
基于元学习的财务舞弊识别研究①
2023-02-03 05:38张学勇
管理科学学报 2023年10期
张学勇, 施 懿
(1. 中央财经大学金融学院, 北京 100081; 2. 微众银行, 深圳 518063)
0 引 言
财务舞弊一直困扰着资本市场建设并愈发成为一个严重的问题[1-3],也引起了学术界的重视[4].过去经验表明上市公司财务舞弊对投资者乃至整个资本市场带来了严重的负面影响.Beasley等[5]统计发现,在初次被爆财务造假的公司在事后股价平均下跌16.7%,并且有47%的财务造假公司退市.另外,美国历史上十大破产案中有四起也与重大财务欺诈相关[6].财务舞弊不仅摧毁了投资者对于财务报表质量的信任,而且还严重扰乱了资本市场的正常运转.因此,如何提高预测上市公司财务舞弊效率,这一命题在当前环境下的重要性也愈发凸显出来.
近年来,中国财务舞弊事件无论从发生频率还是涉及金额都呈现上涨趋势,愈发成为投资者、审计师、监管方所担忧的问题.尽管财务舞弊识别需要具备丰富的经验知识以及依赖外部审计给予客观的审计意见,但从过去曝光的案例来看,传统财务舞弊识别手段由于依靠人工、效率较低,并不能较好地适应当前财务舞弊识别的需求[3],在中国也是如此.
首先,舞弊手段逐渐变得繁复,造假模式呈现系统性、链条化,同时涉及利润表、资产负债表、现金流量表.如新绿股份,通过伪造银行收款、虚构资金流以支撑虚增收入,再将虚增货币资金转移至在建工程、固定资产,因为固定资产折旧期限较长,折旧费用远小于虚增收入,从而使其完成对赌目标.其次,新型金融工具、跨境业务等新形式杂糅于传统公司经营,使财务舞弊更具有隐蔽性.例如,广东榕泰利用虚构保理业务虚增利润,宜华生活虚构境外回款虚构海外业务等.最后,从财务舞弊披露时点来看,财务舞弊处罚具有延迟性.根据国泰安数据统计,2006年~2018年上市公司财务舞弊处罚案例中,延迟1年~4年占所有案例64.15%,17.18%的公司延迟了5年及以上才被披露其舞弊行为,财务舞弊识别的不及时,也放大了财务舞弊的恶性影响.因此,如何提高预测上市公司财务舞弊效率,及时捕捉隐藏的财务造假信息,是解决以上问题的关键.
从过去的研究来看,大部分研究都是从财务舞弊识别因子和舞弊识别方法两个角度出发构建财务舞弊识别模型,试图以模型判断来代替人工识别.从财务舞弊识别因子构建角度,除了传统财务指标外,研究还囊括了公司治理和文本挖掘两方面的指标,公司治理维度包括高管人员背景特征、董事会特征、股权结构等[7, 8],文本挖掘维度包括财务报表附注和管理层讨论与分析(MD&A)、业绩说明会等文本的分析等[1, 9-11].但较少有学者关注如何将财务因子、公司治理因子以及语言因子进行结合,从而提升财务舞弊识别的准确率[3].从舞弊识别方法角度,近年来随着计算机技术的提高以及机器学习模型的研究方法不断深入,财务舞弊识别的准确率也将逐步提高.但目前财务舞弊识别样本存在数据不平衡的问题,一些学者仍采用1∶1或者固定舞弊与非舞弊样本进行模型训练,不符合真实应用场景.并且目前选取模型的方法主要通过后验结果导向选取,而不同时期可能适用于不同的模型[12],这种主观后验选取的方法不能适应新的数据特征分布.
因此,如何提升财务舞弊识别效率并同时适应不同的数据分布特征是本文的研究目标,而本研究也将运用前沿的机器学习算法与元学习框架,将文本词性分析与金融市场相结合,探索机器学习与大数据工具在金融领域的应用.本研究创新在于:1)结合财务因子、公司治理因子、语言因子,丰富了我国财务舞弊识别的因子库,也为财务报表文本分析应用提供了新的实证支持;2)套用元学习框架,提供了一套完整的提高财务舞弊识别准确率的方法,包括解决数据不平衡问题、因子筛选、模型调参以及模型预测,为提升财务舞弊识别预测准确率提供了可实行的客观方案.
本研究模型具体流程如图1所示.

图1 模型流程图
1 文献综述
上市公司财务舞弊的识别不仅是投资者、审计师、监管方所担忧的问题,也是当前资本市场和国内外学术界关注的热点问题之一.
传统财务识别模型基于财务舞弊动因理论而发展起来,其中应用最为广泛的是舞弊三角理论和GONE理论.舞弊三角理论将动机或压力、机会、态度或借口作为识别舞弊的重要条件,其中,实施舞弊的动机或压力是舞弊发生的首要条件.GONE理论由Bologna等[13]提出,认为企业舞弊行为由G(greed)、O(opportunity)、N(need)、E(exposure)四个影响因素驱动导致,之后他们在此基础上不断归纳,最终形成舞弊风险因子理论.
美国注册会计师协会分别在1988年、1997年、2002年发布了审计准则(SAS),明确规定了审计师审查财务舞弊的规范,因此,也开始有学者基于SAS所提及的风险因子构建了财务舞弊识别模型.一方面,一些学者采用问卷、清单的形式获得SAS准则中提及的一些风险因子[14],但这些因子的可靠性无法确认[15].另一方面,SAS几乎没有提供如何利用风险信号或者风险因子来进行判断,因此审计师还需要其他辅助工具进行判断,因此,整个审计流程是非定量且非自动化的[16].
还有一些学者用公开财务数据对财务舞弊风险进行建模.国外较早的系统性识别财务舞弊模型是M-score模型,通过财务指标利用历史数据构建线性方程[17].之后在该基础上丰富了财务舞弊风险因子构成了F-score模型[18],其中F-score预测准确率已达69%.但这些模型仅涉及财务因子,事实证明公司治理、文本因子等非财务因子对于财务舞弊识别也有一定帮助[3, 19-21],并且随着财务舞弊风险因子增多、模型维数上升,大量噪音、不相关的、冗余特征充斥在数据中[22],模型估计准确度也随之下降.
随着机器学习算法研究的深入和方法论的丰富,一些学者将机器学习算法应用到财务舞弊识别中[23],并且相较于传统财务识别模型有着明显的优势.首先,机器学习擅长挖掘数据之间的非线性特征[24],并且准确率得到提升.传统M-score、F-score模型仅能证明财务因子对于识别财务舞弊具有一定的解释力,而缺乏实际证据支持其预测准确效果.而已有学者证明,机器学习准确率基本在80%以上[3,4].并且,这些不同算法中包含的激活函数、核函数形式都丰富了拟合函数以便适应预测目标的复杂性.
