
改进RetinaNet的无人机小目标检测
2023-02-11 09:48刘晋川黎向锋刘安旭赵康李高扬左敦稳
科学技术与工程 2023年1期
刘晋川, 黎向锋, 刘安旭, 赵康, 李高扬, 左敦稳
(南京航空航天大学机电学院, 南京 210016)
近年来,人工智能与计算机技术持续迭代,计算机硬件和光电成像设备不断更新,这极大地推动了计算机视觉领域的发展,同时,搭载着高效视觉系统的无人机在军事和民用领域的应用也更加广泛。然而,无人机由于拍摄高度高、视野广,其获得的图像中往往包含大量小目标,像素信息少且边界模糊,很难提取到有效的目标特征。传统的目标检测方法根据颜色、纹理、边界等信息人工设计特征描述符[1]提取目标特征,最后通过支持向量机(support vector machine,SVM)实现目标分类;但该类算法中特征的设计以及选择在很大程度上依赖于人工,导致特征提取器设置复杂,对复杂多变的特征鲁棒性差,且传统算法中基于滑动窗口的区域选择策略没有针对性,窗口冗余,复杂度高,实时性差,难以胜任无人机图像中的目标检测任务。近年来,基于卷积神经网络(convolutional neural networks, CNN)的深度学习检测方法快速发展,该方法设计方便且泛化能力强,已逐渐成为目标检测的主流方法。
基于深度学习的目标检测方法按照检测阶段大致可以分为二阶段检测算法和一阶段检测算法。二阶段算法通过对候选框进行初筛后再对候选区域中的目标进行定位与识别,如Faster R-CNN[2]、特征金字塔网络(feature pyramid networks,FPN)[3]都是经典的二阶段检测算法,该类算法可以取得较高的检测精度,但检测速度较慢;一阶段算法不对候选框进行初筛,而是通过回归思想直接完成检测和识别,检测速度大大提升,但精度略低,如YOLOv3[4]、单点多盒探测器(single shot multibox detector,SSD)[5]、RetinaNet[6]等都是通用的一阶段算法。相比传统算法,基于深度学习的目标检测算法性能更高,但对小目标的检测效果仍有很大提升空间。
通过丰富特征图中的小目标信息是提高小目标检测精度最有效、最常用的手段,如采用注意力机制、FPN等方法。2018年,Liu等[7]设计了由深至浅、再由浅至深的两条特征图融合路径,相比FPN,进一步加强了特征信息流动,丰富了特征图信息,并由此提出了路径聚合网络(path aggregation