
基于改进SOLOv2的穴盘幼苗图像分割方法
2023-02-02 11:33:32庄前伟王志明吴龙贻李恺王春辉
南京农业大学学报 2023年1期
庄前伟,王志明*,吴龙贻,李恺,王春辉
(1.南京理工大学机械工程学院,江苏 南京 210094;2.农业农村部规划设计研究院设施农业研究所,北京 100125)
穴盘育苗是指用草炭、蛭石、珍珠岩等轻基质无土材料作为育苗基质,进行集约化管理育苗的一项技术[1]。这种技术对幼苗统一播种管理,具有成活率高、育苗周期短、患病虫害率低的优势。但是由于种子品质、培育方式和生长环境等差异,幼苗往往会表现出叶片小、茎秆细、节点多、植株矮等症状,培育的幼苗质量参差不齐,极大影响后续移栽的质量和成活率。因此,幼苗品质分级对于提高幼苗移栽存活率和最大程度实现经济效益具有重要意义。传统方法大都依靠人工观察幼苗的生长状况进行分级移栽,存在耗时耗力、移栽成本高、工作量大等问题,不利于幼苗大规模分级移栽[2-3]。近年来,利用机器视觉技术测量分割幼苗的株高、叶片面积等指标,建立幼苗指标评价体系,可以实现对幼苗品质的自动分级[3]。因此,通过对图像分割领域的不断探索,提高果蔬幼苗的分割精度和效率,可以为幼苗品质分级提供技术帮助。
目前,随着机器学习技术的不断发展,在果蔬幼苗分割研究领域出现了各种算法。Niu等[4]提出 K-means 聚类方法实现对小麦叶片病害区域的分割,将叶片图像转换到Lab色彩空间,利用病害区域颜色信息进行迭代聚类,分割出病害区域的准确性可达90%,但易受噪声干扰,病害区域存在欠分割现象。Anam[5]则在K-means聚类分割叶片病害区域的基础上,使用粒子群算法来搜索病害区域全局最佳阈值作为初始聚类中心,避免受噪声点干扰收敛到局部最优解,进一步提高病害区域的分割精度。针对重叠番茄幼苗叶片的分割,张宁等[6]提出采用大津法OSTU和HOG(histogram of oriented gradient)描述子结合来标记叶片边缘区域,再进行分水岭操作实现叶片的分割,分割较为精确,极大抑制叶片的过分割。这些传统的分割方法虽然对特定场景下叶片分割取得一定的效果,但是算法操作复杂、易受光照不均匀和复杂背景等因素影响,使得分割效果精确度低、鲁棒性差。为此,Ma等[7]提出基于SegNet模型的全卷积语义分割网络,分割平均准确率可达92.7%,有效实现了水稻和杂草的分割,但存在叶片边缘分割不够细致的情况。针对葡萄叶片分割,李余康等[8]采用ResNet101为骨干网络的DeepLab v3+语义分割网络,测试准确率平均值可达98.6%,改善了叶片边缘区域的分割效果。权龙哲等[9]采用改进掩码Mask R-CNN算法实现对农间杂草实例分割,使用Soft-NMS非极大值抑制滤除多余目标候选框,测试交并比0.5下的平均精度可达73.0%,分割精度有了一定提高,但是单个样本的处理耗时在0.6 s左右,运行速度需要进一步提高。
针对以上问题,本文提出一种改进SOLOv2算法对穴盘幼苗进行分割,以设计分离注意力网络(ResNeSt)作为特征提取模块,结合可变形卷积(DCNv2)和数据增强等手段,并加入秩和排序损失(rank & sort loss)平衡类别预测分支和掩码分支下超参数寻优,提高对穴盘幼苗分割的精度和效率,为幼苗的分级筛选提供技术支持。
1 穴盘幼苗分割网络结构
1.1 SOLOv2网络结构
