
基于GEE和Sentinel时序影像的优势树种识别研究
2023-02-11 11:19刘灵张加龙韩雪莲许冬凡王书贤程滔
森林工程 2023年1期
刘灵,张加龙*,韩雪莲,许冬凡,王书贤,程滔
(1.西南林业大学 林学院,昆明 650224;2.国家基础地理信息中心,北京 100830)
0 引言
作为森林资源调查的重要内容,森林树种的识别与分布情况对于森林资源管理、生物多样性评估、水土保持以及森林碳储量估算都具有重要参考价值[1]。
与传统的野外森林调查相比,卫星遥感技术因其快速和高效被广泛应用于森林分类与识别中。各类型的遥感影像被用于树种识别[2-4]。有研究表明,数据源也是影响树种识别精度的因素之一[5]。多数情况下,中低空间分辨率主要用于森林类型分类,而未用于树种组成分析;高光谱数据和激光雷达数据因其高昂的成本而无法应用于大尺度区域树种识别[6-7]。Sentinel-1雷达数据和Sentinel-2多光谱数据凭借其免费获取和较高空间分辨率的优势在大区域树种精细识别领域被广泛使用。
雷达和光学影像的融合可以克服单个传感器的缺点,充分利用多种信息之间的优势互补来提高地物提取精度,尤其改善森林分类[8]。黄翀等[8]通过Sentinel-1/2数据提取树种的多种特征,利用随机森林算法进行热带典型人工林树种精细识别,总体精度达85%。有研究表明,多时相时间序列数据能反映不同树种在生长发育过程中随时间的周期性变化,识别不易区分的树种类型,提高树种分类的精度[9]。例如,Bjerreskov等[10]基于多时相Sentinel-1和Sentinel-2数据结合随机森林算法,对丹麦景观进行全面分类,结果表明多时相和多传感器数据的结合产生了较好的分类效果。Ghorbanian等[11]通过构建Sentinel-1和Sentinel-2时间序列数据以提取树种的季节物候特征,并利用随机森林算法进行红树林生态系统制图,总体精度达93.23%,研究结果表明季节特征和多源遥感数据的结合有助于获得更高的分类精度。
除数据源外,分类算法在一定程度上也会影响分类结果。随机森林分类算法因其模型训练少,计算精度高而被广泛应用于森林类型分类中,是目前森林树种识别应用最广泛的分类方法[8,10-11]。
进行大范围森林树种识别时,数据的获取与处理仍是关键问题。Google Earth Engine(GEE)平台凭借其并行运算,不受空间和时间约束的优势,在土地利用分类[12]、植被类型分类[13]和作物识别[14]等方面被用于进行深入研究。同时,研究区森林类型以针叶林为主,占全市面积的80%以上,在香格里拉市生态保护以及社会经济发展中占据重要地位[15]。因此,本研究基于GEE平台,以Sentinel-1/2时间序列数据为主要数据源,充分利用光学数据的光谱和纹理特征以及合成孔径雷达(SAR)数据的雷达和纹理特征,结合时序特征和地形特征,使用随机森林算法对香格里拉4种针叶林优势树种识别进行研究,以期为该区域进一步开展森林碳储量、碳汇、生态水文保护等研究提供科学参考。
