
融合属性基加密和信用度的水利数据访问控制模型
2023-02-11 07:04刘秋明许泽峣姚哲鑫谢敏朱松挺
科学技术与工程 2023年1期
刘秋明, 许泽峣, 姚哲鑫, 谢敏, 朱松挺
(1.江西理工大学软件工程学院, 南昌 330013; 2.南昌市虚拟数字工厂与文化传播重点实验室, 南昌 330013;3.江西省防汛信息中心, 南昌 330009)
随着互联网时代和数字社会的到来,全球各地以及各行各业都在积极进行数字化转型,而区块链作为一种新兴的互联网信息技术,在全球各种应用中的普及程度正在激增,为水利行业的数字转型、技术集成和创新应用带来了新的发展机遇和挑战[1]。2020年3月,水利部发布的《水利部关于开展智慧水利先行先试工作的通知》指出[2],加强在不同流域和区域先行开展水利业务与物联网、人工智能、大数据、区块链等技术深度融合,推动全国智慧水利快速健康发展。2021年6月,水利部印发了《关于加快推进智慧水利的指导意见》[3],明确在未来的一段时间将大力推进水利工作的智能化发展。
中国智慧水利信息多采用物联网传感器采集数据,水利数据呈现监测数据多样、数据量大、更新频率快以及跨部门使用频次高等特点[4]。技术发展带来海量数据的同时也暴露出一些明显的行业短板,数据不精确限制数据分析提供的决策,未实现统一、分类、分层管理而导致数据“孤岛”问题,以及水利数据价值认知度低[5]。水利数据的价值最大化是现阶段研究的最终目标,而高效安全的水利数据访问是实现这一目标的基本保障。Qian等[6]借助浙江省水利数字化转型总技术框架,设计了集整合、开发、处理以及服务为一体的水利数据中间平台,实现省、市、县业务协同,打破水利数据物理孤岛,但文献未对设计的数据平台进行模拟实验,仅从功能性角度进行理论上的评估和探讨。陈根发等[7]利用区块链技术的特点,提出解决水利数据交互过程中的信任、管理、交互等难的技术方案,并就区块链结合水资源管理提出建议,但该文献仅从理论角度探讨了区块链在水资源管理中的应用前景,并未结合区块链技术开展实际研究。邹秀清等[8]利用超级账本技术搭建“河长制”水质信息系统,将水质信息直接保存在区块链中,实现信息的防篡改以及溯源功能,系统能够保持良好的运行性能。但该研究未考虑区块链存储能力有限的缺点,若水质数据量超过存储界限,系统性能会急剧下降。从上述有关水利数据的研究中可以发现,水利行业已经开始迈入数据时代,区块链技术已融入水利数据领域,但领域整体的数字信息化水平与先进技术之间还具有一定的距离。
区块链作为近段时间来频频被提及的热门技术,凭借其显著的去中心化、数据共享优势,已在金融、医疗等领域具有良好的应用。虽然区块链存在存储容量有限、数据隐私保护以及数据访问控制等问题,但若能够结合其他技术工具针对性地加以改进,取长补短,区块链具有更广泛的应用场景。张国潮等[9]针对区块链存在的存储问题,提出了一种利用改进Shamir门限秘密共享分片存储模型,将数据分成n片存储于n个不同验证节点,仅利用k个节点即可完成数据复原,节点的数据存储量仅为传统方法的1/(k-1),减少了数据存储量且保证数据的隐私性、安全性。该模型虽然解决了区块链存储能力问题,但对于数据的访问控制方面的研究有所欠缺。葛纪红等[10]提出了一种支持属性加密外包的能源数据访问控制模型,结合外包的属性加密和区块链多链结构,实现能源数据的隔离,且避免数据孤岛问题。该模型虽然采用的属性基加密能够实现更高细粒度的访问控制,但是其将加密文件保存在本地数据库,导致数据交互效率大大降低。同时,在加密文件预解密的过程中会占用更多节点资源。芦效峰等[11]提出属性基加密与区块链结合的访问控制方案,利用分布式存储,解决区块链存储瓶颈。但该方案的密钥分发工作完全由一个授权中心承担,造成授权中心负担过重。王海勇等[12]设计了一种基于区块链和用户信用度的访问控制(role-based access control based on blockchain and user credit, BC-RBAC)模型,以区块链为基础结合用户信用度计算,实现用户角色级别的访问控制,文献根据角色访问不同的权限,提升了访问权限管理的动态性,同时融入信用度评估保障模型运行的安全性。张杰等[13]针对物联网边缘节点与海量异构设备的动态接入问题,设计了一种基于区块链与边缘计算的物联网访问控制模型,结合区块链智能合约,实现了物联网数据的有效访问控制和管理。但该方案仅使用非对称加密算法加密数据,当数据量大时会快速消耗系统资源,加解密效率较低,且不同实体间的密钥管理也会带来挑战。王静宇等[14]提出了一种基于区块链和策略分级的访问控制模型,利用智能合约实现用户访问控制权限的动态分级,提高了访问控制的效率、灵活性和安全性。但该方案未实现细粒度的用户行为评估,用户当前信用度需由一段时间的历史行为累积确认,无法对用户恶意行为实现及时监测和快速响应。
