
一种基于改进SSD的原木端面识别方法
2023-02-09 08:09:14胡笑天王克俭王超剪文灏何振学
林业工程学报 2023年1期
胡笑天,王克俭*,王超,剪文灏,何振学
(1.河北农业大学信息科学与技术学院,保定 071001;2.河北省城市森林健康技术创新中心,保定 071001;3.河北省农业大数据重点实验室,保定 071001; 4.河北省木兰围场国有林场管理局,承德 067000)
原木楞堆是森林收获过程中原木暂存和运输的重要方式,传统的楞堆原木材积计量都是采用人工检尺的方法,这种方法需要大量的人力,并且容易受检测工作人员的工作态度和经验影响,效率低、周期长、成本高。随着计算机技术特别是计算机视觉技术的发展,通过图像采集、端面识别代替人工检尺是原木管理的迫切需求,同时原木轮廓的多样性、拍照环境的复杂性,对设计鲁棒的原木轮廓识别算法提出了更高的要求。笔者针对复杂环境,提出了一种原木端面识别方法,为自动检尺系统的构建奠定了基础。
近年来原木端面识别主要是以景林和林耀海团队为代表的对传统方法的研究。2006年,景林等[1]通过计算灰度图像的阈值等效圆拟合原木端面面积;2013—2015年该团队结合彩色特征和空域特征[2]、多特征综合[3]对成捆原木端面区域进行了识别。钟新秀等[4]使用Lab颜色空间的K-Means聚类结合Hough变换对原木根数进行统计。林耀海等[5]利用圆弧特征对原木轮廓进行了识别。另外,赵亚凤等利用双目视觉[6-8]对原木径级和材积进行了计算。李小林等[9]通过将K-Means算法与分水岭算法相结合计算出原木端面区域。唐浩等[10]基于色差聚类对原木图像端面进行了检测与统计。近年来,随着深度学习的发展,卷积神经网络在图像处理上的优势也显现出来[11],林耀海等[12]针对成捆原木端面裂纹、端面有污渍霉变等情况引入YOLOv3-tiny卷积神经网络对原木端面图像进行目标检测,获得了较好效果。
上面这些算法主要利用的是原木端面为类圆的几何特征,原木边缘、纹理等特征进行识别,双目视觉对环境光照要求敏感,计算复杂性高。这些算法在原木端面较为完整干净并且光照比较好的情况下能够准确实现原木端面面积计算。但是,原木背景环境复杂、原木楞堆参差不齐、端面差异大,或者原木端面存在遮挡重叠及阴影覆盖等情况对原木自动检尺提出了更高的要求。以SSD(single shot multibox detector)和YOLO为代表的目标检测算法不需要产生候选框,直接计算出物体的类别概率和位置等信息,具有较高的检测精确度和检测速度。
本研究针对自然环境下原木楞堆存在的端面大小差异大、遮挡重叠或阴影覆盖等问题,以SSD算法作为基本的框架,对其进行改进。首先在SSD上引入RFB模块,RFB模块结合了空洞卷积和多尺度卷积核,能够提高网络的感受野,能够较好识别小目标;然后将CBAM注意力模块添加到SSD的有效特征层,提高SSD的特征提取能力,对于遮挡重叠或阴影覆盖等有较好效果。