1 研究区概况与数据处理
1.1 研究区概况
香格里拉市位于云南省西北部的滇川藏三省交界区,地处迪庆香格里拉腹心地带,地理坐标为99°20′~100°19′E,26°52′~28°52′N,如图1所示。研究区地形西北高、东南低,平均海拔3 549 m,垂直落差大,气候属温带-山地季风气候,年平均气温4.7~16.5 ℃,是我国保存较好的以亚高山针叶林为主的天然林区。据统计,研究区总面积11 613 km2,森林覆盖率74.99%,植物资源丰富,常见树种有高山松(Pinusdensata)、云南松(Pinusyunnanensis)、云冷杉(Piceaasperata)和高山栎(Quercusaquifolioides)等[15]。
1.2 数据来源与处理
1.2.1 Sentinel数据
Sentinel-1雷达数据和Sentinel-2光学数据均从GEE平台获取(https://developers.google.com/earth-engine/datasets/catalog/sentinel),获取的影像时间范围均为2020年1月1日—2020年12月31日。
Sentinel-1数据为IW模式下VV、VH双极化特征的Level-1级别地距影像(Ground Range Detected,GRD),分辨率为10 m。GEE平台中的Sentinel-1 SAR GRD数据已经经过Sentinel-1工具箱工具进行了多视处理、应用轨道文件和辐射定标等预处理。由于SAR影像中固有的斑点噪声降低了影像的质量,因此本研究采用Refined Lee散斑滤波器消除斑点噪声的影响[16]。
Sentinel-2数据以高空间分辨率和丰富的光谱信息被广泛应用于植被、土壤和海洋等监测和分类领域。本研究选择已经过大气校正的Sentinel-2A数据,选取B2—B8、B8A、B11、B12共计10个波段,并用双线性法将波段重采样至10 m。由于云及阴影的噪声影响,筛选云量低于30%的影像中值合成无云影像。

图1 研究区位置、样本及影像Fig.1 Study area, samples and images
主成分分析(Principal Component Analysis,PCA)是一种用于消除数据冗余并保留相关信息的技术。使用PCA对SAR与光学数据进行融合不会丢失大部分信息,因此,与其他融合方法相比,基于PCA融合能提供更高质量的数据[13]。本研究首先对Sentinel-2影像进行PCA变换,然后将贡献最少信息量的2个成分(最后2个成分)替换为Sentinel-1的VV和VH波段,最后通过逆主成分变换将波段融合,得到数据质量较高的影像。