综合现有文献对区块链访问控制的研究,现针对以上研究的不足进行改进和完善,在水利领域应用区块链技术,采用多链架构,提出融合属性基加密和信用度的水利数据访问控制模型,具体的,提出对称加密与属性基加密结合的加密方法。数据对称加密后经星际文件系统(interplanetary file system, IPFS)分布式存储,提升交互效率与避免单点故障问题。利用属性加密策略加密对称密钥,将加密后的密钥存储至区块链,通过管理对称密钥实现数据访问控制,提升数据加解密效率与访问的安全性。提出将用户分层的信用度评估模型。利用用户行为检测值计算用户信用度,区分不同信用值层级用户的操作权限,对用户行为进行细粒度的加权分类,及时阻止恶意操作,实现动态访问权限控制。针对水利数据多部门协同共享的访问需求,提出数据链与访问链结合的多链架构。采用公证人跨链技术,实现不同部门之间的数据隔离、跨部门数据访问控制,对跨链访问请求记录留痕,提升系统安全性和透明性。
1 相关知识
1.1 区块链
区块链由区块构成,后一个区块保存前一个区块的哈希值,构成一条完整的链式结构。区块的本质为一个账本,由区块头和区块体构成,区块头主要存储区块号、区块哈希值、前一个区块哈希值和时间戳等;区块体主要存储交易记录、数字签名等[15]。水利数据在实际应用中具有一定的行业门槛,为合理保护数据的隐私,选择基于超级账本(hyperledger fabric)应用框架的联盟链作为模型基础,该框架具有一定的去中心化特性[16],其通道维护各自的账本,能够保障数据的隔离与隐私。
1.2 IPFS分布式网络
星际文件系统(IPFS)是一种分布式文件系统[17],通过多节点备份原数据,避免出现单机故障问题。IPFS网络将数据保存在256 KB的数据块中,若数据文件大于256 KB,则分割后存储,对同一文件的数据块进行哈希运算,组成数组,再对数组进行二次哈希运算,数组的哈希值作为最终的文件检索信息。哈希值与文件信息对应,若文件遭遇篡改,则运算得到的哈希值与源文件哈希值会出现较大差异,达到防篡改的目的。
1.3 多属性中心加密
属性基加密方法(attribute-based encryption, ABE)首先由Sahai等[18]提出,随后Bethencourt等[19]提出基于密文策略的属性加密方法(ciphertext-policy attribute-based encryption, CP-ABE),该方法将访问策略嵌入密文中,将属性集放入密钥中,只有当访问用户的属性条件满足访问策略时,才能够实现解密。当前属性基加密有隐藏访问结构、多属性权威机构、属性或用户可撤销等方面的研究[20],其中多属性中心加密中用户属性集由不同属性中心管理,且承担各自管理用户的密钥分发工作。各属性中心向授权中心注册获得唯一的标识(Aid),初始化生成自己的公私钥对。用户向各自的属性中心发送属性集,生成属性私钥。由于各属性中心相互独立且负责的属性集不同,即使属性中心合谋也无法破坏破解加密文件。
2 访问控制模型设计
2.1 模型架构
水利数据在实际工作中经常会遇到不同区域、部门的访问需求,要求能够有效地对访问权限进行细分,实现细粒度访问控制;系统的安全控制是另一个关注问题,要求系统能够及时发现参与用户的风险请求,并拒绝风险用户的相关请求。为满足以上要求,提出基于区块链的水利数据访问控制模型,将属性基加密算法和用户信用度评估相结合,实现更加高效、安全的数据访问控制。模型结构如图1所示,主要由数据所有者、数据使访问者、数据链、访问链、IPFS分布式网络、授权中心以及属性中心组组成,其中数据所有者既可以上传数据,也可以进行数据访问。