network,PANet);2019年,Ghiasi等[8]通过神经网络搜索技术搜寻“最优”的特征图融合路径,通过融合跨比例的特征图,得到了性能极高但融合路径复杂的NAS-FPN网络,相比FPN,在COCO测试集上检测精度提升了2%;曹凯等[9]通过模拟人类视觉选择注意力机制提出了SENet注意力模型,通过学习每个特征通道的重要性对特征图特征进行重标定,增强有用信息,抑制无用信息,极大地降低了检测模型的错误率;Woo等[10]采用全局池化方法设计了通道注意力和空间注意力两个模块,并实验验证了其嵌入顺序,通过串行连接两个注意力模块有效提高了对小目标信息的关注程度;Zhang等[11]在2019年提出了CAD-Net,利用注意力机制以及上下文信息实现了对遥感目标的检测,可以对图像中的小目标以及密集目标实现精准识别。虽然上述方法都可以对小目标的检测起到正面效果,但大部分方法都会对网络的计算量和参数量带来较大负荷,最终导致检测速度无法达到实时要求。
合理的锚框机制也是提升网络对小目标的检测精度的常用方法。大部分目标检测算法通过在特征图的每个像素点上铺设一组预定义好的锚框来实现目标检测,该类方法一般通过人工或聚类算法[12]设计合适的锚框尺寸以提升检测精度,对不同的数据集泛化性较差。近年来,一种新型的无锚框(Anchor-free)检测方法也在迅速发展。Law等[13]提出的CornerNet是性能较高的无锚框检测算法,该算法不再设计锚框检测目标,而是将目标检测看作是对两个关键点位置的预测,通过预测两组热力特征图确定关键点的位置,该方法在当时Anchor-base的检测潮流下取得了不错的效果;不同于CornerNet对两个角点的检测方式,Tian等[14]提出的全卷积的单级目标检测器(fully convolutional one-stage,FCOS)算法对每个中心点就行回归,回归目标则是中心点相对于边界框上、下、左、右4条边的距离,在当时Anchor-free检测算法中性能达到最高;Zhang等[15]指出导致Anchor-base与Anchor-free方法存在差异的根本原因在于其正负样本的定义不同,深入分析了正负样本的选择对检测精度的影响,并针对该问题设计了自适应训练样本选择(adaptive training sample selection,ATSS)方法来确定正负样本,实验结果表明,该方法可以有效提升算法的检测精度。
RetinaNet是检测精度较高的一阶段算法,分3个模块完成对目标的检测:首先是特征提取网络,该模块通过CNN提取图片特征,生成包含细粒度信息(纹理、颜色等)的浅层特征图与包含粗粒度信息(语义信息)的深层特征图;随后通过FPN网络融合各特征图信息,加强各特征图之间的信息流动;最后设计锚框检测各特征图中的目标并对其进行打分,筛选出可信度较高的检测结果,从而实现目标的定位和检测。RetinaNet可以对航拍下的中大型目标取得较好的检测效果,但对小目标的漏检率较高。现以RetinaNet为基础,以提高无人机航拍图像中小目标检测精度为主要目标,通过丰富特征图信息及锚框机制等手段设计检测精度高、检测速度快的无人机航拍目标检测算法。首先提出一种多阶段特征融合方法,并结合注意力机制设计特征挖掘模块(feature mining module,FMM),充分提取图像中感兴趣目标信息;其次,在RetinaNet网络中设计基于中心点的Anchor-free检测方法,避免人工设计锚框超参数;最后,为了减小模型大小、提高检测速度,采用深度可分离卷积的方法对提出的特征提取网络进行轻量化设计,使之可以胜任实时的目标检测任务。
