
基于交互注意力的双图卷积网络的金融实体情感极性识别方法
2023-02-04 09:26:56任鹏飞王素格李书琪闫婧涛
中文信息学报 2023年12期
任鹏飞,李 旸,王素格,3,李书琪, 闫婧涛
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 山西财经大学 金融学院,山西 太原 030006;3.山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
0 引言
文本情感分析是自然语言处理领域中一项重要的任务,按照文本表示的语言粒度,实体级和方面级情感分析均属于细粒度情感分类任务,旨在判别给定目标实体或者方面的情感极性(正面、负面、中性)。随着Restaurant、Laptop和Twitter等领域英文数据集的发布[1-2],许多研究人员致力于方面级情感分析的研究[3]。在金融领域,涉及的金融情感主要聚焦在实体级层面,例如,“网络借贷平台选择很重要,优秀公司如京东金融、支付宝借呗、腾讯微粒贷,重点黑名单如小资钱包,涉嫌非法集资近五个亿,平台对外宣称的资格证书和银行存管全是假的”,该句子包括四个实体,对于前三个实体,其情感极性均为正面,而对于“小资钱包”实体,其情感极性为负面。然而,在金融领域的实体情感分析研究相对较少,刘宇瀚等人[4]结合字形特征与迭代学习方法研究金融领域命名实体识别,但仅识别金融领域的公司名、品牌名等实体,并未对实体的情感进行判别。俞佳炳[5]提出了一种使用门控机制融合字词嵌入的表示方法,建立了结合注意力机制的长短期记忆神经网络和卷积神经网络的混合神经网络模型,但该模型并未引入金融实体和语句之间的关联关系。
目前,金融领域的实体情感分析研究主要面临三方面的挑战: 一是缺乏公开标注的金融领域中文实体级情感分析数据集;二是金融实体专有名词表达具有多样性,一些分词工具难以准确地进行分词;三是金融领域的情感表达具有隐式性,例如,“高返平台、暴雷”等。目前仅有2019CCF大数据与计算智能大赛下金融信息负面及主体判定赛题评测(1)https://www.datafountain.cn/competitions/353/datasets,该评测仅识别金融文本中情感极性为负面的实体,未对正面和中性情感极性的实体进一步细分判定。针对这些问题,本文提出了一种基于实体与句子交互注意力机制的双图卷积网络的金融实体情感识别方法(ASynSemGCN)。该方法首先利用预训练模型RoBERTa-wwm-ext[6],结合实体,对句子进行初始表示,再通过多头注意力机制建立实体与句子之间的交互信息表示,从而增强句子对实体情感极性判别的指导。在此基础上,对句子的交互表示,分别利用语法图卷积网络(SynGCN)和语义图卷积网络(SemGCN),获得实体的句法和语义深层表示,最后,将实体的深层表示、实体字级嵌入表示以及句子嵌入表示拼接,再通过全连接层对实体进行情感极性识别。其中,SynGCN模块主要是利用依存句法解析器的所有依赖弧的概率矩阵,丰富句子的语法知识,SemGCN模块主要是利用自注意力机制获得注意力矩阵,进而捕获句子中每个词的语义信息,获得句子的语义表示。本文的主要贡献如下:
(1) 利用注意力机制,建立实体和句子信息交互表示,增强实体的情感语义表示;
(2) 基于双图卷积网络,建立句子的句法和语义的深层表示,从而增强句子对实体的隐式情感表示;
(3) 构建一个金融领域的中文实体情感分析数据集,并且在该数据集上验证了本文所提方法的有效性。
1 相关工作
目前,实体级情感分析任务的相关研究较少,而且与该任务相关的研究主要集中在方面级情感分析。早期的研究人员主要是利用情感词典和人工标注的特征进行情感极性识别,而这些方法耗时费力。近年来,神经网络模型被应用于方面级情感分析中。Tang等人[7]使用两个LSTM将方面与上下文进行建模,以增强方面的信息表示。Liu等人[8]利用BiLSTM从正向和反向对句子进行编码,并将它们进行拼接,用于情感极性识别。然而,仅用LSTM并不能捕获与方面相关的重要信息,因此,Wang等人[9]提出了基于注意力机制的ATAE-LSTM模型,该模型利用注意力机制对LSTM隐藏层输出加权求和,进而计算句子中每个词对给定方面的重要性。Ma等人[10]提出了基于注意力机制的IAN模型,该模型利用LSTM对句子和方面进行编码,并使用注意力机制对它们进行交互学习,获取与方面相关的语义特征。Fan等人[11]提出了一种多粒度注意机制,用于捕获方面和其上下文间的语义交互信息。Wu等人[12]提出了一种方面-上下文交互表示结构,该结构仅依赖一种注意力机制生成上下文和方面的序列到序列的表示。但是,在利用注意力机制进行方面与句子交互时,有可能丢失一些与方面项相关的词语信息。为了增强方面与句子中词的联系,有学者将语法知识应用于方面级情感分析,如Phan等人[13]引入句法相对距离,以降低与方面联系较弱的无关词的影响;Sun等[14]利用依赖树表示句法结构信息,用于缩短方面和句子中观点词的距离,使得句子中保留依赖信息;Liang等[15]利用依赖树上的图卷积网络学习具有语法信息的方面表示。Li等[16]利用双图卷积网络分别获取方面的语法和语义表示,并融合方面的语法和语义表示对其情感极性进行判别。
上述方法主要是针对较短长度的实体进行情感极性判别,并未考虑金融领域中不同实体和句子之间的依赖关系。由于金融领域中实体名称较多,情感表达隐晦,分词工具难以准确进行分词,因此,为了增强实体的情感语义表示,本文建立句子和实体之间的关联信息,并提出了一种基于交互注意力的双图卷积网络的金融实体情感极性识别方法(ASynSemGCN)。
2 金融实体情感分析数据集构建
2.1 数据收集和清洗
本文使用的数据来源于2019CCF大数据与计算智能大赛下金融信息负面及主体判定赛题(2)https://www.datafountain.cn/competitions/353/datasets,并对原始数据进行了数据清洗和重新标注。数据清洗过程如下:
(1) 数据去重: 若数据中包含给定实体且语句有重复,则只保留一条信息。
(2) 删除无关符号: 若数据中存在网址、url标签、特殊符号(表情符号等)以及多余空格,将这些无关符号删除。
(3) 删除多余子词: 若给定的语句中,存在实体列表中多余的子词,将其删除。例如,“旺旺贷跑路!深圳警方确定投资人被骗!”,实体列表为“旺贷、旺旺贷”,仅保留实体“旺旺贷”。
(4) 删除与实体无关联的语句: 例如,实体为“京东白条”,句子为“一个人蹲在角落里,静静的听着歌回忆着曾经,眼泪悄然落下,才知道自己京东白条提现一勇敢互助感恩京东白条提现对话宜宾地震灾区受灾群众京东白条怎么用新华社成都6月24日电记者吴光于康锦谦袁波距宜宾长宁县6.0级地震发生仅过去5天,6月22日夜,珙县一场5.4级的地震让人们再次从睡梦中……”。该实例虽然包含“京东白条”,但句子的整体内容实际与“京东白条”无关,将这类数据删除。
2.2 标注过程及数据规模
按2.1节介绍的方法对原始数据进行清洗处理后,再由两名标注者对每条语句及其对应的实体情感进行独立标注,且相互之间没有交流,标注完成后,若两名标注者标注的数据有差异,则加入第三名标注者商量讨论,直至标注结果一致。为了说明标注实体情感的一致性,采用卡帕系数[17]衡量一致性指标。本文标注数据集的卡帕一致性为0.884 3,说明所标注的金融实体情感分析数据集是可靠的。
数据集中的实体主要包括“蚂蚁金服、小资钱包、京东白条、宜贷网、钱宝网、红岭创投、360金融、中弘控股、上海鼎夕金融信息服务有限公司、e租宝、河北幸福消费金融公司、中国支付通、……”。这些实体主要是公司名和品牌名等。
标注后的金融实体情感分析语料规模如表1所示。

