
基于机器学习的图号申请系统设计与实现*
2023-02-03 01:54:26罗瑞旭张胜文方喜峰
制造技术与机床 2023年1期
罗瑞旭 张 辉 张胜文 李 坤 方喜峰
(江苏科技大学机械工程学院,江苏 镇江 212100)
随着制造业发展不断加快,对产品设计效率的要求不断提高,而为设计图纸文件申请相应的图纸编号则是保证车间顺利生产及实现产品数据管理的重要手段。孙宜然等[1]设计了一种面向工装管理的图号编码系统;黄坤等[2]基于ASP.NET技术实现图号的在线申请、审批等功能。然而这些传统的图号申请系统大都需要繁琐的人工交互式操作,自动化与智能化程度很低。在对企业设计部门的调研后发现,在企业PDM库中保存了大量设计资源,而对应设计图纸的历史图号记录也保存在PDM中。在企业产品设计过程中,一般除直接借用件、标准件外的产品设计图纸都需要申请对应的图号,而这其中60%以上的图纸图号在企业PDM中均存在历史申请记录,特别是对于一些企业中的大批量、常规型产品,产品设计图纸图号的重复申请率达80%~90%。然而当前大多数的制造业企业所使用的仍然是交互式很强的图号申请系统,造成了设计人员大量的重复性劳动,从而导致产品的整体设计效率难以提高。因此,有必要研究智能化的批量图号申请技术,避免设计人员的重复性劳动,提高产品的设计效率。
针对上述问题并结合企业实际需求,本文提出了一种基于机器学习的智能图号申请方法并开发了相应的图号申请系统。通过对已有的图号资源处理后,利用机器学习的方式对这些图号资源进行学习训练,从而实现产品零部件设计图纸图号的自动化批量申请。
1 图号申请概述
1.1 图号命名规则
目前大多数的制造业企业都根据文献[3]制定了相关图号命名规则,将图纸按照技术特征分为9级,每级10个类属性,每个类属性下10个型属性,每个型属性下10个种属性。技术图纸编号的组成形式如图1。图号申请主要在于确定由级、类、型和种4位数字组成的属性图号,而对应流水号只需读取PDM库中对应属性图号的最大值加1即可。
