
融合双语命名实体信息的神经机器翻译模型
2023-02-04 09:26:42贺楚祎张家俊
中文信息学报 2023年12期
贺楚祎,张家俊
(1. 中国科学院 自动化研究所 模式识别国家重点实验室,北京 100190;2. 中国科学院大学,北京 100049)
0 引言
可控翻译[1]是在翻译模型预测过程中添加预先指定的约束单词和短语,从而获得包含约束词汇的翻译结果。它在领域机器翻译、交互式机器翻译等应用中具有重要意义。可控翻译中使用的词典可以是从领域词典中抽取的术语[2],也可以是用户在修正交互式机器翻译系统的翻译结果时所给定[3]。在基于短语的统计机器翻译中[4],可控翻译的思想比较容易实现,然而在神经机器翻译(Neural Machine Translation,NMT)中[5],可控翻译的任务相对难以完成,因为在模型训练过程中难以显式引入额外的词汇约束信息。
一些工作探索了神经机器翻译中的可控翻译方法,这些方法可以分为两类: 硬可控方法和软可控方法。硬可控方法尽可能使给定的约束词汇出现在翻译结果中,这些工作通过设计新的解码算法来实现,而对模型或训练过程不做修改,例如,Hokamp等人[6]提出网格柱搜索(Grid Beam Search,GBS)算法用于模型推理解码阶段,Post等人[7]提出了动态柱分配(Dynamic Beam Allocation,DBA)算法对GBS算法进行加速优化。然而,与传统的柱搜索算法相比,这种解码算法的计算复杂度要高出很多。软可控方法则不能确保所有约束都出现在翻译结果中,这类方法通常修改NMT模型的训练过程来进行可控翻译。Li等人[8]在模型训练过程中用占位符标签替换源端和目标端命名实体,模型通过学习翻译这些占位符来学习翻译约束词汇;Song等人[9]和Dinu等人[10]提出了用数据增强方法来训练NMT模型,这些方法通过用约束替换相应的源端词汇或在相应的源端词汇后附加约束来构建源端训练语料,尽管在训练数据中引入了双语词典信息,但模型无法有效区分文本和约束。
此外,在这两类方法中,双语词典在训练或推理阶段都是必不可少的,因此,其性能在很大程度上取决于双语词典的质量,但对于命名实体而言,类似的双语词典构建工作尚不完善。本文首先提出一种基于多引擎融合的双语命名实体词典构建方法,构建出高质量大规模的双语命名实体词典,为可控翻译提供可靠的外部数据支撑,接着使用数据增强方法在训练数据中显式引入目标端命名实体,并基于Transformer架构,修改嵌入层以适应训练数据变化、引入指针网络来训练模型在合适的时机对源端句子中的目标端词元进行直接复制,从而完成可控翻译的目标。
本文的主要贡献如下:
(1) 提出了一种双语命名实体词典构建方法,该方法通过将源语言命名实体输入多个在线翻译系统得到候选翻译,并使用最小贝叶斯风险决策方法对多个候选翻译进行筛选,获得最优目标端翻译,从而构建大规模、高质量的双语命名实体词典。
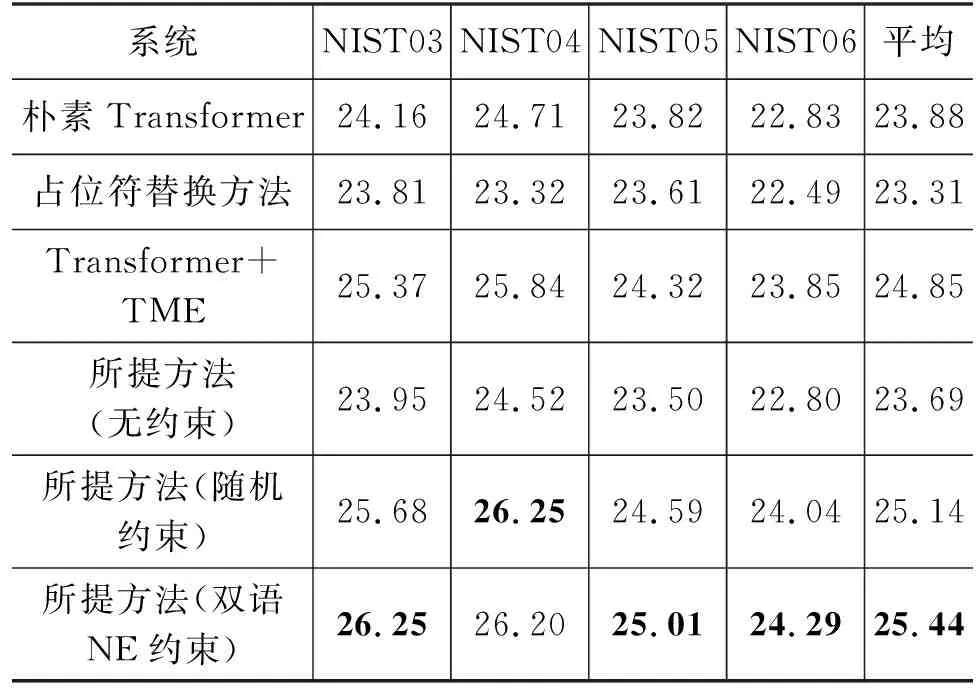
(2) 提出了一种在训练过程中引入词典约束的Transformer模型,该模型能够通过双语命名实体词典,在源端训练数据中引入命名实体约束,使模型生成的翻译结果尽可能包含约束,从而达到翻译可控。通过在NIST中-英测试集上的实验得出,该模型在译文整体翻译质量和命名实体翻译准确率上相比其他NMT中可控翻译相关工作都取得了显著提升,且模型解码速度尚在可接受范围。
