 to the chained subgraph gc;14: Take vertex V1 as the new starting node.15: end while 16: return chained subgraph gc
Through the above method, while completing the secret information embedding, we realize the construction of an ordered directed subgraph chain containing specific semantics from the nonhierarchical knowledge graph. The subgraph chain contains several connected knowledge graph triples,which represent the semantic information on the path.
In the knowledge graph structure,the path coding based on Huffman coding not only guarantees the uniqueness of each path coding, and it will not be the prefix of other path coding, but also, it ensures that any binary bitstream can match the corresponding path. The length of the path or the size of the subgraph depends on the length of the secret information. In this way, the conditional probability distribution of the texts will not get destroyed,and the generated texts will be under the same topic,which can improve the quality and concealment of the steganographic texts.
3.3 Text Generation
In this paper,we use the pre-trained model T5 proposed by Raffel et al.[34].The T5 model uses a standard Transformer-based encoder-decoder framework and is trained on a large cleaned network text corpus C4.It uses a unified framework to transform various problems in NLP into a text-to-text format.
In order to complete the downstream task of graph-to-text that we need in this paper,we fine-tune the T5 model[35].First,we preprocess each subgraph obtained in the graph dataset to get RDF-triples,and input them into a sequence.Then we turn the problem into a text-to-text task,and translate the triples into text to train the model.Finally,we add the ordered chained subgraphs obtained in the path encoding as input to the trained model,so that we can get the text(text1,text2,text3,...)generated by each subgraph in an orderly manner to form the steganographic textS.The Fig.3 shows the whole process of steganographic text generation introduced above.
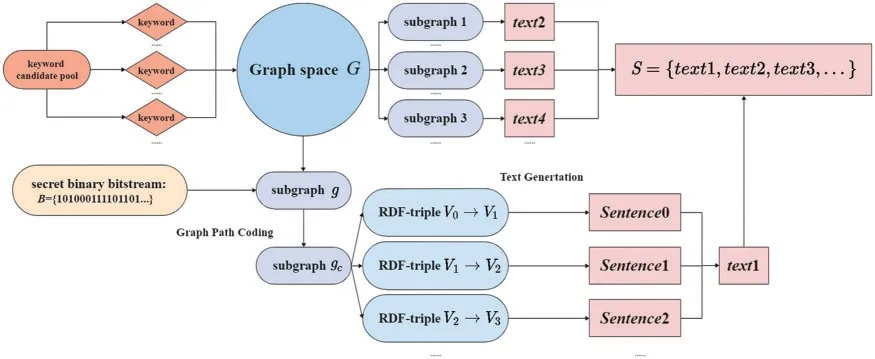
Figure 3:Steganographic text generation

Algorithm 2:Information Extraction Input: steganographic text S={text1,text2,text3, ...},knowledge graph space G Output: secret binary bitstream:B={}1: Add V0 to the chained subgraph gc;2: while not the end of S do 3: Read text1 from S;4: Get the matching subgraph g according to G;5: Get the corresponding chained subgraph gc according to text1;6: Follow the chained subgraph gc,get the chain of ordered vertexes V0,V1,V2, ...;7: while not the end of gc do 8: Get the edge set E0out of the starting vertex V0;9: Construct a Huffman tree according to the weights of each edge;10: if weights of each edge are the same then 11: The vertex of the entity word in the front is regarded as the left child node;12: else 13: The vertex with a larger weight is the left child vertex;14: end if 15: The code of the left child vertex is 1,and the code of the right child vertex is 0,get the Huffman code of each edge,that is,the code of each path;16: Add the code that matches the path V0 →V1 to secret binary bitstream B;17: Remove the edge Ei,j from the subgraph g that connects the previous vertex V0;18: Take vertex V1 as the new starting node.19: end while 20: Read the next text text2 from S.21: end while 22: return secret binary bitstream B
3.4 Information Extraction
Information extraction and information hiding are a pair of opposite operations.After the receiver Bob receives the steganographic text from the public network transmission channel, the receiver needs to correctly decode the secret information contained in it. In the KG-guided text generation steganography framework proposed in this paper,the embedding of secret information is realized by encoding the node path of the knowledge graph before the text is generated. Therefore, the receiver only needs to reconstruct the node path through graph matching to realize the extraction of secret information.
The detailed algorithm of information extraction is shown in Algorithm 2. In our method,when Bob receives the steganographic text,he first extracts entity keywords from the generated text,identifies the subgraphs in sequence,and then performs subgraph matching and coding in the same knowledge graph shared by both the sender and the receiver to reconstruct the path of the subgraph nodes,so that the code of the subgraph can be extracted.It should be noted that Alice and Bob must have exactly the same knowledge graph dataset and use the same path encoding method.Because in the knowledge graph shared by both parties,the path coding of each subgraph is unique,so it can be guaranteed that Bob can accurately extract the hidden secret information.
4 Experiments and Analysis
In this section,we will introduce the details and environments of our experiments.And we evaluate the method from four aspects:semantic correlation,text quality,topic correlation and anti-detection.
