
面向6G通感算融合的网络智能感知
2023-02-09 12:00刘玉鹏王佳妮赵力强
无线电通信技术 2023年1期
刘玉鹏,王佳妮,赵力强
(西安电子科技大学 通信工程学院,陕西 西安 710071)
0 引言
无人驾驶、无人机应急通信、沉浸式扩展现实、工业互联网等新兴智能服务依托环境多维信息感知和超强算力,对传输速率、端到端时延、可靠性和功耗等都提出了极高的要求。为提高6G的网络内生智能感知和算力自适应能力,迫切需要研究通信、感知、计算(通感算)融合理论和关键技术。而智能感知技术作为通感算融合的基石,亟需设计一种面向6G通感算的网络智能感知方案。
如今,数字化技术正在不断地整合到垂直行业,预计将出现大量的新兴服务和应用。随之而来的问题是网络规模增大、网络流量变化剧烈,对网络本身的负载量构成了严峻的挑战。此外,新兴业务类型具有差异化服务需求,这给网络资源管理带来了新的挑战。因此,需通过网络智能感知预测网络流量与估计业务类型,找到流量未来的走势,识别用户的业务类型,实现网络资源的智能、按需分配,从而提高网络中各种资源的利用率,降低传输时延。随着人工智能(Artificial Intelligence,AI)技术[1]的快速发展,AI算法具有易于实现、更偏向于处理复杂问题等优点。此外,对于复杂多变的网络环境,以数据为驱动的AI算法相比于以模型为驱动的传统算法,不需要复杂的建模过程,拥有自学习、自演进能力,具有更好的适应性和求解复杂问题的能力。因此,可以使用一些AI算法替代传统算法对网络进行智能感知。
目前,国内外研究者在通感算融合方面已有较多有益成果。文献[2]对面向6G通感算融合的应用需求,链路级和系统级的关键技术、原理、方法和性能以及技术挑战与未来发展方向进行了概述。未来移动通信论坛对通感算一体化融合的IT趋势、关键技术以及应用场景进行了介绍[3]。文献[4-5]给出了内生智能网络架构图,并对架构图进行了简要介绍。在使用流量预测对网络进行感知方面,Barabas等人[6]的实验结果证明,基于神经网络的流量预测准确率远高于传统的线性方法预测,Ramakrishnan等人[7]使用循环神经网络(Recurrent Neural Network,RNN)、长短期记忆(Long Short-term Memory,LSTM)网络和门控循环单元(Gate Recurrent Unit,GRU)模型来预测流量信息,证明了GRU模型比RNN和LSTM的预测效果更好。Gao等人[8]提出了一种基于注意力机制的卷积递归神经网络方法来捕获流内相关性和流间相关性,预测效果提升明显。文献[9]使用LSTM与序列到序列(Sequence to Sequence,Seq2Seq)模型相结合的算法实现了对未来基站的下行物理资源块平均利用率及空口总业务流的预测。文献[10]提出一种基于深度学习的端到端神经网络用于蜂窝网的流量预测,使用具有注意力机制的Seq2Seq算法用于构建时间序列预测模型。而使用网络业务类型估计方法进行网络感知方面,文献[11]使用RNN以及卷积神经网络(Convolutional Neural Networks,CNN)和RNN结合的方式对服务类型识别,并对两种方法进行了性能比较,Moreira等人[12]采用CNN学习数据包原始数据,从而对流量进行分类。但是上述的网络智能感知方法均采用公开的数据集用来分析或者先采集真实的网络数据再进行验证,并未与真实的网络环境相结合进行实时网络状态感知。