1 改进RetinaNet算法设计
RetinaNet算法精髓是Focal Loss损失函数。针对检测过程中参与反向传播的前景目标和背景目标比例不均衡现象,在交叉熵损失函数中添加了正负样本的权衡因子与之相乘,得到了Focal Loss损失函数,该损失函数可以自动判断正负样本并决定该样本对总损失的贡献,一定程度上解决了正负样本不均衡现象,提升了一阶段算法的检测精度。在RetinaNet之前的通用算法一般使用二分类交叉熵作为损失函数,其计算过程为

(1)
式(1)中:CE为交叉熵函数;y为二分类结果,前景为1,背景为-1;p为预测结果y=1的概率。在Focal Loss中,为了方便,定义新的参数pt为
(2)
则可重写交叉熵损失函数为
CE(p,y)=CE(pt)=-lnpt
(3)
通常解决正负样本不均衡的方法是在损失函数前引入权重因子α(α∈[0,1]),但该方法只能平衡正负样本,并不能区分两者。故在函数上加了权重参数使其注重难分类样本对损失的贡献,整合出的损失函数如式(4)所示。
FL(pt)=-αt(1-pt)γlnpt
(4)
式(4)中:γ为关注度参数;α为权重因子。经实验,当γ=2,α=0.25时,网络的表现最好。
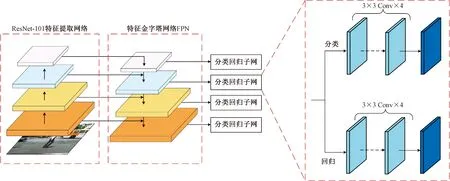
图1 RetinaNet结构图Fig.1 The structure of RetinaNet
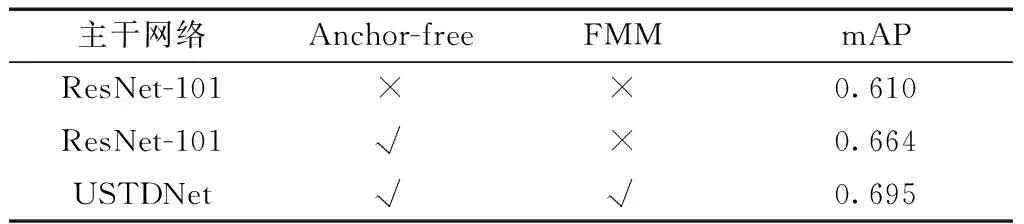
图1为RetinaNet网络检测流程图,RetinaNet[6]采用何恺明团队提出的ResNet-101深度残差网络为主干网络,生成不同深度特征图后经FPN网络进行特征融合,最后基于锚框(Anchor-base)方法在多尺度上回归目标。将设计特征提取能力更强的FMM模块取代ResNet-101中的残差块,并设计Anchor-free的方法检测目标,最后对重新设计的主干网络进行模型压缩,达到检测精度与检测速度的均衡,使其应用在实时检测任务中。
1.1 FMM模块设计
为了尽可能丰富特征图中的目标信息,对传统残差块进行了改进,设计了注意力机制与多阶段特征融合方法,最终构成FMM模块取代传统残差结构。
1.1.1 注意力模块