1 数据集制作
本研究使用的实验数据是拍摄的自然环境下的成垛原木以及木材厂拍摄的成垛原木,拍摄地点为河北省承德市木兰围场工作验收现场以及木材厂,拍摄设备采用尼康D7500相机和华为mate系列手机。
使用python对图像进行裁剪,将原始一张图像裁剪成多个300×300的标准图像,标注图像若没有原木则xml文件为空,会导致训练时出错,因此将不含原木的图像从数据集中剔除。在测试集中可以保留不含原木的图像,最终得到828张,实验中图像数量分布为:训练集596张,占总数据的72%;验证集66张,占总数据的8%;测试集166张,占总数据的20%。清楞和混楞的原木图像如图1a~c所示,其中清楞是原木端面大小相似的原木楞堆,混楞是原木端面差异较大的原木楞堆。原木端面大小差异较大的混楞原木堆见图1b,原木端面存在差异且存在阴影和遮挡的原木楞堆见图1c。

图1 原木楞实验数据示例Fig.1 Examples of log pile experimental data
为了使算法有更好的泛化性,模型中使用数据增广算法,减少因数据集数量限制对模型性能发挥的影响。本研究使用了图像旋转、翻转、高斯噪声、椒盐噪声、图像亮暗变化对训练集数据进行扩充。图像加入噪声以及亮度变化的结果见图1d~f。
裁剪及数据增广完成后获得实验图像3 312张,使用labelImg工具对图像进行标注,将图像中的原木框选并注明类别,标注图像如图1g~i所示。
2 改进的SSD目标检测网络
2.1 SSD网络
SSD是一种one stage的目标检测网络[13]。SSD结合了Faster R-CNN的anchors机制和YOLO回归的思想,不用产生候选框,直接对图像进行多尺度的回归。
本研究中的SSD网络以300×300的图像作为输入,以VGG16作为主干网络,VGG16具有13个卷积层和3个全连接层,SSD将VGG16的全连接层fc6和fc7替换成卷积层,并更名为conv_fc6和conv_fc7,舍弃fc8层并在VGG16后加入了额外的卷积层即Extra层,包括conv6等一系列卷积层。最后以conv4_3、conv_fc7、conv8_2、conv9_2、conv10_2、conv11_2作为有效特征层进行目标的检测,网络结构如图2所示。
SSD进行目标检测时,通过上述6个有效特征层提取不同尺度的特征,检测目标的方法借鉴Faster R-CNN的anchor机制,预先设定先验框,先验框生成规则如下:
SSD的6个有效特征层每个特征单元分别会产生4,6,6,6,4,4个先验框,不同特征层的先验框尺度不同,同一个特征单元的先验框宽高比不同。特征图中每个特征单元产生先验框的个数由参数aspect_ratio决定,asprct_ratio即模型给定的不同特征层先验框的个数和宽高比,其具体值为aspect_ratio ={[2],[2,3],[2,3],[2,3],[2],[2]}。生成情况如图2所示。