4.1 Dataset and Model Training
During the experiments, we use the pre-trained model T5 as we introduced in Section 3.3. To evaluate the proposed method, we fine-tune the model with WebNLG dataset [36], which contains pairs of knowledge graph and corresponding target text that can describe the graph.Specifically,the WebNLG dataset consists of 21855 data/text pairs with a total of 8372 distinct data input. And the input describes entities belonging to 9 distinct DBpedia categories namely, Astronaut, University,Monument, Building, ComicsCharacter, Food, Airport, SportsTeam and WrittenWork. Since the small subgraph which contains few triples are meaningless for path coding, we use the subgraphs in the text dataset that contains more than five triples as our test dataset,and there are 307 subgraphs that meet the requirement.The data statistics of WebNLG are shown in Table 1.
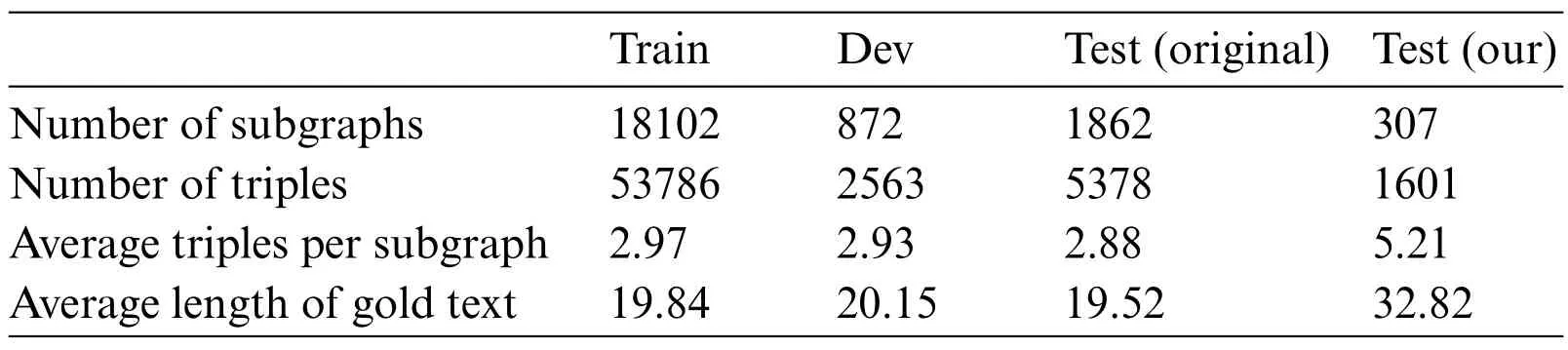
Table 1: The data statistics of WebNLG
To preprocess the dataset, we identify the entities and relationships in the dataset triples as the model’s vocabulary.Then during the training,we set the initial learning rate as 3·10-5,and we choose the batch size as 4.GeForce RTX 3070 GPU and CUDA 11.1 are used for training acceleration.
To evaluate our method,we compare our method with three other steganography methods.Firstly,following the Topic-Aware method proposed in[30],we use conditional probability coding in the same Graph2Text model and WebNLG dataset.Secondly,following the RNN-Stega method proposed in Yang et al.[17],we use RNN for the train set of WebNLG dataset,while using conditional probability coding for the generation. The initial learning rates are set as 0.001 and batch size is set as 128,dropout rate is 0.5.GeForce RTX 3070 GPU and CUDA 8.0 are used for training acceleration.Thirdly,following the VAE-Stega method proposed in Yang et al.[28],two different encoders are used,one of them uses a recurrent neural network with LSTM units as the encoder (shown as VAE-Stega (lstm)in the tables of experimental results)and the other uses Bidirectional Encoder Representations from Transformers (BERT) [37] as the encoder (shown as VAE-Stega(bert) in the tables of experimental results). For VAE-Stega(lstm), the initial learning rates are set as 0.001 and batch size is set as 128.And for VAE-Stega(bert),a pre-trained model released by[37]is also used,the initial learning rates are set as 0.001 while batch size is set as 20.Quadro RTX 5000 and CUDA 9.0 are used for training acceleration.
4.2 Embedding Rate
In general,the generated texts of linguistic steganography consist ofNsteganographic sentences.The embedding rateERstands for how many bits a word can carry (bits per word) during the generation.For the methods using conditional probability coding like RNN-Stega,Topic-Aware and VAE-Stega,ERcan be defined as:

Among them,Nrepresents the number of the sentences in the generated texts, whilenis the number of words each steganographic sentence contains andbis the number of bits that each steganographic sentence can carry.
The embedding rate of our method can be defined as:

Among them,Nrepresents the number of the sentences in the generated texts,nis the number of words each steganographic sentence contains,trepresents how many triples each steganographic sentence uses for generation andBis the number of bits that each triple can carry.The embedding rate of our method depends on the number of triples that each steganographic sentence contains,which is highly relevant to the dataset we use.Therefore,if the experiments are conducted on larger datasets which contain more relations,the embedding efficiency of the proposed method could be higher.
4.3 Evaluation of Semantic Correlation
Semantic correlation is an important evaluation index in the fields of text generation and machine translation. By calculating the similarity between the generated text of the model and the artificial reference text on the vocabulary level, we can more intuitively understand the reliability of the generated texts.
