
融合词性句法位置特征的汉老双语句子相似度计算
2023-02-04 09:26:48周兰江周蕾越
中文信息学报 2023年12期
郭 雷,周兰江,周蕾越
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 昆明理工大学津桥学院 电气与信息工程学院,云南 昆明 650500)
0 引言
老挝语是老挝人民民主共和国的通用语言,谱系上属于汉藏语系壮侗语族壮傣语支,使用人口约400多万。随着时代的发展,中国与老挝等国家交流日益紧密,老挝语等低资源语言的研究显得越来越重要。汉老双语句子相似度计算可衡量汉老两个句子语义的相似程度,是汉老平行句对抽取、汉老双语机器翻译、汉老双语问答系统等研究领域的基石。传统的句子相似度计算方法有基于语义词典(《同义词词林》《知网》及WordNet等)的方法[1-3]、基于主题模型的方法[4-5]、基于句子语法结构特征的方法[6-8]等。以上这些传统的方法只能提取到句子的浅层特征,而且针对老挝语的研究缺乏句法分析、大规模语义词典等工具。基于传统向量空间模型的方法[9-11]则是用向量的形式来表征文本的特征,再通过计算向量的余弦距离、曼哈顿距离等得到句子相似度分数。这种方法表征文本特征,其向量是非常稀疏的,而且忽略了句子中词语的位置信息。随着神经网络的发展,神经网络能自动提取出特征向量表征句子语义,并得到许多学者的广泛应用[12-17]。
本文针对老挝语与汉语表达相同句子时,句子成分中名词、形容词、数词、量词等词序的差异性,构建了词性句法位置特征标签。通过构造特征词标签和特征词性标签,并给特征词性标签和普通词性赋值计算得到句子的特征标签向量,然后与句子的分布式表示拼接来减小汉老双语句子表达上的词序差异性,提高句子相似度计算正确率。为了更好地提取出句子的词序表达特征,本文采用三种不同尺寸的滤波器来提取特征,并通过线性门控单元(GLU)筛选卷积层提取的特征后,利用自注意力机制对句子中的单词赋予不同的权重。同时,通过带有自注意力机制的双向长短时记忆网络(BiLSTM)来获得句子中单词的上下文信息,然后将两个神经网络的语义特征向量进行拼接,最后计算汉老双语句子间的相似度分数。本文方法在语料稀缺的情况下取得了显著效果,F1值达到了77.19%。
本文的主要贡献如下:
(1) 根据老挝语名词、形容词、数词、量词等在句法表达上与汉语的位置差异性,提出一种构建特征词标签和特征词性标签的方法,使句子的分布式表示包含更多的语义信息。
(2) 通过添加包含常见的1 500对汉老词对的词典进行汉语和老挝语的跨语言词嵌入映射,减少因语言不同带来的词向量上的差异。
(3) 根据汉老双语的词序差异特征,本文采用含有自注意力机制的不同尺度卷积核的门控卷积神经网络,提取汉老双语句子中不同词性组合的句法位置特征,再与含有自注意力机制的双向长短时记忆网络提取的上下文语义信息特征向量拼接,并计算句子相似度分数。此方法有效提高了汉老双语句子相似度计算的准确率。