1 相关工作
硬可控翻译方法主要修改模型解码过程,在解码过程中尽最大可能保证约束出现在翻译结果中。Hokamp等人[6]提出了GBS算法,在模型解码过程中采用复杂动态规划方法,使得翻译结果一定是满足所有约束的结果。Post等人[7]在GBS算法的基础上进行优化,提出了DBA算法,通过将假设与将相同数量的约束分配到组中,并在每个时间步动态地在这些组中划分固定大小的波束,解决了GBS算法每个句子所占用波束不固定的问题,将解码算法的时间复杂度降低为原来的1/C(C为约束数目)。这类方法的问题是它们不考虑译文的整体置信度,在解码过程中强制生成约束。此外,这类方法对于约束的顺序有着严格要求,这对于语法差异较大的两种语言的翻译任务可能存在负面影响。另一个问题是与柱搜索相比,这类方法的解码速度显著降低。
软可控方法一般从数据或模型入手改变模型的训练流程。Li等人[8]在模型训练过程中用占位符标签替换源端和目标端命名实体,将模型学习命名实体翻译转化为学习翻译占位符,在推理阶段同样将源端与目标端命名实体替换为占位符,待模型翻译完成后再用双语命名实体词典进行恢复。Song等人[9]提出了一种数据增强方法,通过双语词典将相应的源端词汇替换为目标端约束,构建增强后的训练语料,这样模型在训练过程中可以学习到选择源端词汇或是目标端约束词汇作为当前时间步预测的结果。Dinu等人[10]提出了类似方法来翻译给定的术语约束,用双语词典中相应的目标端术语直接替换源端术语,或是将目标端术语添加在源端术语之后。排除序列长度改变所带来的影响,软可控方法相比于硬可控方法基本不影响模型解码速度,但模型在翻译过程中无法获得源端词汇和目标端约束之间的对应关系,因此会出现约束词汇重复翻译或漏翻译的情况。Alkhouli等人[11]研究了Transformer中使用源端-目标端注意力进行词对齐的质量,并提出通过注入外部对齐信号来提高对齐精度。他们没有使用所有源端词元的注意力权重来计算源端上下文,而是添加了一个特殊的注意力头,其源端上下文仅根据外部词对齐信息在对齐的源端词元上计算。为了在解码过程中提供对齐信号,一个单独的“自注意力对齐模型”被训练来学习源端对齐,同样来自相同的外部词对齐信息。然而,使用单独的对齐模型在很大程度上增加了解码复杂性,需要特殊处理以优化速度。此外,训练和解码中使用的对齐质量之间的差异会对模型性能产生负面影响。Zenkel等人[12]提出在 Transformer 架构中添加一个单独的对齐层,并学习将注意力权重集中在给定目标词的相关源端词元上,以无监督的方式从双语数据中获取,而不使用外部词对齐信息,从注意力层学习到的词对齐比从朴素Transformer 模型中学习到的更加准确。
本文提出的可控翻译方法相比于上述方法可以在训练过程中有效利用双语词典信息,该方法对Transformer模型的源端训练数据及输入表示层进行了增强,并在Transformer模型的解码器中引入指针网络来增加约束词汇的复制概率,大大提高了模型使用外部约束的能力,从而大幅提升命名实体翻译质量。