针对上述面临的复杂无线接入网智能感知问题,本文设计了一种网络智能感知方案,并在6G通感算智能内生融合智能实验平台上验证了此方案可行性。首先采用具有注意力机制的Seq2Seq算法预测用户及基站的流量,提前感知网络流量波动趋势;其次使用CNN算法对用户的业务类型进行识别;最后搭建了通感算智能内生融合系统实验平台,并在此基础上实现不同感知时间粒度下的流量预测与业务类型估计。通过对比在不同参数设置下的流量预测模型的预测误差与业务类型估计模型的准确率,验证了本文所采用的流量预测模型预测误差较小、业务类型估计模型准确率较高。该网络智能感知方案及实验平台的实现,对资源分配及通感算智能融合等研究具有一定的参考价值。
1 网络智能感知方案设计
网络智能感知是指网络自身主动获取网络中的状态数据,并通过AI技术分析网络中的状态信息。感知指标的选择对网络掌握自身状况具有重要的作用,本文选用蜂窝网中应用层的流量以及业务类型两个网络感知指标进行感知,其中流量预测选用Seq2Seq算法,业务类型估计选用CNN算法。
网络智能感知阶段图如图1所示,主要包括原始数据的采集、数据预处理、模型训练以及模型的在线推理4个阶段。首先,使用网络监控工具实时捕获蜂窝网中的原始流量信息;其次,将原始数据分别预处理为流量预测模型和业务类型估计模型可以直接读取的数据;然后,将预处理后的流量数据分别输入到流量预测和业务类型估计模型中,生成训练好的模型。在应用阶段,采用预处理后的实时数据对训练好的流量预测模型和业务类型估计模型进行测试,验证这两种模型的可行性与有效性。

图1 网络智能感知阶段图
2 基于注意力Seq2Seq的用户及基站的多步流量预测
网络流量预测是指根据网络中已存在的历史流量数据,分析这些数据周期性的变化规律或者特征,以此为基础对未来一段时间内的网络流量值或者趋势进行合理的预判[13]。此方法能够提前感知网络的运行状况,常用于流量预测的深度学习方法有RNN、LSTM、GRU等,这些模型不仅考虑了当前的输入,还保留了一定的记忆功能[14],但是GRU的整体结构比LSTM更简洁,训练时收敛速度更快[15]。而在多步预测方面,Seq2Seq模型由于其内部存在编码器和解码器两部分,可以更好地表征历史数据的特征并且用此特征可以进行未来数据的预测,因此本文选用GRU构成的Seq2Seq模型用于用户以及基站的多步流量预测。本文中流量预测包含用户的流量预测和基站的流量预测,统称为流量预测。
2.1 多步流量预测问题建模
多步预测问题经常使用的方法有4种:直接多步流量预测法、递归多步流量预测法、直接递归融合多步流量预测法以及多输出流量预测法。由于第一种预测方法需要训练的模型太多,第二种预测方法会造成误差的积累,第三种预测方法所需的时间以及空间开销较大,故本文使用多输出流量预测法实现用户以及基站的多步流量预测。