其次,机器学习可以采用集成模式而非单一模型.传统模型通常采用单个模型进行预测,而机器学习不仅算法多样化,而且同一算法中根据不同的参数组合训练出的模型也具有多样性.对于基础机器学习算法的优化也可以通过结合模型或者挑选适合的模型来提高预测模型的准确度[25,26].集成学习的思路是通过合并多个弱学习器,提升机器学习性能以获得更好的预测结果.集成学习分类三类:一是用于减少偏差的boosting,二是用于减少方差的bagging,三是用于提升预测结果的stacking.元学习是属于stacking,从机器学习或者数据挖掘中得到数据,用于提升预测结果的质量.通常,机器学习多种算法提供了解决问题的一系列方法,但是并没有给出明确的答案,在给定背景下哪些算法更适合使用,元学习则提供了一种方式能够学习到在学习过程中哪一种算法和潜在特征能够被更有效的运用[12,27],以解决复杂而又动态的财务舞弊识别问题,并且随着时间推移而增强学习能力[28].
第三,机器学习算法为如何解决数据不平衡问题提供了客观方案.传统模型一般采用匹配样本进行解决,但匹配近似样本的标准较为主观,并且数据样本与真实世界不符[29].已有学者采用过采样的方式,或者欠采样生成多个子数据集,分别训练不同的模型,再将模型进行集成输出[30],这样的好处是利用现有全部数据,并且避免主观挑选匹配样本,导致训练样本与实际样本分布偏差过大,避免出现过拟合的情况.
另外,除了财务舞弊模型方法改进之外,非金融变量也开始进入学术界的视野.公司治理层面因子也有助于量化财务舞弊机会,包括高管层持股情况、高管个人背景、股权结构等[4].另外,文本分析生成的语言类因子也成为学术界金融相关研究的新工具.Humpherys等[31]通过词汇多样性和句法复杂性等语言因子应用于财务舞弊识别获得了接近70%的预测准确率.Goel和Uzuner[21]则发现财务造假的公司会同时更多的使用积极和消极的词汇,而不是采用中性词.Dong等[10]将文本因子分类为主体、观点、情感、情态、人称代词、写作风格、题材七个类型,发现加入语言因子的模型平均准确率高达82.36%,显著优于仅采用财务比率的基准方法.Hajek和Henriques[3]则得出使用否定词较少的公司存在欺诈行为的可能性较低的结论.这也说明了数据挖掘新因子对于识别财务舞弊的重要性.近年来,中国学者也开始使用文本分析挖掘不同信息,已有证据表明,中国上市公司年报存在语调管理行为[32],管理层报告提及的对业绩产生负面影响的内部和外部因素越多,亏损扭转的可能性越小[33],管理层业绩说明会上答非所问程度越高,公司业绩则会越差[11].但文本分析在财务舞弊识别的问题中的应用仍相对较缺乏.
基于以上文献梳理,本研究主要贡献在于:1)探索了文本分析在中国财务舞弊识别方面的应用,构建了包含财务、公司治理、语言因子库,扩充了财务舞弊识别因子类型; 2)区别于仅选用一种算法的预测方式,本研究尝试了集成学习方法在财务舞弊识别的应用,有效提高了财务舞弊识别的准确性; 3)相较于前人匹配近似样本时主观选取指标、或主观选取算法池的方式,本研究套用元学习框架,利用机器学习算法,降低了财务舞弊识别中人工干预的程度.
2 模型流程
本研究采用的基学习器包括决策树、梯度提升树(GBDT)、K近邻算法、Logistic回归、朴素贝叶斯算法、随机森林算法、支持向量机、极限梯度提升树(XGBoost)、神经网络(Neural Network).本研究主要用年报数据与季度报告数据作为基学习器的数据源,基学习器输出的预测值作为下一层堆叠分类器的输入源,即从底层数据输入、基学习器训练,再到堆叠训练整个过程称为元学习.
2.1 数据处理
本研究先对全部因子作为全部解释变量进行模型训练,以不同学习器在测试集表现的多数投票结果作为基准.其次,用信息增益率(IGR)作为因子筛选顺序的依据,依次去除信息增益率较小的因子,直到基学习器多数投票结果准确率相对于基准较低为止.
信息增益(IG)是评价特征对于系统的相对影响程度,计算在该特征下的信息熵与原始信息熵的差值,即代表该特征带给整个系统的信息增益.利用信息增益指标有利于衡量特征对于整体系统的贡献程度,但信息增益选择特征时容易偏向取值多的变量.而信息增益率(IGR)则克服了该问题,信息增益率为信息增益(IG)除以分裂信息度量,即考虑了该特征数据分裂的广度和均匀程度后的信息增益.由于在剔除冗余因子的过程中,因子剔除顺序对于因子选择存在较大影响,因此,将信息增益率从小到大排序并依次剔除.
不平衡样本是财务舞弊识别模型首先需要解决的问题,因为其对于有监督机器学习任务有较大影响[34],并且强行平衡取样会导致数据样本与真实世界不符[29].在传统算法中,由于优化目标的设置会导致算法过多的关注多数类样本,从而使得少数类样本的分类准确度下降.已有文献一般有两种处理方法,一是寻找匹配样本,但是对于匹配样本选取而言,匹配标准(如资产规模相近、收入相近、净利润相近等)、匹配样本比例等参数确定都存在一定主观性,并且不同参数组合对应的模型不同、预测效果也不同,存在后验偏差且不符合真实预测场景.
一般不平衡样本处理方式包括欠采样、过采样,本研究采用过采样的随机抽样算法结合集成算法对数据不平衡问题进行处理.首先,用随机抽样过采样算法对将数据样本处理成平衡样本,接着用元学习框架对样本进行训练及样本外预测,重复随机抽样过采样算法多次,生成多个平衡样本,重复以上步骤,并对样本外预测进行预测多数投票汇总,最终得到预测结果.这样处理的优势在于,由于随机抽样算法对于少数类样本的抽样具有随机性,训练结果可能存在随机性,生成多个平衡样本有助于降低元学习框架表现的随机性以及预测效果的随机性,且通过预测结果评价指标的波动范围能够更好的观察不同算法在元学习框架中表现的稳定性与差异性.
2.2 元学习框架
对于训练集、验证集、测试集划分,本研究分别从正常样本和舞弊样本中随机抽取1/3样本组成测试集,剩下的2/3样本作为调参数据集,用5折交叉验证方式进行参数网格最优搜索,用验证集表现最佳的参数作为最优模型.本研究涉及的基学习器包括:决策树、梯度提升树(GBDT)、K近邻算法、Logistic回归、朴素贝叶斯算法、随机森林算法、支持向量机、极限梯度提升树(XGBoost)、神经网络(Neural Network),每个基学习器遵循该流程进行调参.
元学习框架最好选取不同特征的基学习器[27],而最常见的分类方法包括Logistic回归、决策树、神经网络、支持向量机等[3],涵盖线性分类算法、概率分布算法、惰性算法、决策树、神经网络算法.并且为了避免主观选择偏差[12],将不进行选择性集成,例如决策树、梯度提升树、等类似算法一起纳入模型中.