1.2 图号申请系统设计方案及流程
本文提出的基于机器学习的智能图号申请方法,其方案流程如图2。
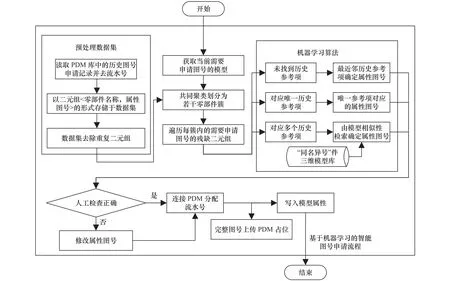
图2 图号申请系统工作流程
首先,从企业PDM库中提取出<零部件名称,属性图号>二元组形式的数据并进行去重处理后作为原始数据集。其次,获取当前需要申请图号的产品零部件集,将需要申请图号的新零部件与数据集中的零部件共同按照名称使用K-means++算法[4]进行聚类划分,得到若干零部件簇。其中,每簇内可能包含若干个仅含新零部件名称的残缺二元组。最后,遍历所有残缺二元组,对每个新零部件,在其所在的零部件簇中判断:若无历史参考项,则利用KNN算法分配属性图号;若存在唯一历史参考项,则分配该参考项的属性图号;若存在多个历史参考项,说明该新零部件名称在该零部件簇中对应多个属性图号,该新零部件即为“同名异号”件。此时利用基于基于多视图卷积神经网络(MVCNN)的相似模型检索技术[5],根据模型最大相似性原则分配属性图号。所有新零部件全部获取属性图号后经审核无误进行流水号分配,并写入对应的零部件模型属性及PDM库中。
2 图号申请系统关键技术
2.1 数据集处理
对需要申请图号的零部件名称与数据集中二元组的零部件名称共同分词后进行One-hot编码[6],以一个N维向量aN表示零部件名称,同时aN对应
2.2 总体算法流程
为提高聚类收敛的速度,避免局部最优,本文使用K-means++算法。对p个新零部件样本和数据集中的m个历史零部件样本共同划分为K簇后,再对每簇内的新样本分别讨论,以提高运算速度。建立融合算法进行图号申请的主要步骤如下。
步骤 1 在包含m个完整历 史样本x≤aN,NUMstr>的原始集中添加p个新的残缺样本x≤aN,None> 作为新样本集 X={x1,x2,···,xm,xm+1,···,xm+p},在 X中以u0≤aN0,NUMstr0>为首个质心,此时k=0。