在实际的场景中,某一终端用户n在第t个时间间隔内通过的数据流大小用fn,t表示,则该用户的流量集合可以表示为fn={fn,1,fn,2,...,fn,t}。多步流量预测是使用历史H个时间步长的流量数据预测未来T个时间步长的流量。因此,在训练阶段,需要使用真实的历史时间步长为H的用户流量数据输入到模型中,而流量数据与历史时间步长H有关,表示为:
(1)
式中,Fn的每一维流量序列Fn,t-H+1需要对应一个未来时间步长为T的预测序列,表示为:
(2)
2.2 数据采集与预处理
本文使用安装在虚拟分组数据网网关(virtual Packet Data Network Gateway,vPGW)所在的Docker容器中的网络数据采集工具Tcpdump和Timeout完成数据的采集工作。
流量预测的数据预处理过程主要包括数据包长度解析、求取包络、数据截取和归一化。解析数据包可以得到一个数据包的长度,将单位时间内所用数据包的大小相加可得到用户的流量序列fn;由于终端用户的流量在短时间内震荡比较严重,流量数据为非平稳序列,这些震荡特征有可能超出了Seq2Seq模型的学习范围,因此通过对流量序列fn取上包络的方式对流量数据进行平滑,得到新的用户流量数据fn;数据截取过程首先对流量数据fn进行截取,得到与历史时间步长H有关的用户流量数据Fn,t-H+1,然后以H+1为起点,长度为T对fn再进行截取,得到与需要预测的未来时间步长T有关的用户流量数据Yn,t-H+1,由此构成一个完整的用户流量样本。之后,再以滑动步长为1,重复上述操作,直到最后一个流量值被截取到为止;归一化过程可以避免模型提取到的数据特征向量与预测值之间的量纲不一致问题,使流量数据更方便模型处理。
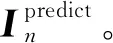
2.3 基于注意力机制的Seq2Seq模型设计
由于普通的Seq2Seq模型编码器得到的中间向量C无法完全表达整个输入的用户流量信息,而且随着输入的用户流量信息不断增加,后来的流量信息会覆盖之前已经编码过的流量信息,造成信息的丢失。因此本文在Seq2Seq模型中加入了注意力机制用来解决上述问题。
在每一次进行用户流量预测的过程中,用户流量的真实值fn,t与经过模型预测后的预测值yn,t越接近,表示预测效果越好,因此损失函数被定义为:
(3)
式中,i为当前时间步,t-H+1为预测序列的长度。在训练过程中,损失越小,模型的效果越好。
本文所设计的基于注意力机制的Seq2Seq模型结构如图2所示。图中,第一层为输入层,其大小与输入样本格式相匹配,为(t-H+1)×H×1。第二层是由含有128个隐藏层神经元的GRU循环单元组成的编码器,负责将输入的流量数据进行编码,得到中间向量。第三层是由含有128个隐藏层神经元的GRU循环单元组成的解码器,负责对中间向量进行解码。最后一层为输出层,其大小与期望预测的未来时间步长有关,为(t-H+1)×T×1。
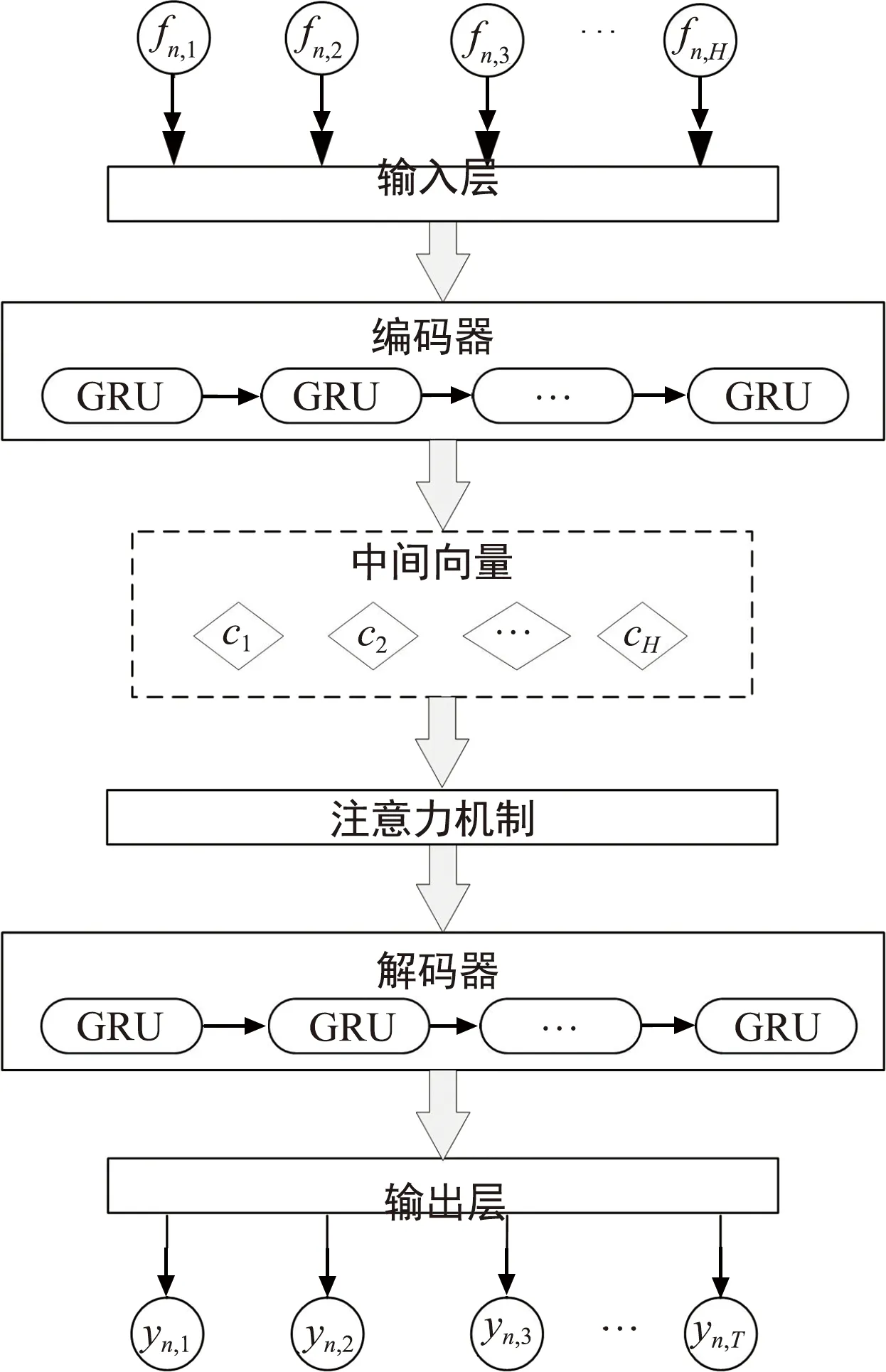
图2 具有注意力机制的Seq2Seq模型结构图
3 基于CNN的业务类型估计
业务类型估计的算法或模型需要根据实际场景需求进行选择,进而搭建、训练业务类型估计模型,调整模型的参数。常见的业务类型估计算法有SVM、决策树、神经网络等,其中CNN通过引入卷积核与池化层等技术手段自动提取矩阵数据中的特征,避免了提取数据特征的复杂过程以及可能引入的相关误差,减少了训练时学习的模型参数数量,因此本文选用CNN用于业务类型估计。