FMM模块中采用的注意力结构如图2所示,该方法旨在通过建模输入特征图通道间的关系,使网络自动学习每个通道的重要程度,从而挖掘特征图中的重要信息。图2中,X和Y分别为输入输出特征图,其维度保持一致,均为H×W×C。整体操作由压缩和扩张两部分完成;由于X的每个通道都是二维特征,很难捕捉到每个通道之间的关系,所以,通过全局池化将特征图每个通道的信息变换为一个像素,保持通道数不变,从而生成1×1×C的特征向量zc,该过程即为压缩操作,公式为
(5)
式(5)中:xc为输入特征图中每个通道对应的二维向量;(i,j)为枚举该通道的每一个像素点;SQ即为压缩操作;zc为压缩得到的一维向量。压缩后通过扩张操作获取每个特征通道间的依赖关系,计算公式为
s=EX(z,W)=σ[W2δ(W1z)]
(6)
式(6)中:s为通道重要性向量;W1的维度是C/r×C,用来进行全连接层的计算;r为缩放因子,一般取r=16,以降低计算量;W1与z相乘后得到1×1×C/r的向量,然后该向量会经过一个ReLU激活函数(式中δ操作),随后与维度为C×C/r的W2相乘,其输出的维度为1×1×C,该向量中的C对应输入特征图X中各个通道的重要程度。最后将得到的表示通道重要性的向量作用到原特征通道上,以完成对原始通道的重标定。
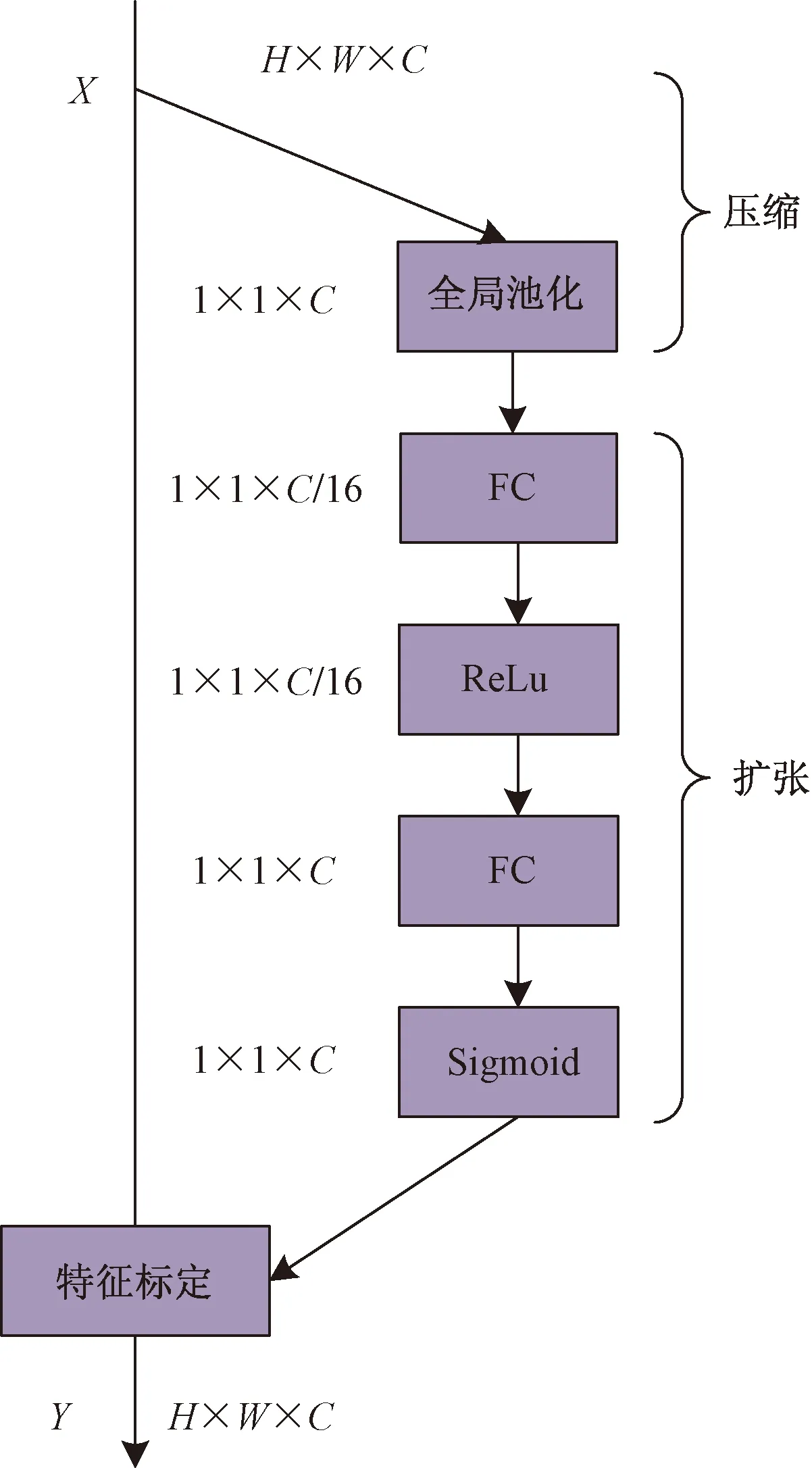
图2 注意力模块结构图Fig.2 The structure of attention module
1.1.2 多阶段特征融合
常见的残差网络如ResNet、ResNext[16]以及ResNeSt[17]等为加强特征图中的小目标信息,会将特征提取网络生成的最终阶段的特征图进行连接融合以增强目标信息,可以有效提升检测精度。借鉴这种思想,在特征提取过程中设计了多阶段特征融合模块,在特征提取过程以及更小的粒度上融合特征图信息。
图3是传统残差块结构图,进入残差块的输入特征图首先经过1×1卷积降低通道数,再通过3×3卷积进行正常的特征提取,最后使用1×1卷积将其还原到初始通道数量,两者进行相加后作为该残差块的输出。提出的特征挖掘模块如图4所示,由多阶段特征融合模块与注意力机制结合而成。多阶段特征融合模块首先通过1×1卷积减少通道数,然后将通道顺序均分为k块,取k=4,每一小块Xi(除X1之外)都会先通过3×3的变形卷积[18]提取特征,该卷积操作用Ki表示,对应的卷积结果为Yi,在该流程中,每个Xi会先于Ki-1进行相加然后再进行Ki的卷积操作,最终会得到k个输出,将这些输出按照分割时的顺序进行拼接融合,再送入1×1的卷积扩张维度,最后与网络的输入相加得到最终的输出。通过在每个残差块中对特征图通道进行拆分和融合,可以在特征提取过程中就实现类似特征图融合的作用,从而提高对各类目标尤其是小目标的检测。
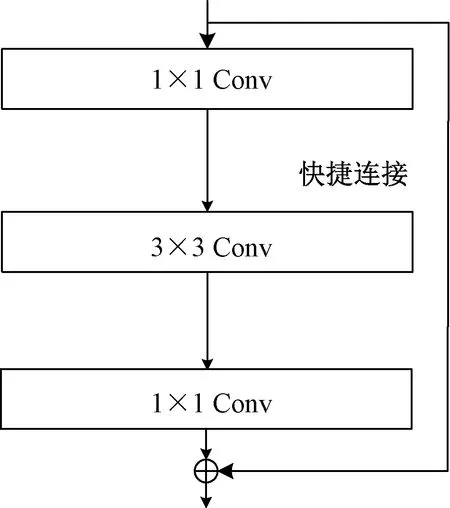
图3 传统残差块Fig.3 Traditional residual blocks
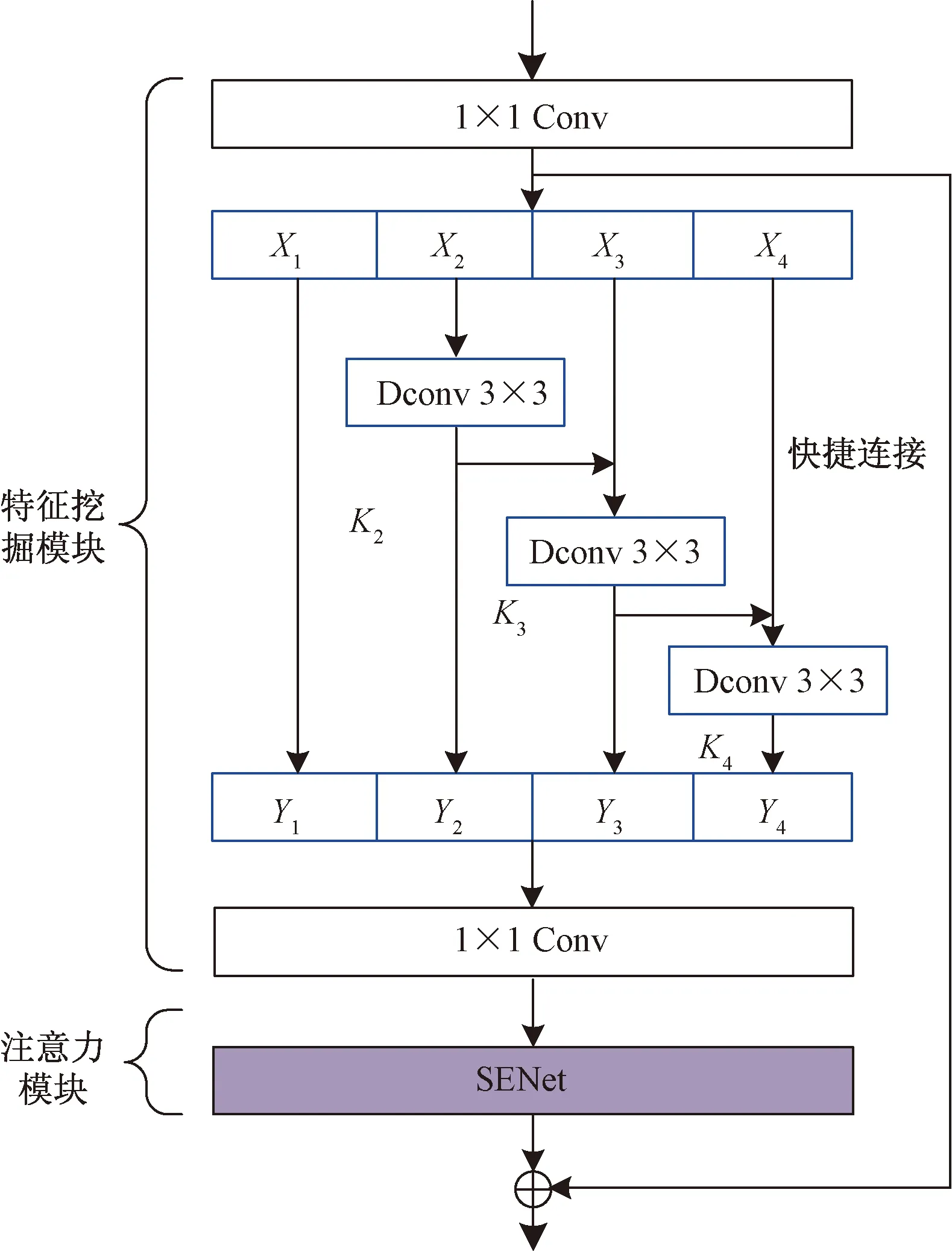