步骤 2 将 A={aNi,i=1, ···,m+p}中的aNi与已有聚类中心uk≤aNk,NUMstrk/None>中aNk的欧式距离作为样本xi与uk的距离度量D(xi,uk),D(xi,uk)由式(1)计算。
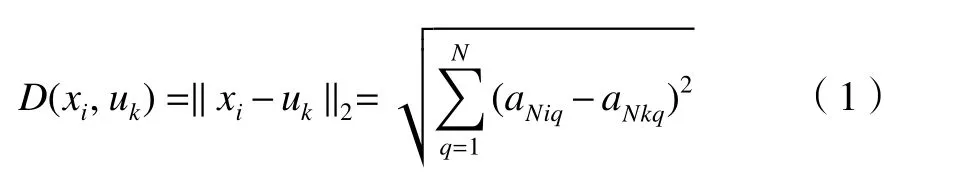
式中:aNiq和akiq分别为向量aNi和aNk的第q个元素。
步骤3 由式(2)计算概率P(xi,uk)得出下一质心。
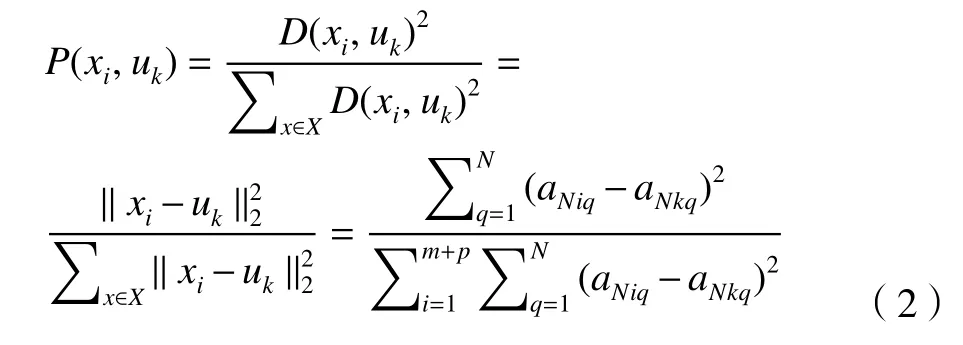
步骤 4 重复 2~3,当k=K时得到 U={u1,u2, ···,uk}为初始聚类中心。
步骤5 进入循环:当xi对应时将xi分配到ukʹ,得到K簇{c1,c2, ···,ck}。每簇由式(3)重算质心。
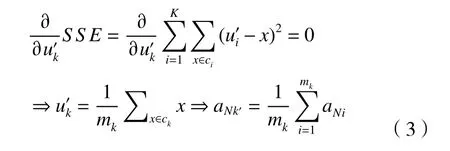
式(3)中:u'k为更新后的质心,mk为ck簇内的样本个数,a'Nk为u'k对应的向量。
步骤6 当质心不变时,迭代停止,生成聚类中心集合 Uʹ={u'1,u'2, ···,u'k},最终样本簇 Cʹ={c'i|
步骤7 进入循环:遍历存在缺失二元组xinc=
步骤8 所有簇中的所有缺失二元组全部补充完整后,算法进程结束。
其中,K-means++中的K值利用轮廓系数法[7]进行评价,获取不同聚类簇数K对应的平均轮廓系数,取平均轮廓系数的最大值所对应的K值为零部件聚类簇数。
2.3 基于三维模型获取属性图号
2.3.1 获取三维模型的二维视图集
对数据集中的“同名异号”件以零部件名称为父类别,以属性图号为子类,从企业SolidWorks三维模型资源库中获取各子类对应的零部件三维模型,利用SolidWorks API函数获取其二维视图集。
2.3.2 基于MVCNN相似模型检索