1.2.2 DEM(数字高程模型)数据
研究区地形垂直落差大,树种的分布具有垂直分布的特点,结合地形数据能够有效增强树种的可分性[17-18]。本研究所使用的高程数据(SRTM DEM)直接从GEE获取,空间分辨率为30 m,并生成海拔(Elevation)、坡度(Slope)、坡向(Aspect)。
1.2.3 样本数据
以Google Earth高清历史影像和森林资源调查数据为参考绘制样本数据。森林资源调查数据来源于香格里拉市2016年森林资源二类调查成果,以矢量形式存储,包括胸径、树高、地类、优势树种和面积等属性信息。
本研究使用的样本数据共分为3层。第1层样本数据为通过Google Earth高清影像目视解译获得的300 m×300 m面数据,用于森林和非森林分类;第2层样本数据由森林资源调查数据获得,根据地类和优势树种随机生成30 m×30 m的面数据,用来划分针叶林和阔叶林。第3层样本数据来源于森林资源调查数据,根据优势树种随机生成10 m×10 m的面数据,用来划分优势树种。每层数据均由面数据转为点数据,并选取70% 作为训练数据,30% 作为测试数据,训练数据和测试数据各自独立不重复,样本统计见表1。
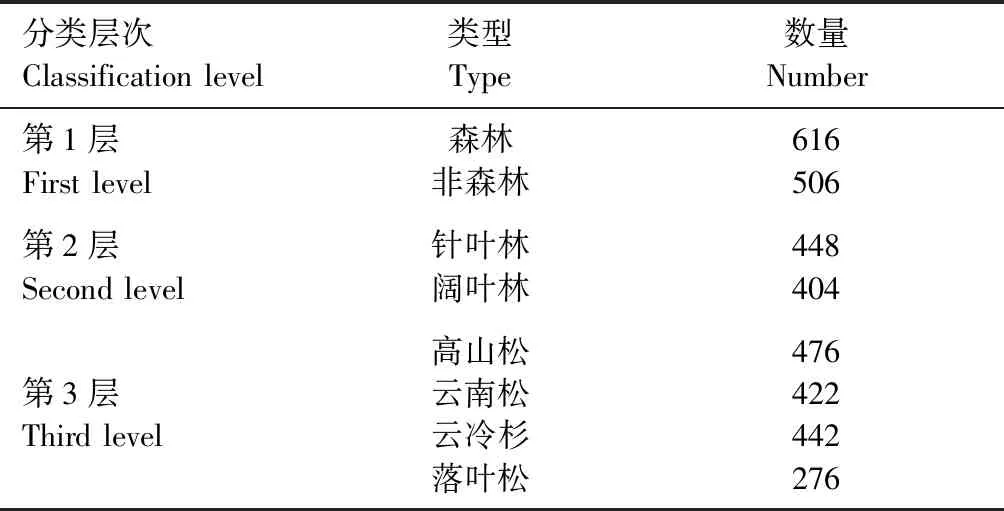
表1 分类体系及样本数量
2 研究方法
优势树种识别技术路线图如图2所示。研究过程总体分为3部分,即数据获取与预处理、特征提取与特征组合以及分层分类与精度评价。首先,在GEE平台上获取Sentinel-1/2数据并进行去噪、去云、裁剪和融合等预处理;其次,提取Sentinel-1雷达特征、纹理特征,Sentinel-2光谱特征、纹理特征、时序特征和地形特征等共计43个特征,根据不同特征组合形成6种组合方案;最后,利用随机森林算法在3个层次上对6种组合方案分别进行森林分类,并对分类结果进行精度评价。
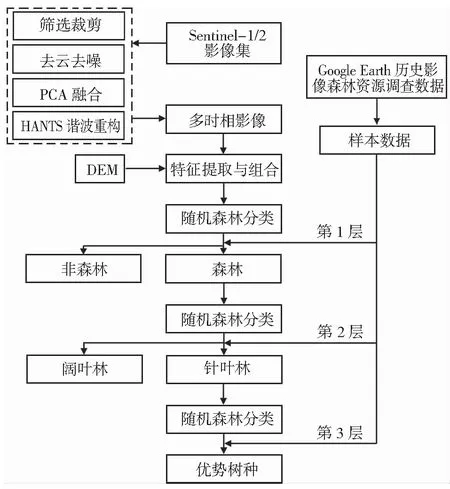
图2 优势树种识别技术路线图Fig.2 Flowchart of dominant species classification
2.1 特征提取与特征组合
2.1.1 Sentinel-1雷达特征提取
研究表明,VV、VH极化特征的差值(Diff)和比值(Ratio)对分类具有重要作用[19]。选择VV、VH、Diff、Ratio4个波段作为Sentinel-1雷达特征参与分类,Diff和Ratio计算公式如下
(1)
(2)
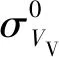
2.1.2 Sentinel-1纹理特征提取