In this paper,the WebNLG dataset provided pairs of knowledge graph and corresponding target text, so that we can use random bitstreams to generate texts from the subgraphs, then analyze the semantic correlation between the generated texts and the target texts. We use the automatic metrics BLEU [38], ROUGE-L [39] and CIDEr [40] for evaluation. We also test the texts generated from the RNN-Stega,Topic-Aware and VAE-Stega as comparison,and we set different embedding rate on RNN-Stega,Topic-Aware and VAE-Stega for experiments.
We use all the 307 subgraphs that contains more than five triples in the test dataset for text generation.Since we will not use all the triples in the subgraph,the generated texts are shorter than the target texts.In order to set the experiments under the same condition,we adjust the length of the text generated by RNN-Stega,Topic-Aware and VAE-Stega to the average length of the text generated by our method.The results are shown in Table 2.
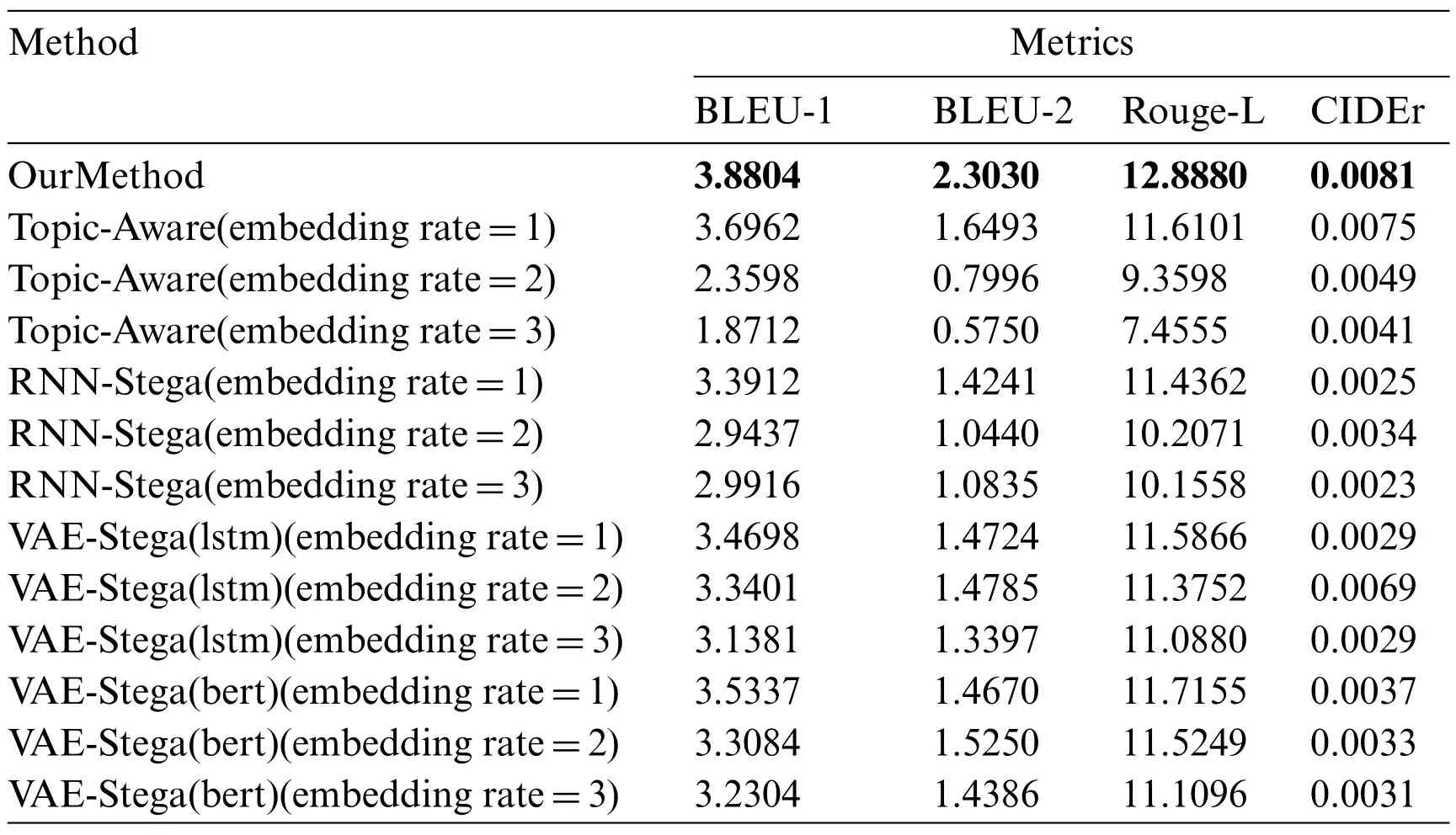
Table 2: Evaluation of semantic correlation
As we can conclude from the results, the scores of RNN-Stega, Topic-Aware and VAE-Stega decrease when the embedding rate increases,and the scores of our method are obviously higher,which indicates that our method can generate texts that follow the input semantic information to a certain extent.