以conv4_3为例,aspect_ratio值只有1个2,根据图2所示规则,默认产生2个不同大小的正方形,如图2虚线所示;然后根据aspect_ratio=2,得出宽高比为1∶2的两个长方形,因此一共产生4个先验框。再如conv_fc7的aspect_ratio值为[2,3],两个值分别得到宽高比为1∶2和1∶3的4个长方形,一共产生6个先验框。
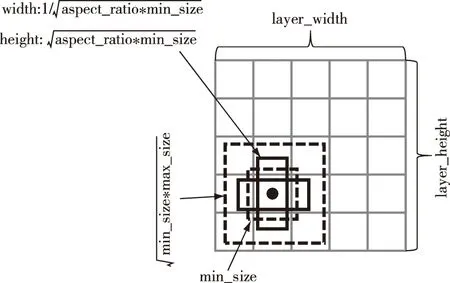
图2 预测框结构Fig.2 Structure chart of prediction box
SSD模型训练过程如图3所示。
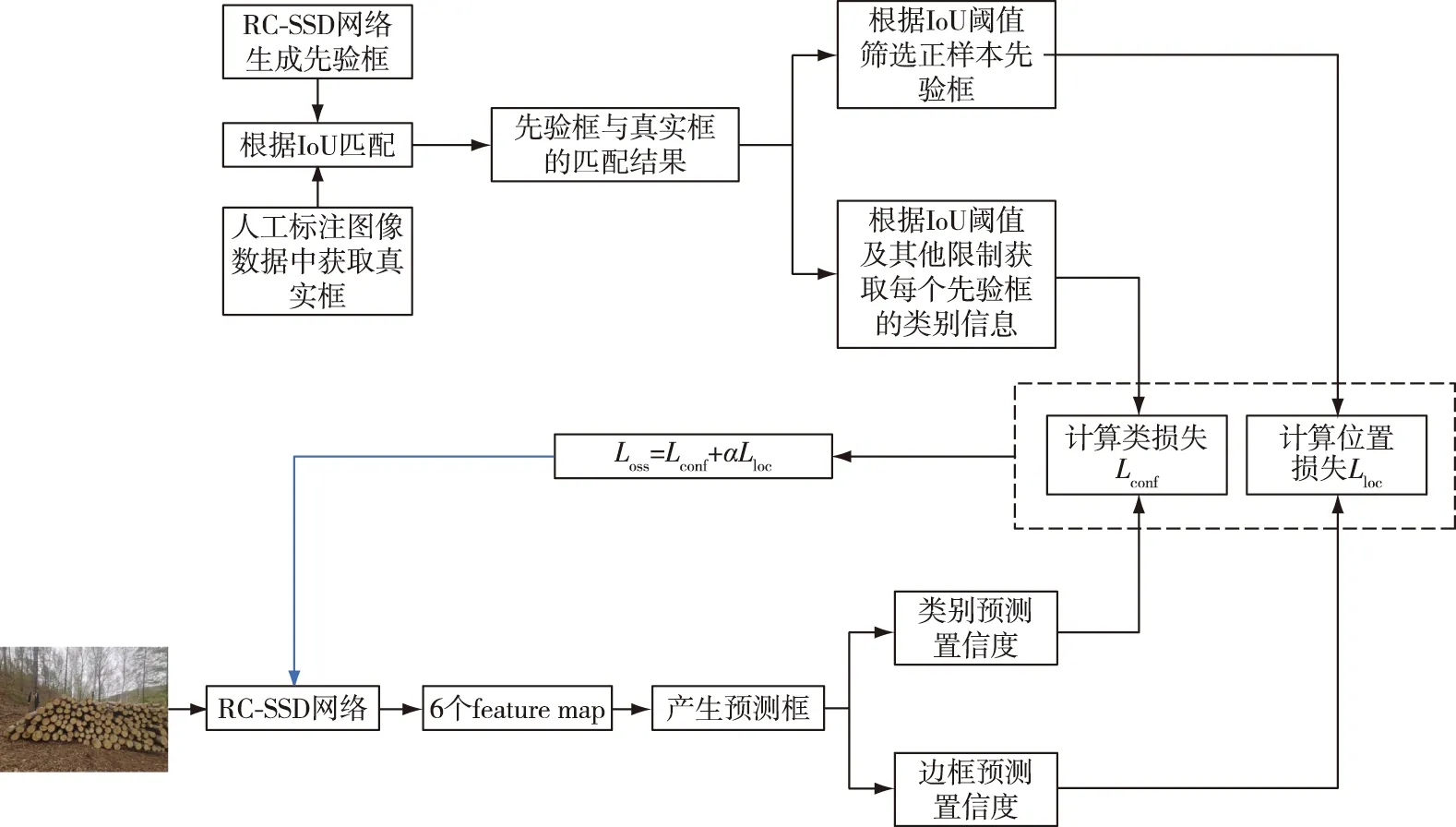
图3 SSD检测流程Fig.3 SSD detection process
首先生成各有效特征层相应数量的先验框,根据输入的训练样本,获取预先人工标注的真实框;然后计算真实框与所有先验框的交并比IoU,选出一个IoU值最大的先验框,保证至少有一个先验框可以作为正样本与真实框进行匹配,将剩余先验框中IoU值大于设定阈值的框也作为正样本与真实框进行匹配;将保留的先验框与真实框进行中心位置和宽高差异的计算,即计算先验框相对于真实框的偏移量,并将计算结果保存,这样能够将真实框转换成能参与loss计算的形式;训练样本经过网络预测得到一系列的预测框,将预测框和上述保存的结果进行loss回归计算,并将loss反向传播修正网络权重。
训练完成之后的预测过程为将待测图片输入网络进行预测,生成的预测框根据类别置信度和相应类别的置信度值,将置信度值低于阈值的预测框舍弃,保留下来的预测框的数量可能依然很多,所以需要通过NMS进行进一步的筛选,得到最终的检测结果。
2.2 基于RFB模块的扩大感受野设计
SSD目标检测算法虽然具有较高的速度,但是在对小目标的检测上,容易出现漏检的现象[14-15]。这是因为SSD网络采用了多尺度特征融合的方法,含有多个有效特征层来提取图像的特征,但是对于小目标的检测主要依赖conv4_3特征层,该层位于网络的浅层,感受野小,特征表达力差。
因此,为了增强浅层conv4_3的特征提取能力,将其相邻的有效特征层conv_fc7增加一个分支,将该分支经过上采样变成与conv4_3大小相同的特征图后融合提高原conv4_3的特征提取能力,conv_fc7特征图与conv4_3的大小差异相比其他有效特征层更小,因此选conv_fc7与其进行上采样融合最合适。