SOLOv2能够动态分割图像中的每个实例,不依赖锚框(anchor box)检测,依靠实例中每个像素的位置和类别信息直接学习掩码标签进行分割[10],主要包括类别分支和掩码分支。SOLOv2结构框架如图1所示。首先,穴盘幼苗原图经全卷积网络[11](fully convolutional network,FCN)和特征金字塔[12](feature pyramid network,FPN)获取幼苗不同层级的特征图I。然后,类别分支采用划分网络的方式实现对物体的类别预测,掩码分支分解为卷积核学习分支和特征学习分支对物体掩码进行预测。最后,采用并行矩阵非极大值抑制(matrix non-maximum suppression,Matrix NMS)的方法得到最终的幼苗分割图。
1.1.1 类别分支SOLOv2将原图像划分成S×S的网格,那么物体中心所在的网格需要预测相应物体的分类类别。使用直接插值或者自适应池化的方式将经过FCN和FPN得到特征图I从尺寸H×W×E对齐到S×S×E,然后经过一系列的3×3的卷积将输出对齐到S×S×C,其中,E为特征通道数,C为预测类别,表示每个实例属于不同类别的概率。
1.1.2 掩码分支SOLOv2采用动态卷积的思想[10],将掩码分支解耦成卷积核分支和特征分支,使网络能够根据位置信息动态分割物体,那么原图像坐标(i,j)的掩码表示为:
Mi,j=Gi,j×F
(1)
式中:Mi,j为坐标(i,j)处的预测掩码;Gi,j为坐标(i,j)处的1×1的卷积核;F为原图像的掩码特征图。
卷积核分支用来学习分类器权重,相应卷积核的参数是基于输入预测的,具有灵活和自适应的特点[10]。将特征图I作为输入,采用4层卷积和3×3×D的卷积后生成预测掩码G的维度为S×S×D,其中,D为卷积核的权重。特征学习分支则用来学习特征的表达,输入的是特征金字塔提取5个不同层级的特征图I,输出特征F维度为H×W×E。将特征金字塔的第2~5层依次经过3×3卷积、组归一化(group norm)、修正线性单元(ReLU)、2个双线性插值,统一到原图的1/4尺寸,然后再做逐点相加(element-wise summation),经过1×1卷积、组归一化、修正线性单元,最终得到特征F。
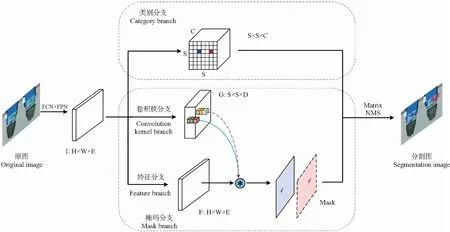
图1 SOLOv2结构框架Fig.1 SOLOv2 structural framework
1.1.3 矩阵非极大值抑制卷积核分支上每一个维度为1×1×D的卷积核在特征F分支上进行卷积操作,得到对应区域的掩码,掩码分支可生成S×S个掩码,给分割实例带来冗余的掩码。因此,针对掩码冗余和计算耗时的问题,Matrix NMS将掩码的交并比(intersection over union,IoU)进行并行化运算,采取得分惩罚机制来抑制冗余掩码。
首先,矩阵非极大值抑制按照置信度得分大小进行排序,生成各掩码之间交并比的关系矩阵,加快对交并比运算速度。其次,由于掩码抑制概率与交并比呈正相关,利用置信度得分最大交并比的值求出对应的抑制概率[10]。最后,通过抑制概率得到预测得分,可以生成掩码新的置信度得分,实现对冗余掩码的抑制。生成掩码j新的置信度得分Sj的计算公式为:
Sj=sj×decayj
(2)
(3)
式中:sj为原掩码j的置信度得分;decayj为掩码j的衰减因子;si为掩码i的置信度得分;f(ioui,j)是关于掩码i和j的衰减函数;f(iou.,i)是掩码i的关于交并比的正相关函数。
1.2 改进SOLOv2
1.2.1 ResNeSt骨干网络在进行穴盘幼苗分割时,骨干网络是用来提取实例特征的网络,提取特征是否充分决定后续网络分割是否精确。有限的感受野大小和缺乏跨通道之间的信息交互制约着如VGG[13]、ResNet[14]等一些网络的提取特征能力。为了保持原有骨干网络参数量不增加过多的情况下提高网络模型特征提取能力,采用拆分注意力网络(ResNeSt)进行特征提取,以提高SOLOv2分割网络性能。