3.1 业务类型估计问题建模
网络中所有用户构成的业务类型集合可以表示为m∈M,其中M表示网络中业务的种类数。输入到模型中某一业务的第i个数据样本Gi表示为:
(4)
式中,b代表某一数据包中的某个字节,k为一个样本中包含的数据包个数,l为所截取的一个数据包中的字节数,所以可将其组合为一个k×l的矩阵。输入到业务类型估计模型中的数据集表示为Iestimate=[(G1,X1),(G2,X2),…,(Gm,Xm)],其中,Xm表示第m种业务的种类标签。
3.2 数据采集与预处理
本节中数据采集过程与前文中数据采集过程相同。数据流中所有的数据包均由数据包细节和字节组成,数据包细节和数据包字节中的内容相对应,包含MAC、IP、数据包长、协议头部或会话特征等关键信息,能够凸显出业务特性[16]。
因此数据的预处理需要从数据包字节中提取关键字节组合成数据集,由数据包解析、截断或填充、数据生成、规范化以及打业务标签这5个步骤组成。数据包解析过程将按会话标准将采集的数据归类,并删除数据包中与业务特征无关的信息(如IP、数据链路层数据等[17]);截断或填充过程是为了统一数据包中的字节数l,从第一个字节开始,对超出预设字节数l的字节进行截断,否则补零直到字节长度达到l;数据生成过程采用进制转换的方式将数据包中的内容转换成带有业务特征信息的数据;规范化过程是对每个数据归一化为[0-1];打业务标签过程是将生成的数据按照业务种类进行标注。
3.3 CNN模型设计
本文所设计的二维CNN结构如图3所示。
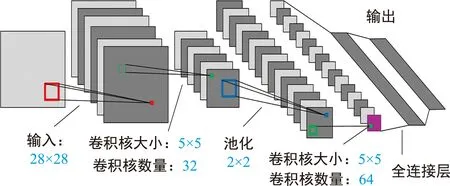
图3 CNN模型结构图
第一层为输入层,其大小为k×l,根据相关研究[18]与实验对比,本文设置k和l均为28。第二层和第三层分别为卷积层和池化层,卷积层中设置32个卷积核,每个卷积核的尺寸设置为5×5,滑动步长设置为1,激活函数选择ReLU,相比于Tanh、Sigmoid等算法更容易求解梯度[19],池化层采用最大池化策略,池化窗口的尺寸设置为2×2,滑动步长设置为2。第四层和第五层也分别为卷积层和池化层,卷积层中设置64个卷积核,其余设置与第二层和第三层保持一致。第六层和第七层均为全连接层,第六层选择Sigmoid作为激活函数,第七层经过Softmax输出业务类型估计结果。
4 平台搭建、实例部署与结果分析
4.1 通感算智能内生融合平台架构
现如今,通信系统与感知、AI等多种系统的深度融合已成为技术发展的新趋势。内生智能架构支持网络元素与AI元素的深度融合,也支持将AI能力按需编排到无线接入网、承载网、核心网中。为了实现网络高度自治且满足多样化业务,需要提供智能化所需的实时、高效的各种基础能力。
因此,本文设计了一个面向RAN的通感算智能内生融合系统架构。该架构综合考虑了RAN中的通感算能力,以微服务的形式将各种能力拆分为多个网络功能(Network Functions,NFs),并使用AI技术将各种能力进行融合,相对于现有网络架构具有模块化设计、解耦资源、便于加载智能算法、便于算法直接调动网络资源等优点。本文提出的通感算智能内生融合系统架构如图4所示。