由于雷达对土壤含水量敏感且对植被冠层具有很强的穿透能力,因此Sentinel-1雷达数据包含较丰富的纹理信息。灰度共生矩阵(Gray-Level Co-occurrence Matrix,GLCM)是Haralick[20]提出的一种有效提取纹理特征的方法,其基于像素点对间的灰度关系统计纹理信息。为减少特征冗余,选取6个重要的纹理特征参与分类,包括熵(Entropy,ENT)、相关性(Correlation,COR)、对比度(Contrast,CON)、角二阶矩(Angular Second Moment,ASM)、相异性(Dissimilarity,DISS)和方差(Variance,VAR)。
2.1.3 Sentinel-2光谱特征提取
研究使用的光谱波段分别为B2—B8、B8A、B11、B12。同时,植被指数能较好地反映植被生长状况,因此加入归一化植被指数(Normalized Difference Vegetation Index,NDVI)和增强型植被指数(Enhanced Vegetation Index,EVI)。
2.1.4 时序特征提取
现有的研究表明,植被指数时间序列被广泛地应用于分类和时序特征提取中[21]。因此,本研究通过重构NDVI、EVI时间序列提取植被的时序特征参与分类。本研究用到的时间序列重构方法为HANTS谐波分析。其核心原理是时间波谱数据可以分解为多个简单的波谱曲线,首先通过快速傅里叶变换得到观测样本的原本拟合曲线,之后通过对无效数据赋予零权重而去除无效数据,从而将原来的曲线拟合问题转化为加权最小二乘曲线拟合以达到时序重构的目的。表达式如下
(3)
式中:A0为余项,表示时序的平均值;n为时间间隔;N为时间序列长度;An为振幅;ωn为时间频率;φn为相位角。
与AG拟合、DL拟合、Savitzky-Golay滤波相比,HANTS谐波分析法能更好地反映植被在长时间序列内的物候特征[20]。其中,相位角(Phase)、振幅(Amplitude)和频率(Frequency)是HANTS谐波分析重构时间序列曲线的主要特征参数。根据植被变化规律,本研究选取的时序特征为相位角(NDVI_ Phase、EVI_ Phase)、振幅(NDVI_ Amplitude、EVI_ Amplitude)和频率(NDVI_ Frequency、EVI_ Frequency)。
2.1.5 Sentinel-2纹理特征提取
同样地,Sentinel-2含有丰富的纹理特征。为了避免特征冗余,本研究选用3×3窗口,利用PCA进行数据降维,基于第一主成分提取6种纹理特征参与分类,详见表2。
2.1.6 特征组合
本研究设计了6种特征组合方案来评估不同特征对香格里拉市优势树种识别的能力与贡献,见表3。

表2 特征统计与说明
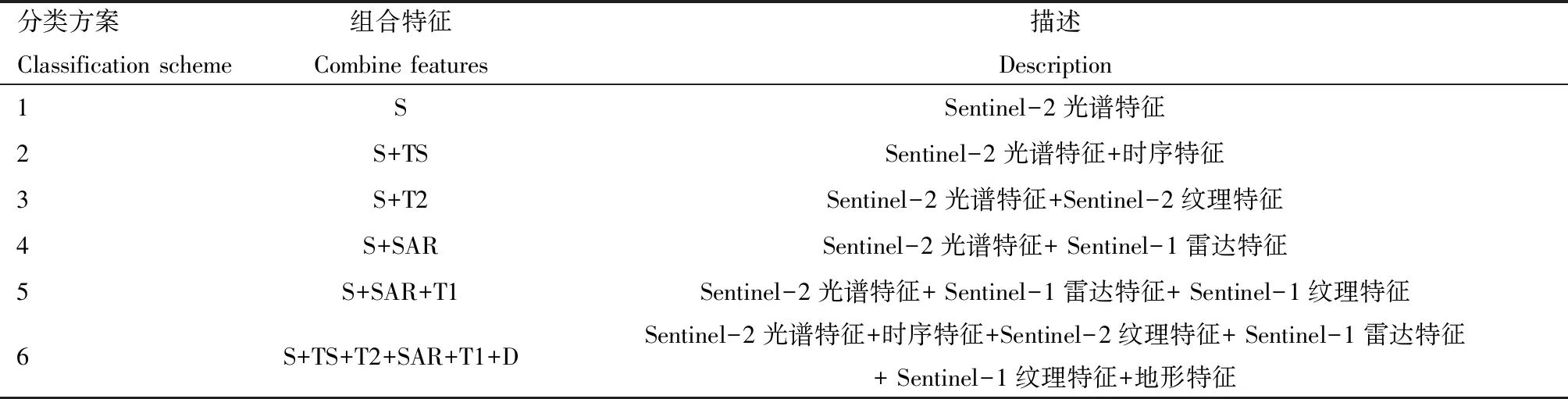
表3 特征组合
2.2 分类方法及精度评价