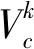
(4)
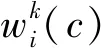
(5)
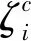
最后,将K个基数组沿通道维度拼接起来得到融合特征(V),V=Concat{V1,V2,…,VK},再经过1×1卷积后与原特征图进行残差连接,得到目标最终的特征信息。
设计ResNeSt作为骨干网络,结合特征金字塔(FPN),可以有效获取不同尺度下目标的特征信息,而且不会引入额外的参数量,在分割幼苗的茎秆和部分叶片等小目标区域时,可以获取更深层特征信息,目标区域分割效果更好。
1.2.2 可变形卷积DCNv2在对穴盘幼苗进行实例分割时,幼苗的大小、高度不一,叶片形状多变。由于常规卷积结构固定,对目标形状的感受野不够灵活,泛化性不强,无法极大提高卷积网络对不同机械手场景下穴盘幼苗几何形变的分割能力。可变形卷积(deformable convolutional networks,DCN)则是在传统卷积的基础上,增加了调整卷积核的方向向量,利用偏移量来学习实例的几何形变,在采样时更贴近物体的形状和尺寸,可以显著提高后续分割的精度。但是,可变形卷积引入随机偏移量的同时,会产生较多的与目标区域无关的干扰信息,DCNv2则加入了对每个采样点的权重,增加学习自由度的同时,可以将一些无关采样点的权重学习为0,使卷积区域在目标物体区域范围内[18]。
对于特征图p处的特征为y(p),计算公式为:
(6)
式中:K是在p处卷积核范围内所有采样的位置总数;wk为第k位置的权重;x(p+pk+Δpk)为p处偏移后的特征值;pk是预先设定p处的偏移;Δpk为第k位置上可学习的偏移;Δmk为第k位置上的可调权重。
可变形卷积DCNv2利用变形卷积核获取穴盘幼苗有效的采样区域,利于学习幼苗叶片形态多变的特征信息,提高SOLOv2算法对幼苗叶片的分割精度。
1.2.3 秩和排序损失SOLOv2算法利用类别分支实现目标类别的预测,利用掩码分支实现类别下对应实例的掩码预测[19],因此,总的损失函数L为:
L=Lcate+λLmask
(7)
式中:Lcate为类别损失函数;Lmask为掩码损失函数;λ为超参数,取值为2。
针对训练样本过程中样本不平衡的问题,使用焦点损失(focal loss,FL)作为类别预测损失函数,函数表达式为:
FL(pt)=-αt(1-pt)γlogpt
(8)
式中:αt是权重系数,取值为0.25;(1-pt)γ是调制因子;pt是样本属于正确类别的概率;γ是难易样本权重因子,取值为2。
为了侧重对前景区域的挖掘,使用骰子损失(dice loss,DL)作为掩码预测损失函数,函数表达式为:
(9)
式中:px,y表示在(x,y)处预测掩码的像素值;qx,y表示在(x,y)处真实掩码的像素值。
在SOLOv2算法架构的设计中,损失函数会引入一些手工设定的λ、αt等一些超参数,平衡不同预测分支下的权重,完成实例分割任务。首先,对于采集的穴盘幼苗,这些手工选取的超参数并不能很好适应特定场景下幼苗的分割。其次,对于类别损失所采用的焦点损失函数,随着训练迭代次数的增加,分类器对样本的拟合程度更高,易分类样本会增多,使用固定参数去调节正负样本的不均衡性,模型收敛较慢,无法使模型分割效果达到最优。此外,对于掩码损失所采用的骰子损失函数,适用于正负样本极度不均的情况,但是训练过程中易出现损失波动大、收敛速度慢的情况。