图4 通感算智能内生融合模型
横向上该架构每一层功能为:
① 应用与服务层:该层主要为各个面的应用与服务提供相应支持,其中通信面的网络应用层主要提供RAN中传输的业务,感知面的感知应用层主要提供网络感知应用服务(如流量感知、业务类型感知等),算力面的算力应用层主要提供算力应用服务(如算力资源分配),智能融合面的通感算App’s智能融合层主要与其他面进行交互。
② 网络功能层:该层主要由一些基于微服务思想设计的特定网络功能组成。该层将各个面提供服务的过程按照功能独立自治、开发简易、可重复调用等原则拆分成几个网络功能,网络功能之间采用SBI总线进行信息交互。
③ 虚拟化层:该层主要基于Docker Engine和Hypervisor技术对基础设施层的多种硬件资源进行虚拟化。
④ 基础设施层:该层主要由提供整个RAN系统正常运行的各种硬件组成,每个硬件中均包含计算、存储、通信等资源。
纵向上该架构中的每一个面的功能为:
① 通信面:该面主要负责承载传统的无线移动通信业务,为用户提供可靠的无线数据传送服务。
② 感知面:该面主要负责采集RAN中各种设备的数据并使用AI算法对数据特征进行提取,进而智能感知网络的整体状况。
③ 算力面:该面主要将计算能力抽象为服务,为其他层和面提供统一的算力支持。
④ 智能融合面:该面负责将各个层与面多方数据的智能融合与共享,并将这些共享数据用于网络管理,反作用于其他层和面。
应用与服务层由算力面、感知面、通信面以及智能融合面最上层的应用构成,网络功能层由算力面、感知面、通信面以及智能融合面中间的网络功能组成,面与层之间相辅相成,存在重叠部分。
4.2 基于深度学习的流量与业务类型感知流程
本文中网络智能感知实例为流量预测实例和业务类型估计实例,分为训练阶段和在线推理阶段,本文只对在线推理阶段实例化流程进行详细描述。
4.2.1 流量预测实例
流量预测在线推理阶段实例化流程如图5所示,具体描述如下:

图5 流量预测在线推理阶段实例化流程
步骤1智能融合面向在线推理NF发起流量预测实例化请求,转向步骤2;
步骤2在线推理NF从模型评估网络功能中获取评估后的流量预测模型并进行加载,然后向感知数据采集NF发起数据采集请求,转向步骤3;
步骤3感知数据采集NF捕获网络中的流量数据包,然后将采集的原始数据存到感知数据存储网络功能中,并发送至数据预处理NF,转向步骤4;
步骤4感知数据预处理NF对采集的原始数据进行数据预处理操作,然后将预处理后的数据存储到感知数据存储网络功能中,并输入至在线推理NF中,转向步骤5;
步骤5在线推理NF将预处理后的数据输入加载好的Seq2Seq模型中,得到多步流量预测结果,再将预测结果反馈给智能融合面。
4.2.2 业务类型估计实例
业务类型估计在线推理阶段实例化流程如图6所示,具体描述如下:

图6 业务类型估计在线推理阶段实例化流程
步骤1智能融合面向在线推理NF发起业务类型估计实例化请求,转向步骤2;
步骤2在线推理NF从模型评估网络功能中获取评估后的业务类型估计模型并进行加载,然后向感知数据采集发起数据采集请求,转向步骤3;