Breiman[22]提出的随机森林(Random Forest,RF)分类模型是一种常用的机器学习分类算法,其通过构建多个决策树来运行。与其他机器学习算法相比,RF算法具有计算精度高、模型训练时间少,且能够确定变量在模型中的重要性等优势,因此该方法被广泛应用于分类研究中。在GEE中调用随机森林分类模型,该模型参数较少,决策树数量和变量数量是影响其结果的参数。针对每一层分类,在计算可以负荷的情况下,选择精度最高时的决策树数量。研究采用的随机森林决策树数量第1层是100,第2层是300,第3层是200,且变量数量默认为特征变量总数的平方根。
本研究使用混淆矩阵对分类精度进行评价,即用户精度(User Accuracy,UA,公式中为UA)、制图精度(Producer Accuracy,PA,公式中为PA)、总体精度(Overall Accuracy,OA)和Kappa系数。但在实际分类中,PA和UA又相互制衡,不能准确判断分类的优劣,所以引入PA和UA的调和平均值(F1)评价分类效果[23]。F1的计算公式如下
(4)
式中,F1的取值范围是[0,1]。
3 结果与分析
3.1 森林/非森林分类精度评价
基于不同特征组合的森林/非森林分类精度评价结果见表4。所有实验的OA均高于87%,Kappa系数均高于0.80,F1均高于86%。基于方案6所有特征的分类精度最高,OA为98.73%,Kappa系数为0.97,F1为98.71%。采用精度最高的方案6的分类结果计算林地面积,得到分类结果:森林面积为7 856.70 km2,而森林资源调查面积为7 800.26 km2,两者之间相对误差0.72%。通过目视评价和面积对比分析可知,基于方案6的森林/非森林分类结果可以作为第2层分类的掩膜。

表4 森林/非森林分类精度评价Tab.4 Accuracy assessment for the forest/non-forest classification
3.2 针叶林/阔叶林分类精度评价
基于不同特征组合的针叶林/阔叶林分类精度评价结果见表5。所有实验的OA均高于83%,Kappa 系数均高于0.70,F1均高于83%。基于方案6所有特征的分类精度最高,OA为92.80%,Kappa系数为0.85,F1为92.58%。采用精度最高的方案6的分类结果计算针叶林面积,得出研究区针叶林面积6 437.94 km2,而森林资源调查为6 157.42 km2,两者之间相对误差4.56%,此次针叶林/阔叶林分类结果可以作为第3层分类的掩膜。

表5 针叶林/阔叶林分类精度评价Tab.5 The summary of the accuracy assessment for the needle-leaved forest/broad-leaved forest classification
3.3 不同树种在光谱特征和雷达特征上的可分离性