2 基于在线翻译引擎的双语命名实体词典构建方法
本文主要聚焦于常见命名实体类别,包括人名、地名和组织机构名的翻译。双语命名实体是指属于不同语言并具有互译关系的命名实体对。本文提出的模型引入外部双语命名实体信息,通过可控翻译方法来提升神经翻译模型对于命名实体的翻译能力,因此,双语命名实体的质量对模型的性能起着至关重要的作用。然而,在目前的相关工作中,双语命名实体词典虽然被广泛应用,但大多工作对其构建并没有引起重视,相关工作中对于双语命名实体词典的构建方法都较为粗糙。此外,本文对于双语命名实体词典构建的相关工作进行了调研与实验,并在此基础上提出了一种融合在线翻译引擎的构建方法,相比之前的工作能够构建更高质量的双语命名实体词典。
2.1 方法
在线翻译引擎对于命名实体的翻译通常有特殊的处理方式,不同的在线翻译引擎可能采用了不同的命名实体翻译方法,因此本文希望综合利用多个在线翻译引擎的优势。例如,对于中-英翻译,可以将中文命名实体送入在线翻译引擎,获得英文翻译结果。当同时爬取到多个在线翻译系统的翻译结果时,使用最小贝叶斯风险决策方法从中选取出最佳翻译候选,如式(1)所示。
(1)
其中,S为源语言命名实体,T为目标语言命名实体,L为风险函数。
P(T|S)是给定源语言命名实体S,目标语言命名实体T的条件概率,当存在多个翻译候选时,P(T|S)可以由式(2)计算得出:
(2)
其中,P(T,S)是源语言命名实体S与翻译候选T的联合概率分布,若为统计机器翻译系统,该概率分布可以根据各个统计机器翻译系统对翻译候选T的总打分近似计算得出,但由于我们的翻译系统都是在线翻译系统,因而我们可以假设条件概率近似服从于均匀分布,即P(T|S)~U(0,1)。L(T,T′)为风险函数,在一般机器翻译系统中,常使用BLEU值作为机器翻译译文评价指标,因而风险函数的定义如式(3)所示。
LTER(T,T′)=1+TER(T,T′)
(3)
TER(Translation Edit Rate)[13]度量的是将候选译文修改为参考译文所需要的编辑次数。尽管TER作为风险函数较为简单,但李等人[14]的研究表明,该指标在机器翻译系统融合领域中能够取得不错的效果,计算也较为简单,因而本文在风险函数中采用这一指标。
2.2 实验结果与分析
本文构建了一个双语命名实体测试集用于测试本文方法的效果,并与其他构建方法进行对比。本文从LDC中-英平行语料中抽取人名、地名和组织机构名三类中文命名实体,按照词频每类抽取词频较高(>1000)和较低(<100)的命名实体各400对,每类再加上200对LDC平行语料不包含的命名实体构成测试集。
本文爬取了Google翻译、百度翻译、有道翻译和Bing翻译四个在线翻译系统,并用2.1节中介绍的最小贝叶斯风险解码方法进行最佳翻译候选获取,结果如表1所示。

表1 最小贝叶斯风险解码方法的效果 (单位: %)
从实验结果可以看出,最小贝叶斯风险决策方法能够整合不同在线翻译系统的优势,从而筛选出最优的翻译候选,提升命名实体翻译质量。
作为对比,介绍两个相关工作:
(1) 基于词对齐的抽取方法。词对齐是自然语言处理领域中的经典任务,能够找出平行句对中词的对应关系,Chen等人[15]利用基于词对齐和命名实体识别(Named Entity Recognition,NER)的多特征交互模型从双语平行语料中进行双语命名实体的大规模对齐。
(2) 基于跨语言词向量的方法。Harris等人[16]认为,具有相同上下文的词汇可能词意相近,因此,我们可以通过跨语言词向量来寻找双语语料中的相似上下文。跨语言词向量是指一个向量空间,这个向量空间能够表示不同语言的词汇信息,因此可以用于计算不同语言之间的上下文或词汇去相似性。Conneau等人[17]提出了通过跨语言词向量构建双语词典的方法,这一方法同样可以用于双语命名实体词典的获取: 对于每个平行句对,首先对源语言句子和目标语言句子分别做NER,得到双语命名实体,用跨语言词向量编码双边命名实体的向量表示,对于每个源语言命名实体,都计算它与每个目标端命名实体的上下文相似度,将最相似的作为其对应的目标端命名实体。
本文使用NIST03中-英测试集对三种方法进行测试。由于命名实体的抽取率主要与NER模型的性能相关,因而本文仅评估翻译准确率。由于一个源语言命名实体可能存在多个正确翻译,如“北京”译为“Beijing”或“Peking”都是正确翻译,因而本文采用人工评估的方式对词典准确率进行评估。结果如表2所示。
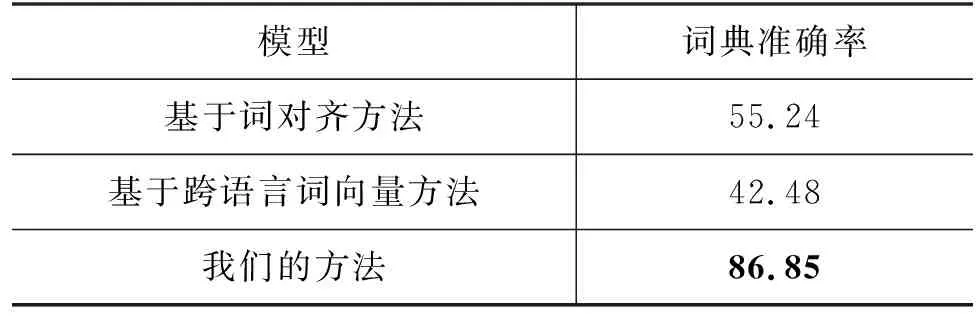
表2 三种构建方法准确率对比 (单位: %)
从实验结果看出,本文方法的命名实体翻译准确率远超这两类方法,并且由于算法简单,耗时较短,因此适用于构建双语命名实体词典。同时,本文方法也存在着一定的不足,例如,双语命名实体词典中仍会存在翻译错误,这些错误会传播到后续的翻译流程中,给正确翻译命名实体带来一定困难。
3 模型
本文在Transformer模型的基础上进行改进,Transformer模型由Vaswani等人在2017年提出[18],是一个使用了多头自注意力机制的编-解码网络,编码器和解码器均是由六个相同的子层堆叠而成,相比于之前的端到端序列模型,Transformer使用了多头自注意力机制用于加速计算并能有效缓解长距离依赖下梯度消失的问题。
3.1 源端训练数据添加约束词汇
给定一个由源语言句子X,目标语言句子Y以及约束词汇的集合C,模型的训练损失可以定义如式(4)所示。
L=∑log(Y|X′,C;θ)
(4)
其中,X′=[X,C]为约束增强后的源语言句子,它是通过将源语言句子X和该句子约束集合C中每个约束Ci用分隔符号拼接而成的:
约束词汇可以在训练过程中随机选取,也可以用第2节所构建的双语命名实体词典进行动态添加,具体内容将在4.2节中进行阐述。
3.2 输入表示层增强
由于在源端训练数据中加入了目标端词汇,因此本文共享了源语言和目标语言词表,并共享源端和目标端的词汇嵌入层(Word Embedding)参数,以强化模型对于双语的表示能力,使得模型更容易将源端句子中的约束词汇复制到翻译结果中。同时,为了让模型适应增强后的数据,本文参考了BERT模型[19]的结构来修改编码器的表示层。
在编码器的嵌入层网络中增加段嵌入(Segment Embedding)部分,与BERT模型相同,段嵌入将文本部分与约束部分用不同的位置下标进行标识,让模型的表示层获得文本与约束的分块信息,使我们的模型像BERT模型一样能够处理分段输入信息。