图4 特征挖掘模块Fig.4 Feature mining module
经FMM模块设计的特征提取网络结构如表1所示,命名为无人机小目标探测网络(UAV small target detection network,USTDNet)。输入网络的图像尺寸为800 pixel×800 pixel。
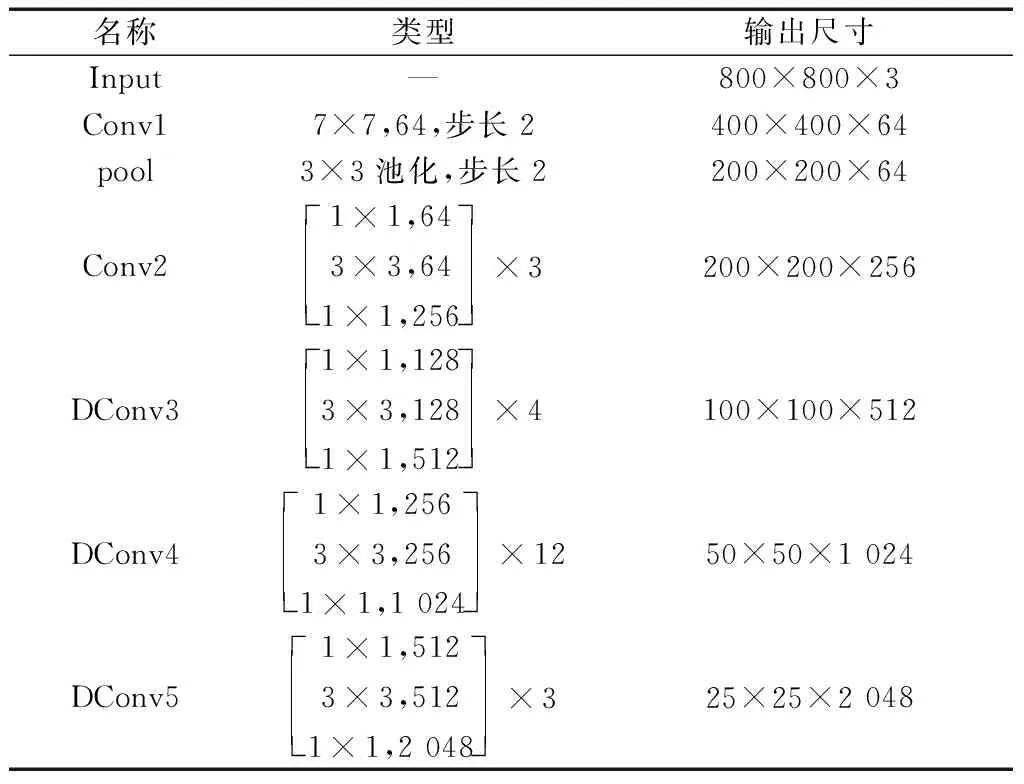
表1 USTDNet网络结构Table 1 The structure of USTDNet
图5为ResNet-101与USTDNet对同一张图像进行特征提取后得到的热力特征图,其中暖色像素对网络的决策更加重要。从图5中可以看出,经FMM设计后的特征提取网络可以更加有效地关注到目标信息。

图5 ResNet-101与USTDNet热力图对比Fig.5 Heat map comparison between ResNet-101 and USTDNet
1.2 Anchor-free检测方法
目前的主流算法都是基于锚框检测目标的,虽然也能取得较高的检测精度,但是这种Anchor-base方法也有不少缺陷。Anchor-base模型依赖于初始锚框的设计,尺寸、长宽比都是重要的影响因素,设定好的anchor可以匹配到大多数目标,但是对于形变较大或者小尺寸目标会表现出一定的局限性,对不同的数据集泛化性能不好;再者,Anchor-base方法为了取得较高的召回率,会在每个特征图的像素点上铺设密集的锚框,导致网络在进行前向推演以及非极大值抑制[19](non-maximum suppression,NMS)时占用较多的资源。近年来研究学者提出Anchor-free的方法对其进行改进,经过几年的不断发展和完善,已经达到甚至超越了Anchor-base方法的检测精度。将设计基于中心的Anchor-free算法[20]对网络进行改进。
主干网络生成各阶段特征图之后,通过在特征图的每个特征点上生成一个中心点来对目标进行回归,回归的目标是该点距离真实框上、下、左、右边界的距离,分别用t、b、l、r表示,如图6所示。当某个点(x,y)落入真实框中时,就将其作为正样本,回归目标为T*=(l*,t*,r*,b*),按式(7)进行计算。
(7)
式(7)中:(x0,y0)和(x1,y1)分别为矩形框左上角和右下角的坐标。

图6 Anchor-free示意图Fig.6 Schematic diagram of Anchor-free
在上述过程中,由于有些中心点会远离其预测目标的中心,导致网络生成质量较低的边界框,影响检测精度,所以在Anchor-free方法中引入Center-ness策略抑制无效框的产生,计算公式为
(8)
式(8)中:d为预测中心(x,y)与预测物体中心之间的距离。