表1 金融实体情感分析语料规模统计
部分标注示例如表2所示。

表2 部分标注示例
在表2中,金融实体情感极性为负面、正面、中性三类。对于Id为2的句子,“京东白条”仅给出定义,对于此类数据,标注为中性。
3 ASynSemGCN模型
由于不同的金融实体采用的情感表达有可能不同,并且一个句子还有可能包含多个实体,例如,“现如今网络借贷平台很多,京东金融深受用户喜爱,而钱宝网、雅堂金融、唐小僧以及联璧金融被业内称为四大高返平台,在唐小僧之前,钱宝网及雅堂金融已经爆雷。”,该例子中涉及多个金融实体,包括京东金融、钱宝网、雅堂金融、唐小僧、联璧金融,它们所在句子的情感表达有所不同,其情感极性也不尽相同。因此,实体所在句子对实体情感极性判别具有重要的指导作用,为此,本文将实体融入句子的表示中,建立两者的交互表示,在此基础上,利用双图卷积网络对其进一步深层表示,从而建立金融实体情感极性的判别模型。该模型总体框架包含四部分: 融入实体的句子嵌入表示、实体与句子交互表示、双图卷积网络的句子深层表示、实体情感极性预测。总体模型框架如图1所示。
3.1 融入实体的句子嵌入表示
RoBERTa-wwm-ext[6]是利用大量文本语料训练得到的一个预训练模型,可以生成序列的字向量。金融实体的专名较多,需要字向量的支持,因此,本文将金融实体情感极性识别任务的输入设计为融入实体的句子,即将句子s与给定实体a进行连接,作为RoBERTa-wwm-ext(RoBERTa)的输入“[CLS]句子[SEP]实体[SEP]”,从而分别获得句子字级嵌入表示H∈R(m+n+3)×d、实体字级嵌入表示Ha∈Rm×d和句子嵌入表示Hpool∈R1×d。其中,m和n分别是实体中字的个数和句子中字的个数。
3.2 实体与句子交互表示
为了进一步刻画实体与句子的关联关系,本文采用多头注意力机制[18]对实体字级嵌入表示和句子字级嵌入表示进行交互表示。将实体作为注意力机制Query,句子作为注意力机制Key和Value,第i个头注意力的句子表示如式(1)所示。
(1)
通过h个头注意力的句子表示Hs如式(2)所示。
Hs=MultiHead(Q,K,V)
=Concat(head1,…,headh)WO
(2)

3.3 双图卷积网络的句子嵌入表示
受文献[16]的启发,依存语法和上下文语义均有利于金融实体的情感识别,为此,本文在实体与句子的交互表示的基础上,利用SynGCN和SemGCN对句子进行深层表示。
将句子表示向量Hs∈Rn×d作为语法图和语义图的初始结点表示,将依存句法解析器[19]的所有依赖弧的概率矩阵Msyn∈Rn×n作为SynGCN中边的初始输入。将自注意机制获得句子中每个词的注意力得分矩阵Msem∈Rn×n作为SemGCN中边的初始输入,具体计算如式(3)所示。
(3)
其中,WQ∈Rd×d和WK∈Rd×d表示可学习的参数矩阵,d表示输入结点维度,自注意力头数为1。利用SynGCN和SemGCN,分别得到网络的第l层的第i个结点的隐层向量表示如式(4)、式(5)所示。

基于SynGCN和SemGCN的句子表示分别如下:

为了提升模型对实体情感极性识别的性能,本文引入了正交正则化因子和差分正则化因子。正交正则化的目的是让句子中每个词的注意力得分向量保持正交性,差分正则化的目的是学习SynGCN模块和SemGCN模块的差异特征。正交正则化因子Lort和差分正则化因子Ldif计算分别如式(6)、式(7)所示。
(6)
(7)
其中,I表示单位矩阵,下标F表示Frobenius范数。
其中,W1和W2表示可训练参数。
利用包含实体的句子表示的式(8)和式(9),可以得到实体的句法和语义深层表示分别如式(10)、式(11)所示。
3.4 实体情感极性预测

池化操作如式(12)~式(14)所示。
其中,f(·)为池化函数。
连接操作后实体特征表示x,如式(15)所示。
(15)
对于实体表示x,将其输入到线性层,再通过softmax函数获得实体x情感极性概率,计算如式(16)所示。
(16)
其中,Wp和bp表示可学习的权重和偏置。
本文所提模型的最终损失由标准交叉熵Lcro、正交正则化子Lort、差分正则化子Ldif、其他参数θ损失之和确定。
(17)
其中,λ1,λ2,λ3表示正则化系数,θ表示所有可训练模型参数,Lcro表示标准交叉熵损失,计算如式(18)所示。
(18)