以下部分介绍元学习框架的预测流程.设混合样本一共有k个,特征有m个,则元学习框架具体表示为:
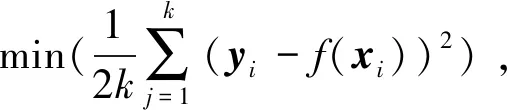
2)每一个分类器获得一个k×1维的预测向量z,将所有分类器预测结果堆叠形成k×9维的Z;
3)将Z从基学习器输出,输入到不同的堆叠分类器中再一次通过不同机器学习算法训练,优化函数同上,对应分类标签依旧是k×1维向量y;
4)每一个堆叠分类器输出结果为k×1维向量z′,通过计算
(1)
获得预测值y′.
通过元学习框架,整个流程能够自动学习各个分类器在给定情况下的优势和劣势,从底层模型的预测和分类偏差中学习,获得更大的分类能力[12, 35].这种堆叠的成功来源于它可以利用基学习器的预测多样性,从而在元级获得更高的预测准确性,这种基学习器的再学习相较于单个分类器或者简单结合策略会更有效[6],并且在支持数据挖掘自动化方面提高学习模型的泛化能力和稳定性[36].
3 数据说明
本研究模型中的输入数据从数据来源上划分,包括年报因子和季报因子;从类型上划分,包括财务类原始因子、财务类调整因子、公司治理因子、语言因子.
3.1 财务舞弊样本标记
财务舞弊相较于盈余管理最大的不同在于其违法违规性质,因此,本研究采用国泰安数据库违规信息数据,以确保样本选取的客观性.
国泰安数据库中的违规信息数据中,包含了违规事件的证券代码、实际违规年份、违规类型的数据,而其中违规类型包括虚构利润、虚列资产、推迟披露、出资违规、擅自改变资金用途、内幕交易、操纵股价、违规担保等.根据财务舞弊的性质,本研究财务舞弊样本选取的违规类型包括虚构利润、虚列资产、虚假记载(误导性陈述)、披露不实(其它),以确保财务舞弊样本类型的客观性和准确性.财务舞弊样本标记为1,非财务舞弊样本标记为0.
3.2 财务因子选取以及衍生因子构建
本研究主要参照Beneish、Cecchini等、Abbasi等[6, 17, 37]以及文献中最常见的财务舞弊指标,从资产结构、盈利能力、现金流量、营运能力四个方面选取了11个公司基本面特征变量.资产结构方面,本研究选取了资产质量指数、杠杆率[17, 37].资产质量指数计算方式是非流动性资产/总资产,并将当期(t)除以上一期(t-1).若资产质量指数>1说明,该公司潜在的递延成本增加,有资产夸大的可能.杠杆率是当期总债务/总资产比上一期该值.若杠杆率上升,债务增长相对于资产增长过快,存在财务危机可能.
盈利能力方面,本研究选取了边际利润率、净利润率、销售收入增长率[6, 17, 37].边际利润率是上一期边际利润率/当期边际利润率.当边际利润率>1,说明边际利润率在恶化,说明公司可能在虚增收入而利润没有变化.净利润率即净利润/营业利润,若企业虚增收入而没有对应的成本增加,会导致净利润上涨过快,净利润率过大.销售收入增长率是当期销售收入/上一期销售收入,若虚增销售收入,销售收入增长率会上涨过快.
现金流量方面,本研究选取了净经营现金流与净利润的差值.净经营现金流与净利润的差值评估应计项目对财务报表的影响[17].该比率如果为正,说明存在潜在收入造假的可能.
营运能力方面,本研究选取了总资产周转率、应收账款周转天数变化率、存货增长率、应收账款增长率、销售管理费用增长率[6, 37].总资产周转率是销售收入/总资产,当虚增销售收入,会导致该值偏大.应收账款周转天数变化率是当期(t)应收账款/销售收入比上一期(t-1)期数据,若企业虚增收入,会导致应收账款虚增,那么应收账款周转天数也会增加.当期存货/上一期存货.当存货增长率值越大,说明部分销售成本转嫁到存货账面成本,虚增营业利润.应收账款增长率是当期应收账款比上一期应收账款.虚增收入会导致应收账款过高,应收账款增长率增加过快.销售管理费用增长率是当期销售管理费用占销售收入比/上一期销售、管理费用占销售收入比.若公司虚增收入,那么销售、管理费用占比会下降,销售管理费用增长率会更小.
另外,财务因子还存在一定的行业偏差和结构偏差[6].结构偏差是指该公司基于上一个年度或者上一个同比季度数值水平的比较,增幅或者跌幅变化.例如该公司虽然营业利润相对于行业水平处于正常范围,但相较于上一个年度有一个极大的增幅,说明该公司可能存在营业利润调节的可能性.而行业偏差是指该公司与行业水平的偏差.例如该公司相较于上一年度没有异常的变动,但是其整体与行业水平相差甚远,也与同行业营业收入接近的公司水平相差甚远,这也说明了其异常的营业利润率,存在潜在财务舞弊的可能性.因此,将行业偏差与结构偏差因素纳入模型中,也有利于财务舞弊的识别.
考虑到行业偏差和结构偏差,本研究在11个指标的基础上增加了衍生的行业调整因子和衍生的结构调整因子.首先是行业调整因子.行业调整因子分为两类,一个是样本对应同行业营业收入最接近的前5%家公司的对应因子平均,另一个是同行业营业收入最高的前5%样本因子平均,通过对比同行业接近水平以及同行业顶尖水平的公司,可以判断该公司因子值是否处于正常范围.然后,再将原有的公司特有因子分别与同行业营业收入最接近的五个公司平均、同行业营业收入前五平均对应因子做差或者做除法.例如净利润率的行业调整因子可以衍生出四个因子,分别是净利润率original-净利润率close5%和净利润率original/净利润率close5%,以及净利润率original-净利润率top5%和净利润率original/净利润率top5%,其中下标为original原始数据,close5%表示近似5%,top5%表示行业龙头前5%.其次是结构调整因子,即使用该因子对应的同比值,然后做差或者做除法.例如净利润率的结构调整因子可以衍生出两个因子,分别是净利润率t-净利润率t-1以及净利润率t/净利润率t-1.
3.3 治理因子构建
学术界研究发现上市公司高管背景、高管组织结构、股本结构等与会计信息质量、财务重述行为具有一定相关性[4,38,39].本研究选取了高管团队背景、财报审计、股本结构、治理结构几个方面构造公司治理因子.
高管背景方面,本研究选取了高管团队女性性别占比、平均年龄、教育背景作为高管背景因子,数据来源国泰安数据库.Gao等、Liao等[40,41]发现女性的存在与实施财务舞弊的低可能性相关,因此女性比例越高,财务舞弊可能性就越低.Hambrick和Mason[42]认为年龄大的高管人员更加厌恶风险,因此高管平均年龄有可能与财务舞弊行为呈负相关.卢馨等[38]发现高管学历与财务舞弊行为严重负相关,说明学历越高财务舞弊可能性就越低.