3.3 加强模型复制约束词汇的能力
参考Gulcehre等人[20]将指针网络用于稀有词与未登录词预测方面的工作,本文在Transformer解码器中引入了指针网络。指针网络能让每个指针对应输入序列的一个元素,从而能够通过模型之外的一些计算,例如通过Transformer中的编码-解码器注意力得分对输入序列的每个词汇直接进行权重分配,产生一个新的概率分布,这一概率分布通常被称为复制概率Pcopy,代表模型直接复制源端词汇作为目标端输出的概率分布。这与我们的想法不谋而合: 在源端训练数据中加入了目标端约束词汇,希望模型能够在合适的时机从源端句子中直接复制约束词汇作为输出,达到可控翻译的目的。
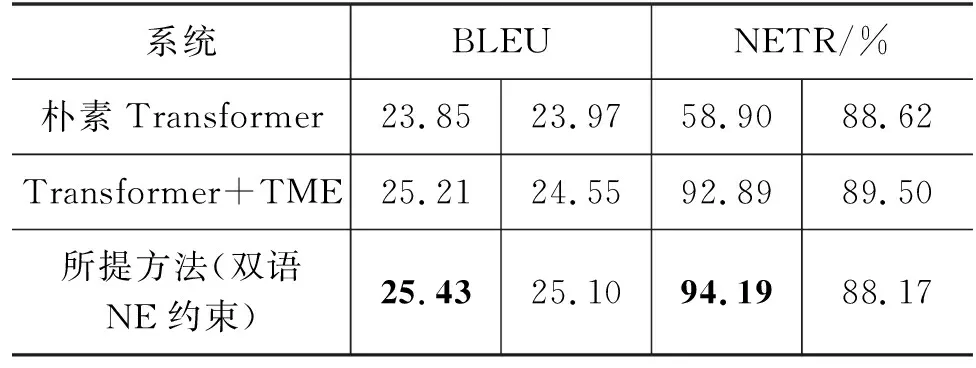
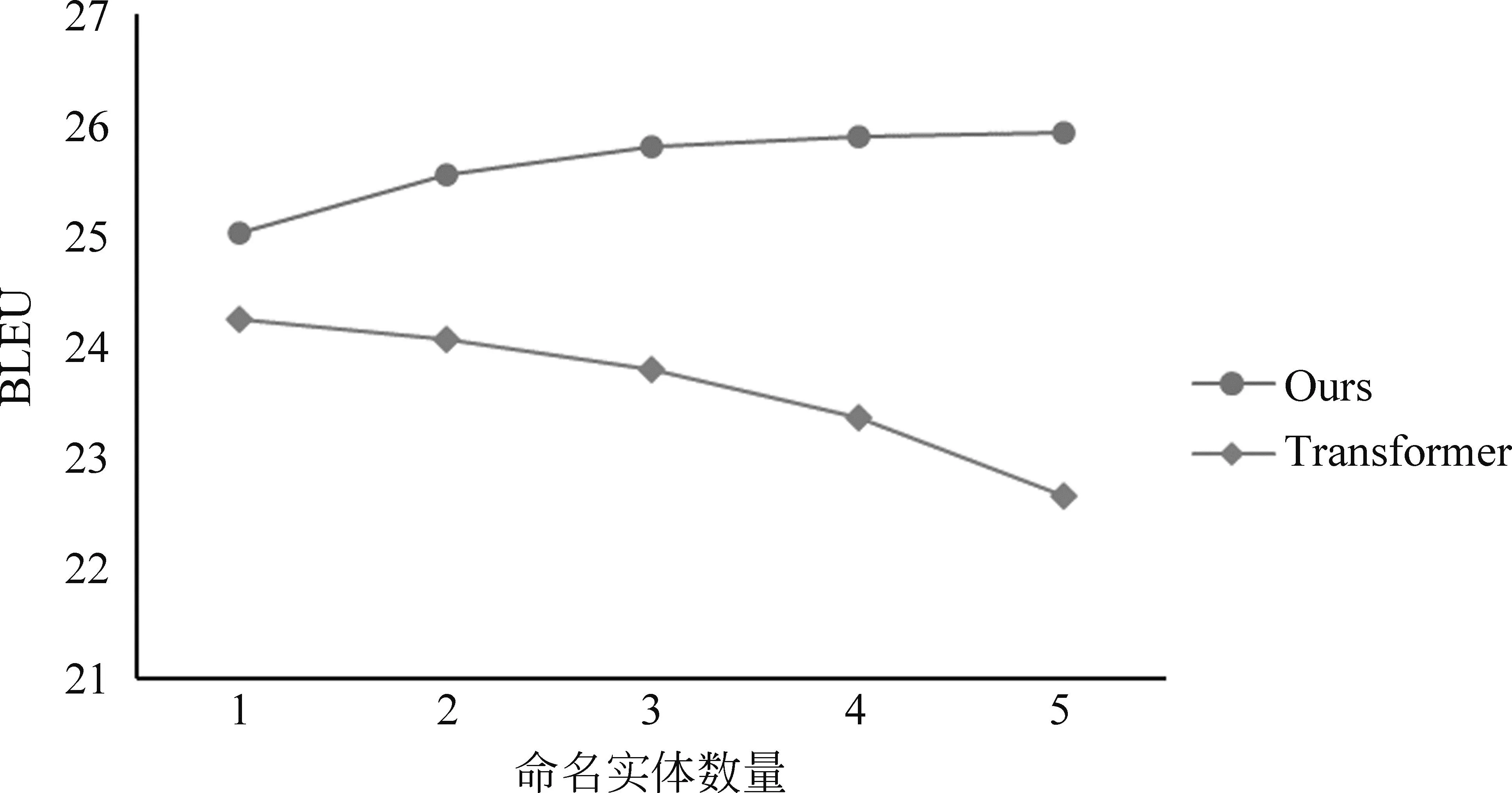
具体来说,在任意解码时间t,模型对于当前目标端词汇的预测概率分布为P(yt|X′,y P(yt|X′,y (5) 模型预测概率分布Ppredict由模型解码器输出进行Softmax运算后得到;复制概率Pcopy由解码器最后一层的多头编码-解码器注意力(Multi-head Attention)均值作为权重得到。 对于输出词表中的每一个词汇,如果目标端词汇y在源端句子中(即y为设置的约束),则其对应的复制概率值Pcopy(y)为y在最后一层解码器的编码-解码器注意力henc中对应位置的得分;反之如果y没有在源端句子中出现,则将复制概率Pcopy(y)设置为0。结合Pcopy与Ppredict,就得到了模型新的输出词表概率分布如式(6)、式(7)所示。 其中,gt∈[0,1]是控制两部分概率权重的门控信号,由上下文向量ct和最后一层解码器输出的隐层状态zt计算得到,其中上下文向量ct又由编码-解码器注意力和编码器输出隐状态计算得到: 其中,hn是编码器输出在位置n的隐状态,αt,n是t时刻位置n最后一层解码器的编码-解码器注意力得分,N是源端句子的长度。gt由一个简单的前馈神经网络(Feed Forward Network,FFN)计算得到,其中,Wc,Wz,bg都是可训练的参数,σ为sigmoid函数。gt的计算方式参考了传统注意力分数,本文认为,其意义可以概括为:gt可以度量模型在时间步t的注意力更倾向于复制源端词汇,或是预测目标端词汇,以此来选择复制约束词汇的合适时机。模型整体架构如图1所示。 图1 模型整体架构 本节将详细阐述模型训练的实验数据,实验设置,并从译文整体质量、命名实体翻译质量以及模型解码速度对模型性能进行评估和分析。 我们从LDC中-英平行语料中抽取了约200万句对的平行数据对模型进行训练,并使用NIST02-06中-英测试集进行模型性能的测试。NIST测试集中有四个参考译文,考虑到不同参考译文给出的命名实体翻译可能存在差异,我们不在一次测试中使用所有的参考译文,而是对四个参考译文分别测试后取平均值。中、英文句子均使用Mosesdecoder进行预处理和子词分割,并共同学习大小为32K的联合词表。 为了进行对比和验证模型的效果,我们选取了一些相关工作中的方法作为基线模型: (1) 基于占位符替换的数据增强方法[8]。