步骤3感知数据采集NF捕获网络中的流量数据包,然后将采集的原始数据存到感知数据存储网络功能,并发送至数据预处理NF,转向步骤4;
步骤4感知数据预处理NF对之前采集的原始数据数据预处理操作,然后将预处理后的数据存储到感知数据存储网络功能中,并输入至在线推理NF中,转向步骤5;
步骤5在线推理NF将预处理后的数据输入加载好的CNN模型中,得到业务类型估计的结果,再将业务类型估计结果反馈给智能融合面。
4.3 平台搭建与实例部署
使用蜂窝网实验平台对用户与基站的流量和业务类型感知算法进行实现,实验场景如图7所示。
图7 RAN场景图
主要考虑具有单个基站的下行链路蜂窝网络系统,服务提供商在边缘服务器中部署了高清视频、无损音乐、电子书三种业务。
为了模拟真实的网络场景,实验中使用Nginx总共部署了三种业务,分别为高清视频、无损音乐以及电子书,三个4G智能手机通过基站随机访问这三种业务,业务的相关信息如表1所示。

表1 用户参数设置信息
4.4 方案测试与结果分析
4.4.1 用户及基站的流量预测
在进行多步流量预测时需要考虑所使用的历史序列步长以及需要预测的未来步长。当选用的历史步长过小时,模型无法捕获时间序列的完整依赖关系,当所选用的历史步长过大时,模型会将本不存在依赖关系的流量数据过度挖掘。当设置的未来步长过小时,无法突出多步流量预测的优势;而未来步长较大时,会导致预测值误差的积累。因此,本文对比了采用不同历史和未来时间步长的预测模型,从中选择出预测误差最小的模型,而基站的流量预测结果为所有用户的流量预测结果之和。
不同感知时间粒度的用户流量数据决定了资源分配的最小时间粒度,从而决定了资源分配的灵敏度。因此,本文对比了采用不同感知时间粒度的流量数据进行流量预测。为了对预测结果进行评估,使用平均绝对值误差(Mean Absolute Error,MAE)和决定系数R2[20]这两个指标衡量预测结果,其表达式如下:
(5)
(6)
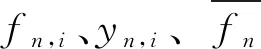
不同算法在感知时间粒度为0.1 s的不同步长的流量预测性能对比结果如表2所示,其中“HxTy”表示使用历史步长为x的用户流量数据输入模型中预测未来步长为y的用户流量数据。可以看出,相较于其他两种算法,具有注意力机制的Seq2Seq算法平均MAE最小,同时平均R2也最大。这是由于递归GRU算法依然是一个多输入单输出的模型,在用于多步流量预测时,是将当前时间步的预测值用于下一时间步的预测,随着预测时间步的增大,累计的误差就越大。对于普通的Seq2Seq算法,是将输入序列编码为一个中间向量,然后解码器根据中间向量解码得到多步预测值。而对于注意力Seq2Seq算法,由于历史每个时间步的流量值对当前时间步的预测值影响程度不同,该算法通过给每个历史时间步的中间向量赋予不同的权重值,从而预测出未来的多步流量值,因此预测效果最好。

表2 流量预测性能对比(感知时间粒度为0.1 s)
在使用注意力Seq2Seq算法时,当选用“H4T2”时,MAE最小,而R2可达最大为0.65,相较于其他设置,预测结果最接近真实值。