因此,设计秩和排序损失(Rank & Sort Loss,RS Loss)[20]函数平衡类别预测分支和掩码分支下超参数寻优问题,大大简化了原有模型训练的复杂性,使模型收敛更快。秩和排序损失是一种基于排序的损失函数,主要依据分类概率区分出目标图像的正负样本,可以处理极端样本不平衡的情况,并且依据交并比的大小对正样本优先级进行排序,训练时不再需要额外的辅助头。因此,对于样本i和样本j之间的差异性损失Lij为:
(10)
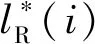
那么秩和排序总损失函数LRS为:
(11)
式中:Lij为样本i和样本j之间的差异性损失;Z为归一化常数;P为正样本集合;N为负样本集合。
SOLOv2是将分割问题转化为位置分类问题的直接实例分割方法,没有锚框回归头,因此使用骰子系数作为秩和排序损失训练视觉检测器的标签,区分正负样本并对分割目标的正样本进行优先级排序,加快类别分支和掩码分支下的寻优效率,使SOLOv2模型对幼苗分割时可更快收敛,提高分割的精度和效率。

图2 穴盘幼苗图像采集示意图Fig.2 Image collection schematic diagram of plug seedlings
2 材料与试验设计
2.1 样本采集与处理
穴盘幼苗图像的采集地点在农业农村部规划设计研究院永清院区。其中,穴盘幼苗是在温室中人工培育的番茄幼苗,育苗基质中蛭石、珍珠岩和草炭的质量比为1∶1∶3,白天环境温度为25 ℃左右,夜间温度为17 ℃左右,基质含水率约为13.9%,培育幼苗时间3~10 d。在自动移栽样机上进行穴盘幼苗图像采集,如图2所示。硬件部分主要选用S-YUE晟悦USB免驱工业相机,上方工业相机距幼苗高660 mm,采集穴盘幼苗的俯视图,正前方工业相机距幼苗500 mm,采集幼苗正视图,并配有光源照明。
为了增加幼苗样本图像的数量,在现场环境中,又加入一些样品假苗进行图像采集试验。采集到不同分辨率场景下包含6只机械手、2只机械手和 1只机械手抓取幼苗的正视图和俯视图图像,共计800张,以JPG格式存储,如图3所示。

图3 采集穴盘幼苗样本图Fig.3 Map of plug seedlings collected samples
为了提高训练模型的泛化性和鲁棒性,对采集的穴盘幼苗图像进行数据增强。随机挑选250张幼苗图像进行数据增强,主要变换有亮度调节、尺度变换和随机擦除[21]等。图4是以1只机械手正视图幼苗图像为例,进行数据增强。变换后最终幼苗样本图像为1 750张,使用开源工具Labelme软件对穴盘幼苗的基质、茎秆和叶片进行标注,将数据集制作成COCO数据集格式,随机划分穴盘幼苗60%作为训练集,20%作为验证集,20%作为测试集。
2.2 试验环境
试验运行环境:Ubuntu18.04操作系统,运行内存30 GB,显卡为2×GeForce GTX2080ti,配置python3.7、PyTorch1.6、GPU运行架构CUDA10.1、加速库为CUDNN7.6.5下的OpenMMLab开源框架[22]MMdetection 2.11作为模型运行框架。

图4 数据增强下幼苗样本Fig.4 Seedling samples under data augmentation
2.3 试验参数