基于MVCNN的模型检索[8]基本原理为利用卷积神经网络对三维模型的二维视图集进行训练,获取待识别模型的二维视图导入训练好的CNN模型中,通过二维视图的检索匹配结果来确定与待识别模型相似件。轻量型卷积神经网络MobileNet相较于其他神经网络如VGG[9]、GoogleNet[10]和ResNet[11]等具有参数量少,运算速度快等优点[12],故本文使用MobileNet卷积神经网络对三维模型的二维视图集进行训练和检索匹配。
MobileNet神经网络由于对每个输入通道采用不同的卷积核,故每个通道的输出只受之前对应通道信息的影响[13]。同时, MobileNet与标准卷积的计算量之比为,当DK=3,两者计算量之比约为1/9。同时应用中加入归一化处理并使用ReLU激活函数。
由于模型二维视图集分类属于多分类任务,故选择交叉熵损失函数[14](cross-entropy loss function)
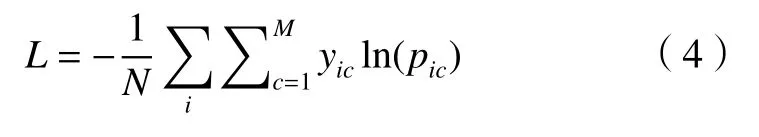
为使参数训练更稳定,选择Adam优化器[15]来调节和约束参数学习率,其公式为
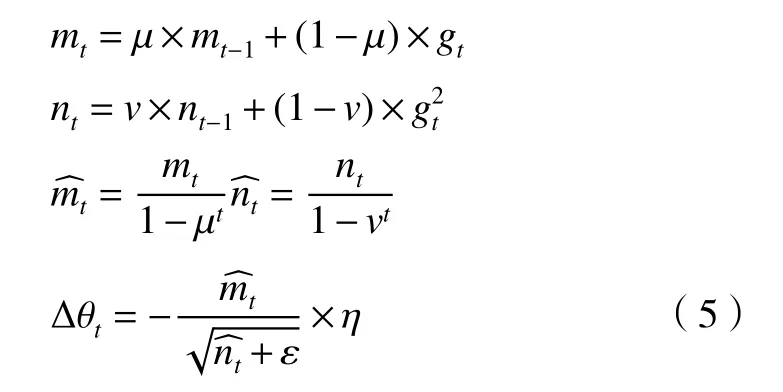
在获得各“同名异号”件模型的视图集后,使用MobileNet卷积神经网络对各父类模型的二维视图集进行训练,以属性图号作为各父类的样本标签,每一父类模型对应一个MobileNet训练结果。在2.2步骤7的情况③利用SolidWorks API函数获取目标样本xinc的典型二维视图,包括等轴测图、六面视图、剖视图及若干随机旋转角度视图,确定xinc所属的模型父类,调用该父类中的训练结果进行三维模型相似性检索匹配,将匹配到的子类赋予xinc,匹配流程如图3。
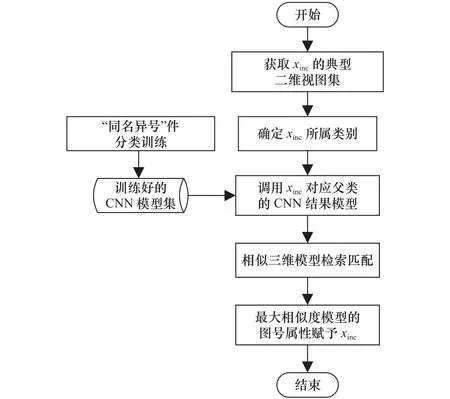
图3 基于模型相似性检索的属性图号分配流程
3 系统实现与验证
3.1 数据集处理