分别提取针叶林中高山松、云南松、云冷杉和落叶松在光谱特征和雷达特征上的特征均值,如图3所示。由图3(a)可知,同为针叶林,不同树种在不同波段的反射率不同,但在整体上这4种树种的曲线走势较为相似,符合绿色植被的光谱曲线。在B2、B3、B4波段呈现“蓝谷”“绿峰”“红谷”现象,之后波段反射率先上升后下降,在B5、B6、B7、B8、B8A、B11、B12波段相差较大,从而提高不同树种之间的光谱可分性。由图3(b)可知,高山松在VV、VH波段与其他3种树种具有明显差异,特征值最低,可分离性较好;云南松、云冷杉、落叶松在VV、VH、Diff特征上有一定的差异,且特征值从大到小排序为:云南松、云冷杉、落叶松,可充分利用Sentinel-1雷达波段对优势树种进行有效提取。
NDVI、EVI时间序列曲线如图3(c)和图3(d)所示。云南松的EVI值要高于其他3种类型,NDVI值大部分时间高于其他3种类型。云南松与云冷杉在NDVI时间序列曲线上呈现季节性相反状态。落叶松属落叶树种,在冬季的NDVI和EVI值明显低于其他3种树种,春夏2季树木生长,其NDVI和EVI值上升,秋季开始落叶,NDVI和EVI值开始下降。4种树种的EVI整体呈现春夏上升,秋冬下降,夏季值最高的趋势。4种树种的植被指数时间序列具有一定的差异,可以作为树种识别的分类基础。

图3 4种树种在光谱特征、雷达特征和时序特征上的可分离性Fig.3 Separability of spectral features, SAR features, time-series features of 4 species
3.4 优势树种识别精度评价
基于6种特征组合的树种分类结果如图4所示。与仅利用Sentinel-2光谱特征(S)分类相比,加入其他分类特征(S+TS、S+T2、S+SAR、S+SAR+T1、S+TS+T2+SAR+T1+D)后,分类图斑的破碎化程度减少,各地类更为集中。但是不同特征组合分类结果的局部差异仍然存在,方案6(如图5(f)所示)的分类结果显示各树种更聚集,高山松和云南松之间、云冷杉和落叶松之间的混淆程度相对其他方案(图5(a)—图5(e))减少,与实际调查情况(图5(g))最接近。
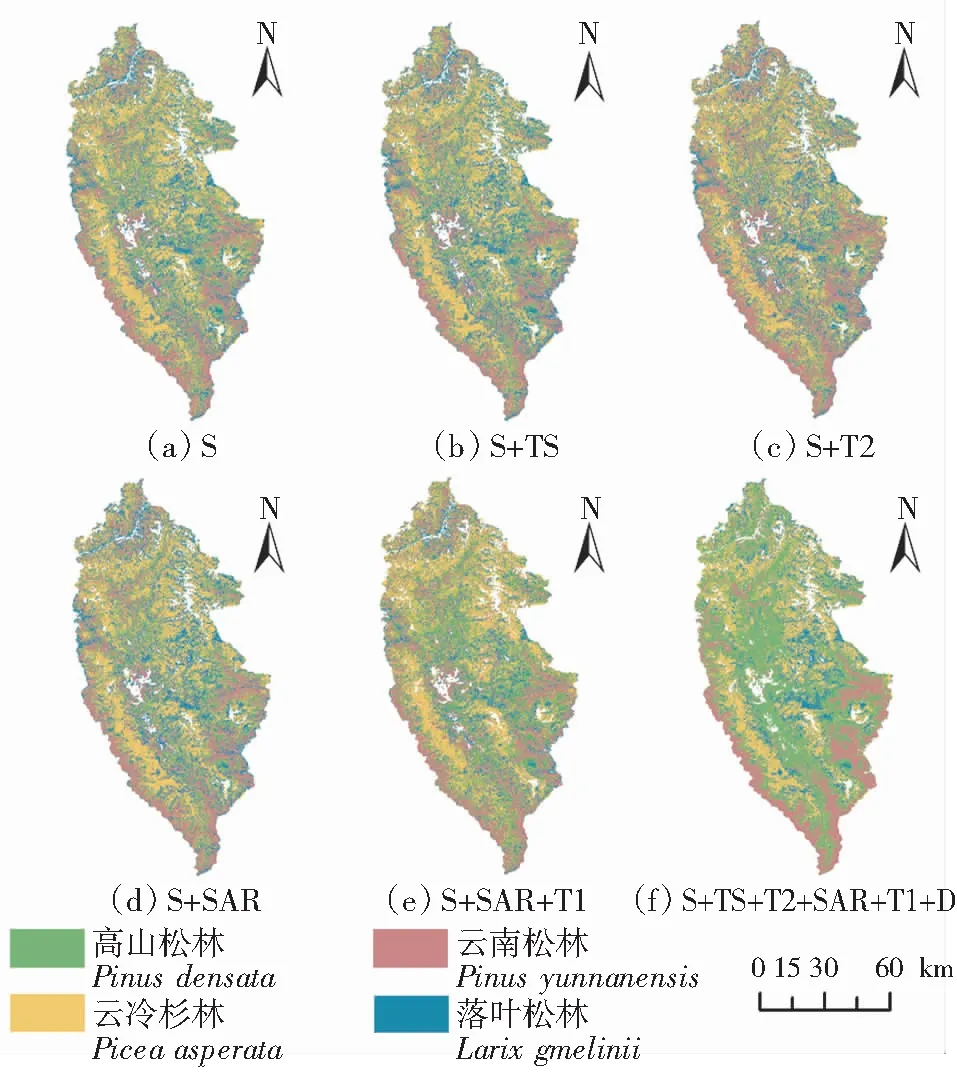
图4 不同特征组合的树种分类结果Fig.4 Classification results of different feature combinations