设置不同尺度、不同拍摄角度下幼苗图像作为输入数据,类别数为3类:基质、茎秆和叶片;FPN输入各层通道数为256、512、1 024、2 048,输出特征层通道为256;设置SOLOv2和改进SOLOv2模型网格数分别为12、16、24、36、40,对应负责预测区域(384,2 048)、(192,768)、(96,384)、(48,192)、(1,96);优化器选择随机梯度下降,双卡GPU进行训练,单片显卡的batch为2,设置学习率为0.005,动量因子为0.9,权重衰减因子为0.000 1;设定36个epochs训练周期,每隔10个batch记录当前损失值信息,学习策略采取预热学习率,先线性迭代500次到0.005并保持稳定,训练到27和34个epochs学习率时进行衰减,加快收敛。用焦点损失作为类别分支损失函数,权重置为1;用骰子损失作为掩码分支损失函数,权重置为3。
2.4 分割指标
实例分割算法主要是将感兴趣的不同目标实例分割出来,本质上是解决像素点分类和类别识别的问题。实例分割算法评价指标是平均精度(average precision,AP)、平均精度均值(mean average precision,mAP)等。其中,AP是准确率和召回率曲线与坐标轴围成面积值,表达式为:
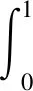
(12)
式中:p为准确率;r为召回率。
mAP是所有类别下平均精度,表达式为:
(13)
式中:N为类别数;APi为第i类别下的平均精度值。

图5 不同骨干网络训练损失曲线Fig.5 Training loss curves of different backbone network
3 结果与分析
3.1 骨干网络性能分析
将采集的穴盘幼苗图像输入到SOLOv2分割网络中,分别用ResNet50、ResNet101、ResNeSt50、ResNeSt101骨干网络进行模型训练,得到不同骨干网络下SOLOv2训练损失值变化曲线。由图5可知:4个不同的骨干网络随着迭代次数的增加,总损失值逐渐下降并趋于稳定,迭代到8 000次时损失值基本趋于稳定,迭代到9 930次时,模型基本达到收敛,以ResNeSt50为骨干网络的SOLOv2模型总损失值为 0.252,低于其他骨干网络模型的损失值,收敛能力较强。
为了选择最优的骨干网络,提高模型的泛化能力,将4种不同的骨干网络在验证集上分割能力进行比较,如表1所示。以ResNeSt50为骨干网络的参数量为27.5 M,模型训练时间为92 min,平均精度均值为62.1%,比ResNet101和ResNeSt101骨干网络的参数量少约40%,训练时间大约少30 min,平均精度均值高约0.9%,说明层次更深的网络参数量大,训练时间更长,收敛速度较慢。与ResNet50骨干网络相比,ResNeSt50模型参数量和训练时间略高,但是基质、茎秆和叶片平均精度分别高0.62%、1.54%和1.14%,说明ResNeSt网络增加跨通道间信息交互,使得提取幼苗的茎秆和叶片小目标区域信息能力更强。因此,综合考虑骨干网络模型的整体性能,选择ResNeSt50作为骨干网络。
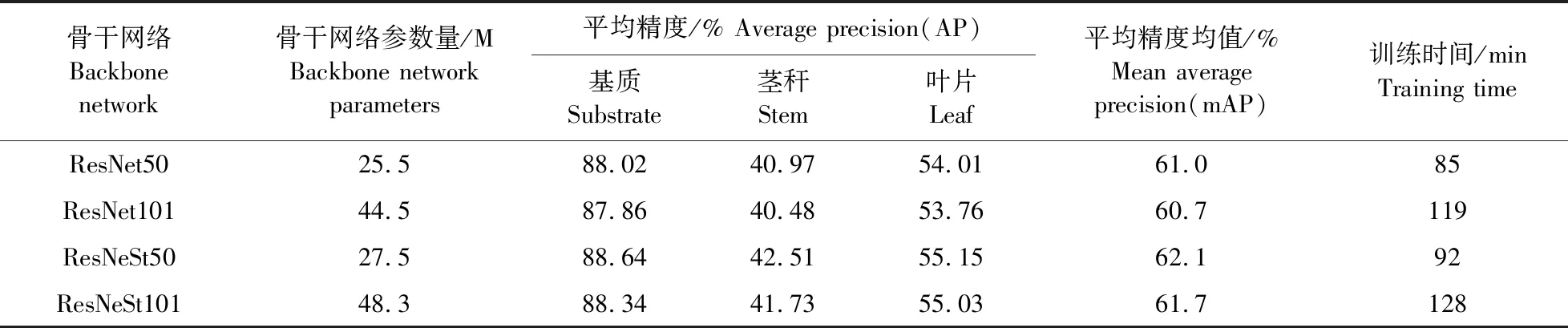
表1 不同骨干网络模型在验证集上分割能力结果对比Table 1 Comparison of segmentation ability results of different backbone network models on the validation set
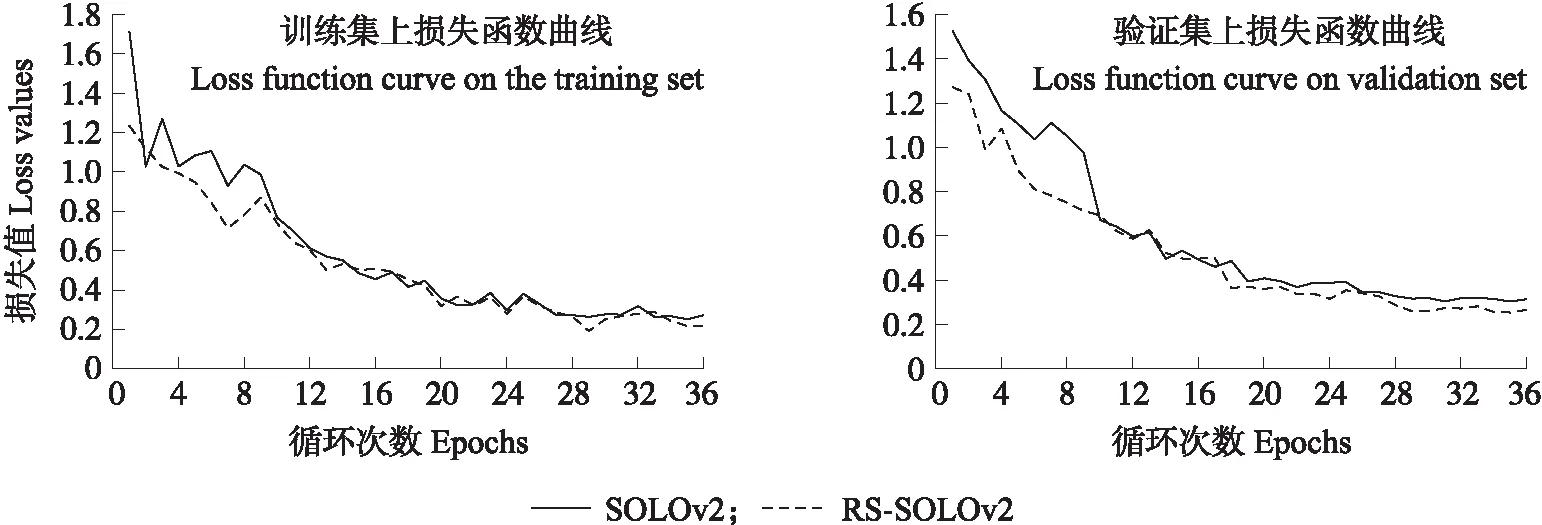