融合两层特征替换原conv4_3后,为进一步扩大SSD有效特征层的感受野,提高网络的特征提取能力,引入了RFB模块,RFB模块来源于RFB Net[16],由多分支卷积层和膨胀卷积层组成。多分支卷积层借鉴了Inception的思想,用不同尺寸的卷积核进行卷积操作,从增加网络的宽度实现增加感受野、提升网络性能的目的,但网络宽度的增加也造成网络学习参数的增加,使网络计算量增大并且容易陷入过拟合。为了使计算量不增加又能扩大网络的感受野,在引入多分支卷积结构的基础上加入膨胀卷积层,与普通卷积的不同是膨胀卷积包括一个膨胀率,用来表示膨胀的大小,若膨胀率为1,则与普通卷积核相同;膨胀率为3,则在普通卷积核的每个参数之间插入两个空洞。因为是空洞,所以在计算时并没有增加计算量且扩大了感受野。
RFB模块分为BasicRFB和BasicRFB-a两种,BasicRFB模块结构见图4虚线内部。BasicRFB模块使用了1×1、3×3、5×5 3个不同尺寸的卷积核构成多分支卷积结构,模块内还包含rate={1,3,5}的膨胀卷积层;最后将不同尺度的特征图进行融合,并使用1×1卷积来调整特征维度,调整特征维度后与shortcut执行element-wise相加。BasicRFB-a与BasicRFB不同的是使用3×3卷积层替换5×5的卷积层,并将原有的3×3卷积层拆分成1×3和3×1两个卷积层,减少了计算量,提升了网络性能。
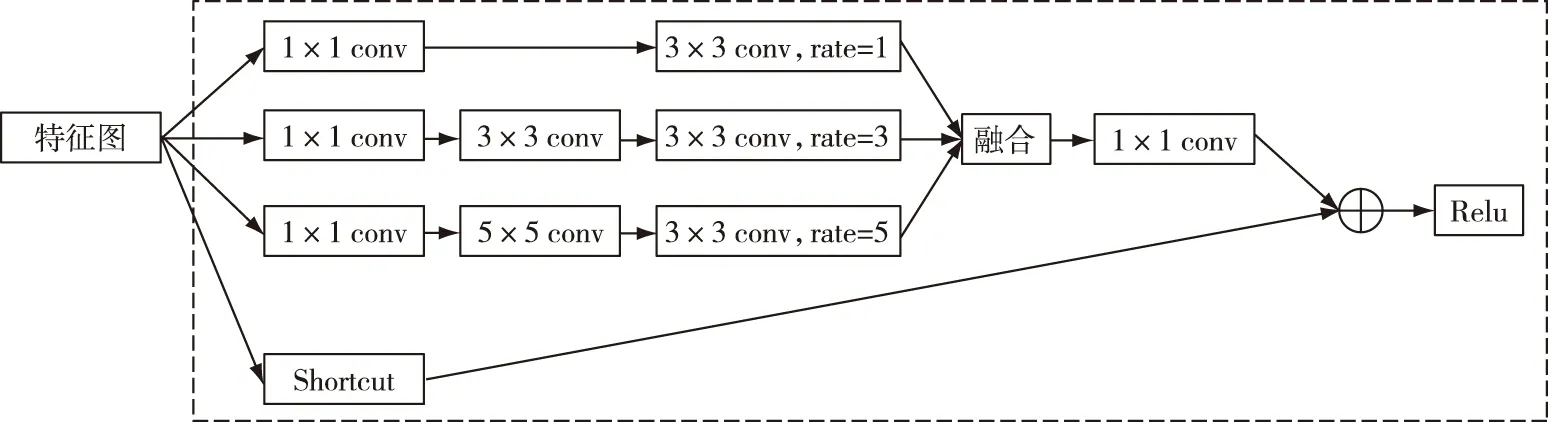
图4 BasicRFB结构Fig.4 Structure chart of BasicRFB
将BasicRFB_a放在融合conv4_3与经过下采样的conv_fc7分支之后,目的是在增加较少计算量的情况下进一步扩大该特征层的感受野。将BasicRFB放在conv_fc7层之后,并将SSD的extras特征层中的前两组卷积层即conv6和conv7替换成BasicRFB,增大了网络的感受野。
2.3 基于CBAM的原木有效特征提取设计
扩大了感受野之后,网络的特征提取能力增强,但是不同特征的重要程度不同,而且在计算机视觉领域,卷积操作的工作大部分是在空间上更多特征的融合,而卷积对通道维度的特征融合仅限于对特征图的所有通道进行融合。针对这一问题引入注意力机制,在原木端面识别的过程中根据特征的重要程度分配权重。
常用的注意力机制有两个,分别是squeeze-and-excitation (SE)和convolutional block attention module (CBAM)。SE模块仅对通道特征进行加权,CBAM则是一种结合通道和空间的注意力模块,经过对比实验,本研究选择的是CBAM注意力模块[17],实验结果如表1所示。
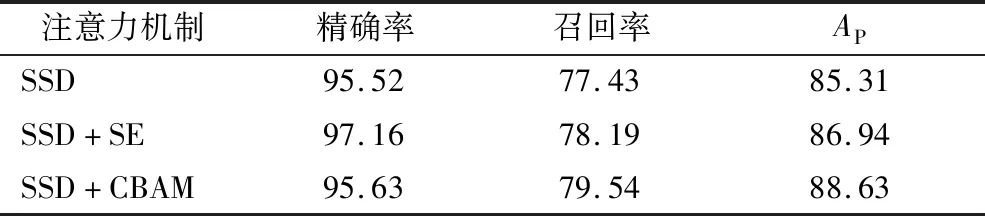
表1 注意力机制对比Table 1 Comparison of attention mechanism 单位:%