本文组织结构如下: 引言介绍本文研究对象的背景、意义、方法。第1节为相关工作,综述了目前句子相似度计算的方法与成果。第2节介绍汉语与老挝语在句子表达上的差异性。第3节介绍本文使用的模型结构。第4节介绍实验参数设置、实验效果以及与其他模型的对比实验、本文模型不同特征下的实验对比和不同卷积核尺度的实验效果对比。第5节为总结与展望。
1 相关工作
传统的同类语言文档相似度或跨语言文档相似度计算方法主要有基于语义词典的方法、基于主题模型的方法、基于句子语法结构特征的方法和基于传统的向量空间模型方法。
在基于语义词典的方法中,石杰等人[1]利用多语言版本词典WordNet,将中、泰双语文本特征词转换成英语,最后在英语版WordNet词典上计算特征词的相似度来得到文本相似度;程传鹏等人[2]利用《知网》来计算词语之间的相似度以此求得句子之间的相似度;周艳平等人[3]借助同义词词林来计算句子词形相似度以此得到句子的相似度。
在基于主题模型的方法中,程蔚等人[4]利用双语LDA模型预测新语料的主题分布,并结合主题分布使用余弦相似度计算双语文档的相似度;Preiss[5]翻译源主题模型中的每个单词并替换成目标语言的单词映射,创建目标主题语言模型来计算不同语言的相似度。
在基于句子语法结构特征的方法中,李彬等人[6]通过语义依存树计算句子中的核心关键词来计算两个句子的相似度;李茹等人[7]利用多框架语义对句子语义进行刻画,并利用框架的重要程度来计算句子间的语义相似度;黄洪等人[8]改进基于语义依存的句子相似度算法,计算两个句子中核心词、关键词和其他词的相似度分数,并精确分配其权重来计算句子的相似度。
在基于传统的向量空间模型方法中,殷耀明等人[9]分别给表达两个句子语义的关键词元组中的关键词向量赋予不同的权重,以此表达句子语义特征,计算句子的相似度;Li等人[10]利用两个句子的语义向量和词序向量分别计算语义相似度和词序相似度,最后得到两个句子的相似度;张俊飞[11]改进TF-IDF算法,结合余弦定理计算中文语句相似度。
虽然传统的句子相似度计算方法取得了不错的效果,但是对于跨语言句子相似度计算还有很多局限性。例如,基于语义词典的方法无法解决未登录词的语义问题,针对本文的研究对象老挝语,则缺乏大规模双语语义词典;基于主题模型的方法对每个词的表征不够,仅仅属于这个主题范围;基于句子语法结构特征的方法依赖于人工提取特征的效果;基于传统的向量空间模型的方法的向量维度十分小,向量表征的句子语义有限,TF-IDF模型中句子语义向量表示十分稀疏,不具有任何语义信息,也无法表达词序信息等。目前大多数学者是利用神经网络的方法提取句子语义特征向量。李晓等人[12]利用Word2Vec得到的词向量计算句子中主语成分、谓语成分、宾语成分的相似度,最后得到句子的相似度;Yin等人[13]利用CNN获取句子局部信息得到语义特征向量来计算句子的相似度;Mueller等人[14]提出并利用孪生LSTM模型获取句子中上下文的语义信息,得到语义特征向量,最后采用曼哈顿距离计算句子间的相似度分数;李霞等人[15]采用融合了自注意力机制的门控线性卷积神经网络提取句子的局部和全局语义信息,最后输入Softmax函数得到两个句子的语义相似度概率;江燕等人[16]采用CNN和BiLSTM相结合的方法获取句子语义信息,并结合门控机制给语义信息赋予不同的权重,最后通过曼哈顿距离计算两个句子的相似度分数;郭浩等人[17]采用CNN和BiLSTM相结合的方式,并结合Attention机制给语义信息赋予不同的权重,最后通过余弦相似度方法计算两个句子的相似度分数。