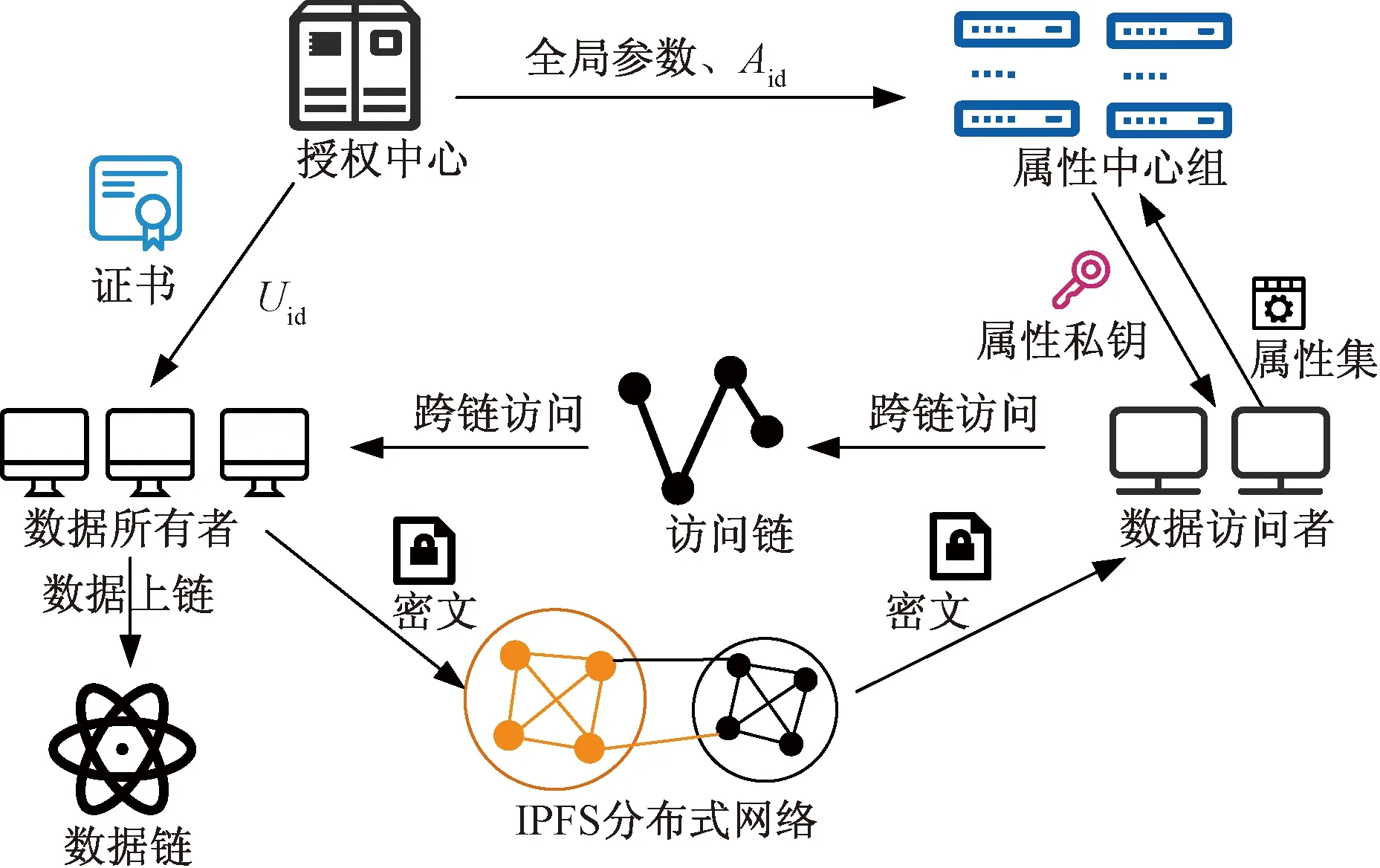
Uid为用户唯一身份标识;Aid为属性中心唯一标识图1 水利数据访问控制模型Fig.1 Water conservancy data access control mode
数据所有者(data owner, DO),代表水利数据的所属部门,是系统中的数据上传者。其在模型中的主要职责为对原数据进行对称加密,设置访问策略,以及相应的属性基加密步骤,并将加密数据上传至IPFS系统。最后将数据哈希值、IPFS地址哈希值以及访问策略上传至数据链。
数据访问者(data user, DU),代表需要访问数据的用户,包括水利部门以及其他职能的政府部门。若访问用户的属性集满足需要访问数据设定的访问策略,且用户信用度也满足要求,则能够进行后续数据访问。
数据链(data blockchain, DB),该区块链负责存储通道内用户的数据哈希值、IPFS哈希值、数据访问策略以及通道内用户访问信息等信息。
访问链(access blockchain, AB),该区块链负责存储跨通道数据访问的信息。由于不同区域的水利数据归属权不同,通道将不同组织的数据隔离,组织间用户进行数据交互时,必须通过中间节点,并在访问链上留痕。
IPFS分布式网络,由于区块链的存储能力受限,模型引入IPFS系统,能够有效减少区块链的存储负担。数据所有者将加密后的数据上传至IPFS系统,IPFS返回数据的地址哈希值。IPFS地址哈希值最终写入数据链,实现链上记录链下存储,由于IPFS的存储原理,可以实现数据的防篡改。
授权中心(certificate authority, CA),基础功能为参与用户颁发可信证书、唯一的Uid以及用户身份密钥。在模型中,授权中还需生成属性加密所需的全局参数以及标记各属性中心的Aid。
属性中心组(attribute authority, AA),由若干个属性中心组成,分别管理下属用户的属性集。每个属性中心有自己的公私钥对,并在属性加密过程中,负责生成用户的属性私钥。
2.2 属性基加密流程
在传统政务系统中,文件的访问控制权往往需要向某个部门申请,水利数据也不例外,因此往往数据的访问效率低下,数据所有部门对文件的控制权很低。而属性基加密可以实现所有权的细粒度划分,并且访问策略由文件所有者设定,访问效率高。
本模型采用多属性中心的属性基加密算法,其基本架构如图2所示。
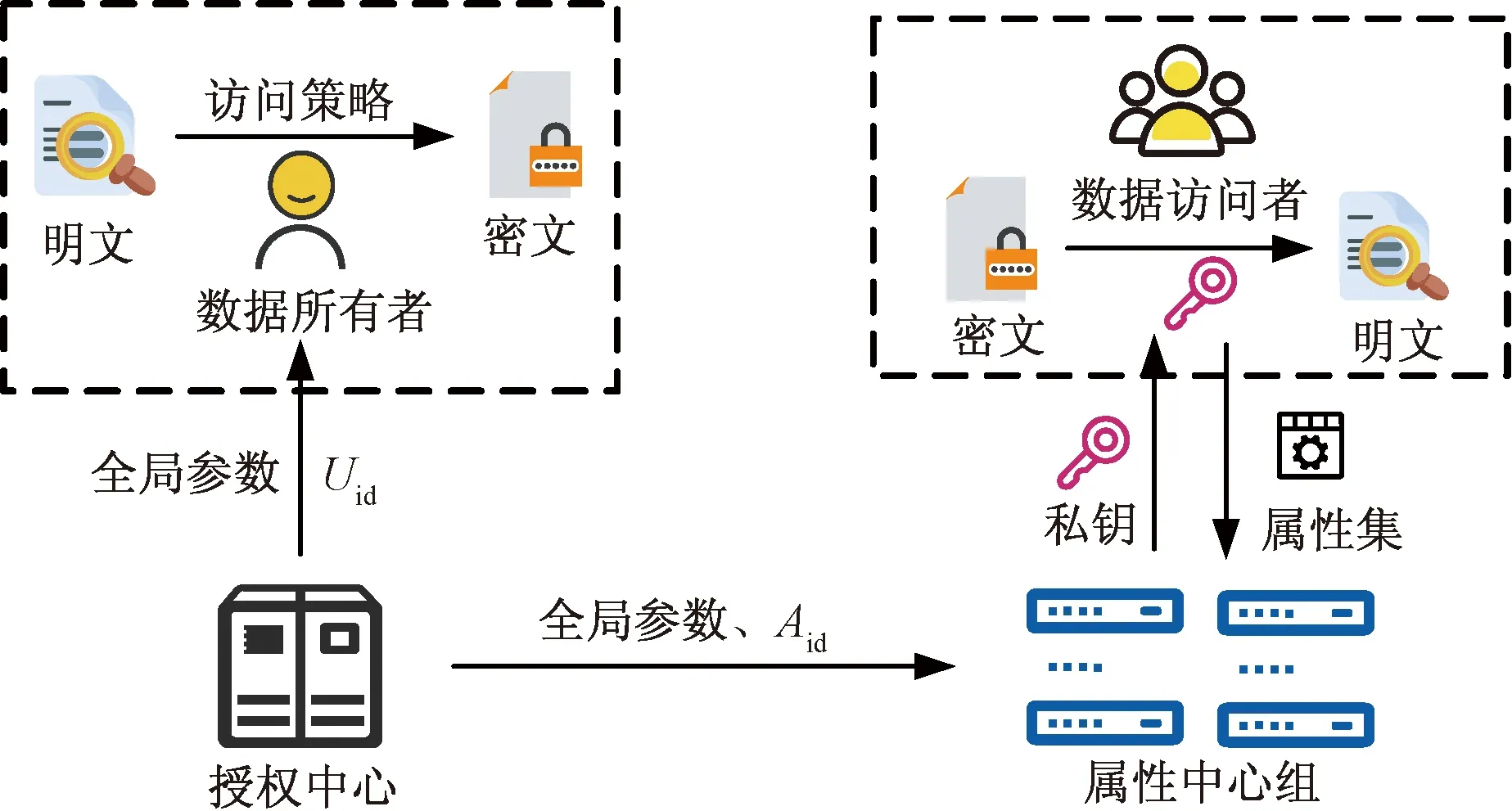
图2 属性基加密架构Fig.2 The structure of attribute encryption
主要由授权中心初始化、属性中心初始化、属性密钥生成、数据加密以及数据解密5个步骤构成,具体加密算法流程如下。
步骤1授权中心初始化(CA_Setup):该步骤在CA执行,输入安全参数c,通过初始化算法(随机化算法)输出系统的全局唯一参数GP,即CA_Setup(1c)→(GP)。
步骤2属性中心初始化(AA_Setup):在属性中心获得全局参数后,输入全局参数GP,运行随机算法,输出属性中心的公私钥对,即AA_Setup(GP)→(APK,ASK)。
步骤3属性密钥生成(Key_Prod):该步骤在各属性中心执行,输入请求用户的Uid,属性集Att,全局参数GP以及当前属性中心的属性私钥ASK,输出用户的私钥,即Key_Prod(Uid,Att,GP,ASK)→sks,uid。
步骤4数据加密(Enc_Data):该步骤由数据所有者执行,输入需要加密的数据文件D,自定义访问策略(A,ρ),全局参数GP以及所属属性中心的公钥APK,输出密文ED,即Enc_Data[D,(A,ρ),GP,APK]→ED。
步骤5数据解密(Dec_Data):该步骤由数据访问用户执行,输入全局参数GP,密文ED以及用户属性私钥sks,uid。若私钥的属性满足密文的访问策略,则访问成功读取到明文D,即Dec_Data(GP,ED,sks,uid)→D。
2.3 信用度评估
用户的风险行为会对系统的稳定造成严重威胁,因此,如果能够检测到用户的风险操作,阻止后续行为,能够避免巨大损失。模型通过对每个参与节点标记信用度来评判其是否属于恶意用户,若评判为恶意用户,则系统应拒绝其相关请求。