从PDM库中读取的历史图号申请记录并完成去重去流水号处理后共获取1 327条有效记录,将之作为有效二元组写入原始数据集。利用Python中的jieba分词器将零部件名称分词后进行One-hot编码。表1所示为部分零部件的编码结果及其对应的属性图号。
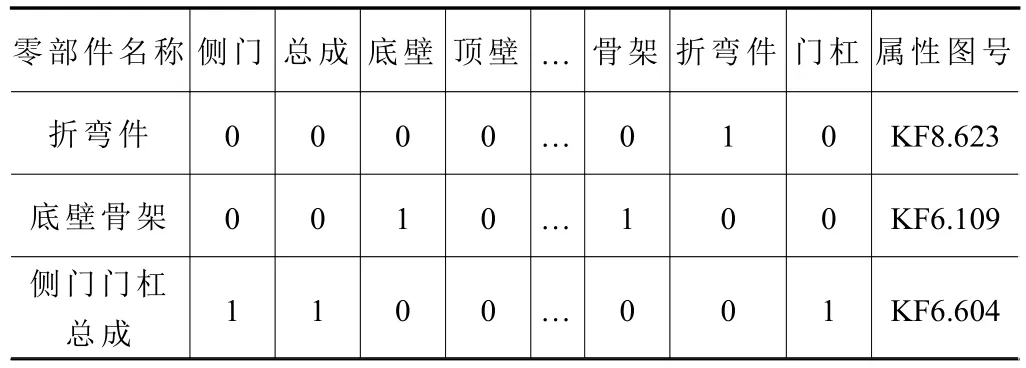
表1 部分零部件名称One-hot编码示例
“同名异号”件按名称分类共计39种父类,每一父类中都包含两个及以上的属性图号子类。利用SolidWorks API函数获取每个属性图号对应模型的二维视图集,以“.JPG”格式保存模型的各个视图。图4为“折弯件”父类中属性图号为“KF8.607”子类的部分视图。

图4 “KF8.607”折弯件的部分二维视图
3.2 算法验证
通过对企业常用零部件种类的归纳分析,结合轮廓系数法进行综合对比,在K-means++算法中取K=22。以企业某批次冷藏车车厢为例进行图号申请测试,按照式(3)获取最终聚类中心,如表2。
以“顶壁木骨架”为目标模型xinc为例,在第2簇内计算xinc与其他样本xi的欧式距离d(xinc,xi),计算结果如表3。
由表3可知,对“顶壁木骨架”恰好存在唯一的历史参考样本x2与xinc使得d(xinc,x2)=0,故将样本x2的属性图号“KF6.712”赋予“顶壁木骨架”。同理,遍历每簇中的xinc并按照2.2节所述为每个需要申请图号的零部件进行分配属性图号,直到全部xinc匹配完成后停止。
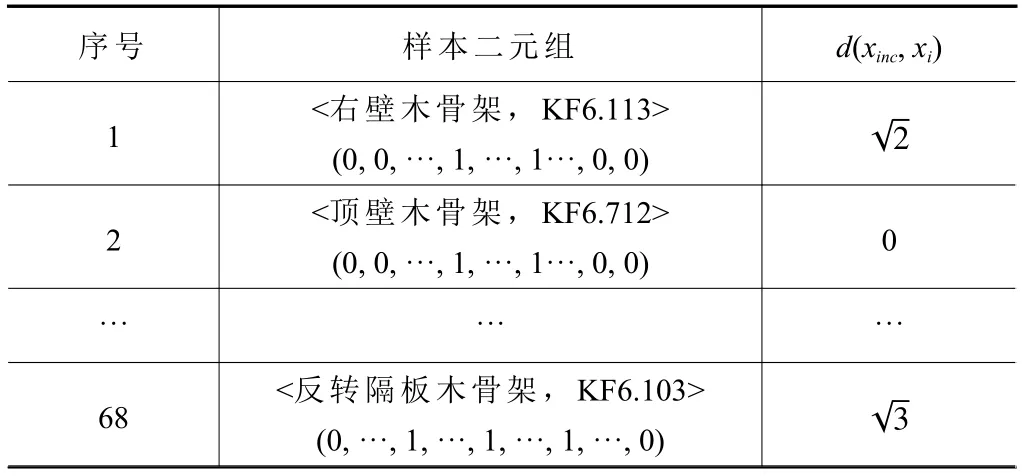
表3 KNN算法中欧式距离d(xinc ,xi)的计算结果
对“同名异号”件以“折弯件”父类为例,借助Tensorflow对其6种子类模型视图集进行训练,其中,训练集(Train):验证集(Val)=8:2。以经典CNN模型作为对比并采用SGD优化器。两种模型均进行归一化,图像处理为224×224大小,单次训练图像数batchsize=16,训练次数epoch=30。绘制两种模型的Accuracy及Loss曲线,如图5。