2 汉语-老挝语句子词序差异
在汉语和老挝语中,名词、形容词、数词、量词都是很重要的词性。名词一般充当句子的主语或者宾语,表示人或事物等实体存在的词。形容词一般修饰名词或代词,用来修饰人或事物的性质、状态、属性等。而数词常被用来表示名词和代词的数目、顺序,尤其在新闻、经济等领域,数词的作用表现得更加明显。量词一般用来修饰名词,传统的量词,如点、粒、颗、滴、条、串、堆、叠等有明显的表形作用,用来区分本质相同而外部形态有区别的事物,且使用广泛,成为句法结构中不可缺少的因素。通过汉语和老挝语对比,发现两者在形容词和名词的表达顺序上有很大的差异[18],同时量词、数词的语法规律也比较复杂,存在许多不同之处[19]。主要表现在以下几个方面:
(1) 汉语中的表达如“大苹果”“美丽的风景”“大碗米饭”,在老挝语里面的表达则是“苹果大”“风景美丽的”“米饭碗大”。与汉语常用表达不同,汉语里面形容词一般放在被修饰名词所处位置的前面,而老挝语中形容词一般放在被修饰名词所处位置的后面。
(2) 当数词是“一”时,汉语中的表达如“一本书”,在老挝语里面的表达则是“书本一”或“书一本”。与汉语常用表达不同,老挝语中的名词一般是放在量词所处位置前面,而数词“一”的位置放在量词所处位置前面或者后面都行。而当数词是“二”或“二”以上时,如汉语中表达“两个人”,在老挝语里面的表达则是“人两个”。与汉语常用表达不同,老挝语中名词一般是放在量词所处位置前面,而量词一般是在数词所处位置之后。其具体表达示例如表1所示。
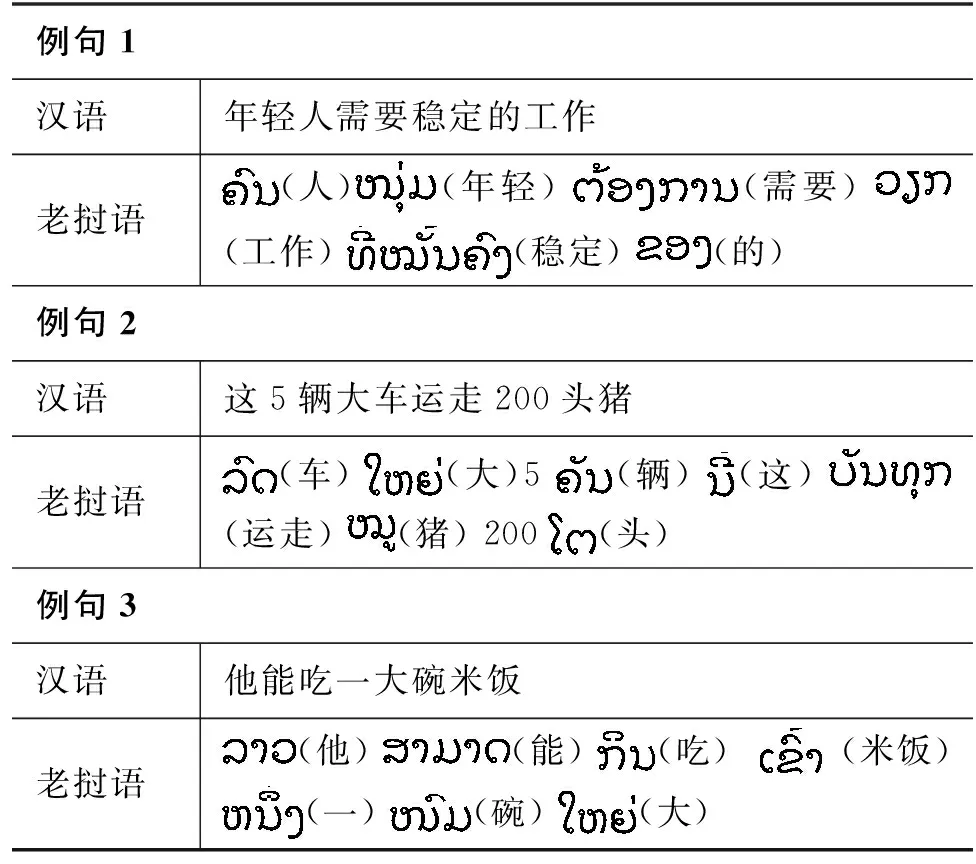
表1 汉语-老挝语句子示例
3 融合词性句法位置特征的汉老双语句子相似度计算模型
3.1 模型结构
本文首先对汉老双语平行句对进行分词和词性标注的预处理,分别得到老挝语和汉语的词性标签。其次根据汉老双语句子的词性句法位置特征构造特征词标签和特征词性标签,并给特征词性标签赋值,计算得到该句子的特征标签向量后与该句子的分布式表示进行拼接。然后将汉老双语句子分布式表示输入到均含自注意力机制的门控卷积神经网络和双向长短时记忆网络中,将提取到的特征语义向量进行融合后分别计算其相对差和相对积。最后将得到的结果拼接并输入到全连接网络层,得到汉老双语句子的相似度分数,模型结构如图1所示。
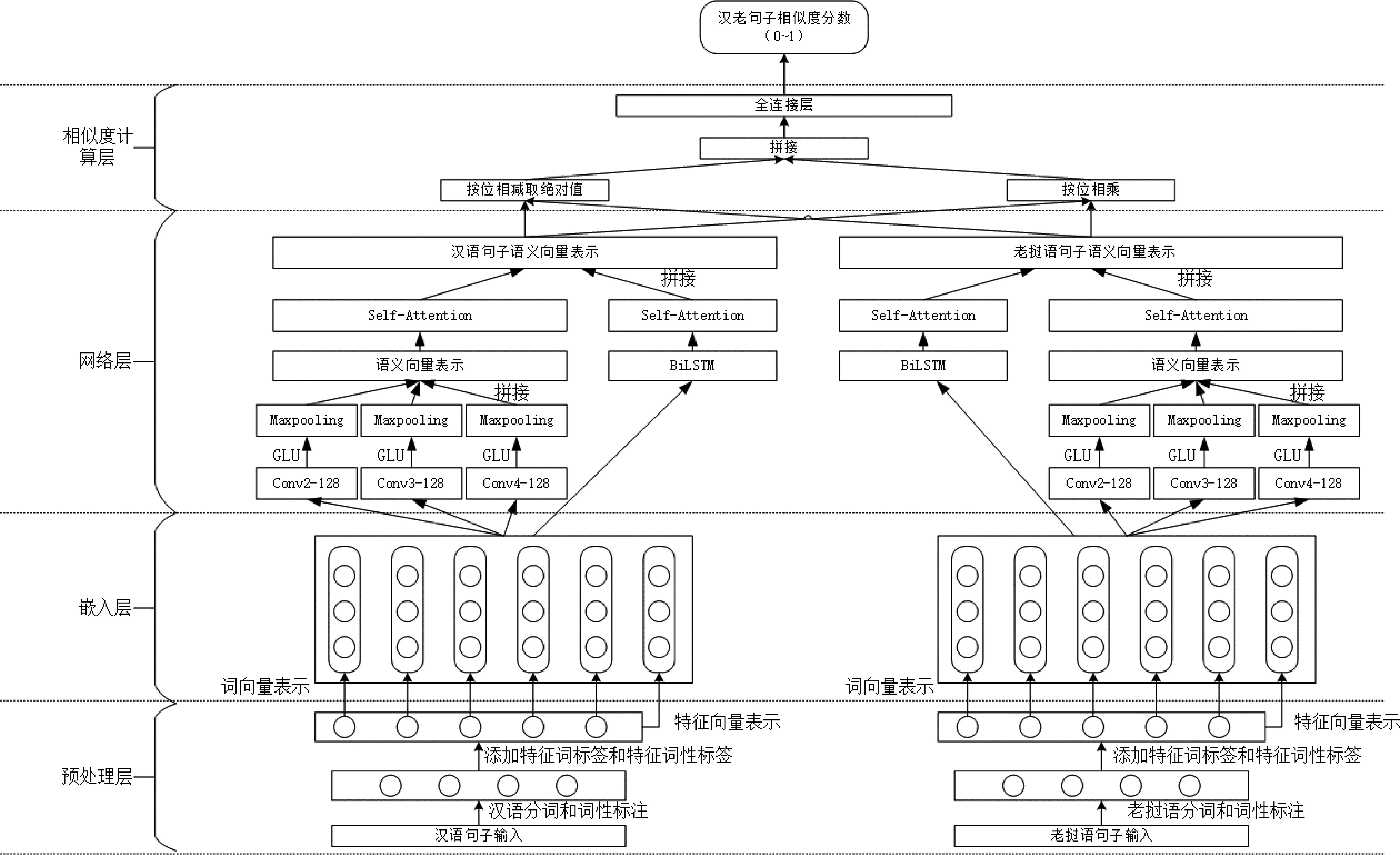
图1 融合词性句法位置特征的汉老双语句子相似度计算模型图
如图1所示,该模型框架图由以下几部分构成:
(1)预处理层: 对汉老双语句子进行分词和词性标注,根据词性句法位置添加特征词标签和特征词性标签。
(2)嵌入层: 通过嵌入层获得含有特征词标签向量和特征词性标签向量的汉老双语句子的分布式表示。