本研究改进的目的是加强模型对小目标的检测能力,从而提高原木端面的识别效果。因此召回率的提升较为重要,从表1数据可以看出,SE模块和CBAM在混楞原木端面识别中,CBAM的召回率较高,因此本研究选择CBAM来对SSD进行改进。
CBAM首先通过一个通道注意力模块,将输入的特征图F0经过最大化池化和平均池化操作得到两个通道特征,再将两个通道特征分别通过两个全连接层,将全连接层的输出融合再经过sigmoid激活,得到了通道注意力权值Mchannel,如公式(1)所示。
Mchannel=σ{MLP[AvgPool(F0)]+
MLP[MaxPool(F0)]}
(1)
式中:MLP为全连接层;AvgPool和MaxPool分别为平均池化和最大池化;σ为sigmoid激活函数。
将通道注意力权值Mchannel与输入特征F0进行矩阵全乘,得到空间注意力模块的输入F1,如公式(2)所示;将F1分别通过最大池化和平均池化得到两个特征图,融合后再经过一个卷积层得到空间维度特征权值Mspatial,如公式(3)所示;利用矩阵全乘运算,将这个特征权值与F1融合得到的新特征图F2能够加强有效特征的权重,提高识别效果,如公式(4)所示。
F1=Mchannel×F0
(2)
Mspatial=σ(f7×7{[AvgPool(F1),MaxPool(F1)]})
(3)
F2=MspatialF1
(4)
式中,f7×7为一个7×7的卷积层。
2.4 融合RFB与CBAM模块的SSD网络
本研究在SSD目标检测网络的基础上使用RFB模块与CBAM注意力机制(图5)。对conv_fc7层的一个分支使用上采样,将conv_fc7与conv4_3两层进行特征组合,提高特征提取能力,然后在融合后的特征图后嵌入BasicRFB_a模块,使其成为第1个有效特征层(effective feature layer,EF1);在conv_fc7后嵌入BasicRFB模块,作为EF2;将原SSD的conv6、conv7两个卷积层替换成BasicRFB模块,并作为EF3、EF4;第5和第6特征层保持原有特征层不变,即Conv8_2和Conv9_2。
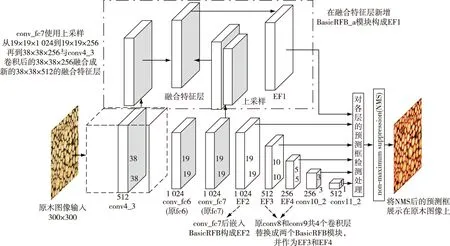
图5 改进SSD结构Fig.5 Improved SSD structure diagram
此外,在SSD嵌入RFB模块的基础上,为了使较大的目标获得较大的感受野并保持特征的完整性,较小的目标可以使用较小的感受野来保证足够的细节信息,引入CBAM注意力机制,使得网络自适应的学习特征在空间和通道上的权重,与原特征图相乘后的结果能够更有效地使网络增加对有效特征的关注,尤其是对小目标细节特征的关注。在conv4_3、conv_fc7、EF3、EF4、conv8_2、conv9_2层嵌入CBAM模块,提高网络的特征提取能力。改进的网络结构如图5所示。