4 实验
为了验证本文提出的模型对金融实体情感极性判别的有效性,神经网络模型采用PyTorch深度学习框架编写,运行环境为Python 3.6.9。
4.1 数据集与评价指标
采用第2节构建的金融领域实体情感分析数据集,评价指标为准确率(Acc)和宏平均F1值(Ma-F1)。数据集中训练集、验证集和测试集的比例为8∶1∶1,统计情况如表3所示。

表3 数据集统计
4.2 对比模型
由于实体级情感分析方法较少,为了验证本文所提出方法的有效性,选择以下与实体级情感分析相关的八种方面级情感分析方法进行对比实验。
(1)ATAE-LSTM[9]: 利用LSTM对给定的句子和方面进行编码,再利用注意力机制对LSTM隐藏层输出加权求和,获得关注方面的特征。
(2)IAN[10]: 利用LSTM对句子和方面进行编码,再利用注意力机制对它们进行交互学习,获得交互信息特征。
(3)TD-LSTM[7]: 利用两个LSTM分别对方面与其左边的句子、方面与其右边的句子进行编码,预测方面的情感极性。
(4)TC-LSTM[7]: 利用两个LSTM分别对方面与其左边的句子、方面与其右边的句子进行编码,并且拼接方面的向量表示,预测方面的情感极性。
(5)MemNet[20]: 多次利用注意力机制计算句子中每个词和方面之间的得分,获得与方面相关的特征。
(6)AOA[21]: 利用交叉注意力模块,计算句子到方面和方面到句子之间的注意力权重。
(7)BERT-SPC[22]: 将句子和方面分别输入到BERT预训练模型中,获取各自的语义表示。
(8)DualGCN[16]: 利用双图卷积网络,获得句子的句法和语义表示。
4.3 实验设置
本文模型利用RoBERTa对融合实体的句子进行编码,隐层向量维度为768,优化器采用Adam。对于ATAE-LSTM,IAN,TD-LSTM,TC-LSTM,MemNet和AOA比较模型,本文利用已经训练好的金融中文词向量[23]进行编码, 隐层向量维度为300。全部模型的实验参数设置如表4所示。