图6 不同损失函数模型损失值变化曲线Fig.6 Change curve of loss value of different loss function models
3.2 损失函数性能分析
把拆分注意力网络ResNeSt50和特征金字塔(FPN)作为穴盘幼苗特征提取的网络,将引入秩和排序损失(RS Loss)的RS-SOLOv2网络模型与SOLOv2模型分别训练36个epochs,得到训练集和验证集的总损失值变化曲线。由图6可知:引入秩和排序损失后的RS-SOLOv2模型比SOLOv2模型能更快实现收敛,并且RS-SOLOv2模型在验证集上泛化能力更好,迭代到36个epochs后在验证集上损失值为0.266,比SOLOv2损失值减小了0.048。
为了进一步验证引入秩和排序损失函数后模型的性能,计算该模型在测试集上的平均精度和单张图像分割时间,如表2所示。RS-SOLOv2模型的平均精度均值、IoU为0.5时平均精度和IoU为0.75时平均精度分别比SOLOv2模型提高0.8%、0.9%、0.6%,而且单张图片的平均分割时间为0.088 s,比SOLOv2模型分割时间减少48.8%。一方面,这是因为RS-SOLOv2模型不仅可以根据分类类别对应的概率区分出正负样本,而且将预测掩码所采用的骰子损失函数的系数作为实例分割标签,依据定位掩码质量对正样本进行排序,直接优化平均精度指标,使得训练的收敛模型与评估的平均精度指标在幼苗数据集上分割效果保持一致。另一方面,RS-SOLOv2不需要额外的辅助头,在优化平均精度指标的过程中不需要超参数调优,减少超参数的数量,提高分割运行的效率。因此,加入秩和排序损失函数后的RS-SOLOv2模型更具有鲁棒性和高效性。

表2 不同损失函数模型在测试集上的性能对比Table 2 Performance comparison of different loss function models on the test set
3.3 不同模型的性能分析
在确定骨干网络ResNeSt50与秩和排序损失的基础上,结合可变形卷积(Deformable Convolutional Networks version 2,DCNv2),得到改进SOLOv2模型。为了验证该算法的性能,将改进SOLOv2与其他主流的分割算法在穴盘幼苗的测试集上进行分割试验对比,计算分割精度和分割时间,如表3所示。其中,本文选择的主流算法主要有基于锚框的双阶段检测模型Mask RCNN[23]、基于锚框的单阶段检测模型YOLACT[24]和基于无锚框直接分割模型SOLO[19]、SOLOv2[10]。
由表3可知:改进SOLOv2算法对穴盘幼苗有更强的特征学习能力,能够较为准确地分割出目标区域,精度指标mAP、AP50、AP75分别为64.1%、88.5%、65.7%,比其他算法的mAP高2.8%~13.4%,AP50高3.1%~14.2%,AP75高2.3%~14.2%。此外,改进SOLOv2算法在图像处理器(graphics processing unit,GPU)上对每张幼苗图像的平均分割时间为0.114 s,比YOLACT略高,比Mask RCNN减少58.7%,比SOLO减少53.1%,比SOLOv2减少33.7%,分割速度快,极大地满足实时性的需求。

表3 不同模型对穴盘幼苗分割性能对比Table 3 Comparison of the segmentation performance of plug seedlings with different models
3.4 穴盘幼苗分割效果