原木端面检测的流程为输入待检测图像,由改进的网络各层产生先验框并用卷积对不同特征图提取检测结果,经过分类器判定是原木或背景后,采用非极大值抑制去除大量的无效框,进而获得最终的原木端面检测结果。
3 结果与分析
为验证本研究改进SSD网络的有效性和实用性,对算法进行对比实验,实验使用的硬件平台为windows10操作系统,内存16 GB,处理器为酷睿i7-9750H,GPU为NVIDIA GeForce GTX 1660Ti。
3.1 评价指标
神经网络中最常用的评价指标有精确率(precision,P)、召回率(recall,R)、AP(average precision,AP)值和mAP(mean average precision)值,本研究检测类别只有原木,因此评价指标只使用精确率、召回率和AP值。其中精确率和召回率的计算如公式(5)、(6)所示。
(5)
(6)
式中:tp为被判断为正样本的正样本;fp为被判断为正样本的负样本;fn为被判断为负样本的正样本。
AP则为一个目标检测中的常用指标,通常其AP值越高,说明这个分类器的效果越好。根据应用场景的不同,对精确率和召回率的要求不同,因此得到精确率和召回率后,可以绘制Precision-Recall曲线来帮助分析,确定应用场景适合的值,AP的几何意义是P-R曲线下的面积。
3.2 基于改进SSD的原木识别
为验证改进算法在原木识别上的有效性,对本研究制作的数据集使用改进的SSD进行检测,并使用改进前的SSD、SSD+RFB以及YOLO系列网络中常用的模型来进行对比实验,因为YOLOv5是以速度为优势的轻量级网络,在识别效果上不足以与其他网络进行对比,所以选用YOLOv3和YOLOv4进行对比,从而验证本研究改进的算法对目标的检测能力有很大的提升。
为减少模型的训练时间,在实验中采用迁移学习的思想,将SSD算法在PASCAL VOC2007上的训练模型迁移到本应用中,无须从零开始学习,只要稍加训练,即可得到较好的效果。清楞原木数据集上的AP、精确率、召回率对比结果如表2所示。
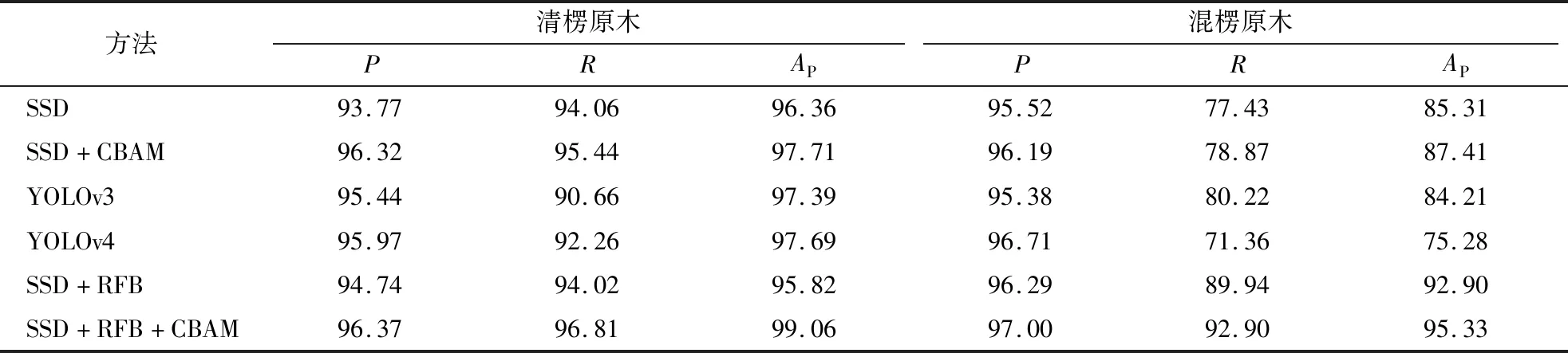
表2 原木检测结果Table 2 Log test results 单位:%
从表2可以看出,SSD+RFB以及本研究改进的算法在精确率、召回率上均有提升,但提升幅度较小,分析原因是测试集中如图1a所示的清楞原木容易检测,因此检测效果好,算法之间区分度较低,因此再针对混楞原木堆组成的测试集进行检测,检测结果如表2所示。
从表2可以看出,SSD、YOLOv3、YOLOv4、SSD+RFB与本研究算法的精确率相差较小,但本研究改进的SSD召回率比SSD、YOLOv3、YOLOv4和SSD+RFB分别高14.03%,12.68%,21.54%和2.96%。