2.3.1 信用度计算模型
采用模糊层次分析法(fuzzy analytic hierarchy process, FAHP),将选择对象的行为划分为若干个特征,再把每个特征划分成有参考意义的多个因素,经过一系列数值转换之后,将抽象的用户行为转换为明确的数值加权问题。
为了避免给系统产生额外的压力,选取方便检测、具有代表性的行为因素,再利用FAHP进行数值转换。以图3为例,将用户行为分为3种特征:安全特征S、服务特征P以及可靠特征R。每种行为特征再划分成若干种行为因素,安全特征由尝试越权访问次数(负面)s1以及文件数据错误(负面)s2组成,服务特征由水利文件上传数p1、区块贡献数p2以及所属文件受访问次数p3组成,可靠特性由资源占用率r1、访问成功数r2以及上传无效文件数(负面)r3组成。

图3 行为特征分类Fig.3 Classification of behavior characteristics
步骤1以行为因素作为参照,建立特征矩阵T=[tij]n×m,其中n为特征个数,m为因素划分最大个数,不足m列的行以零值填充。选取n=3,m=3。此时的数据为原始数据,离散且不确定。若直接作为参数计算无法得出准确结果。因此,通过式(1)对数据需规范化处理,将离散值转换成值域在[0,1],且单调递增的无量纲值。
f(x)=(ex-e-x)/(ex+e-x)
(1)
步骤2特征矩阵T转化为规范化特征矩阵E=[eij]n×m后,构造初始判断矩阵EQ。以服务特征P为例,将其行为因素进行两两比较得到初始判断矩阵EQ=[eqij]v×v,其中v为在服务特征下的因素个数,取v=3,因素之间的比较规则为
(2)
步骤3将判断矩阵转换成模糊判断一致矩阵。由于研究问题的复杂性以及数据收集者认识上的偏差,导致构造的判断矩阵EQ不具有一致性,因此使用式(3)进一步将判断矩阵转换成模糊一致性矩阵Q=[qij]v×v,其中:
(3)
步骤4使用式(4)计算各行为因素的权重值,组成所属特征的行为因素权重向量W=[w1,w2,…,wv]T,其中:
(4)
按照式(1)~式(4)计算得到安全特征S的行为因素权重向量WS=[ws1,ws2]T,服务特征P的行为因素权重向量WP=[wp1,wp2,wp3]T,可靠特征R的行为因素权重向量WR=[wr1,wr2,wr3]T,3个合成因素权重矩阵Wd=[WS,WP,WR]n×m=[wij]n×m,其中n为特征个数,m为因素划分最大个数,不足m列的行以零值填充。
步骤5由规范化特征矩阵E与因素权重矩阵Wd根据式(5)计算得到当前信用度。由于选取的行为因素包含
(5)
正面因素与负面因素,则在总信用度中应减去负面因素,如在本文中,用户发生行为s1时信用度会相应减小。其中,wfi∈Wf=[wf1,wf2,…,wfn]T,Wf为行为特征的权重向量,n为特征划分个数。
步骤6用户刚进入系统时,行为因素值无法检测,故用户当前的用户度为0,采用式(6)来计算用户综合信用度,即
Final_Value=1+Credit_Value
(6)
通过式(6)实现信用度的归一化,可以得到用户刚加入系统时默认信用度为1。
2.3.2 信用数组
用户登入系统后,会自动计算用户的信用度,并将其发布至区块链交易池,由区块链系统中的排序节点(矿工)负责将信用度打包成信用数组,生成数据区块,结构如图4所示。区块链中交易单以Merkle树结构存储,交易单中包括文件数据信息,以及信用数组。信用数组设计为Map数据格式,用户Uid作为键(Key)。
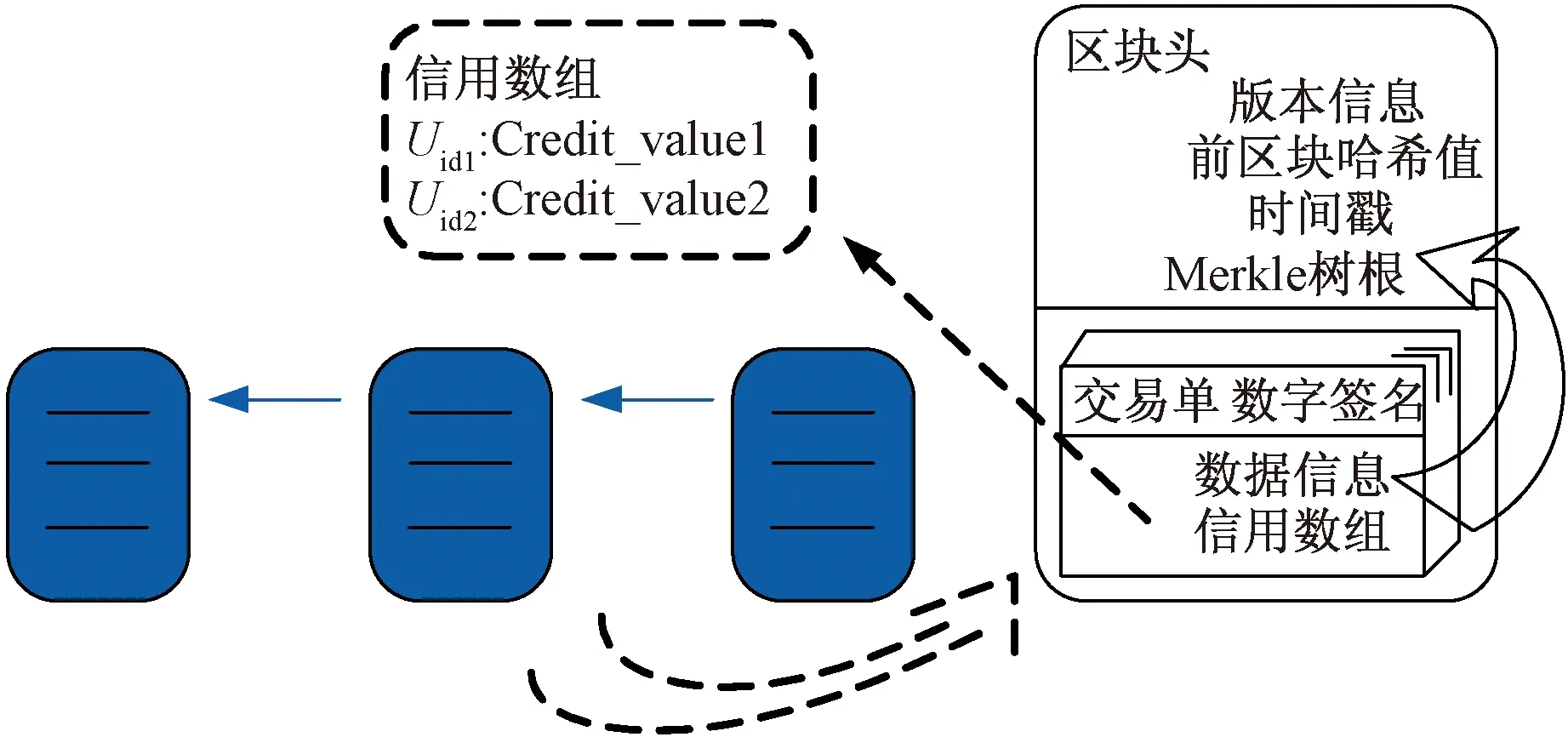
图4 区块数据结构Fig.4 Data structure of block
系统运行过程中会不断有用户加入与离开,为提高存储空间利用效率,设定每隔30个区块,通道清除当前所有用户的行为因素累计监测值,调用智能合约重新计算用户信用度。矿工在交易池进行信用度打包时,根据前一个区块的信用数组,删除已经离开的用户,组成新的信用数组。
2.3.3 信用度分级
为防范用户误操作而导致信用度下降,系统应具有一定的容错能力。模型将用户分为3个层级:恶意用户,信用度小于δ;风险用户,信用度在δ~1;安全用户,信用度大于1。其中δ的取值范围在0~1。