4.4 Evaluation of Text Quality
The text quality represents the imperceptibility of information hiding, which is one of the most important evaluation of a concealment system. In this paper, we set the embedding rate of RNNStega,Topic-Aware and VAE-Stega from 1 to 3,and we useperplexity[41]to analyze the text quality.It is a widely used evaluation method in the field of NLP, and it is defined as the average per-word log-probability on the test texts:

Among them,S= {Word1,Word2,...,Wordn} represents the generated text, whilep(S)is the probability distribution of the text. During the experiment, we test the texts that generated in Section 4.3.The results are shown in Table 3.
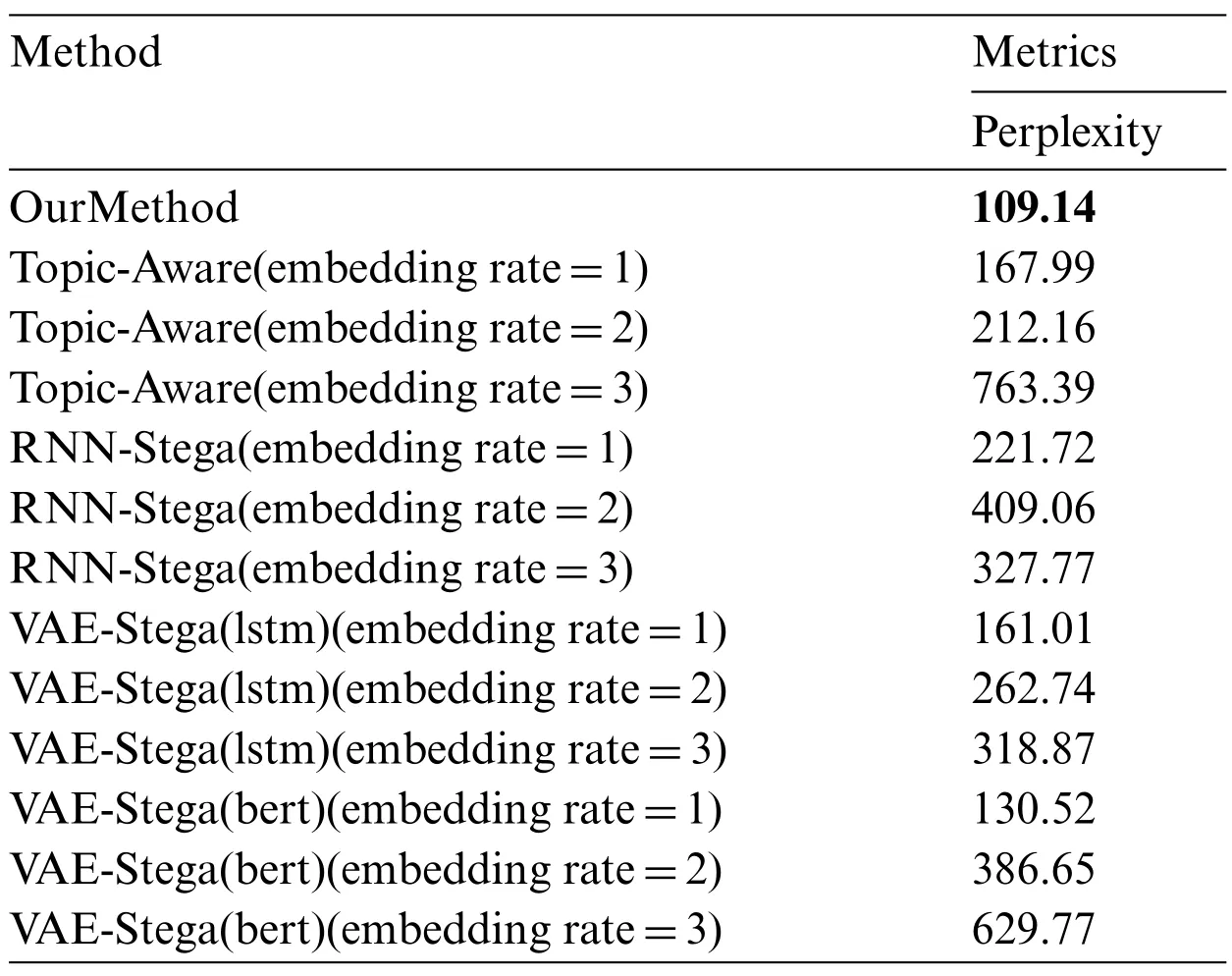
Table 3: Evaluation of text quality
From the results, we can clearly see that the perplexity of RNN-Stega, Topic-Aware and VAEStega gets higher as the embedding rate increases, and the perplexity of our method is much lower than that of RNN-Stega,Topic-Aware and VAE-Stega,which means that the texts generated by our method are closer to the real semantic expression,that is,our method performed better in information imperceptibility.