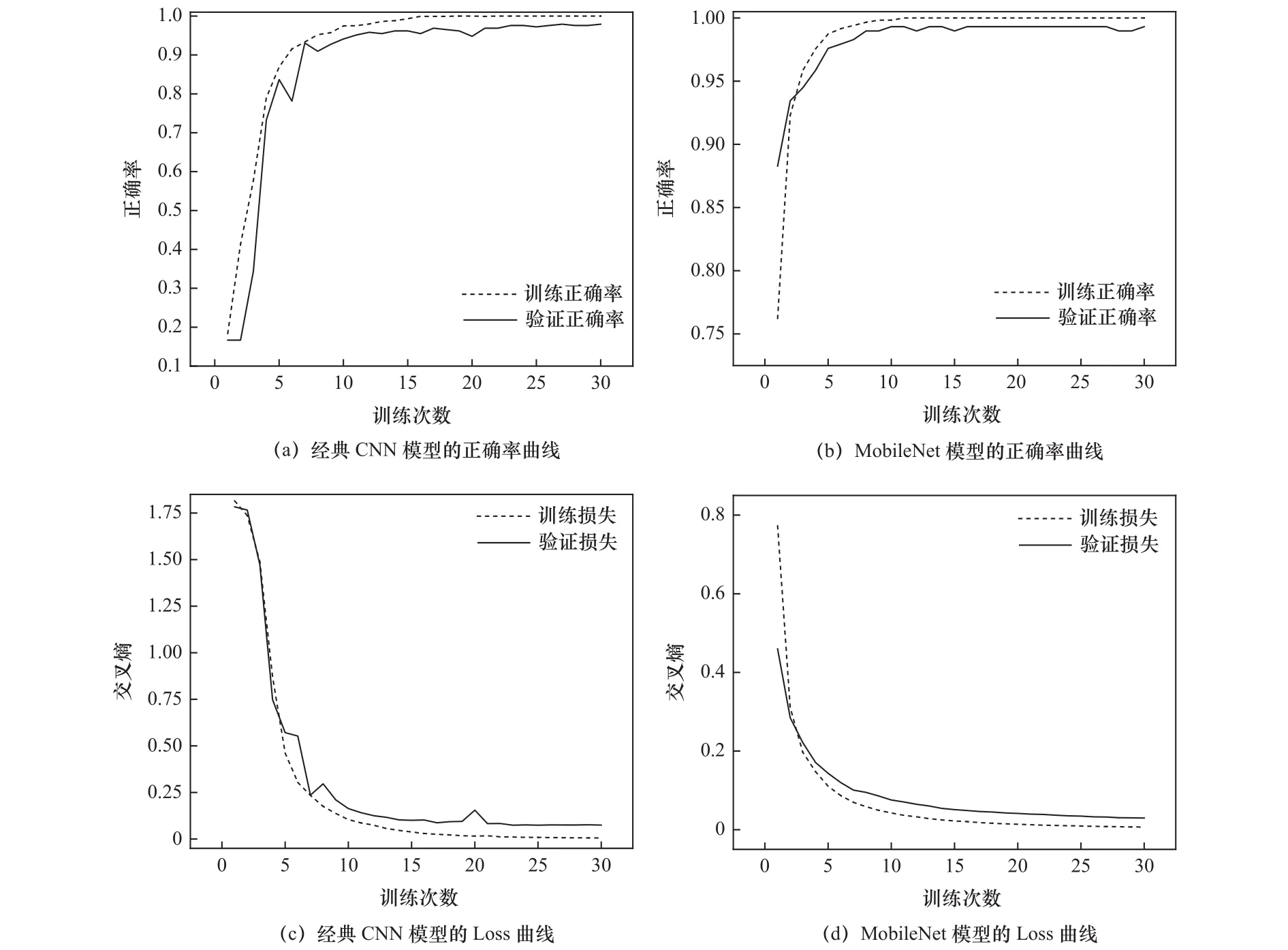
图5 两种神经网络模型的预测准确率与Loss曲线
经典CNN模型每次训练时长45 s,而MobileNet每次的训练时长约为34 s,后者相较于前者的训练效率提高20%~30%。对验证集绘制Heatmap图反映测试结果,从图6可以看出MobileNet模型相比于经典CNN模型具有较高的正确率。
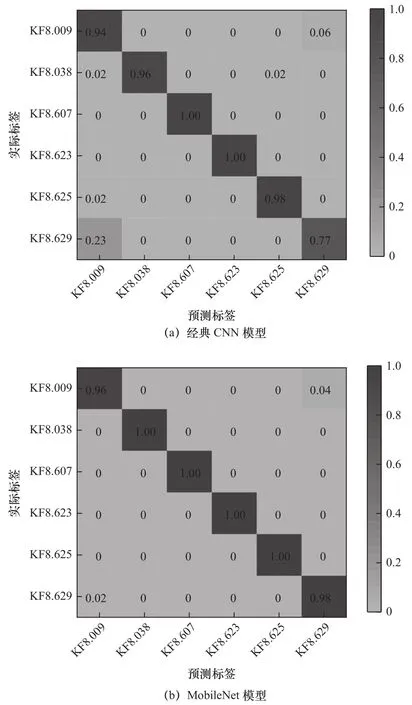
图6 两种神经网络模型的Heatmap
3.3 图号申请系统实现
基于Visual Studio 2012与PyCharm 2021编译平台,通过对SolidWorks 2020进行二次开发,使用VB.NET及Python混合编程完成系统的搭建。读取SolidWorks装配体进行图号批量申请,审核检查界面如图7a,并在图7b修改完成后在图7c批量分配流水号,最后将完整图号对应保存写入SolidWorks模型属性,关闭UI界面。
若在本次使用中产生了新的“同名异号”件,后台程序则对新模型进行归类,根据本次使用记录添加新子类并获取其三维模型的二维视图集,重新对该父类模型下的属性图号子类进行CNN训练,生成新的训练结果,以供下一次调用。
3.4 图号申请系统效果评估与误差分析
从正确率及申请耗时对系统进行评估,对企业20个冷藏车的订单批次进行测试,利用程序自动筛出标准件、借用件,统计系统申请耗时及图号正确率,并与人工申请耗时对比,绘制如图8。
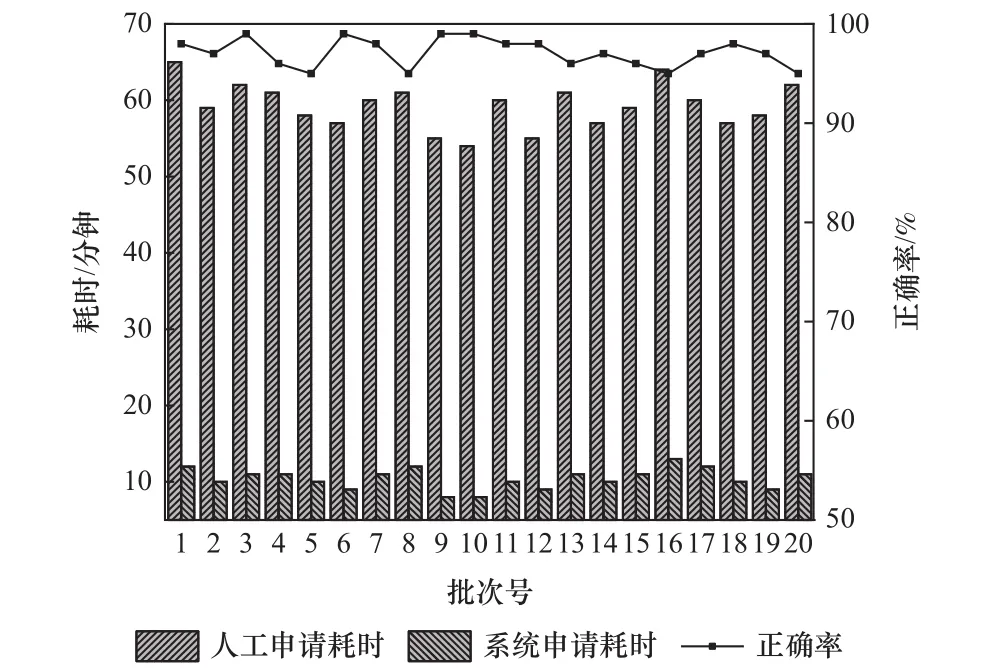
图8 人机图号申请耗时及系统申请正确率
在使用系统申请图号时,综合程序运行时间、人工修改检查时间及图号写入模型属性所需的总时间,总耗时平均在10~15 min,而人工申请图号的耗时平均在1 h。同时,系统图号申请的正确率均在95%以上,在误差率可接受范围内可节省80%以上的时间,效率可提高5~6倍。