表1 财务原始因子
财报审计方面,本研究选取了是否所属四大审计事务所、当年年报审计意见、披露年报时间作为财报审计的特征因子.四大审计事务所基于丰富经验以及出于维持其声誉的考虑,其相较于其他审计事务所的审计报告质量更高且更可信.当年年报审计意见因子定义为标准无保留或者无保留意见加事项段为1,保留或保留意见加事项段为2,否定以及无法发表意见为3.披露年报时间定义为,该公司财务报表正式披露年报时间距离上一年12月31日之间间隔的天数.Conover等[43]发现财务报表披露时滞与资本市场监督程度存在相互关系,若财务报告披露越延迟,往往公司的业绩越欠佳,越有可能进行财务舞弊.
股本结构方面,本研究选取了股本结构是否变化、董事会持股数量占比、管理层持股总股数、国有股股数占比、流通股数占比、监管层持股数、股东总数作为股本结构特征.许多学者都研究了股权结构对财务报表质量、公司治理能力的影响[39,40,44].总体来看,政府关联公司的治理水平较高,以及股权较分散、治理结构变动频率较低的公司财务舞弊可能性也相对较低.
治理质量方面,本研究选取了前十大股东是否存在关联、董事长与总经理是否同一人、高管团队总人数、董事人数、独立董事人数占比、监事会人数占比、董事监事及高管年薪总额作为治理质量因子.已有研究发现董事会规模与财务舞弊有相关性,较高的独立董事占比意味着较高的盈余信息质量[19],能够抑制财务舞弊事件的发生[14].另外,高管年薪与财务舞弊也有一定关系,股票薪酬的正向激励与其财务舞弊的负面效应存在矛盾[45, 46],而舞弊公司往往给予高管较低的现金薪资[47].
3.4 语言因子构建
已有学者发现,年报文字所蕴含或积极或消极的信息与公司业绩、高管行为、财务报表质量有显著关系.Goel和Uzuner、Hajek和Henriques[3,21]对美国上市公司董事会分析(MD&A)部分进行了文本分析,中国上市公司从2005年开始也包含了这一项内容,这一部分内容是基于管理层视角对于公司当前表现以及未来规划的文字叙述.

表2 公司治理层面因子
已有文献发现财务造假者倾向于采用负面以及不确定的词汇进行表述[1],以及MD&A提及的负面信息越多,亏损扭转的可能性越小[33].并且已有证据表明,中国上市公司年报存在语调管理行为[32],并且管理层报告样板化对不同财务风险的企业影响存在差异[48],因此也需要将对年报文本信息进行解析.本研究将基于MD&A部分的文本进行语言分析,包括7个指标:正向词(POS)、负向词(NEG)、情感基调(TONE)、强烈语气(STRONG)、模糊语气(UNCERT)、确定性程度(CERTAIN)、表达观点动词(REGARD).由于部分公司会出现更新财务报表的情况,本研究采取的语言因子采用更新后的报表MD&A进行文本分析.并且中国A股从2005年才开始要求对这一部分进行强制披露,爬取文本出现较多格式错误,以及提取董事会讨论与分析文本部分规则较为混乱,因此文本因子数据从2006年开始.
3.5 数据说明
根据国泰安财务处罚数据统计,从图2可以看到每年处罚频数都在呈现上涨的趋势,并且还会出现同一年份同一家公司出现多条违规记录,并且一条记录中还出现多个财务舞弊的类型,并且平均类型数也在逐年上涨,这也说明了财务舞弊问题的严峻性.另外,2006年—2018年上市公司财务舞弊处罚案例中,延迟1年~4年占所有案例64.15%,17.18%的公司延迟了5年及以上才被披露其舞弊行为,这反映了财务舞弊具有隐蔽性,导致财务舞弊识别不及时,放大了财务舞弊的恶性影响,不过近几年财务舞弊识别延迟现象有所改善.
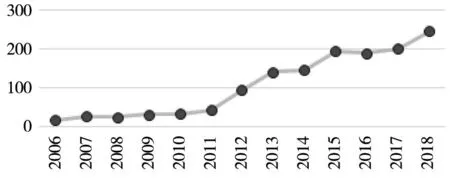
图2 处罚记录分布
本研究财务数据用国泰安数据库财务报表数据进行计算,文本因子从东方财富网公司公告中爬取.先剔除了包含缺失值的样本,并对上下1%的异常值进行了处理,2006年—2018年,最终有1 786个舞弊样本,12 770个非舞弊样本.并用随机抽样算法对不平衡数据进行过采样处理,训练出模型后,再带入真实数据进行模型性能测试.每只股票在每年所采用因子以及个数汇总如下表3.

表3 因子列表
4 实证结果
由于本研究为识别财务舞弊问题,相对于非舞弊样本中能够正确预测多少非舞弊样本而言,真实世界更关心预测结果为非舞弊样本中,有多少样本是真正非舞弊的公司.同理,对于预测结果为舞弊样本中,有多少样本是真正舞弊的公司.这样的指标称为召回率(recall),召回率更关心预测结果中的正确率.
与召回率相对应的是准确率(precision),这二者一般在同一条件下相对呈反向变化.为了兼顾这二者指标,F1-score作为一个综合指标可以综合考察准确率与召回率的平衡情况.若召回率和准确率相差较大,F1-score将会相对较小.
(2)
另一个模型性能指标是AUC数值,即为ROC曲线与坐标轴包围成的面积.ROC曲线是按照财务舞弊识别模型预测概率进行降序排列,并累积计算模型的假正率与真正率,获得斜向上的ROC曲线.若ROC曲线围成的面积越大,AUC数值则越高,也说明模型分类效果越好.
4.1 信息增益率(IGR)值排序统计
每个样本在年度横截面数据中,一共有356个因子,最终筛选剩下120个因子.以下对IGR值降序排序前50、前100、前120个因子进行统计,观察什么种类的因子对于财务舞弊识别更有效.
以上统计数据为排序靠前的因子中,来源于年报或者季报因子占其总体因子的比例,百分比含义为该属性因子占该属性原有总体因子的比例.从上表来看,年度因子的有效性更高,说明年报数据相对于季报数据而言对于识别舞弊样本更加有效,这也比较符合直观的认识,年报相较于季报审计更为严格,因此年报因子的信息有效性程度也相较于季度因子更为高.并且从最终挑选的因子池来看,年度因子占比高于季度因子占比35.58%远远高于季度因子32.94%的占比.
在最终因子池中被采用率最高的是原始财务因子,其占原始财务因子的38.64%,其次是行业调整财务因子占初始因子36.36%,紧接着是结构调整财务因子31.82%,接着是治理因子30%,最后是语言因子17.86%.