4.5 Evaluation of Topic Correlation
In this part,we use two evaluating indicators to analyze topic correlation of our method.First,we use Topic-Coherence,which is an important measurement for evaluating topic models.We adopt LDA topic model[42]to train the target texts and evaluate Topic-Coherence score of our generated texts.The results are shown in Table 4,where the“tp”in the table means the number of topic words that used in the evaluation.From the results we can see that our method get better scores with different topic numbers, which means our method performs better in controlling the topic in steganography texts.Second,we use an IE(Information Extraction)model proposed in[43].After training the IE model using the WebNLG dataset,we use the model to extract triples from our generated texts and calculate the Precision,Recall and F1 score of the extraction.Since the conditional probability coding changes the statistical distribution characteristics of texts,which makes it hard for the IE model to extract the triples from the texts generated by Topic-Aware and VAE-Stega,we only present the results on other methods.The results are shown in Table 5 with the corresponding figure shown in Fig.4, where the correct,Predict,Gold in the table stand for the number of triples extracted correctly,the number of triples predicted from the model,the number of corresponding triples matched in the gold texts,the results of IE system are also shown here as a baseline.An example of information extraction on our dataset is also proposed in Table 6.From the results we can see that the steganography texts generated from our method present the entities and relationship in the text more precisely,which means the topic of generated texts closer to the gold texts.