一般在进行NMS时,将其与分类置信度相乘作为NMS排序的分数依据,以去除距离物体中心较远的无效框。然而,在加入Center-ness分支的网络中,训练时分类预测和质量估计单独训练,测试时将两者相乘作为NMS排序指标,这必然会导致一定的误差;因为分类子网是将前景目标与大量背景目标混合进行训练的,而定位质量子网一般只针对前景目标进行训练,故存在一部分分类分数较低的背景目标可能获得较高的定位质量估计,两者相乘做NMS排序时,该背景目标可能被划分为正样本。
针对此现象,提出在训练时将分类预测与质量预测结合。通常,分类估计的输出为0或1(分类分数),通过将检测框的分类得分改为对应框的定位质量预测分数,从而达到训练和检测一致的目的。但由于Focal Loss是针对0和1这种离散标签设计的,而联合表示后得到的是0~1的连续值,所以有必要对其损失函数进行修改,故将原来的损失函数改为式(9),命名为质量焦点损失(quality focal loss,QFL)。
QFL(σ)=-|y-σ|β[(1-y)ln(1-σ)+ylnσ]
(9)
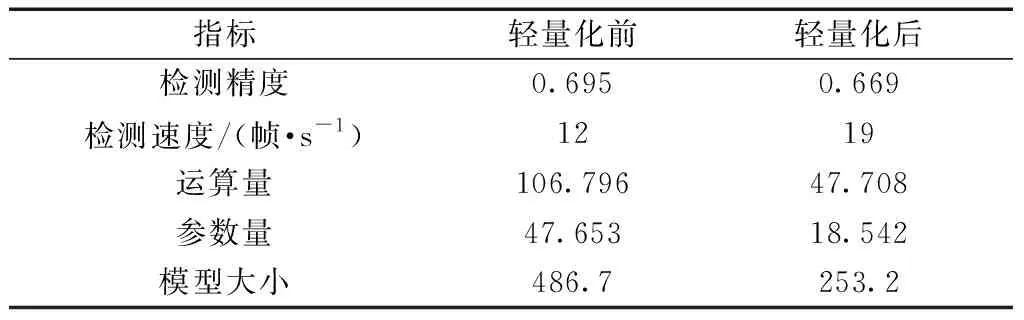
式(9)中:-[(1-y)ln(1-σ)+ylnσ]为原函数中-lnpt交叉熵函数的展开版本;y∈[0,1],表示定位质量分数,y为0时表示背景样本,0 采用深度可分离卷积的方法对改进RetinaNet进行轻量算法设计。深度可分离卷积由逐通道卷积和逐点卷积两部分组成。图7为上述3种不同卷积的操作流程图。可以看出,普通卷积中的每个卷积核都需要对特征图的每一个通道依次执行卷积计算,而逐通道卷积中每个卷积核只需要负责输入特征图的一个通道,大大减少了计算量,由于每个卷积核负责一个通道,所以特征图的输入和输出维度一致,后续可以使用逐点卷积对通道数进行扩充或缩减。 图7 三种不同卷积对比Fig.7 The comparisons of three different convolution 设输入、输出特征图尺寸分别为H×W×M、H×W×N,卷积核尺寸为K×K×M,则普通卷积的计算量Cstd和参数量Pstd分别为 Cstd=HWK2MN (10) Pstd=HWMN (11) 在进行深度可分离卷积时,逐通道卷积的计算量Cdc与参数量Pdc分别为 Cdc=HWK2M (12) Pdc=HWM (13) 逐点卷积的计算量Cpc和参数量Ppc分别为 Cpc=MNK2 (14) Ppc=MN (15) 则深度可分离卷积的计算量Cdsc和参数量Pdsc分别为 Cdsc=Cdc+Cpc=HWMK2+MNK2 (16) Pdsc=Pdc+Ppc=HWM+MN (17) 深度可分离卷积与普通卷积的计算量和参数量之比分别为 (18) (19) 在USTDNet网络中,卷积操作一般是由3×3大小的卷积核完成的,将网络中的3×3全集全部使用可分离卷积替换,采用该方法大约可以将计算量降为原来的1/9,参数量的减少比例取决与输入特征图的宽、高以及输出特征图的通道数。 