注意力Seq2Seq算法在步长为“H4T2”、感知时间粒度为0.1 s时的预测结果如图8所示,从图中可以看出,以0.1 s为感知时间粒度所采集的用户流量数据波动性较大,模型很难预测出流量的突然上升或下降,造成模型拟合流量数据的效果一般,且预测值相对于真实值具有一定的滞后性。
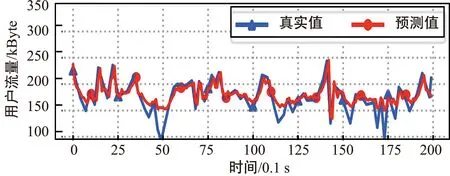
图8 步长为“H4T2”结果图(感知时间粒度为0.1 s)
不同算法在感知时间粒度为1 s的不同步长的流量预测性能对比结果如表3所示。从表中可以看出,在使用注意力Seq2Seq算法时,选用“H6T4”的归一化MAE最小,R2可达最大为0.93,相较于其他几种设置,预测效果最好。
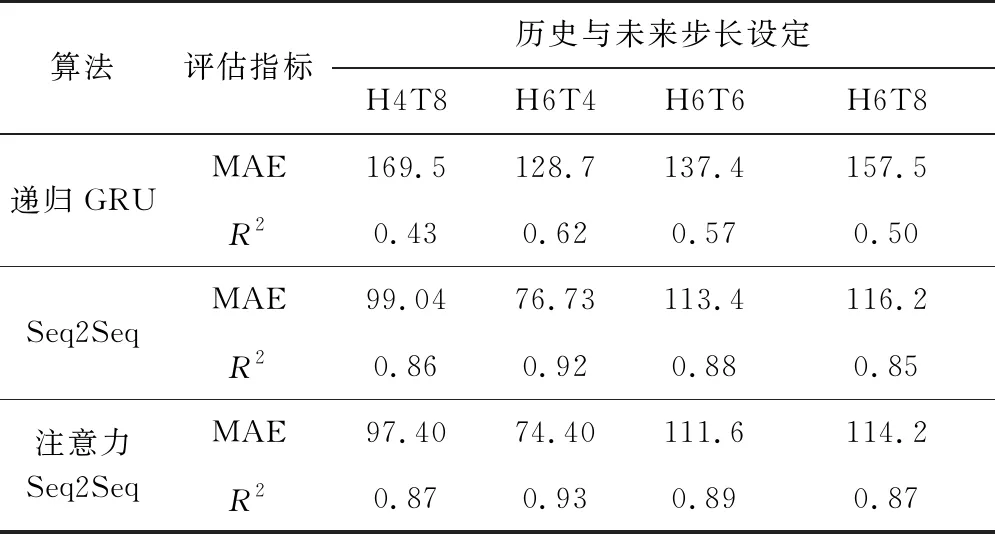
表3 流量预测性能对比(感知时间粒度为1 s)
注意力Seq2Seq算法在步长为“H6T4”、感知时间粒度为1 s时的预测结果如图9所示,从图中可以看出,当用户访问高清视频业务、访问无损音乐以及下载电子书业务时,预测的用户流量值与对应业务所要求的最低传输速率大概一致。只有在流量激增或者陡降时,预测结果稍有滞后。这是由于模型很难在短时间内根据有限的历史数据判断未来的流量数据增长或者下降,但是随着时间的不断增加,模型的输出值会缓慢过渡到真实值附近。
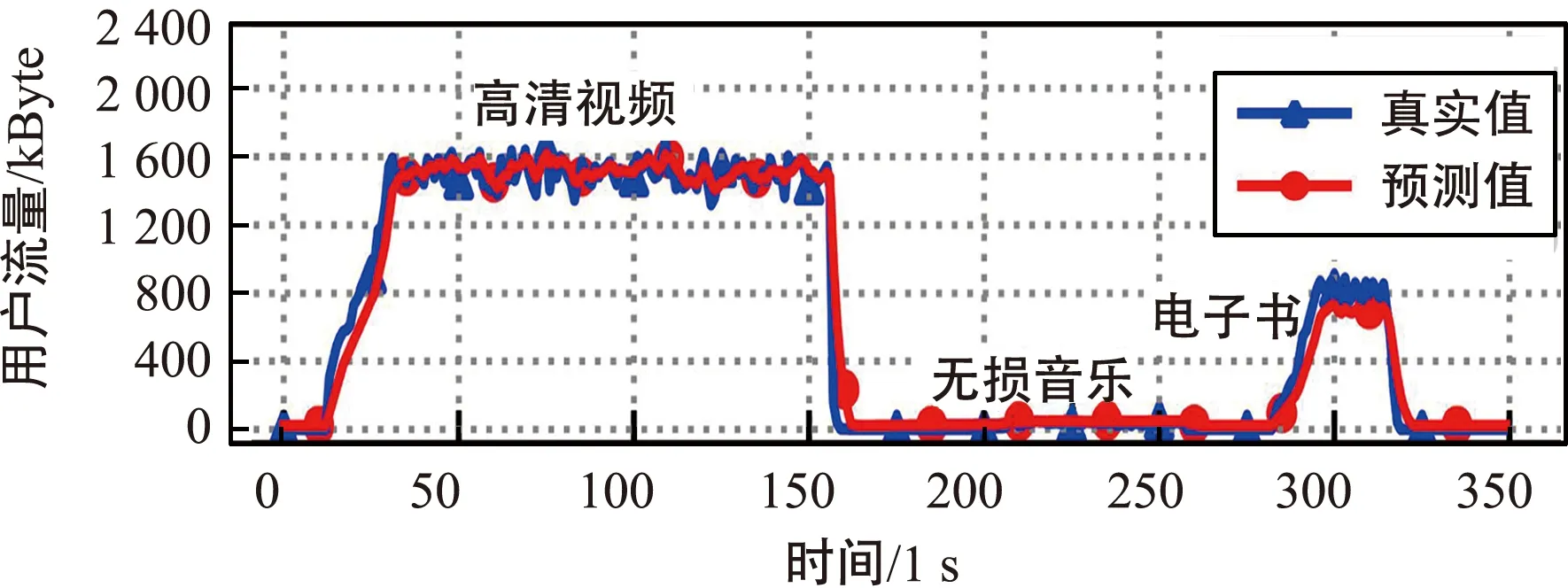
图9 步长为“H6T4”结果图(感知时间粒度为1 s)
不同算法在感知时间粒度为10 s时,不同步长的流量预测性能对比结果,如表4所示。从表中可以看出,当选用“H4T2”时,MAE最小,R2最大,相较于其他几种设置,所得到的预测效果最好。
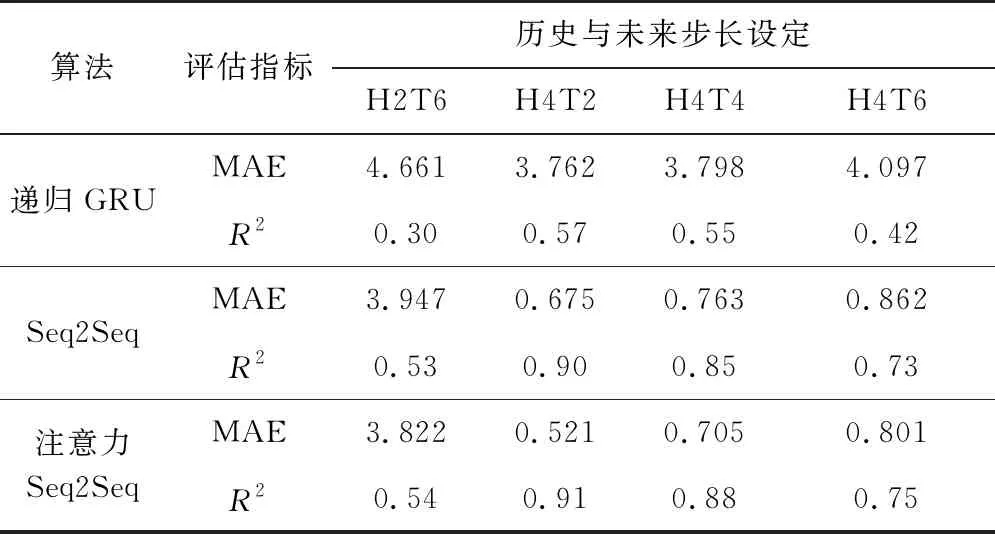
表4 流量预测性能对比(感知时间粒度为10 s)
注意力Seq2Seq算法在步长为“H4T2”、感知时间粒度为10 s时的预测结果如图10所示,从图中可以看出,当用户访问高清视频业务与无损音乐时,预测的用户流量值与对应业务所要求的单位时间内最低传输数据量大概一致。而只有当用户下载电子书时,略低于用户访问该业务时的真实值,这是由于在感知时间粒度为10 s的情况下采集到该业务的流量数据较少,且流量值相对较大,将这些流量数据输入到模型中,模型输出的预测值还未过渡到该业务需要达到的真实值附近就开始下降。
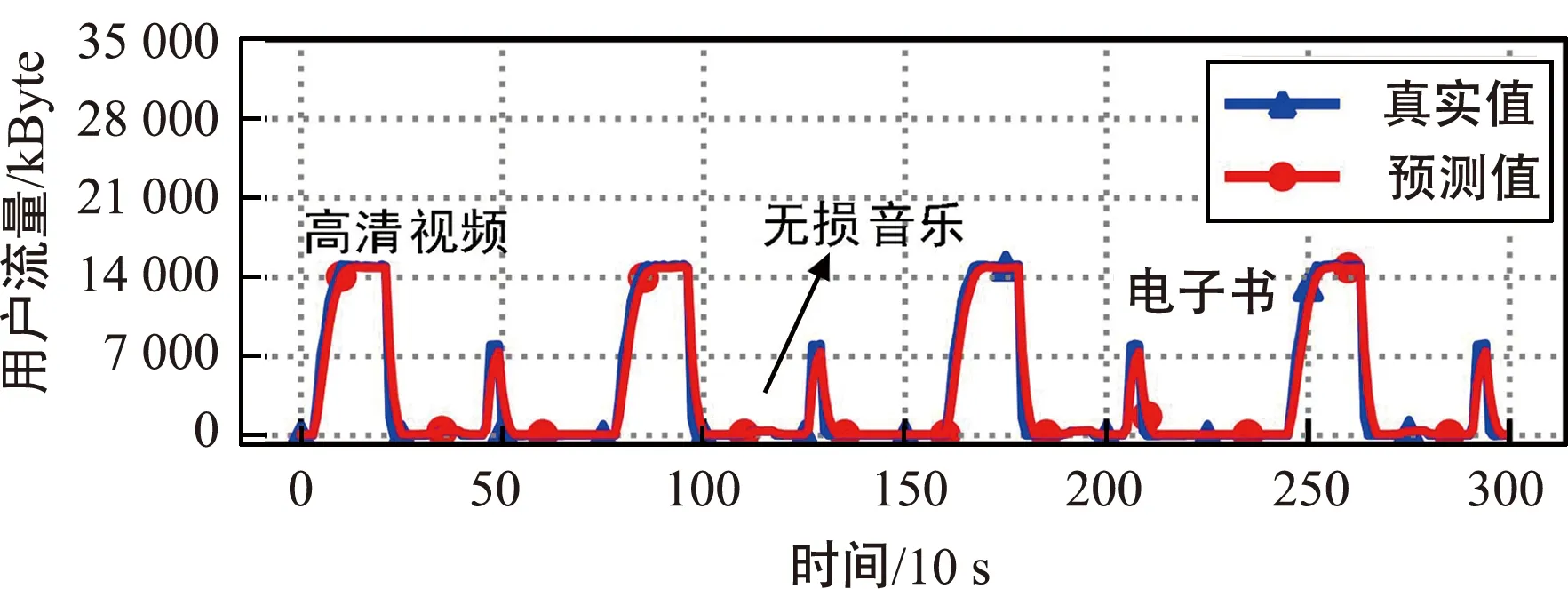
图10 步长为“H4T2”结果图(感知时间粒度为10 s)
从上述不同感知时间粒度的用户流量预测结果可知,设置步长为“H6T4”、感知时间粒度为1 s时的用户流量预测值与真实值之间的误差最小;设置步长为“H4T2”、感知时间粒度为10 s时的预测效果仅次于感知时间粒度为1 s。
4.4.2 业务类型估计
本文使用CNN模型估计了RAN中用户的业务类型并使用估计准确率衡量估计结果。准确率被定义为模型估计正确的业务样本数除以总输入的业务样本数,即
(7)
式中,Gi是样本数据,Xi是样本数据的业务类型标签。