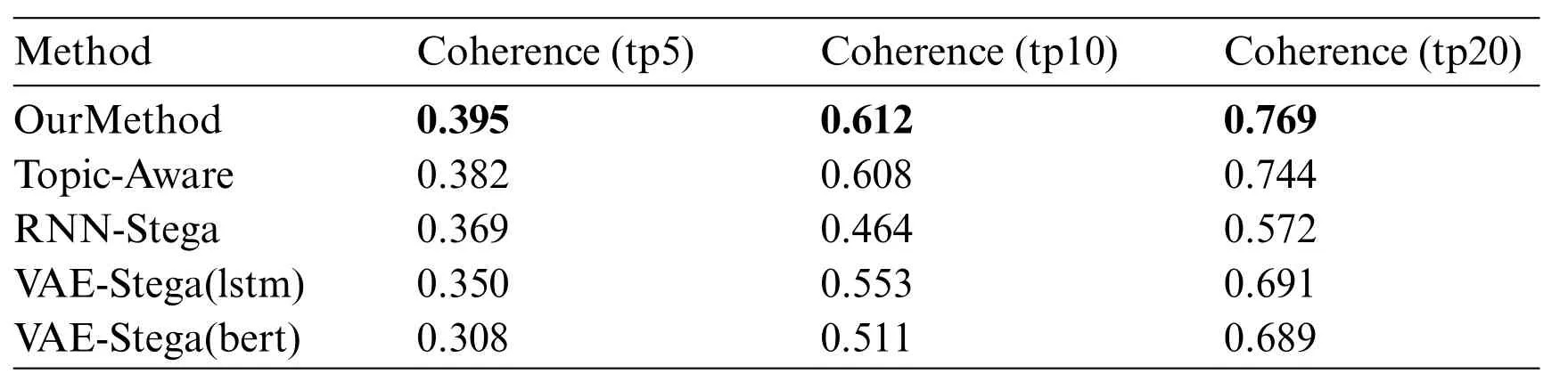
Table 4: Evaluation of topic-coherence

Table 5: Evaluation of topic correlation
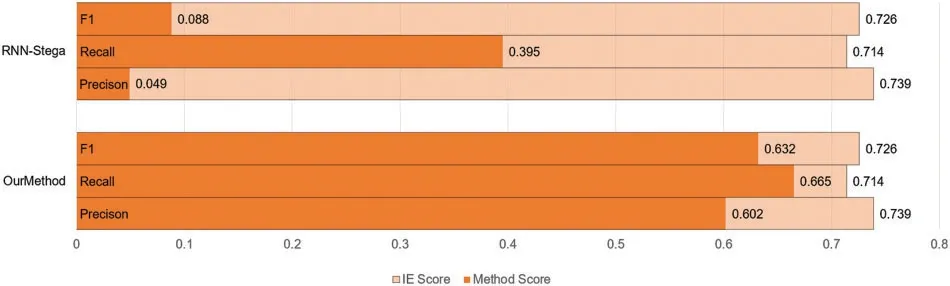
Figure 4:Evaluation of topic correlation
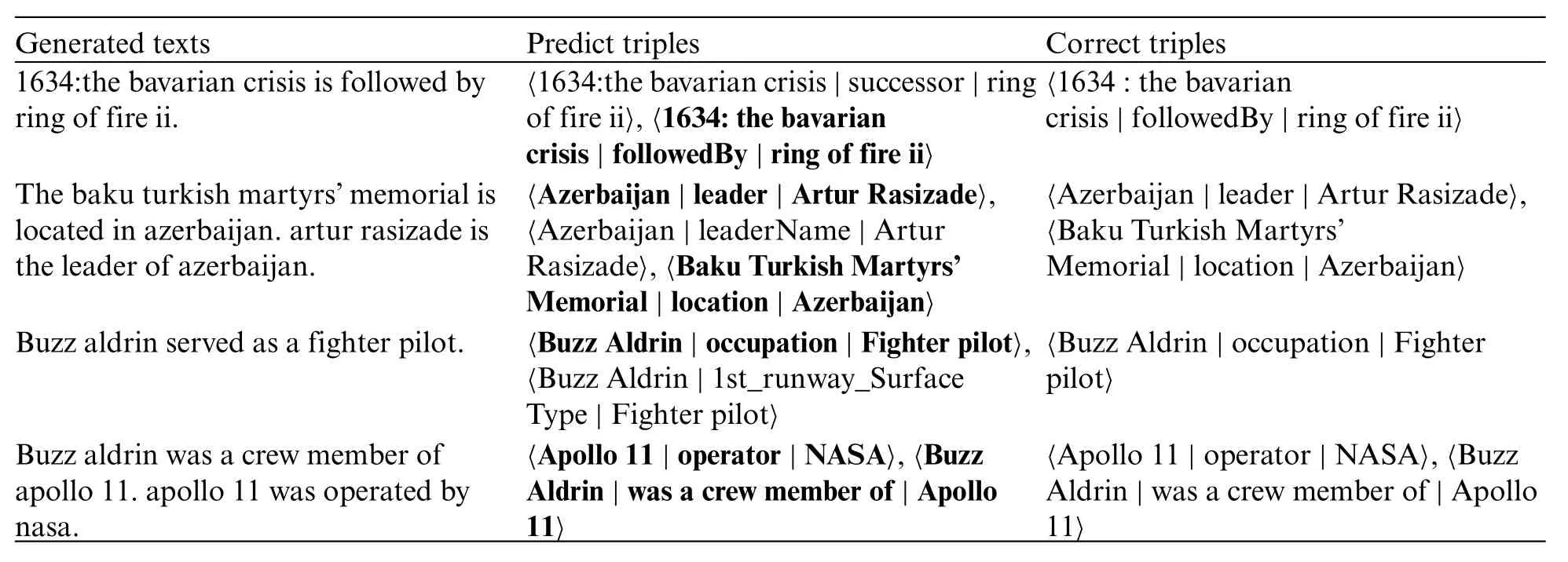
Table 6: Information extraction results of topic correlation
4.6 Evaluation of Anti-Detection
With the continuous development of steganography, various steganalysis methods are also developing.During the experiment,we also use three different steganalysis methods:FCN[44],CNN[45], RBiLSTMC [46], so that we can analyze the anti-detection ability of our method. The results are shown in Table 7.Since the length of texts that generated from our method is uncontrollable,the advantage of the anti-detection ability of our method is not huge,but we can still see from the results that the steganalysis method can detect the other two methods more easily, which means that our method can actually avoid detection to a certain degree.
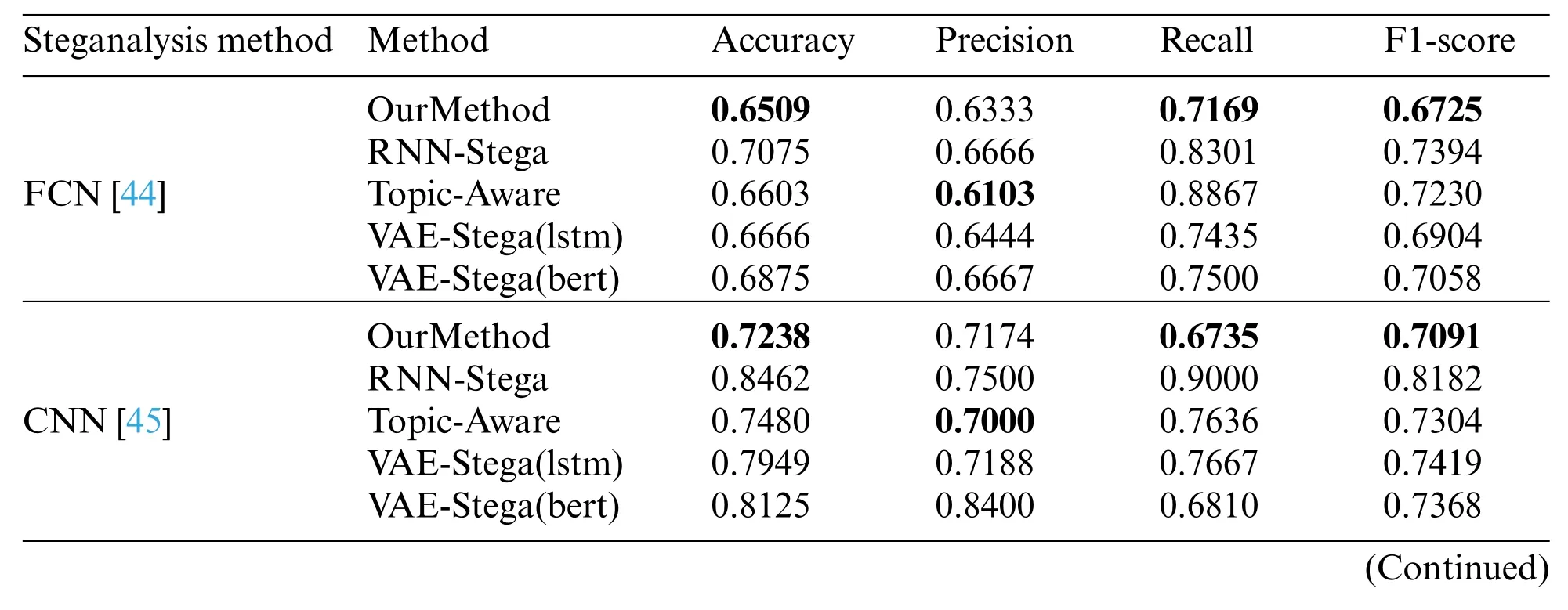
Table 7: Evaluation of anti-detection
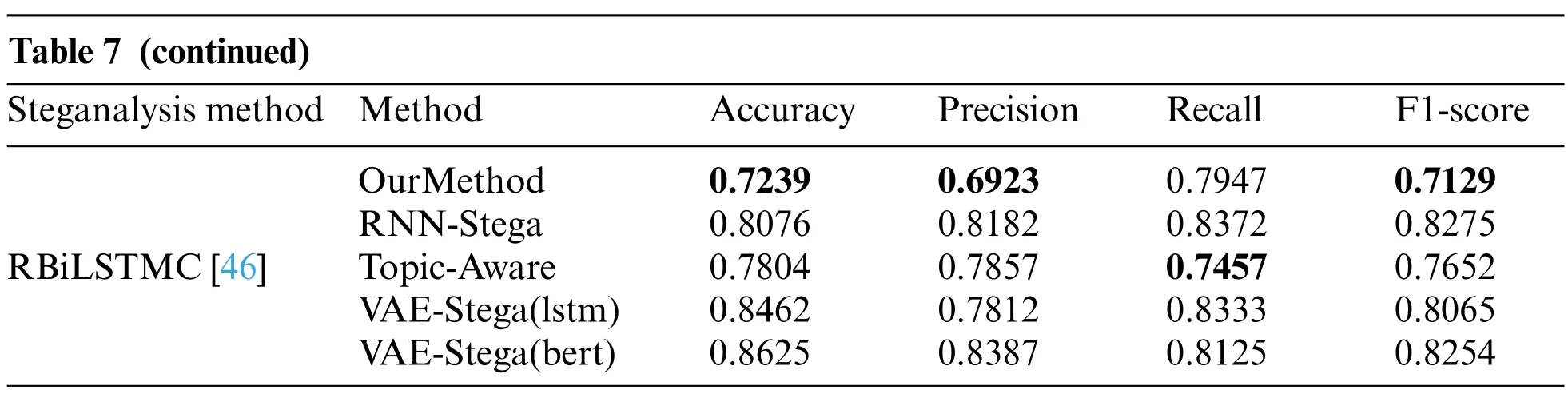
Table 7 (continued)Steganalysis method Method Accuracy Precision Recall F1-score OurMethod 0.7239 0.6923 0.7947 0.7129 RNN-Stega 0.8076 0.8182 0.8372 0.8275 RBiLSTMC[46] Topic-Aware 0.7804 0.7857 0.7457 0.7652 VAE-Stega(lstm) 0.8462 0.7812 0.8333 0.8065 VAE-Stega(bert) 0.8625 0.8387 0.8125 0.8254
4.7 Example of Generation