表4 参数设置
4.4 比较实验结果与分析
利用4.2节中介绍的八种比较方法与本文方法在第4.1节介绍的数据集进行对比实验,实验结果如表5所示。

表5 九种不同方法之间的比较实验结果
从表5可以看出:
(1) 本文提出的ASynSemGCN方法在Acc和Ma-F1值上均优于其他对比方法,说明本文方法对金融领域实体情感可以进行有效判别,同时也说明在金融领域中句子对判别实体情感的极性起到重要的作用。
(2) 基于RoBERTa词向量的方法与基于Word2Vec向量的方法相比,其性能更好。这是由于RoBERTa是一种动态的词向量表示方法,该方法可以动态地根据所给词上下文生成词向量,另外, RoBERTa词向量维度为768维,可以包含更丰富的语义知识,而基于Word2Vec词向量的维度仅为300维,远低于RoBERTa,而且每个词的词向量都是固定的,不能根据词的上下文来动态生成。
(3) 本文方法和DualGCN-RoBERTa方法进行对比,在Acc和Ma-F1值上分别提升了1.56和1.81个百分点,说明了实体和句子之间注意力机制有利于捕获实体和句子间的情感交互信息。此外进一步实体字级嵌入表示信息的引入,也有利于增强不同实体对其情感极性的指导作用,进而提升整体实体情感识别的性能。
4.5 消融实验
为了验证本文提出模型的各个部件的性能,本节进行消融实验。
DualGCN-RoBERTa: 在ASynSemGCN模型的基础上,去除实体和句子间注意力机制和实体字级嵌入表示。
-attention: 在ASynSemGCN模型的基础上,仅去除实体和句子间注意力机制。
-entity: 在ASynSemGCN模型的基础上,仅去除实体字级嵌入表示。
-SemGCN: 在ASynSemGCN模型的基础上,仅去除基于语义的图卷积网络。
-SynGCN: 在ASynSemGCN模型的基础上,仅去除基于语法的图卷积网络。
-mutual: 在ASynSemGCN模型的基础上,仅去除基于语法和基于语义的图卷积网络之间的交互模块。
-pooled_output: 在ASynSemGCN模型的基础上,仅去除句子的嵌入表示。
模型消融在金融领域实体情感分析数据集的实验结果如表6所示。