(3)网络层: 利用不同大小卷积核的CNN层获得句子的局部词性组合语义信息,然后利用GLU层和池化层对CNN提取到的信息进行筛选并拼接得到局部语义信息特征向量,最后通过自注意力机制获得句子长距离的语义信息。同时,利用BiLSTM网络层得到句子的上下文语义信息后,再通过自注意力机制对句子中的单词进行加权获得语义信息。最后将两个网络层得到的特征向量进行拼接,作为该句子最后的特征语义向量表示。
(4)相似度计算层: 将网络层得到的语义特征向量进行按位减、按位乘后,将结果拼接输入到全连接层,得到汉老双语句子相似度分数。
3.2 词性句法特征标记
通过与老挝语专家讨论和相关文献的研读,为了减小汉老双语句子表达时的词序差异,本文对汉语和老挝语的词性(名词、形容词、数词、量词等)在句子中的位置特征进行标记。老挝语利用实验室工具进行分词[20]和词性标注[21],汉语利用中国科学院研发的NLPIR工具进行分词和词性标注,得到“名词/n、形容词/a、数词/m、量词/q”等词性,并去除影响特征标记且不影响句意的助词“的/u”。具体标记样式如下:



表2 汉老词性句法位置特征标记示例
3.3 嵌入层3.3.1 基于汉老双语词典的双语词向量映射
词向量作为自然语言处理任务中的核心表征技术,其质量在很大程度上影响着下游任务的质量。虽然Conneau等人[22]和Mikolov等人[23]的研究表明,不同语言在词向量表征上有相似之处,但本文为了得到高质量的汉老双语词向量,采用与Artetxe[24]相同的方法,预先训练好汉语词嵌入矩阵X和含有特征标签词的老挝语词嵌入矩阵Z,利用只需要少量人工标注数据(种子词典)的半监督跨语言词向量模型训练得到高质量的跨语言词向量。
本文使用1 500对汉老常见单词的种子词典D,在汉老双语字典条目Dij=1(第i个汉语言单词和第j个老挝语单词对齐)的情况下,通过式(1)利用SVD方法求解得到最优映射矩阵W*,使得映射汉语词嵌入矩阵Xi*W和老挝语词嵌入矩阵Zj*之间的平方欧几里得距离之和最小。得到最优映射矩阵以后,将汉语词嵌入矩阵X和老挝语词嵌入矩阵Z通过式(2)和式(3)映射到共享语义空间中。
3.3.2 汉老双语特征标签向量表示
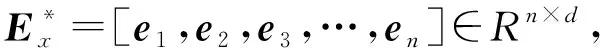
ei+1×1+…+en×0
(4)

3.4 网络层
通过嵌入层获得汉老双语句子的分布式表示后,将其输入到网络层以获得包含更多信息的语义特征向量。模型的网络层由含有自注意力机制的门控卷积神经网络和双向长短时记忆神经网络构成。
3.4.1 门控卷积神经网络(GCN)
门控卷积神经网络是Dauphin等人[25]在2016年提出来的,使用CNN卷积网络层和门控线性单元(Gated Linear Units,GLU)组成的网络结构,门控卷积神经网络的结构如图2所示。
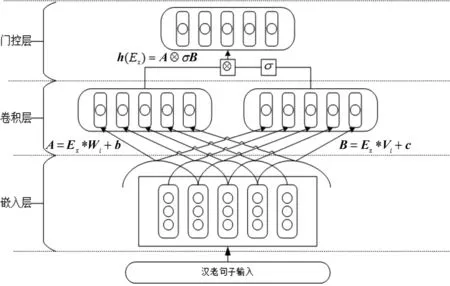
图2 门控卷积神经网络的结构
门控卷积的计算如式(5)~式(7)所示,一个普通卷积的计算结果和一个Sigmoid函数运算的卷积结果点乘。
A=Ex*Wi+b
(5)
B=Ex*Vi+c
(6)
h(Ex)=A⊗σB