在采集的穴盘幼苗测试集图像中,选择一些分割难度较大的4只机械手、2只机械手和1只机械手抓取幼苗正视图的图像,并用传统分割算法、SOLOv2和改进SOLOv2模型进行分割可视化,分割效果如图7所示。其中,对于穴盘幼苗的分割,传统分割算法主要用模板匹配方法来提取幼苗的基质区域,考虑到幼苗茎秆和叶片呈现绿色,选用颜色阈值法提取幼苗区域。对于暗环境(图7-c)则是先进行亮度增强,再使用颜色阈值分割方法提取幼苗区域。SOLOv2和改进SOLOv2模型则是用默认的参数设置对幼苗进行分割试验。
针对穴盘幼苗的分割,传统图像分割算法整体的分割效果较差,对于图7-a中较细的茎秆和暗环境下图7-c中茎秆区域分割不出来,对于图7-a、b和c中叶片分割不够细致,无法准确分割出茎秆和叶片区域,并且易受背景颜色干扰,造成目标区域欠分割和背景过分割现象。SOLOv2和改进SOLOv2分割模型则可以准确分割出幼苗的目标区域,在较暗环境下也能准确分割出茎秆区域。相比于SOLOv2模型,改进SOLOv2模型可以分割出图7-a中第一株穴盘幼苗中的小叶片区域,而SOLOv2则出现了漏检的情况,说明引入拆分注意力网络ResNeSt增强了特征信息通道间的交互,结合多尺度变换策略,增强对小目标区域的检测能力。同时,改进SOLOv2采用DCNv2的变形卷积核,使得对于图7-a、b和c中茎秆与叶片相粘连的区域处分割精确高,而SOLOv2模型在图7-c的暗环境下,对于茎秆与叶片相粘连的区域处出现欠分割现象。因此,改进SOLOv2模型更适用于幼苗在暗环境和多变机械手抓取场景下的高精度分割要求。

图7 穴盘幼苗分割效果Fig.7 The segmentation effect of plug seedlings
4 小结
为了提高穴盘幼苗在多变机械手抓取场景下分割的精确度和高效性,在原SOLOv2网络模型的架构下,使用特征提取能力更强的拆分注意力网络,结合特征金字塔,进行穴盘幼苗的特征提取,并使用可变形卷积,加强对不规则叶片目标区域的定位能力。模型损失函数中加入秩和排序损失优化平均精度指标,减少超参数调优,同时采用多尺度训练和网络擦除等数据增强手段,极大地提升了对幼苗分割的精确度和分割效率。
本研究对不同机械手场景下采集的1 750张穴盘幼苗图像进行训练、验证和测试。试验结果表明,改进SOLOv2算法的平均精度均值为64.1%,交并比为0.5的平均精度为88.5%,交并比为0.75的平均精度为65.7%,明显优于传统的SOLOv2、Mask RCNN、YOLACT、SOLO网络模型,单张图像平均分割时间为0.114 s,分割速度略低于YOLACT网络,优于Mask RCNN、SOLO和传统SOLOv2网络,满足实时分割的需求,为实现果蔬幼苗品质自动分级筛选奠定基础。
猜你喜欢
今日农业(2021年10期)2021-11-27 09:45:24
四川蚕业(2020年3期)2020-07-16 08:09:42
通信学报(2019年5期)2019-06-11 03:05:56
通信技术(2018年3期)2018-03-21 00:56:37
蔬菜(2016年8期)2016-10-10 06:49:04
中国火炬(2015年12期)2015-07-31 17:38:35
浙江大学学报(工学版)(2015年4期)2015-03-01 01:17:53
电子设计工程(2015年20期)2015-01-29 02:58:24
长江蔬菜(2014年1期)2014-03-11 15:09:54
茶叶通讯(2014年1期)2014-02-27 07:55:37