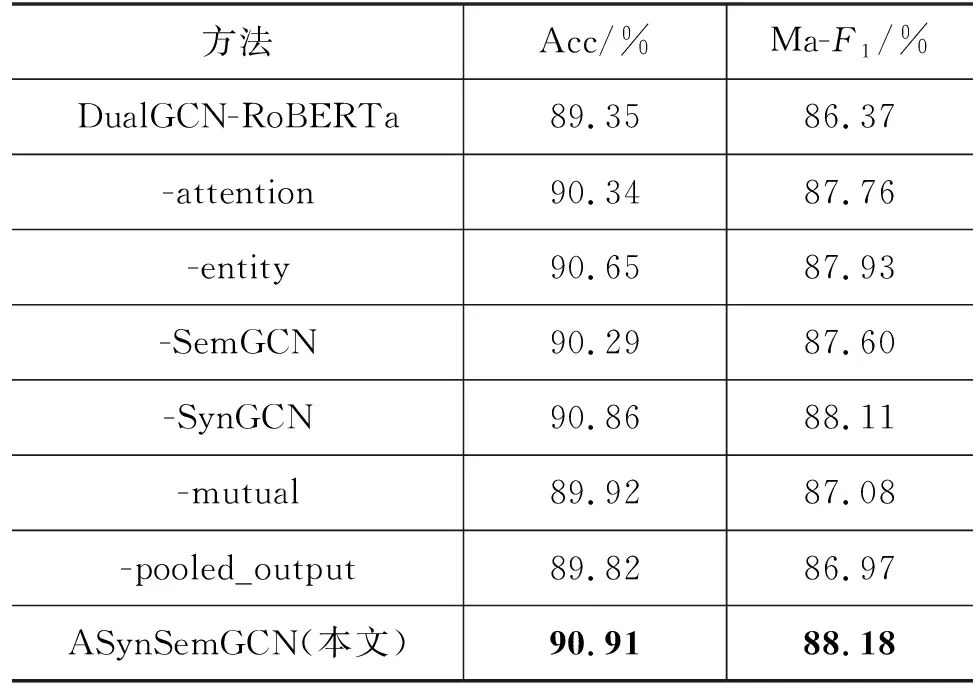
表6 模型消融实验结果
由表6实验结果可以看出:
(1) 去除任一模块,金融实体情感判别的Acc和Ma-F1指标均会下降,说明所有模块均有利于判别金融实体情感的极性。
(2) -attention方法和-entity方法,实体情感识别的Acc和Ma-F1相比本文的方法都下降了,说明交互注意力机制可以增强实体和句子间的信息交互表示,实体字级嵌入表示可以增强实体情感语义表示。
(3) -SemGCN和-SynGCN两个,相比于本文方法的实体情感识别的Acc和Ma-F1均有下降,说明SemGCN利用自注意力机制后获得了注意力矩阵,可以捕获句子中每个词的语义信息,而丰富句子的语法知识,增强实体和句子之间的关联,但是-SemGCN比-SynGCN下降更多,说明数据的语义信息比句法结构更重要,这也验证了金融数据的实体情感表达更多是隐式表述,结构性不强。
(4) -mutual方法和-pooled_output方法,相比于其他模块,它们的实体情感识别的Acc和Ma-F1下降是最为明显的,说明一方面在得到SemGCN和SynGCN表示后,对二者进行交互可以充分融合句子语法和语义的信息表示,另一方面,实体所在句子不同,对实体情感极性判别指导作用不同,引入句子嵌入表示可以进一步增强实体的情感语义表示。
4.6 注意力头数对实体情感识别的影响
为了验证实体和句子之间信息交互的注意力头数对金融实体情感极性识别的影响,本节针对不同注意力头数进行对比实验,实验结果如表7所示。
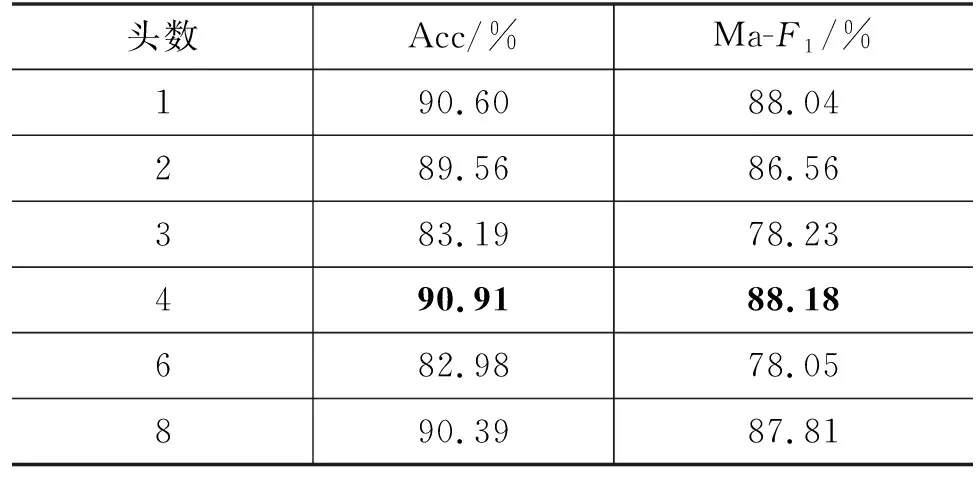
表7 不同注意力头数的实验结果比较
由表7实验结果可以看出,当注意力的头数为4时,本文提出的模型判别金融实体情感性能达到最优。当头数为3和6时,模型性能会急剧下降,说明模型的头数并不是越多越好,而是当模型性能达到较好的效果后,增加头数反而会降低模型的性能。
4.7 图卷积层数对实体情感识别的影响
为了验证不同图卷积网络层数对金融实体情感判别性能的影响,将选择层数1到层数4进行对比实验,实验结果如表8所示。