从IGR值来看,单个财务因子对于识别舞弊样本起到了主要作用,并且经过行业调整及结构调整的财务因子对于整个分类系统也有较大贡献,也说明了财务因子对于识别财务舞弊的重要性.排名前30财务因子对应的原始变量包括净利润率、销售收入增长率、销售管理费用增长率、边际利润率、总资产周转率,这与已有文献的观点[6,37]也是相一致的.

表4 财务报表类型统计
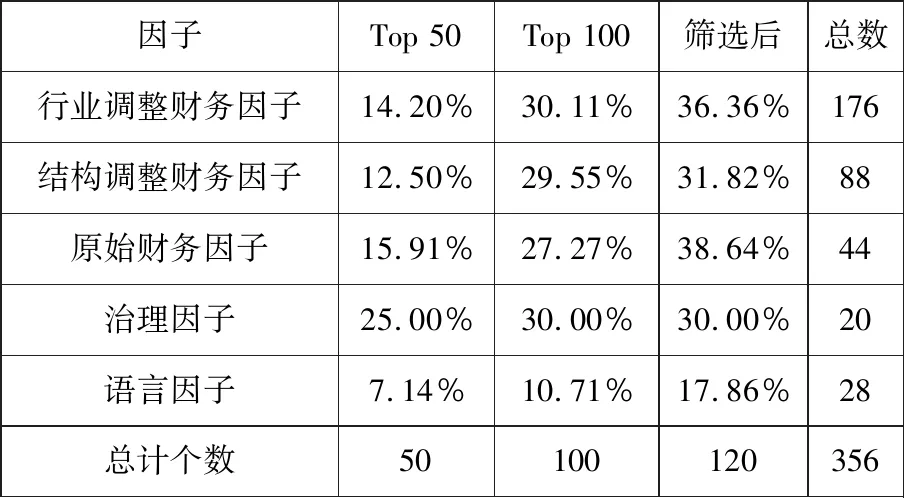
表5 因子类型统计
对于公司治理因子而言,虽然总体因子数较少,但整体入选比例也相对较高.因子池中最终入选的因子包括:董事会持股比例、是否为四大审计事务所、审计意见、报告披露时间、高管薪资,并且这几个因子的IGR排名也较为靠前.从这些因子来源观察,财报审计因素对于整体公司治理因子的贡献率较高,这也侧面说明了财报审计相关因素对于判断财务舞弊也是一个重要的因素.例如,越大的机构可能越注重声誉,其所具备能力也越专业,审计结果也越值得信赖,也就保证其审计的公司财务舞弊可能性越低.报告披露时间距离截止时间越近,可能越欠佳,越有可能用较长的时间进行财务掩饰以及财务舞弊.另外,董事会持股比例越高,其公司控制力越大,根据财务舞弊动因理论,其进行财务舞弊的机会也就越充分,公司财务舞弊的可能性就越大.以及,高管薪资对于财务舞弊识别也具有一定的作用.对于语言因子而言,在最终的因子池中只有五个因子入选,分别是第三季度确定程度因子、第一季度确定程度因子、第三季度负向因子、第二季度不确定因子以及第二季度表观点动词因子,并且分别排名第2、第3、第94、第108、第110,这说明在第一季度、第二季度和第三季度董事会分析与讨论中,文本部分可能会释放表示确定性程度、或负向的信号,而这一信号对于识别公司舞弊将会有一定帮助.
除此之外,对比财务因子和公司治理因子,语言因子排名相对靠前的因子,全部为季报因子,而财务因子和公司治理因子中年报因子的排名靠前,这也侧面说明了对于识别财务舞弊,季报的文本信息相对于年报的文本信息更为丰富.对于财务舞弊识别问题,投资者或者监管层更应该关注季度报告中管理层讨论与分析部分,一些不确定的用词或者负向的表述,都有可能成为其未来业绩反转或者未来财务舞弊事件发生可能的线索和指向.
4.2 Kolmogorov-Smirnov test(K-S检验)
为了进一步检验因子池的有效性,本研究采用K-S检验验证因子池的因子,在舞弊样本和非舞弊样本中存在显著差异.按照P值从大到小、前30个因子排序结果如下表6.
只有表示确定性程度的第三季度因子(CERTAIN9)未能在90%的置信水平下通过检验,其余因子均在90%的置信水平下通过检验.以上结果说明了大部分的因子在非舞弊和舞弊样本中存在显著的分布差异,并且在统计层面上,挑选出的因子是显著有效的,这也侧面证明了从IGR排序筛选的方法,在统计上对于因子挑选的结果也同样存在意义.

表6 K-S检验结果
4.3 各基学习器表现
首先,在不筛选因子的情况下,各基学习器表现如表7.通过信息增益率进行排序并依次剔除信息增益率较小的变量,若剔除后基学习器多数投票结果的AUC值低于剔除前的AUC值,则停止剔除.重复以上步骤获得了筛选后的因子库,并得到了各基学习器表现结果见表8.
对比表7和表8,从筛选前后预测效果来看,一方面,除了决策树和神经网络的AUC值有小幅下降外在因子筛选过后其余基学习器算法的AUC值都有了明显的提高;从F1值来看,除了随机森林算法外,其他算法的F1值都有了明显提高.另一方面,无论是因子筛选前还是筛选后,各基学习器的非舞弊精确率要明显平均高于舞弊精确率,并且因子筛选前该结论更为突出,这可能是由于一些信息增益较低的因子可能存在噪声信息,干扰了基学习器的预测.
另外,从基学习器之间预测效果对比角度(图3),无论在因子筛选前还是筛选后,Logistic回归的舞弊精确率都要明显高于非舞弊精确率,这与其他基学习器表现完全不同.除此之外,不同基学习器的预测性能、非舞弊和舞弊精确率的权衡以及精确率和召回率的权衡上表现都不相同.对比筛选前后,不同算法在非舞弊和舞弊精确率的权衡分布也更为分散,这也为元学习框架学习吸收不同分类器的优势提供了有利条件.

表7 筛选前基学习器表现
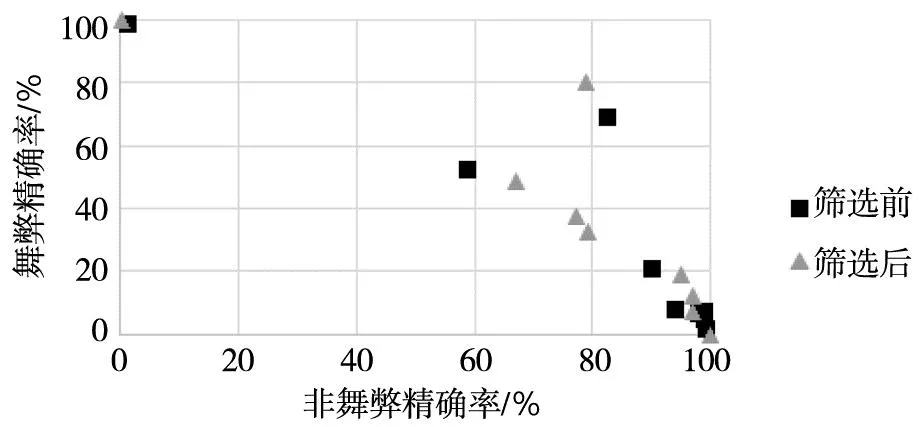
图3 因子筛选前后基学习器预测效果对比
4.4 元学习框架下不同算法表现
将样本预测的结果进行堆叠,继续将预测结果作为解释变量,放入不同的学习器中进行进一步学习,得到单个元学习输出结果,如表9所示.