(7)
其中,Ex为句子Sx的分布式表示,有两组参数矩阵W={W1,W2,W3,…,Wm/2}和V={V1,V2,V3,…,Vm/2}也就是使用的卷积核,m是卷积核个数,Wi,Vi∈Rk×d,b,c∈Rd是参数矩阵,其中,k是卷积核的大小,d是词向量维度,*表示滑动卷积。在式(5)和式(6)中,Ex经过m个卷积核后得到数量各为m/2的特征图A和特征图B,卷积核之间的训练参数不共享。通过式(7)(门控线性单元(GLU))筛选卷积层特征得到最后的语义特征矩阵h,σ是Sigmoid函数,⊗是矩阵间的元素点积。最后池化层对线性门控卷积计算得到的特征矩阵h进行采样,得到新的特征矩阵H。特征矩阵H保留主要特征,减小了模型参数,增加了模型的的泛化能力。为了纵向提取句子的局部语义信息,采用不同尺度大小的卷积核,将3个不同大小卷积核窗口的输出结果经过GLU和池化层提取特征后,将其拼接得到句子Sx的语义向量表示Vx=[H1⊕H2⊕H3],⊕表示向量拼接。本文将GCN网络层得到的汉老双语句子向量分别表示为VC_GCN和VL_GCN。
3.4.2 双向长短时记忆网络(BiLSTM)
长短时记忆网络(LSTM)是RNN的衍生网络,针对梯度消失和梯度爆炸问题,在RNN的基础上加入门控机制。但是LSTM模型无法编码从后到前的信息,本文采用前向的LSTM与后向的LSTM结合成BiLSTM的方法来提取文本特征。其结构如图3所示。
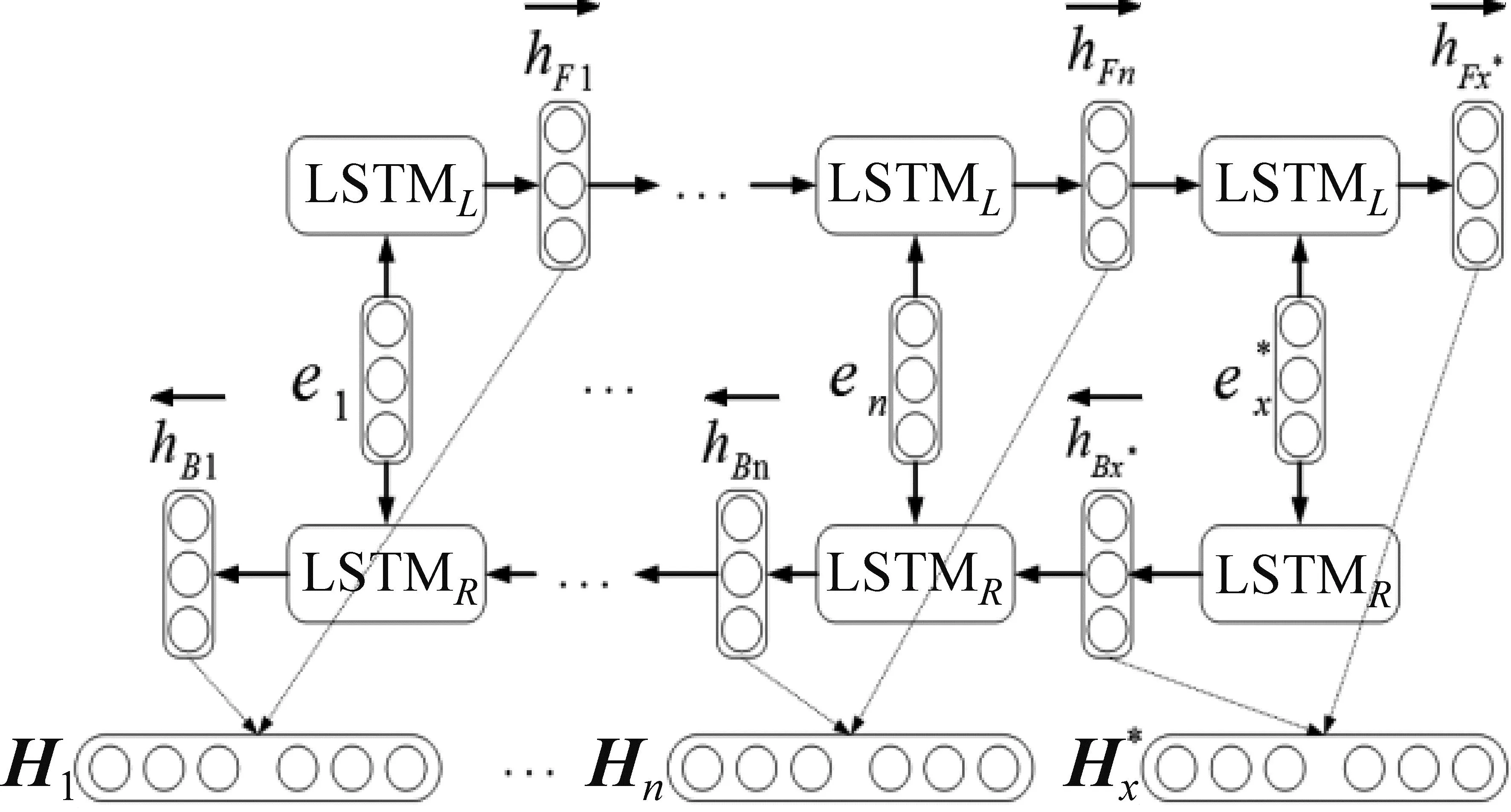
图3 BiLSTM结构示意图

3.4.3 自注意力(Self-Attention)层
在句子中,不同的单词对整个句子的语义贡献不同,使用自注意力(Self-Attention)机制来给每个单词分配权重,以此得到句子的全局信息。句子Sx在经过BiLSTM和GCN网络层输出的句子语义特征向量Hx、Vx,再通过式(8)~式(10)对句子Sx中不同单词赋予不同的权重,最终得到该句子新的语义特征向量Z。
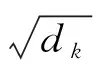
本文将汉语和老挝语句子经过GCN网络层和BiLSTM得到的输出状态向量VC_GCN、VL_GCN和HC_Bi、HL_Bi分别输入到自注意力层,得到含有各单词权重信息的汉老双语句子特征语义向量,分别表示为ZC_GCN、ZL-GCN和ZC_Bi、ZL_Bi,然后对此输出进行拼接,得到汉老双语句子的最终语义特征向量SC=[ZC_GCN⊕ZC_Bi]、SL=[ZL_GCN⊕ZL_Bi]。
3.5 相似度计算层
通过网络层获取到汉老双语句子最终语义表示SC、SL后,类似于Shao[26]的工作,对其执行按位减操作(取绝对值)和按位乘操作,然后将其结果进行拼接获得两个句子的语义相似度的表示。计算如式(11)所示。
P1=(|SC⊖SL|)⊕(SC⊗SL)
(11)
其中,⊖表示汉老元素对应相减,⊗表示汉老元素对应相乘,⊕表示将结果进行拼接。
最后将汉、老句子的语义相似度的表示输入全连接层进行计算,得到汉老句子的相似度分数。其计算如式(12)、式(13)所示。