该方法将源端与目标端训练数据中的命名实体替换为一一对应的特殊符号,对模型进行训练。测试阶段同样将源语言测试集中的命名实体替换,并输入模型翻译,得到翻译结果后再将特殊符号还原为目标语言命名实体。 (2) Wang等人提出的Transformer + TME方法[21]。该方法对Transformer进行了三处修改,一是Tagging,在源端训练数据中用分隔符将命名实体区分出来;二是Mixed,即混合源端与目标端命名实体,将目标端命名实体直接拼接在源端命名实体之后;三是Extra Embedding,即加入额外的嵌入层向量,与我们的方法类似,在嵌入层中加入一个区分普通词汇与命名实体的向量表示,从而使模型能够从源端训练数据中区分出命名实体,为了方便起见,我们将该方法的三个改进简写为“TME”。 同时,为了验证双语命名实体词典在模型训练中的必要性,我们还对比了不添加约束和随机选取约束进行训练的情况。随机选取约束的方式为: 首先随机生成一个约束数目k(本文中设置为0~4),k服从[0.3,0.2,0.3,0.1,0.1]的概率分布。之后对训练集中的每个平行句对,我们在训练过程中都采取动态约束选取,并在选取过程中从候选项排除高频词与停用词。在测试阶段,我们统一使用双语命名实体词典对测试集进行约束。 超参数设置方面,由于设置了源端最大输入长度为1 024,因此我们将最大约束数量设置为50,避免过长句的出现;同时使用Adam优化器和标签平滑(Label Smoothing)进行训练,学习率l=0.000 5,warmup步数取4 000,所有网络层的Dropout参数都设为0.3,最大更新步数设定为20万步。 该部分从BLEU值[22]、命名实体翻译准确率(Named Entity Translate Rate,NETR)和解码速度(token/s)三个指标分别对比了我们的方法和4.2节中提到的方法。NETR是命名实体翻译准确率指标,其计算方法是每个测试集中被正确翻译的不重复命名实体占所有命名实体的比例。 BLEU值评估结果和NETR评估结果如表3、表4所示。 表3 BLEU值结果对比 表4 NETR结果对比 (单位: %) 可以看出,占位符替换方法虽然在NETR上相比Transformer模型有所提升,但BLEU值评估表明,该方法会损害整体译文质量。Wang等人提出的方法相比朴素Transformer在两个指标上都有显著的提升,在四个测试集上分别平均提升0.97的BLEU值和32.3个百分点的NETR。而本文方法在BLEU和NETR上都超越了所有基线模型,相比基线模型在四个测试集上平均提升了1.56的BLEU值和35.3个百分点的NETR,同时,在训练中使用双语命名实体词典进行约束的方法比随机选取约束的方法提升了0.3的BLEU值和4.5个百分点的NETR,这也证实了双语命名实体词典在模型训练中的有效性。此外,在训练时不添加约束的情况下,本文模型依然能够保持与Transformer相比的性能。 我们还对比了在基线模型和本文方法中额外加入约束解码方法DBA时[7]的效果。该方法通过在模型预测阶段使用双语命名实体词典对模型进行约束,采取复杂动态规划的方法改变束搜索的解码过程,来确定模型当前预测的词汇,以满足约束条件。