结合公式(6)分析,是因为正样本被检测为负样本导致召回率低。4种算法针对复杂图像的检测效果如图6所示。为方便观察,将目标检测算法中传统的画矩形框改为椭圆形框,因此边界处少于半棵的原木轮廓框不准确,但不影响个数的统计,黑色椭圆框代表标记出的未检测到的原木。从图6可以看出,图6a、b、c中明显有未被检测到的原木存在,这些原木在图6e中被网络检测到,图6d也检测出绝大部分原木,但也存在少部分未检测的原木在图6e中被正确检测出来。因此改进的SSD召回率比另外3种算法高,从而充分验证了本研究对SSD改进的有效性。

图6 混楞原木检测效果对比Fig.6 Comparison of detection results of mixed log
YOLOv3和SSD同属于one stage的目标检测算法,具有速度快等优点,但是同时存在检测精度不足,尤其是对小目标检测不足的缺点。本研究对SSD目标检测算法的改进在于针对其对小目标检测不足的缺点以及其对小目标检测主要依赖conv4_3这一有效特征层的特点,引入了CBAM的conv4_3与引入CBAM并经过上采样的conv_fc7层进行结合,最后将结合得到的新特征图通过RFB模块获得第一个有效特征层。其余有效特征层分别为引入了CBAM的两个RFB模块和conv6_2、conv7_2。与原SSD相比,提高了小目标的特征提取能力,也提高了整体网络的特征提取能力。
本研究改进的SSD目标检测对存在遮挡重叠或阴影覆盖情况的原木楞堆检测效果如图7所示,可见本研究改进的算法对上述复杂情况的原木楞堆检测有了显著提高。

图7 遮挡重叠或阴影覆盖检测Fig.7 Detection of occlusion overlap or shadow coverage
4 基于图像分割的原木端面识别方法
SSD目标检测模型只能对300×300的原木图像进行检测,因此在本研究改进SSD的基础上设计一种能够检测常规大小图像的原木端面识别模型,算法流程如下:
1)下采样。与制作数据集用于训练时的方法相同,首先对高分辨率的原木图像使用下采样,将图片统一下采样成900×900,经过实验验证,本研究使用尼康D7500和华为mate系列手机拍摄的原木图像下采样到900×900,再使用分割进行检测不会对检测效果产生影响即没有丢失特征信息。因此将下采样大小预先设置成900×900。
2)小块图像分割。对图像使用含重叠区域的分割机制进行分割,重叠区域的大小需要根据待检测目标大小和原高分辨率图像进行评估,重叠区域越大包含的重复目标信息越多,造成的重复计算越多。本研究经过实验将原木图像分割时的重叠区域设置为0.3。
设置小块图像保存路径及名称,名称包含其左上角坐标在原图上的坐标及小块图像尺寸等信息,方便后续根据小块图像的名称得到其与原图的位置映射。