其中,W1、W2和b、c均为模型参数,P为模型最后输出的相似度分数,其输出值在0~1之间。
4 实验及分析
4.1 实验数据
本文使用的数据集分为两部分。第一部分用于预训练双语词向量的数据集: 汉语部分采用Li等人[27]已经预训练好的词向量(1.68 GB),老挝语部分通过老挝语维基百科爬取的150.4 MB单语语料训练得到。在分别得到汉老单语词向量的基础上,采用与Artetxe等人相同的方法,加入汉老词语在计数单位、月份等方面表达差异性较大的1 500单词对作为种子词典,并利用半监督跨语言词向量模型训练得到高质量的汉语词向量和老挝语词向量。第二部分数据为模型训练数据集: 在老挝语维基百科和中文维基百科爬取的篇章级对齐语料上,经过老挝语留学生人工对齐和校对后得到95 100条平行句对。本文以每个平行句对的负样本数为7的比例来构建非平行语料库,最终得到665 800条非平行句对,如表3所示。
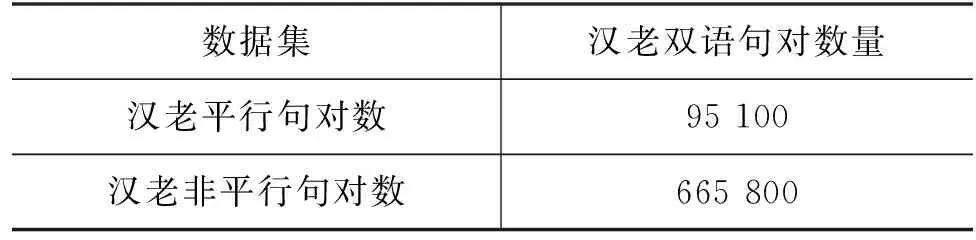
表3 汉老双语句对数据集
将数据集按照9∶1进行训练集和测试集的划分。本文实验在固定随机种子数下使用10折交叉验证,轮流将训练集中9份作为训练数据、1份作为验证数据进行实验,取10次实验结果的均值。每次训练使用的数据集划分如表4所示。

表4 训练模型数据集划分结果
4.2 实验参数设置
模型实现使用Python语言及Keras框架。实验中每个句子的长度设定为25,在线性门控卷积神经网络中,使用不同尺寸的卷积核来提取文本特征,其卷积核大小为2、3、4,卷积核长度为词向量维度300,卷积核个数各128个。经过门控线性层和池化层的特征提取后将其输出拼接,为了防止过拟合,加入dropout,参数值设为0.2。BiLSTM的隐节点数量设置为64。采用Adam算法对模型进行优化,学习率设为0.01。Batch size的大小设置为1 024,Epoch为50。实验采用交叉熵作为损失函数,如式(14)所示。
Loss(pi,yi)=
(14)
其中,pi为模型预测的分值,yi为人工评定的分值,N为样本的个数。
4.3 评价指标
本文对实验结果评测采用常用的评价指标精确率P(Precision)、召回率R(Recall)和F1值。将汉、老平行句对的标签设置为1,将汉、老非平行句对的标签设置为0。本文采用数值0.5作为汉老句子相似度分数的判别阈值,当汉老句子的相似度分数大于数值0.5时,即将其分为相似句子对。准确率、召回率和F1值计算如式(15)~式(17)所示。
4.4 模型对比实验
本文使用均含有自注意力机制的门控卷积神经网络和双向长短时记忆网络的模型框架来分别提取汉老句子特征,将两个网络层提取到的特征进行融合,在此基础上融合本文提出的词性句法位置特征来提高模型的准确率。为了探索本文方法的有效性,设置了以下几个对比实验:
(1) 将门控线性卷积网络(GCN)和双向长时期记忆网络(BiLSTM)组合的模型作为本文的基准模型(Base Model)。
(2) 将自注意力机制加入模型验证其有效性。
(3) 加入特征词标签(A-TAG、B-TAG)和特征词性标签向量(为了表达方便,本文将其记作“V-TAG”)的模型,即本文方法(Ours)。