由于这一方法只对模型的解码策略进行了调整,因此与模型结构上的改进可以共同使用,对比结果如表5所示,左右栏数据依次为添加DBA前后模型的效果。 表5 添加DBA算法前后模型表现对比 从表5中的结果可以得出,对于命名实体翻译能力较弱的朴素Transformer来说,DBA算法的引入对命名实体翻译能力的提升相当显著,但在BLEU指标上的提升不明显,对于Wang等人的方法和本文所提方法来说,DBA解码策略对两个指标都没有带来正向提升,且模型性能与朴素Transformer接近,这可能是由于解码策略所生成译文的优先级较高,因而我们认为DBA解码策略在一定程度上是与模型结构的改进策略冲突的。 表6给出了不同方法的平均训练时长与解码速度,所有测试均在NVIDIA TITAN X单卡GPU上进行。训练时长方面,所有结果均为获得最佳模型所需的训练时间,对于占位符替换方法,由于将所有命名实体替换为特殊符号,模型解码器的计算量有所下降,可能加快了训练速度。对于Wang等人的方法和本文所提方法,尽管增加了额外的训练数据长度与网络结构,但这两种模型达到收敛所需的训练轮数相比朴素Transformer也有所降低,因而训练时长并未增加。 表6 模型训练时长与解码速度对比 解码速度方面,本文方法相比基线模型的解码速度稍慢,原因可能是引入的约束词汇增加了输入文本的长度,以及引入段嵌入部分使得模型的参数量增加,导致了解码速度的降低,但考虑到模型整体性能的提升,与朴素Transformer同一数量级的计算开销是可以接受的。此外,在引入DBA解码策略的情况下,我们与Wang等人的方法解码速度都出现大幅降低,这可以归因于DBA解码策略的算法复杂度较高,以及算法并行化较为困难。 因此,上述实验表明,DBA解码策略对于命名实体翻译能力较强的模型效果并没有明显提升,反而会影响模型解码速度。 4.4.1 消融实验 在消融实验中,我们在NIST02中-英测试集上依次测试了不加任何优化,增加数据增强方法(+Data Augment),增加嵌入层优化(+Embedding Improvement),增加指针网络(+Pointer Network)情况下模型的性能,结果如表7所示。 表7 消融实验 从实验结果可以看出,只增加数据增强方法虽然让模型能够一定程度上学习复制源端训练数据中的约束词汇,但对于整体译文质量是有所损害的;嵌入层部分的改进为模型带来了译文质量的整体提升;而指针网络在小幅提升整体译文质量的同时,也大幅提升了实体命中率,这与我们的预期相符: 三个部分的改进是相互促进的,当三者结合在一起时,模型获得了最佳性能。 4.4.2 实例分析 表8给出了两个用Transformer模型和我们的模型将相同中文句子翻译成英文的实例,可以看到,在这两个实例中,Transformer模型对于命名实体分别存在错翻和漏翻现象。在实例1中,Transformer模型对于地名“宁边”翻译错误,原因可能是该实体在训练数据中出现频率较低,从而模型将其错译成“南宁”的英文“nanning”,而我们的模型在成功翻译“宁边”的情况下,也将其他一些Transformer模型未成功翻译的词汇进行了正确翻译。