结合不同特征组合的混淆矩阵(图6)和精度评价(表6)可知,所有实验的OA均高于81%,Kappa系数均高于0.75,F1均高于80%。方案1中,不同树种之间存在不同程度的混淆,整体分类效果不佳,这是因为各树种同属森林地类,仅利用光谱信息很难进行区分,OA为81.28%,Kappa系数为0.75,F1为80.74%。方案2—方案6中,在光谱特征的基础上,加入其他分类特征,使得高山松和云南松、云冷杉和落叶松之间的混淆程度有所减少,各优势树种的PA和UA明显提高,与方案1相比OA分别提高了2.05%、1.23%、0.82%、2.05%和8.23%,Kappa系数分别提高了2.68%、1.65%、1.00%、2.72%和11.13%,F1分别提高了1.75%、1.34%、0.75%、2.16%和8.62%,说明增加时序特征、纹理特征、雷达特征和地形特征在一定程度上可提高树种识别精度。在方案6中,4种优势树种间的混淆程度最小,分类结果最好,整体分类精度最高,其OA为89.51%,Kappa系数为0.86,F1为89.36%。
综合来看,高山松和云南松之间容易发生混淆,原因是:虽然高山松在垂直分布上较云南松高,但在海拔3 000 m以下以高山松与云南松混交为主,因此容易相互混淆。云冷杉和落叶松相互混淆也较多,这是因为这2种优势树种同属于寒温性针叶林,在海拔上分布几乎一致,而落叶松往往是云冷杉经火烧采伐后恢复更新的树种,因此比较容易造成错分。
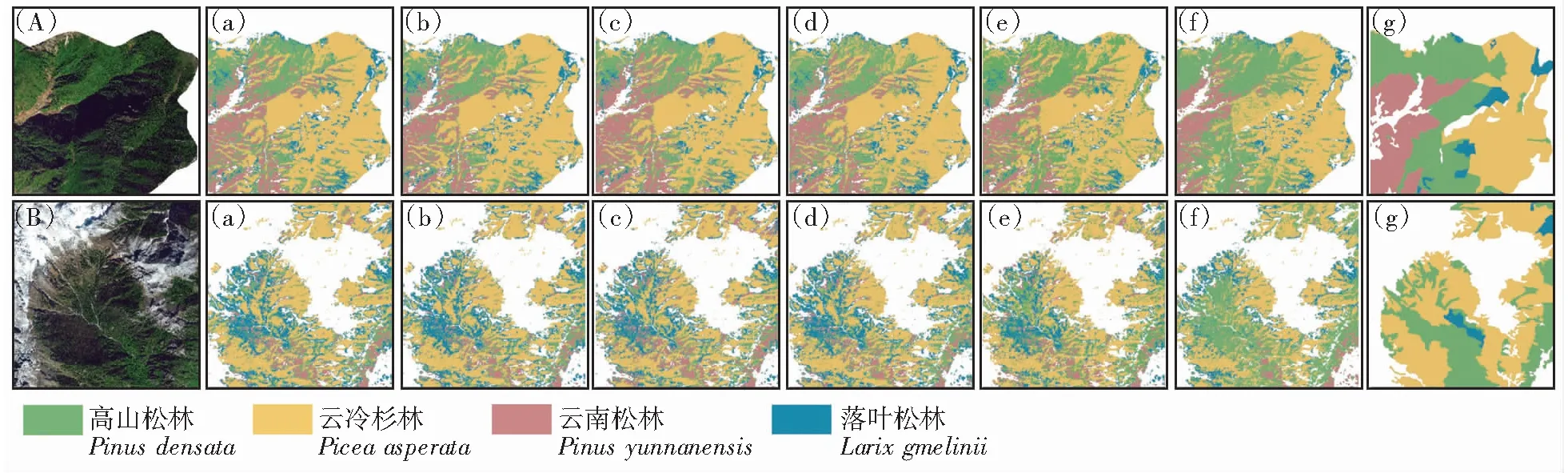
(A)、(B) 高清影像;(a) S;(b) S+TS;(c) S+T2;(d) S+SAR(e) S+SAR+T1;(f) S+TS+T2+SAR+T1+D;(g) 二类调查

Pd代表高山松;Py代表云南松;Pa代表云冷杉;Lg代表落叶松。

表6 不同特征组合的分类精度Tab.6 Classification accuracy of different feature combinations %
3.5 特征重要性排名
基于方案6使用RF计算得出的特征重要性结果见表7。

表7 基于方案6特征重要性结果Tab.7 The result of feature importance based on experiment 6
海拔的重要性最高,为6.10%;其次为短波红外波段B11、B12,重要性分别为3.98%和3.33%;红边波段B8A、B5、B7、B6的重要性分别为2.64%、2.51%、2.46%和2.32%,近红外波段B8的重要性为2.45%,也进一步说明了Sentinel-2新增红边波段、近红外波段与短红外波段在树种识别中的优势。植被指数EVI和NDVI的重要性为2.73%和2.63%,时序特征EVI_Phase、NDVI_Phase、NDVI_Frequency、NDVI_Amplitude、EVI_Frequency和EVI_ Amplitude的重要性分别为3.19%、2.73%、2.62%、2.47%、2.40%和2.17%,说明了加入植被指数及其衍生的时序特征能够有效提升树种识别的能力;雷达特征Diff、Ratio、VV和VH的重要性分别为3.13%、2.33%、2.26%和2.17%,说明雷达特征对树种识别具有较高价值;Sentinel-2纹理特征pc1_CON、pc1_VAR、pc1_DISS和pc1_COR的重要性分别为2.81%、2.50%、2.28%和2.27%,而波段pc1_ENT和pc1_ASM的重要性最低,不足1%。