表8 不同图卷积网络层数的实验结果比较
由表8实验结果可以看出,当图卷积网络层数为3时,本文提出模型的判别金融实体情感的Acc最高,性能达到最优。相比于图卷积网络层数为4时模型,即使Ma-F1指标略微有所下降,但是模型的复杂度有较大的降低,因此,本文所有实验均采用了3层图卷积网络。
4.8 实例可视化的分析
为了探究ASynSemGCN模型中注意力机制所关注的内容,本文对句子1~3的注意力权重进行了可视化,颜色越深,代表词在句子中越重要,如表9所示。

表9 注意力机制可视化表
由表9可以看出,通过ASynSemGCN模型标注句子1的极性正确,句子2和句子3标注错误。
从可视化结果可以看出,句子1中对于“京东金融”和“钱宝网”两个实体,模型对“用户喜爱”、“网络借贷”“高返平台”“爆雷”等词汇颜色最深,因此,可以正确判断“京东金融”实体情感极性为正面,“钱宝网”实体的情感极性为负面。而句子2和句子3,针对“京东金融”和“微时贷”两个实体,模型关注句子中词汇较为均匀,没有重点强调信息,因此,错误判断情感极性为中性。说明模型在面对较短长度的金融文本时,缺乏对文本进行深入分析的能力,之后将针对这一问题尝试引入常识库来增加句子外部知识,以提高情感极性判别准确率。
5 结束语
本文构建了一个金融实体情感分析数据集,并提出了一种基于交互注意力的双图卷积网络的金融实体情感极性识别方法(ASynSemGCN)。该方法首先利用预训练模型RoBERTa-wwm-ext,结合实体对句子进行初始表示,并且利用多头注意力机制获取实体和句子之间的交互信息,提升了实体和句子之间的语义关联程度。通过基于语法的图卷积网络(SynGCN)和基于语义的图卷积网络(SemGCN)分别获得句子的句法和语义的深层表示。最后,将实体的深层表示、实体字级嵌入表示以及句子嵌入表示拼接,再通过全连接层获得最终实体的情感极性。在未来的研究工作中,我们将引入金融常识库丰富句子语义信息,进一步提升金融实体的情感极性判别的准确率。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中国外汇(2019年18期)2019-11-25 01:41:54
时代英语·高一(2019年5期)2019-09-03 02:09:34
哲学评论(2017年1期)2017-07-31 18:04:00
传媒评论(2017年3期)2017-06-13 09:18:10
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
电测与仪表(2016年11期)2016-04-11 12:20:42
电源技术(2015年5期)2015-08-22 11:18:28