3)小块图像目标检测。遍历小块图像的保存路径,将该路径下的所有小块图像均通过本研究改进的SSD目标检测网络进行检测,检测结果为一系列的预测框,预测框的位置信息是其在小图上的坐标。
根据预测框在小图的位置信息和其关于原图的位置映射,得到这些预测框在原图上的位置信息,并将其保存。
4)检测结果合并。将每个小图的预测框位置信息合并至一个列表中,即得到较高分辨率图像所分割的所有块图像经过目标检测产生的预测框信息。
5)NMS去除冗余。由于采用了含有重叠区域的分割机制,导致有大量的重复计算,上一步保存的检测结果若直接画在原高分辨率图像上,同一个位置的原木会有多个预测框出现,因此调用NMS进行冗余预测框的删除。
6)获得检测结果。将经过NMS去除冗余的预测框逐一画在完整原木图像上,就得到了较高分辨率原木图像目标检测结果。
模型的实际检测效果如图8所示。被检测图像是尼康D7500拍摄的,图像尺寸为4 608×3 456,经过算法缩放至900×900,这样的尺寸不仅能够使图像不失真,又便于分割成300×300的图像进行检测。检测结果最终呈现在900×900的图像上,并且通过统计预测框的个数得到原木堆中原木共149个。

图8 模型检测结果Fig.8 Test results of the model
5 结 论
本研究提出一种基于RFB模块和CBAM机制改进SSD目标检测模型的原木识别方法。
1)通过conv4_3和经过上采样的conv_fc7层的结合提高网络对小目标的检测能力,并通过引入RFB和CBAM提高了网络的整体特征提取能力。
2)利用迁移学习的思想,将PASCAL VOC公共数据集的训练权重引入改进的SSD算法中作为预训练权重,使得本研究改进的SSD训练时间缩短。
3)改进的SSD能对自然环境下堆放的原木进行识别,尤其在混楞原木上的小目标和存在遮挡重叠或阴影覆盖检测,更能证明改进的有效性和实用性。
本研究改进的SSD提高了网络对小目标的特征提取能力,使网络的整体性能得到提升,结合能够检测高分辨率图像的原木端面识别模型,能够对成堆原木进行计数统计。下一步研究将着重关注原木端面面积的计算方法,从而实现自动原木检尺系统。
猜你喜欢
设备管理与维修(2022年21期)2022-12-28 07:34:02
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电镀与环保(2017年6期)2018-01-30 08:33:37
国际木业(2016年8期)2017-01-15 13:55:21
国际木业(2016年3期)2016-12-01 05:04:51
幸福(2016年9期)2016-12-01 03:08:42
设备管理与维修(2016年6期)2016-03-16 02:21:54
国际木业(2016年12期)2016-03-10 16:10:00