4 结论与讨论
4.1 结论
本研究基于GEE平台,以香格里拉市为研究区,通过融合Sentinel-1和Sentinel-2时间序列数据,提取其时序特征,并结合雷达特征、纹理特征和地形特征,采用随机森林算法和分层分类法开展研究区优势树种识别研究,主要得出以下结论。
(1)融合Sentinel-1/2时间序列数据能够在10 m空间分辨率下进行森林树种识别,总体精度可达89.51%,Kappa系数可达0.86,表明Sentinel数据在识别植被这一领域有较好的应用价值。
(2)不同分类特征的结合比仅用光谱特征分类时的精度都高,说明单一特征进行树种识别仍具有局限性,而多源遥感数据融合与多特征的结合能充分利用不同树种在各个特征上的可分性,提高其识别精度。
(3)分层分类法和随机森林算法的结合能够提高分类效率,使结果更加可靠。
(4) 研究区气候类型多变,植被复杂多样,云与地形等因素严重影响遥感影像的获取,所以研究使用密集的时序数据结合HANTS时序重构方法以减少云对识别精度的影响。时间序列影像数据及其时序特征对于提高识别精度具有关键作用。
4.2 讨论
本研究融合Sentinel-1/2时间序列影像的森林优势树种识别精度明显高于使用单期Sentinel-1/2影像的树种分类精度[8],表明采用多源时序遥感数据的时序特征能够提高森林优势树种的分类精度。与其他使用时序特征(平均值)的树种识别研究相比[10],本研究加入了基于HANTS时序谐波重构的时序拟合特征(相位角、振幅和频率),分类精度由74%提高到89%。但需说明的是,本研究仅采用了2020年的NDVI、EVI曲线衍生的时序特征进行分类,实际上Sentinel-2包含丰富的光谱信息及衍生的光谱指数,如何利用多样的长时序特征结合多变的环境变量(温度、降水等)进行高海拔地区森林优势树种识别需要进一步研究。
猜你喜欢
中国农业信息(2021年3期)2021-11-22
电子制作(2018年2期)2018-04-18
现代园艺(2018年2期)2018-03-15
电子制作(2017年13期)2017-12-15
电子制作(2016年15期)2017-01-15
高师理科学刊(2016年8期)2016-06-15
中国林业产业(2016年5期)2016-04-03
中国林业产业(2016年5期)2016-04-03
西藏科技(2015年4期)2015-09-26
武夷学院学报(2014年5期)2014-07-19