DIOR数据集[21]是由西北工业大学在2019年提出的大型航拍数据集,是目前公开的最大、最多样化的航拍数据集之一。DIOR数据集中的图像来自Google Earth,包含23 463张图片,共有192 472个对象实例,图像尺寸均为800 pixel×800 pixel。作者选取了飞机、船舶、储罐、车辆等20类具有实用价值的目标,这些目标具有较大的尺寸变化,且存在较高的类内多样性,类间如车辆与船舶相似性较高。该数据集中的车辆、船只以及储罐等众多目标在图像中占比很小,十分适用于无人机视角下的小目标检测研究,故选取该数据集进行实验。 设计的算法应用在无人机图像检测任务中,需要对算法的预测结果进行定量评估以评价其性能。使用平均精度均值(mean average precision,mAP)作为检测精度的度量指标;用每秒检测帧数(frame per second,FPS)作为检测速度的度量指标。 DIOR数据集中用于训练、验证和测试的比例与原论文保持一致,按照1∶1∶2的比例设置,方便与其他研究结果进行对比;其中验证集的作用是在训练过程可以及时发现模型或者参数设置的问题,以便及时调整。训练过程中采用SGD优化器更新网络参数,共训练16轮,设置初始学习率为0.001,根据学习率衰减策略,分别在第12轮和第15轮下降到0.000 1和0.000 01以寻求SGD优化器的最优解。训练初期采用ResNet论文中提出的学习率预热方法,首先采用较小学习率训练,然后逐渐增大至设置的初始学习率继续训练,避免收敛效果不好以及模型不稳定等问题。实验在Ubuntu20.04系统下进行,使用Python3.6开发语言,基于Pytorch1.6深度学习框架设计网络。 为验证所提出的Anchor-free检测方法与FMM模块的有效性,对网络进行消融实验,结果如表2所示。从消融实验结果可知,对算法的几种改进方法都取得了不错的效果,其中基于中心点的Anchor-free检测方法将网络检测精度提升了0.054;设计的FMM特征挖掘模块使网络检测精度提升了0.031。 表2 消融实验结果Table 2 Ablation results 为验证本文算法的先进性,将其与现阶段先进算法进行比较。表3是各种算法在DIOR数据集上的mAP以及FPS对比。可知,所提出的算法可以大幅度提高检测精度,其检测效果优于YOLOv3、RetinaNet、经典Faster R-CNN以及文献[22-24]提出的算法;其检测速度几乎与原算法持平,在800 pixel×800 pixel的图像上检测速度达到12帧/s。 表3 各类算法在DIOR数据集上的检测结果Table 3 Detection results of various algorithms on DIOR 为观察本文算法对数据集中各尺寸目标的检测情况,列出本章算法与其他几种算法在各类目标上的AP值进行对比分析,如表4所示。 