根据2.3.1节的信用度评估模型,选择1作为信用度分界岭。若安全用户正常操作过程中,偶然产生负面行为,信用度会降低,但高于1,不会对其他权限产生影响。若用户产生负面操作达到一定次数,导致信用度低于1,但大于δ,系统会限制该用户的上链权限,并且权威中心将其列入风险列表。风险用户仍可进行查链操作,且可向权威中心提交身份安全申请,审核通过后可移出风险列表。若用户持续进行负面操作,使得信用度低于δ,系统会禁止该用户的所有权限,权威中心将其列入恶意列表,且无法移除。
2.3.4 信用模型应用方案
信用度评估模型保障系统运行的安全,监测用户的操作行为,分析了在用户在数据操作过程中,信用度模型的具体应用。
(1)水利数据用户初入系统时,无法评估其行为因素值,故由2.3.1节评估模型计算得到用户信用度值为1,评判为安全用户。系统运行过程中,用户信用度随着与系统的交互产生变化,用户信用度值与数据信息一起发布至交易池,并最终由区块链矿工负责打包上链。
(2)数据用户上传水利数据时,在本地预处理之后,将上链数据发布至交易池。矿工打包数据时,先查询最新区块的信用数组,若数据发布者信用度低于1,则不打包该数据。数据成功上链以及发布新区块发布均属于积极行为因素,相关用户的信用度会增长。信用评估模型限制风险用户以及恶意用户的上链行为,保证水利数据的正确性,而随着风险用户其他积极行为因素的增长,又可恢复上链权限,起到动态控制系统安全的目的。
(3)数据用户查询水利数据时,向属性中心组申请属性私钥,即水利部门属性管理节点查询数据用户所在通道最新区块的信用数组,若数据用户信用度至不低于设定值δ,则分发属性私钥,否则,拒绝用户申请。数据用户需访问其他区域水利数据或跨部门访问水利数据时,即需要跨通道访问数据,此时监管组织节点审核用户信用度,过程同上。信用模型仅允许安全用户与风险用户访问数据,且在访问过程中,越权访问、访问数据无效等为负面行为因素,相应用户信用度值减小;有效数据成功访问次数增加,数据发布者信用度值也会增长。
2.4 多链模型
水利数据的访问对象可以分为两类:同一部门的其他用户和其他部门的用户,后者又可以分为水利领域不同专业的部门、不同区域的水利部门以及其他领域的部门。而Fabric联盟链中的通道结构能够有效地进行数据隔离,每个通道维护自己的区块链结构,用户不能直接访问其他通道的区块链数据。在本模型中将各地方水利部门视作不同通道内的组织,各组织选择节点维护自己通道内的数据链,而将上级水利部门以及其他监管部门组成监管组织,存在于各通道的交叉通道中,负责维护交叉通道的访问链。
跨通道访问的主要技术为跨链访问技术,当前主流的跨链技术有公证人机制、侧链/中继和哈希锁定3种[21]。利用公证人机制,选出权威个人或者群体充当公证人角色,被选举的公证人担有监听、查看、验证等职能[22]。选取监管组织(即上级水利部门以及其他监管部门)充当跨链过程中公证人角色的访问流程如图5所示。当组织O1中有用户想要请求数据链L2上的数据时,联络节点负责收集访问请求,将访问请求提交给交叉通道中的监管组织O3。监管节点审核访问请求发起用户的权限资格,审核通过后,向组织O2的联络节点申请数据请求。联络节点调用数据查询智能合约,将目标数据返回给监管节点,监管节点成功获得数据后,返回给组织O1联络节点,再返回给发起用户,完成此次跨链访问。访问过程中,监管组织更新维护访问链L3,将用户的访问信息记录至访问链。
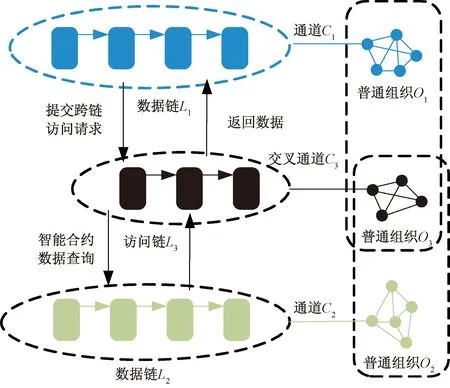
图5 跨链访问模型Fig.5 Model of cross-blockchain access
3 水利数据访问控制流程
3.1 数据存储
水利数据存储过程的主要参与者包含:数据所有者 DO、属性中心组AA、数据链DB和IPFS分布式网络,存储流程如图6所示。
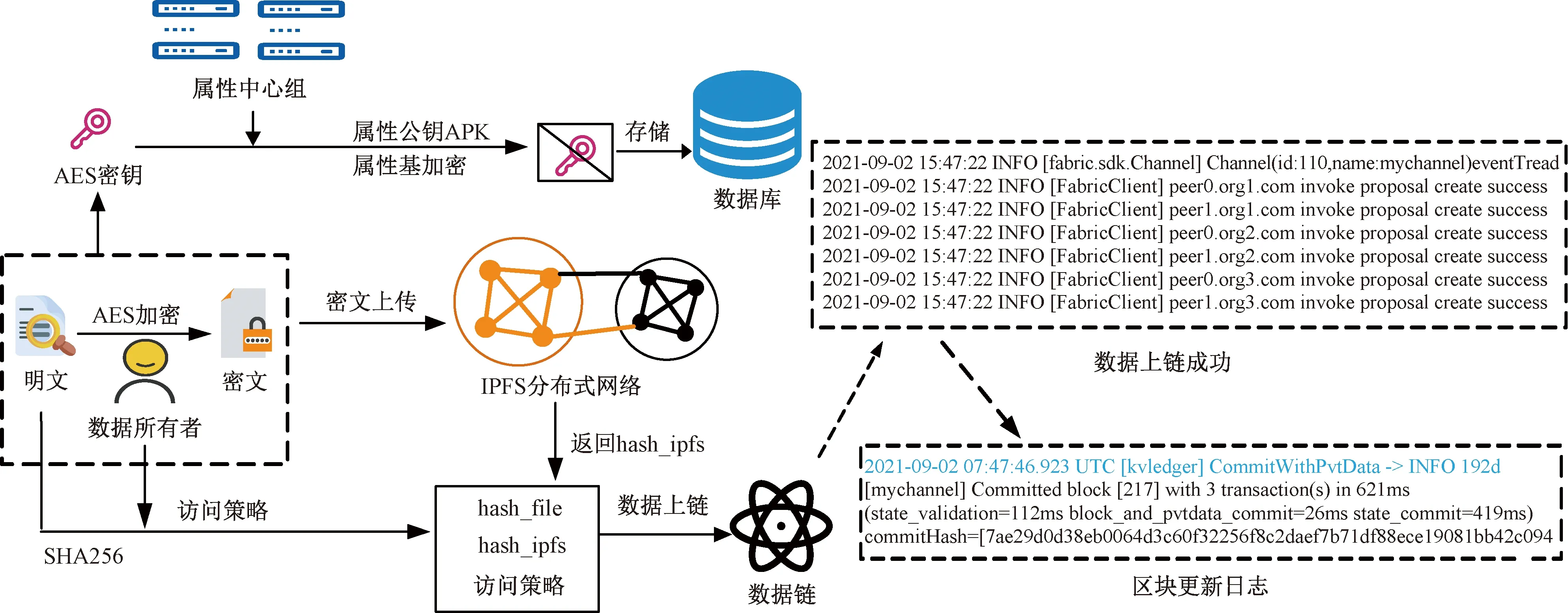
图6 数据存储流程Fig.6 The process of data storage