将训练集和测试集分别输入到训练好的CNN模型中对业务类型估计模型进行评估,如图11所示。从图中可以看出,随着输入数据量的增加,平均准确率在不断提高,最终具有较高的准确率,但是在测试集数据量规模为10 000之前,模型的估计结果准确率不高,这是由于训练过程中出现了过拟合现象,随着测试集数据量的不断增大,业务估计模型的估计结果准确率也逐渐上升,最终趋于稳定。
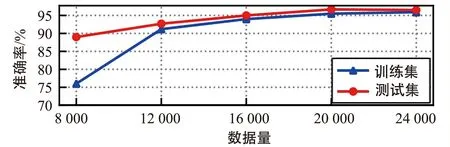
图11 训练集与测试集的平均准确率
本文测试了CNN模型中卷积核数量对业务类型估计准确率的影响,如图12所示。本文中的CNN模型有两个卷积层,卷积核数量表示为[x,y],其中,x表示第一个卷积层的卷积核数量,y表示第二个卷积层的卷积核数量。从图中可以看出,随着卷积核数量的增大,CNN模型估计结果的平均准确率在不断提升,当卷积核数量达到[32,64]时,准确率达到95%左右且趋于稳定。因此本文综合考虑选用卷积核数量为[32,64]的CNN模型用于业务类型估计。

图12 卷积核数量对平均准确率的影响
本文测试了CNN模型中卷积核大小对业务类型估计准确率的影响,如图13所示。CNN中的卷积核为一个[x*y]的二维矩阵。从图中可以看出,随着卷积核大小不断增大,平均准确率有所提升,当卷积核大小达到[5*5]时,准确率达到95%左右且趋于稳定。因此本文选用卷积核大小为[5*5]的CNN模型进行业务类型估计。
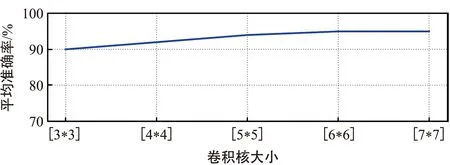
图13 卷积核大小对平均准确率的影响
三种业务类型估计的准确率如表5所示。由于在单位时间内高清视频传输的数据量最多,电子书次之,无损音乐最少,因此构建的业务类型估计样本高清视频最多,无损音乐最少,而三种业务类型的估计准确率与对应的业务样本数成正比关系,这是数据分布不均造成的。但是三种业务类型的平均准确率为95.63%,估计结果相对较好。
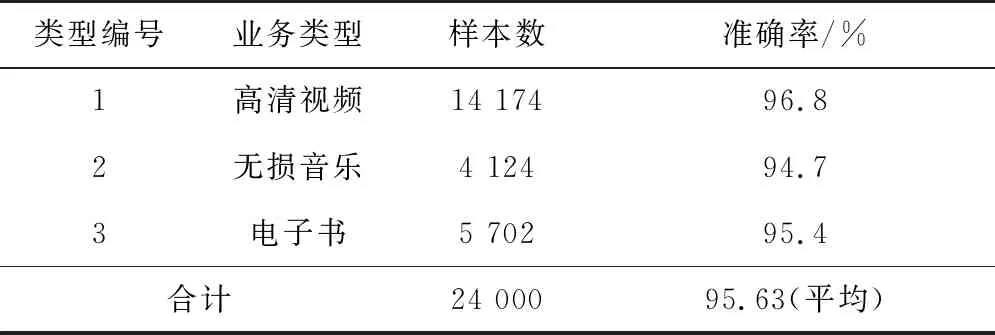
表5 三种业务类型估计准确率
5 结论
本文设计了一种面向6G通感算融合的网络智能感知方案,分别使用Seq2Seq和CNN算法对基站与用户未来流量与当前网络业务种类这两个网络感知指标进行智能感知,并在实验平台上进行了部署与测试。通过实验验证,证明了本文所设计的模型能够实现较低误差的流量预测,同时也能够实现较高准确率的业务类型估计。网络智能感知方案及实验平台的实现,对资源分配及6G通感算智能融合等研究具有一定的参考价值。未来可以考虑将物理层的一些指标也进行感知,如信道质量指示、SNR、参考信号接收质量等,从而更全面的感知网络状态,获取更加丰富的网络信息用于做出决策。
猜你喜欢
玩具世界(2022年2期)2022-06-15
成都信息工程大学学报(2021年5期)2021-12-30
北京航空航天大学学报(2021年9期)2021-11-02
房地产导刊(2021年8期)2021-10-13
出版人(2020年4期)2020-11-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
河北科技大学学报(2015年5期)2015-03-11
电测与仪表(2014年2期)2014-04-04
电视技术(2014年19期)2014-03-11