为了验证本文方法的有效性,本文与目前主流的计算跨语言句子(文本)相似度的计算模型做了对比: 分别为Yin等人[13]提出的将CNN用来提取句子特征,并将特征用来计算文本相似度;Mueller等人[14]提出的Siamese LSTM模型来提取句子的深层语义特征,通过比较两个句子向量间的曼哈顿距离来计算两个句子的相似度;郭浩等人[17]提出的CNN+BiLSTM+Self-Attention模型,分别利用CNN和BiLSTM网络层提取的句子结构特征来计算文本的相似度;李霞等人[15]提出的CNN+GLU+Self-Attention模型利用卷积提取的局部特征和自注意力机制提取的全局特征来计算跨语言句子的相似度。以上7个模型均在同一语料下采用10折交叉验证法进行实验。最终实验结果如表5所示。

表5 不同模型实验结果 (单位: %)
由表中结果可知,模型(1)为本文的基准模型,模型(2)加入了自注意力机制,其F1值提高了2.74%。说明自注意力机制给句子中的单词加以不同的权重以区分句子中每个单词的重要性的方法使模型学到了更多的语义信息。模型(3)加入了词性句法位置特征标签,其F1值在此基础上又提高了2.56%。这是因为汉老双语在名词、形容词、量词、数词语序表达上有较大的差异,通过词性句法位置特征标注后求得句子的特征标注词向量,将其拼接在汉老句子的分布式表示的最后,使得模型能学到更加丰富的语义信息。
另一方面,在与前人的模型实验对比上面,通过模型(2)与模型(6)比较,模型(2)的F1值提高了1.09%。此结果表明门控线性单元(GLU)对卷积神经网络(CNN)提取到的特征进行了有效的筛选,更好地捕获了句子的局部语义信息。通过模型(2)与模型(4)、模型(5)、模型(7)的比较,本文提出的模型方法效果最好。因为本文模型结合了门控卷积神经网络(GCN)和双向长短时记忆网络(BiLSTM)的优势,并融合自注意力机制,使得网络提取到的汉老双语句子语义特征向量含有更加丰富的语义信息。
4.5 特征词和词性标签添加对比
汉老句子在名词+形容词、名词+量词+形容词、数词+量词+名词等词性组合下存在表达的差异。为了提高句子相似度计算的准确性,本文给句子中的词性组合后面添加特征词标签(A-TAG、B-TAG)、句末添加特征词性标签向量(V-TAG)来丰富句子的语义信息。以下是添加不同特征词标签和是否添加特征词性标签向量的对比实验,其结果如表6所示。
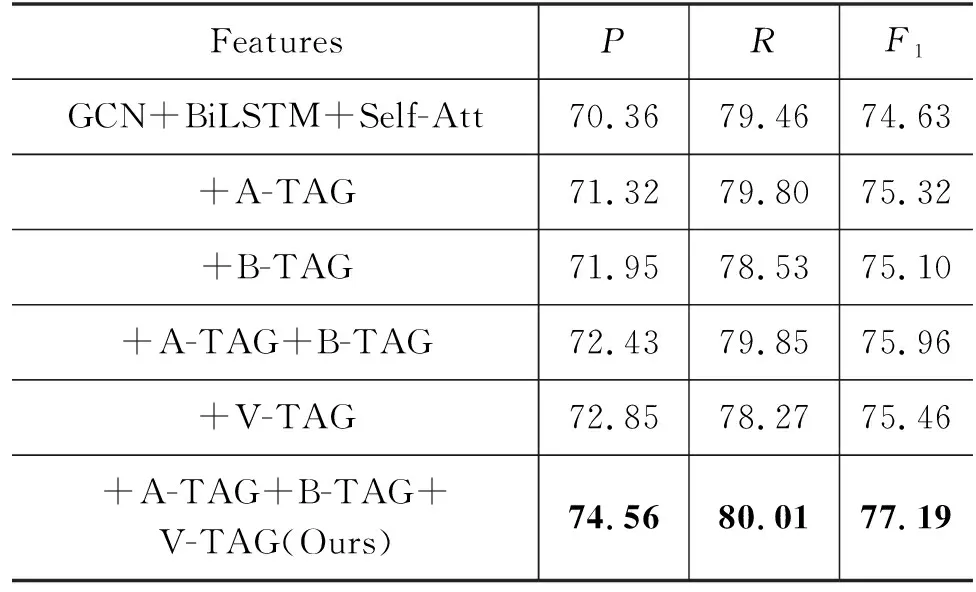
表6 不同特征对比实验 (单位: %)
由以上实验可知,加入特征词标签(A-TAG、B-TAG)和特征词性标签向量(V-TAG)对实验效果有较大的提升。其中加入特征词标签(A-TAG)的F1值提升了0.69%,对比加入特征词标签(B-TAG)的F1值提升的0.47%效果要好,是因为汉老双语句子中的形容词+名词或形容词+量词+名词的词性组合较多,能提供的语义信息更多,模型学习效果更好。在句末添加特征词性标签向量(V-TAG)的方式相比于不加特征的实验效果,其F1值提升了0.83%。相比于单独添加特征词标签的实验效果要好,是因为此方法更精确地表达了汉老句子中的词性组合。将这两种融合特征的方式加入实验中,其F1值提高了2.55%,对实验效果提升明显。