数据所有者选择文件file,用AES算法进行对称加密,得到密文enc_file,同时利用SHA256算法取文件的哈希值hash_file。对称加密完成后,利用IPFS算法将加密文件上传至IPFS分布式系统,系统返回文件地址的哈希值hash_ipfs。数据所有者将文件哈希值hash_file、IPFS地址哈希值hash_ipfs以及设置的文件访问策略(A,ρ)打包,发布至区块链交易池,等待写入数据链。模型采用链下文件存储链上存储地址信息方式,能够高效地利用区块链存储容量。文件加密后,再对AES密钥进行属性基加密。数据所有者利用属性基加密算法,以全局参数GP、访问策略P、以及对应属性中心公钥APK作为输入,得到加密后的AES密钥,并保存至系统数据库。
在文件存储过程中,用户的信用度会发生变化,根据信用度的分层机制,风险用户以及恶意用户无法进行上链操作与上传加密密钥的权限。若风险用户需要恢复完整权限,可以向权威中心提交身份证明,审核通过后,恢复权限;而恶意用户被列入恶意列表,限制其所有权限,防止产生更多负面行为。
3.2 数据访问
在水利数据的访问阶段,参与对象有:数据使用者DU、授权中心CA、属性中心组AA、IPFS分布式网络、数据链DB以及访问链AB,数据访问流程如图7所示。

图7 数据访问流程Fig.7 The process of data access
数据访问过程分为相同通道访问与跨通道访问,且访问过程中由授权中心与属性中心共同承担审核访问用户信用度的职责。
在相同通道数据请求情况下,数据用户发起访问请求,通道调用智能合约,返回文件的hash_file以及hash_ipfs信息,并将用户访问信息打包,进行上链。数据访问用户向属性中心发送自己的属性集与用户ID,属性中心查询用户所在数据链最近区块的信用数组,若信用度满足条件,则属性中心返回用户的属性私钥sk;否则,拒绝用户请求。若数据用户的信用度符合要求,则访问控制系统查询文件的加密后的AES密钥,同时,用户通过IPFS检索算法,利用hash_ipfs值获得文件密文。同时,数据用户利用属性私钥sk以及全局参数进行属性基解密,若用户属性集满足数据所有者设定的访问策略,则成功解密获得AES密钥;否则,解密失败。最后,利用AES密钥对密文进行机密,获得文件明文。数据用户可对明文进行SHA256运算,获得值与hash_file值进行比较,若两值相同,则访问成功。
在跨通道数据请求情况下,模型采用公证人跨链技术,默认将上级水利部门选为公证人,构成授权中心。数据用户发起授权中心发起访问请求,授权中心查询相应数据链最新区块的信用数组,若用户信用度符合要求则授权中心向目标通道发起访问请求,目标通道调用查询智能合约返回文件信息hash_file以及hash_ipfs。授权中心将文件信息发送给访问用户,并将访问信息打包,等待记录到访问链。若用户信用度不满足要求,或者其他原因造成的访问失败,用户访问信息也会被记录到访问链中。用户获得文件信息,模型后续流程与上文一致。
在数据访问过程中,用户的信用度会产生变化,信用度分层机制规定,对于风险用户不进行数据访问类权限限制,防止正常用户误操作导致信用度下降,但限制其写入权限;而恶意用户限制所有权限,无法访问数据。
4 实验与分析
为验证基于区块链的水利数据访问控制模型的可行性,利用HyperLedger Fabric1.4开源框架搭建区块链平台,测试不同节点个数情况下区块链的读写性能情况,比较在不同加密方案下文件的加密与解密时间,并模拟信用度评估模型的流程。
实验配置电脑搭载Window10操作系统、Intel Core i5处理器、8 GB内存、DDR4,利用Centos7虚拟机为区块链提供运行环境,用Docker容器模拟不同数量的节点情况。
模型首先与相关访问控制方案进行功能性比较。如表1所示,评估数据不同操作阶段的功能。数据上链前,本文方案用户将数据AES加密后上传至IPFS,利用属性访问策略加密AES密钥,而文献[10]以SM4算法加密数据,且将密文保存在本地数据库,相较于IPFS的分布式存储,单节点存储方式的安全性和稳定性更差。数据上链阶段,本文方案设计有信用度评估模型,起到监控用户行为,限制风险用户以及恶意用户的上链请求,保障系统数据安全,而文献[10-11]均未对用户行为进行评估,系统安全性漏洞较大。数据查链阶段,本文方案设计多链架构,采用公证人技术实现跨链访问控制,较文献[10]采用中继技术方式更为简洁,且由信用度评估模型动态控制数据访问,限制恶意用户访问权限。此外,本文方案采用多属性中心,避免文献[11]存在单个属性中心计算负载过重问题,减轻属性解密的计算开销。