申请结果之所以存在误差,原因之一是一个批次订单中可能需要设计若干个全新的零部件,这使得图号在分配时无法保证100%的正确率。除此之外,从图6中可以发现,如果“同名异号”件之中存在少数三维模型相似度很高的情况,MobileNet卷积神经网络模型也并不能达到100%的预测正确率。
同时,针对导致误差的原因,本文探索性地提出两点以提高图号申请的准确率:首先,规范设计人员的图纸名称命名方式以保证算法匹配的准确率。其次,针对“同名异号”件也考虑其他更为准确、快速且适合的三维模型相似性识别方法。除本文使用的基于多视图的识别思想外,基于体素或点云的三维模型识别方法也能够准确地进行三维模型的匹配,但同时也需要考量识别耗时,以求达到正确率与耗时之间的良好平衡。
4 结语
本文针对制造型企业设计过程中存在的图号申请耗时多、效率低的问题设计了一种智能图号批量申请系统。基于机器学习的思想充分利用历史图号申请记录对当下的图号申请进行决策,将K-means++、KNN和MVCNN等算法结合实际需求进行融合和改进,在保证正确率的同时大大缩减了图号申请的耗时,提高了产品设计的效率。
猜你喜欢
北京测绘(2022年6期)2022-08-01 03:57:08
磁共振成像(2021年4期)2021-03-25 07:48:26
蚌埠医学院学报(2020年9期)2020-12-11 15:38:47
科学中国人·上半月(2020年4期)2020-06-03 09:07:52
电子竞技(2018年20期)2018-12-17 01:23:52
中学生数理化·中考版(2017年6期)2017-11-09 02:46:46
非公有制企业党建(2017年10期)2017-11-03 02:26:27
火控雷达技术(2017年1期)2017-08-16 13:28:57
现代兵器(2017年4期)2017-06-02 15:59:24
现代兵器(2017年4期)2017-06-02 15:58:14