4.6 不同卷积核大小对比
汉老句子在名词+形容词、名词+量词+形容词、数词+量词+名词等词性组合下存在表达的差异。为了提高句子相似度计算的准确性,依据不同词性组合中词的数量,本文使用卷积核大小为2、3、4,卷积核长度为词向量维度的三种不同尺度的卷积核来提取句子中词性组合特征向量,以减少汉老双语句子词序表达的差异性。在本文模型下,不同尺度的卷积核对汉老双语句子相似度计算的实验结果如表7所示。
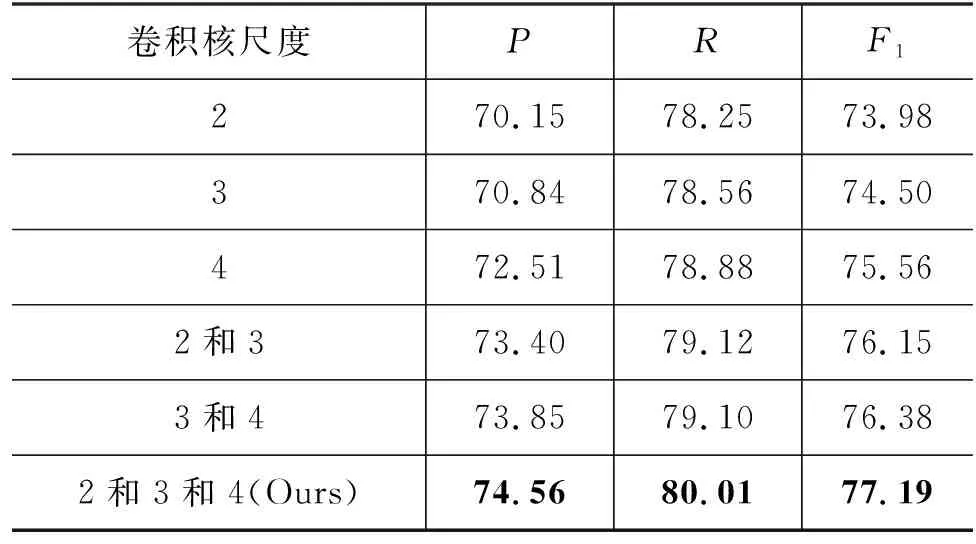
表7 不同尺度卷积核大小实验 (单位: %)
从以上实验可知,不同的卷积核尺度大小对实验结果有影响。根据老挝语和汉语的表达特征,当卷积核尺度为2时,能提取到名词+形容词词性组合特征向量;当卷积核尺度为3时,能提取到名词+形容词+特征词标签(A-TAG)、名词+量词+形容词、数词+量词+名词的词性组合特征向量;当卷积核尺度为4时,能提取到名词+量词+形容词+特征词标签(A-TAG)、数词+量词+名词+特征词标签(B-TAG)的特征向量。通过实验可知,卷积核尺度为4的实验效果最好,是因为融入了较多特征词标签而增加了向量的语义信息,而且几乎将汉老句子中全部词序差异的特征都提取出来了。由实验可知,当三个不同尺度的卷积核同时使用时效果最好,能分别提取句子在纵向词语上的词序信息,相比于单个尺度的卷积核,效果分别提升了3.20%、2.68%、1.62%。
5 结论
本文针对汉语和老挝语中名词、形容词、量词、数词等词性在句子语序表达上的差异,为了提高句子相似度计算的准确性,提出了融合词性句法位置特征的汉老双语句子相似度计算的模型。通过此差异性构造了特征词标签和特征词性标签,以此降低汉老句子分布式表示的差异性。在此基础上,分别使用均含有自注意力机制的门控卷积神经网络和双向长短时记忆网络来提取句子的词性位置特征向量、上下文语义特征向量和全局语义特征向量。最后将经过网络层得到的汉老句子语义特征向量进行按位乘和按位减的操作,并将结果拼接输入到全连接层得到句子语义相似度概率分值。与目前主流方法相比,本文提出的方法实验效果更好,取得了77.19%的F1值。下一步考虑利用该方法做汉老双语问答系统的研究。
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
现代语文(2016年21期)2016-05-25 13:13:44
公民与法治(2016年10期)2016-05-17 04:12:58
计算机工程(2015年8期)2015-07-03 12:20:27
大连民族大学学报(2015年2期)2015-02-27 08:28:11
新晨(2013年7期)2014-09-29 06:19:50
新晨(2013年5期)2014-09-29 06:19:50
新晨(2013年10期)2014-09-29 02:50:54