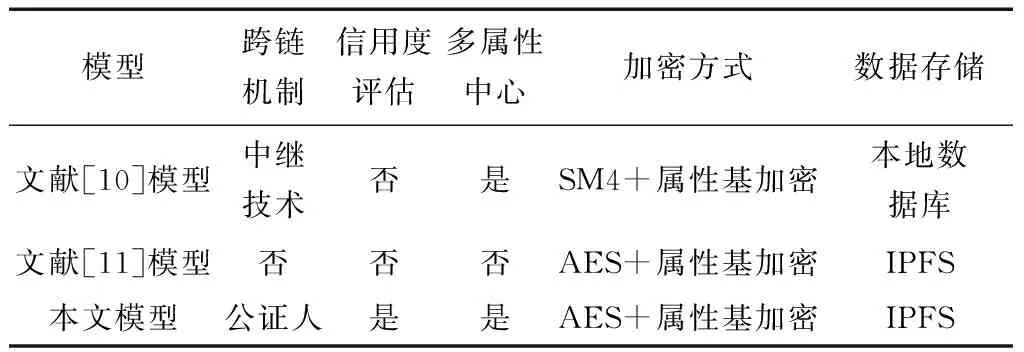
表1 方案功能性比较Table 1 Functional comparison of different model
4.1 区块链网络性能分析
区块链网络测试环境运行在单个主机上,利用Java语言开发区块链客户端,利用Go语言编写智能合约,分别模拟在两个组织分别含单个节点、2个组织分别含2个节点以及3个组织分别含2个节点情况下数据链以及访问链的上链与查链时延,每个组织均有一个成员服务提供者(member service provider, MSP)列表,排序方法采用单节点通信(SOLO)模式,实验结果如图8、图9所示。
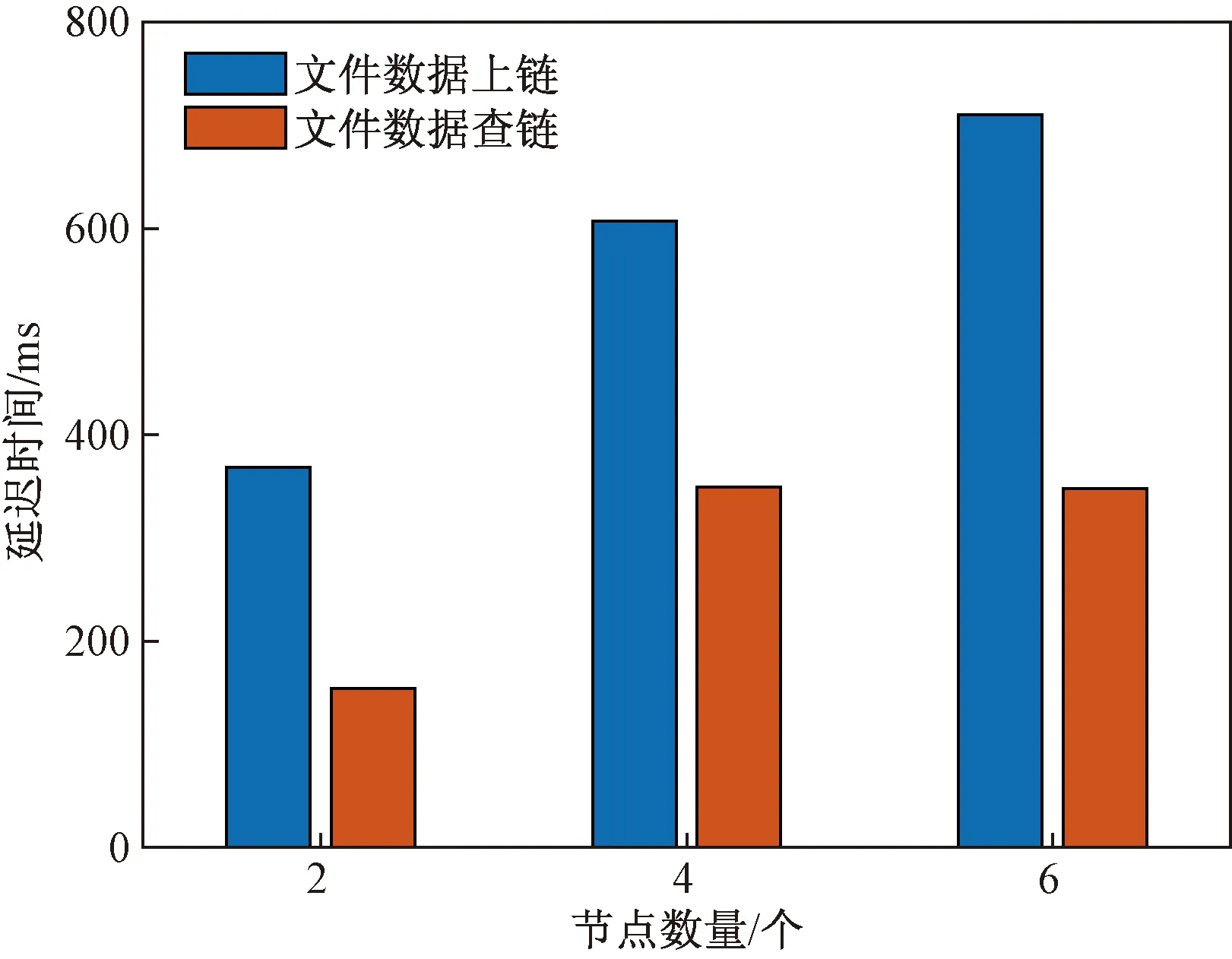
图8 数据链操作时延Fig.8 Delay of operation on data blockchain
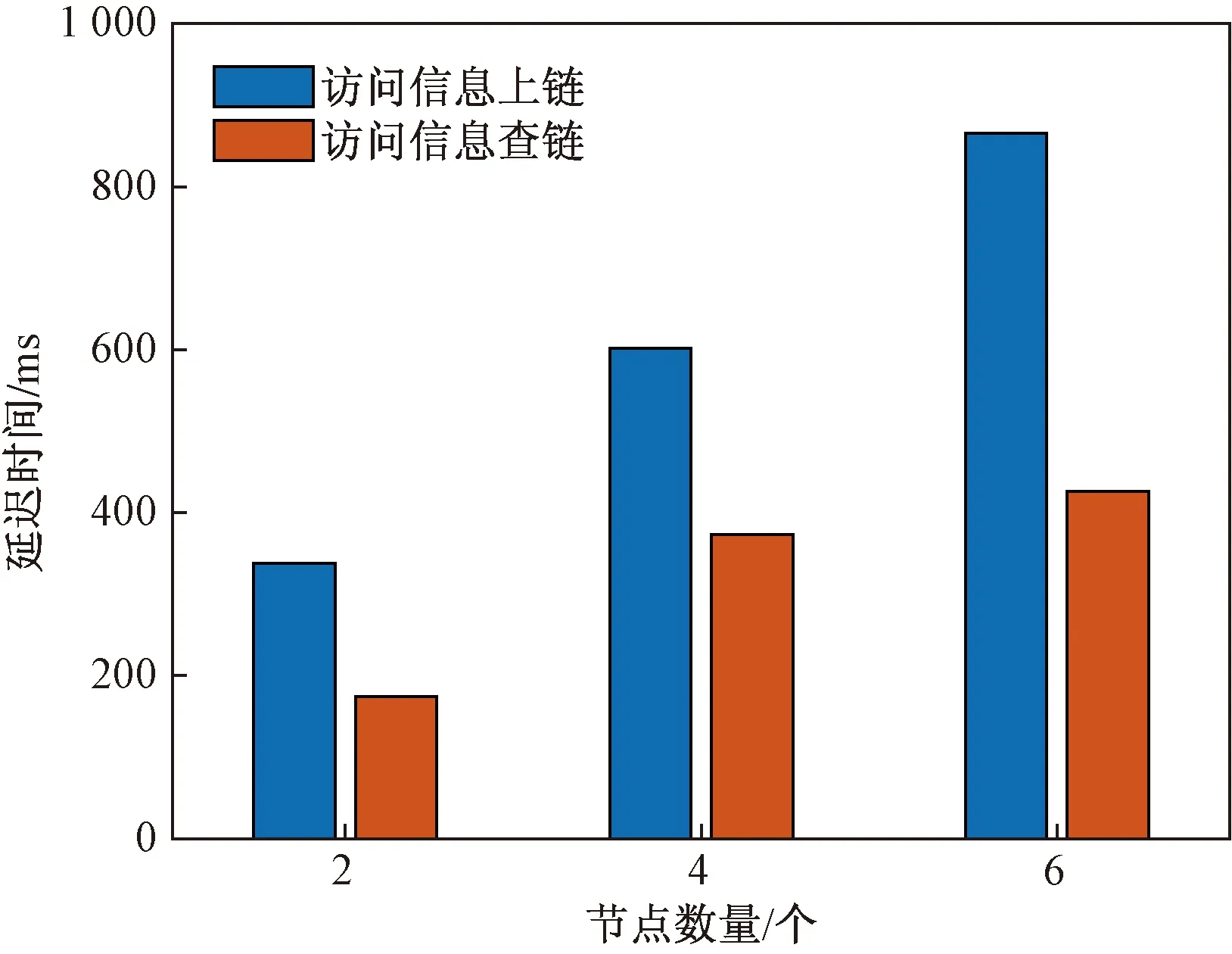
图9 访问链操作时延Fig.9 Delay of operation on access blockchain
从实验结果可知,两种区块链的上链时间随着节点数以及组织数的增加也近乎成倍的增长,而查链时间增长速度稍缓并区域稳定。数据上链时,区块链的交易单在可信节点的背书后才允许上链,而智能合约默认情况下将交易单发送给尽可能多的节点进行背书验证,因而随着节点数量增大,验证造成的延迟也会越大。此外,排序结点打包区块后发送给各个组织形成共识也会随着规模的增加,产生延迟。而进行查链时,节点维护账本的内容都是相同的,故只需向某个节点发起请求即可,故查链的延迟时间受节点规模增长的影响很小。
4.2 属性基加密性能分析
通过分析属性基加密过程,可知文件的大小以及属性的数量是加密效率的最大影响因素,实验分别测试在不同文件大小以及不同属性个数情况下属性基加密以及解密的时间。
对于文件大小的影响,实验对比仅属性基加密情况下的加/解密时间,文献[10]方案的加/解密时间以及本方案的加/解密时间,实验结果如图10所示,其中纵坐标为加密与解密时间之和。从结果可知,文件体积较小时,3种方案的加/解密时间之和相差不大,而文件大小一旦超过一定值,3种方案逐渐展开差距。实验中,直接采用属性基加密和解密文件的方法,当文件超过10 MB时,由于文件体积过大,算法效率变差。而本文方案与文献[10]方案均采用先对文件进行对称加密,然后再对对称密钥进行属性基加密,因此,加/解密时间受文件大小影响较小。文献[10]采用SM4对称加密算法,该算法加密时间随文件大小增长以较缓的速度增长,而本文方案采用的AES对称加密算法几乎不受文件大小的影响,故较另两种方案,本文方案的加/解密效率更高。
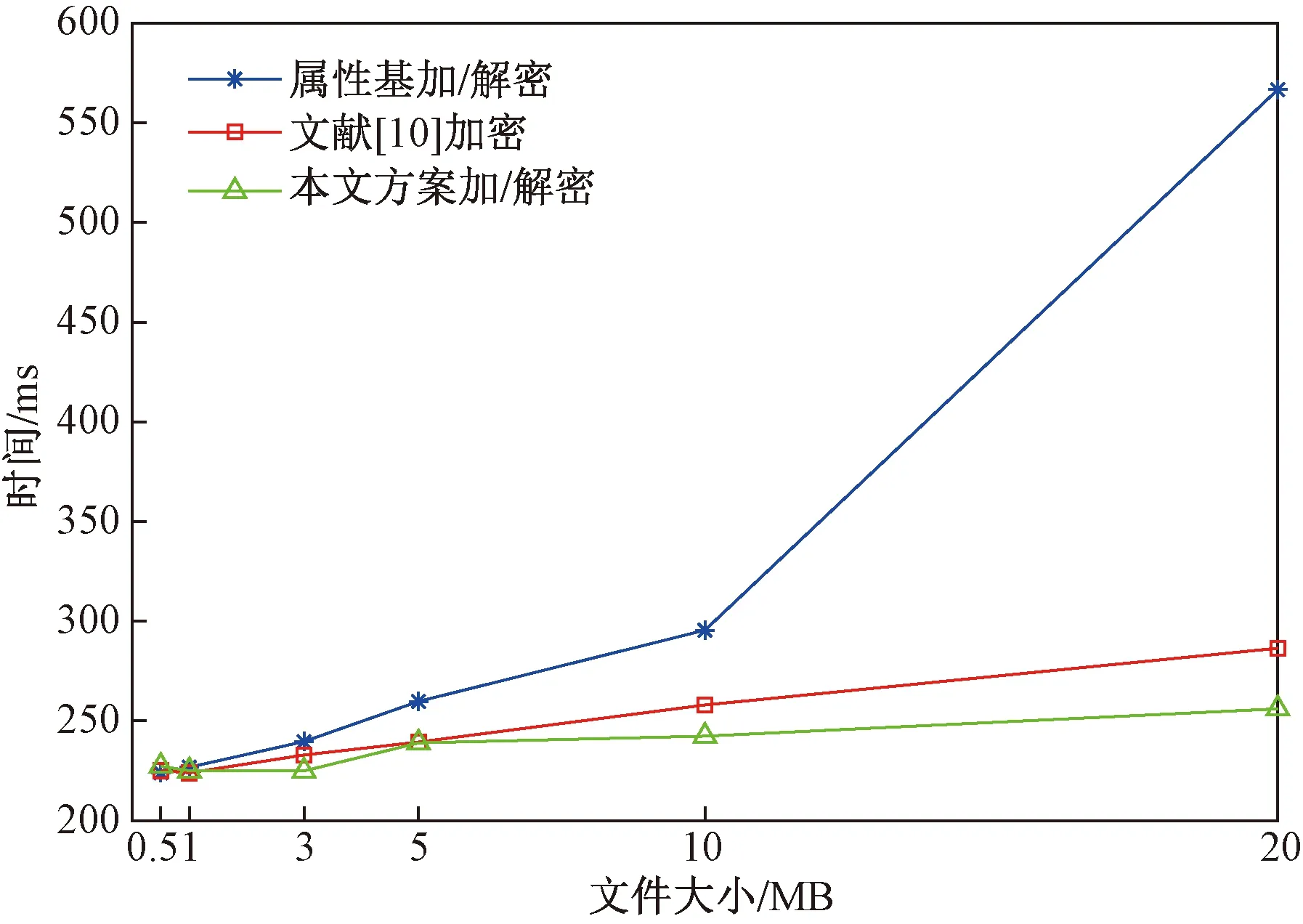
图10 不同文件大小加/解密时间比较Fig.10 Encryption time and decryption time comparison with different file size
实验设置不同属性个数情况下,固定文件大小为2 MB,本文方案与文献[10]以及文献[11]方案加密与解密时间的对比,实验结果如图11所示。实验结果表明,3种方案的加/解密时间均逐步增加,且本文方案的加密与解密效率最优。实验中,设置的属性个数越多,目标数据的访问策略结构就越复杂,虽提高了数据的访问细粒度的,但增加了加/解密时消耗的时间,而本文方案先采用AES对称加密,再利用多中心的属性加密技术,在3种方案中效率最高。
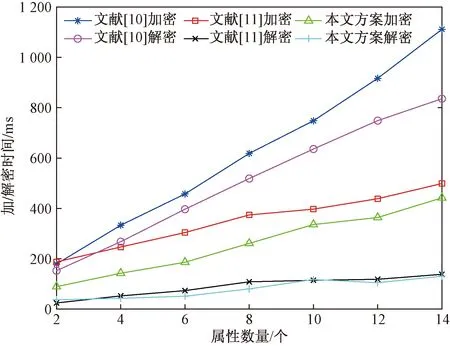
图11 不同属性数量加/解密时间比较Fig.11 Encryption time and decryption time comparison with different attribute number
4.3 信用度模型评估