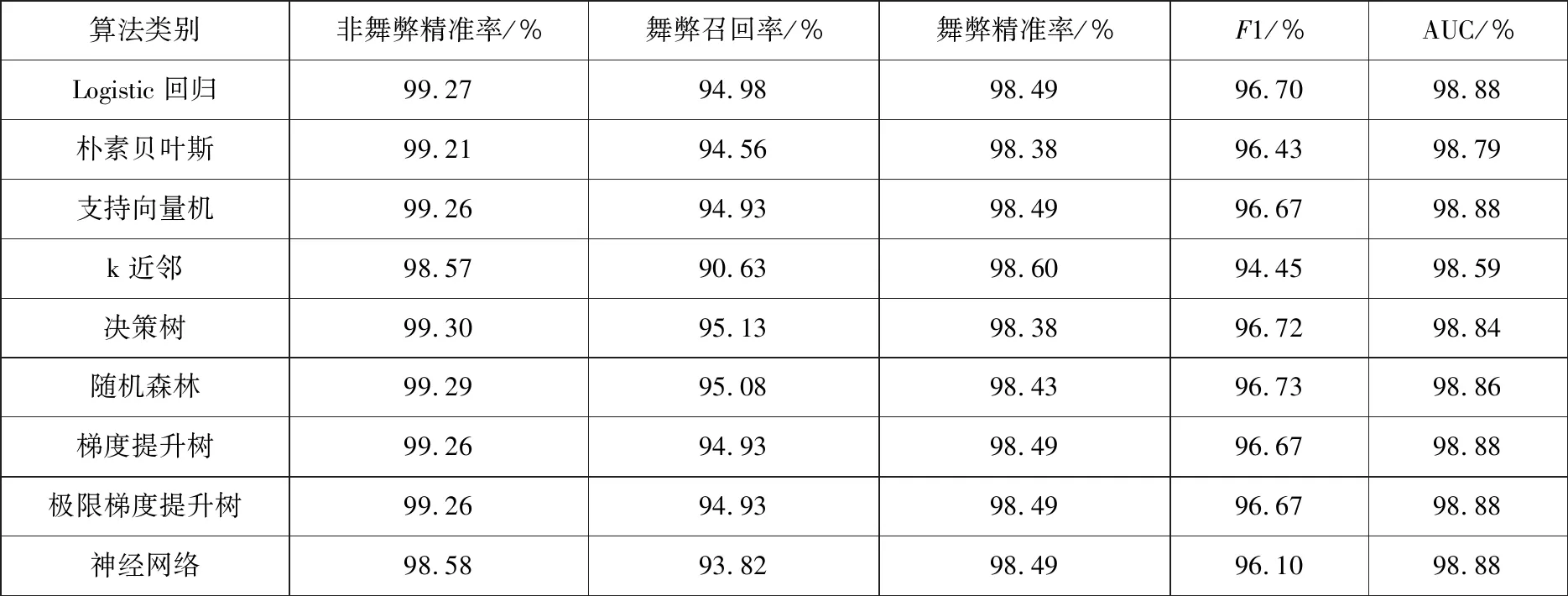
表9 元学习框架结果
由元学习框架结果对比各基学习器单层学习结果对比分析发现,无论是舞弊精准率、非舞弊精准率、舞弊召回率、AUC值平均水平都有显著的提高.非舞弊精准率最高达到了99.30%,最低精准率也达到了98.57%,而舞弊精准率最低达到了98.38%,最高则达到了98.49%.另外,舞弊召回率也均分布在90.63%~95.13%的区间.从综合评价指标F1和AUC值来看,也明显高于基学习器之前的预测水平,F1值从原来的0.29%~48.70%区间提高至将近95%以上的区间,AUC指标从50.02%~79.74%区间提升值98%以上的区间.
但通过观察发现,不同算法的结果是相同的,这是由于在堆叠各基学习器的结果后,对于同一个优化的输出结果再学习时,不同算法输出了相似的结果,这样无法对比各算法套用元学习框架时的优劣.因此,通过采样生成多个平衡数据集,每个数据集都堆叠出不同的输出结果,并将不同算法在各个平衡数据集的表现提取出来,便于比较不同算法在学习其他算法输出结果时的优劣.下表为20个平衡数据集中不同算法的表现.
本研究展示了20个随机抽样数据集运用元学习训练后,以多数投票输出的结果,也做了5个元学习、10个元学习、15个元学习训练,结果也是类似的,只是标准差范围存在一定差异.
以综合指标F1和AUC作为比较标准,对比不同的算法,朴素贝叶斯和k近邻算法表现相对于其他算法较差,无论是F1值还是AUC值均值相对其他算法较低,并且标准差相对较高,但与其他算法相差也仅有大约1%的差距,也说明了元学习框架能够充分学习不同算法的预测结果,最终提高预测结果.而相对表现较为良好的是决策树、随机森林、梯度提升树、极限梯度提升树这几种以决策树为核心的算法,其F1和AUC的均值相对较高并且标准差也较小,说明财务舞弊识别问题场景下,以非线性挖掘特征的算法能够发挥较好的优势.