In this section,we will demonstrate an example of subgraph and corresponding text that generated from our method. To present the process of coding and generation more directly, we artificially combine several subgraphs from the original WebNLG dataset to get a bigger subgraph.During the path coding,7 triples were used to generate text in this subgraph.The example is shown in Fig.5,the entities that used for generation were tagged in orange,while the not used ones were tagged in blue.The used triples,bitstream and the corresponding generated text are shown in Table 8.
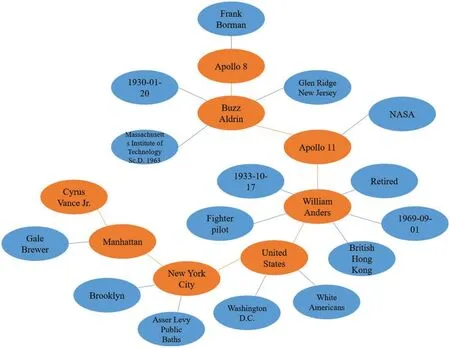
Figure 5:Example of a knowledge graph
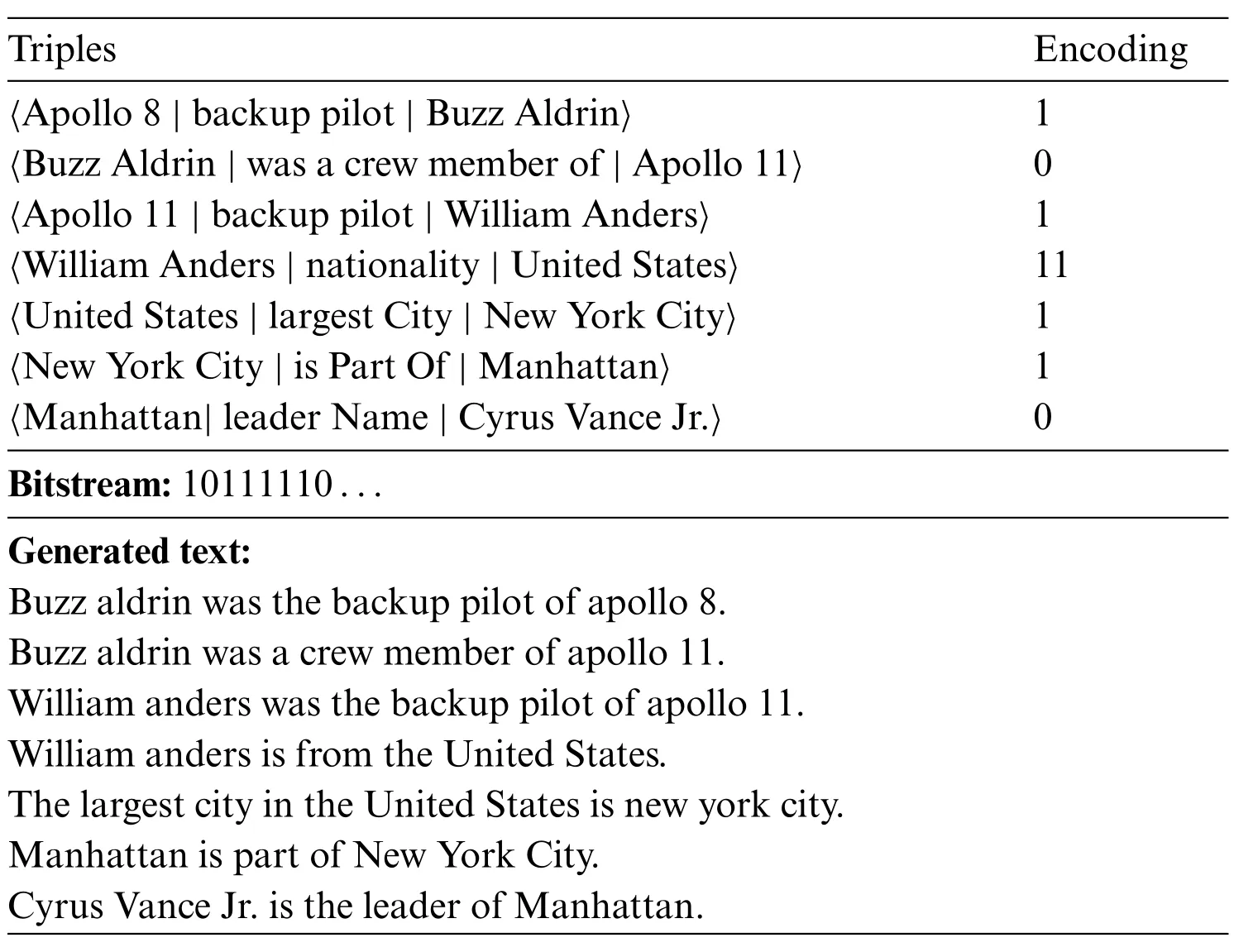
Table 8: Example of generation
5 Conclusion
Steganography is a hot topic with challenge and huge research value.In this paper,we propose a model that can automatically generate steganographic texts from knowledge graphs.In order to hide secret information,we abandon traditional way of using conditional probability and choose to encode during the process of graph-to-text generation.We realize the semantic control of the steganographic texts by introducing knowledge graphs with our topic matching method. We also provide detailed algorithms for our path coding method,and we carry out many comparative experiments to verify the effect of our method.Compared with the previous steganography methods,the experiments confirm the feasibility of our method. The texts generated by our method have a certain improvement in imperceptibility and anti-detection ability.The results show that compared with the previous methods,our method improves the quality of steganographic texts by more than 34%,and improves semantic correlation and anti-detection ability by more than 3%and 6%.In future work,we look forward to building our own dataset which