表4 各类算法在DIOR数据集上精度对比Table 4 Precision comparison of various algorithms on DIOR 由表4可知,本文算法在各类目标上的检测精度均超越了RetinaNet算法;相比文献[22]的二阶段算法检测结果,大多数目标检测精度处于领先。通过对数据集中的小目标如汽车、船舶、储罐的检测精度观察分析可知,算法在汽车、船舶、储罐上的检测精度相对原RetinaNet算法分别增加了0.192、0.143、0.253,提升明显。如图8为RetinaNet算法与本文算法在DIOR数据集上的检测效果图,可以看出,相对于RetinaNet算法,本文算法不仅提高了召回率,且定位框精度更高。 使用1.3节中提出的深度可分离卷积方法对特征提取网络进行模型压缩,其结果如表5所示。由表5中数据可知,虽然压缩后的模型较压缩前精度损失2.6%,但其检测速度由12帧/s提升到了19帧/s,且在运算量、参数量及模型大小方面都有较大优势,更加适合在移动端部署。 图8 检测结果Fig.8 Comparison of test results 表5 轻量化前后结果对比Table 5 Comparison of results before and after lightweight 针对无人机视角下的小目标难以检测的问题,对RetinaNet网络模型进行了多方面改进。首先为了丰富特征图中的目标信息,提出了多阶段特征融合方法与注意力机制模块,将其串联形成FMM模块,加强网络对感兴趣目标的特征提取能力;其次,引入了基于中心点检测的Anchor-free算法,并通过将质量估计和分类分数联合训练的方法解决了一般Anchor-free中的弊病,不仅提升了检测精度,还加快了模型的推理速度;改进后的算法精度在DIOR数据集上达到69.5%,且改进后算法的检测速度与原算法持平。为了使提出的算法能够满足实时检测的要求,并达到移动端部署的要求,对网络进行了轻量化设计,将网络中的3×3标准卷积替换为深度可分离卷积,在损失少量精度的前提下压缩了模型,提高了检测速度。但轻量化之后的网络精度损失2.6%,后续应当使用更加智能的模型压缩策略,例如结合剪枝与轻量化方法,以求在损失较少精度的前提下压缩模型。1.3 改进RetinaNet的轻量算法设计

2 实验结果与分析
2.1 数据集及评价标准
2.2 训练策略
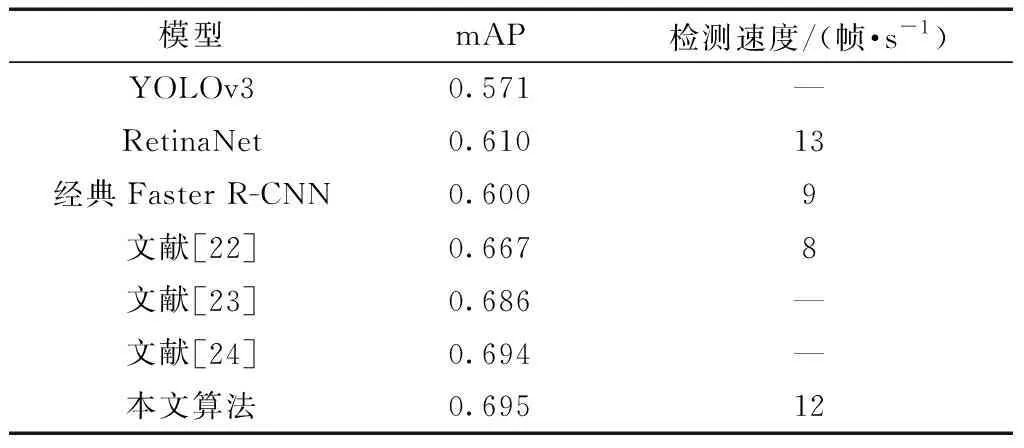
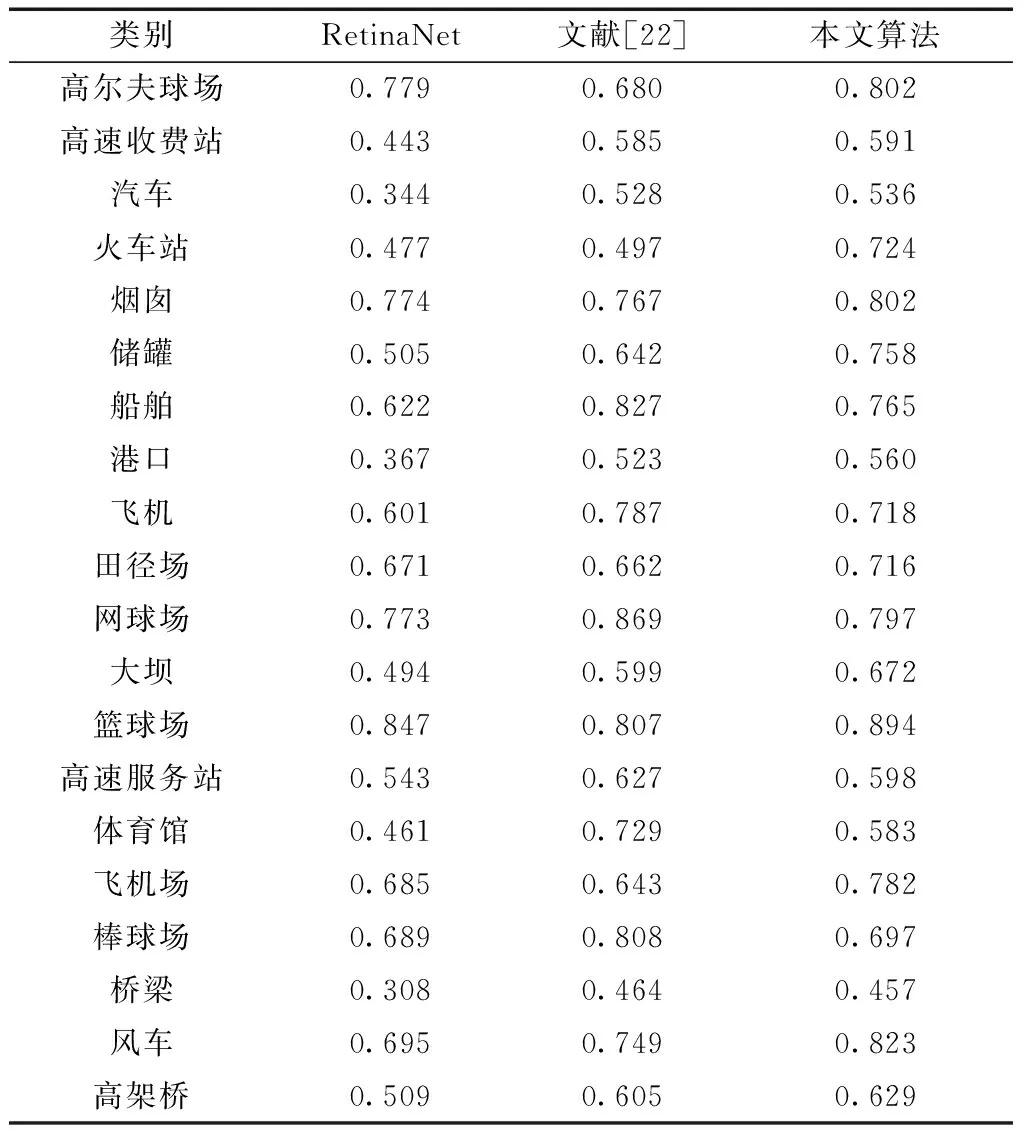
2.3 实验分析

3 结论
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