在第二个实例中,Transformer模型漏翻了命名实体“时事通信社”,漏翻在机器翻译中也是常见现象,大多出现在有低频词或复杂语法的句子中,这种情况往往如实例2一样,会导致整个句子漏翻。而在我们的模型中,不仅“时事通信社”翻译正确,被Transformer模型漏翻的句子也完整地得到翻译。 表8 实例分析 4.4.3 约束数量对模型性能的影响 图2与图3对比了Transformer模型与本文模型在NIST中-英测试集上翻译不同数量命名实体句子的性能表现。从图2可以看出,在BLEU值指标上,本文模型性能会随着句子中命名实体数量的增加而不断提升(提升幅度越来越小),而Transformer模型的BLEU值会随着命名实体数量的增加而缓慢下降,这是因为本文模型对于大部分命名实体都能正确翻译而Transformer模型却不能;从图3可以看出,本文模型在不同数量命名实体的句子上都显著优于Transformer基线模型。不过,我们也观察到本文的方法对于命名实体的翻译准确率随着句子中命名实体的数量增加出现小幅降低,我们猜测这种现象与本文使用的软约束模型有关,后续将进行更加深入的分析。 图2 BLEU值与句子中NE数量的关系 图3 NETR与句子中NE数量的关系 本文主要完成了两部分工作: 一是通过最小贝叶斯风险决策方法融合多个在线翻译引擎,从而构建了高质量的双语命名实体词典辅助后续的文本翻译。二是在可控翻译的方法创新上,改进了一种数据增强方法,引入了双语命名实体词典;在Transformer模型结构中改进了编码器嵌入层,使之更适用于新的输入数据;引入了指针网络,使得模型可以高效利用双语命名实体词典带来的额外信息。三者结合使得网络可以有效实现可控翻译的目标,根据在NIST中-英测试集上的实验表明,本文模型在译文质量和实体命中率两个指标上相比基线模型性能有着显著提升。同时,本文方法在领域翻译的相关工作中也有一定的实用性,因为该方法不仅可以用于命名实体,也可以用于任意领域的域内词汇和专业术语。 在未来的工作中,将这一方法用于其他任务例如领域机器翻译和交互式机器翻译是我们工作的重点,我们相信这一方法在这些任务中同样能够取得很好的效果。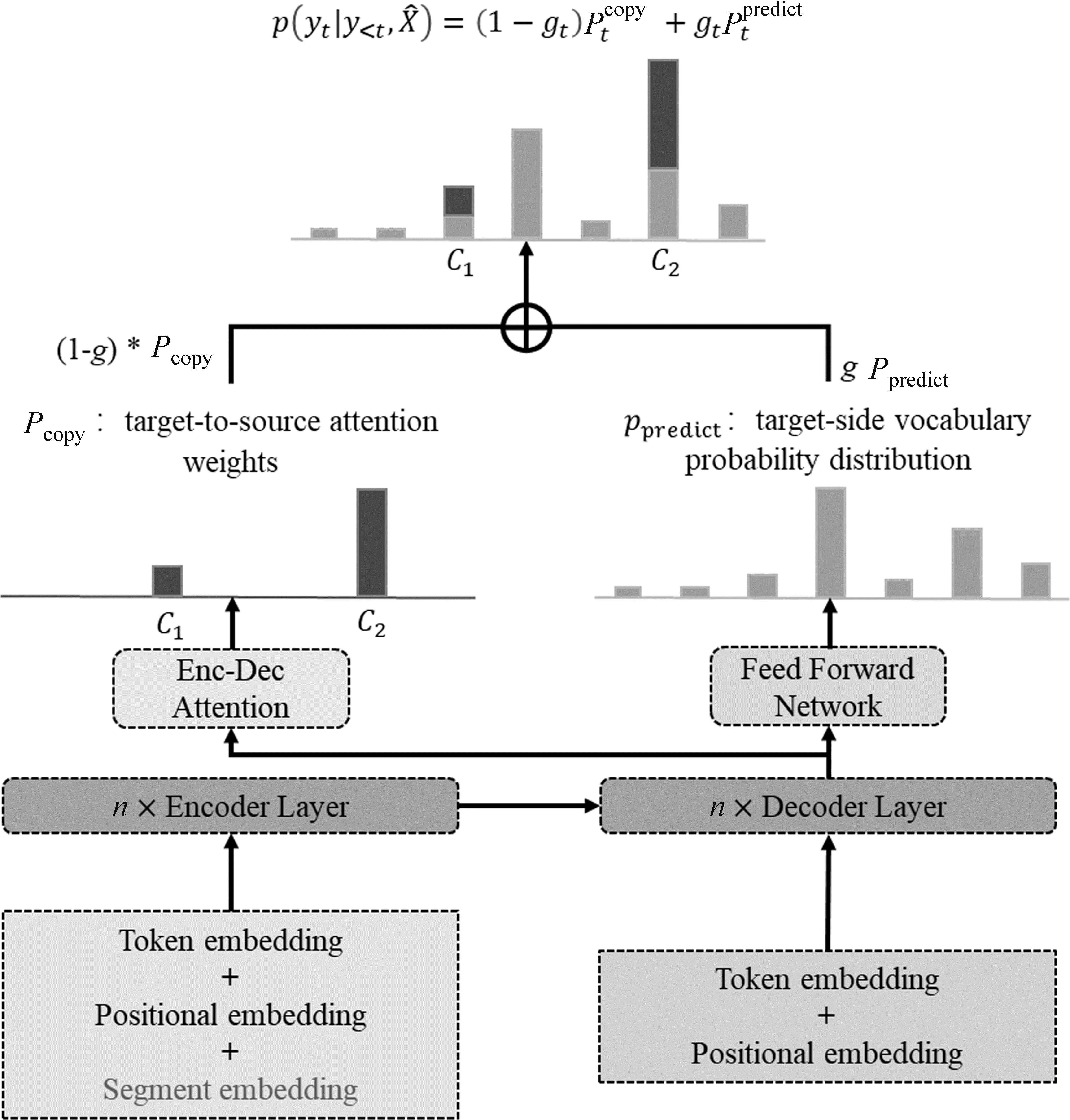
4 实验与分析
4.1 实验数据
4.2 实验设置
4.3 实验结果


4.4 实验分析



5 总结与展望
猜你喜欢
中国石油石化(2022年12期)2022-07-16 08:28:28中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46中国外汇(2019年19期)2019-11-26 00:57:32中文信息学报(2019年8期)2019-09-05 12:33:36数码世界(2019年4期)2019-05-10 09:52:54家庭影院技术(2018年11期)2019-01-21 02:20:50家庭影院技术(2018年11期)2019-01-21 02:20:48东方女性(2018年3期)2018-04-16 15:30:02散文诗(2017年17期)2018-01-31 02:34:08科技视界(2016年22期)2016-10-18 15:53:02