以2.3.1节的信用度模型的划分方法,检测用户的行为因素值,通过程序进行规范化及后续操作,计算出安全特征、服务特征以及可靠特征的数值。根据水利系统的实际应用情况对行为特征以及行为因素权重进行重要程度划分:行为特征权重S>R>P,安全特征S行为因素权重s1>s2,服务特征P行为因素权重p1>p2>p3,可靠特征R行为因素权重r3>r1>r2。实验模拟节点在产生不同负面行为下,用户信用度值得变化情况,结果如图12所示。正常运行情况下,用户的信用度随着正面行为慢慢增长,而在运行时间至100 s时,实验分别模拟产生3种负面行为的情况,用户的信用度立即下降。运行至120 s时,停止负面行为,此时随着正常行为比重的上升,用户信用度开始回升。
模型按照信用度不同,将用户分为3类,模拟实验取信用度阈值δ=0.8,当用户信用度低于0.8时被列为恶意用户,结果如图13所示。运行至100 s时,系统检测到用户2与用户3的负面行为,调整信用度,用户2信用度降至1~δ,判定为风险用户,而用户3降至δ以下,判定为恶意用户。正常用户1与风险用户2在运行30个区块后即200 s左右时信用度更新为1,由于风险用户被列入风险列表,仅有查链权限,信用度增长较慢。
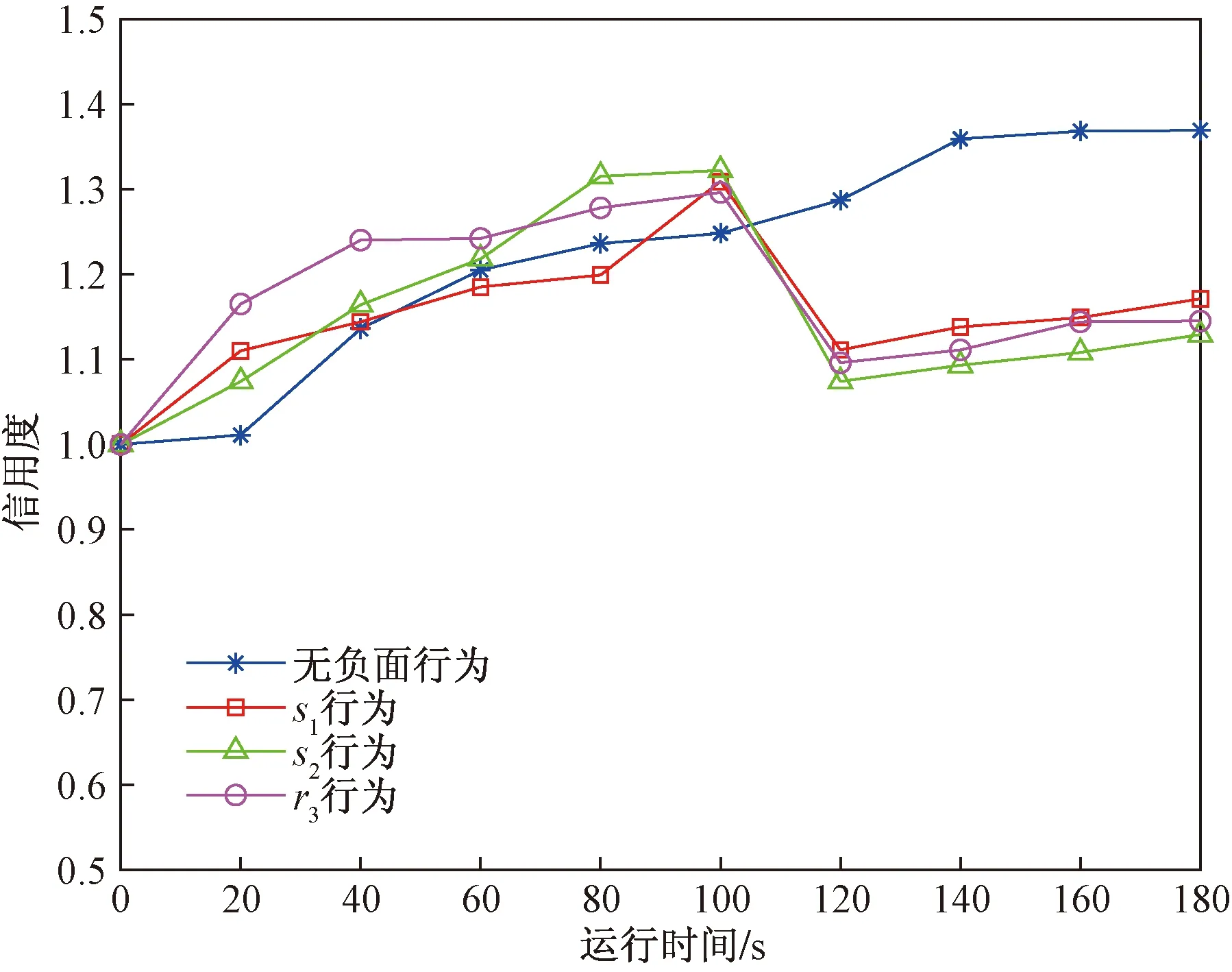
图12 不同负面行为下信用度比较Fig.12 The comparison of credit value under different negative actions

图13 三类用户信用度比较Fig.13 The comparison of credit value among three users
4.4 模型运行评估
本文模型以数据链与访问链组合的多链架构为基础,将文件对称加密之后,上传至IPFS系统,且利用属性加密技术加密对称密钥。系统将IPFS的哈希地址、文件摘要以及属性加密策略上传至数据链,数据上链日志如图14所示。

图14 数据上链日志Fig.14 The log of data upload to blockchain
用户发起跨链请求时,触发访问链智能合约。访问链合约审核用户权限后跨通道调用数据链合约完成查询操作,将查询结果返回给用户,再将用户跨链操作过程记录到访问链中作为操作留痕,访问链智能合约调用如图15所示。

图15 访问链智能合约调用Fig.15 Access chain smart contract invocation
系统运行过程中,用户信用度按照信用度评估模型变化,不同负面行为下变化情况如图12所示,且每隔30个区块重置信用度值,更新情况如图13所示,用户一旦评估为恶意用户,系统将限制其所有权限。用户进行数据访问时,满足数据所有者的属性访问策略,才可属性解密文件,其中加密属性个数设置越多即访问策略越复杂,加/解密消耗时间越多,时间消耗情况如图11所示。在文件访问过程中,模拟系统的区块链网络运行情况如图7所示,系统运行良好。
5 结论
在日益重视数据的高效访问以及价值最大化的背景下,数据的安全访问控制对于行业的发展具有重要作用,而水利领域正在经历智能化大变革,实现高效安全的数据访问十分迫切。根据水利数据的访问特点,提出基于区块多链的访问模型,利用区块链通道的特性有效的分隔数据,以属性基加密技术实现数据的细粒度访问控制,并利用信用度模型评估用户的安全性,提高数据访问的高效性和可靠性。实验结果表明,该模型能够根据用户行为动态更新用户信用度,并能够根据信用度阈值对用户进行分层。同时,对称加密技术与属性基加密技术结合的方法能够实现数据的隐私保护以及属性级访问控制。
猜你喜欢
湖南理工学院学报(自然科学版)(2022年1期)2022-03-16
水利建设与管理(2020年6期)2020-07-08
水利建设与管理(2020年6期)2020-07-08
河南水利年鉴(2020年0期)2020-06-09
河南水利年鉴(2020年0期)2020-06-09
太原科技大学学报(2019年3期)2019-08-05
课堂内外(小学版)(2017年5期)2017-06-07
中国公共安全(2017年11期)2017-02-06
通信学报(2016年11期)2016-08-16
现代工业经济和信息化(2016年19期)2016-05-17