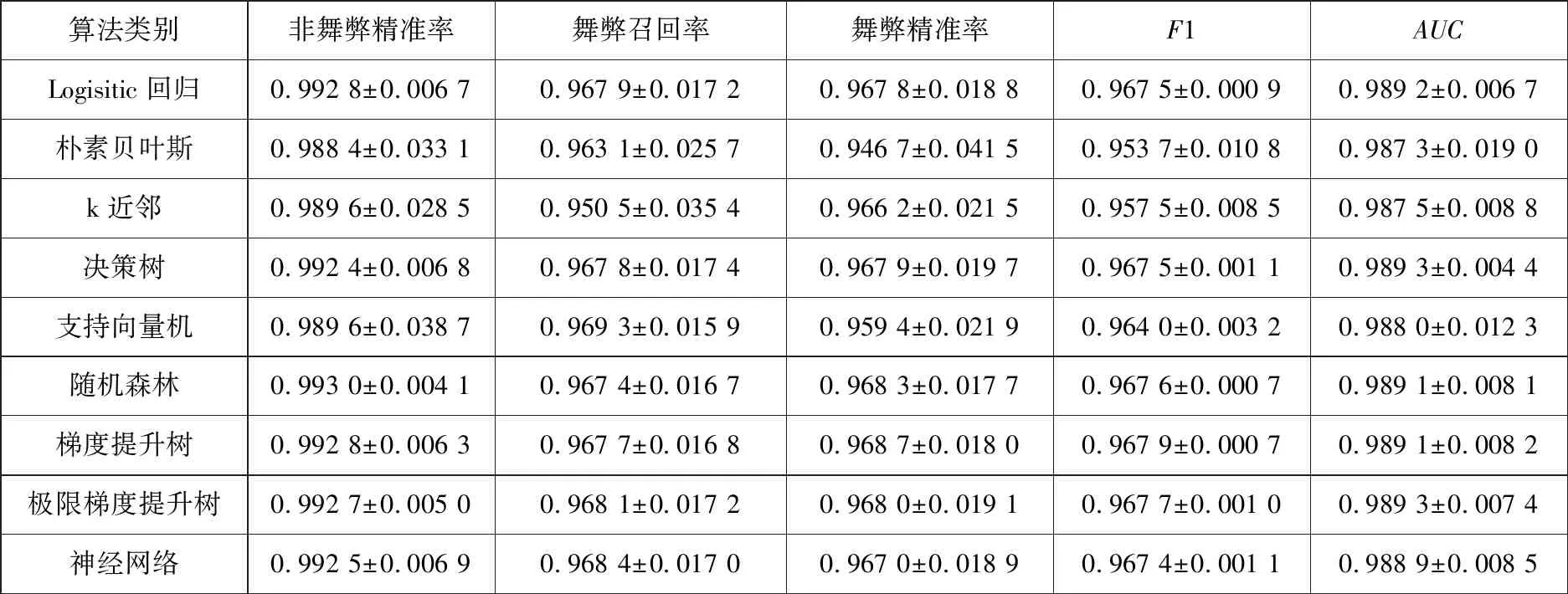
表10 20个元学习结果
4.5 分行业观察元学习框架性能
在预测过程中,本研究并未针对不同行业构建不同模型,即在元学习框架下并未对行业进行区分,对于所有行业均采用同一优化参数,那么元学习框架是否对于不同行业也有同样的适用度呢?
表11展示基于同一模型下,不同行业预测准确度是否表现良好.一些行业由于其在A股上市的规模较大,其舞弊对中国资本市场造成的影响也会更大,因此,本研究将按照证监会行业分类,重点观察上市企业较多的行业,分析其对应的舞弊识别性能如何.

表11 分行业模型预测效果
本研究选取了有效样本数排名前10的行业,可以看到F1分数几乎均在94%以上,AUC大多在98%以上.制造业作为周期性行业,业绩波动幅度较大,有较强的盈余管理以及财务造假动机,但制造业在元学习框架下,预测结果为舞弊样本中有98.79%为真正的舞弊样本,并且F1分数也达到了97.06%,AUC数值达99.06%,说明元学习框架能够覆盖和有效预测制造业样本.对于有效样本前十的行业中,舞弊样本召回率最小值也高达91.96%,说明大部分样本中,真实为舞弊样本的公司中有高达90%以上的样本预测正确.不同行业财务舞弊的手段可能是不相似的,但是粉饰业绩的指标可能是相似的,例如应收账款周转率、销售收入等.虽然对于所有行业仅采用了一套优化参数,但是对于大部分行业的预测效果都较为稳定且良好,也说明了元学习框架在行业层面具有一定的稳健性.
4.6 滚动预测性能分析
前面的结果按照全样本进行随机抽样组成训练集、验证集和测试集,但真实世界下,当年只能知道去年全年的信息,无法预知未来的舞弊信息以及财务信息,因此,该部分用两种滚动的方式检验元学习框架的稳健性.
第一种是以五年为单位进行滚动,例如2006年—2010年为一组,2011年作为测试集,2006年—2000年用5折交叉验证进行参数调参,然后每年都以固定时间5年为窗口进行滚动.第二种是时间窗口不断扩大的方式滚动,例如一开始以2006年—2010年为一组,最新的2011年样本为测试集,2006年—2010年用5折交叉验证的方式进行参数调参;接着以2006年—2011年为一组,最新的2012年测试集,2006年—2011年用5折交叉验证的方式进行参数调参,以此类推.
对比表12和表13,元学习框架能够较好的提高舞弊样本召回率,舞弊样本准确率也有一定的提升,说明元学习框架对于基学习器预测效果提升有较大的帮助.虽然对比随机抽样生成的训练集、验证集、验证集而言,按照真实世界采用固定窗口滚动预测方法的AUC值有所下降,但最低也达到了86.41%,F1最低也达到了94.59%,并且相较于单层基学习器的多数投票预测结果而言,明显有显著的提高.

表12 基学习器固定时间5年窗口滚动结果
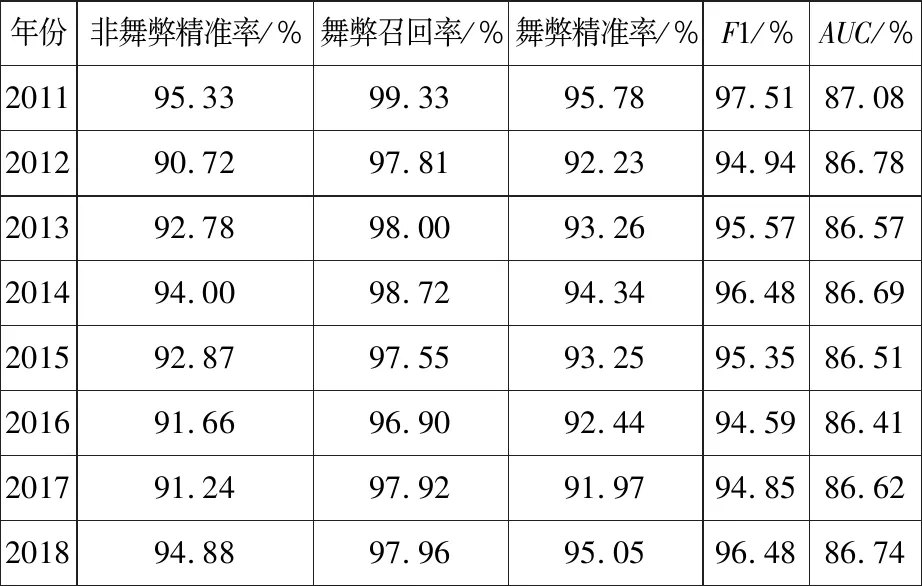
表13 元学习固定时间5年窗口滚动结果
尝试第二种时间窗口不断扩大滚动的预测方式也得到了相同的结论(表14、表15).