takes the depth of the graph structure as the construction standard and has a larger capacity; in this way, we can better use our method and put it into practical application.Furthermore,we hope to create more effective methods in linguistic steganography.This paper successfully reveals the possibility of combining graph-to-text generation with steganography and we hope that our work can bring help and inspiration to more researchers in this field.
Funding Statement:This work was supported in part by the National Natural Science Foundation of China[62102136],the 2020 Opening Fund for Hubei Key Laboratory of Intelligent Vision Based Monitoring for Hydroelectric Engineering[2020SDSJ06]and the Construction Fund for Hubei Key Laboratory of Intelligent Vision Based Monitoring for Hydroelectric Engineering[2019ZYYD007].
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
 Computer Modeling In Engineering&Sciences2023年7期
Computer Modeling In Engineering&Sciences2023年7期
- Computer Modeling In Engineering&Sciences的其它文章
- Edge Intelligence with Distributed Processing of DNNs:A Survey
- Turbulent Kinetic Energy of Flow during Inhale and Exhale to Characterize the Severity of Obstructive Sleep Apnea Patient
- The Effects of the Particle Size Ratio on the Behaviors of Binary Granular Materials
- A Novel Light Weight CNN Framework Integrated with Marine Predator Optimization for the Assessment of Tear Film-Lipid Layer Patterns
- Implementation of Rapid Code Transformation Process Using Deep Learning Approaches
- A New Hybrid Hierarchical Parallel Algorithm to Enhance the Performance of Large-Scale Structural Analysis Based on Heterogeneous Multicore Clusters