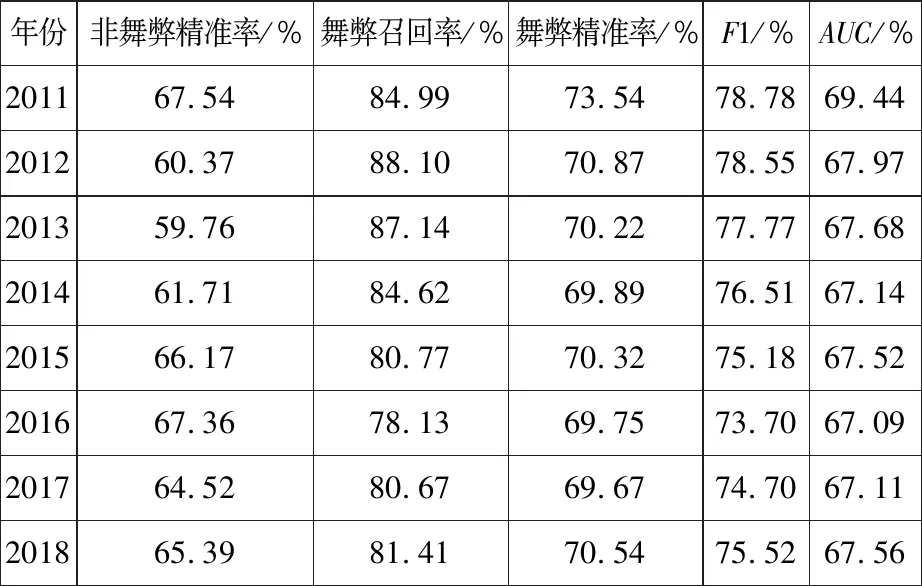
表14 基学习器时间窗口不断扩大滚动结果

表15 元学习时间窗口不断扩大滚动结果
在元学习框架下,不同年份之间识别的精准率、召回率、F1值都维持在90%以上,AUC值维持在85%以上,并未有太大的波动,也侧面说明了元学习框架预测效果的稳健性和预测性能的优越性.
而对比固定时间窗口(表12、表13)的滚动以及扩大时间窗口(表14、表15)的滚动结果,汇总如图4,基学习器表现以及元学习框架表现大体相差较小,但大部分的固定窗口的表现要优于扩大窗口,这一现象也说明了,可能存在舞弊企业特征与非舞弊企业特征的识别模式有较小的改变,但总体差距较小.近年财务舞弊现象的频发并不是财务舞弊方式发生了较大的改变,而是财务舞弊可能愈发成为一种较为常见的现象,同时财务舞弊事件公布的延迟率下降、市场信息传递的效率提高,也让更多的财务舞弊事件被大众所周知.
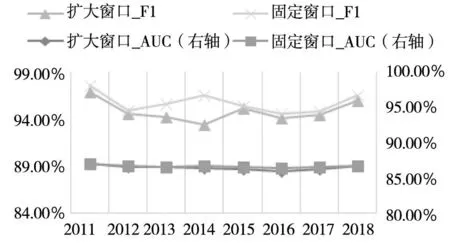
图4 扩大窗口与固定窗口结果对比
5 结束语
本研究对于无缺失数据的2 437家上市公司进行分析,涉及三大类五小类包括原始财务因子、行业调整财务因子、结构调整财务因子、公司治理因子、语言因子共计356个因子,并依次对因子进行筛选、异常值处理,再对数据不平衡问题处理,最后运用元学习框架对基学习器进行优化改进,以提高上市公司财务舞弊识别的准确性,并得到了如下结论:
第一,总体而言,元学习框架能够有效的提升财务舞弊识别的准确性,可以体现在提升非舞弊样本和舞弊样本精确率、舞弊样本召回率、F1、AUC数值,这也可以说明集成算法思想的优越性.并且元学习框架对于不同行业也同样适用,有效样本排名前十的行业召回率均在90%以上,说明了元学习框架的广泛适用性.
第二,在整个模型流程中,因子筛选和数据不平衡处理对于提升模型准确度也有十分重要的贡献.筛选因子过程采用了信息增益率加逐步筛查的方法进行,用K-S检验方法对因子有效性进行检验,也证明了最终筛选出的因子在舞弊样本和非舞弊样本之间存在着显著的分布差异.另外,通过非舞弊样本精确率和舞弊样本精确率的不同算法结果分布比较,本研究发现筛选因子后不同算法区分度更高,更有利于元学习训练.而数据不平衡处理则避免了在训练样本的过程中,过多样本一方过度学习的现象,用采样的方式解决了数据不平衡的问题,并且也提高了模型对于识别少数样本的敏感度.
第三,对于元学习框架的有效性进行了稳定性检验.本研究模拟真实世界的信息流,采用滚动预测的方式对元学习框架进行测试,虽然结果稍逊于随机抽样生成测试集的结果,但召回率均维持在90%以上,AUC数值均维持在85%以上.并且对比不同滚动方式的预测结果,基学习器表现以及元学习框架表现大体相差较小,说明舞弊企业特征与非舞弊企业特征的识别模式仅有较小的改变.
第四,年度财务报告中提取的因子相对于季度报告因子,在识别舞弊方面更有效.财务类因子中,结构偏差调整因子对于财务舞弊识别帮助最大,其次是行业偏差调整因子,最后是原始因子.其次,最终有25%的公司治理因子被纳入最终因子库,具体包括董事会持股比例、是否为四大审计事务所、审计意见、报告披露时间、高管薪资.语言类因子对于财务舞弊识别也有一定的帮助,其中确定性程度因子对于财务舞弊识别帮助最大,并且季报的语言类因子的有效性要高于年报的语言类因子.
总之,本研究通过元学习框架及机器学习方法,降低了以往模型的主观干预程度,有效提高了模型预测的准确性和稳定性,其中,决策树为核心的相关算法对财务舞弊识别问题上具有更大的帮助,以及语言类因子对财务舞弊识别也有一定作用.
未来工作可以从以下三个方面进行深入研究:首先,基学习器可以进一步扩展,例如使用深度学习以进一步提高模型的预测效果,另外,对于延迟样本识别方法也有待进一步挖掘.其次,本研究采用的字典为知网正负面评价情感词库、中国台湾大学简体中文情感词典、清华大学李军中文褒贬词典,这些字典对于解析会计文本存在一定的偏差,一些专有名词可能无法得到准确分类,未来字典的扩展和完善也有利于会计文本得到更准确的解析.最后,本研究仅将管理层经营讨论与经营部分进行了文本词性分析,今后可以对年报其他内容进行进一步分析,也还可以对于文本分析方法进行进一步扩展,以丰富文本信息挖掘的工具并提炼更多的文本信息.
猜你喜欢
活力(2021年6期)2021-08-05
现代企业(2021年2期)2021-07-20
中学生数理化·高一版(2021年2期)2021-03-19
现代经济信息(2020年34期)2020-06-08
意林·全彩Color(2019年9期)2019-10-17
经济技术协作信息(2018年11期)2019-01-14
知识经济·中国直销(2018年8期)2018-08-23
河南水利年鉴(2017年0期)2017-05-19
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
